Sponsoroitu Sisältö
ChatGPT ja vastaavat työkalut, jotka perustuvat suuriin kielimalleihin (LLM) ovat hämmästyttäviä. Mutta ne eivät ole yleistyökaluja.
Se on aivan kuin muiden työkalujen valitseminen rakentamiseen ja luomiseen. Sinun on valittava oikea työhön. Et yrittäisi kiristää pulttia vasaralla tai kääntää hampurilaispihvi vispilällä. Prosessi olisi hankala ja johtaisi sotkuiseen epäonnistumiseen.
Kielimallit, kuten LLM:t, ovat vain osa laajempaa koneoppimisen työkalupakkia, joka kattaa sekä generatiivisen tekoälyn että ennustavan tekoälyn. Oikeantyyppisen koneoppimismallin valitseminen on ratkaisevan tärkeää, jotta se vastaa tehtäväsi vaatimuksia.
Pohditaanpa syvemmälle, miksi LLM:t sopivat paremmin tekstin luomiseen tai lahjaideoiden pohtimiseen kuin yrityksesi kriittisimpien ennakoivan mallintamisen tehtävien hoitamiseen. "Perinteisillä" koneoppimismalleilla, jotka edelsivät LLM-yrityksiä ja ovat toistuvasti osoittaneet arvonsa liiketoiminnassa, on edelleen tärkeä rooli. Tutkimme myös uraauurtavaa lähestymistapaa näiden työkalujen yhteiskäyttöön – tätä jännittävää kehitystä me Pecanissa kutsumme Ennakoiva GenAI.
LLM:t on suunniteltu sanoille, ei numeroille
Koneoppimisessa käytetään erilaisia matemaattisia menetelmiä niin sanotun "koulutusdatan" analysointiin. Tämä on ensimmäinen tietojoukko, joka edustaa ongelmaa, jonka dataanalyytikko tai datatieteilijä toivoo ratkaisevan.
Harjoitustietojen merkitystä ei voi yliarvioida. Se pitää sisällään malleja ja suhteita, jotka koneoppimismalli "oppii" ennustamaan tuloksia, kun sille myöhemmin annetaan uutta, näkymätöntä dataa.
Joten mikä on LLM? Suuret kielimallit eli LLM:t kuuluvat koneoppimisen sateenvarjon alle. Ne ovat peräisin syväoppimisesta, ja niiden rakenne on kehitetty erityisesti luonnollisen kielen käsittelyyn.
Voit sanoa, että ne on rakennettu sanojen pohjalle. Heidän tavoitteenaan on yksinkertaisesti ennustaa, mikä sana on seuraava sanasarjassa. Esimerkiksi iPhonen automaattinen korjausominaisuus iOS 17:ssä käyttää nyt LLM:ää ennustaakseen paremmin, minkä sanan aiot todennäköisimmin kirjoittaa seuraavaksi.

Kuvittele nyt olevasi koneoppimismalli. (Keskeä meitä, tiedämme, että se on venyttely.) Sinut on koulutettu ennustamaan sanoja. Olet lukenut ja tutkinut miljoonia sanoja laajasta valikoimasta lähteitä kaikenlaisista aiheista. Mentorisi (eli kehittäjät) ovat auttaneet sinua oppimaan parhaat tavat ennustaa sanoja ja luoda uutta tekstiä, joka sopii käyttäjän pyyntöön.
Mutta tässä on käänne. Käyttäjä antaa sinulle nyt valtavan asiakas- ja tapahtumatiedon laskentataulukon, jossa on miljoonia numerorivejä, ja pyytää sinua ennustamaan näihin olemassa oleviin tietoihin liittyviä lukuja.
Miten luulet ennustuksesi toteutuvan? Ensinnäkin olet luultavasti ärsyyntynyt siitä, että tämä tehtävä ei vastaa sitä, mitä olet työskennellyt niin kovasti oppiaksesi. (Onneksi, sikäli kuin tiedämme, LLM:illä ei vielä ole tunteita.) Vielä tärkeämpää on, että sinua pyydetään tekemään tehtävä, joka ei vastaa sitä, mitä olet oppinut tekemään. Etkä todennäköisesti suoriudu niin hyvin.
Koulutuksen ja tehtävien välinen kuilu auttaa selittämään, miksi LLM:t eivät sovellu hyvin ennakoiviin tehtäviin, jotka sisältävät numeerista taulukkotietoa – useimpien yritysten keräämää ensisijaista tietomuotoa. Sen sijaan koneoppimismalli, joka on erityisesti suunniteltu ja hienosäädetty tämäntyyppisten tietojen käsittelyyn, on tehokkaampi. Se on kirjaimellisesti koulutettu tähän.
LLM:n tehokkuus- ja optimointihaasteet
Sen lisäksi, että perinteiset koneoppimismenetelmät sopivat paremmin numeeriseen dataan, ne ovat paljon tehokkaampia ja helpompia optimoida suorituskyvyn parantamiseksi kuin LLM:t.
Palataan kokemukseesi, joka esiintyy LLM:nä. Kaikkien noiden sanojen lukeminen ja niiden tyylin ja järjestyksen tutkiminen kuulostaa suurelta työltä, eikö niin? Kaiken tämän tiedon sisäistäminen vaatisi paljon vaivaa.
Vastaavasti LLM:ien monimutkainen koulutus voi johtaa malleihin, joissa on miljardeja parametreja. Tämän monimutkaisuuden ansiosta nämä mallit voivat ymmärtää ihmisen kielen hankalia vivahteita ja vastata niihin. Raskaaseen koulutukseen liittyy kuitenkin raskaita laskentavaatimuksia, kun LLM:t luovat vastauksia. Numeerisesti suuntautuneet "perinteiset" koneoppimisalgoritmit, kuten päätöspuut tai neuroverkot, tarvitsevat todennäköisesti paljon vähemmän laskentaresursseja. Ja tässä ei ole kyse "isompi on parempi". Vaikka LLM:t pystyisivät käsittelemään numeerista dataa, tämä ero tarkoittaisi, että perinteiset koneoppimismenetelmät olisivat silti nopeampia, tehokkaampia, ympäristöystävällisempiä ja kustannustehokkaampia.
Lisäksi oletko koskaan kysynyt ChatGPT:ltä, kuinka se tiesi antaa tietyn vastauksen? Sen vastaus on todennäköisesti hieman epämääräinen:
Luon vastauksia lisensoitujen tietojen, ihmiskouluttajien luomien tietojen ja julkisesti saatavilla olevien tietojen yhdistelmän perusteella. Koulutukseeni sisältyi myös laajamittaisia tietokokonaisuuksia, jotka saatiin useista eri lähteistä, mukaan lukien kirjoista, verkkosivustoilta ja muista teksteistä, kehittääkseni laaja-alaista ymmärrystä ihmiskielestä. Koulutusprosessiin kuuluu laskelmien suorittaminen tuhansilla GPU:illa viikkojen tai kuukausien aikana, mutta tarkat yksityiskohdat ja aikataulut ovat OpenAI:n omia.
Kuinka paljon vastauksessa heijastuvasta "tiedosta" tuli ihmiskouluttajilta verrattuna julkisiin tietoihin vs. kirjoihin? Jopa ChatGPT itse ei ole varma: "Näiden lähteiden suhteelliset osuudet ovat tuntemattomia, eikä minulla ole yksityiskohtaista tietoa siitä, mitkä asiakirjat olivat osa koulutuspakettiani."
On hieman ahdistavaa, että ChatGPT antaa niin varmoja vastauksia kysymyksiisi, mutta ei pysty jäljittämään vastauksiaan tiettyihin lähteisiin. LLM:ien rajallinen tulkinta- ja selitettävyys asettaa haasteita myös niiden optimoinnissa tiettyihin liiketoiminnan tarpeisiin. Voi olla vaikea ymmärtää heidän tietojensa tai ennusteidensa taustalla olevia perusteita. Asiaa mutkistaa entisestään se, että tietyt yritykset kamppailevat säännösten kanssa, mikä tarkoittaa, että niiden on kyettävä selittämään mallin ennusteisiin vaikuttavat tekijät. Kaiken kaikkiaan nämä haasteet osoittavat, että perinteiset koneoppimismallit - yleensä paremmin tulkittavissa ja selitettävissä - sopivat todennäköisesti paremmin yrityskäyttöön.
Oikea paikka LLM:ille yritysten ennakoivassa työkalupakkissa
Pitäisikö meidän siis jättää LLM:t sanoihin liittyviin tehtäviinsä ja unohtaa ne ennakoivia käyttötapauksia varten? Nyt saattaa vaikuttaa siltä, että he eivät voi auttaa ennustamaan asiakkaiden vaihtuvuutta tai asiakkaan elinkaaren arvoa.
Tässä on asia: Vaikka sanomalla "perinteiset koneoppimismallit" saavat nämä tekniikat kuulostamaan laajalti ymmärrettyiltä ja helppokäyttöisiltä, tiedämme Pecan-kokemuksestamme, että yrityksillä on edelleen suuria vaikeuksia ottaa käyttöön jopa näitä tutumpia tekoälyn muotoja.

Workdayn tuore tutkimus paljastaa, että 42 % Pohjois-Amerikan yrityksistä joko ei ole aloittanut tekoälyn käyttöä tai ovat vasta alkuvaiheessa tutkimassa vaihtoehtojaan. Ja on kulunut yli vuosikymmen siitä, kun koneoppimistyökalut tulivat helpommin yritysten saataville. Heillä on ollut aikaa, ja erilaisia työkaluja on saatavilla.
Jostain syystä onnistuneet tekoälytoteutukset ovat olleet yllättävän harvinaisia huolimatta datatieteen ja tekoälyn ympärillä olevasta massiivisesta vilinästä – ja niiden tunnustetusta mahdollisuudesta vaikuttaa merkittäviin liiketoimintaan. Jotkin tärkeät mekanismit puuttuvat, mikä auttaisi kuromaan umpeen kuilua tekoälyn lupausten ja kyvyn välillä panna ne tuottavasti täytäntöön.
Ja juuri siinä uskomme, että LLM:t voivat nyt olla tärkeässä siltaroolissa. LLM:t voivat auttaa yrityskäyttäjiä ylittämään kuilun ratkaisevan liiketoimintaongelman tunnistamisen ja ennakoivan mallin kehittämisen välillä.
Kun LLM:t ovat nyt kuvassa, yritys- ja datatiimit, joilla ei ole kykyä tai kykyä koodata käsin koneoppimismalleja, voivat nyt paremmin muuntaa tarpeensa malleiksi. He voivat "käyttää sanojaan", kuten vanhemmat haluavat sanoa, käynnistääkseen mallinnusprosessin.
LLM:ien yhdistäminen koneoppimistekniikoihin, jotka on suunniteltu menestymään yritysdataan
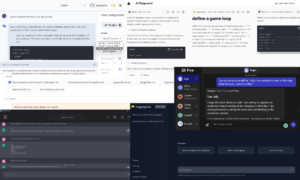
Tämä ominaisuus on nyt saapunut Pecanin Predictive GenAI:hen, joka yhdistää LLM:n vahvuudet jo pitkälle jalostettuun ja automatisoituun koneoppimisalustaan. LLM-pohjainen Predictive Chat kerää yrityskäyttäjän palautetta ennakoivan kysymyksen määrittelyyn ja kehittämiseen. Tämä on tietty ongelma, jonka käyttäjä haluaa ratkaista mallilla.
Sitten GenAI:n avulla alustamme luo Predictive Notebookin, joka tekee seuraavan askeleen kohti mallintamista entistä helpompaa. Jälleen LLM-ominaisuuksia hyödyntäen muistikirja sisältää esitäytettyjä SQL-kyselyitä ennustavan mallin harjoitustietojen valitsemiseksi. Pecanin automatisoidut tietojen valmistelu-, ominaisuussuunnittelu-, mallinrakennus- ja käyttöönottoominaisuudet voivat suorittaa loput prosessista ennätysajassa, nopeammin kuin mikään muu ennakoiva mallinnusratkaisu.
Lyhyesti sanottuna Pecan's Predictive GenAI käyttää LLM:iden vertaansa vailla olevaa kielitaitoa tehdäkseen luokkansa parhaan ennustavan mallinnuksen alustamme paljon helpommin saavutettavissa ja ystävällisemmän yrityskäyttäjille. Olemme innoissamme nähdessämme, kuinka tämä lähestymistapa auttaa monia muita yrityksiä menestymään tekoälyn kanssa.
Joten kun LLM:t yksin eivät sovellu hyvin kaikkiin ennakoiviin tarpeisiisi, vaan niillä voi olla merkittävä rooli AI-projektien eteenpäin viemisessä. Pecanin Predictive GenAI on edelläkävijä näiden tekniikoiden yhdistämisessä tulkitsemalla käyttötapaustasi ja antamalla sinulle etumatkan automaattisesti luodulla SQL-koodilla. Sinä pystyt tarkista se nyt ilmaisella kokeilulla.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/2024/01/pecan-llms-used-alone-cant-address-companys-predictive-needs?utm_source=rss&utm_medium=rss&utm_campaign=why-llms-used-alone-cant-address-your-companys-predictive-needs
- :on
- :On
- :ei
- :missä
- 15%
- 17
- a
- kyky
- pystyy
- Meistä
- saatavilla
- tunnustettu
- Lisäksi
- osoite
- hyväksyä
- Jälkeen
- uudelleen
- AI
- alias
- algoritmit
- kohdista
- Kaikki
- mahdollistaa
- yksin
- jo
- Myös
- hämmästyttävä
- Amerikka
- an
- analyytikko
- analysoida
- ja
- vastaus
- vastauksia
- Kaikki
- lähestymistapa
- OVAT
- noin
- saapui
- AS
- auttaa
- At
- Automatisoitu
- automatisoitu koneoppiminen
- automaattisesti
- saatavissa
- takaisin
- perustua
- BE
- Bear
- tuli
- ollut
- Alku
- takana
- ovat
- Uskoa
- PARAS
- Paremmin
- välillä
- miljardeja
- Bitti
- Pultti
- Kirjat
- sekä
- neronleimaus
- SILTA
- siltana
- laajempaa
- Rakentaminen
- rakennettu
- liiketoiminta
- liiketoiminnan vaikutukset
- yritykset
- mutta
- by
- soittaa
- tuli
- CAN
- kyvyt
- valmiudet
- Koko
- kuljettaa
- tapaus
- tapauksissa
- tietty
- haasteet
- kuilu
- jutella
- ChatGPT
- valita
- koodi
- kerätä
- tulee
- Yritykset
- Yrityksen
- monimutkainen
- monimutkaisuus
- laskennallinen
- laskelmat
- tietojenkäsittely
- luottavainen
- muodostaa
- sisältää
- korjata
- kustannustehokas
- voisi
- muotoillun
- luoda
- luotu
- Luominen
- kriittinen
- Ylittää
- ratkaiseva
- asiakas
- tiedot
- data-analyytikko
- Tietojen valmistelu
- tietojenkäsittely
- tietojen tutkija
- aineistot
- vuosikymmen
- päätös
- syvä
- syvä oppiminen
- syvempää
- määritelmä
- vaatii
- käyttöönotto
- suunniteltu
- Huolimatta
- yksityiskohtainen
- yksityiskohdat
- kehittää
- kehitetty
- kehittäjille
- kehittämällä
- Kehitys
- ero
- eri
- DIG
- do
- asiakirjat
- ei
- Don
- Dont
- luonnos
- piirustus
- Varhainen
- helpompaa
- helppo
- Tehokas
- tehokkuus
- tehokas
- vaivaa
- myöskään
- kattaa
- Tekniikka
- ympäristöä
- Eetteri (ETH)
- Jopa
- EVER
- esimerkki
- kunnostautua
- innoissaan
- jännittävä
- olemassa
- experience
- Selittää
- Selitettävyys
- tutkia
- Tutkiminen
- tekijät
- Epäonnistuminen
- Pudota
- tuttu
- paljon
- nopeampi
- Ominaisuus
- tunteet
- vähemmän
- Etunimi
- sovittaa
- sopii
- Kääntää
- varten
- muoto
- lomakkeet
- Onneksi
- Eteenpäin
- perusta
- Ilmainen
- ystävällinen
- alkaen
- edelleen
- kiinnityslämpötila
- kuilu
- genai
- yleensä
- tuottaa
- syntyy
- synnyttää
- generatiivinen
- Generatiivinen AI
- lahja
- tietty
- antaa
- Antaminen
- Go
- tavoite
- GPU
- ohjaavat
- HAD
- lyö
- kahva
- Käsittely
- Kova
- Olla
- satama
- pää
- raskas
- auttaa
- auttanut
- auttaa
- auttaa
- erittäin
- pitää
- toivoo
- Miten
- Kuitenkin
- HTTPS
- ihmisen
- i
- ideoita
- tunnistaminen
- if
- kuvitella
- Vaikutus
- toteuttaa
- toteutukset
- tärkeä
- merkittävästi
- in
- Mukaan lukien
- vaikuttaminen
- tiedot
- ensimmäinen
- aloitettu
- panos
- sen sijaan
- aikovat
- tulee
- osallistuva
- liittyy
- johon
- iOS
- IT
- SEN
- itse
- Job
- vain
- KDnuggets
- Tietää
- tunnettu
- Kieli
- suuri
- laaja
- suureksi osaksi
- myöhemmin
- johtava
- OPPIA
- oppinut
- oppiminen
- jättää
- Licensed
- elinikäinen
- pitää
- Todennäköisesti
- rajallinen
- Erä
- kone
- koneoppiminen
- Koneoppimistekniikat
- tehty
- tehdä
- TEE
- monet
- massiivinen
- ottelu
- matemaattinen
- tarkoittaa
- mekanismi
- mentoreita
- menetelmät
- ehkä
- miljoonia
- puuttuva
- seos
- malli
- mallintaminen
- mallit
- kk
- lisää
- tehokkaampi
- eniten
- liikkuvat
- paljon
- täytyy
- my
- Luonnollinen
- Luonnollinen kieli
- Luonnollinen kielen käsittely
- Tarve
- tarpeet
- verkot
- hermo-
- hermoverkkoihin
- Uusi
- seuraava
- Pohjoiseen
- Pohjois-Amerikka
- muistikirja
- nyt
- vivahteet
- numerot
- saatu
- of
- on
- ONE
- vain
- OpenAI
- optimointi
- Optimoida
- optimoimalla
- Vaihtoehdot
- or
- Muut
- meidän
- ulos
- tuloksiin
- yli
- liioitella
- parametrit
- vanhemmat
- osa
- erityinen
- kuviot
- suorittaa
- suorituskyky
- poimia
- kuva
- uraauurtava
- Paikka
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- Pelaa
- mahdollinen
- voimakas
- tarkasti
- ennustaa
- ennustamiseen
- Ennusteet
- ennustavan
- valmistelu
- ensisijainen
- todennäköisesti
- Ongelma
- prosessi
- käsittely
- hankkeet
- Promises
- patentoitu
- todistettu
- toimittaa
- julkinen
- julkisesti
- kyselyt
- kysymys
- kysymykset
- alue
- HARVINAINEN
- perussyyt
- Lue
- Lukeminen
- reason
- ennätys
- puhdistettu
- heijastunut
- sääntelyn
- liittyvä
- Ihmissuhteet
- suhteellinen
- TOISTUVASTI
- edustavat
- pyyntö
- vaatimukset
- tutkimus
- Esittelymateriaalit
- Vastata
- vastaus
- vasteet
- REST
- johtua
- Saatu ja
- paljastaa
- oikein
- Rooli
- juoksu
- s
- sanoa
- sanonta
- tiede
- Tiedemies
- nähdä
- näyttää
- valita
- valitsemalla
- Järjestys
- setti
- Lyhyt
- shouldnt
- näyttää
- merkitys
- merkittävä
- samankaltainen
- yksinkertaisesti
- koska
- taitoja
- So
- ratkaisu
- SOLVE
- jonkin verran
- kuulostaa
- äänet
- Lähteet
- erityinen
- erityisesti
- taulukkolaskentaohjelma
- SQL
- vaiheissa
- Alkaa
- alkoi
- Vaihe
- Yhä
- vahvuudet
- rakenne
- Struggling
- tutkittu
- Opiskelu
- tyyli
- menestyä
- onnistunut
- niin
- varma
- kestävä
- T
- puuttumalla
- ottaa
- Tehtävä
- tehtävät
- tiimit
- tekniikat
- Technologies
- teksti
- kuin
- että
- -
- heidän
- Niitä
- Nämä
- ne
- asia
- asiat
- ajatella
- tätä
- ne
- tuhansia
- kiristää
- aika
- että
- yhdessä
- tonni
- työkalupakki
- työkalut
- Aiheet
- kohti
- jäljittää
- perinteinen
- koulutettu
- koulutus
- kauppa
- Kääntää
- Puut
- yrittää
- VUORO
- twist
- tyyppi
- sateenvarjo
- varten
- ymmärtää
- ymmärtäminen
- ymmärsi
- yhdistävä
- tuntematon
- vertaansa vailla oleva
- us
- käyttää
- käyttölaukku
- käytetty
- käyttäjä
- Käyttäjät
- käyttötarkoituksiin
- käyttämällä
- arvo
- lajike
- eri
- valtava
- näkyvyys
- elintärkeä
- vs
- haluaa
- Tapa..
- tavalla
- we
- sivustot
- viikkoa
- HYVIN
- olivat
- Mitä
- Mikä on
- kun
- joka
- vaikka
- miksi
- laajalti
- tulee
- with
- sisällä
- sana
- sanoja
- Referenssit
- työskenteli
- arvoinen
- olisi
- vielä
- te
- Sinun
- zephyrnet