Kuva tekijältä
Datatiede on monitieteinen ala, joka perustuu vahvasti oivallusten poimimiseen ja tietoisten päätösten tekemiseen valtavasta datamäärästä. Yksi datatieteilijän työkalupakin perustyökaluista on SQL (Structured Query Language), ohjelmointikieli, joka on suunniteltu relaatiotietokantojen hallintaan ja manipulointiin.
Tässä artikkelissa keskityn yhteen SQL:n tehokkaimmista ominaisuuksista: liittymisestä.
SQL-liitosten avulla voit yhdistää tietoja useista tietokantataulukoista yhteisten sarakkeiden perusteella. Näin voit yhdistää tiedot yhteen ja luoda merkityksellisiä yhteyksiä toisiinsa liittyvien tietojoukkojen välille.
On olemassa useita SQL-liitostyypit:
- Sisäinen liittyminen
- Vasen ulompi liitos
- Oikea ulompi liitos
- Täysi ulkoliitos
- Risti liittyä
Selitetään jokainen tyyppi.
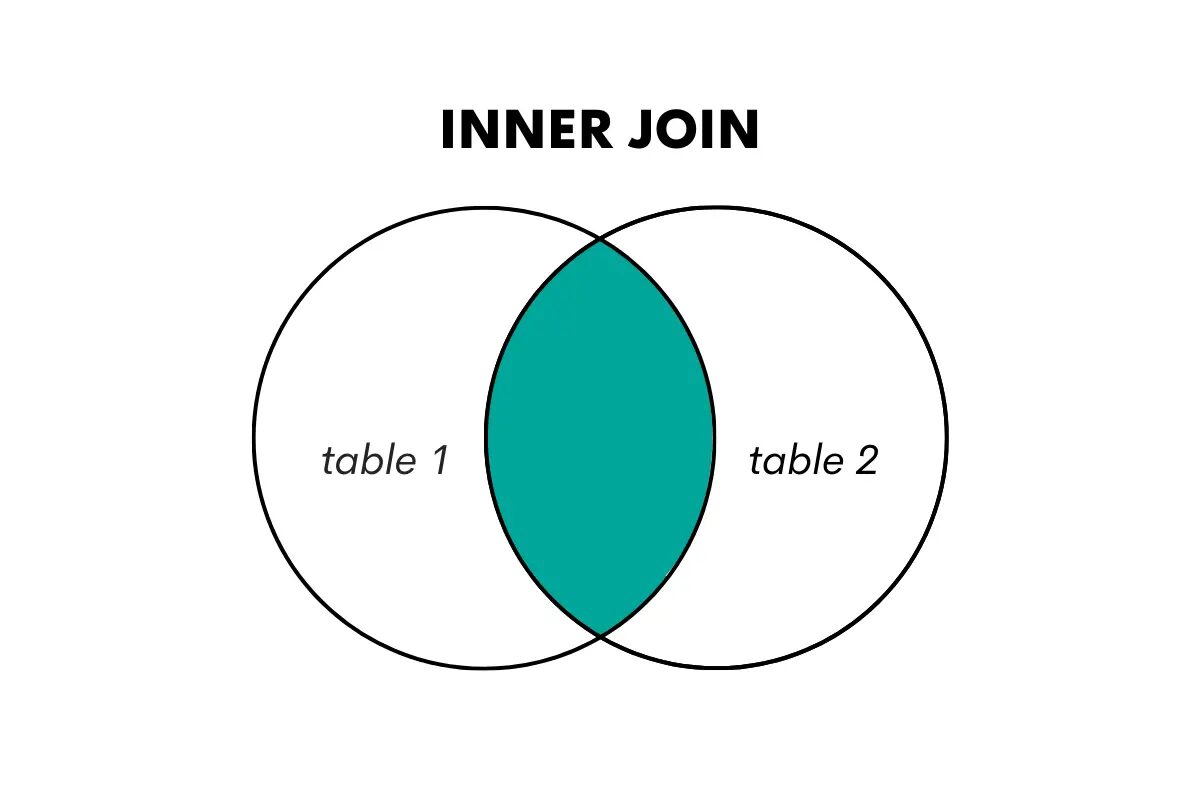
Sisäinen liitos palauttaa vain ne rivit, joilla molemmissa yhdistetyissä taulukoissa on osuma. Se yhdistää rivit kahdesta taulukosta jaetun avaimen tai sarakkeen perusteella ja hylkää yhteensopimattomat rivit.
Visualisoimme tämän seuraavalla tavalla.
Kuva tekijältä
SQL:ssä tämäntyyppinen liitos suoritetaan käyttämällä avainsanoja JOIN tai INNER JOIN.
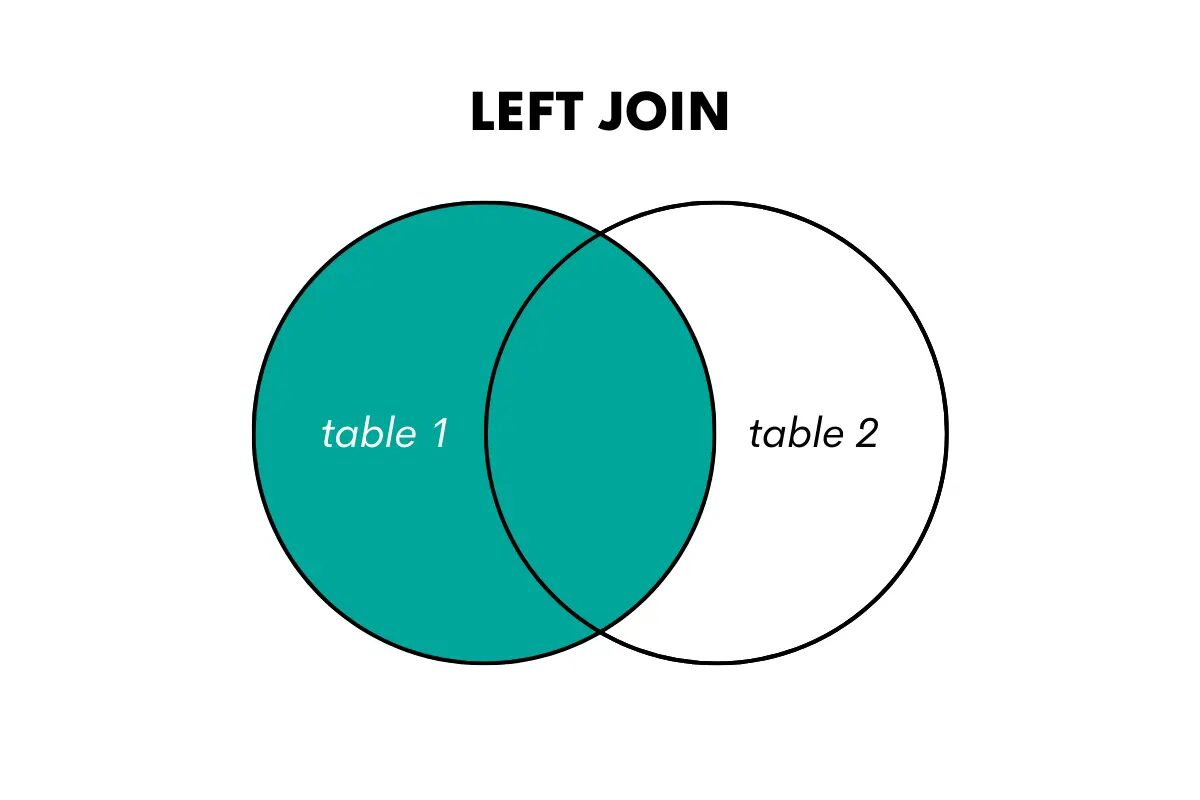
Vasen ulompi liitos palauttaa kaikki rivit vasemmasta (tai ensimmäisestä) taulukosta ja vastaavat rivit oikeasta (tai toisesta) taulukosta. Jos vastaavuutta ei löydy, se palauttaa oikeanpuoleisen taulukon sarakkeiden NULL-arvot.
Voimme visualisoida sen näin.
Kuva tekijältä
Kun haluat käyttää tätä liitosta SQL:ssä, voit tehdä sen käyttämällä LEFT OUTER JOIN tai LEFT JOIN avainsanoja. Tässä on artikkeli, jossa puhutaan vasen liitos vs vasen ulompi liitos.
Oikea liitos on vasemman liitoksen vastakohta. Se palauttaa kaikki rivit oikeanpuoleisesta taulukosta ja vastaavat rivit vasemmasta taulukosta. Jos vastaavuutta ei löydy, se palauttaa NULL-arvot sarakkeille vasemmasta taulukosta.
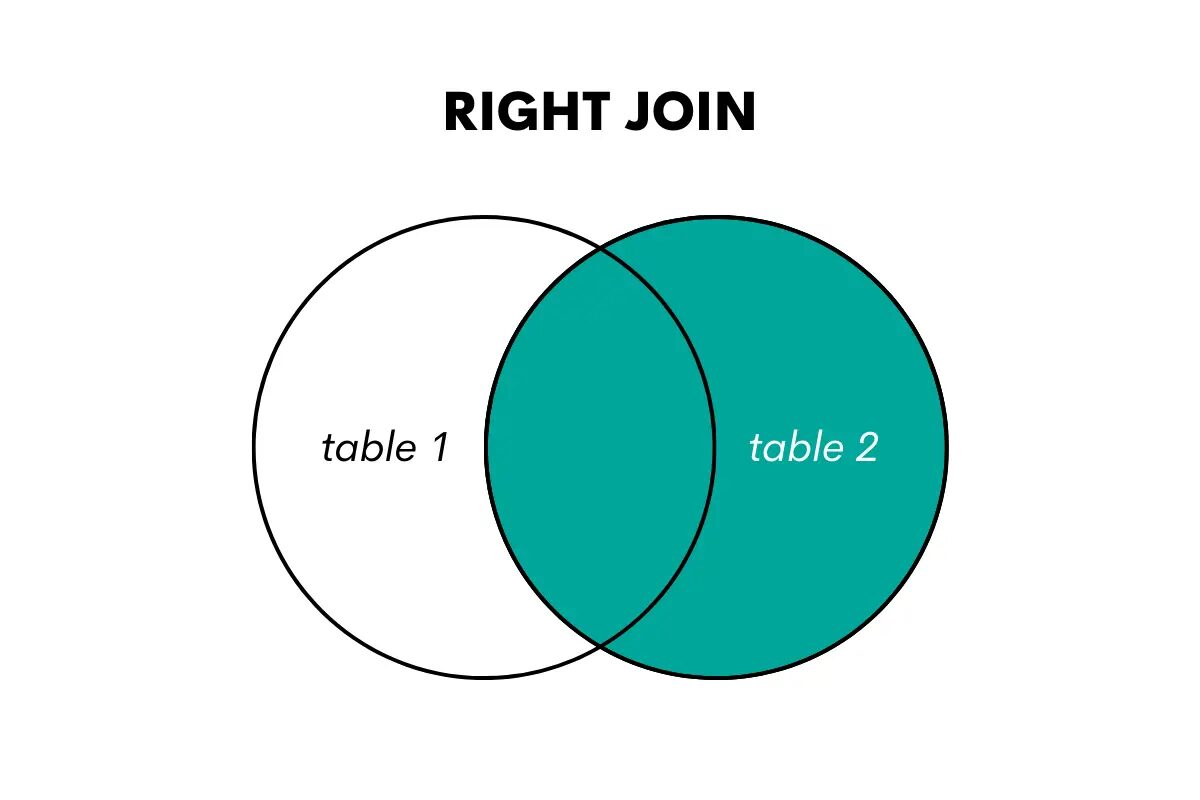
Kuva tekijältä
SQL:ssä tämä liitostyyppi suoritetaan käyttämällä avainsanoja RIGHT OUTER JOIN tai RIGHT JOIN.
Täysi ulompi liitos palauttaa kaikki rivit molemmista taulukoista, vastaavat rivit mahdollisuuksien mukaan ja täyttämällä NULL-arvot yhteensopimattomille riveille.
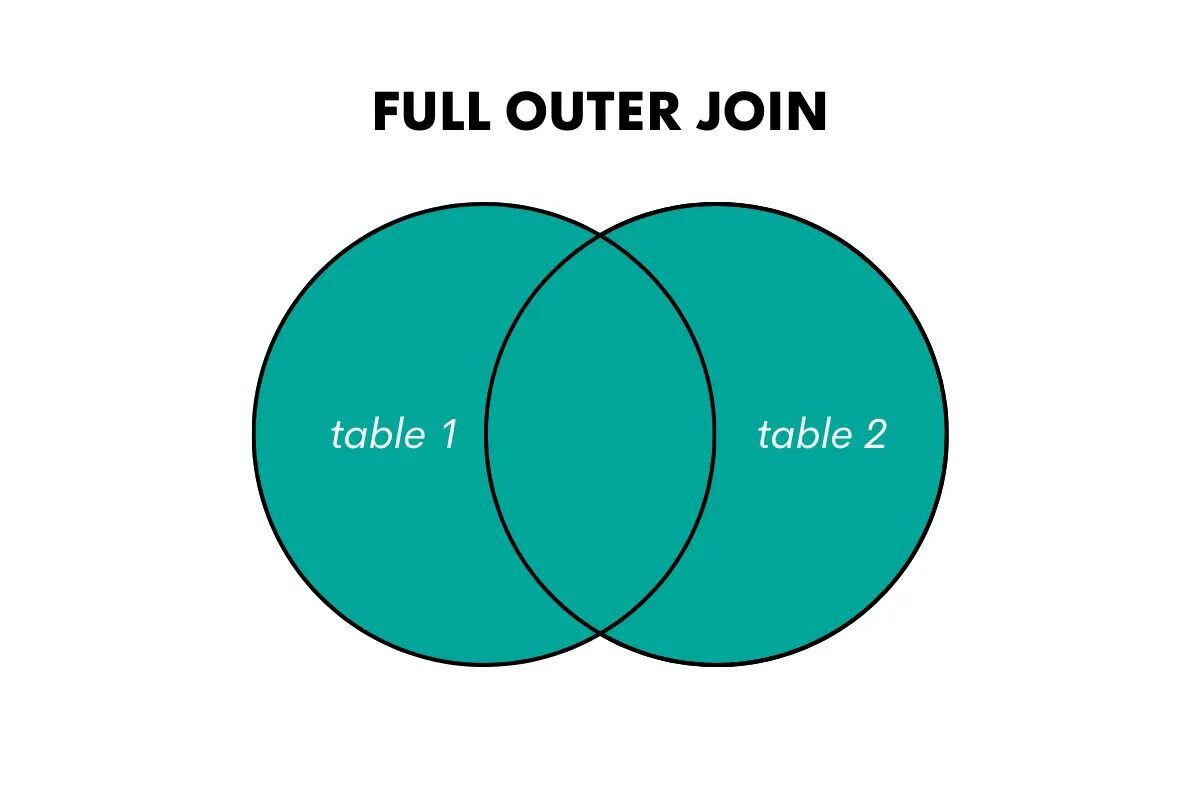
Kuva tekijältä
Tämän liitoksen avainsanat SQL:ssä ovat FULL OUTER JOIN tai FULL JOIN.
Tämäntyyppinen liitos yhdistää kaikki yhden taulukon rivit kaikkiin toisen taulukon riveihin. Toisin sanoen se palauttaa karteesisen tuotteen eli kaikki mahdolliset yhdistelmät kahden taulukon rivistä.
Tässä on visualisointi, joka helpottaa ymmärtämistä.
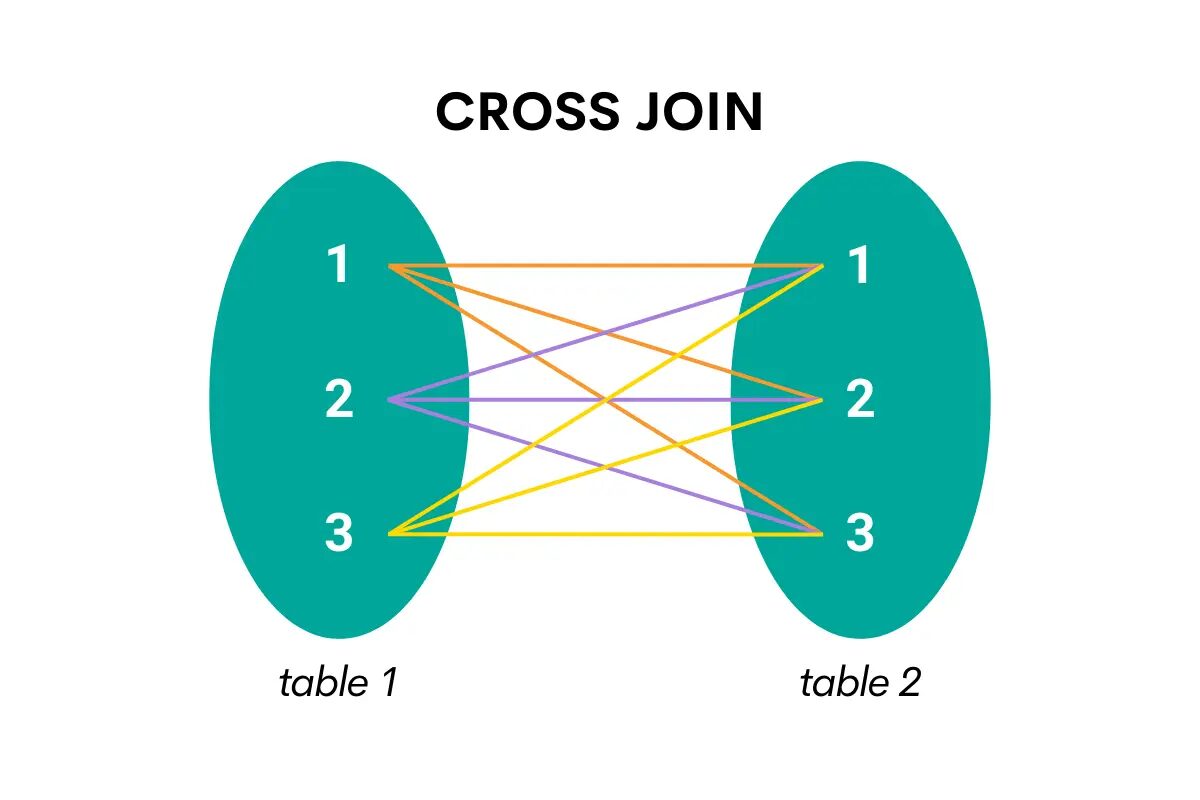
Kuva tekijältä
SQL:ssä ristiin liitettäessä avainsana on CROSS JOIN.
Suorittaaksesi liitoksen SQL:ssä sinun on määritettävä yhdistettävät taulukot, täsmäämiseen käytetyt sarakkeet ja liitoksen tyyppi, jonka haluamme suorittaa. Taulukoiden yhdistämisen perussyntaksi SQL:ssä on seuraava:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
Tämä esimerkki näyttää kuinka JOIN-toimintoa käytetään.
Viittaat ensimmäiseen (tai vasempaan) taulukkoon FROM-lauseessa. Sitten seuraat sitä JOIN-komennolla ja viittaat toiseen (tai oikeaan) taulukkoon.
Sitten tulee liittymisehto ON-lauseessa. Tässä voit määrittää, mitä sarakkeita käytät kahden taulukon yhdistämiseen. Yleensä se on jaettu sarake, joka on ensisijainen avain yhdessä taulukossa ja vierasavain toisessa taulukossa.
Huomautus: Ensisijainen avain on yksilöllinen tunniste taulukon jokaiselle tietueelle. Vierasavain muodostaa linkin kahden taulukon välille, eli se on sarake toisessa taulukossa, joka viittaa ensimmäiseen taulukkoon. Näytämme sinulle esimerkeissä, mitä se tarkoittaa.
Jos haluat käyttää LEFT JOIN, RIGHT JOIN tai FULL JOIN, käytä vain näitä avainsanoja JOIN sijaan – kaikki muu koodissa on täsmälleen sama!
Asiat ovat hieman erilaisia CROSS JOINin kanssa. Luonteeltaan on yhdistää kaikki rivien yhdistelmät molemmista taulukoista. Tästä syystä ON-lausetta ei tarvita, ja syntaksi näyttää tältä.
SELECT columns
FROM table1
CROSS JOIN table2;
Toisin sanoen viittaat vain yhteen taulukkoon kohdassa FROM ja toiseen CROSS JOINissa.
Vaihtoehtoisesti voit viitata molempiin FROM-taulukoihin ja erottaa ne pilkulla – tämä on lyhenne sanoista CROSS JOIN.
SELECT columns
FROM table1, table2;On myös yksi erityinen tapa yhdistää pöytiä – pöydän liittäminen itsensä kanssa. Tätä kutsutaan myös itseliittymiseksi pöytään.
Se ei ole aivan erillinen liitostyyppi, koska mitä tahansa aiemmin mainituista liitostyypeistä voidaan käyttää myös itseliittämiseen.
Itseliittymisen syntaksi on samanlainen kuin aiemmin näytin. Suurin ero on siinä, että samaan taulukkoon viitataan FROM:issa ja JOIN:issa.
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
Lisäksi sinun on annettava taulukolle kaksi aliasta erottaaksesi ne toisistaan. Sinä liität pöydän itsensä kanssa ja käsittelet sitä kahtena pöytänä.
Halusin vain mainita tämän täällä, mutta en mene sen enempää yksityiskohtiin. Jos olet kiinnostunut liittymään itse, katso tämä kuvitettu opas itse liittyminen SQL:ään.
On aika näyttää, kuinka kaikki mainitsemani toimii käytännössä. käytän SQL JOIN -haastattelukysymykset StrataScratchista esitelläksesi jokaisen erillisen liitostyypin SQL:ssä.
1. LIITY Esimerkki
Tämä Microsoftin kysymys haluaa sinun listaavan jokaisen projektin ja laskevan työntekijän projektin budjetin.
Kalliit Projektit
"Kun annetaan luettelo projekteista ja kuhunkin projektiin kartoitetuista työntekijöistä, laske kullekin työntekijälle osoitetun projektibudjetin mukaan . Tuloksen tulee sisältää projektin nimi ja projektin budjetti pyöristettynä lähimpään kokonaislukuun. Järjestä luettelosi ensin hankkeiden mukaan, joilla on suurin budjetti työntekijää kohti."
Päiväys
Kysymys antaa kaksi taulukkoa.
ms_projektit
| id: | int |
| otsikko: | Varchar |
| budjetti: | int |
ms_emp_projects
| emp_id: | int |
| projektin_tunnus: | int |
Nyt taulukon sarakkeen tunnus ms_projektit on taulukon ensisijainen avain. Sama sarake löytyy taulukosta ms_emp_projects, vaikkakin eri nimellä: projektin_tunnus. Tämä on taulukon viiteavain, joka viittaa ensimmäiseen taulukkoon.
Käytän näitä kahta saraketta taulukoiden yhdistämiseen ratkaisussani.
Koodi
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
Yhdistän kaksi taulukkoa JOIN-komennolla. Pöytä ms_projektit viitataan kirjoissa FROM, while ms_emp_projects viitataan JOIN jälkeen. Olen antanut molemmille taulukoille aliaksen, joten en voi käyttää taulukon pitkiä nimiä myöhemmin.
Nyt minun on määritettävä sarakkeet, joihin haluan liittää taulukot. Mainitsin jo, mitkä sarakkeet ovat ensisijainen avain yhdessä taulukossa ja vierasavain toisessa taulukossa, joten käytän niitä tässä.
Olen yhtä suuri kuin nämä kaksi saraketta, koska haluan saada kaikki tiedot, joissa projektin tunnus on sama. Käytin myös taulukoiden aliaksia jokaisen sarakkeen edessä.
Nyt kun minulla on pääsy molempien taulukoiden tietoihin, voin luetella sarakkeet SELECT-kohdassa. Ensimmäinen sarake on projektin nimi, ja toinen sarake lasketaan.
Tämä laskelma käyttää COUNT()-funktiota kunkin projektin työntekijöiden määrän laskemiseen. Sitten jaan kunkin projektin budjetin työntekijöiden lukumäärällä. Muunnan tuloksen myös desimaaliarvoiksi ja pyöristän sen nollaan desimaaliin.
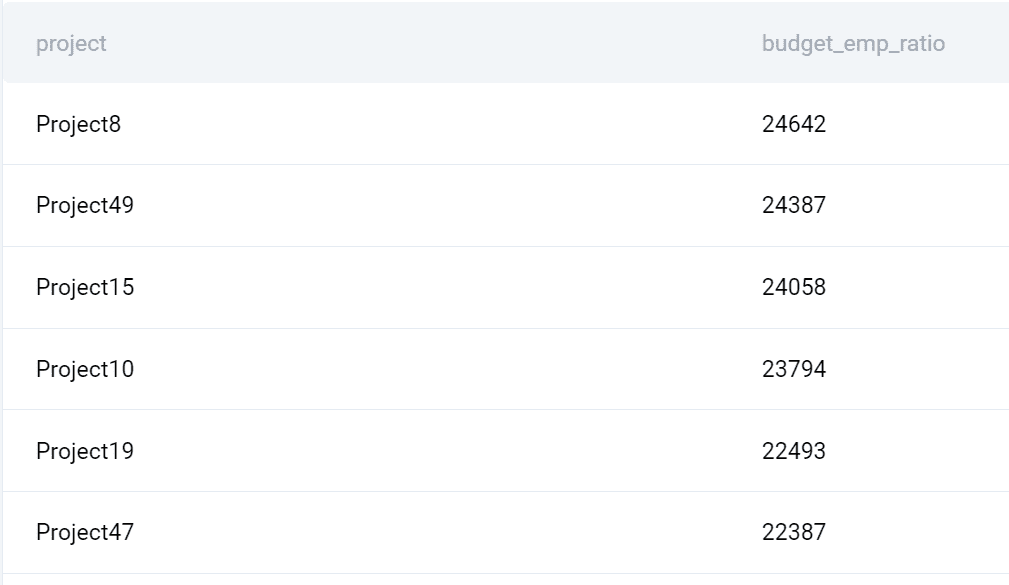
ulostulo
Tässä on mitä kysely palauttaa.
2. LEFT JOIN Esimerkki
Harjoitellaan tätä liittymistä Airbnb:n haastattelukysymys. Se haluaa sinun selvittävän kunkin kaupungin tilausten määrän, asiakkaiden lukumäärän ja tilausten kokonaiskustannukset.
Asiakkaiden tilaukset ja tiedot
"Etsi kunkin kaupungin tilausten määrä, asiakkaiden määrä ja tilausten kokonaiskustannukset. Sisällytä vain kaupungit, jotka ovat tehneet vähintään 5 tilausta, ja laske kaikki asiakkaat kussakin kaupungissa, vaikka he eivät olisi tehneet tilausta.
Tulosta jokainen laskelma yhdessä vastaavan kaupungin nimen kanssa."
Päiväys
Sinulle on annettu pöydät Asiakkaat, ja määräys.
asiakkaat
| id: | int |
| etunimi: | Varchar |
| sukunimi: | Varchar |
| kaupunki: | Varchar |
| osoite: | Varchar |
| puhelinnumero: | Varchar |
määräys
| id: | int |
| cust_id: | int |
| tilauspäivämäärä: | treffiaika |
| Tilauksen tiedot: | Varchar |
| total_order_cost: | int |
Jaetut sarakkeet ovat id taulukosta asiakkaat ja cust_id taulukosta määräys. Käytän näitä sarakkeita taulukoiden yhdistämiseen.
Koodi
Näin voit ratkaista tämän kysymyksen LEFT JOIN -toiminnolla.
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Viittaan taulukkoon asiakkaat in FROM (tämä on vasen taulukkomme) ja LEFT JOIN sen kanssa määräys asiakastunnussarakkeissa.
Nyt voin valita kaupungin, käyttää COUNT()-komentoa saadakseni tilausten ja asiakkaiden määrän kaupungeittain ja käyttää SUM()-komentoa tilausten kokonaiskustannusten laskemiseen kaupungeittain.
Saadaksesi kaikki nämä laskelmat kaupungeittain, ryhmittelen tuotoksen kaupunkien mukaan.
Kysymyksessä on yksi ylimääräinen pyyntö: "Sisällytä vain kaupungit, jotka ovat tehneet vähintään 5 tilausta..." Käytän HAVING-toimintoa näyttääkseni vain kaupungit, joilla on vähintään viisi tilausta.
Kysymys kuuluu, miksi käytin LEFT LIITY ja ei LIITY? Vihje on kysymyksessä: "...ja laske kaikki asiakkaat kussakin kaupungissa, vaikka he eivät olisi tehneet tilausta." On mahdollista, että kaikki asiakkaat eivät ole tehneet tilauksia. Tämä tarkoittaa, että haluan näyttää kaikki asiakkaat pöydästä asiakkaat, joka sopii täydellisesti LEFT JOINin määritelmään.
Jos olisin käyttänyt JOINia, tulos olisi ollut väärä, koska olisin jäänyt kaipaamaan asiakkaita, jotka eivät tehneet tilauksia.
Huomautus: Liitosten monimutkaisuus SQL:ssä ei heijastu niiden syntaksissa vaan niiden semantiikassa! Kuten näit, jokainen liitos kirjoitetaan samalla tavalla, vain avainsana muuttuu. Jokainen liitos toimii kuitenkin eri tavalla ja voi siksi tuottaa erilaisia tuloksia datasta riippuen. Tästä syystä on tärkeää, että ymmärrät täysin kunkin liitoksen toiminnan ja valitset sen, joka palauttaa juuri sen, mitä haluat!
ulostulo
Katsotaanpa nyt tulosta.

3. RIGHT JOIN Esimerkki
RIGHT JOIN on peilikuva LEFT JOINista. Siksi olisin voinut helposti ratkaista edellisen ongelman käyttämällä RIGHT JOINia. Anna minun näyttää sinulle, kuinka se tehdään.
Päiväys
Pöydät pysyvät samoina; Käytän vain erilaista liitosta.
Koodi
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city
HAVING COUNT(o.id) >=5;
Tässä on mikä on muuttunut. Koska käytän RIGHT JOIN -toimintoa, vaihdoin taulukoiden järjestystä. Nyt pöytä määräys siitä tulee vasen ja pöytä asiakkaat oikea. Liitosehto pysyy samana. Vaihdoin juuri sarakkeiden järjestystä vastaamaan taulukoiden järjestystä, mutta se ei ole välttämätöntä.
Vaihtamalla pöytien järjestystä ja käyttämällä RIGHT JOIN -toimintoa, tulostan jälleen kaikki asiakkaat, vaikka he eivät olisi tehneet tilauksia.
Loput kyselystä ovat samat kuin edellisessä esimerkissä. Sama pätee ulostuloon.
Huomautus: Käytännössä OIKEA LIITTYMINEN käytetään suhteellisen harvoin. LEFT JOIN vaikuttaa luonnollisemmalta SQL-käyttäjille, joten he käyttävät sitä paljon useammin. Kaikki, mitä voidaan tehdä RIGHT JOIN -toiminnolla, voidaan tehdä myös LEFT JOIN -toiminnolla. Tästä syystä ei ole olemassa erityistä tilannetta, jossa RIGHT JOIN voitaisiin suosia.
ulostulo
4. FULL JOIN Esimerkki
Salesforcen ja Teslan kysymys haluaa sinun laskevan nettoeron vuonna 2020 lanseerattujen tuoteyritysten ja edellisenä vuonna lanseerattujen tuoteyritysten lukumäärän välillä.
Uudet tuotteet
”Saat taulukon tuotelanseerauksista yrityskohtaisesti vuosittain. Kirjoita kysely laskeaksesi nettoero vuonna 2020 lanseerattujen tuoteyritysten ja edellisenä vuonna lanseerattujen tuoteyritysten lukumäärän välillä. Ilmoita yritysten nimet ja vuodelle 2020 julkaistujen nettotuotteiden nettoero edelliseen vuoteen verrattuna.”
Päiväys
Kysymys tarjoaa yhden taulukon, jossa on seuraavat sarakkeet.
auto_lanseeraukset
| vuosi: | int |
| Yrityksen nimi: | Varchar |
| tuotteen nimi: | Varchar |
Miten ihmeessä liityn pöytiin, kun pöytää on vain yksi? Hmm, katsotaanpa sekin!
Koodi
Tämä kysely on hieman monimutkaisempi, joten paljastan sen vähitellen.
SELECT company_name, product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
Ensimmäinen SELECT-lause löytää yrityksen ja tuotteen nimen vuonna 2020. Tämä kysely muutetaan myöhemmin alikyselyksi.
Kysymys haluaa sinun löytävän eron vuosien 2020 ja 2019 välillä. Joten kirjoitetaan sama kysely, mutta vuodelle 2019.
SELECT company_name, product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
Teen nyt näistä kyselyistä alikyselyitä ja liitän niihin käyttämällä FULL OUTTER JOIN -toimintoa.
SELECT *
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
Alikyselyitä voidaan käsitellä taulukoina ja siksi ne voidaan yhdistää. Annoin ensimmäiselle alikyselylle aliaksen ja laitoin sen FROM-lauseeseen. Sitten yhdistän sen yrityksen nimisarakkeen toiseen alikyselyyn käyttämällä FULL OUTER JOINia.
Käyttämällä tämäntyyppistä SQL-liitosta saan kaikki vuoden 2020 yritykset ja tuotteet yhdistettynä kaikkiin yrityksiin ja tuotteisiin vuonna 2019.
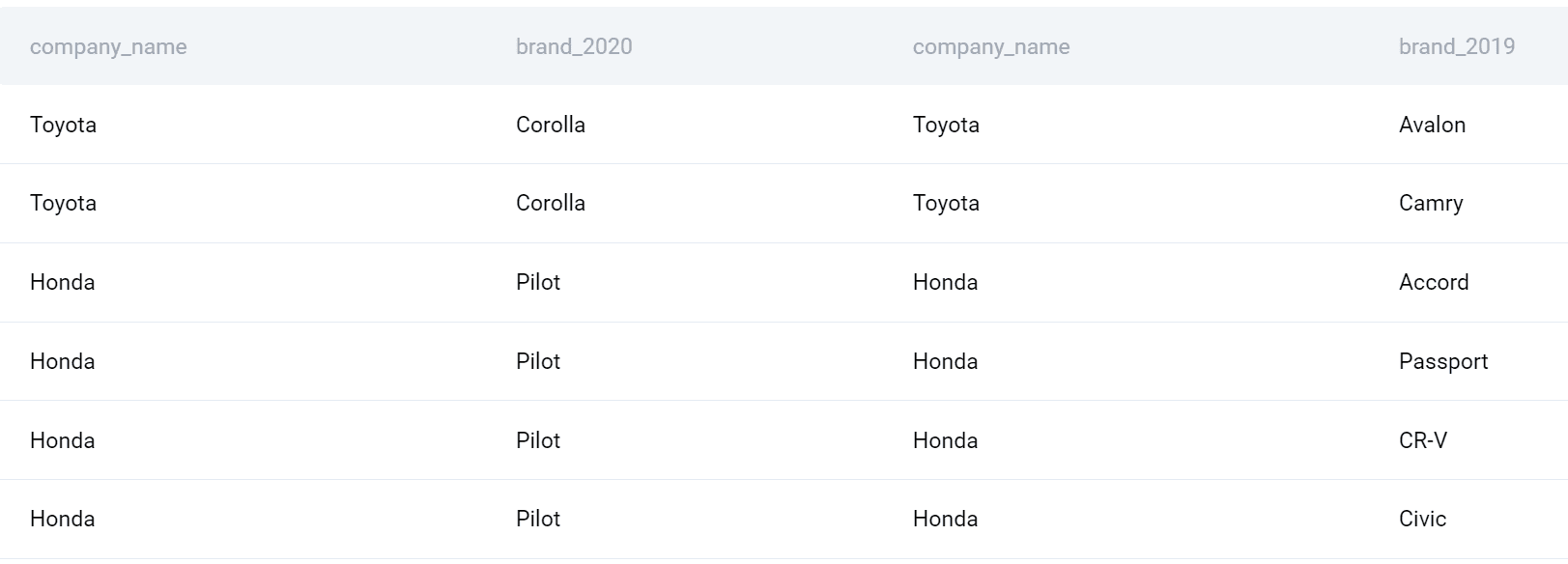
Nyt voin viimeistellä kyselyni. Valitaan yrityksen nimi. Lisäksi käytän COUNT()-funktiota löytääkseni jokaisena vuonna lanseerattujen tuotteiden määrän ja sitten vähennän sen saadakseni eron. Lopuksi ryhmittelen tulosteet yritysten mukaan ja lajittelen ne myös yritysten mukaan aakkosjärjestykseen.
Tässä on koko kysely.
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name
GROUP BY a.company_name
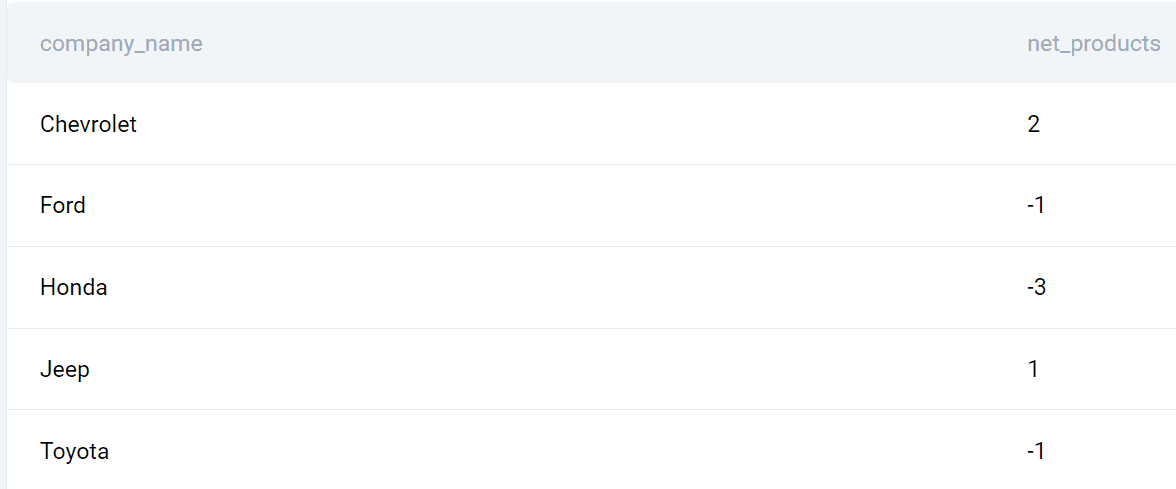
ORDER BY company_name;ulostulo
Tässä on luettelo yrityksistä ja lanseerattujen tuotteiden eroista vuosien 2020 ja 2019 välillä.
5. RISTILIITOS Esimerkki
Tämä Deloitten kysymys on loistava näyttämään, kuinka CROSS JOIN toimii.
Enintään kaksi numeroa
"Kun annetaan yksi numerosarake, harkitse kaikkia mahdollisia kahden luvun permutaatioita olettaen, että lukuparit (x,y) ja (y,x) ovat kaksi eri permutaatiota. Etsi sitten jokaiselle permutaatiolle kahdesta luvusta suurin.
Tulosta kolme saraketta: ensimmäinen numero, toinen numero ja suurin kahdesta."
Kysymys haluaa sinun löytävän kaikki mahdolliset kahden luvun permutaatiot olettaen, että lukuparit (x,y) ja (y,x) ovat kaksi erilaista permutaatiota. Sitten meidän on löydettävä lukujen enimmäismäärä jokaiselle permutaatiolle.
Päiväys
Kysymys antaa meille yhden taulukon yhdellä sarakkeella.
deloitte_numbers
| määrä: | int |
Koodi
Tämä koodi on esimerkki CROSS JOINista, mutta myös itseliittymisestä.
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
Viittaan taulukkoon kohdassa FROM ja annan sille yhden aliaksen. Sitten I CROSS JOIN sen itsensä kanssa viittaamalla siihen CROSS JOIN jälkeen ja antamalla taulukolle toisen aliaksen.
Nyt on mahdollista käyttää yhtä pöytää, koska niitä on kaksi. Valitsen sarakkeen numeron jokaisesta taulukosta. Sitten käytän CASE-käskyä asettaakseni ehdon, joka näyttää kahden luvun enimmäismäärän.
Miksi CROSS JOINia käytetään täällä? Muista, että se on eräänlainen SQL-liitos, joka näyttää kaikkien rivien kaikki yhdistelmät kaikista taulukoista. Juuri sitä kysymys kysyy!
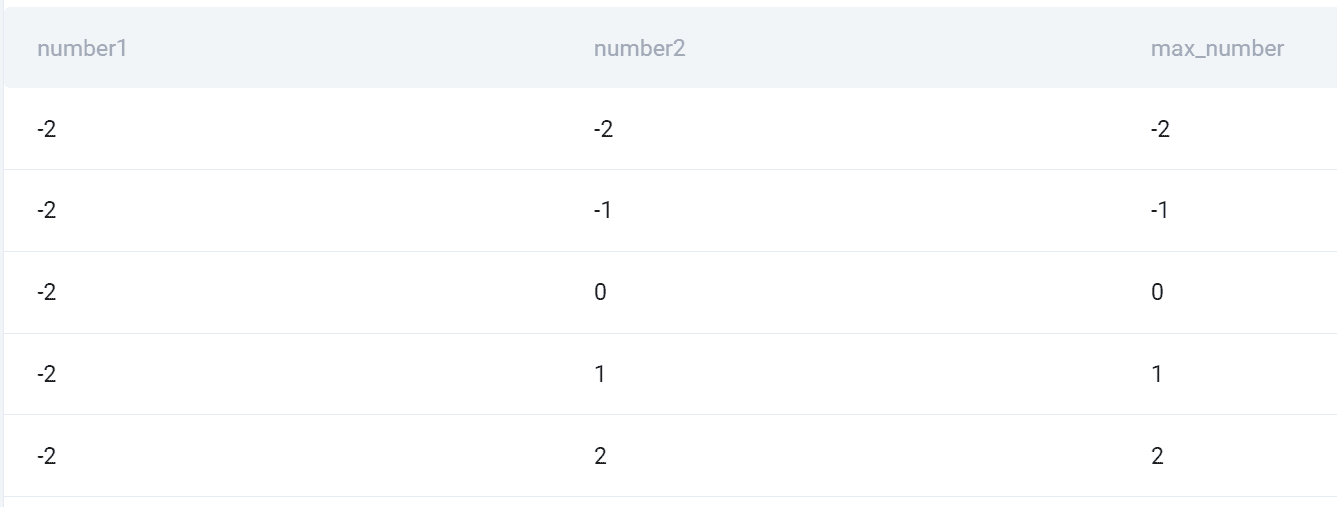
ulostulo
Tässä on tilannekuva kaikista yhdistelmistä ja näiden kahden suuremmasta määrästä.
Nyt kun osaat käyttää SQL-liitoksia, kysymys on, kuinka hyödyntää tätä tietoa datatieteessä.
SQL-liitoksilla on ratkaiseva rooli datatieteen tehtävissä, kuten tietojen tutkimisessa, tietojen puhdistamisessa ja ominaisuuksien suunnittelussa.
Tässä on muutamia esimerkkejä siitä, kuinka SQL-liitoksia voidaan hyödyntää:
- Tietojen yhdistäminen: Taulukoiden yhdistäminen mahdollistaa eri tietolähteiden yhdistämisen, jolloin voit analysoida useiden tietojoukkojen suhteita ja korrelaatioita. Esimerkiksi asiakastaulukon yhdistäminen tapahtumataulukon kanssa voi antaa käsityksen asiakkaiden käyttäytymisestä ja ostotottumuksista.
- Tietojen validointi: Liitoksia voidaan käyttää tietojen laadun ja eheyden vahvistamiseen. Vertailemalla eri taulukoiden tietoja voit tunnistaa epäjohdonmukaisuudet, puuttuvat arvot tai poikkeamat. Tämä auttaa sinua tietojen puhdistamisessa ja varmistaa, että analysointiin käytetyt tiedot ovat tarkkoja ja luotettavia.
- Ominaisuuksien suunnittelu: Liitokset voivat auttaa luomaan uusia ominaisuuksia koneoppimismalleihin. Yhdistämällä asiaankuuluvat taulukot voit poimia merkityksellisiä tietoja ja luoda ominaisuuksia, jotka tallentavat tärkeitä suhteita tiedoissa. Tämä voi parantaa malliesi ennustevoimaa.
- Aggregointi ja analyysi: Liitosten avulla voit suorittaa monimutkaisia aggregaatioita ja analyyseja useissa taulukoissa. Yhdistämällä tietoja eri lähteistä voit saada kattavan kuvan tiedoista ja saada arvokkaita oivalluksia. Esimerkiksi myyntitaulukon yhdistäminen tuotetaulukkoon voi auttaa sinua analysoimaan myynnin tehokkuutta tuoteluokan tai alueen mukaan.
Kuten jo mainitsin, liitosten monimutkaisuus ei näy niiden syntaksissa. Näit, että syntaksi on suhteellisen yksinkertainen.
Parhaat liitoskäytännöt heijastavat myös tätä, koska ne eivät koske itse koodausta vaan sitä, mitä liitos tekee ja miten se toimii.
Ota seuraavat parhaat käytännöt huomioon saadaksesi parhaan hyödyn SQL:n liitoksista.
- Ymmärrä tietosi: Tutustu tietojesi rakenteeseen ja suhteisiin. Tämä auttaa sinua valitsemaan sopivan liitostyypin ja valitsemaan oikeat sarakkeet vastaavuuksia varten.
- Käytä indeksejä: Jos taulukot ovat suuria tai niitä liitetään usein, harkitse indeksien lisäämistä liittämiseen käytettyihin sarakkeisiin. Indeksit voivat parantaa merkittävästi kyselyn suorituskykyä.
- Ole tietoinen suorituskyvystä: Suurten tai useiden pöytien yhdistäminen voi olla laskennallisesti kallista. Optimoi kyselysi suodattamalla tietoja, käyttämällä sopivia liitostyyppejä ja harkitsemalla väliaikaisten taulukoiden tai alikyselyjen käyttöä.
- Testaa ja validoi: Vahvista liitostulokset aina oikeellisuuden varmistamiseksi. Suorita mielenterveystarkastuksia ja varmista, että yhdistetyt tiedot vastaavat odotuksiasi ja liiketoimintalogiikkaasi.
SQL Joins on perustavanlaatuinen käsite, joka antaa sinulle datatieteilijänä mahdollisuuden yhdistää ja analysoida tietoja useista lähteistä. Ymmärtämällä eri tyyppisiä SQL-liitoksia, hallitsemalla niiden syntaksia ja hyödyntämällä niitä tehokkaasti datatieteilijät voivat saada arvokkaita oivalluksia, validoida tietojen laadun ja ohjata datalähtöistä päätöksentekoa.
Näytin sinulle, kuinka se tehdään viidessä esimerkissä. Nyt sinun on hyödynnettävä SQL:n voima ja liitokset datatieteen projekteissasi ja saavutettava parempia tuloksia.
Nate Rosidi on datatieteilijä ja tuotestrategiassa. Hän on myös analytiikkaa opettava dosentti ja perustaja StrataScratch, alusta, joka auttaa datatieteilijöitä valmistautumaan haastatteluihin huippuyritysten todellisilla haastattelukysymyksillä. Ota yhteyttä häneen Twitter: StrataScratch or LinkedIn.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html?utm_source=rss&utm_medium=rss&utm_campaign=sql-for-data-science-understanding-and-leveraging-joins
- :On
- :ei
- :missä
- $ YLÖS
- 1
- 11
- 12
- 13
- 2019
- 2020
- 7
- 8
- a
- Meistä
- pääsy
- Tietojen saatavuus
- tarkka
- Saavuttaa
- poikki
- lisää
- lisäaine
- Jälkeen
- uudelleen
- aggregaatti
- Kohdistaa
- Kaikki
- kohdennetaan
- sallia
- Salliminen
- mahdollistaa
- pitkin
- jo
- Myös
- aina
- määrä
- määrät
- an
- analyysi
- Analytics
- analysoida
- ja
- Toinen
- Kaikki
- mitään
- sopiva
- OVAT
- artikkeli
- AS
- At
- b
- perustua
- perustiedot
- BE
- koska
- tulee
- ollut
- ovat
- PARAS
- parhaat käytännöt
- Paremmin
- välillä
- sekä
- tuoda
- talousarvio
- liiketoiminta
- mutta
- by
- laskea
- laskettu
- nimeltään
- CAN
- kaapata
- tapaus
- Kategoria
- muuttunut
- Muutokset
- Tarkastukset
- Valita
- Kaupungit
- Kaupunki
- Siivous
- koodi
- Koodaus
- Sarake
- Pylväät
- KOM
- yhdistelmät
- yhdistää
- yhdistää
- yhdistely
- tulee
- Yhteinen
- Yritykset
- yritys
- verrattuna
- vertaamalla
- monimutkainen
- monimutkaisuus
- monimutkainen
- kattava
- käsite
- huolestunut
- ehto
- kytkeä
- Liitännät
- Harkita
- ottaen huomioon
- muuntaa
- vastaava
- Hinta
- luoda
- Luominen
- Ylittää
- ratkaiseva
- asiakas
- asiakkaan käyttäytyminen
- Asiakkaat
- tiedot
- tiedon laatu
- tietojenkäsittely
- tietojen tutkija
- data-driven
- tietokanta
- tietokannat
- aineistot
- Päätöksenteko
- päätökset
- määritelmä
- Riippuen
- suunniteltu
- yksityiskohta
- DID
- ero
- eri
- selvä
- erottaa
- do
- ei
- ei
- tekee
- tehty
- ajaa
- e
- kukin
- Aikaisemmin
- helpompaa
- helposti
- tehokkaasti
- muu
- Työntekijä
- työntekijää
- valtuutetaan
- mahdollistaa
- mahdollistaa
- loppu
- Tekniikka
- parantaa
- varmistaa
- varmistaa
- yhtäläinen
- laatii
- Jopa
- kaikki
- täsmälleen
- esimerkki
- Esimerkit
- odotukset
- kallis
- Selittää
- tutkimus
- lisää
- uute
- Ominaisuus
- Ominaisuudet
- harvat
- ala
- täyte
- suodatus
- viimeistellä
- Vihdoin
- Löytää
- löydöt
- Etunimi
- viisi
- kellua
- Keskittää
- seurata
- jälkeen
- seuraa
- varten
- ulkomainen
- löytyi
- perustaja
- usein
- alkaen
- etuosa
- koko
- täysin
- toiminto
- perus-
- edelleen
- Saada
- tuottaa
- saada
- Antaa
- tietty
- antaa
- Antaminen
- Goes
- menee
- vähitellen
- suuri
- Ryhmä
- ohjaavat
- valjaat
- Olla
- ottaa
- he
- raskaasti
- auttaa
- auttaa
- auttaa
- tätä
- korkeampi
- suurin
- häntä
- Miten
- Miten
- Kuitenkin
- HTTPS
- i
- Minä
- ID
- tunniste
- tunnistaa
- if
- kuva
- tärkeä
- parantaa
- in
- Muilla
- sisältää
- indeksit
- tiedot
- tietoa
- oivalluksia
- sen sijaan
- instrumentaalinen
- eheys
- kiinnostunut
- Haastatella
- haastattelu kysymykset
- Haastattelut
- tulee
- IT
- SEN
- itse
- yhdistää
- liittyi
- tuloaan
- Liitosten
- jpg
- vain
- KDnuggets
- avain
- avainsanat
- Tietää
- tuntemus
- Kieli
- suuri
- myöhemmin
- käynnistettiin
- käynnistää
- oppiminen
- vähiten
- vasemmalle
- vipuvaikutuksen
- pitää
- LINK
- Lista
- vähän
- logiikka
- Pitkät
- katso
- ulkonäkö
- kone
- koneoppiminen
- tehty
- tärkein
- tehdä
- Tekeminen
- toimitusjohtaja
- käsittelylaite
- masterointi
- ottelu
- Hyväksytty
- matching
- maksimi
- me
- mielekäs
- välineet
- mainitsi
- mennä
- sulautuvan
- ehkä
- peili
- Peilikuva
- hukata
- puuttuva
- mallit
- lisää
- eniten
- paljon
- moninkertainen
- my
- nimi
- nimet
- Luonnollinen
- luonto
- välttämätön
- Tarve
- tarvitaan
- netto
- Uusi
- Uudet ominaisuudet
- Nro
- nyt
- numero
- numerot
- of
- usein
- on
- ONE
- vain
- päinvastainen
- Optimoida
- or
- tilata
- määräys
- Muut
- meidän
- ulos
- ulostulo
- paria
- kuviot
- varten
- suorittaa
- suorituskyky
- suoritettu
- suorittaa
- Paikka
- paikat
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- Pelaa
- Ole hyvä
- mahdollinen
- teho
- voimakas
- harjoitusta.
- käytännöt
- Suositut
- Valmistella
- edellinen
- ensisijainen
- Ongelma
- Tuotteet
- Tuotteemme
- Opettaja
- Ohjelmointi
- projekti
- hankkeet
- toimittaa
- tarjoaa
- osto-
- laatu
- kyselyt
- kysymys
- kysymykset
- harvoin
- todellinen
- ennätys
- viittaukset
- viittaaminen
- heijastaa
- heijastunut
- alue
- liittyvä
- Ihmissuhteet
- suhteellisesti
- julkaistu
- merkityksellinen
- luotettava
- muistaa
- pyyntö
- REST
- johtua
- tulokset
- palata
- Tuotto
- paljastaa
- oikein
- Rooli
- kierros
- s
- myynti
- Salesforce
- sama
- näki
- tiede
- Tiedemies
- tutkijat
- Toinen
- nähdä
- näyttää
- SELF
- erillinen
- setti
- useat
- yhteinen
- lyhenne
- shouldnt
- näyttää
- näyteikkuna
- osoittivat
- näyttää
- Näytä
- merkittävästi
- samankaltainen
- yksinkertaisesti
- single
- tilanne
- Kuva
- So
- ratkaisu
- SOLVE
- Lähteet
- erityinen
- SQL
- Lausunto
- pysyä
- suora
- Strategia
- rakenne
- jäsennelty
- niin
- kytketty
- syntaksi
- T1
- taulukko
- Neuvottelut
- tehtävät
- Opetus
- tilapäinen
- testi
- että
- -
- heidän
- Niitä
- sitten
- Siellä.
- siksi
- Nämä
- ne
- tätä
- kolmella
- aika
- Otsikko
- että
- yhdessä
- Toolbox
- työkalut
- ylin
- Yhteensä
- kauppa
- käsitelty
- käsittelemällä
- Sorvatut
- kaksi
- tyyppi
- tyypit
- ymmärtää
- ymmärtäminen
- unique
- avata
- us
- käyttää
- käytetty
- Käyttäjät
- käyttötarkoituksiin
- käyttämällä
- yleensä
- käyttää
- VAHVISTA
- validointi
- arvokas
- arvot
- eri
- valtava
- todentaa
- Näytä
- visualisointi
- vs
- haluta
- halusi
- haluavat
- haluaa
- Tapa..
- we
- Mitä
- kun
- joka
- vaikka
- koko
- miksi
- tulee
- with
- sisällä
- sanoja
- toimii
- kirjoittaa
- kirjallinen
- Väärä
- X
- vuosi
- te
- Sinun
- itse
- zephyrnet
- nolla-