Kuva tekijältä
Sukeltaessasi tietotieteen ja koneoppimisen maailmaan, yksi kohtaamistasi perustaidoista on datan lukemisen taito. Jos sinulla on jo kokemusta siitä, olet todennäköisesti perehtynyt JSON:iin (JavaScript Object Notation) – suosittu muoto sekä tietojen tallentamiseen että vaihtoon.
Ajattele, kuinka NoSQL-tietokannat, kuten MongoDB, rakastavat tietojen tallentamista JSONiin tai kuinka REST-sovellusliittymät reagoivat usein samassa muodossa.
Vaikka JSON sopii täydellisesti varastointiin ja vaihtoon, se ei kuitenkaan ole aivan valmis syvälliseen analyysiin raakamuodossaan. Tässä muutamme sen joksikin analyyttisemmäksi - taulukkomuotoiseksi.
Olitpa siis tekemisissä yksittäisen JSON-objektin tai niiden ihastuttavan joukon kanssa, Pythonin termein käsittelet pääasiassa sanelua tai saneluluetteloa.
Tutkitaan yhdessä, miten tämä muutos etenee, tehden tietomme valmiiksi analysoitavaksi ????
Tänään selitän taikakomennon, jonka avulla voimme helposti jäsentää minkä tahansa JSON-tiedoston taulukkomuotoon sekunneissa.
Ja se on… pd.json_normalize()
Katsotaanpa, kuinka se toimii erityyppisten JSON-tiedostojen kanssa.
Ensimmäinen JSON-tyyppi, jonka kanssa voimme työskennellä, ovat yksitasoiset JSON-tiedostot, joissa on muutamia avaimia ja arvoja. Määrittelemme ensimmäiset yksinkertaiset JSON-tiedostomme seuraavasti:
Kirjoittajan koodi
Joten simuloidaan tarvetta työskennellä näiden JSON-tiedostojen kanssa. Tiedämme kaikki, että heidän JSON-muodossaan ei ole paljon tekemistä. Meidän on muutettava nämä JSON-tiedostot johonkin luettavaan ja muokattavaan muotoon… mikä tarkoittaa Pandas DataFrame -kehyksiä!
1.1 Yksinkertaisten JSON-rakenteiden käsittely
Ensin meidän on tuotava pandaskirjasto ja sitten voimme käyttää komentoa pd.json_normalize() seuraavasti:
import pandas as pd
pd.json_normalize(json_string)
Kun käytät tätä komentoa JSON-tiedostoon yhdellä tietueella, saamme yksinkertaisimman taulukon. Kuitenkin, kun tietomme ovat hieman monimutkaisempia ja sisältävät luettelon JSON-tiedostoista, voimme silti käyttää samaa komentoa ilman muita komplikaatioita ja tulos vastaa taulukkoa, jossa on useita tietueita.

Kuva tekijältä
Helppoa… eikö?
Seuraava luonnollinen kysymys on, mitä tapahtuu, kun osa arvoista puuttuu.
1.2 Nolla-arvojen käsittely
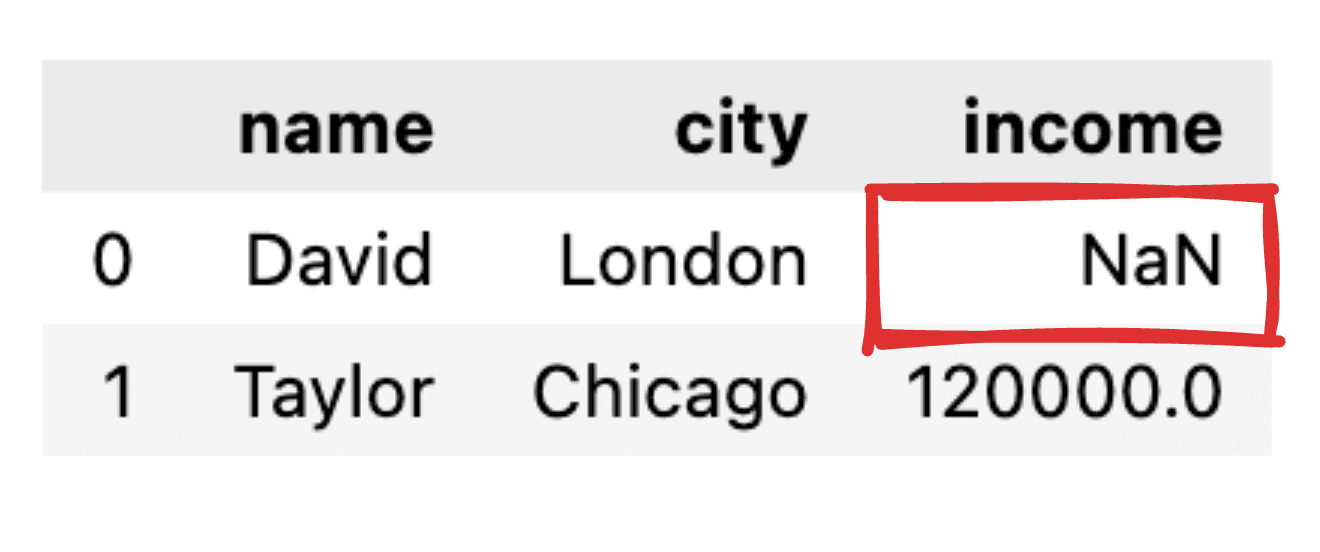
Kuvittele, että joitain arvoja ei ilmoiteta, kuten esimerkiksi Davidin tulotietue puuttuu. Kun muunnamme JSON:n yksinkertaiseksi panda-tietokehykseksi, vastaava arvo näkyy nimellä NaN.
Kuva tekijältä
Entä jos haluan vain osan pelloista?
1.3 Valitse vain kiinnostavat sarakkeet
Jos haluamme vain muuntaa tietyt kentät taulukkomuotoiseksi pandas DataFrame -kehykseksi, json_normalize()-komento ei salli meidän valita, mitä kenttiä muunnetaan.
Siksi JSON:lle tulisi suorittaa pieni esikäsittely, jossa suodatamme vain kiinnostavat sarakkeet.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Joten siirrytään kehittyneempään JSON-rakenteeseen.
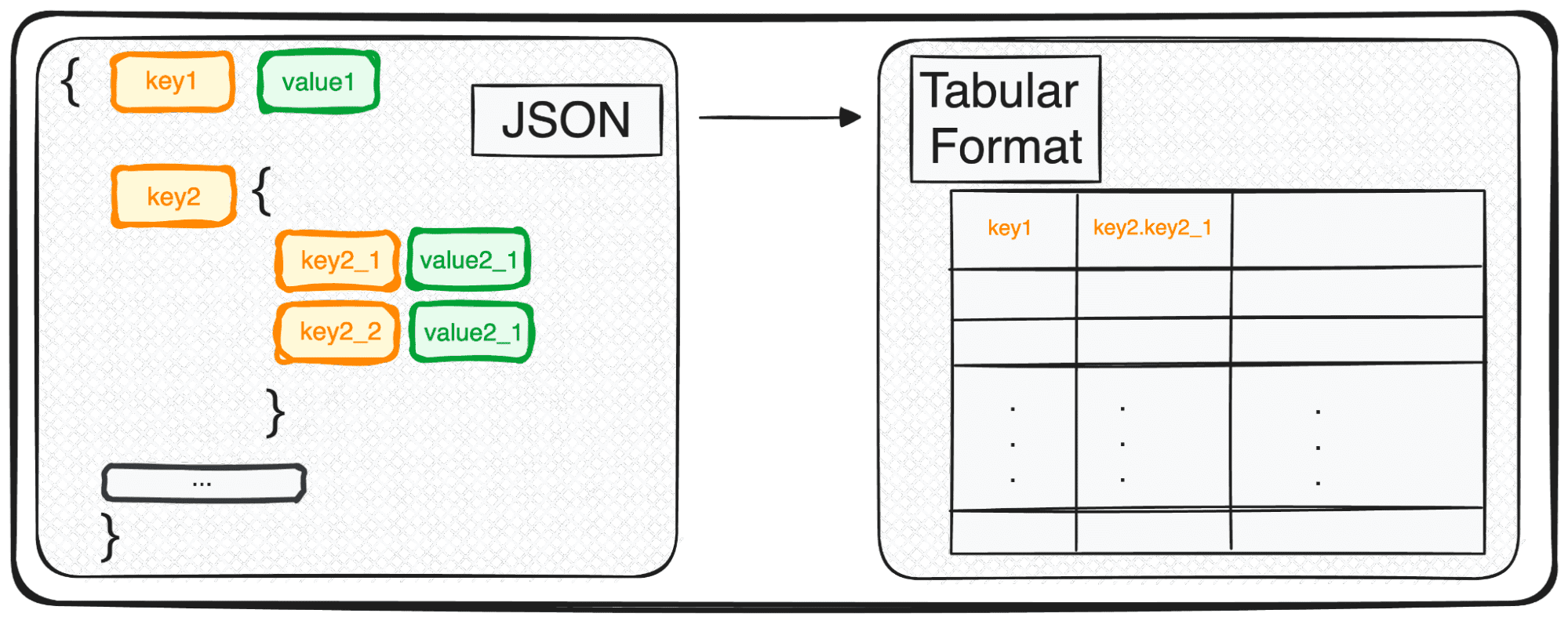
Kun käsittelemme monitasoisia JSON-tiedostoja, huomaamme, että sisäkkäiset JSON-tiedostot ovat eri tasoilla. Toimenpide on sama kuin aiemmin, mutta tässä tapauksessa voimme valita kuinka monta tasoa haluamme muuttaa. Oletusarvon mukaan komento laajentaa aina kaikki tasot ja luo uusia sarakkeita, jotka sisältävät kaikkien sisäkkäisten tasojen ketjutetut nimet.
Joten jos normalisoimme seuraavat JSONit.
Kirjoittajan koodi
Kenttätaitojen alle saamme seuraavan taulukon, jossa on 3 saraketta:
- taidot.python
- taidot.SQL
- taidot.GCP
ja 4 saraketta kenttäroolien alla
- roolit.projektipäällikkö
- roolit.data-insinööri
- roolit.tietotieteilijä
- roolit.data-analyytikko

Kuva tekijältä
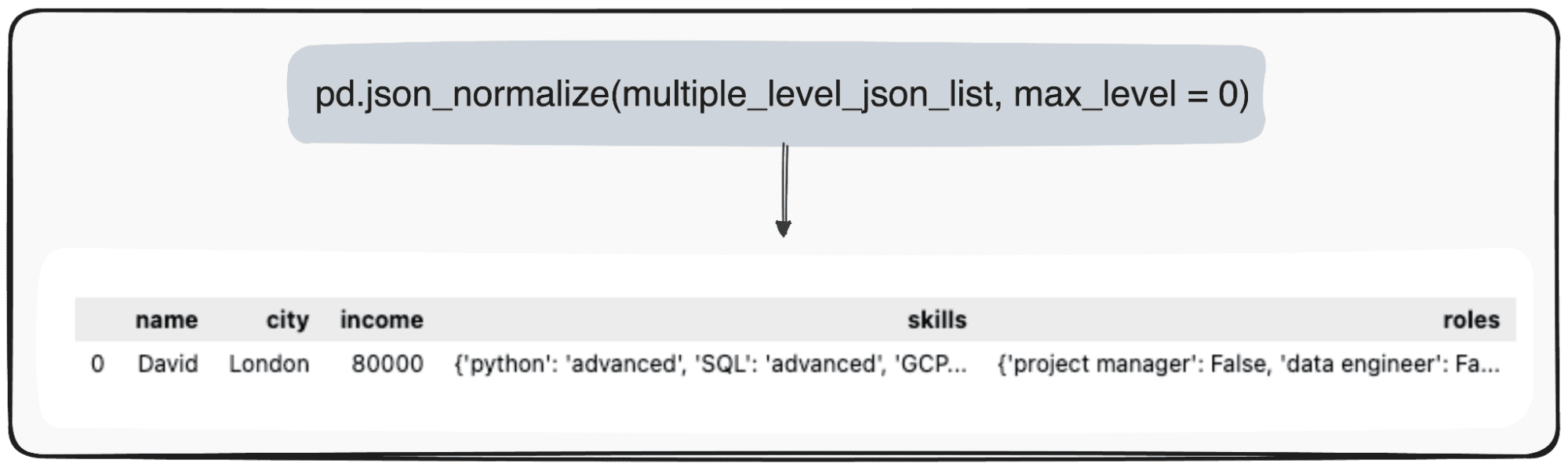
Kuvittele kuitenkin, että haluamme vain muuttaa huipputasoamme. Voimme tehdä sen määrittämällä parametrin max_level arvoksi 0 (max_level, jota haluamme laajentaa).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Odottavat arvot säilytetään JSONissa pandas DataFrame -kehyksessä.
Kuva tekijältä
Viimeinen tapaus, jonka voimme löytää, on sisäkkäinen luettelo JSON-kentässä. Joten määritämme ensin käytettävät JSON-tiedostomme.
Kirjoittajan koodi
Voimme hallita näitä tietoja tehokkaasti käyttämällä Pandasia Pythonissa. Funktio pd.json_normalize() on erityisen hyödyllinen tässä yhteydessä. Se voi litistää JSON-tiedot, mukaan lukien sisäkkäisen luettelon, jäsenneltyyn muotoon, joka sopii analysointiin. Kun tätä toimintoa käytetään JSON-tietoihimme, se tuottaa normalisoidun taulukon, joka sisältää sisäkkäisen luettelon osana kenttiään.
Lisäksi Pandas tarjoaa mahdollisuuden kehittää tätä prosessia edelleen. Käyttämällä parametria record_path parametrissa pd.json_normalize(), voimme ohjata funktion erityisesti normalisoimaan sisäkkäisen luettelon.
Tämä toiminto johtaa siihen, että luettelon sisällölle on varattu taulukko. Oletuksena tämä prosessi avaa vain luettelon elementit. Voit kuitenkin rikastaa tätä taulukkoa lisäkontekstilla, kuten säilyttää kullekin tietueelle liittyvän tunnuksen, käyttämällä meta-parametria.

Kuva tekijältä
Yhteenvetona voidaan todeta, että JSON-tietojen muuntaminen CSV-tiedostoiksi Pythonin Pandas-kirjastolla on helppoa ja tehokasta.
JSON on edelleen yleisin muoto nykyaikaisessa tietojen tallentamisessa ja vaihdossa, erityisesti NoSQL-tietokannassa ja REST API:issa. Se kuitenkin asettaa tärkeitä analyyttisiä haasteita käsiteltäessä dataa sen raakamuodossa.
Pandasin pd.json_normalize()-funktion keskeinen rooli tulee esiin erinomaisena tapana käsitellä tällaisia muotoja ja muuntaa tietomme pandan DataFrame-kehykseksi.
Toivon, että tämä opas oli hyödyllinen, ja kun seuraavan kerran käsittelet JSONia, voit tehdä sen tehokkaammin.
Voit tarkistaa vastaavan Jupyter-muistikirjan GitHub-repon jälkeen.
Josep Ferrer on analytiikkainsinööri Barcelonasta. Hän valmistui fysiikan insinööriksi ja työskentelee tällä hetkellä tietotieteen alalla, jota sovelletaan ihmisen liikkuvuuteen. Hän on osa-aikainen sisällöntuottaja, joka keskittyy tietotieteeseen ja teknologiaan. Voit ottaa häneen yhteyttä LinkedIn, Twitter or Keskikokoinen.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :On
- :ei
- :missä
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Meistä
- Toiminta
- lisä-
- kehittynyt
- Kaikki
- sallia
- mahdollistaa
- jo
- aina
- an
- analyysi
- analyytikko
- Analyyttinen
- Analytics
- ja
- Kaikki
- API
- näyttää
- sovellettu
- Hakeminen
- OVAT
- Ryhmä
- Art
- AS
- liittyvä
- Barcelona
- perustiedot
- BE
- ennen
- Bitti
- sekä
- mutta
- by
- CAN
- valmiudet
- tapaus
- haasteet
- tarkastaa
- Valita
- Kaupunki
- Pylväät
- Yhteinen
- monimutkainen
- komplikaatioita
- ottaa yhteyttä
- pitoisuus
- sisältö
- tausta
- muuntaa
- muuntaminen
- vastata
- vastaava
- luoja
- Tällä hetkellä
- tiedot
- data-analyytikko
- tietotekniikka
- tietojenkäsittely
- tietojen tutkija
- tietovarasto
- tietokannat
- David
- tekemisissä
- omistautunut
- oletusarvo
- määritellä
- määrittelemällä
- ihana
- DICT
- eri
- ohjata
- do
- ei
- kukin
- helposti
- helppo
- Tehokas
- tehokkaasti
- elementtejä
- syntyy
- kohdata
- insinööri
- Tekniikka
- rikastuttaa
- olennaisesti
- Vaihdetaan
- vaihtamalla
- yksinomaan
- Laajentaa
- experience
- selitetään
- tutkia
- tuttu
- harvat
- ala
- Fields
- Asiakirjat
- suodattaa
- Löytää
- Etunimi
- keskityttiin
- jälkeen
- seuraa
- varten
- muoto
- muoto
- ystävällinen
- alkaen
- toiminto
- perus-
- edelleen
- GCP
- tuottaa
- saada
- GitHub
- Go
- suuri
- ohjaavat
- kahva
- Käsittely
- tapahtuu
- Olla
- ottaa
- he
- häntä
- toivoa
- Miten
- Kuitenkin
- HTTPS
- ihmisen
- i
- Minä
- ID
- if
- kuvitella
- tuoda
- tärkeä
- in
- perusteellinen
- sisältää
- Mukaan lukien
- Tulo
- sisältää
- tietoa
- esimerkki
- korko
- tulee
- ISN
- IT
- SEN
- JavaScript
- json
- Jupyter Notebook
- vain
- KDnuggets
- avain
- avaimet
- Tietää
- Sukunimi
- oppiminen
- Taso
- tasot
- Kirjasto
- pitää
- Lista
- vähän
- ll
- rakkaus
- kone
- koneoppiminen
- taika-
- ylläpidetään
- Tekeminen
- hoitaa
- johtaja
- monet
- välineet
- Meta
- puuttuva
- liikkuvuus
- Moderni
- MongoDB
- lisää
- eniten
- liikkua
- paljon
- moninkertainen
- nimi
- Luonnollinen
- Tarve
- sisäkkäisiä
- Uusi
- seuraava
- Nro
- etenkin
- muistikirja
- objekti
- saada
- of
- Tarjoukset
- usein
- on
- ONE
- vain
- or
- meidän
- itse
- ulostulo
- pandas
- parametri
- osa
- erityisesti
- odotettaessa
- täydellinen
- suoritettu
- Fysiikka
- keskeinen
- Platon
- Platonin tietotieto
- PlatonData
- Suosittu
- lahjat
- todennäköisesti
- menettelyt
- prosessi
- tuottaa
- projekti
- Python
- kysymys
- melko
- raaka
- RE
- Lukeminen
- valmis
- ennätys
- asiakirjat
- tarkentaa
- Vastata
- REST
- tulokset
- säilyttäen
- oikein
- Rooli
- s
- sama
- tiede
- Tiede ja teknologia
- Tiedemies
- sekuntia
- nähdä
- valitsemalla
- shouldnt
- Yksinkertainen
- simuloida
- single
- taitoja
- pieni
- So
- jonkin verran
- jotain
- erityinen
- erityisesti
- SQL
- Yhä
- Levytila
- verkkokaupasta
- rakenne
- jäsennelty
- niin
- sopiva
- YHTEENVETO
- T
- taulukko
- Elektroniikka
- ehdot
- että
- -
- maailma
- heidän
- Niitä
- sitten
- Nämä
- tätä
- ne
- aika
- että
- yhdessä
- ylin
- Muuttaa
- Muutos
- muuttamassa
- tyyppi
- tyypit
- varten
- us
- käyttää
- hyödyllinen
- käyttämällä
- Hyödyntämällä
- arvo
- arvot
- haluta
- oli
- Tapa..
- we
- Mitä
- kun
- onko
- joka
- vaikka
- tulee
- with
- sisällä
- Referenssit
- työskentely
- toimii
- maailman-
- olisi
- te
- zephyrnet