Nykymaailmassa useimmat yritykset luottavat big datan ja analytiikan tehoon kasvun, strategisten investointien ja asiakkaiden sitoutumisen edistämisessä. Big data on perusvakio kohdistetussa mainoksessa, personoidussa markkinoinnissa, tuotesuosituksissa, oivallusten luomisessa, hintaoptimoinnissa, mielipideanalyysissä, ennakoivassa analytiikan sisällössä ja monessa muussa.
Tiedot kerätään usein useista lähteistä, muunnetaan, tallennetaan ja käsitellään datajärvissä on-prem- tai pilvipalveluissa. Vaikka tietojen alkuunotto on suhteellisen triviaalia ja se voidaan saavuttaa talon sisällä kehitetyillä mukautetuilla komentosarjoilla tai perinteisillä ETL-työkaluilla (Extract Transform Load), ongelmasta tulee nopeasti kohtuuttoman monimutkainen ja kallis ratkaista, koska yritysten on:
- Hallitse tietojen koko elinkaarta – taloudenhoito- ja vaatimustenmukaisuustarkoituksiin
- Optimoi tallennustila – vähentää siihen liittyviä kustannuksia
- Yksinkertaista arkkitehtuuria – käyttämällä laskentainfrastruktuuria uudelleen
- Käsittele tietoja asteittain – tehokkaan tilanhallinnan avulla
- Käytä samoja käytäntöjä erä- ja suoratoistotiedoissa – ilman päällekkäistä työtä
- Siirrä On-premin ja Cloudin välillä – vähimmällä vaivalla
Se on missä Apache Gobblin, avoimen lähdekoodin tiedonhallinta- ja integrointijärjestelmä tulee sisään. Apache Gobblin tarjoaa vertaansa vailla olevia ominaisuuksia, joita voidaan käyttää joko kokonaan tai osittain yrityksen tarpeiden mukaan.
Tässä osiossa perehdymme Apache Gobblinin erilaisiin ominaisuuksiin, jotka auttavat vastaamaan aiemmin hahmoteltuihin haasteisiin.
Tietojen koko elinkaaren hallinta
Apache Gobblin tarjoaa joukon ominaisuuksia dataputkien rakentamiseen, jotka tukevat kaikkia datajoukkojen tietojen elinkaaritoimintoja.
- Kerää dataa – useista lähteistä nieluihin tietokannoista, Rest API:ista, FTP/SFTP-palvelimista, tiedostoista, CRM:istä, kuten Salesforce ja Dynamics, ja paljon muuta.
- Replikoi tiedot – useiden datajärvien välillä erikoisominaisuuksilla Hadoop Distributed File System -tiedostojärjestelmää varten Distcp-NG:n kautta.
- Tyhjennä tiedot – käyttämällä säilytyskäytäntöjä, kuten Aikaperusteinen, Uusin K, Versioitu tai käytäntöjen yhdistelmä.
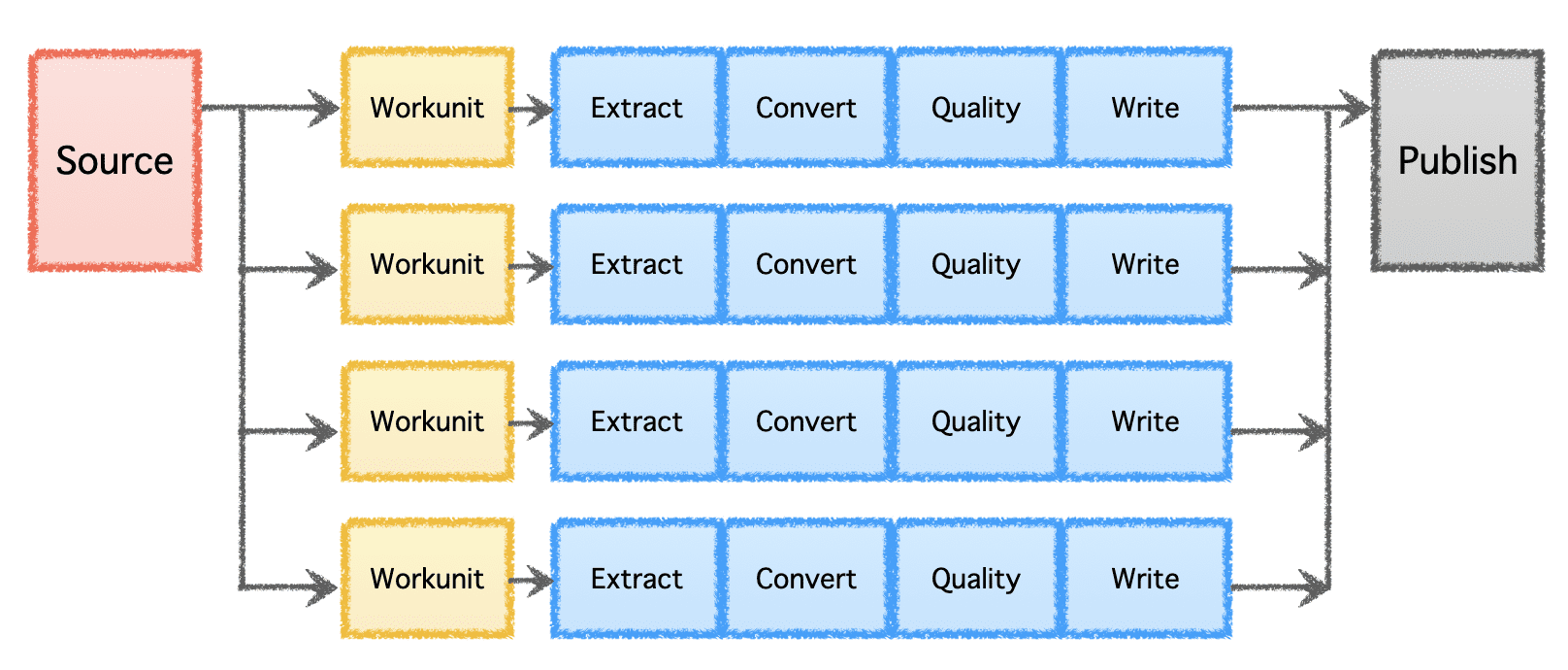
Gobblinin looginen putkisto koostuu 'Lähteestä', joka määrittää työn jakautumisen ja luo 'työskentelyä'. Nämä 'työt' noudetaan sitten suoritettaviksi 'tehtävinä', jotka sisältävät tietojen poimimisen, muuntamisen, laaduntarkistuksen ja tietojen kirjoittamisen määränpäähän. Viimeinen vaihe, 'Data Publish', vahvistaa liukuhihnan onnistuneen suorituksen ja sitoo tulostiedot atomisesti, jos kohde tukee sitä.
Kuva tekijältä
Optimoi tallennustila
Apache Gobblin voi auttaa vähentämään datalle tarvittavan tallennustilan määrää käsittelemällä tietoja sen jälkeen, kun ne on syötetty tai replikoitu pakkaamisen tai muotomuunnoksen avulla.
- Tiivistys – tietojen jälkikäsittely, joka poistetaan tietueiden kaikkien kenttien tai avainkenttien perusteella, leikataan tiedot siten, että säilytetään vain yksi tietue, jossa on viimeisin aikaleima samalla avaimella.
- Avro ORC:ksi – erikoistunut muotojen muunnosmekanismi, jolla muunnetaan suosittu rivipohjainen Avro-muoto hyperoptimoituun sarakepohjaiseen ORC-muotoon.
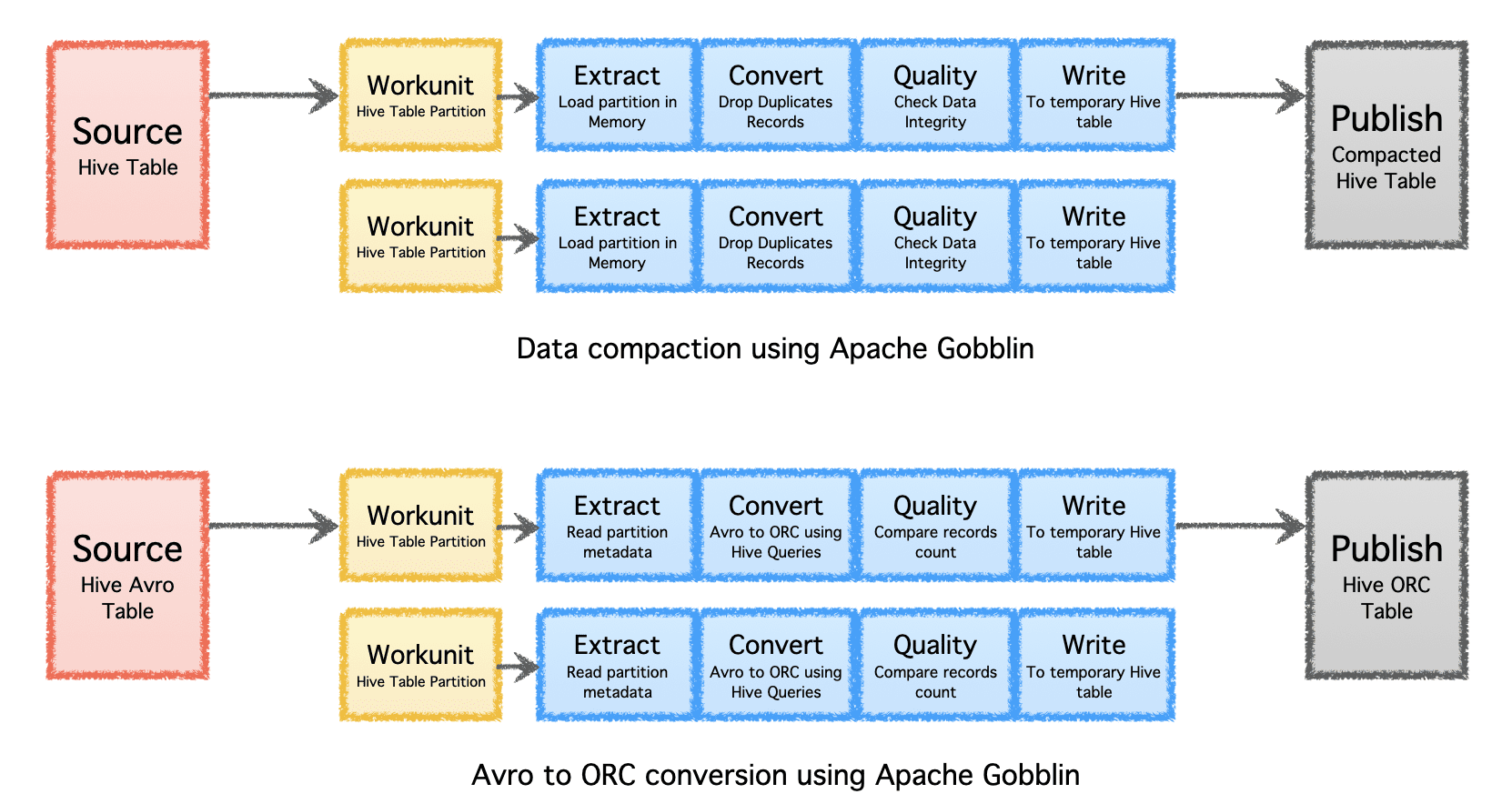
Kuva tekijältä
Yksinkertaista arkkitehtuuria
Riippuen yrityksen vaiheesta (käynnistä yritykseen), mittakaavavaatimuksista ja niiden arkkitehtuurista, yritykset haluavat perustaa tai kehittää tietoinfrastruktuuriaan. Apache Gobblin on erittäin joustava ja tukee useita suoritusmalleja.
- Itsenäinen tila – toimii erillisenä prosessina paljaalla metallilaatikolla, eli yhdellä isännällä yksinkertaisiin käyttötapauksiin ja vähän vaativiin tilanteisiin.
- MapReduce-tila – Suoritetaan MapReduce-työnä Hadoop-infrastruktuurissa suuria datatapauksia varten, jotta voidaan käsitellä petatavun mittakaavassa olevia tietojoukkoja.
- Klusteritila: Itsenäinen – toimii Apache Helixin ja Apache Zookeeperin tukemana klusterina paljasmetallikoneilla tai isännillä suuren mittakaavan käsittelyä varten Hadoop MR -kehyksestä riippumatta.
- Klusteritila: Lanka – ajaa klusterina natiivilangalla ilman Hadoop MR -kehystä.
- Cluster Mode: AWS – toimii klusterina Amazonin julkisessa pilvipalvelussa, esim. AWS AWS:ssä isännöidyille infrastruktuureille.
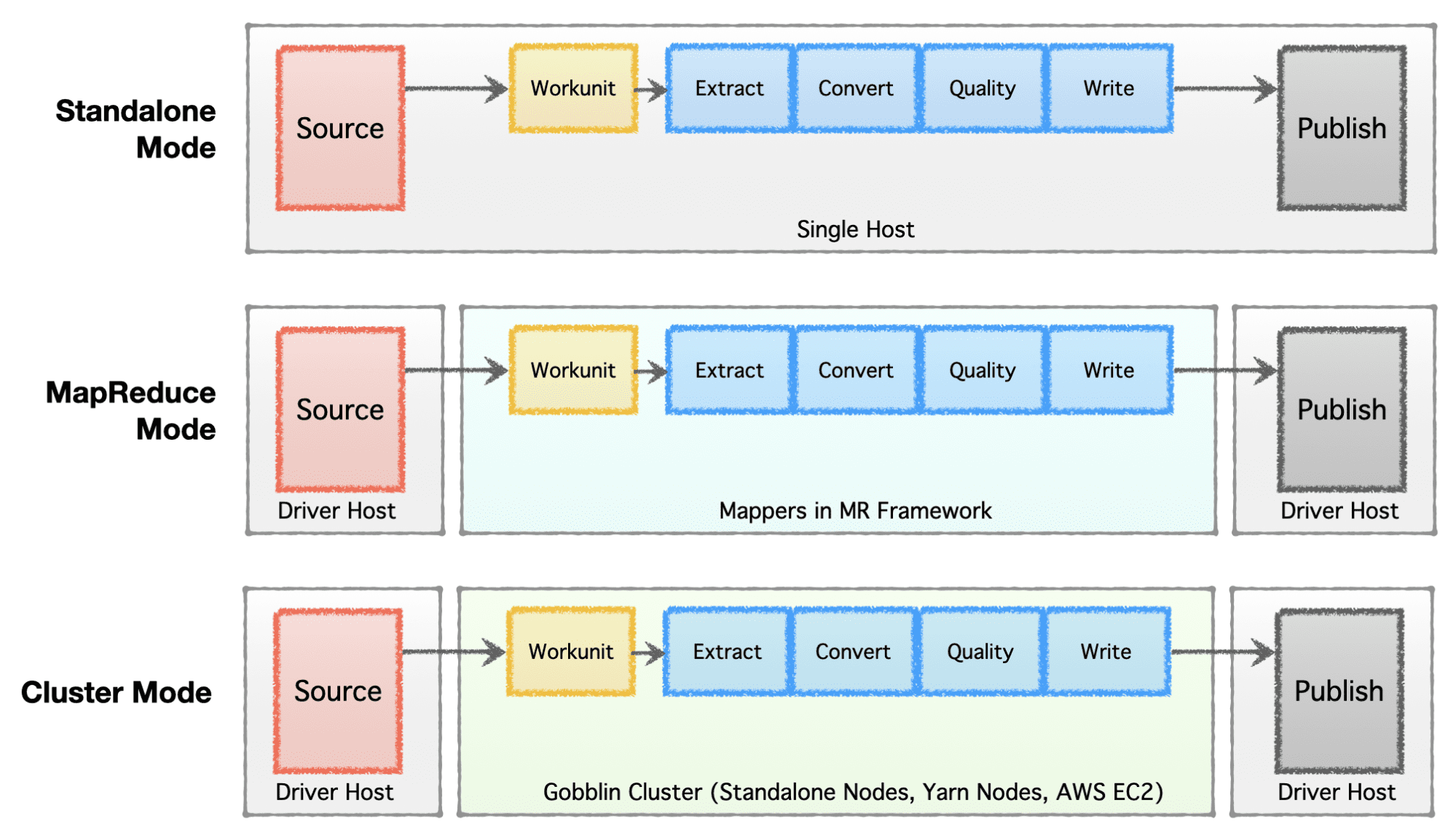
Kuva tekijältä
Käsittele tietoja asteittain
Merkittävässä mittakaavassa, jossa on useita dataputkia ja suuri määrä, tiedot on käsiteltävä erissä ja ajan mittaan. Siksi se vaatii tarkistuspisteen, jotta dataputket voivat jatkaa siitä, mihin ne viime kerralla jäivät, ja jatkaa siitä eteenpäin. Apache Gobblin tukee alhaisia ja korkeita vesileimoja ja tukee vankkaa tilanhallinnan semantiikkaa State Storen kautta HDFS:ssä, AWS S3:ssa, MySQL:ssä ja avoimemmin.
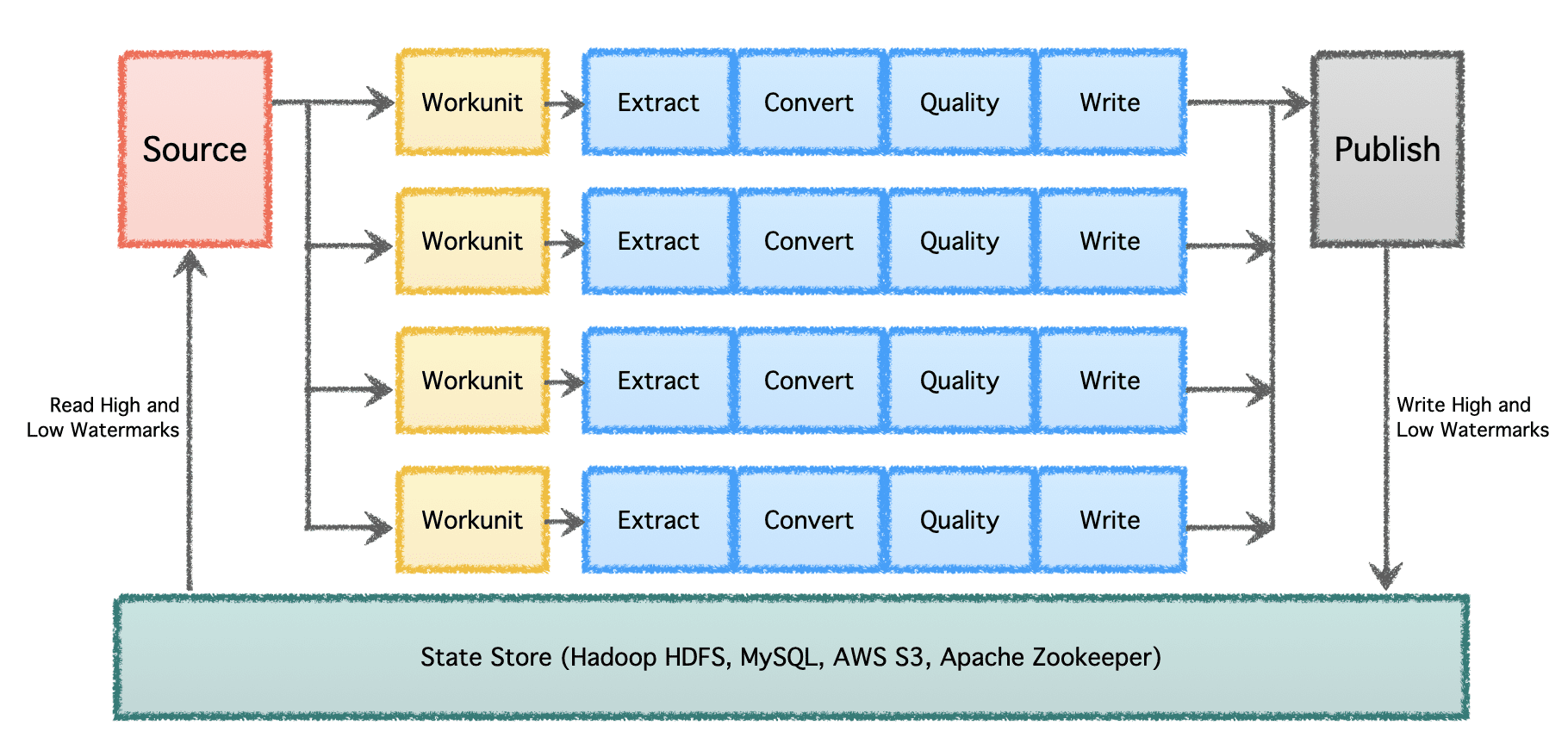
Kuva tekijältä
Samat käytännöt erä- ja suoratoistotiedoissa
Useimmat dataliukuhihnat on nykyään kirjoitettava kahdesti, kerran erädataa varten ja uudelleen lähes riviä tai suoratoistodataa varten. Se kaksinkertaistaa vaivan ja aiheuttaa epäjohdonmukaisuuksia erityyppisiin putkiin sovellettuihin käytäntöihin ja algoritmeihin. Apache Gobblin ratkaisee tämän antamalla käyttäjien luoda liukuhihnan kerran ja suorittaa sen sekä erä- että suoratoistotiedoissa, jos sitä käytetään Gobblin Cluster -tilassa, Gobblin AWS -tilassa tai Gobblin on lankatilassa.
Siirrä On-premin ja Cloudin välillä
Monipuolisten tilojensa ansiosta, jotka voivat toimia on-prem-tilassa yhdessä laatikossa, solmuklusterissa tai pilvessä – Apache Gobblin voidaan ottaa käyttöön ja käyttää sekä paikan päällä että pilvessä. Tämän vuoksi käyttäjät voivat kirjoittaa dataputkistonsa kerran ja siirtää ne yhdessä Gobblin-asennusten kanssa helposti on-prem- ja pilvipalveluiden välillä erityistarpeiden perusteella.
Erittäin joustavan arkkitehtuurinsa, tehokkaiden ominaisuuksiensa ja äärimmäisen laajamittaisten tietomäärien ansiosta, joita se voi tukea ja käsitellä, Apache Gobblinia käytetään tuotantoinfrastruktuurissa. suuria teknologiayrityksiä ja se on välttämätön nykypäivän big data-infrastruktuurin käyttöönotossa.
Lisätietoja Apache Gobblinista ja sen käytöstä löytyy osoitteesta https://gobblin.apache.org
Abhishek Tiwari on Senior Manager LinkedInissä ja johtaa yrityksen Big Data Pipelines -organisaatiota. Hän on myös Apache Software Foundationin Apache Gobblinin varapuheenjohtaja ja British Computer Societyn jäsen.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- saavutettu
- käsitellään
- Mainos
- Jälkeen
- Tuki
- algoritmit
- Kaikki
- Salliminen
- määrä
- analyysi
- Analytics
- ja
- Apache
- API
- sovellettu
- arkkitehtuuri
- liittyvä
- kirjoittaja
- AWS
- Tukena
- perustua
- tulee
- välillä
- Iso
- Big Data
- Laatikko
- Brittiläinen
- liiketoiminta
- yritykset
- kyvyt
- tapauksissa
- haasteet
- tarkkailun
- pilvi
- Cluster
- yhdistelmä
- Yritykset
- yritys
- monimutkainen
- noudattaminen
- tietokone
- tietojenkäsittely
- vakio
- rakentaa
- jatkaa
- Muuntaminen
- muuntaa
- luo
- asiakassuhde
- asiakas
- Asiakkaan sitoutuminen
- tiedot
- tietoinfrastruktuuri
- tiedonhallinta
- tietokannat
- aineistot
- Riippuen
- käyttöön
- käyttöönotto
- käyttöönotot
- määränpää
- yksityiskohdat
- määrittää
- kehitetty
- eri
- jaettu
- jakelu
- dynamiikka
- helposti
- vaivaa
- sitoumus
- yritys
- Eetteri (ETH)
- kehittää
- teloitus
- kallis
- uute
- uuttaminen
- äärimmäinen
- Ominaisuudet
- kaveri
- Fields
- filee
- lopullinen
- joustava
- muoto
- löytyi
- perusta
- Puitteet
- alkaen
- polttoaine
- koko
- sukupolvi
- Kasvu
- Hadoop
- kahva
- auttaa
- Korkea
- erittäin
- isäntä
- isännöi
- Miten
- Miten
- HTTPS
- in
- sisältää
- itsenäinen
- Infrastruktuuri
- infrastruktuuri
- ensimmäinen
- oivalluksia
- integraatio
- Esittelee
- Investoinnit
- IT
- Job
- KDnuggets
- Pitää
- avain
- suuri
- Sukunimi
- uusin
- johtava
- kuormitus
- Matala
- Koneet
- johto
- johtaja
- Marketing
- mekanismi
- metalli-
- vaeltaa
- tila
- mallit
- Moderni
- tilat
- lisää
- eniten
- moninkertainen
- Pakkohankinta
- MySQL
- syntyperäinen
- tarvitaan
- tarpeet
- Uusimmat
- solmut
- tarjoamalla
- ONE
- avoimen lähdekoodin
- Operations
- organisaatio
- hahmoteltu
- osat
- yksilöllinen
- poimitaan
- putki
- Platon
- Platonin tietotieto
- PlatonData
- politiikkaa
- Suosittu
- teho
- voimakas
- Ennakoiva Analytics
- mieluummin
- puheenjohtaja
- aiemmin
- hinta
- Ongelma
- prosessi
- Tuotteet
- tuotanto
- tarjoaa
- julkinen
- Julkinen pilvi
- julkaista
- laatu
- nopeasti
- alainen
- suosituksia
- ennätys
- asiakirjat
- vähentää
- suhteellisesti
- replikointi
- vaatimukset
- ne
- REST
- jatkaa
- säilyttäminen
- luja
- ajaa
- Salesforce
- sama
- Asteikko
- skaalaus
- skriptejä
- Osa
- semantiikka
- vanhempi
- näkemys
- setti
- merkittävä
- Yksinkertainen
- single
- tilanteita
- So
- yhteiskunta
- Tuotteemme
- SOLVE
- Ratkaisee
- lähde
- Lähteet
- erikoistunut
- erityinen
- Vaihe
- itsenäinen
- käynnistyksen
- Osavaltio
- Vaihe
- Levytila
- verkkokaupasta
- tallennettu
- Strateginen
- virta
- streaming
- onnistunut
- sviitti
- tuki
- Tukee
- järjestelmä
- kohdennettu
- tehtävät
- Elektroniikka
- -
- heidän
- siksi
- Kautta
- aika
- aikaleima
- että
- tänään
- työkalut
- perinteinen
- Muuttaa
- transformoitu
- tyypit
- taustalla oleva
- vertaansa vailla oleva
- käyttää
- Käyttäjät
- eri
- monipuolinen
- kautta
- Varapresidentti
- tilavuus
- volyymit
- joka
- vaikka
- tulee
- ilman
- Referenssit
- maailman-
- kirjoittaa
- kirjoittaminen
- kirjallinen
- zephyrnet