Organisaatiot kaikkialla maailmassa – sekä voittoa tavoittelevat että voittoa tavoittelemattomat – pyrkivät hyödyntämään data-analytiikkaa parantaakseen liiketoiminnan suorituskykyä. Havainnot osoitteesta a McKinseyn kysely osoittavat, että datalähtöiset organisaatiot hankkivat asiakkaita 23 kertaa todennäköisemmin, säilyttävät kuusi kertaa todennäköisemmin asiakkaita ja 19 kertaa kannattavampia [1]. MIT:n tutkimus havaitsi, että digitaalisesti kypsät yritykset ovat 26 prosenttia kannattavampia kuin muut [2]. Mutta monet yritykset, vaikka ovat runsaasti dataa, kamppailevat data-analytiikan käyttöönotossa, koska liiketoiminnan tarpeet, käytettävissä olevat ominaisuudet ja resurssit ovat ristiriidassa prioriteettien kanssa. Gartnerin tutkimus havaitsi, että yli 85 % data- ja analytiikkaprojekteista epäonnistuu [3] ja a yhteinen raportti IBM ja Carnegie Melon osoittavat, että 90 prosenttia organisaation tiedoista ei koskaan käytetä menestyksekkäästi mihinkään strategiseen tarkoitukseen [4].
Tässä taustassa esittelemme "data analytics fabric (DAF)" -konseptin ekosysteeminä tai rakenteena, joka mahdollistaa data-analytiikan toiminnan tehokkaasti perustuen (a) liiketoiminnan tarpeisiin tai tavoitteisiin, (b) käytettävissä oleviin ominaisuuksiin, kuten ihmisiin/taidot. , prosessit, kulttuuri, teknologiat, oivallukset, päätöksentekokompetenssit ja paljon muuta, ja (c) resurssit (eli komponentit, joita yritys tarvitsee liiketoiminnassaan).
Ensisijainen tavoitteemme ottamalla käyttöön data-analytiikkakudoksen on vastata tähän peruskysymykseen: "Mitä tarvitaan päätöksentekojärjestelmän tehokkaaseen rakentamiseen data Science algoritmeja liiketoiminnan suorituskyvyn mittaamiseen ja parantamiseen?" Data-analytiikkarakenne ja sen viisi keskeistä ilmentymää esitetään ja käsitellään alla.
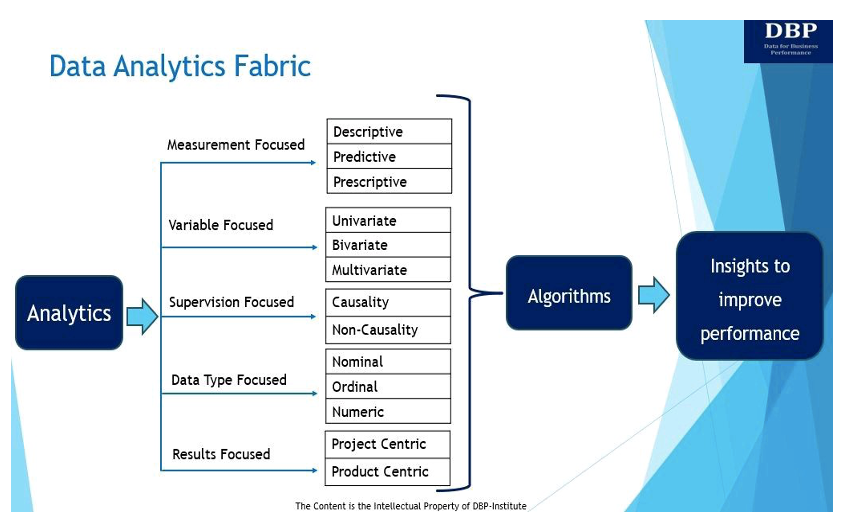
1. Mittaukseen keskittyvä
Analytiikan ytimessä on datan käyttäminen oivallusten saamiseksi mittaamaan ja parantamaan liiketoiminnan suorituskykyä [5]. On olemassa kolme päätyyppiä analytiikkaa liiketoiminnan suorituskyvyn mittaamiseksi ja parantamiseksi:
- Kuvaava analytiikka kysyy: "Mitä tapahtui?" Kuvaavaa analytiikkaa käytetään historiallisten tietojen analysointiin kuvioiden, trendien ja suhteiden tunnistamiseksi käyttämällä tutkivia, assosiatiivisia ja päätteleviä data-analyysitekniikoita. Tutkivat data-analyysitekniikat analysoivat ja tekevät yhteenvedon tietokokonaisuuksista. Assosiatiivinen kuvaava analyysi selittää muuttujien välisen suhteen. Päättelevää kuvaavaa data-analyysiä käytetään päättämään tai päättämään trendejä suuremmasta populaatiosta otostietojoukon perusteella.
- Ennustava analyysi katsoo vastausta kysymykseen "Mitä tapahtuu?" Pohjimmiltaan ennakoiva analytiikka on prosessi, jossa dataa käytetään ennustamaan tulevaisuuden trendejä ja tapahtumia. Ennakoiva analyysi voidaan suorittaa manuaalisesti (tunnetaan yleisesti analyytikkovetoisena ennustavana analytiikkana) tai käyttämällä koneoppimisalgoritmit (tunnetaan myös nimellä dataohjattu ennakoiva analytiikka). Joka tapauksessa historiallisia tietoja käytetään tulevaisuuden ennusteiden tekemiseen.
- Määräysanalytiikka auttaa vastaamaan kysymykseen "Kuinka voimme saada sen tapahtumaan?" Periaatteessa preskriptiivinen analytiikka suosittelee parasta toimintatapaa eteenpäin siirtymiseen optimointi- ja simulointitekniikoiden avulla. Yleensä ennustava analyysi ja ohjeellinen analytiikka menevät yhteen, koska ennustava analytiikka auttaa löytämään mahdollisia tuloksia, kun taas preskriptiivinen analytiikka tarkastelee näitä tuloksia ja löytää lisää vaihtoehtoja.
2. Muuttuva-keskittynyt
Tietoja voidaan myös analysoida käytettävissä olevien muuttujien lukumäärän perusteella. Tässä suhteessa muuttujien lukumäärän perusteella data-analytiikkatekniikat voivat olla yksimuuttujia, kaksimuuttujia tai monimuuttujia.
- Yksimuuttuja-analyysi: Yksimuuttuja-analyysi sisältää yksittäisessä muuttujassa esiintyvän kuvion analysoinnin käyttämällä keskeisyyden (keskiarvo, mediaani, tila ja niin edelleen) ja vaihtelun (keskihajonta, keskivirhe, varianssi ja niin edelleen) mittareita.
- Kaksimuuttuja-analyysi: On olemassa kaksi muuttujaa, joissa analyysi liittyy syyn ja kahden muuttujan väliseen suhteeseen. Nämä kaksi muuttujaa voivat olla toisistaan riippuvaisia tai riippumattomia. Korrelaatiotekniikka on eniten käytetty kaksimuuttujaanalyysitekniikka.
- Monimuuttuja-analyysi: Tätä tekniikkaa käytetään useamman kuin kahden muuttujan analysointiin. Monimuuttuja-asetuksissa toimimme tyypillisesti ennustavan analytiikan areenalla ja useimpia tunnetuista koneoppimisalgoritmeista (ML) kuten lineaarisesta regressiosta, logistisesta regressiosta, regressiopuusta, tukivektorikoneista ja hermoverkoista sovelletaan tyypillisesti monimuuttujaan. asetusta.
3. Valvontakeskeinen
Kolmannen tyyppinen data-analytiikan kudos käsittelee syötetietojen tai riippumattoman muuttujan datan koulutusta, joka on nimetty tietylle lähdölle (eli riippuvaiselle muuttujalle). Pohjimmiltaan riippumaton muuttuja on se, jota kokeilija ohjaa. Riippuva muuttuja on muuttuja, joka muuttuu riippumattoman muuttujan vaikutuksesta. Valvontakeskeinen DAF voi olla toinen kahdesta tyypistä.
- Syy-yhteys: Merkitty data, joko automaattisesti tai manuaalisesti luotu, on välttämätöntä ohjatun oppimisen kannalta. Merkitty data mahdollistaa riippuvan muuttujan selkeän määrittelyn, ja sitten ennustavan analytiikan algoritmin tehtävänä on rakentaa AI/ML-työkalu, joka rakentaisi suhteen nimiön (riippuvaisen muuttujan) ja riippumattomien muuttujien joukon välille. Koska meillä on selkeä rajaus riippuvaisen muuttujan käsitteen ja riippumattomien muuttujien joukon välillä, sallimme itsemme ottaa käyttöön termin "kausaliteetti" selittääksemme suhteen parhaiten.
- Ei-kausaliteetti: Kun merkitsemme ulottuvuutemme "valvontakeskeistä", tarkoitamme myös "valvonnan puuttumista", ja se tuo ei-kausaaliset mallit keskusteluun. Ei-syy-mallit ansaitsevat maininnan, koska ne eivät vaadi merkittyjä tietoja. Perustekniikka tässä on klusterointi, ja suosituimmat menetelmät ovat k-Means ja Hierarchical Clustering.
4. Tietotyyppikeskeinen
Tämä data-analytiikkakudoksen ulottuvuus tai ilmentymä keskittyy kolmeen erityyppiseen datamuuttujaan, jotka liittyvät sekä riippumattomiin että riippuvaisiin muuttujiin, joita käytetään data-analytiikkatekniikoissa oivallusten johtamiseen.
- Nimellistiedot käytetään tietojen merkitsemiseen tai luokitteluun. Se ei sisällä numeerista arvoa, joten tilastolliset laskelmat eivät ole mahdollisia nimellistiedoilla. Esimerkkejä nimellistiedoista ovat sukupuoli, tuotekuvaus, asiakkaan osoite ja vastaavat.
- Järjestystiedot tai järjestystiedot on arvojen järjestys, mutta niiden välisiä eroja ei oikeastaan tunneta. Yleisiä esimerkkejä tästä ovat yritysten luokitus markkina-arvon, myyjän maksuehtojen, asiakastyytyväisyyspisteiden, toimitusprioriteettien ja niin edelleen perusteella.
- Numeerinen data ei vaadi esittelyä, ja sen arvo on numeerinen. Nämä muuttujat ovat perustietotyyppejä, joita voidaan käyttää kaikentyyppisten algoritmien mallintamiseen.
5. Tuloksiin keskittyvä
Tämän tyyppisessä data-analytiikkakankaassa tarkastellaan tapoja, joilla analytiikan avulla saatujen oivallusten avulla voidaan tuottaa liiketoiminta-arvoa. Analytiikan avulla liiketoiminnan arvoa voidaan ohjata kahdella tavalla, ja ne ovat tuotteiden tai projektien kautta. Vaikka tuotteiden on ehkä puututtava käyttökokemukseen ja ohjelmistosuunnitteluun liittyviin lisähaaroihin, mallin johtamiseen tehtävä mallinnus on samanlainen sekä projektissa että tuotteessa.
- A data-analytiikkatuote on uudelleenkäytettävä tietoresurssi, joka palvelee liiketoiminnan pitkän aikavälin tarpeita. Se kerää tietoja asiaankuuluvista tietolähteistä, varmistaa tiedon laadun, käsittelee sen ja tuo sen kaikkien sitä tarvitsevien saataville. Tuotteet on tyypillisesti suunniteltu henkilöille, ja niissä on useita elinkaarivaiheita tai iteraatioita, joissa tuotteen arvo toteutuu.
- A data-analytiikkaprojekti on suunniteltu vastaamaan tiettyyn tai ainutlaatuiseen liiketoiminnan tarpeeseen ja sillä on määritelty tai kapea käyttäjäkunta tai tarkoitus. Pohjimmiltaan projekti on väliaikainen yritys, jonka tarkoituksena on toimittaa ratkaisu määritellylle laajuudelle, budjetin rajoissa ja ajallaan.
Maailmantalous muuttuu dramaattisesti tulevina vuosina, kun organisaatiot käyttävät yhä enemmän dataa ja analytiikkaa saadakseen näkemyksiä ja tehdäkseen päätöksiä liiketoiminnan suorituskyvyn mittaamiseksi ja parantamiseksi. McKinsey havaitsi, että näkemykseen perustuvat yritykset raportoivat EBITDA:n (tulos ennen korkoja, veroja ja poistoja) kasvavan jopa 25 % [5]. Monet organisaatiot eivät kuitenkaan onnistu hyödyntämään dataa ja analytiikkaa liiketoiminnan tulosten parantamiseksi. Mutta ei ole olemassa yhtä vakiotapaa tai lähestymistapaa data-analytiikan toimittamiseen. Tietojen analysointiratkaisujen käyttöönotto tai käyttöönotto riippuu liiketoiminnan tavoitteista, kyvyistä ja resursseista. DAF ja sen viisi tässä käsiteltyä ilmentymää voivat mahdollistaa analytiikan tehokkaan käyttöönoton liiketoiminnan tarpeiden, käytettävissä olevien ominaisuuksien ja resurssien perusteella.
Viitteet
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-their-their-peers/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, "Analytics Best Practices", Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- ChartPrime. Nosta kaupankäyntipeliäsi ChartPrimen avulla. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :on
- :On
- :ei
- $ YLÖS
- 1
- 19
- 23
- a
- Meistä
- saatavilla
- hankkia
- Toiminta
- lisä-
- osoite
- AI / ML
- algoritmi
- algoritmit
- Kaikki
- sallia
- mahdollistaa
- Myös
- kuoletus
- an
- analyysi
- Analytics
- analysoida
- analysoidaan
- analysointi
- ja
- vastaus
- Kaikki
- joku
- sovellettu
- lähestymistapa
- OVAT
- areena
- noin
- AS
- etu
- At
- automaattisesti
- saatavissa
- b
- taustakulissi
- pohja
- perustua
- perustiedot
- Pohjimmiltaan
- BE
- koska
- ollut
- ennen
- ovat
- alle
- PARAS
- välillä
- sekä
- Tuo
- talousarvio
- rakentaa
- liiketoiminta
- liiketoiminnan suorituskyky
- mutta
- by
- CAN
- kyvyt
- arvo
- luokittelu
- Aiheuttaa
- Keskeinen asema
- Muutokset
- selvästi
- klustereiden
- kerää
- KOM
- tuleva
- Yhteinen
- yleisesti
- Yritykset
- osat
- käsite
- päättelee
- tehty
- ristiriitaiset
- valvonta
- Ydin
- Korrelaatio
- voisi
- kurssi
- Kulttuuri
- asiakas
- Asiakastyytyväisyys
- Asiakkaat
- tiedot
- tietojen analysointi
- Data Analytics
- tiedon laatu
- tietojoukko
- tietueita
- data-driven
- DATAVERSITEETTI
- Tarjoukset
- Päätöksenteko
- päätökset
- määritellä
- määritelty
- toimittaa
- toimitettu
- toimitus
- riippuvainen
- riippuu
- käyttöön
- käyttöönotto
- arvonalennus
- johdettu
- kuvaus
- ansaita
- suunniteltu
- Huolimatta
- poikkeama
- erot
- eri
- digitaalisesti
- Ulottuvuus
- keskusteltiin
- keskustelu
- selvä
- do
- ei
- tehty
- dramaattisesti
- ajanut
- kaksi
- e
- kukin
- Tulot
- Käyttökate
- talous
- ekosysteemi
- tehokkaasti
- myöskään
- mahdollistaa
- mahdollistaa
- yrittää
- Tekniikka
- varmistaa
- virhe
- olennainen
- Tapahtumat
- Esimerkit
- Käyttää
- experience
- Selittää
- selittää
- Tutkimusaineistoanalyysi
- kangas
- tosiasia
- FAIL
- Löytää
- tulokset
- löydöt
- yritykset
- viisi
- keskittyy
- varten
- Forbes
- Ennuste
- Eteenpäin
- löytyi
- alkaen
- toiminto
- perus-
- tulevaisuutta
- Gartner
- Sukupuoli
- syntyy
- Go
- tavoite
- tapahtua
- tapahtui
- Olla
- auttaa
- siten
- tätä
- historiallinen
- Kuitenkin
- HTTPS
- i
- IBM
- tunnistaa
- toteuttaa
- täytäntöönpano
- parantaa
- parani
- parantaminen
- in
- Lisäykset
- yhä useammin
- itsenäinen
- osoittaa
- panos
- oivalluksia
- tarkoitettu
- korko
- esitellä
- käyttöön
- esittely
- aiheuttaa
- liittyy
- IT
- toistojen
- SEN
- avain
- tunnettu
- Merkki
- merkinnät
- suurempi
- oppiminen
- vipuvaikutuksen
- elinkaari
- pitää
- Todennäköisesti
- pitkän aikavälin
- näköinen
- ulkonäkö
- kone
- koneoppiminen
- Koneet
- tärkein
- tehdä
- TEE
- käsin
- monet
- markkinat
- Markkina-arvo
- asia
- kypsä
- max-width
- Saattaa..
- McKinsey
- tarkoittaa
- mitata
- toimenpiteet
- mainita
- menetelmät
- MIT
- ML
- tila
- malli
- mallintaminen
- mallit
- lisää
- eniten
- Suosituin
- liikkuvat
- moninkertainen
- Tarve
- tarpeet
- verkot
- hermo-
- hermoverkkoihin
- ei ikinä
- Nro
- Voittoa tavoittelematon
- Käsite
- numero
- tavoitteet
- of
- on
- ONE
- käyttää
- optimointi
- Vaihtoehdot
- or
- tilata
- organisaatio
- organisaatioiden
- Muut
- meidän
- itse
- tuloksiin
- ulostulo
- yli
- erityinen
- Kuvio
- kuviot
- maksu
- suorituskyky
- Platon
- Platonin tietotieto
- PlatonData
- Suosittu
- väestö
- mahdollinen
- mahdollinen
- Ennusteet
- ennustavan
- Ennustava analyysi
- Ennakoiva Analytics
- esittää
- ensisijainen
- prioriteetti
- prosessi
- Prosessit
- Tuotteet
- Tuotteemme
- Voitto
- kannattava
- projekti
- hankkeet
- tarkoitus
- laatu
- kysymys
- seurauksia
- sijoittui
- Sijoitus
- tajusi
- ihan oikeesti
- suosittelee
- ottaa huomioon
- regressio
- liittyvä
- yhteys
- Ihmissuhteet
- merkityksellinen
- raportti
- edellyttää
- tarvitaan
- Esittelymateriaalit
- vastaus
- säilyttää
- uudelleen käytettävä
- tyytyväisyys
- laajuus
- tulokset
- palvella
- setti
- Setit
- asetus
- esitetty
- Näytä
- samankaltainen
- simulointi
- single
- SIX
- So
- Tuotteemme
- ohjelmistotuotanto
- ratkaisu
- Ratkaisumme
- lähde
- Lähteet
- vaiheissa
- standardi
- tilastollinen
- Strateginen
- rakenne
- taistelu
- onnistunut
- Onnistuneesti
- niin
- yhteenveto
- valvottu oppiminen
- valvonta
- tuki
- järjestelmä
- Verot
- tekniikat
- Technologies
- tilapäinen
- termi
- ehdot
- kuin
- että
- -
- maailma
- heidän
- sitten
- Siellä.
- Nämä
- ne
- kolmas
- tätä
- ne
- kolmella
- Kautta
- aika
- kertaa
- että
- yhdessä
- työkalu
- koulutus
- Muuttaa
- Puut
- Trendit
- kaksi
- tyyppi
- tyypit
- tyypillisesti
- unique
- käyttää
- käytetty
- käyttäjä
- Käyttäjäkokemus
- käyttämällä
- arvo
- arvot
- muuttuja
- myyjä
- Tapa..
- tavalla
- we
- tunnettu
- kun
- onko
- joka
- vaikka
- KUKA
- tulee
- with
- sisällä
- maailman-
- maailman
- olisi
- vuotta
- zephyrnet











