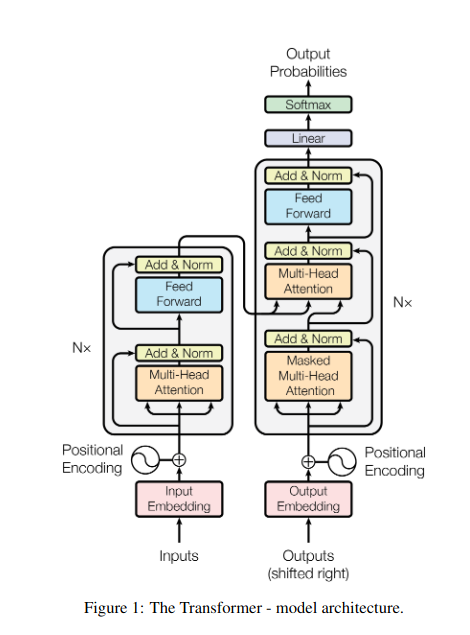
esittely
Kuvittele seisovasi hämärässä kirjastossa ja kamppailemassa monimutkaisen asiakirjan tulkinnassa samalla kun jongleeraat kymmenien muiden tekstien kanssa. Tämä oli Transformers-maailmaa ennen kuin "Attention is All You Need" -lehti paljasti vallankumouksellisen valokeilansa - huomiomekanismi.
Sisällysluettelo
RNN:iden rajoitukset
Perinteiset peräkkäiset mallit, kuten Toistuvat hermoverkot (RNN), käsitteli kieltä sana sanalta, mikä johtaa useisiin rajoituksiin:
- Lyhyen kantaman riippuvuus: RNN:t kamppailivat ymmärtääkseen kaukaisten sanojen välisiä yhteyksiä, ja he tulkitsivat usein väärin lauseiden, kuten "mies, joka vieraili eläintarhassa eilen", merkityksen, kun aihe ja verbi ovat kaukana toisistaan.
- Rajoitettu rinnakkaisuus: Tietojen peräkkäinen käsittely on luonnostaan hidasta, mikä estää tehokkaan koulutuksen ja laskennallisten resurssien käytön erityisesti pitkissä sarjoissa.
- Keskity paikalliseen kontekstiin: RNN:t huomioivat ensisijaisesti välittömät naapurit, jotka saattavat puuttua ratkaisevan tiedon muista lauseen osista.
Nämä rajoitukset estivät Transformersin kykyä suorittaa monimutkaisia tehtäviä, kuten konekäännös ja luonnollisen kielen ymmärtäminen. Sitten tuli huomiomekanismi, vallankumouksellinen valokeila, joka valaisee sanojen välisiä piilotettuja yhteyksiä ja muuttaa käsityksemme kielenkäsittelystä. Mutta mitä huomio tarkalleen ratkaisi ja miten se muutti Transformersin peliä?
Keskitytään kolmeen avainalueeseen:
Pitkäaikainen riippuvuus
- Ongelma: Perinteiset mallit kompastuivat usein lauseisiin, kuten "kukkulalla asunut nainen näki eilen illalla tähdenlennon". Heillä oli vaikeuksia yhdistää "nainen" ja "tähdet" etäisyyden vuoksi, mikä johti väärintulkintoihin.
- Huomiomekanismi: Kuvittele, että malli loistaa kirkkaana säteen poikki lauseen yhdistäen "naisen" suoraan "tähdeen" ja ymmärtäen lauseen kokonaisuutena. Tämä kyky vangita suhteita etäisyydestä riippumatta on ratkaisevan tärkeä tehtävissä, kuten konekäännös ja yhteenveto.
Lue myös: Yleiskatsaus pitkäkestoiseen lyhytaikaiseen muistiin (LSTM)
Rinnakkaisprosessointiteho
- Ongelma: Perinteiset mallit käsittelivät tietoja peräkkäin, kuten kirjan lukeminen sivulta sivulta. Tämä oli hidasta ja tehotonta varsinkin pitkien tekstien kohdalla.
- Huomiomekanismi: Kuvittele, että useat kohdevalot skannaavat kirjastoa samanaikaisesti ja analysoivat tekstin eri osia rinnakkain. Tämä nopeuttaa mallin työtä dramaattisesti, jolloin se pystyy käsittelemään valtavia tietomääriä tehokkaasti. Tämä rinnakkainen prosessointiteho on välttämätön monimutkaisten mallien koulutuksessa ja reaaliaikaisten ennusteiden tekemisessä.
Globaali kontekstitietoisuus
- Ongelma: Perinteiset mallit keskittyivät usein yksittäisiin sanoihin, puuttuen lauseen laajemmasta kontekstista. Tämä johti väärinkäsityksiin sellaisissa tapauksissa kuin sarkasmi tai kaksinkertainen merkitys.
- Huomiomekanismi: Kuvittele valokeilan pyyhkäisevän koko kirjaston halki, joka ottaa vastaan jokaisen kirjan ja ymmärtää, kuinka ne liittyvät toisiinsa. Tämä globaali kontekstitietoisuus mahdollistaa sen, että malli ottaa huomioon tekstin kokonaisuuden tulkitessaan jokaista sanaa, mikä johtaa rikkaampaan ja vivahteikkaampaan ymmärrykseen.
Monipuolisten sanojen yksiselitteisyys
- Ongelma: Sanat, kuten "pankki" tai "omena", voivat olla substantiivija, verbejä tai jopa yrityksiä, mikä luo epäselvyyttä, jota perinteiset mallit kamppailivat ratkaista.
- Huomiomekanismi: Kuvittele mallin valaisevan valokeilassa kaikkia sanan "pankki" esiintymiä lauseessa ja analysoivan sitten ympäröivää kontekstia ja suhteita muihin sanoihin. Huomiomekanismi voi päätellä tarkoitetun merkityksen ottamalla huomioon kieliopin rakenteen, lähellä olevat substantiivit ja jopa menneet lauseet. Tämä monisanaisten sanojen yksiselitteisyys on ratkaisevan tärkeä tehtävissä, kuten konekäännöksissä, tekstin yhteenvedossa ja dialogijärjestelmissä.
Nämä neljä näkökohtaa – pitkän kantaman riippuvuus, rinnakkainen prosessointiteho, globaali kontekstitietoisuus ja yksiselitteisyys – esittelevät huomiomekanismien muuntavaa voimaa. Ne ovat nostaneet Transformersin luonnollisen kielen käsittelyn eturintamaan, mikä mahdollistaa monimutkaisten tehtävien suorittamisen huomattavan tarkasti ja tehokkaasti.
Kun NLP ja erityisesti LLM:t kehittyvät edelleen, huomiomekanismit ovat epäilemättä entistä kriittisempi rooli. Ne ovat silta lineaarisen sanasarjan ja ihmiskielen rikkaan kuvakudoksen välillä ja viime kädessä avain näiden kielellisten ihmeiden todellisen potentiaalin avaamiseen. Tässä artikkelissa tarkastellaan erityyppisiä huomiomekanismeja ja niiden toimintoja.
1. Itsehuomio: Transformerin opastähti
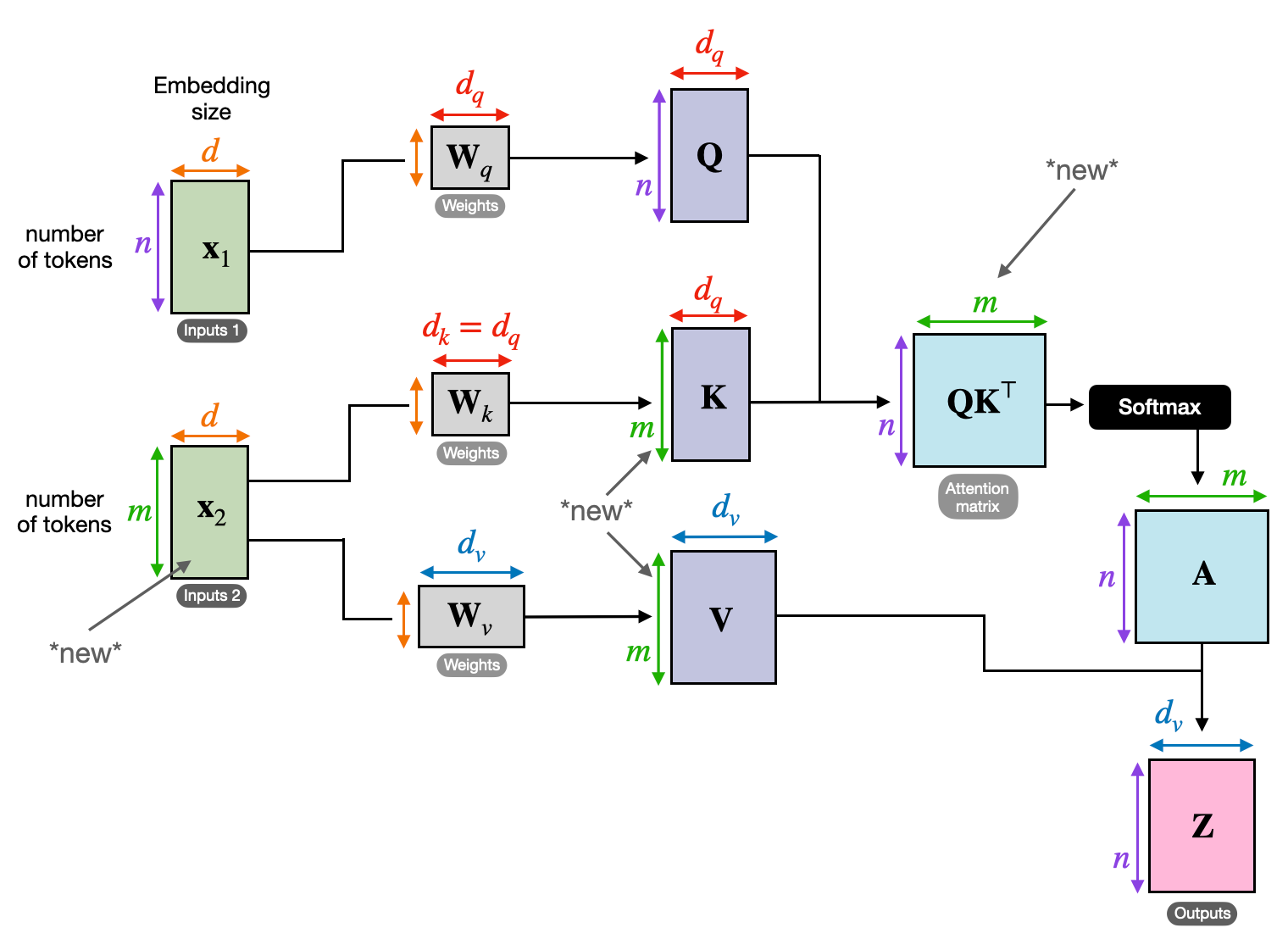
Kuvittele, että jongleeraat useita teoksia ja sinun on viitattava kuhunkin tiettyyn kohtaan, kun kirjoitat yhteenvetoa. Self-attention tai Scaled Dot-Product -tarkkailu toimii kuin älykäs avustaja, joka auttaa malleja tekemään saman peräkkäisten tietojen, kuten lauseiden tai aikasarjojen, kanssa. Sen avulla jokainen sekvenssin elementti voi ottaa huomioon kaikki muut elementit ja vangita tehokkaasti pitkän kantaman riippuvuuksia ja monimutkaisia suhteita.
Tässä on tarkempi katsaus sen tärkeimpiin teknisiin näkökohtiin:
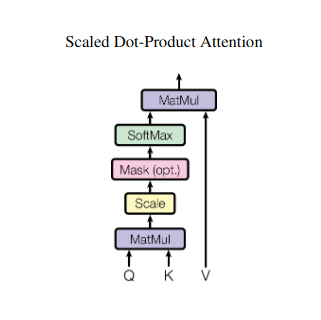
Vektoriesitys
Jokainen elementti (sana, tietopiste) muunnetaan korkeadimensionaaliseksi vektoriksi, joka koodaa sen tietosisällön. Tämä vektoriavaruus toimii perustana elementtien väliselle vuorovaikutukselle.
QKV-muunnos
Kolme avainmatriisia määritellään:
- Kysely (Q): Edustaa "kysymystä", jonka kukin elementti esittää muille. Q kaappaa nykyisen elementin tietotarpeet ja ohjaa sitä etsimään oleellista tietoa sekvenssistä.
- Avain (K): Pitää "avaimen" kunkin elementin tietoihin. K koodaa kunkin elementin sisällön olemuksen, jolloin muut elementit voivat tunnistaa mahdollisen merkityksen omien tarpeidensa perusteella.
- Arvo (V): Tallentaa todellisen sisällön, jonka kukin elementti haluaa jakaa. V sisältää yksityiskohtaiset tiedot, joita muut elementit voivat käyttää ja hyödyntää huomiopisteidensä perusteella.
Huomiopisteiden laskeminen
Kunkin elementtiparin välinen yhteensopivuus mitataan niiden vastaavien Q- ja K-vektorien välisellä pistetulolla. Korkeammat pisteet osoittavat, että elementtien välillä on vahvempi mahdollinen relevanssi.
Skaalatut huomiopainot
Suhteellisen tärkeyden varmistamiseksi nämä yhteensopivuuspisteet normalisoidaan softmax-funktiolla. Tämä johtaa huomiopainoihin, jotka vaihtelevat välillä 0–1, jotka edustavat kunkin elementin painotettua merkitystä nykyisen elementin kontekstissa.
Painotettu kontekstin yhdistäminen
V-matriisiin sovelletaan huomiopainoja, jotka pohjimmiltaan korostavat kunkin elementin tärkeitä tietoja sen relevanssin perusteella. Tämä painotettu summa luo nykyiselle elementille kontekstuaalisen esityksen, joka sisältää kaikista muista sekvenssin elementeistä poimitut oivallukset.
Parannettu elementtien esitys
Rikastetun esityksen ansiosta elementillä on nyt syvempi ymmärrys omasta sisällöstään sekä suhteistaan sarjan muihin elementteihin. Tämä muunnettu esitys muodostaa perustan myöhempään käsittelyyn mallin sisällä.
Tämä monivaiheinen prosessi mahdollistaa itsensä huomioimisen:
- Kaappaa pitkän kantaman riippuvuudet: Etäisten elementtien väliset suhteet tulevat helposti ilmeisiksi, vaikka ne erottuvatkin useista välissä olevista elementeistä.
- Malli monimutkaisia vuorovaikutuksia: Hienovaraiset riippuvuudet ja korrelaatiot sekvenssin sisällä tuodaan esiin, mikä johtaa rikkaampaan ymmärrykseen tietorakenteesta ja dynamiikasta.
- Kontekstualisoi jokainen elementti: Malli ei analysoi kutakin elementtiä erikseen vaan laajemman sekvenssin puitteissa, mikä johtaa tarkempiin ja vivahteikampiin ennusteisiin tai esityksiin.
Itsensä huomioiminen on mullistanut tavan, jolla mallit käsittelevät peräkkäistä dataa ja avaavat uusia mahdollisuuksia monilla eri aloilla, kuten konekäännös, luonnollisen kielen luominen, aikasarjaennusteet ja muut. Sen kyky paljastaa sekvenssien piilotetut suhteet tarjoaa tehokkaan työkalun oivallusten paljastamiseen ja erinomaisen suorituskyvyn saavuttamiseen monissa eri tehtävissä.
2. Multi-Head Attention: Näkeminen eri linssien läpi
Itsensä huomioiminen tarjoaa kokonaisvaltaisen näkemyksen, mutta joskus on ratkaisevan tärkeää keskittyä tietojen tiettyihin näkökohtiin. Siinä usean pään huomio tulee esiin. Kuvittele, että sinulla on useita avustajia, joista jokaisella on eri objektiivi:
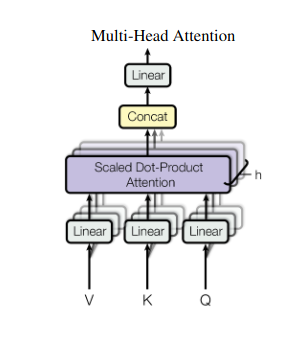
- Useita "päitä" luodaan, ja jokainen huolehtii syötesekvenssistä omien Q-, K- ja V-matriisiensa kautta.
- Jokainen pää oppii keskittymään datan eri puoliin, kuten pitkän kantaman riippuvuuksiin, syntaktisiin suhteisiin tai paikallisiin sanavuorovaikutuksiin.
- Kunkin pään lähdöt yhdistetään sitten ja heijastetaan lopulliseksi esitykseksi, joka vangitsee syötteen monitahoisuuden.
Tämä antaa mallille mahdollisuuden tarkastella samanaikaisesti erilaisia näkökulmia, mikä johtaa rikkaampaan ja vivahteikkaampaan tiedon ymmärtämiseen.
3. Cross Attention: Siltojen rakentaminen sekvenssien välille
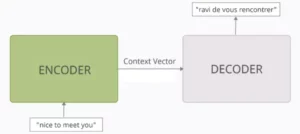
Kyky ymmärtää yhteyksiä eri tiedon välillä on ratkaisevan tärkeää monissa NLP-tehtävissä. Kuvittele kirjoittavasi kirja-arvostelun – et vain tiivistäisi tekstiä sanasta sanaan, vaan vedäisit oivalluksia ja yhteyksiä lukujen välillä. Tulla sisään ristiin huomiota, tehokas mekanismi, joka rakentaa siltoja sekvenssien välille ja antaa malleille mahdollisuuden hyödyntää tietoa kahdesta erillisestä lähteestä.
- Enkooderi-dekooderiarkkitehtuureissa, kuten Transformers, kooderi käsittelee syöttösekvenssin (kirjan) ja luo piilotetun esityksen.
- - dekooderi käyttää ristikkäistä huomiota kiinnittääkseen huomiota kooderin piilotettuun esitykseen jokaisessa vaiheessa luodessaan tulossekvenssiä (tarkistusta).
- Dekooderin Q-matriisi on vuorovaikutuksessa kooderin K- ja V-matriisien kanssa, jolloin se voi keskittyä kirjan olennaisiin osiin kirjoittaessaan arvostelun jokaista virkettä.
Tämä mekanismi on korvaamaton tehtävissä, kuten konekäännöksissä, yhteenvetojen tekemisessä ja kysymyksiin vastaamisessa, joissa syöttö- ja lähtösekvenssien välisten suhteiden ymmärtäminen on välttämätöntä.
4. Syy-huomio: Ajan virran säilyttäminen
Kuvittele ennustavasi lauseen seuraavan sanan katsomatta eteenpäin. Perinteiset huomiomekanismit kamppailevat tehtävien kanssa, jotka edellyttävät tiedon ajallisen järjestyksen säilyttämistä, kuten tekstin luominen ja aikasarjaennusteet. Ne "kurkistavat eteenpäin" järjestyksessä, mikä johtaa epätarkkoihin ennusteisiin. Syy-huomio korjaa tämän rajoituksen varmistamalla, että ennusteet riippuvat yksinomaan aiemmin käsitellyistä tiedoista.
Näin se toimii
- Peittomekanismi: Tarkkailupainoihin sovelletaan erityistä maskia, joka estää tehokkaasti mallin pääsyn sarjan tuleviin elementteihin. Esimerkiksi ennustaessaan toista sanaa sanassa "nainen, joka…", malli voi ottaa huomioon vain "the" eikä "kuka" tai myöhempiä sanoja.
- Autoregressiivinen käsittely: Tieto virtaa lineaarisesti, jolloin kunkin elementin esitys on rakennettu yksinomaan sitä edeltäneistä elementeistä. Malli käsittelee sekvenssin sana sanalta luoden ennusteita siihen asti muodostetun kontekstin perusteella.
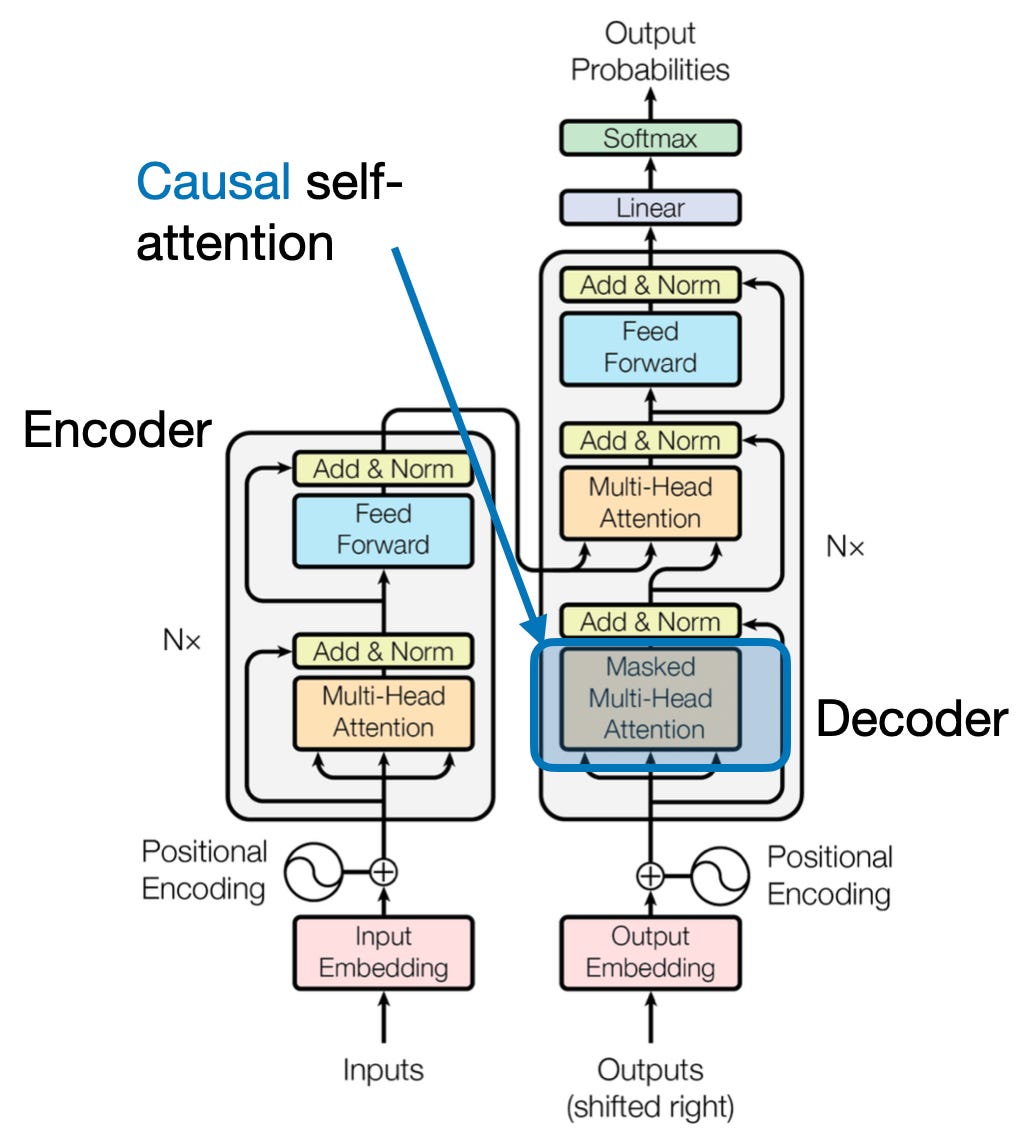
Syy-huomio on ratkaisevan tärkeää tehtävissä, kuten tekstin luomisessa ja aikasarjaennusteissa, joissa tietojen ajallisen järjestyksen ylläpitäminen on välttämätöntä tarkkojen ennusteiden kannalta.
5. Globaali vs. paikallinen huomio: tasapainon saavuttaminen
Huomiomekanismit kohtaavat keskeisen kompromissin: pitkän kantaman riippuvuuksien vangitseminen verrattuna tehokkaan laskennan ylläpitämiseen. Tämä ilmenee kahdessa ensisijaisessa lähestymistavassa: globaali huomio ja paikallista huomiota. Kuvittele lukevasi koko kirjan verrattuna tiettyyn lukuun keskittymiseen. Globaali huomio käsittelee koko sarjan kerralla, kun taas paikallinen huomio keskittyy pienempään ikkunaan:
- Globaali huomio kaappaa pitkän kantaman riippuvuudet ja kokonaiskontekstin, mutta voi olla laskennallisesti kallista pitkille sarjoille.
- Paikallinen huomio on tehokkaampi, mutta saattaa jäädä paitsi etäsuhteista.
Valinta globaalin ja paikallisen huomion välillä riippuu useista tekijöistä:
- Tehtävän vaatimukset: Konekäännösten kaltaiset tehtävät edellyttävät etäisten suhteiden vangitsemista, mikä suosii maailmanlaajuista huomiota, kun taas mielipideanalyysi saattaa edistää paikallisen huomion keskittymistä.
- Sekvenssin pituus: Pidemmät sekvenssit tekevät maailmanlaajuisesta huomiosta laskennallisesti kalliita, mikä edellyttää paikallisia tai hybridilähestymistapoja.
- Mallin kapasiteetti: Resurssirajoitukset saattavat vaatia paikallista huomiota jopa globaalia kontekstia vaativissa tehtävissä.
Optimaalisen tasapainon saavuttamiseksi mallit voivat käyttää:
- Dynaaminen vaihto: käytä globaalia huomiota avainelementteihin ja paikallista huomiota muihin sopeutuen tärkeyden ja etäisyyden perusteella.
- Hybridilähestymistapoja: yhdistä molemmat mekanismit samaan kerrokseen hyödyntäen niiden vahvuuksia.
Lue myös: Hermoverkkotyyppien analysointi syväoppimisessa
Yhteenveto
Lopulta ihanteellinen lähestymistapa on globaalin ja paikallisen huomion välissä. Näiden kompromissien ymmärtäminen ja sopivien strategioiden ottaminen käyttöön mahdollistaa mallien tehokkaan hyödyntämisen asiaankuuluvan tiedon eri mittakaavassa, mikä johtaa rikkaampaan ja tarkempaan sekvenssin ymmärtämiseen.
Viitteet
- Raschka, S. (2023). "Omat huomion, monen pään huomion, ristiin huomioimisen ja syy-huomion ymmärtäminen ja koodaaminen LLM:issä."
- Vaswani, A., et ai. (2017). "Huomio on kaikki mitä tarvitset."
- Radford, A., et ai. (2019). "Kielimallit ovat valvomattomia moniajooppijoita."
liittyvä
Olen datan ystävä ja rakastan tiedon poimia ja ymmärtämistä. Haluan oppia ja kasvaa koneoppimisen ja datatieteen alalla.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- kyky
- pääsy
- tarkkuus
- tarkka
- Saavuttaa
- saavuttamisessa
- poikki
- säädökset
- todellinen
- osoitteet
- hyväksymällä
- eteenpäin
- AL
- Kaikki
- Salliminen
- mahdollistaa
- am
- epäselvyys
- määrät
- an
- analyysi
- analyysit
- analysointi
- ja
- puhelinvastaaja
- erilleen
- näennäinen
- sovellettu
- lähestymistapa
- lähestymistavat
- OVAT
- alueet
- artikkeli
- AS
- näkökohdat
- Avustaja
- avustajat
- At
- käydä
- hoitava
- huomio
- tietoisuus
- Balance
- perustua
- perusta
- BE
- Palkki
- tulevat
- ennen
- välillä
- Jälkeen
- esto
- kirja
- Kirjat
- sekä
- SILTA
- sillat
- Kirkas
- laajempaa
- toi
- Rakentaminen
- rakentaa
- rakennettu
- mutta
- by
- tuli
- CAN
- kaapata
- kaappaa
- Kaappaaminen
- tapauksissa
- muuttaa
- Luku
- luvuissa
- valinta
- lähempänä
- Koodaus
- yhdistää
- tulee
- Yritykset
- yhteensopivuus
- monimutkainen
- laskeminen
- laskennallinen
- kytkeä
- Kytkeminen
- Liitännät
- Harkita
- ottaen huomioon
- rajoitteet
- sisältää
- pitoisuus
- tausta
- jatkaa
- Ydin
- korrelaatiot
- luotu
- luo
- Luominen
- kriittinen
- ratkaiseva
- Nykyinen
- tiedot
- tietojenkäsittely
- Tulkita
- syvä
- syvempää
- määritelty
- Delves
- riippua
- riippuvuus
- riippuvuudet
- riippuvuus
- riippuu
- yksityiskohtainen
- Vuoropuhelu
- DID
- eri
- suoraan
- etäisyys
- kaukainen
- selvä
- useat
- do
- asiakirja
- DOT
- kaksinkertainen
- kymmeniä
- dramaattisesti
- piirtää
- kaksi
- dynamiikka
- E&T
- kukin
- tehokkaasti
- tehokkuus
- tehokas
- tehokkaasti
- elementti
- elementtejä
- valtuuttamisesta
- mahdollistaa
- mahdollistaa
- koodaus
- rikastettu
- varmistaa
- varmistamalla
- enter
- Koko
- kokonaisuus
- varustettu
- erityisesti
- ydin
- olennainen
- olennaisesti
- vakiintunut
- Jopa
- Joka
- kehittää
- täsmälleen
- kallis
- Käyttää hyväkseen
- uute
- Kasvot
- tekijät
- paljon
- suosivat
- ala
- Fields
- lopullinen
- virtaus
- virrat
- Keskittää
- keskityttiin
- keskittyy
- tarkennus
- varten
- eturintamassa
- lomakkeet
- perusta
- neljä
- Puitteet
- alkaen
- toiminto
- toiminnallisuudet
- tulevaisuutta
- peli
- synnyttää
- tuottaa
- sukupolvi
- Global
- globaalissa kontekstissa
- ymmärtää
- Kasvaa
- Oppaat
- ohjaava
- kahva
- Olla
- ottaa
- pää
- auttaa
- kätketty
- Korkea
- korkeampi
- korostus
- pitää
- kokonaisvaltainen
- Miten
- HTTPS
- ihmisen
- Hybridi
- i
- ihanteellinen
- tunnistaa
- if
- kuvitella
- Välitön
- merkitys
- tärkeä
- in
- epätarkka
- sisältävät
- osoittaa
- henkilökohtainen
- tehoton
- tiedot
- luonnostaan
- panos
- oivalluksia
- esimerkki
- Älykäs
- tarkoitettu
- vuorovaikutus
- vuorovaikutukset
- vuorovaikutuksessa
- välissä oleva
- tulee
- korvaamaton
- eristäminen
- IT
- SEN
- jpg
- vain
- avain
- Keskeiset alueet
- Kieli
- Sukunimi
- kerros
- johtava
- OPPIA
- Opi ja kasva
- oppijat
- oppiminen
- Led
- Linssi
- linssit
- Vaikutusvalta
- vipuvaikutuksen
- Kirjasto
- piilee
- valo
- pitää
- rajoitus
- rajoitukset
- paikallinen
- Pitkät
- kauemmin
- katso
- rakkaus
- kone
- koneoppiminen
- konekäännös
- ylläpitäminen
- tehdä
- Tekeminen
- mies
- monet
- naamio
- Matriisi
- max-width
- merkitys
- merkityksiä
- mitattu
- mekanismi
- mekanismit
- Muisti
- ehkä
- menettää
- puuttuva
- malli
- mallit
- lisää
- tehokkaampi
- moniulotteinen
- moninkertainen
- Luonnollinen
- Luonnollinen kieli
- Luonnollisen kielen luominen
- Luonnollinen kielen käsittely
- Luonnollisen kielen ymmärtäminen
- luonto
- Tarve
- tarvitsevat
- tarpeet
- naapurit
- verkot
- hermo-
- hermoverkkoihin
- Uusi
- seuraava
- yön
- NLP
- substantiiveja
- nyt
- vivahteikas
- of
- usein
- on
- kerran
- vain
- optimaalinen
- or
- tilata
- Muut
- Muuta
- meidän
- ulos
- ulostulo
- lähdöt
- yleinen
- yleiskatsaus
- oma
- sivulla
- pari
- Paperi
- Parallel
- osat
- kanavat
- Ohi
- kuviot
- suorittaa
- suorituskyky
- näkökulmia
- kappaletta
- Platon
- Platonin tietotieto
- PlatonData
- Pelaa
- Kohta
- aiheuttaa
- hallussaan
- mahdollisuuksia
- voimakas
- mahdollinen
- mahdollisesti
- teho
- voimakas
- ennustamiseen
- Ennusteet
- säilöntä
- estää
- aiemmin
- pääasiallisesti
- ensisijainen
- prosessi
- jalostettu
- Prosessit
- käsittely
- Jalostusteho
- Tuotteet
- ennustetaan
- ajettu
- tarjoaa
- kysymys
- alue
- alainen
- pikemminkin
- Lue
- helposti
- Lukeminen
- reaaliaikainen
- viite
- riippumatta
- Ihmissuhteet
- suhteellinen
- Merkitys
- merkityksellinen
- huomattava
- edustus
- edustavat
- edustaa
- edellyttää
- ratkaisee
- resurssi
- Esittelymateriaalit
- ne
- tulokset
- arviot
- vallankumouksellinen
- mullistanut
- Rikas
- Rooli
- s
- sama
- sarkasmi
- näki
- asteikot
- skannaus
- tiede
- pisteet
- tulokset
- Haku
- Toinen
- koska
- tuomita
- näkemys
- Järjestys
- Sarjat
- palvelee
- useat
- Jaa:
- loistava
- ammunta
- Lyhyt
- näyteikkuna
- samanaikaisesti
- hidas
- pienempiä
- Yksin
- SOLVE
- joskus
- Lähteet
- Tila
- erityinen
- erityisesti
- spektri
- nopeudet
- Valokeila
- seisova
- Tähti
- Vaihe
- varastot
- strategiat
- vahvuudet
- vahvempi
- rakenne
- taistelu
- Struggling
- aihe
- myöhempi
- niin
- sopiva
- summa
- yhteenveto
- YHTEENVETO
- esimies
- ympäröivä
- järjestelmät
- puuttua
- ottaen
- kuvakudos
- tehtävät
- Tekninen
- termi
- teksti
- tekstin luominen
- että
- -
- maailma
- heidän
- Niitä
- sitten
- Nämä
- ne
- tätä
- kolmella
- Kautta
- aika
- Aikasarja
- että
- työkalu
- perinteinen
- koulutus
- transformatiivinen
- transformoitu
- muuntaja
- muuntajat
- muuttamassa
- Kääntäminen
- totta
- kaksi
- tyypit
- Lopulta
- ymmärtää
- ymmärtäminen
- epäilemättä
- lukituksen
- paljastaa
- paljastettiin
- käyttää
- käyttötarkoituksiin
- käyttämällä
- eri
- valtava
- Vastaan
- Näytä
- vieraili
- elintärkeä
- vs
- haluta
- haluaa
- oli
- HYVIN
- Mitä
- kun
- vaikka
- KUKA
- koko
- leveä
- Laaja valikoima
- tulee
- ikkuna
- with
- sisällä
- ilman
- nainen
- sana
- sanoja
- Referenssit
- maailman-
- kirjoittaminen
- eilen
- te
- zephyrnet
- ZOO