Amazonin punainen siirto on nopea, täysin hallittu petatavun mittakaavainen pilvitietovarasto, jonka avulla on helppoa ja kustannustehokasta analysoida kaikki tietosi käyttämällä SQL-standardia ja olemassa olevia Business Intelligence (BI) -työkalujasi. Kymmenet tuhannet asiakkaat käyttävät nykyään Amazon Redshiftiä analysoidakseen eksatavuja dataa ja suorittaakseen analyyttisiä kyselyitä, mikä tekee siitä laajimmin käytetyn pilvitietovaraston. Amazon Redshift on saatavana sekä palvelimettomina että provisioiduissa kokoonpanoissa.
Amazon Redshiftin avulla voit käyttää suoraan sisään tallennettuja tietoja Amazonin yksinkertainen tallennuspalvelu (Amazon S3) käyttämällä SQL-kyselyitä ja yhdistämällä tietoja tietovarastossasi ja datajärvessäsi. Amazon Redshiftin avulla voit tiedustella S3-datajärvesi tietoja keskusyksikön avulla AWS-liima metastore Redshift-tietovarastostasi.
Amazon Redshift tukee useiden tietomuotojen kyselyä, kuten CSV, JSON, Parquet ja ORC, ja taulukkomuotoja, kuten Apache Hudi ja Delta. Amazon Redshift tukee myös sisäkkäisten tietojen kyselyä monimutkaisilla tietotyypeillä, kuten struct, array ja map.
Tämän ominaisuuden avulla Amazon Redshift laajentaa petatavun mittakaavan tietovarastosi Amazon S3:n eksatavun mittakaavan datajärveksi kustannustehokkaalla tavalla.
Apache Iceberg on uusin taulukkomuoto, jota Amazon Redshift tukee nyt esikatselussa. Tässä viestissä näytämme sinulle, kuinka voit tehdä kyselyitä Iceberg-taulukoista Amazon Redshiftin avulla ja tutkia Iceberg-tukea ja -vaihtoehtoja.
Ratkaisun yleiskatsaus
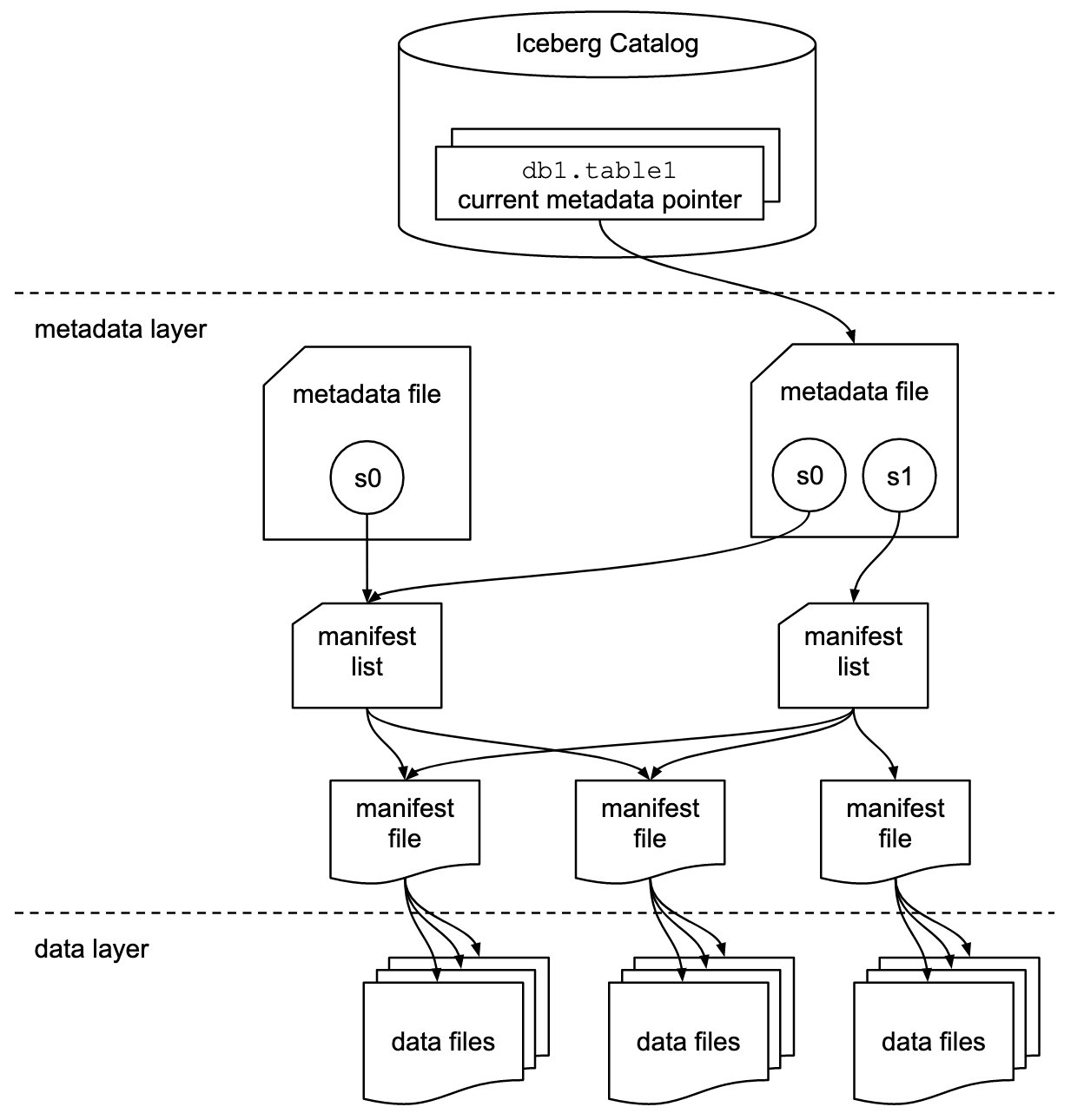
Apache jäävuori on avoin taulukkomuoto erittäin suurille petabyyttimittaisille analyyttisille tietojoukoille. Iceberg hallitsee suuria tiedostokokoelmia taulukoina, ja se tukee nykyaikaisia analyyttisiä datajärvitoimintoja, kuten tietuetason lisäys-, päivitys-, poisto- ja aikamatkakyselyitä. Iceberg-spesifikaatio mahdollistaa saumattoman taulukoiden, kuten skeemojen ja osioiden evoluution, ja sen suunnittelu on optimoitu käytettäväksi Amazon S3:ssa.
Iceberg tallentaa metatietoosoittimen kaikille metatietotiedostoille. Kun SELECT-kysely lukee Iceberg-taulukkoa, kyselykone siirtyy ensin Iceberg-luetteloon ja hakee sitten viimeisimmän metatietotiedoston sijainnin seuraavan kaavion mukaisesti.
Amazon Redshift tukee nyt Apache Iceberg -taulukoita, joiden avulla data Lake -asiakkaat voivat suorittaa vain luku -muotoisia analytiikkakyselyitä tapahtumien johdonmukaisella tavalla. Tämän avulla voit helposti hallita ja ylläpitää taulukoitasi tapahtumatietojärvissä.
Amazon Redshift tukee Apache Icebergin alkuperäistä skeemaa ja osion kehitysominaisuuksia käyttämällä AWS-liimatietoluettelo, jolloin ei tarvitse muuttaa taulukkomäärityksiä uusien osioiden lisäämiseksi tai suurten tietomäärien siirtämiseksi ja käsittelemiseksi olemassa olevan datajärvitaulukon kaavion muuttamiseksi. Amazon Redshift käyttää Apache Iceberg -taulukon metatietoihin tallennettuja saraketilastoja optimoidakseen kyselysuunnitelmansa ja vähentääkseen kyselyiden suorittamiseen tarvittavia tiedostotarkistuksia.
Tässä viestissä käytämme Keltainen taksitietojoukko NYC Taxi & Limousine Commissionilta lähdetietoinamme. Tietojoukko sisältää datatiedostoja Apache-parketti muodossa Amazon S3:ssa. Käytämme Amazon Athena muuntaaksesi tämän Parketti-tietojoukon ja käyttääksesi sitä Amazonin punasiirtospektri tehdä kyselyitä ja liittyä paikalliseen Redshift-taulukkoon, suorittaa rivitason poistoja ja päivityksiä sekä osioiden kehitystä, kaikki koordinoidaan AWS Glue Data Catalogin kautta S3-tietojärvessä.
Edellytykset
Sinulla tulee olla seuraavat edellytykset:
Muunna parkettitiedot jäävuoritaulukoksi
Tätä postausta varten tarvitset Keltainen taksitietojoukko NYC Taxi & Limousine Commissionilta saatavilla Iceberg-muodossa. Voit ladata tiedostot ja sitten muuntaa Parquet-tietojoukon Iceberg-taulukoksi Athenen avulla tai katsoa Rakenna Apache Iceberg datajärvi käyttämällä Amazon Athenaa, Amazon EMR:ää ja AWS Gluea blogikirjoitus jäävuoritaulukon luomiseksi.
Tässä viestissä käytämme Athenaa tietojen muuntamiseen. Suorita seuraavat vaiheet:
- Lataa tiedostot edellisen linkin kautta tai käytä AWS-komentoriviliitäntä (AWS CLI) kopioidaksesi tiedostot julkisesta S3-alueesta vuosille 2020 ja 2021 S3-säilöisi käyttämällä seuraavaa komentoa:
Lisätietoja on Amazon Redshift CLI:n määrittäminen.
- Luo tietokanta
Icebergdbja luo Athena-ohjelmalla taulukko, joka osoittaa Parquet-muotoisia tiedostoja käyttämällä seuraavaa käskyä: - Tarkista Parketti-taulukon tiedot seuraavalla SQL:llä:

- Luo Iceberg-taulukko Athenassa seuraavalla koodilla. Näet taulukkotyypin ominaisuudet Iceberg-pöytänä parkettimuodolla ja napsahtaneella pakkauksella seuraavassa
create tablelausunto. Sinun on päivitettävä S3-sijainti ennen SQL:n suorittamista. Huomaa myös, että Iceberg-taulukko on osioituYearnäppäintä. - Kun olet luonut taulukon, lataa tiedot Iceberg-taulukkoon käyttämällä aiemmin ladattua Parkettitaulukkoa
nyc_taxi_yellow_parquetseuraavalla SQL:llä: - Kun SQL-käsky on valmis, tarkista Iceberg-taulukon tiedot
nyc_taxi_yellow_iceberg. Tämä vaihe on pakollinen ennen seuraavaan vaiheeseen siirtymistä. - Voit varmistaa, että nyc_taxi_yellow_iceberg-taulukko on Iceberg-muodossa ja osioitu Vuosi-sarakkeeseen käyttämällä seuraavaa komentoa:



Luo ulkoinen skeema Amazon Redshiftissä
Tässä osiossa osoitamme, kuinka luodaan ulkoinen skeema Amazon Redshiftissä, joka osoittaa AWS Glue -tietokantaan icebergdb kysyäksesi Iceberg-taulukosta nyc_taxi_yellow_iceberg jonka näimme edellisessä osiossa käyttämällä Athenaa.
Kirjaudu Redshiftiin kautta Kyselyeditori v2 tai SQL-asiakasohjelma ja suorita seuraava komento (huomaa, että AWS Glue -tietokanta icebergdb ja aluetietoja käytetään):

Lisätietoja ulkoisten skeemojen luomisesta Amazon Redshiftissä on kohdassa luo ulkoinen skeema
Kun olet luonut ulkoisen skeeman spectrum_iceberg_schema, voit tehdä kyselyn Iceberg-taulukosta Amazon Redshiftissä.
Tee kysely Iceberg-taulukosta Amazon Redshiftissä
Suorita seuraava kysely kyselyeditorissa v2. Ota huomioon, että spectrum_iceberg_schema on Amazon Redshiftissä luodun ulkoisen skeeman nimi nyc_taxi_yellow_iceberg on kyselyssä käytetty AWS Glue -tietokannan taulukko:
Seuraavan kuvakaappauksen kyselytiedot osoittavat, että Iceberg-muodossa oleva AWS-liimataulukko on kyselyssä Redshift Spectrumilla.

Tarkista jäävuoritaulukon kyselyn selityssuunnitelma
Voit käyttää seuraavaa kyselyä saadaksesi selityssuunnitelman, joka näyttää muodon ICEBERG:

Tarkista päivitykset tietojen johdonmukaisuuden varmistamiseksi
Kun päivitys on valmis Iceberg-taulukossa, voit tehdä kyselyn Amazon Redshiftistä nähdäksesi tapahtumien johdonmukaisen näkymän tiedoista. Suoritetaan kysely valitsemalla a vendorid ja tiettyä noutoa ja palautusta varten:

Päivitä seuraavaksi arvo passenger_count 4 ja trip_distance 9.4 hintaan a vendorid ja tietyt nouto- ja palautuspäivät Athenassa:

Suorita lopuksi seuraava kysely kyselyeditorissa v2 nähdäksesi päivitetyn arvon passenger_count ja trip_distance:
Kuten seuraavassa kuvakaappauksessa näkyy, Iceberg-taulukon päivitystoiminnot ovat saatavilla Amazon Redshiftissä.

Luo yhtenäinen näkymä paikallisesta taulukosta ja historiallisista tiedoista Amazon Redshiftissä
Nykyaikaisena tietoarkkitehtuuristrategiana voit järjestää historiallisia tietoja tai harvemmin käytettyjä tietoja datajärvessä ja säilyttää usein käytettyä dataa Redshift-tietovarastossa. Tämä tarjoaa joustavuutta hallita analytiikkaa mittakaavassa ja löytää kustannustehokkain arkkitehtuuriratkaisu.
Tässä esimerkissä lataamme 2 vuoden tiedot Redshift-taulukkoon; loput tiedoista jää S3-tietojärveen, koska kyseistä tietojoukkoa kysytään harvemmin.
- Käytä seuraavaa koodia ladataksesi 2 vuoden tiedot
nyc_taxi_yellow_recenttaulukko Amazon Redshiftissä, hankittu Iceberg-taulukosta:
- Seuraavaksi voit poistaa viimeisen 2 vuoden tiedot Iceberg-taulukosta käyttämällä seuraavaa Athenen komentoa, koska latasit tiedot Redshift-taulukkoon edellisessä vaiheessa:

Kun olet suorittanut nämä vaiheet, Redshift-taulukossa on 2 vuoden tiedot ja loput tiedoista ovat Amazon S3:n Iceberg-taulukossa.
- Luo näkymä käyttämällä
nyc_taxi_yellow_icebergJäävuoripöytä janyc_taxi_yellow_recenttaulukko Amazon Redshiftissä: - Tee nyt kysely näkymästä, suodatinolosuhteista riippuen, Redshift Spectrum skannaa joko jäävuoren tiedot, punasiirtymätaulukon tai molemmat. Seuraava esimerkkikysely palauttaa joukon tietueita kustakin lähdetaulukosta tarkistamalla molemmat taulukot:

Osion kehitys
Jäävuori käyttää piilotettu osiointi, mikä tarkoittaa, että sinun ei tarvitse manuaalisesti lisätä osioita Apache Iceberg -taulukoihisi. Amazon Redshift havaitsee automaattisesti uudet osioarvot tai uudet osion tiedot (lisää tai poista osiosarakkeita) Apache Iceberg -taulukoissa, eikä osioita tarvitse manuaalisesti päivittää taulukon määrittelyssä. Seuraava esimerkki osoittaa tämän.
Esimerkissämme jäävuoripöytä nyc_taxi_yellow_iceberg jaettiin alun perin vuoden ja myöhemmin sarakkeen mukaan vendorid lisättiin ylimääräiseksi osiosarakkeeksi, niin Amazon Redshift voi tehdä saumattomasti kyselyjä Iceberg-taulukosta nyc_taxi_yellow_iceberg kahdella eri osiojärjestelmällä tietyn ajanjakson aikana.

Huomioitavaa, kun kysytään Iceberg-taulukoita Amazon Redshiftillä
Ota esikatselujakson aikana huomioon seuraavat asiat, kun käytät Amazon Redshift -ohjelmaa Iceberg-taulukoiden kanssa:
- Vain AWS Glue Data Catalogissa määritettyjä Iceberg-taulukoita tuetaan.
- Ulkoisen taulukon CREATE- tai ALTER-komentoja ei tueta, mikä tarkoittaa, että Iceberg-taulukon pitäisi olla jo olemassa AWS Glue -tietokannassa.
- Aikamatkakyselyitä ei tueta.
- Iceberg-versiot 1 ja 2 ovat tuettuja. Lisätietoja Iceberg-muotoisista versioista on kohdassa Muotoilun versiointi.
- Katso luettelo tuetuista tietotyypeistä Iceberg-taulukoilla Apache Iceberg -taulukoiden tuetut tietotyypit (esikatselu).
- Iceberg-taulukon kyselyn hinnoittelu on sama kuin muiden tietomuotojen käyttäminen Amazon Redshiftillä.
Lisätietoja Iceberg-muotoisten taulukoiden esikatseluun liittyvistä näkökohdista on kohdassa Apache Iceberg -taulukoiden käyttäminen Amazon Redshiftin kanssa (esikatselu).
Asiakaspalaute
"Tinuiti, suurin riippumaton suorituskykymarkkinointiyritys, käsittelee suuria määriä dataa päivittäin, ja sillä on oltava vankka datajärvi ja tietovarastostrategia, jotta markkinatiimimme voivat tallentaa ja analysoida kaikki asiakastietomme helposti, edullisessa ja turvallisessa muodossa. , ja vankka tapa”, sanoo Justin Manus, Tinuitin teknologiajohtaja. "Amazon Redshiftin tuki Apache Iceberg -taulukoille datajärvessämme, joka on ainoa totuuden lähde, vastaa kriittiseen haasteeseen suorituskyvyn ja käytettävyyden optimoinnissa ja yksinkertaistaa entisestään tietojen integrointiputkistoamme päästäksemme käsiksi kaikkeen eri lähteistä syötettyyn dataan ja tehostaaksemme toimintaamme. asiakkaiden brändipotentiaalia.”
Yhteenveto
Tässä viestissä näytimme sinulle esimerkin Iceberg-taulukon kyselyn tekemisestä Redshiftissä käyttämällä Amazon S3:een tallennettuja tiedostoja, jotka on luetteloitu taulukoksi AWS Glue Data Catalogissa, ja esittelimme joitain tärkeimmistä ominaisuuksista, kuten tehokkaan rivitason päivityksen ja poistamisen, ja skeeman evoluutiokokemus, jonka avulla käyttäjät voivat vapauttaa big datan voiman Athenen avulla.
Voit käyttää Amazon Redshiftiä kyselyjen suorittamiseen Data Lake -taulukoissa eri tiedostoissa ja taulukkomuodoissa, kuten Apache Hudi ja Delta-järvi, ja nyt kanssa Apache Iceberg (esikatselu), joka tarjoaa lisävaihtoehtoja nykyaikaisten tietoarkkitehtuurien tarpeisiin.
Toivomme, että tämä antaa sinulle loistavan lähtökohdan Iceberg-taulukoiden kyselyyn Amazon Redshiftissä.
Tietoja Tekijät
 Rohit Bansal on Analyticsin asiantuntijaratkaisujen arkkitehti AWS:ssä. Hän on erikoistunut Amazon Redshiftiin ja työskentelee asiakkaiden kanssa rakentaakseen seuraavan sukupolven analytiikkaratkaisuja käyttämällä muita AWS Analytics -palveluita.
Rohit Bansal on Analyticsin asiantuntijaratkaisujen arkkitehti AWS:ssä. Hän on erikoistunut Amazon Redshiftiin ja työskentelee asiakkaiden kanssa rakentaakseen seuraavan sukupolven analytiikkaratkaisuja käyttämällä muita AWS Analytics -palveluita.
 Satish Sathiya on Amazon Redshiftin vanhempi tuotesuunnittelija. Hän on innokas iso data-harrastaja, joka tekee yhteistyötä asiakkaiden kanssa ympäri maailmaa menestyksen saavuttamiseksi ja heidän tietovarastoinnin ja datajärvi-arkkitehtuurin tarpeiden tyydyttämiseksi.
Satish Sathiya on Amazon Redshiftin vanhempi tuotesuunnittelija. Hän on innokas iso data-harrastaja, joka tekee yhteistyötä asiakkaiden kanssa ympäri maailmaa menestyksen saavuttamiseksi ja heidän tietovarastoinnin ja datajärvi-arkkitehtuurin tarpeiden tyydyttämiseksi.
 Ranjan Burman on Analyticsin asiantuntijaratkaisujen arkkitehti AWS:ssä. Hän on erikoistunut Amazon Redshiftiin ja auttaa asiakkaita rakentamaan skaalautuvia analyyttisiä ratkaisuja. Hänellä on yli 16 vuoden kokemus erilaisista tietokanta- ja tietovarastointitekniikoista. Hän on intohimoinen automatisoimiseen ja asiakkaiden ongelmien ratkaisemiseen pilviratkaisuilla.
Ranjan Burman on Analyticsin asiantuntijaratkaisujen arkkitehti AWS:ssä. Hän on erikoistunut Amazon Redshiftiin ja auttaa asiakkaita rakentamaan skaalautuvia analyyttisiä ratkaisuja. Hänellä on yli 16 vuoden kokemus erilaisista tietokanta- ja tietovarastointitekniikoista. Hän on intohimoinen automatisoimiseen ja asiakkaiden ongelmien ratkaisemiseen pilviratkaisuilla.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- ChartPrime. Nosta kaupankäyntipeliäsi ChartPrimen avulla. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Meistä
- pääsy
- Accessed
- saavutettavuus
- Pääsy
- Saavuttaa
- poikki
- lisätä
- lisä-
- lisä-
- osoitteet
- edullinen
- Kaikki
- mahdollistaa
- jo
- Myös
- Amazon
- Amazon Athena
- Amazonin EMR
- Amazon Web Services
- määrät
- an
- Analyyttinen
- analyyttinen
- Analytics
- analysoida
- ja
- Kaikki
- Apache
- arkkitehtuuri
- OVAT
- noin
- Ryhmä
- AS
- At
- automaattisesti
- automatisointi
- saatavissa
- AWS
- AWS-liima
- perusta
- koska
- ennen
- ovat
- Iso
- Big Data
- sitova
- Blogi
- sekä
- merkki
- rakentaa
- liiketoiminta
- bisnesvaisto
- by
- CAN
- kyvyt
- valmiudet
- luettelo
- keskeinen
- tietty
- haaste
- muuttaa
- päällikkö
- Chief Technology Officer
- asiakas
- pilvi
- koodi
- kokoelmat
- Sarake
- Pylväät
- täydellinen
- monimutkainen
- olosuhteet
- Harkita
- näkökohdat
- johdonmukainen
- sisältää
- muuntaa
- koordinoi
- kustannustehokas
- luoda
- luotu
- Luominen
- kriittinen
- asiakas
- asiakastiedot
- Asiakkaat
- päivittäin
- tiedot
- datan integraatio
- Datajärvi
- tietovarasto
- tietokanta
- aineistot
- Päivämäärät
- oletusarvo
- määritelty
- määritelmä
- määritelmät
- Delta
- osoittaa
- osoittivat
- osoittaa
- Riippuen
- Malli
- yksityiskohdat
- havaittu
- dev
- eri
- suoraan
- Dont
- kaksinkertainen
- download
- kukin
- helposti
- helppo
- toimittaja
- tehokas
- myöskään
- poistamalla
- mahdollistaa
- Moottori
- insinööri
- intoilija
- merkintä
- Eetteri (ETH)
- evoluutio
- esimerkki
- olla
- olemassa
- experience
- Selittää
- tutkia
- ulottuu
- ulkoinen
- lisää
- FAST
- Ominaisuudet
- filee
- Asiakirjat
- suodattaa
- Löytää
- Yritys
- Etunimi
- Joustavuus
- jälkeen
- varten
- muoto
- usein
- alkaen
- täysin
- edelleen
- saada
- antaa
- maapallo
- Goes
- suuri
- Ryhmä
- Vetimet
- Olla
- he
- auttaa
- historiallinen
- toivoa
- Miten
- Miten
- HTML
- http
- HTTPS
- if
- in
- itsenäinen
- tiedot
- integraatio
- Älykkyys
- tulee
- IT
- SEN
- yhdistää
- jpg
- json
- Justin
- Pitää
- avain
- järvi
- suuri
- suurin
- Sukunimi
- myöhemmin
- uusin
- OPPIA
- vähemmän
- pitää
- RAJOITA
- linja
- LINK
- Lista
- kuormitus
- paikallinen
- sijainti
- ylläpitää
- TEE
- Tekeminen
- hoitaa
- onnistui
- hallinnoi
- tapa
- manuaalinen
- käsin
- kartta
- markkinat
- Marketing
- välineet
- Tavata
- Metadata
- Moderni
- lisää
- eniten
- liikkua
- liikkuvat
- täytyy
- nimi
- syntyperäinen
- Tarve
- tarvitaan
- tarpeet
- Uusi
- seuraava
- seuraavan sukupolven
- Nro
- huomata
- nyt
- numero
- NYC
- of
- upseeri
- on
- avata
- toiminta
- Operations
- Optimoida
- optimoitu
- optimoimalla
- Vaihtoehdot
- or
- alun perin
- Muut
- meidän
- ulostulo
- yli
- sivulla
- intohimoinen
- suorittaa
- suorituskyky
- aika
- suunnitelma
- suunnitelmat
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- Kirje
- mahdollinen
- teho
- edellytyksiä
- preview
- edellinen
- aiemmin
- ongelmia
- prosessi
- Tuotteet
- ominaisuudet
- tarjoaa
- julkinen
- kyselyt
- Lukeminen
- asiakirjat
- vähentää
- alue
- poistaa
- korvata
- tarvitaan
- REST
- Tuotto
- luja
- ajaa
- juoksu
- sama
- näki
- sanoo
- skaalautuva
- Asteikko
- skannata
- skannaus
- skannaa
- järjestelmiä
- saumaton
- saumattomasti
- Osa
- turvallinen
- nähdä
- vanhempi
- serverless
- Palvelut
- setti
- shouldnt
- näyttää
- osoittivat
- esitetty
- Näytä
- Yksinkertainen
- single
- ratkaisu
- Ratkaisumme
- Solving
- jonkin verran
- lähde
- Lähteet
- Sourcing
- asiantuntija
- erikoistunut
- määrittely
- silmälasit
- spektri
- SQL
- standardi
- Aloita
- Lausunto
- tilasto
- Vaihe
- Askeleet
- Levytila
- verkkokaupasta
- tallennettu
- varastot
- Strategia
- jono
- menestys
- niin
- tuki
- Tuetut
- Tukee
- taulukko
- tiimit
- Technologies
- Elektroniikka
- kymmeniä
- kuin
- että
- -
- Lähde
- heidän
- sitten
- Nämä
- tätä
- tuhansia
- Kautta
- aika
- aikamatka
- aikaleima
- että
- tänään
- työkalut
- kaupallisen
- matkustaa
- Totuus
- kaksi
- tyyppi
- tyypit
- yhdistynyt
- liitto
- avata
- Päivitykset
- päivitetty
- Päivitykset
- Käyttö
- käyttää
- käytetty
- Käyttäjät
- käyttötarkoituksiin
- käyttämällä
- VAHVISTA
- arvo
- arvot
- lajike
- eri
- hyvin
- kautta
- Näytä
- volyymit
- Varasto
- Varastointi
- oli
- Tapa..
- we
- verkko
- verkkopalvelut
- kun
- joka
- KUKA
- leveä
- laajalti
- tulee
- with
- toimii
- vuosi
- vuotta
- te
- Sinun
- zephyrnet