AWS-käyttöiset datajärvet, joita tukee vertaansa vailla oleva saatavuus Amazonin yksinkertainen tallennuspalvelu (Amazon S3), pystyy käsittelemään mittakaavaa, ketteryyttä ja joustavuutta, joita vaaditaan erilaisten data- ja analytiikkalähestymistapojen yhdistämiseen. Datajärvien koon kasvaessa ja käytön kypsyessä datan pitäminen johdonmukaisena liiketoimintatapahtumien kanssa voidaan vaatia paljon vaivaa. Varmistaakseen tiedostojen päivittämisen tapahtumien johdonmukaisella tavalla, yhä useammat asiakkaat käyttävät avoimen lähdekoodin tapahtumataulukkomuotoja, kuten Apache jäävuori, Apache Hudija Linux Foundation Delta Lake joiden avulla voit tallentaa tietoja korkeilla pakkausnopeuksilla, olla natiivi käyttöliittymä sovelluksiisi ja kehystesi kanssa ja yksinkertaistaa inkrementaalista tietojenkäsittelyä Amazon S3:lle rakennetuissa datajärvissä. Nämä muodot mahdollistavat ACID- (atomicity, johdonmukaisuus, eristys, kestävyys) -tapahtumat, katkokset ja poistot sekä edistyneet ominaisuudet, kuten aikamatkat ja tilannekuvat, jotka olivat aiemmin saatavilla vain tietovarastoissa. Jokainen tallennusmuoto toteuttaa tämän toiminnon hieman eri tavoin; vertailua varten katso AWS:n tapahtumatietojärvelle avoimen taulukkomuodon valitseminen.
Vuonna 2023, AWS ilmoitti yleisestä saatavuudesta Apache Icebergille, Apache Hudille ja Linux Foundation Delta Lakelle Amazon Athena Apache Sparkille, joka poistaa tarpeen asentaa erillistä liitintä tai siihen liittyviä riippuvuuksia ja hallita versioita ja yksinkertaistaa näiden kehysten käyttämiseen tarvittavia määritysvaiheita.
Tässä viestissä näytämme sinulle, kuinka Spark SQL:ää käytetään Amazon Athena muistikirjoja ja työskentele Iceberg-, Hudi- ja Delta Lake -taulukkomuotojen kanssa. Esittelemme yleisiä toimintoja, kuten tietokantojen ja taulukoiden luomista, tietojen lisäämistä taulukoihin, tiedoista kyselyitä ja tilannekuvien katsomista Amazon S3:n taulukoista Spark SQL:llä Athenassa.
Edellytykset
Täytä seuraavat edellytykset:
Lataa ja tuo esimerkkimuistikirjoja Amazon S3:sta
Jatka lataamalla tässä viestissä käsitellyt muistikirjat seuraavista paikoista:
Kun olet ladannut muistikirjat, tuo ne Athena Spark -ympäristöösi seuraamalla Muistikirjan tuominen osassa Muistikirjan tiedostojen hallinta.
Siirry tiettyyn Open Table Format -osioon
Jos olet kiinnostunut Iceberg-taulukkomuodosta, siirry kohtaan Työskentely Apache Iceberg -pöytien kanssa osiossa.
Jos olet kiinnostunut Hudi-taulukkomuodosta, siirry kohtaan Työskentely Apache Hudi -pöytien kanssa osiossa.
Jos olet kiinnostunut Delta Lake -taulukkomuodosta, siirry kohtaan Työskentely Linux Foundation Delta Lake -taulukoiden kanssa osiossa.
Työskentely Apache Iceberg -pöytien kanssa
Kun käytät Spark-muistikirjoja Athenassa, voit suorittaa SQL-kyselyitä suoraan ilman PySparkin käyttöä. Teemme tämän käyttämällä solumaikioita, jotka ovat muistikirjan solun erityisiä otsikoita, jotka muuttavat solun käyttäytymistä. SQL:lle voimme lisätä %%sql magic, joka tulkitsee koko solun sisällön SQL-käskyksi, joka suoritetaan Athenassa.
Tässä osiossa näytämme, kuinka voit käyttää SQL:ää Apache Spark for Athenassa Apache Iceberg -taulukoiden luomiseen, analysointiin ja hallintaan.
Määritä muistikirjaistunto
Jos haluat käyttää Apache Iceberg -ohjelmaa Athenassa istuntoa luodessasi tai muokkaaessasi, valitse Apache jäävuori vaihtoehto laajentamalla Apache Spark -ominaisuudet osio. Se esitäyttää ominaisuudet seuraavan kuvakaappauksen mukaisesti.
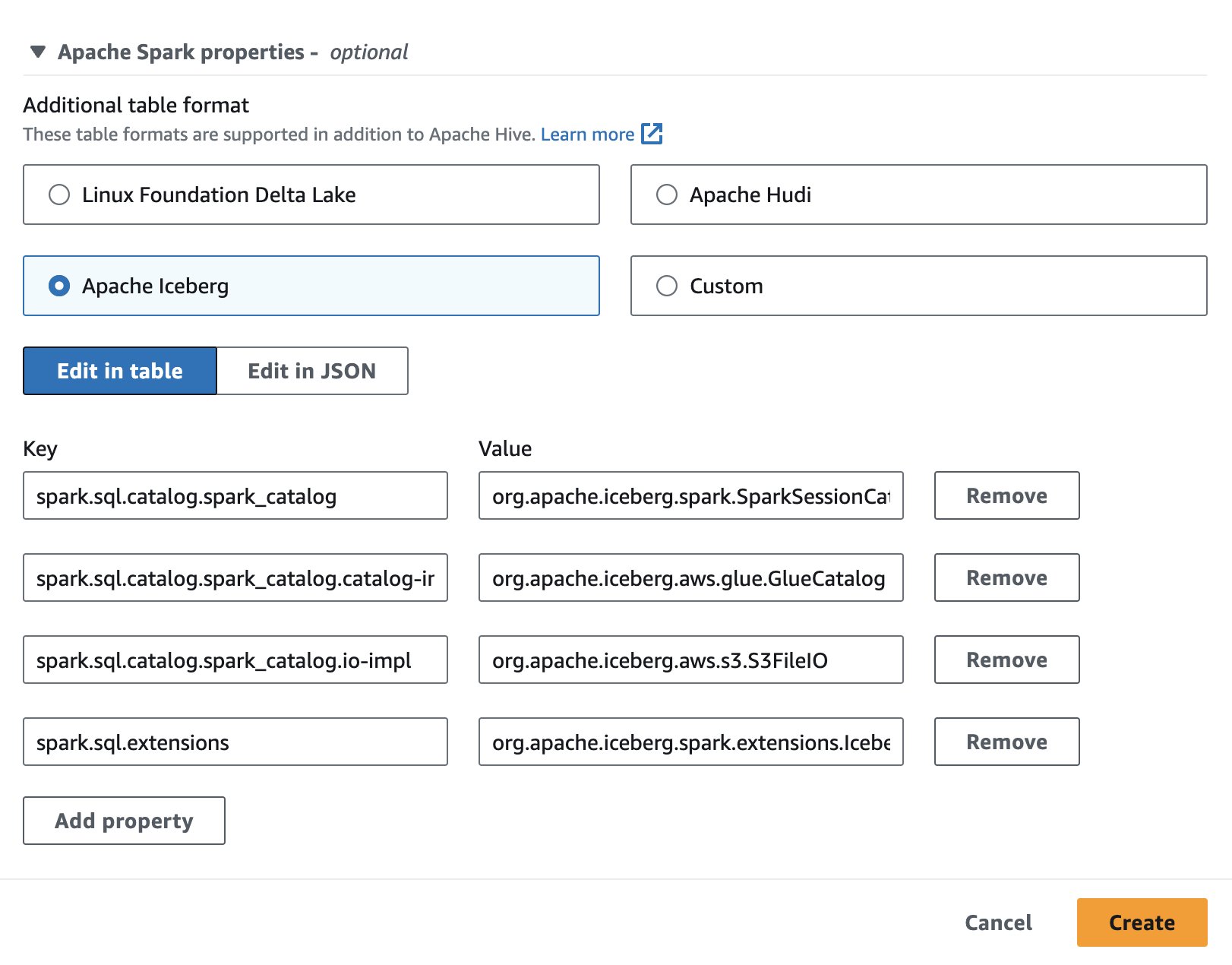
Katso vaiheet Muokkaa istunnon tietoja or Oman muistikirjan luominen.
Tässä osiossa käytetty koodi on saatavilla osoitteessa SparkSQL_iceberg.ipynb tiedostoa seurataksesi.
Luo tietokanta ja jäävuoritaulukko
Ensin luomme tietokannan AWS Glue Data Catalogiin. Seuraavalla SQL:llä voimme luoda tietokannan nimeltä icebergdb:
Seuraavaksi tietokannassa icebergdb, luomme Iceberg-taulukon nimeltä noaa_iceberg osoittaa Amazon S3:ssa olevaan paikkaan, jossa lataamme tiedot. Suorita seuraava lauseke ja korvaa sijainti s3://<your-S3-bucket>/<prefix>/ S3-ämpärisi ja etuliitteesi kanssa:
Lisää tiedot taulukkoon
Kansoittaaksesi noaa_iceberg Jäävuoripöytä, lisäämme tiedot Parkettipöydästä sparkblogdb.noaa_pq joka luotiin osana edellytyksiä. Voit tehdä tämän käyttämällä LAITTAA SISÄÄN lausunto Sparkissa:
Vaihtoehtoisesti voit käyttää LUO TAULU VALITSENA USING iceberg -lausekkeen avulla voit luoda Iceberg-taulukon ja lisätä tiedot lähdetaulukosta yhdessä vaiheessa:
Kysy Iceberg-taulukosta
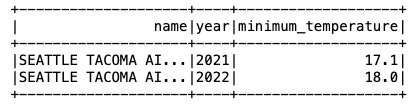
Nyt kun tiedot on lisätty Iceberg-taulukkoon, voimme aloittaa niiden analysoinnin. Suoritetaan Spark SQL löytääksemme tallennetun vähimmäislämpötilan vuoden mukaan 'SEATTLE TACOMA AIRPORT, WA US' sijainti:
Saamme seuraavan tuloksen.
Päivitä tiedot Iceberg-taulukossa
Katsotaan kuinka päivittää tiedot taulukossamme. Haluamme päivittää aseman nimen 'SEATTLE TACOMA AIRPORT, WA US' että 'Sea-Tac'. Spark SQL:n avulla voimme ajaa PÄIVITYS lausunto Iceberg-pöytää vastaan:
Voimme sitten suorittaa edellisen SELECT-kyselyn löytääksemme tallennetun vähimmäislämpötilan 'Sea-Tac' sijainti:
Saamme seuraavan tuotoksen.

Kompaktit datatiedostot
Avoimet taulukkomuodot, kuten Iceberg, toimivat luomalla delta-muutoksia tiedostojen tallennustilaan ja seuraamalla rivien versioita luettelotiedostojen kautta. Useammat datatiedostot johtavat siihen, että luettelotiedostoihin tallennetaan enemmän metadataa, ja pienet datatiedostot aiheuttavat usein tarpeettoman määrän metadataa, mikä johtaa tehottomampiin kyselyihin ja korkeampiin Amazon S3:n käyttökustannuksiin. Juoksemassa Icebergiä rewrite_data_files Spark for Athenan menetelmä tiivistää datatiedostot yhdistäen monia pieniä deltamuutostiedostoja pienemmäksi lukuoptimoitujen Parquet-tiedostojen joukkoon. Tiedostojen tiivistäminen nopeuttaa lukutoimintoa kyselyn yhteydessä. Suorita tiivistys taulukossamme suorittamalla seuraava Spark SQL:
rewrite_data_files tarjoaa vaihtoehtoja määrittääksesi lajittelustrategiasi, joka voi auttaa järjestämään ja tiivistämään tietoja.
Listaa taulukon tilannekuvia
Jokainen jäävuoren taulukon kirjoitus-, päivitys-, poisto-, upsert- ja tiivistystoiminto luo uuden tilannekuvan taulukosta samalla, kun vanhat tiedot ja metatiedot säilytetään tilannekuvan eristämistä ja aikamatkoja varten. Voit luetella Iceberg-taulukon tilannevedokset suorittamalla seuraavan Spark SQL -käskyn:
Vanhenna vanhat tilannekuvat
Säännöllisesti vanhentuvia tilannekuvia suositellaan tarpeettomien tiedostojen poistamiseksi ja taulukon metatietojen koon pitämiseksi pienenä. Se ei koskaan poista tiedostoja, joita vanhentumaton tilannekuva vaatii edelleen. Suorita Spark for Athenassa seuraava SQL vanhentuaksesi taulukon tilannevedokset icebergdb.noaa_iceberg jotka ovat vanhempia kuin tietty aikaleima:
Huomaa, että aikaleiman arvo on määritetty merkkijonona muodossa yyyy-MM-dd HH:mm:ss.fff. Tulos näyttää poistettujen data- ja metatietotiedostojen lukumäärän.
Pudota taulukko ja tietokanta
Voit suorittaa seuraavan Spark SQL:n puhdistaaksesi Iceberg-taulukot ja niihin liittyvät tiedot Amazon S3:ssa tästä harjoituksesta:
Suorita seuraava Spark SQL poistaaksesi tietokanta icebergdb:
Lisätietoja kaikista toiminnoista, joita voit suorittaa Iceberg-pöydillä käyttämällä Spark for Athenaa, katso Spark kyselyt ja Spark-menettelyt Iceberg-dokumentaatiossa.
Työskentely Apache Hudi -pöytien kanssa
Seuraavaksi näytämme, kuinka voit käyttää SQL:ää Spark for Athenassa Apache Hudi -taulukoiden luomiseen, analysointiin ja hallintaan.
Määritä muistikirjaistunto
Jos haluat käyttää Apache Hudia Athenassa, kun luot tai muokkaat istuntoa, valitse Apache Hudi vaihtoehto laajentamalla Apache Spark -ominaisuudet osiossa.
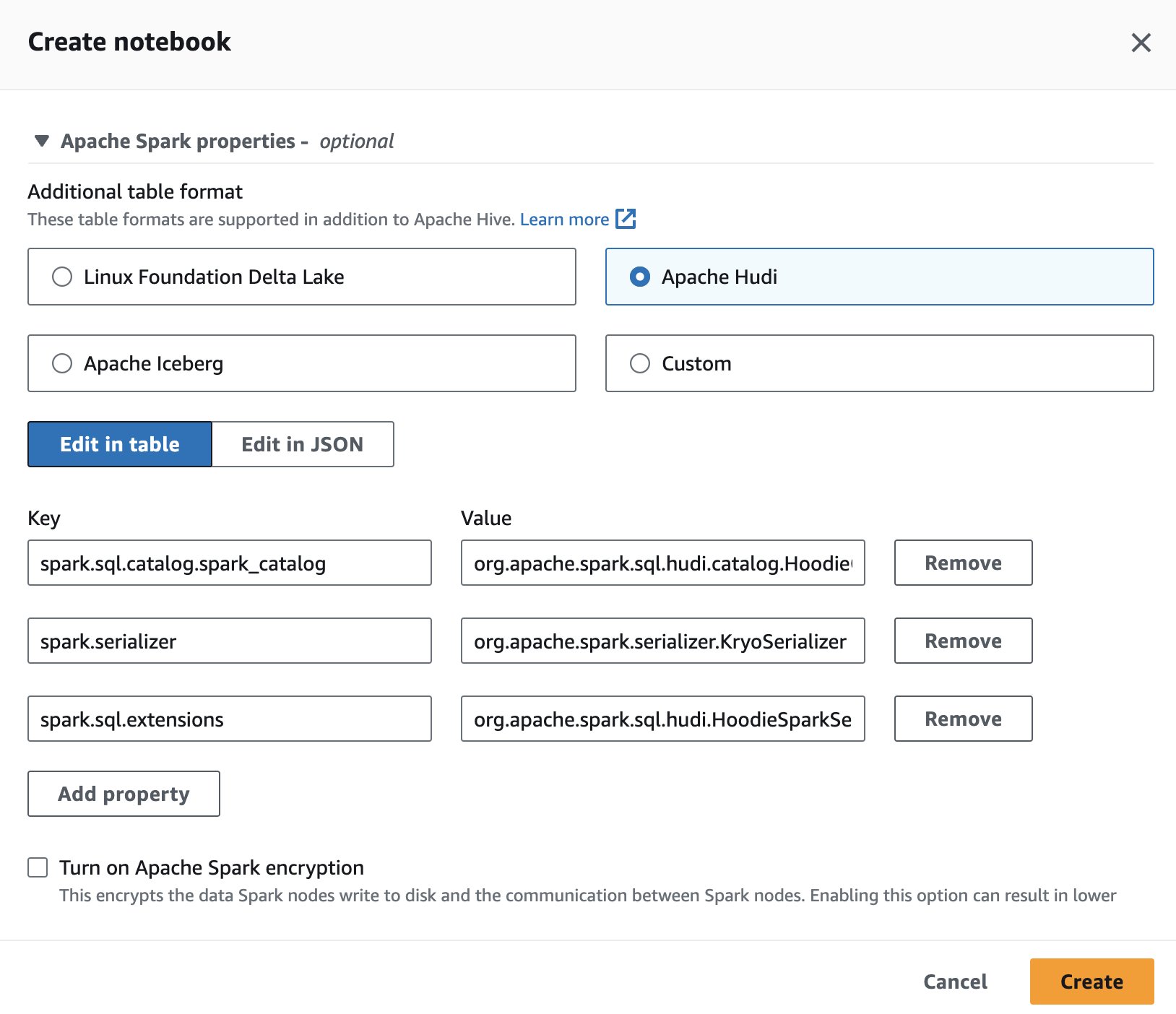
Katso vaiheet Muokkaa istunnon tietoja or Oman muistikirjan luominen.
Tässä osiossa käytetyn koodin tulee olla saatavilla osoitteessa SparkSQL_hudi.ipynb tiedostoa seurataksesi.
Luo tietokanta ja Hudi-taulukko
Ensin luodaan tietokanta nimeltä hudidb joka tallennetaan AWS-liimatietokatalogiin, jonka jälkeen luodaan Hudi-taulukko:
Luomme Hudi-taulukon, joka osoittaa sijaintiin Amazon S3:ssa, jossa lataamme tiedot. Huomaa, että taulukko on kopioi kirjoitettavaksi tyyppi. Sen määrittelee type= 'cow' taulukossa DDL. Olemme määrittäneet aseman ja päivämäärän useiksi ensisijaisiksi avaimille ja preCombinedField vuodeksi. Lisäksi taulukko on jaettu vuoden mukaan. Suorita seuraava lauseke ja korvaa sijainti s3://<your-S3-bucket>/<prefix>/ S3-ämpärisi ja etuliitteesi kanssa:
Lisää tiedot taulukkoon
Kuten Icebergin kanssa, käytämme LAITTAA SISÄÄN lauseke taulukon täyttämiseksi lukemalla tiedot sparkblogdb.noaa_pq edellisessä viestissä luotu taulukko:
Kysy Hudi-taulukosta
Nyt kun taulukko on luotu, suoritamme kyselyn, joka etsii lämpötilan enimmäislämpötilan 'SEATTLE TACOMA AIRPORT, WA US' sijainti:
Päivitä tiedot Hudi-taulukossa
Muutetaan aseman nimi 'SEATTLE TACOMA AIRPORT, WA US' että 'Sea–Tac'. Voimme suorittaa Spark for Athenen UPDATE-ilmoituksen päivitys tietueita noaa_hudi taulukossa:
Suoritamme edellisen SELECT-kyselyn löytääksemme suurimman tallennetun lämpötilan 'Sea-Tac' sijainti:
Suorita aikamatkakyselyitä
Voimme käyttää aikamatkakyselyitä SQL:ssä Athenassa analysoidaksemme aiempia datan tilannekuvia. Esimerkiksi:
Tämä kysely tarkistaa Seattlen lentokentän lämpötilatiedot tietyltä aikaisemmalta ajalta. Aikaleimalausekkeen avulla voimme matkustaa taaksepäin muuttamatta nykyisiä tietoja. Huomaa, että aikaleiman arvo on määritetty merkkijonona muodossa yyyy-MM-dd HH:mm:ss.fff.
Optimoi kyselyn nopeus klusteroinnin avulla
Voit parantaa kyselyn suorituskykyä suorittamalla klustereiden Hudi-taulukoissa käyttämällä SQL:ää Spark for Athenassa:
Kompaktit pöydät
Tiivistys on taulukkopalvelu, jota Hudi käyttää erityisesti Merge On Read (MOR) -taulukoissa päivityksen yhdistämiseksi rivipohjaisista lokitiedostoista vastaavaan sarakepohjaiseen perustiedostoon ajoittain uuden version tuottamiseksi perustiedostosta. Tiivistys ei koske Copy On Write (COW) -taulukoita ja koskee vain MOR-taulukoita. Voit suorittaa seuraavan kyselyn Spark for Athenassa suorittaaksesi MOR-taulukoiden tiivistämisen:
Pudota taulukko ja tietokanta
Suorita seuraava Spark SQL poistaaksesi luomasi Hudi-taulukon ja siihen liittyvät tiedot Amazon S3 -sijainnista:
Poista tietokanta suorittamalla seuraava Spark SQL hudidb:
Lisätietoja kaikista toiminnoista, joita voit suorittaa Hudi-pöydillä käyttämällä Spark for Athenaa, katso SQL DDL ja Menettelyt Hudi-dokumentaatiossa.
Työskentely Linux Foundation Delta Lake -taulukoiden kanssa
Seuraavaksi näytämme, kuinka voit käyttää SQL:ää Spark for Athenassa Delta Lake -taulukoiden luomiseen, analysointiin ja hallintaan.
Määritä muistikirjaistunto
Jos haluat käyttää Delta Lakea Spark for Athenassa istuntoa luodessasi tai muokkaaessasi, valitse Linux Foundation Delta Lake laajentamalla Apache Spark -ominaisuudet osiossa.
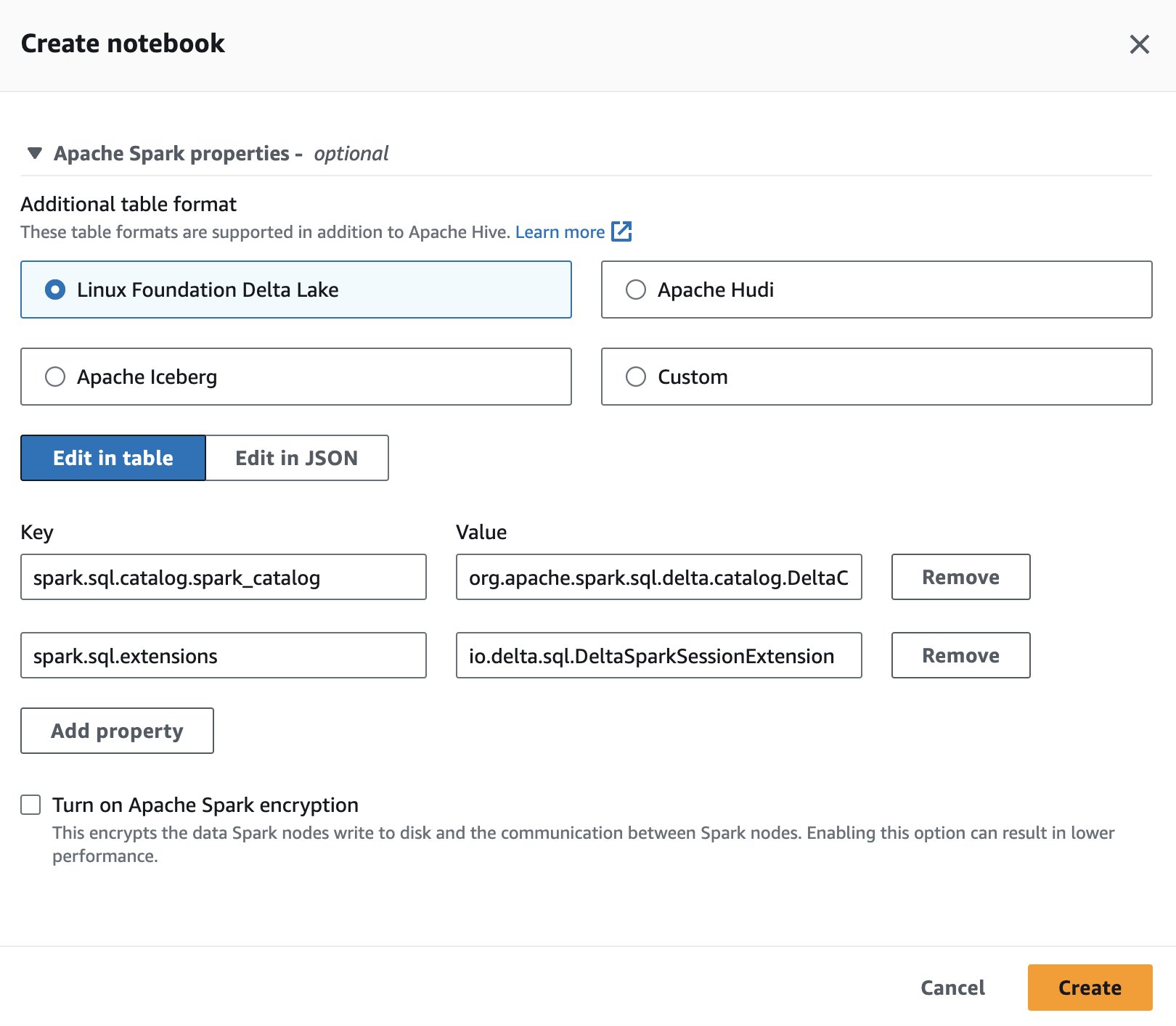
Katso vaiheet Muokkaa istunnon tietoja or Oman muistikirjan luominen.
Tässä osiossa käytetyn koodin tulee olla saatavilla osoitteessa SparkSQL_delta.ipynb tiedostoa seurataksesi.
Luo tietokanta ja Delta Lake -taulukko
Tässä osiossa luomme tietokannan AWS-liimatietokatalogiin. Seuraavaa SQL:ää käyttämällä voimme luoda tietokannan nimeltä deltalakedb:
Seuraavaksi tietokannassa deltalakedb, luomme Delta Lake -taulukon nimeltä noaa_delta osoittaa Amazon S3:ssa olevaan paikkaan, jossa lataamme tiedot. Suorita seuraava lauseke ja korvaa sijainti s3://<your-S3-bucket>/<prefix>/ S3-ämpärisi ja etuliitteesi kanssa:
Lisää tiedot taulukkoon
Käytämme LAITTAA SISÄÄN lauseke taulukon täyttämiseksi lukemalla tiedot sparkblogdb.noaa_pq edellisessä viestissä luotu taulukko:
Voit myös käyttää CREATE TABLE AS SELECT -toimintoa luodaksesi Delta Lake -taulukon ja lisätäksesi tietoja lähdetaulukosta yhteen kyselyyn.
Kysy Delta Lake -taulukkoa
Nyt kun tiedot on lisätty Delta Lake -taulukkoon, voimme aloittaa niiden analysoinnin. Suoritetaan Spark SQL löytääksesi tallennetun vähimmäislämpötilan 'SEATTLE TACOMA AIRPORT, WA US' sijainti:
Päivitä tiedot Delta Lake -taulukossa
Muutetaan aseman nimi 'SEATTLE TACOMA AIRPORT, WA US' että 'Sea–Tac'. Voimme ajaa PÄIVITYS lausunto Spark for Athenasta päivittääkseen tiedot noaa_delta taulukossa:
Voimme suorittaa edellisen SELECT-kyselyn löytääksemme tallennetun vähimmäislämpötilan 'Sea-Tac' sijainti, ja tuloksen pitäisi olla sama kuin aiemmin:
Kompaktit datatiedostot
Spark for Athenassa voit suorittaa OPTIMIZE-ohjelman Delta Lake -taulukossa, joka tiivistää pienet tiedostot suuremmiksi tiedostoiksi, joten pienten tiedostojen ylimääräiset kustannukset eivät rasita kyselyitä. Suorita tiivistys suorittamalla seuraava kysely:
Mainita Optimointeja Delta Lake -oppaassa eri vaihtoehtoja varten, jotka ovat käytettävissä OPTIMIZE-ohjelman aikana.
Poista tiedostot, joihin Delta Lake -taulukko ei enää viittaa
Voit poistaa Amazon S3:een tallennetut tiedostot, joihin Delta Lake -taulukko ei enää viittaa ja jotka ovat säilytyskynnystä vanhempia, suorittamalla VACCUM-komennon taulukossa Spark for Athenan avulla:
Mainita Poista tiedostot, joihin Delta-taulukko ei enää viittaa Delta Lake -dokumentaatiosta VACUUM-vaihtoehtojen osalta.
Pudota taulukko ja tietokanta
Suorita seuraava Spark SQL poistaaksesi luomasi Delta Lake -taulukon:
Poista tietokanta suorittamalla seuraava Spark SQL deltalakedb:
DROP TABLE DDL:n suorittaminen Delta Lake -taulukossa ja -tietokannassa poistaa näiden objektien metatiedot, mutta ei automaattisesti poista datatiedostoja Amazon S3:sta. Voit suorittaa seuraavan Python-koodin muistikirjan solussa poistaaksesi tiedot S3-sijainnista:
Lisätietoja SQL-käskyistä, joita voit suorittaa Delta Lake -taulukossa Spark for Athenan avulla, katso quickstart Delta Lake -dokumentaatiossa.
Yhteenveto
Tämä viesti osoitti, kuinka Spark SQL:ää käytetään Athena-muistikirjoissa tietokantojen ja taulukoiden luomiseen, tietojen lisäämiseen ja kyselyyn sekä yleisten toimintojen, kuten päivitysten, tiivistysten ja aikamatkojen suorittamiseen Hudi-, Delta Lake- ja Iceberg-taulukoissa. Avoimet taulukkomuodot lisäävät ACID-tapahtumia, upsers- ja -poistoja datalakkeihin, mikä ylittää raakaobjektien tallennuksen rajoitukset. Poistamalla tarpeen asentaa erillisiä liittimiä, Spark on Athenen sisäänrakennettu integraatio vähentää konfigurointivaiheita ja hallintakustannuksia käytettäessä näitä suosittuja kehyksiä luotettavien datajärvien luomiseen Amazon S3:ssa. Lisätietoja avoimen taulukkomuodon valitsemisesta datajärven työkuormille on kohdassa AWS:n tapahtumatietojärvelle avoimen taulukkomuodon valitseminen.
Tietoja Tekijät
![]() Pathik Shah on vanhempi Analytics-arkkitehti Amazon Athenassa. Hän liittyi AWS:ään vuonna 2015 ja on keskittynyt siitä lähtien big datan analytiikka-avaruuteen auttaen asiakkaita rakentamaan skaalautuvia ja kestäviä ratkaisuja AWS-analytiikkapalveluiden avulla.
Pathik Shah on vanhempi Analytics-arkkitehti Amazon Athenassa. Hän liittyi AWS:ään vuonna 2015 ja on keskittynyt siitä lähtien big datan analytiikka-avaruuteen auttaen asiakkaita rakentamaan skaalautuvia ja kestäviä ratkaisuja AWS-analytiikkapalveluiden avulla.
![]() Raj Devnath on tuotepäällikkö AWS:ssä Amazon Athenassa. Hän on intohimoinen asiakkaiden rakastamien tuotteiden rakentamiseen ja auttaa asiakkaita saamaan arvoa tiedoistaan. Hänen taustansa on toimittanut ratkaisuja useille loppumarkkinoille, kuten rahoitus, vähittäiskauppa, älykkäät rakennukset, kotiautomaatio ja tietoliikennejärjestelmät.
Raj Devnath on tuotepäällikkö AWS:ssä Amazon Athenassa. Hän on intohimoinen asiakkaiden rakastamien tuotteiden rakentamiseen ja auttaa asiakkaita saamaan arvoa tiedoistaan. Hänen taustansa on toimittanut ratkaisuja useille loppumarkkinoille, kuten rahoitus, vähittäiskauppa, älykkäät rakennukset, kotiautomaatio ja tietoliikennejärjestelmät.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- Meistä
- pääsy
- lisätä
- kehittynyt
- vastaan
- lentoasema
- Kaikki
- pitkin
- Myös
- Amazon
- Amazon Athena
- Amazon Web Services
- määrä
- an
- Analytics
- analysoida
- analysointi
- ja
- ilmoitti
- Apache
- Apache Spark
- sovelletaan
- sovellukset
- sovelletaan
- lähestymistavat
- OVAT
- noin
- AS
- liittyvä
- At
- automaattisesti
- Automaatio
- saatavuus
- saatavissa
- AWS
- AWS-liima
- takaisin
- tausta
- pohja
- BE
- ollut
- käyttäytyminen
- Iso
- Big Data
- rakentaa
- Rakentaminen
- rakennettu
- sisäänrakennettu
- liiketoiminta
- mutta
- by
- soittaa
- nimeltään
- CAN
- luettelo
- Aiheuttaa
- solu
- muuttaa
- Muutokset
- Tarkastukset
- puhdas
- koodi
- yhdistää
- yhdistely
- Yhteinen
- Viestintä
- viestintäjärjestelmät
- kompakti
- vertailu
- Konfigurointi
- johdonmukainen
- sisältö
- vastaava
- kustannukset
- laskea
- luoda
- luotu
- luo
- Luominen
- luominen
- Nykyinen
- Asiakkaat
- tiedot
- Data Analytics
- Datajärvi
- tietojenkäsittely
- tietovarastot
- tietokanta
- tietokannat
- Päivämäärä
- määritelty
- tuottaa
- Delta
- osoittaa
- osoittivat
- riippuvuudet
- eri
- suoraan
- keskusteltiin
- do
- dokumentointi
- ei
- download
- Pudota
- kestävyys
- kukin
- Aikaisemmin
- muokkaus
- tehokas
- vaivaa
- Työllisiä
- mahdollistaa
- loppu
- varmistaa
- Koko
- ympäristö
- Eetteri (ETH)
- Tapahtumat
- esimerkki
- Käyttää
- laajenee
- uute
- Ominaisuudet
- filee
- Asiakirjat
- rahoittaa
- Löytää
- Etunimi
- Joustavuus
- tarkennus
- seurata
- seurannut
- jälkeen
- varten
- muoto
- perusta
- puitteet
- alkaen
- toiminnallisuus
- general
- saada
- Antaa
- Ryhmä
- Kasvava
- täysikasvuinen
- kahva
- Olla
- ottaa
- he
- otsikot
- auttaa
- auttaa
- hh
- Korkea
- korkeampi
- hänen
- Koti
- Home Automation
- Miten
- Miten
- HTML
- http
- HTTPS
- kuva
- työkoneet
- tuoda
- parantaa
- in
- inkrementaalinen
- asentaa
- integraatio
- kiinnostunut
- liitäntä
- tulee
- eristäminen
- IT
- liittyi
- jpg
- Pitää
- pito
- avaimet
- järvi
- järvet
- suurempi
- leveysaste
- Liidit
- OPPIA
- vähemmän
- Lets
- pitää
- rajoitukset
- linux
- linux säätiö
- Lista
- kuormitus
- sijainti
- sijainnit
- log
- kauemmin
- katso
- näköinen
- rakkaus
- taika-
- hoitaa
- johto
- johtaja
- tapa
- monet
- markkinat
- max
- maksimi
- mennä
- Metadata
- minuuttia
- minimi
- lisää
- moninkertainen
- nimi
- natiivisti
- Navigoida
- Tarve
- tarvitaan
- ei ikinä
- Uusi
- Nro
- huomata
- muistikirja
- kannettavat tietokoneet
- numero
- objekti
- Objektien varastointi
- esineet
- of
- Tarjoukset
- usein
- Vanha
- vanhempi
- on
- ONE
- vain
- OP
- avata
- avoimen lähdekoodin
- toiminta
- Operations
- Optimoida
- Vaihtoehto
- Vaihtoehdot
- or
- tilata
- meidän
- ulostulo
- voittaminen
- oma
- osa
- intohimoinen
- Ohi
- suorittaa
- suorituskyky
- Platon
- Platonin tietotieto
- PlatonData
- Suosittu
- Kirje
- edellytyksiä
- edellinen
- aiemmin
- ensisijainen
- menettelyt
- käsittely
- tuottaa
- Tuotteet
- tuotepäällikkö
- Tuotteemme
- ominaisuudet
- Python
- kyselyt
- Hinnat
- raaka
- Lue
- Lukeminen
- suositeltu
- kirjataan
- asiakirjat
- vähentää
- katso
- viitattu
- luotettava
- poistaa
- Poistaa
- poistamalla
- korvata
- tarvitaan
- johtua
- Saatu ja
- vähittäiskauppa
- säilyttäminen
- luja
- ajaa
- juoksu
- sama
- skaalautuva
- Asteikko
- Seattle
- Toinen
- Osa
- nähdä
- valita
- valitsemalla
- erillinen
- palvelu
- Palvelut
- Istunto
- setti
- shouldnt
- näyttää
- esitetty
- Näytä
- merkittävä
- Yksinkertainen
- yksinkertaistetaan
- yksinkertaistaa
- koska
- Koko
- hieman eri
- SLP
- pieni
- pienempiä
- fiksu
- Kuva
- So
- Ratkaisumme
- lähde
- Tila
- Kipinä
- erityinen
- erityinen
- erityisesti
- määritelty
- nopeus
- nopeudet
- käytetty
- SQL
- Alkaa
- Lausunto
- lausuntoja
- asema
- Vaihe
- Askeleet
- Yhä
- Levytila
- verkkokaupasta
- tallennettu
- Strategia
- jono
- niin
- Tuetut
- järjestelmä
- järjestelmät
- taulukko
- Tacoma
- kuin
- että
- -
- heidän
- Niitä
- sitten
- Nämä
- tätä
- kynnys
- Kautta
- aika
- aikamatka
- aikaleima
- että
- Seuranta
- kaupallisen
- Liiketoimet
- matkustaa
- tyyppi
- verraton
- Päivitykset
- päivitetty
- Päivitykset
- us
- Käyttö
- käyttää
- käytetty
- käyttämällä
- tyhjiö
- arvo
- versio
- versiot
- haluta
- oli
- tavalla
- we
- verkko
- verkkopalvelut
- olivat
- kun
- joka
- vaikka
- tulee
- with
- ilman
- Referenssit
- kirjoittaa
- vuosi
- te
- Sinun
- zephyrnet