Ymmärsimme äskettäin, ettemme ole tuoneet sinulle tietojenkäsittelytaulukoita jonkin aikaa. Ja se ei johdu niiden saatavuuden puutteesta; datatieteen ohjelehtiä on kaikkialla, aina johdantokehityksestä edistyneeseen, joka kattaa aiheita algoritmeista, tilastoihin, haastatteluvinkkeihin ja muuhun.
Mutta mikä tekee hyvästä huijausarkista? Mikä tekee huijauslehdestä kelvollisen erottaa erityisen hyväksi? On vaikea laittaa sormeasi tarkasti mikä tekee hyvän huijauslehden, mutta tietysti sellainen, joka välittää välttämättömät tiedot tiiviisti - onko kyseinen tieto luonteeltaan erityistä - on ehdottomasti hyvä alku. Ja se tekee ehdokkaistamme huomionarvoisia. Joten lue neljästä kuratoidusta täydentävästä cheatsheetsistä, jotka auttavat sinua datatieteen oppimisessa tai tarkastelussa.
Ensimmäinen on Aaron Wangin Data Science Cheatsheet 2.0, neljän sivun kokoinen tilastollinen abstraktio, perustavanlaatuiset koneoppimisalgoritmit sekä syvällisen oppimisen aiheet ja käsitteet. Sitä ei ole tarkoitettu tyhjentäväksi, vaan pikakuvaus tilanteisiin, kuten haastattelujen valmistelu ja tenttiarvostelut, ja mihin tahansa muuhun, joka vaatii samanlaista arvostelusyvyyttä. Kirjoittaja huomauttaa, että vaikka tilastotietojen ja lineaarisen algebran perustiedot ymmärtäisivät tämän resurssin eniten, aloittelijoiden tulisi pystyä keräämään hyödyllistä tietoa myös sen sisällöstä.

Näyttökuva Aaron Wang'silta Data Science Cheatsheet 2.0
Seuraava tarjouksemme tänään on se, johon Aaron Wangin resurssi perustuu, Maverick Linin Data Science -huijauslehti (Wangin viittaus omaansa 2.0: ksi on suora nyökkäys Linin "alkuperäiselle"). Voimme ajatella Linin huijauslehteä syvällisemmäksi kuin Wang (vaikka Wangin päätös tehdä vähemmän syvälliseksi vaikuttaa tarkoitukselliselta ja hyödylliseltä vaihtoehdolta), joka kattaa perustavanlaatuisemmat datatieteelliset käsitteet, kuten datanpuhdistuksen, mallinnuksen ajatuksen, tekemisen " big data ”Hadoopin, SQL: n ja jopa Pythonin perusteiden kanssa.
Selvästi tämä vetoaa niihin, jotka ovat tiukemmin ”aloittelijoiden” leirillä ja tekevät hyvää työtä ruokahalun herättämiseksi ja lukijoiden tietämiseksi laajasta tietojenkäsittelyalasta ja monista sen käsitteistä. Tämä on ehdottomasti toinen vankka resurssi, varsinkin jos lukija on uusi tulokas tietojenkäsittelyssä.

Kuvakaappaus Maverick Lin'siltä Data Science Cheatsheet
Kun siirrymme ajassa taaksepäin - etsimme inspiraatiota Linin huijauslehtiä varten - kohtaamme William Chenin Todennäköisyys-Cheatsheet 2.0. Chenin huijauslehti on saanut vuosien varrella paljon huomiota ja kiitosta, joten ehkä olet törmännyt siihen jossain vaiheessa. Chenin huijauslehti on selvästi eri painopiste (jolla on annettu nimi) on kaatumiskurssi todennäköisyyskäsitteille tai syvä sukelluskatsaus, mukaan lukien erilaiset jakaumat, kovarianssi ja muunnokset, ehdollinen odotus, Markov-ketjut, erilaiset tärkeät kaavat ja paljon enemmän.
Kymmenen sivun kohdalla sinun pitäisi pystyä kuvittelemaan tässä käsiteltyjen todennäköisyysaiheiden laajuus. Mutta älä anna sen estää sinua; Chenin kyky keittää käsitteet olennaisiin luodinkohtiin ja selittää yksinkertaisella englannilla, mutta olematta uhrautumatta olennaiseen, on huomionarvoista. Siinä on myös runsaasti selittäviä visualisointeja, mikä on varsin hyödyllistä, kun tilaa on rajoitetusti ja halu olla ytimekäs on vahva.
Paitsi että Chenin kokoelma on laadukas ja ansaitsee aikasi, aloittelijana tai täydestä katsauksesta kiinnostuneena työskentelisin päinvastaisessa järjestyksessä siitä, miten nämä resurssit esitettiin - Chenin huijauslehdestä Liniin ja lopuksi Wangiin, rakentamalla käsitteiden päälle.
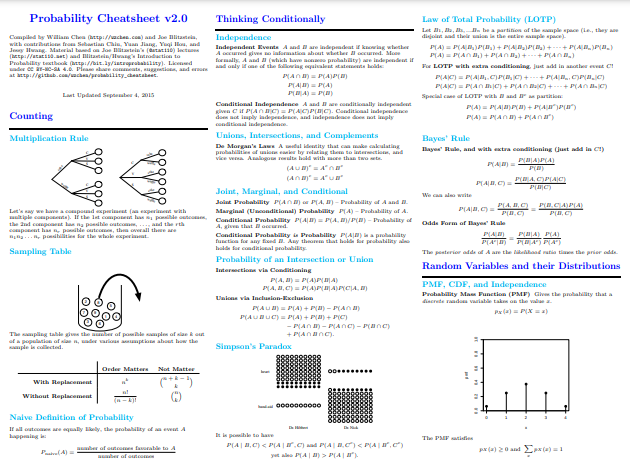
Näyttökuva William Chen'siltä Todennäköisyys-Cheatsheet 2.0
Yksi viimeinen resurssi, jonka olen sisällyttänyt tähän, vaikka se ei ole teknisesti huijauslehti, on Rishabh Anandin koneoppimisen puremat. Laskutus itseään "[haastatteluoppaana yleisistä koneoppimisen käsitteistä, parhaista käytännöistä, määritelmistä ja teoriasta", Anand on koonnut laajan kokoelman tietoa "puree", jonka hyödyllisyys ylittää ehdottomasti alun perin tarkoitetun haastattelun valmistelun. Käsiteltyjä aiheita ovat:
- Mallin pisteytysmittaus
- Parametrien jakaminen
- k-taitettava ristivalidointi
- Python-tietotyypit
- Mallin suorituskyvyn parantaminen
- Tietokonenäkömallit
- Huomio ja sen vaihtoehdot
- Luokan epätasapainon käsittely
- Computer Vision Sanasto
- Vanilja-lisäys
- laillistamisen
- Viitteet

Kuvakaappaus Koneoppimisen puremat
Vaikka koneoppimisessa käsitellään "käsitteitä, parhaita käytäntöjä, määritelmiä ja teoriaa", kuten resurssin itsekuvauksessa luvataan, nämä "puremat" on ehdottomasti suunnattu käytännöllisyyteen, mikä tekee sivustosta täydentävän suurelle osalle aineistoa kolme aiemmin mainittua ohjelehteä. Jos haluaisin kattaa kaiken tämän julkaisun kaikkien neljän aineiston materiaalin, tarkastelen sitä varmasti kolmen muun jälkeen.
Joten sinulla on neljä cheatsheets (tai kolme cheatsheets ja yksi cheatsheet-vieressä resurssi) käyttää oppimiseen tai tarkasteluun. Toivottavasti jokin tässä on sinulle hyödyllinen, ja kutsun kuka tahansa jakamaan cheatsheets, jonka he ovat löytäneet hyödyllisiksi alla olevissa kommenteissa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Aaron
- kyky
- pystyy
- poikki
- kehittynyt
- Jälkeen
- algoritmit
- Kaikki
- vaihtoehto
- ja
- Toinen
- joku
- valitus
- huomio
- kirjoittaja
- saatavuus
- takaisin
- perustua
- perustiedot
- Perusasiat
- Aloittelijan
- ovat
- alle
- hyödyttää
- PARAS
- parhaat käytännöt
- Jälkeen
- Iso
- Big Data
- laskutus
- leveys
- laaja
- toi
- Rakentaminen
- Leiri
- ehdokkaat
- varmasti
- kahleet
- chen
- luokka
- Siivous
- selvästi
- kokoelma
- Tulla
- kommentit
- Yhteinen
- täydentävä
- käsitteet
- pitoisuus
- kurssi
- kattaa
- katettu
- päällyste
- Crash
- Ylittää
- kuratoitu
- tiedot
- tietojenkäsittely
- päätös
- syvä
- syväsukellus
- syvä oppiminen
- ehdottomasti
- syvyys
- kuvaus
- eri
- vaikea
- ohjata
- Jakaumat
- tekee
- alas
- kattaa
- Englanti
- erityisesti
- olennainen
- olennaiseen
- Eetteri (ETH)
- Jopa
- tentti
- odotus
- Selittää
- ala
- Kuva
- lopullinen
- Vihdoin
- Löytää
- tiukasti
- Keskittää
- löytyi
- alkaen
- koko
- perus-
- edelleen
- suunnattu
- general
- tietty
- Go
- hyvä
- hyvä työ
- ohjaavat
- tätä
- Toivon mukaan
- Miten
- HTTPS
- ajatus
- epätasapaino
- merkitys
- in
- perusteellinen
- sisältää
- Mukaan lukien
- tiedot
- Inspiraatio
- sen sijaan
- tahallinen
- kiinnostunut
- Haastatella
- alustava
- kutsu
- IT
- itse
- Job
- tuntemus
- Lack
- oppiminen
- Taso
- rajallinen
- katso
- näköinen
- kone
- koneoppiminen
- tehdä
- TEE
- Tekeminen
- monet
- materiaali
- yksinäinen susi
- mainitsi
- Metrics
- malli
- mallit
- lisää
- eniten
- liikkua
- nimi
- luonto
- seuraava
- Huomautuksia
- huomionarvoinen
- Käsite
- tarjoamalla
- ONE
- tilata
- alkuperäinen
- alun perin
- Muut
- oma
- erityisesti
- suorituskyky
- tavallinen
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- pistettä
- Kirje
- Käytännön
- käytännöt
- esitetty
- aiemmin
- luvattu
- laittaa
- Python
- laatu
- nopea
- alainen
- Lue
- lukija
- lukijoita
- tajusi
- äskettäin
- resurssi
- Esittelymateriaalit
- käänteinen
- arviot
- Arvostelut
- Rikas
- uhraa
- tiede
- pisteytys
- etsiä
- näyttää
- Jaa:
- jakaminen
- shouldnt
- samankaltainen
- paikka
- tilanteita
- So
- vankka
- jonkin verran
- Joku
- jotain
- Tila
- erityinen
- Alkaa
- tilastollinen
- tilasto
- vahva
- niin
- -
- Perusteet
- heidän
- kolmella
- aika
- vinkit
- että
- tänään
- ylin
- Aiheet
- kohti
- muunnokset
- tyypit
- ymmärtäminen
- käyttää
- validointi
- lajike
- eri
- visio
- Mitä
- onko
- joka
- vaikka
- KUKA
- leveä
- tulee
- sisällä
- Referenssit
- olisi
- vuotta
- Sinun
- zephyrnet




