Kuten käytännössä kaikki asiakkaat, haluat kuluttaa mahdollisimman vähän ja saavuttaa parhaan mahdollisen suorituskyvyn. Tämä tarkoittaa, että sinun on kiinnitettävä huomiota hinta-suorituskykyyn. Kanssa Amazonin punainen siirto, voit ottaa kakkusi ja syödä sen myös! Amazon Redshift tarjoaa jopa 4.9 kertaa pienemmät kustannukset käyttäjää kohti ja jopa 7.9 kertaa paremman hinta-suorituskyvyn kuin muut pilvitietovarastot todellisissa työkuormissa käyttämällä kehittyneitä tekniikoita, kuten samanaikaisuuden skaalaus, joka tukee satoja samanaikaisia käyttäjiä, parannettu merkkijonokoodaus nopeampaan kyselyn suorituskykyyn , ja Amazon Redshift Serverless suorituskyvyn parannuksia. Lue eteenpäin ymmärtääksesi, miksi hinta-suorituskyvyllä on merkitystä ja kuinka Amazon Redshift -hinta-suorituskyky mittaa, kuinka paljon tietyn työkuorman suoritustason saavuttaminen maksaa, eli suorituskyvyn ROI (sijoitetun pääoman tuotto).
Koska hinta-suorituskykylaskennassa otetaan huomioon sekä hinta että suorituskyky, on kaksi tapaa ajatella hinta-suorituskykyä. Ensimmäinen tapa on pitää hinta vakiona: jos sinulla on 1 dollari käytettävää, kuinka paljon suorituskykyä saat tietovarastostasi? Tietokanta, jolla on parempi hinta-suorituskyky, tarjoaa paremman suorituskyvyn jokaista käytettyä dollaria kohden. Siksi, kun hinta pidetään vakiona, kun verrataan kahta saman hintaista tietovarastoa, tietokanta, jolla on parempi hinta-tehokkuus, suorittaa kyselysi nopeammin. Toinen tapa tarkastella hinta-suorituskykyä on pitää suorituskyky vakiona: jos tarvitset työmääräsi valmistuvan 10 minuutissa, mitä se maksaa? Tietokanta, jolla on parempi hinta-suorituskyky, suorittaa työmääräsi 10 minuutissa pienemmällä hinnalla. Siksi, kun suorituskyky pysyy vakiona, kun verrataan kahta tietovarastoa, jotka on mitoitettu tuottamaan saman suorituskyvyn, paremman hinta-suorituskyvyn omaava tietokanta maksaa vähemmän ja säästää rahaa.
Lopuksi toinen tärkeä hinta-suorituskyvyn näkökohta on ennustettavuus. Suunnittelun kannalta on ratkaisevan tärkeää tietää, kuinka paljon tietovarastosi tulee maksamaan tietovaraston käyttäjien määrän kasvaessa. Sen ei pitäisi vain tarjota paras hinta-laatusuhde tänään, vaan myös skaalata ennakoitavasti ja tarjota paras hinta-suorituskyky, kun käyttäjiä ja työkuormia lisätään. Ihanteellisessa tietovarastossa pitäisi olla lineaarinen asteikko-tietovaraston skaalaaminen niin, että se tuottaa kaksinkertaisen kyselyn suorituskyvyn, tulisi ihanteellisesti maksaa kaksi kertaa niin paljon (tai vähemmän).
Tässä viestissä jaamme suorituskykytuloksia havainnollistaaksemme, kuinka Amazon Redshift tarjoaa huomattavasti paremman hinta-suorituskyvyn verrattuna johtaviin vaihtoehtoisiin pilvitietovarastoihin. Tämä tarkoittaa, että jos käytät Amazon Redshiftissä saman summan kuin johonkin näistä muista tietovarastoista, saat paremman suorituskyvyn Amazon Redshiftillä. Vaihtoehtoisesti, jos muutat Redshift-klusterin kokoa samaan suorituskykyyn, näet alhaisemmat kustannukset verrattuna näihin vaihtoehtoihin.
Hinta-suorituskyky todellisiin työkuormiin
Voit käyttää Amazon Redshiftiä tehostamaan hyvin monenlaisia työkuormia, monimutkaisten otteen, muunnos- ja lataus (ETL) -pohjaisten raporttien eräkäsittelystä ja reaaliaikaisesta suoratoistoanalytiikasta alhaisen viiveen liiketoimintatiedon (BI) hallintapaneeleihin, jotka tarve palvella satoja tai jopa tuhansia käyttäjiä samaan aikaan alle sekunnin vasteajoilla ja kaikella siltä väliltä. Yksi tavoista, joilla parannamme jatkuvasti asiakkaidemme hinta-suorituskykyä, on tarkistaa jatkuvasti Redshift-kaluston ohjelmistojen ja laitteistojen suorituskyvyn telemetriaa ja etsiä mahdollisuuksia ja asiakkaiden käyttötapauksia, joissa voimme edelleen parantaa Amazon Redshiftin suorituskykyä.
Joitakin viimeaikaisia esimerkkejä kaluston telemetrian ohjaamista suorituskyvyn optimoinneista ovat:
- Merkkijonokyselyn optimoinnit – Analysoimalla, kuinka Amazon Redshift käsitteli eri tietotyyppejä Redshift-laivastossa, havaitsimme, että pitkäkestoisten kyselyiden optimointi hyödyttäisi merkittävästi asiakkaidemme työtaakkaa. (Keskustamme tästä tarkemmin myöhemmin tässä viestissä.)
- Automatisoidut materialisoidut näkymät – Huomasimme, että Amazon Redshift -asiakkaat suorittavat usein monia kyselyitä, joilla on yhteisiä alikyselymalleja. Esimerkiksi useat eri kyselyt voivat yhdistää samat kolme taulukkoa käyttämällä samaa liitosehtoa. Amazon Redshift pystyy nyt automaattisesti luomaan ja ylläpitämään materialisoituja näkymiä ja sitten läpinäkyvästi uudelleenkirjoittamaan kyselyitä käyttääkseen materialisoituja näkymiä koneoppitun avulla. automatisoitu materialisoitu näkymä autonominen ominaisuus Amazon Redshiftissä. Kun tämä on käytössä, automatisoidut materialisoidut näkymät voivat parantaa läpinäkyvästi kyselyn suorituskykyä toistuvissa kyselyissä ilman käyttäjän toimia. (Huomaa, että automatisoituja näkymiä ei käytetty missään tässä viestissä käsitellyissä vertailutuloksissa).
- Korkean samanaikaisuuden työmäärät – Kasvava käyttötapaus on Amazon Redshiftin käyttö kojelaudan kaltaisten työkuormien palvelemiseen. Näille työkuormille on ominaista halutut kyselyvastausajat, jotka ovat enintään yksinumeroisia sekunteja, ja kymmenet tai sadat samanaikaiset käyttäjät suorittavat kyselyitä samanaikaisesti piikkisillä ja usein arvaamattomilla käyttötavoilla. Prototyyppinen esimerkki tästä on Amazon Redshift -tuettu BI-kojelauta, jonka liikennepiikki on maanantaiaamuisin, kun suuri määrä käyttäjiä aloittaa viikkonsa.
Erityisesti korkean samanaikaisuuden työkuormilla on erittäin laaja sovellettavuus: useimmat tietovaraston työmäärät toimivat samanaikaisesti, eikä ole harvinaista, että sadat tai jopa tuhannet käyttäjät suorittavat kyselyitä Amazon Redshiftissä samanaikaisesti. Amazon Redshift on suunniteltu pitämään kyselyiden vastausajat ennustettavina ja nopeina. Redshift Serverless tekee tämän automaattisesti puolestasi lisäämällä ja poistamalla laskentaa tarpeen mukaan pitääkseen kyselyn vastausajat nopeina ja ennustettavina. Tämä tarkoittaa, että Redshift Serverless -tukipaneeli, joka latautuu nopeasti, kun yksi tai kaksi käyttäjää käyttää sitä, latautuu nopeasti, vaikka monet käyttäjät lataavat sitä samanaikaisesti.
Tämän tyyppisen työmäärän simuloimiseksi käytimme TPC-DS:stä johdettua vertailuarvoa 100 Gt:n tietojoukolla. TPC-DS on alan standardi benchmark, joka sisältää useita tyypillisiä tietovarastokyselyjä. Tässä suhteellisen pienessä 100 Gt:n mittakaavassa tämän vertailuarvon kyselyt suoritetaan Redshift Serverlessissä keskimäärin muutamassa sekunnissa, mikä edustaa sitä, mitä interaktiivista BI-hallintapaneelia lataavat käyttäjät odottavat. Teimme 1–200 samanaikaista testiä tälle vertailuarvolle, simuloiden 1–200 käyttäjää, jotka yrittivät ladata kojelautaa samanaikaisesti. Toistimme testin myös useita suosittuja vaihtoehtoisia pilvitietovarastoja vastaan, jotka tukevat myös automaattista skaalausta (jos olet perehtynyt viestiin Amazon Redshift jatkaa hinta-suorituskykynsä johtajuutta, emme sisällyttäneet kilpailijaa A, koska se ei tue automaattista skaalausta). Mittasimme kyselyn keskimääräisen vasteajan, mikä tarkoittaa, kuinka kauan käyttäjä odottaa kyselynsä päättymistä (tai hallintapaneelin latautumista). Tulokset näkyvät seuraavassa kaaviossa.
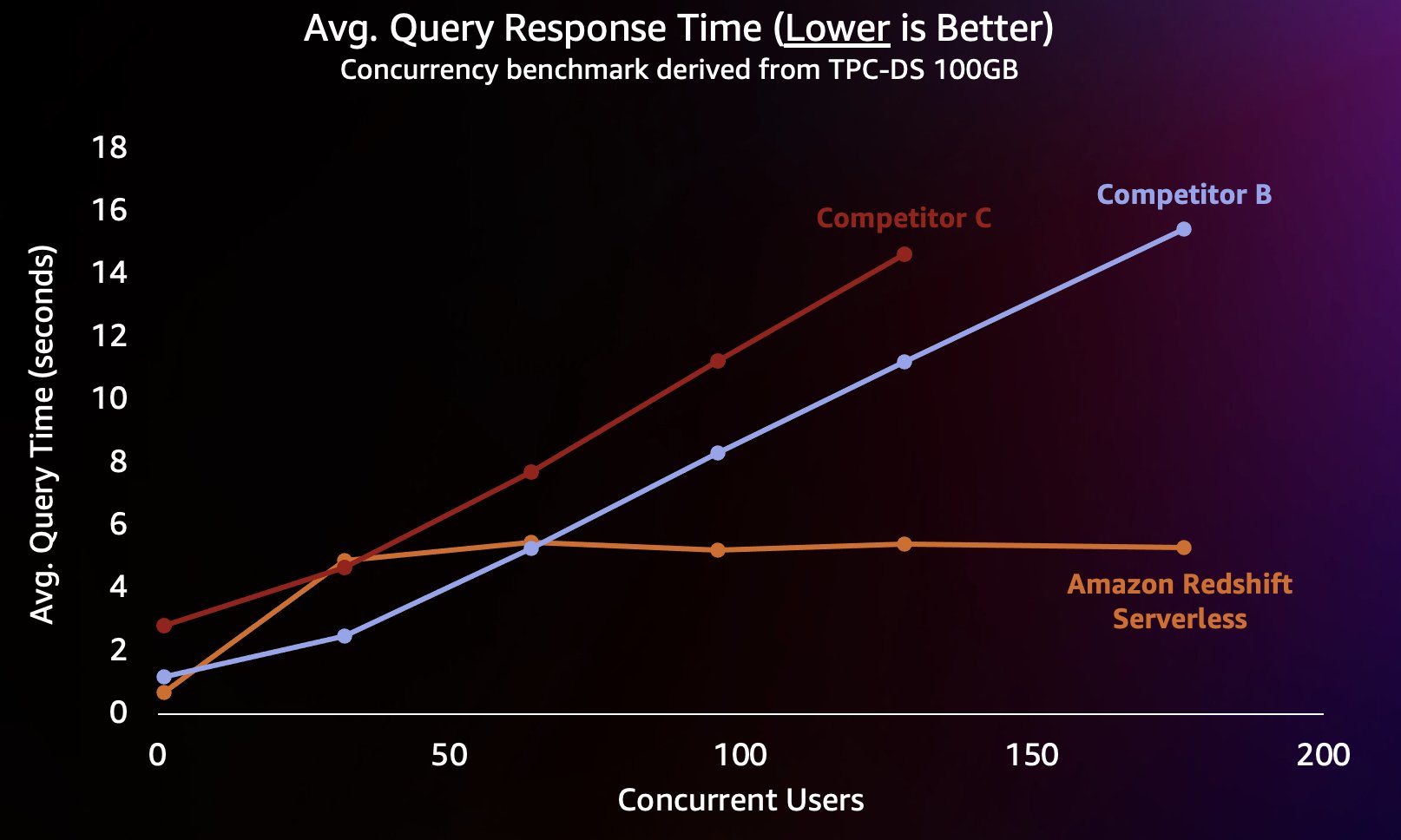
Kilpailija B skaalautuu hyvin, kunnes noin 64 samanaikaista kyselyä, jolloin se ei pysty tarjoamaan lisälaskentaa ja kyselyt alkavat jonottaa, mikä lisää kyselyjen vastausaikoja. Vaikka kilpailija C pystyy skaalautumaan automaattisesti, se skaalautuu alhaisempaan kyselyn suorituskykyyn kuin sekä Amazon Redshift että kilpailija B, eikä se pysty pitämään kyselyn suoritusaikoja alhaisina. Lisäksi se ei tue jonokyselyitä, kun sen laskenta loppuu, mikä estää sitä skaalautumasta yli noin 128 samanaikaisen käyttäjän. Järjestelmä hylkää lisäkyselyjen lähettämisen tämän jälkeen.
Tässä Redshift Serverless pystyy pitämään kyselyn vasteajan suhteellisen yhtenäisenä noin 5 sekunnissa, vaikka sadat käyttäjät suorittavat kyselyjä samanaikaisesti. Kilpailijoiden B ja C keskimääräiset kyselyjen vastausajat kasvavat tasaisesti varastojen kuormituksen kasvaessa, mikä johtaa siihen, että käyttäjien on odotettava pidempään (jopa 16 sekuntia) kyselyiden paluuta, kun tietovarasto on varattu. Tämä tarkoittaa, että jos käyttäjä yrittää päivittää kojelautaa (joka voi lähettää jopa useita samanaikaisia kyselyitä uudelleen ladattuna), Amazon Redshift pystyy pitämään kojelaudan latausajat paljon johdonmukaisempana, vaikka mittaristoa lataavat kymmenet tai sadat muut käyttäjiä samaan aikaan.
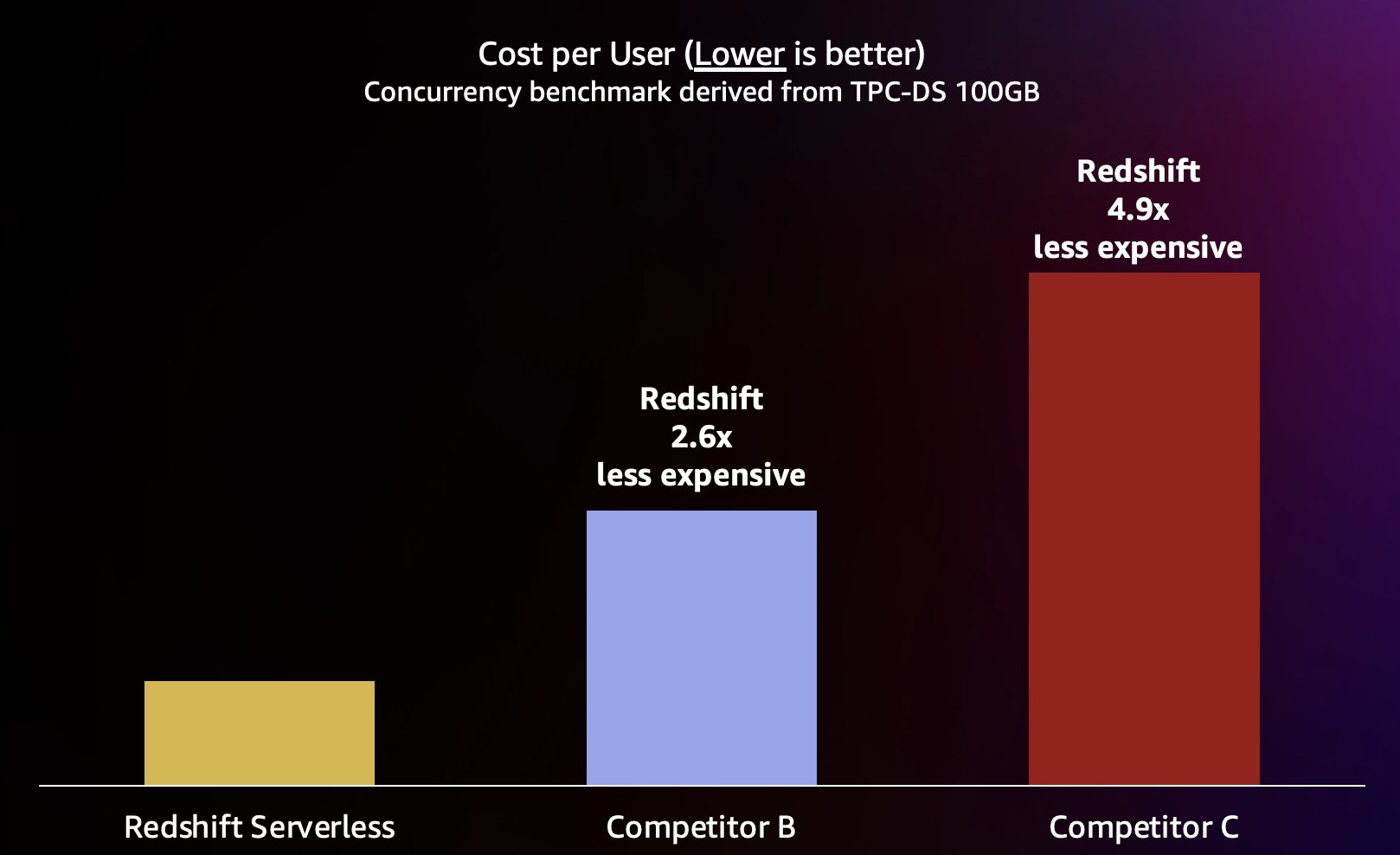
Koska Amazon Redshift pystyy tarjoamaan erittäin korkean kyselyn suorituskyvyn lyhyille kyselyille (kuten kirjoitimme Amazon Redshift jatkaa hinta-suorituskykynsä johtajuutta), se pystyy myös käsittelemään näitä korkeampia samanaikaisuuksia skaalautuessaan tehokkaammin ja siten huomattavasti pienemmillä kustannuksilla. Tämän kvantifioimiseksi tarkastelemme hinta-suorituskykyä käyttämällä julkaistua on-demand-hinnoittelu jokaiselle edellisen testin varastolle, joka näkyy seuraavassa taulukossa. Kannattaa huomioida, että käyttää Varatut esiintymät (RI), erityisesti 3 vuoden RI:t, jotka on ostettu kaikki ennakkomaksuvaihtoehdolla, on alhaisimmat kustannukset Amazon Redshiftin käyttämisestä Provisioned-klustereissa, mikä johtaa parhaaseen suhteelliseen hinta-suorituskykyyn verrattuna on-demand- tai muihin RI-vaihtoehtoihin.

Joten Amazon Redshift ei vain pysty tarjoamaan parempaa suorituskykyä korkeammilla samanaikaisuuksilla, se pystyy tekemään sen huomattavasti pienemmillä kustannuksilla. Jokainen hinta-suorituskykykaavion datapiste vastaa vertailuindeksin suorittamisen kustannuksia määritetyllä samanaikaisesti. Koska hinta-suorituskyky on lineaarinen, voimme jakaa vertailuarvon suorittamisen kustannukset milloin tahansa samanaikaisuudella (samanaikaisten käyttäjien määrä tässä kaaviossa), jotta voimme kertoa meille, kuinka paljon kunkin uuden käyttäjän lisääminen maksaa tälle tietylle vertailuarvolle.
Edelliset tulokset on helppo toistaa. Kaikki vertailussa käytetyt kyselyt ovat saatavilla meidän GitHub-arkisto ja suorituskykyä mitataan käynnistämällä tietovarasto, ottamalla käyttöön samanaikaisuusskaalaus Amazon Redshiftissä (tai vastaava automaattinen skaalausominaisuus muissa varastoissa), lataamalla tiedot pakkauksesta (ei manuaalista viritystä tai tietokantakohtaista asennusta) ja suorittamalla sitten samanaikainen kyselyvirta samanaikaisuuksilla 1–200 32:n välein kussakin tietovarastossa. Sama GitHub-repo viittaa esiluotuun (ja muokkaamattomaan) TPC-DS-dataan Amazonin yksinkertainen tallennuspalvelu (Amazon S3) eri mittakaavassa käyttämällä virallista TPC-DS-tiedontuotantosarjaa.
Raskaiden työkuormien optimointi
Kuten aiemmin mainittiin, Amazon Redshift -tiimi etsii jatkuvasti uusia mahdollisuuksia tarjota asiakkaillemme entistä paremman hinta-laatusuhteen. Yksi äskettäin lanseeraamamme parannus, joka on merkittävästi parantunut suorituskykyä, on optimointi, joka nopeuttaa kyselyiden suorituskykyä merkkijonotietojen yli. Saatat esimerkiksi haluta löytää New Yorkissa sijaitsevista vähittäismyymälöistä kertyneet kokonaistulot kyselyllä kuten SELECT sum(price) FROM sales WHERE city = ‘New York’. Tämä kysely käyttää predikaattia merkkijonotietojen päälle (city = ‘New York’). Kuten voit kuvitella, merkkijonotietojen käsittely on kaikkialla tietovarastosovelluksissa.
Arvioidaksemme kuinka usein asiakkaiden työmäärät käyttävät merkkijonoja, teimme yksityiskohtaisen analyysin merkkijonotietotyyppien käytöstä käyttämällä Amazon Redshiftin hallinnoimien kymmenien tuhansien asiakasklustereiden telemetriaa. Analyysimme osoittaa, että 90 %:ssa klustereista merkkijonosarakkeet muodostavat vähintään 30 % kaikista sarakkeista ja 50 %:ssa klusteista merkkijonosarakkeet muodostavat vähintään 50 % kaikista sarakkeista. Lisäksi suurin osa kaikista kyselyistä suoritetaan Amazon Redshift -pilvitietovarastoalustalla, ja niillä on pääsy vähintään yhteen merkkijonosarakkeeseen. Toinen tärkeä tekijä on, että merkkijonodatalla on hyvin usein matala kardinaliteetti, mikä tarkoittaa, että sarakkeet sisältävät suhteellisen pienen joukon yksilöllisiä arvoja. Esimerkiksi vaikka an orders myyntitietoja edustava taulukko voi sisältää miljardeja rivejä, an order_status taulukon sarake saattaa sisältää vain muutaman ainutlaatuisen arvon näillä miljardeilla riveillä, kuten pending, in processja completed.
Tätä kirjoittaessa useimmat Amazon Redshiftin merkkijonosarakkeet on pakattu LZO or ZSTD algoritmeja. Nämä ovat hyviä yleiskäyttöisiä pakkausalgoritmeja, mutta niitä ei ole suunniteltu hyödyntämään matalan kardinaalisuuden merkkijonotietoja. Erityisesti ne vaativat, että tiedot puretaan ennen käyttöä, ja ne käyttävät vähemmän tehokkaita laitteiston muistin kaistanleveyden käytössä. Matalakardinaliteettitiedoille on olemassa toinen koodaustyyppi, joka voi olla optimaalisempi: BYTEDICT. Tämä koodaus käyttää sanakirjakoodausmenetelmää, jonka avulla tietokantamoottori voi toimia suoraan pakatun tiedon päällä ilman, että sitä tarvitsee purkaa ensin.
Parantaakseen entisestään hinta-suorituskykyä raskaissa työkuormissa Amazon Redshift ottaa nyt käyttöön lisäparannuksia suorituskykyyn, jotka nopeuttavat skannauksia ja predikaattien arviointia BYTEDICT-koodattujen matalakardinaliteettien merkkijonosarakkeisiin verrattuna 5–63 kertaa nopeammin (katso tulokset seuraava osa) verrattuna vaihtoehtoisiin pakkauskoodauksiin, kuten LZO tai ZSTD. Amazon Redshift saavuttaa tämän suorituskyvyn parannuksen vektorisoimalla skannaukset kevyiden, prosessoritehokkaiden, BYTEDICT-koodattujen, matalakardinaliteettisten merkkijonosarakkeiden yli. Nämä merkkijonojen käsittelyn optimoinnit hyödyntävät tehokkaasti nykyaikaisen laitteiston tarjoamaa muistin kaistanleveyttä, mikä mahdollistaa reaaliaikaisen analytiikan merkkijonotietojen yli. Nämä äskettäin käyttöön otetut suorituskykyominaisuudet ovat optimaalisia matalakardinaliteettisarakkeille (jopa muutama sata ainutlaatuista merkkijonoarvoa).
Voit automaattisesti hyötyä tästä uudesta korkean suorituskyvyn merkkijonoparannosta ottamalla käyttöön automaattinen pöydän optimointi Amazon Redshift -tietovarastossasi. Jos taulukoissasi ei ole käytössä automaattista taulukon optimointia, voit saada suosituksia Amazon Redshift -neuvoja Amazon Redshift -konsolissa merkkijonosarakkeen soveltuvuudesta BYTEDICT-koodaukseen. Voit myös määrittää uusia taulukoita, joissa on matalakardinaliteettisarakkeita BYTEDICT-koodauksella. Amazon Redshiftin merkkijonoparannukset ovat nyt saatavilla kaikilla AWS-alueilla Amazon Redshift on saatavilla.
Tulokset
Mittaaksemme merkkijonoparannuksiemme tehokkuutta loimme 10 Tt:n (teratavun) tietojoukon, joka koostui matalan kardinaalisuuden merkkijonodatasta. Loimme kolme versiota tiedoista käyttämällä lyhyitä, keskipitkiä ja pitkiä merkkijonoja, jotka vastaavat Amazon Redshift -laivaston telemetrian merkkijonojen pituuden 25., 50. ja 75. prosenttipistettä. Latasimme nämä tiedot Amazon Redshiftiin kahdesti, koodaamalla ne yhdessä LZO-pakkauksella ja toisessa BYTEDICT-pakkauksella. Lopuksi mittasimme sellaisten vaativien kyselyiden tehokkuuden, jotka palauttavat useita rivejä (90 % taulukosta), keskimääräisen määrän rivejä (50 % taulukosta) ja muutaman rivin (1 % taulukosta) näiden alhaisten tulosten yli. -kardinaliteettimerkkijonotietojoukot. Suorituskyvyn tulokset on koottu seuraavaan taulukkoon.

Kyselyt, joiden predikaatit vastaavat suurta prosenttiosuutta riveistä, saivat 5–30-kertaisia parannuksia uudella vektorisoidulla BYTEDICT-koodauksella LZO:han verrattuna, kun taas kyselyt, joiden predikaatit vastaavat vain pientä prosenttiosuutta riveistä, paranivat tässä sisäisessä vertailussa 10–63-kertaisesti.
Redshift palvelimeton hinta-laatusuhde
Tässä viestissä esitettyjen korkean samanaikaisuuden suorituskykytulosten lisäksi käytimme myös TPC-DS-pohjaista Cloud Data Warehouse -vertailua vertaillaksemme Redshift Serverlessin hinta-suorituskykyä muihin tietovarastoihin käyttämällä suurempaa 3 Tt:n tietojoukkoa. Valitsimme tietovarastot, jotka hinnoiteltiin samalla tavalla, tässä tapauksessa 10 % sisällä 32 dollarista tunnissa käyttämällä julkisesti saatavilla olevaa on-demand -hinnoittelua. Nämä tulokset osoittavat, että Amazon Redshift RA3 -esiintymien tavoin Redshift Serverless tarjoaa paremman hinta-suorituskyvyn verrattuna muihin johtaviin pilvitietovarastoihin. Kuten aina, nämä tulokset voidaan kopioida käyttämällä SQL-skriptejämme GitHub-arkisto.

Kehotamme sinua kokeilemaan Amazon Redshiftiä omallasi todiste käsitteestä työmäärät parhaana tapana nähdä, kuinka Amazon Redshift voi vastata data-analytiikkatarpeesi.
Löydä työkuormituksillesi paras hinta-laatusuhde
Tässä viestissä käytetyt vertailuarvot on johdettu alan standardinmukaisesta TPC-DS-vertailuarvosta, ja niillä on seuraavat ominaisuudet:
- Kaavaa ja tietoja käytetään muuttamattomina TPC-DS:stä.
- Kyselyt luodaan käyttämällä virallista TPC-DS-sarjaa ja kyselyparametreja, jotka on luotu TPC-DS-sarjan oletussatunnaisella siemenellä. TPC-hyväksyttyjä kyselymuunnelmia käytetään varastossa, jos varasto ei tue oletusarvoisen TPC-DS-kyselyn SQL-murretta.
- Testi sisältää 99 TPC-DS SELECT -kyselyä. Se ei sisällä ylläpito- ja suoritusvaiheita.
- Yhdelle 3 Tt:n samanaikaisuustestille ajettiin kolme tehoajoa, ja kullekin tietovarastolle tehdään paras ajo.
- TPC-DS-kyselyiden hinta-suorituskyky lasketaan tuntihinnalla (USD) kertaa vertailuarvon ajoaika tunteina, mikä vastaa vertailuarvon suorittamisen kustannuksia. Viimeisin julkaistu on-demand-hinnoittelu on käytössä kaikissa tietovarastoissa, ei Reserved Instance -hinnoittelussa, kuten aiemmin mainittiin.
Kutsumme tätä Cloud Data Warehouse -vertailuarvoksi, ja voit helposti toistaa edelliset vertailutulokset käyttämällä skriptejä, kyselyitä ja tietoja, jotka ovat saatavilla GitHub-arkisto. Se on johdettu tässä viestissä kuvatuista TPC-DS-vertailuarvoista, eikä se sellaisenaan ole verrattavissa julkaistuihin TPC-DS-tuloksiin, koska testiemme tulokset eivät ole virallisten eritelmien mukaisia.
Yhteenveto
Amazon Redshift on sitoutunut tarjoamaan alan parhaan hinta-laatusuhteen mitä erilaisimmissa työkuormissa. Redshift Serverless skaalautuu lineaarisesti parhaalla (matalimmalla) hinta-suorituskyvyllä ja tukee satoja samanaikaisia käyttäjiä säilyttäen samalla johdonmukaiset vastausajat kyselyihin. Tässä viestissä käsiteltyjen testitulosten perusteella Amazon Redshiftillä on jopa 2.6 kertaa parempi hinta-suorituskyky samalla samanaikaisuustasolla verrattuna lähimpään kilpailijaan (kilpailija B). Kuten aiemmin mainittiin, varattujen ilmentymien käyttäminen 3 vuoden all-upfront -vaihtoehdon kanssa antaa sinulle alhaisimmat kustannukset Amazon Redshiftin käyttämisestä, mikä johtaa vielä parempaan suhteelliseen hinta-suorituskykyyn verrattuna tässä viestissä käyttämiimme on-demand-instanssien hinnoitteluun. Lähestymistapamme jatkuvaan suorituskyvyn parantamiseen sisältää ainutlaatuisen yhdistelmän asiakkaiden pakkomielteitä ymmärtää asiakkaiden käyttötapauksia ja niihin liittyviä skaalautuvuuden pullonkauloja yhdistettynä jatkuvaan kalustotietojen analysointiin tunnistaaksemme mahdollisuudet merkittäviin suorituskyvyn optimointiin.
Jokaisella työkuormalla on ainutlaatuiset ominaisuudet, joten jos olet vasta aloittamassa, a todiste käsitteestä on paras tapa ymmärtää, kuinka Amazon Redshift voi alentaa kustannuksia ja parantaa suorituskykyä. Kun suoritat omaa konseptitodistusta, on tärkeää keskittyä oikeisiin mittareihin – kyselyn suorituskykyyn (kyselyiden määrä tunnissa), vasteaikaan ja hinta-suorituskykyyn. Voit tehdä tietopohjaisen päätöksen suorittamalla konseptin todisteen itse tai avustuksella AWS:ltä tai a järjestelmäintegraatio- ja konsultointikumppani.
Pysy ajan tasalla Amazon Redshiftin uusimmasta kehityksestä seuraamalla Mitä uutta Amazon Redshiftissä ruokkia.
Tietoja kirjoittajista
 Stefan Gromoll on vanhempi suorituskykyinsinööri Amazon Redshift -tiimissä, jossa hän vastaa Redshiftin suorituskyvyn mittaamisesta ja parantamisesta. Vapaa-ajallaan hän nauttii ruoanlaitosta, leikkimisestä kolmen poikansa kanssa ja polttopuiden pilkkomisesta.
Stefan Gromoll on vanhempi suorituskykyinsinööri Amazon Redshift -tiimissä, jossa hän vastaa Redshiftin suorituskyvyn mittaamisesta ja parantamisesta. Vapaa-ajallaan hän nauttii ruoanlaitosta, leikkimisestä kolmen poikansa kanssa ja polttopuiden pilkkomisesta.
 Ravi Animi on Amazon Redshift -tiimin Senior Product Management -johtaja ja hallitsee useita Amazon Redshift -pilvitietovarastopalvelun toiminnallisia osa-alueita, mukaan lukien suorituskyky, tila-analytiikka, suoratoiston käsittely ja siirtostrategiat. Hänellä on kokemusta relaatiotietokannoista, moniulotteisista tietokannoista, IoT-teknologioista, tallennus- ja laskentainfrastruktuuripalveluista sekä viime aikoina startup-yritysten perustaja käyttämällä tekoälyä/syväoppimista, tietokonenäköä ja robotiikkaa.
Ravi Animi on Amazon Redshift -tiimin Senior Product Management -johtaja ja hallitsee useita Amazon Redshift -pilvitietovarastopalvelun toiminnallisia osa-alueita, mukaan lukien suorituskyky, tila-analytiikka, suoratoiston käsittely ja siirtostrategiat. Hänellä on kokemusta relaatiotietokannoista, moniulotteisista tietokannoista, IoT-teknologioista, tallennus- ja laskentainfrastruktuuripalveluista sekä viime aikoina startup-yritysten perustaja käyttämällä tekoälyä/syväoppimista, tietokonenäköä ja robotiikkaa.
 Aamer Shah on vanhempi insinööri Amazon Redshift Service -tiimissä.
Aamer Shah on vanhempi insinööri Amazon Redshift Service -tiimissä.
 Sanket Hase on ohjelmistokehityspäällikkö Amazon Redshift Service -tiimissä.
Sanket Hase on ohjelmistokehityspäällikkö Amazon Redshift Service -tiimissä.
 Orestis Polychroniou on pääinsinööri Amazon Redshift Service -tiimissä.
Orestis Polychroniou on pääinsinööri Amazon Redshift Service -tiimissä.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 10
- 100
- 16
- 32
- 7
- 9
- a
- pystyy
- Meistä
- kiihdyttää
- pääsy
- Accessed
- päästään
- poikki
- lisä-
- lisää
- Lisäksi
- lisä-
- kehittynyt
- Etu
- varaa
- vastaan
- algoritmit
- Kaikki
- mahdollistaa
- Myös
- vaihtoehto
- vaihtoehdot
- Vaikka
- aina
- Amazon
- Amazon Web Services
- määrä
- an
- analyysi
- Analytics
- analysointi
- ja
- Toinen
- Kaikki
- sovellukset
- Hakeminen
- lähestymistapa
- OVAT
- alueet
- noin
- AS
- ulkomuoto
- liittyvä
- At
- huomio
- auto
- Automatisoitu
- automaattisesti
- automaattisesti
- saatavissa
- keskimäärin
- AWS
- b
- kaistanleveys
- perustua
- BE
- koska
- ennen
- alkaa
- ovat
- benchmark
- Viitearvot
- hyödyttää
- PARAS
- Paremmin
- välillä
- Jälkeen
- miljardeja
- sekä
- pullonkauloja
- Laatikko
- tuoda
- laaja
- liiketoiminta
- bisnesvaisto
- kiireinen
- mutta
- by
- CAKE
- laskettu
- laskeminen
- soittaa
- CAN
- kyvyt
- tapaus
- tapauksissa
- ominaisuudet
- tunnettu siitä,
- Kaavio
- paloittelu
- valitsi
- Kaupunki
- pilvi
- Cluster
- Sarake
- Pylväät
- yhdistelmä
- sitoutunut
- Yhteinen
- vertailukelpoinen
- verrata
- verrattuna
- vertaamalla
- kilpailija
- kilpailijat
- monimutkainen
- noudatettava
- Laskea
- tietokone
- Tietokoneen visio
- käsite
- samanaikainen
- ehto
- tehty
- johdonmukainen
- Console
- vakio
- alituisesti
- muodostaa
- konsultointi
- sisältää
- jatkuvasti
- jatkaa
- jatkuu
- jatkuva
- jatkuvasti
- ruoanlaitto
- vastaava
- Hinta
- kustannukset
- kytketty
- luoda
- ratkaiseva
- asiakas
- Asiakkaat
- kojelauta
- mittaristot
- tiedot
- tietojen analysointi
- Data Analytics
- tietojenkäsittely
- tietojoukko
- tietovarasto
- tietovarastot
- data-driven
- tietokanta
- tietokannat
- aineistot
- Päivämäärä
- päätös
- oletusarvo
- määritellä
- toimittaa
- tuottaa
- Antaa
- johdettu
- on kuvattu
- suunniteltu
- haluttu
- yksityiskohta
- yksityiskohtainen
- Kehitys
- kehitys
- eri
- suoraan
- pohtia
- keskusteltiin
- Monimuotoisuus
- jakaa
- do
- ei
- ei
- Dont
- ajanut
- kukin
- Aikaisemmin
- helposti
- syödä
- Tehokas
- tehokas
- tehokkaasti
- käytössä
- mahdollistaa
- kannustaa
- Moottori
- insinööri
- tehostettu
- lisälaite
- parannuksia
- enter
- Vastaava
- erityisesti
- Eetteri (ETH)
- arvioinnit
- Jopa
- kaikki
- esimerkki
- Esimerkit
- odottaa
- experience
- uute
- tekijä
- tuttu
- paljon
- FAST
- nopeampi
- Ominaisuus
- harvat
- Vihdoin
- Löytää
- viimeistely
- Etunimi
- LAIVASTON
- Keskittää
- seurata
- jälkeen
- varten
- löytyi
- perustaja
- alkaen
- toiminnallinen
- edelleen
- yleinen tarkoitus
- syntyy
- sukupolvi
- saada
- saada
- GitHub
- antaa
- menee
- hyvä
- Kasvava
- kasvaa
- kahva
- Palvelimet
- Olla
- ottaa
- he
- Korkea
- korkeampi
- hänen
- pitää
- pito
- tunti
- TUNTIA
- Miten
- HTML
- http
- HTTPS
- sata
- Sadat
- ihanteellinen
- ihannetapauksessa
- tunnistaa
- if
- valaista
- kuvitella
- Vaikutus
- tärkeä
- tärkeä näkökohta
- parantaa
- parani
- parannus
- parannuksia
- parantaminen
- in
- sisältää
- sisältää
- Mukaan lukien
- Kasvaa
- kasvoi
- Lisäykset
- ilmaisee
- teollisuuden
- Infrastruktuuri
- esimerkki
- tapauksia
- integraatio
- Älykkyys
- vuorovaikutteinen
- sisäinen
- interventio
- tulee
- käyttöön
- käyttöön
- investointi
- liittyy
- Esineiden internet
- IT
- SEN
- yhdistää
- jpg
- vain
- Pitää
- pakki
- tietäen
- suuri
- suurempi
- myöhemmin
- uusin
- viimeisin kehitys
- käynnistettiin
- käynnistäminen
- johtaja
- johtava
- oppiminen
- vähiten
- vähemmän
- Taso
- kevyt
- pitää
- vähän
- kuormitus
- lastaus
- kuormat
- sijaitsevat
- Pitkät
- kauemmin
- katso
- näköinen
- Matala
- alentaa
- alin
- ylläpitää
- ylläpitäminen
- huolto
- Enemmistö
- tehdä
- onnistui
- johto
- johtaja
- hallinnoi
- manuaalinen
- monet
- ottelu
- Matters
- Saattaa..
- merkitys
- välineet
- mitata
- mitattu
- mittaus
- keskikokoinen
- Tavata
- Muisti
- mainitsi
- ehkä
- muutto
- pöytäkirja
- Moderni
- maanantai
- raha
- lisää
- Lisäksi
- eniten
- paljon
- nimittäin
- Tarve
- tarvitaan
- tarpeet
- Uusi
- New York
- new york city
- hiljattain
- seuraava
- Nro
- huomata
- huomattava
- huomata
- nyt
- numero
- of
- virallinen
- usein
- on
- Tarpeen vaatiessa
- ONE
- vain
- käyttää
- toimi
- Mahdollisuudet
- optimaalinen
- optimointi
- optimoimalla
- Vaihtoehto
- Vaihtoehdot
- or
- Muut
- meidän
- ulos
- yli
- oma
- parametrit
- erityinen
- Kuvio
- kuviot
- Maksaa
- maksu
- varten
- osuus
- suorituskyky
- suunnittelu
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- pelaa
- Kohta
- Suosittu
- mahdollinen
- Kirje
- teho
- Ennustettavissa
- esitetty
- estää
- hinta
- hinnoittelu
- Pääasiallinen
- jalostettu
- käsittely
- Tuotteet
- tuotehallinta
- todiste
- todiste käsitteestä
- toimittaa
- julkisesti
- julkaistu
- osti
- kyselyt
- nopeasti
- satunnainen
- Lue
- todellinen maailma
- reaaliaikainen
- vastaanottaa
- äskettäinen
- äskettäin
- suosituksia
- viittaukset
- alueet
- Hylätty..
- suhteellinen
- suhteellisesti
- poistamalla
- toistuva
- toistuva
- monistaa
- Raportit
- edustaja
- edustavat
- edellyttää
- varattu
- vastaus
- vastuullinen
- Saatu ja
- tulokset
- vähittäiskauppa
- palata
- tulot
- arviot
- oikein
- robotiikka
- ROI
- ajaa
- juoksu
- toimii
- myynti
- sama
- Säästä
- näki
- skaalautuvuus
- Asteikko
- asteikot
- skaalaus
- skannaa
- järjestelmä
- skriptejä
- Toinen
- sekuntia
- Osa
- nähdä
- siemenet
- vanhempi
- palvella
- serverless
- palvelu
- Palvelut
- setti
- setup
- useat
- Jaa:
- Lyhyt
- shouldnt
- näyttää
- esitetty
- merkittävä
- merkittävästi
- samalla lailla
- Yksinkertainen
- samanaikaisesti
- single
- Koko
- kokoinen
- pieni
- So
- Tuotteemme
- ohjelmistokehitys
- tila-
- määrittely
- määritelty
- nopeus
- viettää
- käytetty
- piikki
- SQL
- Alkaa
- alkoi
- käynnistyksen
- pysyä
- tasaisesti
- Askeleet
- Levytila
- varastot
- suora
- strategiat
- virta
- streaming
- jono
- antaa
- niin
- sopivuus
- tuki
- Tukea
- järjestelmä
- taulukko
- ottaa
- otettava
- joukkue-
- tekniikat
- Technologies
- kertoa
- kymmeniä
- testi
- testit
- kuin
- että
- -
- heidän
- sitten
- Siellä.
- siksi
- Nämä
- ne
- ajatella
- tätä
- ne
- tuhansia
- kolmella
- suoritusteho
- aika
- kertaa
- että
- tänään
- Yhteensä
- liikenne
- Muuttaa
- avoimesti
- yrittää
- yrittää
- Kahdesti
- kaksi
- tyyppi
- tyypit
- tyypillinen
- kaikkialla läsnä oleva
- kykenemätön
- harvinainen
- ymmärtää
- unique
- ennalta arvaamaton
- asti
- us
- Käyttö
- USD
- käyttää
- käyttölaukku
- käytetty
- käyttäjä
- Käyttäjät
- käyttötarkoituksiin
- käyttämällä
- arvot
- lajike
- eri
- hyvin
- näkymät
- käytännössä
- visio
- odottaa
- haluta
- Varasto
- oli
- Tapa..
- tavalla
- we
- verkko
- verkkopalvelut
- viikko
- HYVIN
- olivat
- Mitä
- kun
- taas
- joka
- vaikka
- miksi
- leveä
- tulee
- with
- sisällä
- ilman
- arvoinen
- olisi
- kirjoittaminen
- kirjoitti
- york
- te
- Sinun
- zephyrnet