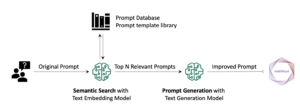
Generatiivisen tekoälyn myötä nykyiset perusmallit (FM:t), kuten suuret kielimallit (LLM) Claude 2 ja Llama 2, voivat suorittaa erilaisia generatiivisia tehtäviä, kuten kysymyksiin vastaamisen, yhteenvedon ja sisällön luomisen tekstidataan. Reaalimaailman dataa on kuitenkin olemassa useissa eri muodoissa, kuten tekstiä, kuvia, videoita ja ääntä. Otetaan esimerkiksi PowerPoint-diasarja. Se voi sisältää tietoa tekstin muodossa tai upotettuna kaavioihin, taulukoihin ja kuviin.
Tässä viestissä esittelemme ratkaisun, joka käyttää multimodaalisia FM-laitteita, kuten Amazon Titan -multimodaaliset upotukset malli ja LLaVA 1.5 ja AWS-palvelut mukaan lukien Amazonin kallioperä ja Amazon Sage Maker suorittaa samanlaisia generatiivisia tehtäviä multimodaalista dataa varten.
Ratkaisun yleiskatsaus
Ratkaisu tarjoaa toteutuksen kysymyksiin vastaamiseen käyttämällä tekstin sisältämää tietoa ja diapakan visuaalisia elementtejä. Suunnittelu perustuu Retrieval Augmented Generation (RAG) -konseptiin. Perinteisesti RAG on liitetty tekstitietoihin, joita LLM:t voivat käsitellä. Tässä viestissä laajennamme RAG:ta sisältämään myös kuvia. Tämä tarjoaa tehokkaan hakutoiminnon kontekstuaalisen sisällön poimimiseen visuaalisista elementeistä, kuten taulukoista ja kaavioista, sekä tekstiä.
Kuvia sisältävä RAG-ratkaisu voidaan suunnitella eri tavoin. Olemme esittäneet täällä yhden lähestymistavan ja jatkamme vaihtoehtoisella lähestymistavalla tämän kolmiosaisen sarjan toisessa viestissä.
Tämä ratkaisu sisältää seuraavat komponentit:
- Amazon Titan Multimodal Embeddings -malli – Tätä FM:ää käytetään upotusten luomiseen tässä viestissä käytetyn diapakan sisällölle. Multimodaalisena mallina tämä Titan-malli voi käsitellä tekstiä, kuvia tai yhdistelmiä syötteenä ja luoda upotuksia. Titan Multimodal Embeddings -malli luo vektoreita (upotuksia), joiden ulottuvuus on 1,024 XNUMX, ja siihen pääsee Amazon Bedrockin kautta.
- Suuri kieli- ja näköavustaja (LLaVA) – LLaVA on avoimen lähdekoodin multimodaalinen malli visuaaliseen ja kielen ymmärtämiseen, ja sitä käytetään diojen datan tulkitsemiseen, mukaan lukien visuaaliset elementit, kuten kaaviot ja taulukot. Käytämme 7 miljardin parametrin versiota LLaVA 1.5-7b tässä ratkaisussa.
- Amazon Sage Maker – LLaVA-malli otetaan käyttöön SageMaker-päätepisteessä SageMaker-isännöintipalveluita käyttäen, ja käytämme tuloksena olevaa päätepistettä tehdäksemme päätelmiä LLaVA-mallia vastaan. Käytämme myös SageMaker-muistikirjoja tämän ratkaisun ohjaamiseen ja esittelyyn.
- Amazon OpenSearch palvelimeton – OpenSearch Serverless on on-demand-palvelimeton kokoonpano Amazon OpenSearch-palvelu. Käytämme OpenSearch Serverlessiä vektoritietokantana Titan Multimodal Embeddings -mallin luomien upotusten tallentamiseen. OpenSearch Serverless -kokoelmaan luotu hakemisto toimii RAG-ratkaisumme vektorivarastona.
- Amazon OpenSearch Ingestion (OSI) – OSI on täysin hallittu, palvelimeton tiedonkeruulaite, joka toimittaa tietoja OpenSearch-palvelun toimialueille ja OpenSearch-palvelimettomille kokoelmille. Tässä viestissä käytämme OSI-putkia tietojen toimittamiseen OpenSearch Serverless -vektorisäilöön.
Ratkaisuarkkitehtuuri
Ratkaisusuunnittelu koostuu kahdesta osasta: sisäänotto ja käyttäjävuorovaikutus. Käsittelyn aikana käsittelemme syötediapakin muuntamalla jokaisen dian kuvaksi, luomme upotuksia näille kuville ja täytämme sitten vektoritietovaraston. Nämä vaiheet suoritetaan ennen käyttäjän vuorovaikutusvaiheita.
Käyttäjän vuorovaikutusvaiheessa käyttäjän kysymys muunnetaan upotuksiksi ja samankaltaisuushaku suoritetaan vektoritietokannasta löytääkseen dia, joka saattaa sisältää vastauksia käyttäjän kysymykseen. Tämän jälkeen toimitamme tämän dian (kuvatiedoston muodossa) LLaVA-malliin ja käyttäjän kysymykseen kehotteena luoda vastaus kyselyyn. Kaikki tämän viestin koodi on saatavilla osoitteessa GitHub levätä.
Seuraava kaavio havainnollistaa käsittelyn arkkitehtuuria.
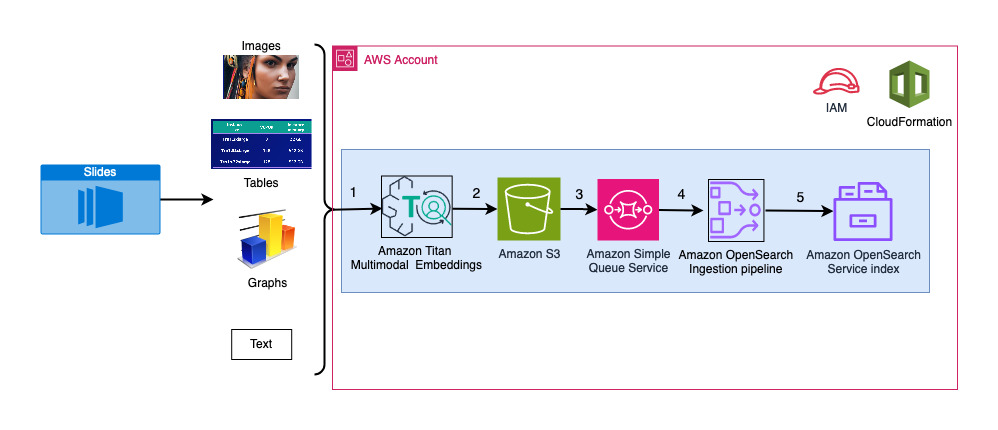
Työnkulun vaiheet ovat seuraavat:
- Diat muunnetaan kuvatiedostoiksi (yksi diaa kohden) JPG-muodossa ja siirretään Titan Multimodal Embeddings -malliin upotusten luomiseksi. Tässä viestissä käytämme diaa nimeltä Harjoittele ja ota käyttöön Stable Diffusionia AWS Trainiumin ja AWS Inferentian avulla AWS-huippukokouksesta Torontossa kesäkuussa 2023 ratkaisun esittelyyn. Näytepakissa on 31 diaa, joten luomme 31 sarjaa vektori upotuksia, joista jokaisessa on 1,024 XNUMX ulottuvuutta. Lisäämme metatietokenttiä näihin luotuihin vektoriupotuksiin ja luomme JSON-tiedoston. Näitä lisämetatietokenttiä voidaan käyttää monipuolisten hakukyselyiden suorittamiseen OpenSearchin tehokkaiden hakuominaisuuksien avulla.
- Luodut upotukset kootaan yhteen JSON-tiedostoon, johon ladataan Amazonin yksinkertainen tallennuspalvelu (Amazon S3).
- kautta Amazon S3 -tapahtumailmoitukset, tapahtuma on asetettu Amazonin yksinkertainen jonopalvelu (Amazon SQS) -jono.
- Tämä SQS-jonon tapahtuma laukaisee OSI-putkilinjan, joka puolestaan syöttää tiedot (JSON-tiedoston) asiakirjoina OpenSearch Serverless -hakemistoon. Huomaa, että OpenSearch Serverless -hakemisto on määritetty tämän liukuhihnan nieluksi ja se luodaan osana OpenSearch Serverless -kokoelmaa.
Seuraava kaavio havainnollistaa käyttäjän vuorovaikutuksen arkkitehtuuria.
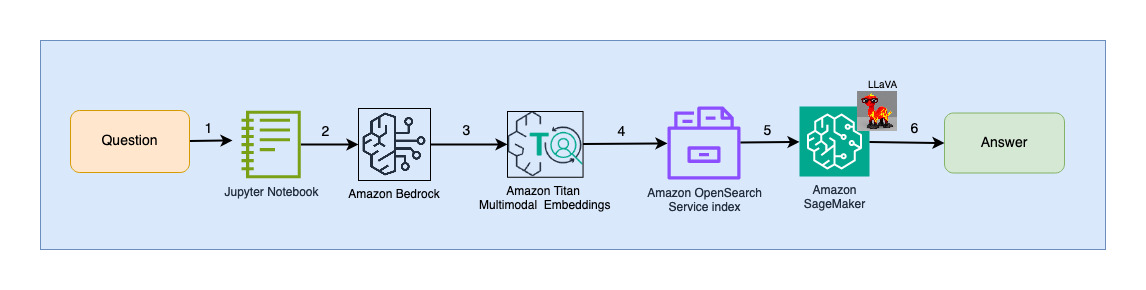
Työnkulun vaiheet ovat seuraavat:
- Käyttäjä lähettää kysymyksen, joka liittyy syötettyyn diasarjaan.
- Käyttäjän syöttö muunnetaan upotuksiksi käyttämällä Titan Multimodal Embeddings -mallia, jota käytetään Amazon Bedrockin kautta. OpenSearch-vektorihaku suoritetaan käyttämällä näitä upotuksia. Suoritamme k-lähimmän naapurin (k=1) haun hakeaksemme käyttäjän kyselyä vastaavan osuvimman upotuksen. Asetus k=1 hakee käyttäjän kysymykseen osuvimman dian.
- OpenSearch Serverlessin vastauksen metatiedot sisältävät polun asiaankuuluvinta diaa vastaavaan kuvaan.
- Kehote luodaan yhdistämällä käyttäjän kysymys ja kuvapolku ja tarjotaan SageMakerissa isännöidylle LLaVAlle. LLaVA-malli pystyy ymmärtämään käyttäjän kysymyksen ja vastaamaan siihen tarkastelemalla kuvan tietoja.
- Tämän päätelmän tulos palautetaan käyttäjälle.
Näitä vaiheita käsitellään yksityiskohtaisesti seuraavissa osissa. Katso tulokset osio kuvakaappauksia ja tulosteen yksityiskohtia varten.
Edellytykset
Tässä viestissä tarjotun ratkaisun toteuttamiseksi sinulla pitäisi olla AWS-tili ja tuntemus FM:istä, Amazon Bedrockista, SageMakerista ja OpenSearch Servicestä.
Tämä ratkaisu käyttää Titan Multimodal Embeddings -mallia. Varmista, että tämä malli on otettu käyttöön Amazon Bedrockissa. Valitse Amazon Bedrock -konsolista Mallin käyttöoikeus navigointiruudussa. Jos Titan Multimodal Embeddings on käytössä, käyttöoikeustila näkyy Pääsy myönnetty.
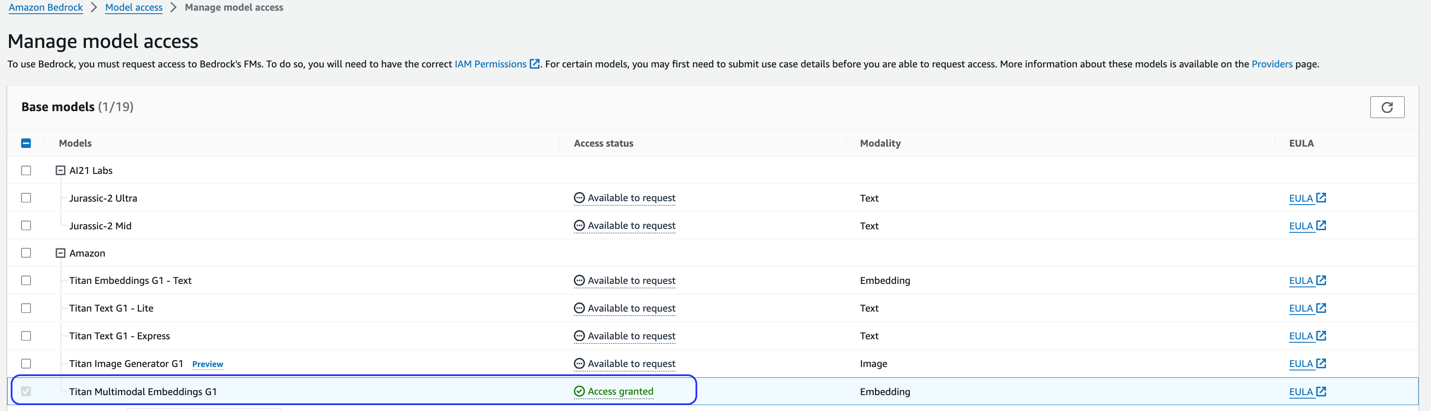
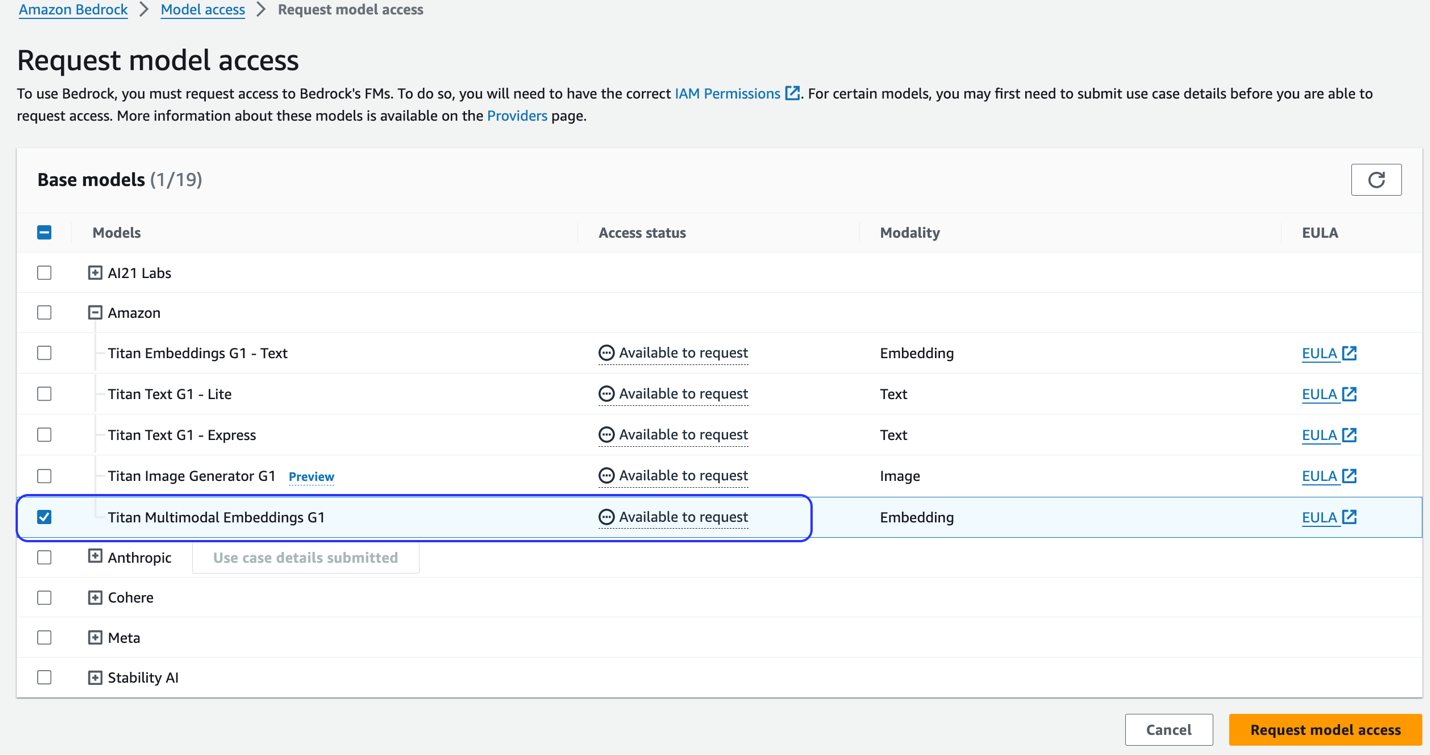
Jos mallia ei ole saatavilla, salli mallin käyttö valitsemalla Hallinnoi mallin käyttöä, valitsemalla Titan Multimodal Embeddings G1, ja valitsemalla Pyydä mallin käyttöoikeutta. Malli otetaan heti käyttöön.
Käytä AWS CloudFormation -mallia ratkaisupinon luomiseen
Käytä jotakin seuraavista AWS-pilven muodostuminen malleja (alueestasi riippuen) ratkaisuresurssien käynnistämiseksi.
| AWS-alue | Linkki |
|---|---|
us-east-1 |
|
us-west-2 |
Kun pino on luotu onnistuneesti, siirry pinoon Lähdöt -välilehti AWS CloudFormation -konsolissa ja kirjaa arvo muistiin MultimodalCollectionEndpoint, jota käytämme seuraavissa vaiheissa.
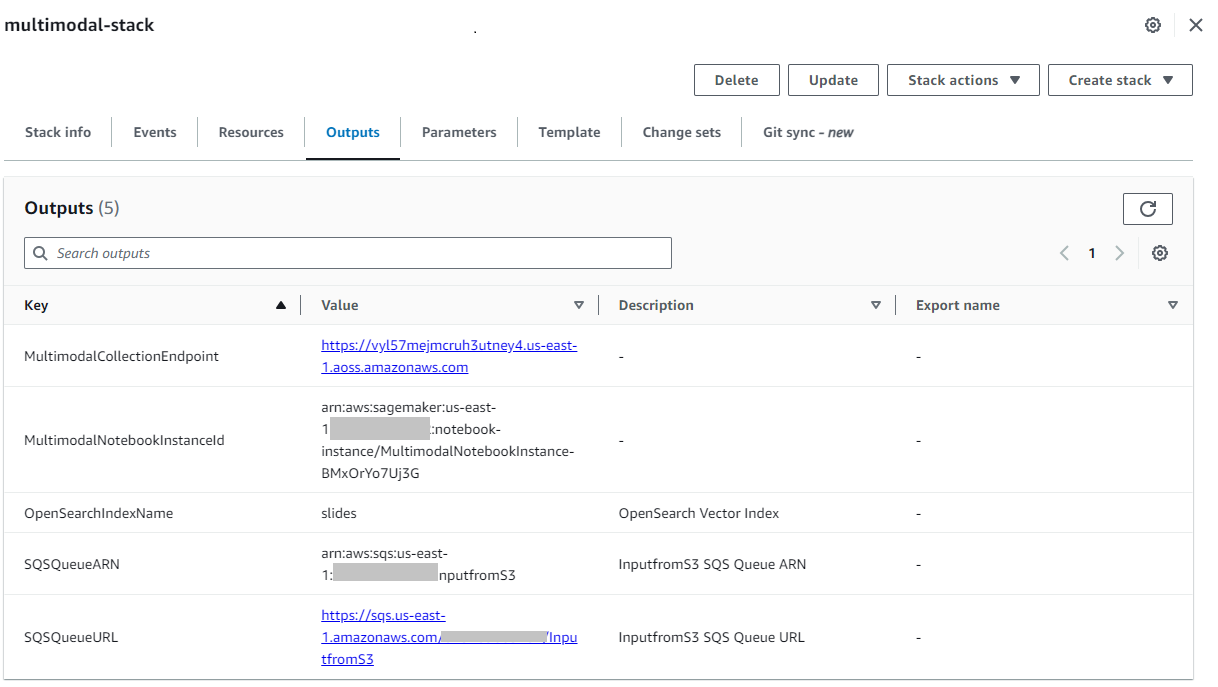
CloudFormation-malli luo seuraavat resurssit:
- IAM-roolit - Seuraavat AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) roolit luodaan. Päivitä nämä roolit käyttöön vähiten etuoikeuksia.
SMExecutionRoleAmazon S3:n, SageMakerin, OpenSearch Servicen ja Bedrockin täydet käyttöoikeudet.OSPipelineExecutionRolejoilla on pääsy tiettyihin Amazon SQS- ja OSI-toimintoihin.
- SageMaker-muistikirja – Kaikki tämän viestin koodi ajetaan tämän muistikirjan kautta.
- OpenSearch Serverless kokoelma – Tämä on vektoritietokanta upotusten tallentamiseen ja hakemiseen.
- OSI-putki – Tämä on putki tietojen siirtämiseksi OpenSearch Serverlessiin.
- S3-kauha – Kaikki tämän viestin tiedot on tallennettu tähän ämpäriin.
- SQS-jono – OSI-liukuhihnan ajon laukaisutapahtumat laitetaan tähän jonoon.
CloudFormation-malli määrittää OSI-putkilinjan Amazon S3- ja Amazon SQS -käsittelyn lähteenä ja OpenSearch Serverless -hakemiston nieluna. Kaikki objektit, jotka on luotu määritettyyn S3-alueeseen ja etuliitteeseen (multimodal/osi-embeddings-json) käynnistää SQS-ilmoitukset, joita OSI-putkisto käyttää tietojen siirtämiseen OpenSearch Serverless -palveluun.
CloudFormation-malli luo myös verkko, salausja tietojen käyttö OpenSearch Serverless -kokoelman edellyttämät käytännöt. Päivitä nämä käytännöt ottaaksesi käyttöön vähiten oikeudet.
Huomaa, että CloudFormation-mallin nimeen viitataan SageMaker-muistikirjoissa. Jos mallin oletusnimi muuttuu, muista päivittää se globals.py
Testaa ratkaisu
Kun vaaditut vaiheet on suoritettu ja CloudFormation-pino on luotu onnistuneesti, olet nyt valmis testaamaan ratkaisua:
- Valitse SageMaker-konsolissa Kannettavat navigointipaneelissa.
- Valitse
MultimodalNotebookInstancemuistikirjan esimerkki ja valitse Avaa JupyterLab.
- In File Browser, siirry muistikirjat-kansioon nähdäksesi muistikirjat ja tukitiedostot.
Muistikirjat on numeroitu siinä järjestyksessä, jossa niitä ajetaan. Jokaisen muistikirjan ohjeet ja kommentit kuvaavat muistikirjan suorittamia toimia. Käytämme näitä muistikirjoja yksitellen.
- Valita 0_deploy_llava.ipynb avataksesi sen JupyterLabissa.
- On ajaa valikosta, valitse Suorita kaikki solut suorittaaksesi koodin tässä muistikirjassa.
Tämä muistikirja ottaa käyttöön LLaVA-v1.5-7B-mallin SageMaker-päätepisteeseen. Tässä muistikirjassa lataamme mallin LLaVA-v1.5-7B HuggingFace Hubista, korvaamme inference.py-komentosarjan komennolla llava_inference.py, ja luo model.tar.gz-tiedosto tälle mallille. Model.tar.gz-tiedosto ladataan Amazon S3:een ja sitä käytetään mallin käyttöönotossa SageMaker-päätepisteessä. The llava_inference.py skriptillä on lisäkoodi, joka mahdollistaa kuvatiedoston lukemisen Amazon S3:sta ja päättelemisen siitä.
- Valita 1_data_prep.ipynb avataksesi sen JupyterLabissa.
- On ajaa valikosta, valitse Suorita kaikki solut suorittaaksesi koodin tässä muistikirjassa.
Tämä muistikirja lataa liukukansi, muuntaa jokaisen dian JPG-tiedostomuotoon ja lataa ne tässä viestissä käytettyyn S3-säihöön.
- Valita 2_data_ingestion.ipynb avataksesi sen JupyterLabissa.
- On ajaa valikosta, valitse Suorita kaikki solut suorittaaksesi koodin tässä muistikirjassa.
Teemme seuraavat tässä muistikirjassa:
- Luomme indeksin OpenSearch Serverless -kokoelmaan. Tämä hakemisto tallentaa diapakan upotustiedot. Katso seuraava koodi:
- Käytämme Titan Multimodal Embeddings -mallia muuntaaksemme edellisessä muistikirjassa luodut JPG-kuvat vektori upotuksiksi. Nämä upotukset ja muut metatiedot (kuten kuvatiedoston S3-polku) tallennetaan JSON-tiedostoon ja ladataan Amazon S3:een. Huomaa, että luodaan yksi JSON-tiedosto, joka sisältää asiakirjat kaikille upotuksiksi muunnetuille dioille (kuville). Seuraava koodinpätkä näyttää, kuinka kuva (Base64-koodatun merkkijonon muodossa) muunnetaan upotuksiksi:
- Tämä toiminto käynnistää OpenSearchin käsittelyputkilinjan, joka käsittelee tiedoston ja syöttää sen OpenSearch Serverless -hakemistoon. Seuraavassa on esimerkki luodusta JSON-tiedostosta. (Esimerkkikoodissa näkyy vektori, jossa on neljä ulottuvuutta. Titan Multimodal Embeddings -malli tuottaa 1,024 XNUMX ulottuvuutta.)
- Valita 3_rag_inference.ipynb avataksesi sen JupyterLabissa.
- On ajaa valikosta, valitse Suorita kaikki solut suorittaaksesi koodin tässä muistikirjassa.
Tämä muistikirja toteuttaa RAG-ratkaisun: muunnamme käyttäjän kysymyksen upotuksiksi, etsimme samanlaisen kuvan (dian) vektoritietokannasta ja toimitamme haetun kuvan LLaVA:lle vastauksen muodostamiseksi käyttäjän kysymykseen. Käytämme seuraavaa kehotemallia:
Seuraava koodinpätkä tarjoaa RAG-työnkulun:
tulokset
Seuraavassa on kokoelma käyttäjien kysymyksistä ja vastauksista, jotka on luotu toteutuksemme avulla. The Kysymys sarake kaappaa käyttäjän kysymyksen ja Vastaus sarake on LLaVA:n luoma tekstivastaus. Kuva on k-lähin (k=1) diaosuma, jonka OpenSearch-palvelimeton vektorihaku palauttaa. LLaVA tulkitsee tämän dian vastauksen antamiseksi.
Multimodaaliset RAG-tulokset
| Kysymys | Vastaus | Kuva |
|---|---|---|
| Miten Inf2 vertaa suorituskykyä vastaaviin EC2-esiintymiin? Tarvitsen numeroita. | Slide deckin mukaan AWS Inferentia2:n Inf2-instanssit tarjoavat jopa 4x suuremman suorituskyvyn ja 10x pienemmän viiveen verrattuna vastaaviin EC2-instanssiin. |  |
| Mitä AWS:n AI/ML-palvelut tarjoavat AI/ML-vauhtipyörän mukaan? | AWS AI/ML -palvelut tarjoavat parempia $/perfer-ominaisuuksia, uusia ominaisuuksia ja investointeja innovaatioihin. | 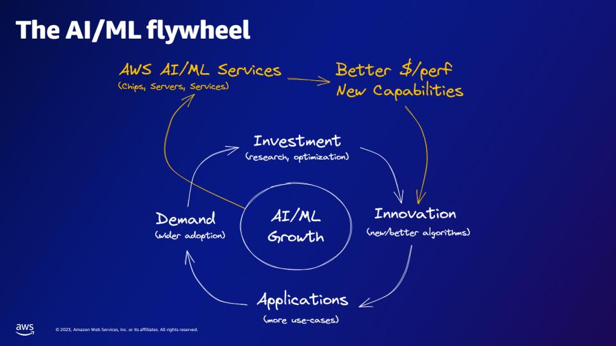 |
| Kuinka monta parametria GPT-2:ssa on enemmän kuin GPT-3? Mikä on numeerinen ero GPT-2:n ja GPT-3:n parametrikoon välillä? | Dian mukaan GPT-3:lla on 175 miljardia parametria, kun taas GPT-2:lla on 1.5 miljardia parametria. Numeerinen ero GPT-2:n ja GPT-3:n parametrikoon välillä on 173.5 miljardia. | 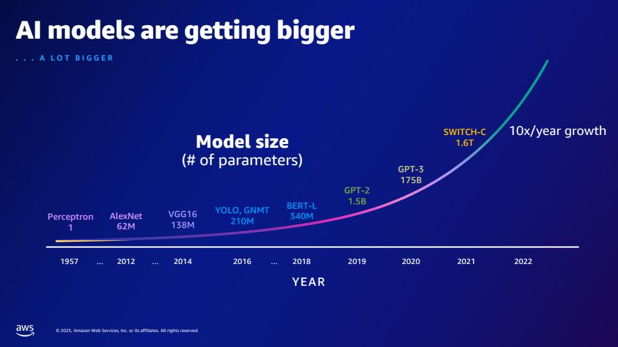 |
| Mitä kvarkit ovat hiukkasfysiikassa? | En löytänyt vastausta tähän kysymykseen diasta. |  |
Voit laajentaa tätä ratkaisua liukukansiisi. Päivitä vain globals.py:n SLIDE_DECK-muuttuja diapakin URL-osoitteella ja suorita edellisessä osiossa kuvatut käsittelyvaiheet.
Kärki
Voit käyttää OpenSearch-hallintapaneeleja OpenSearch-sovellusliittymän kanssa ja suorittaa pikatestejä hakemistollesi ja syötetyille tiedoille. Seuraava kuvakaappaus näyttää OpenSearch-hallintapaneelin GET-esimerkin.
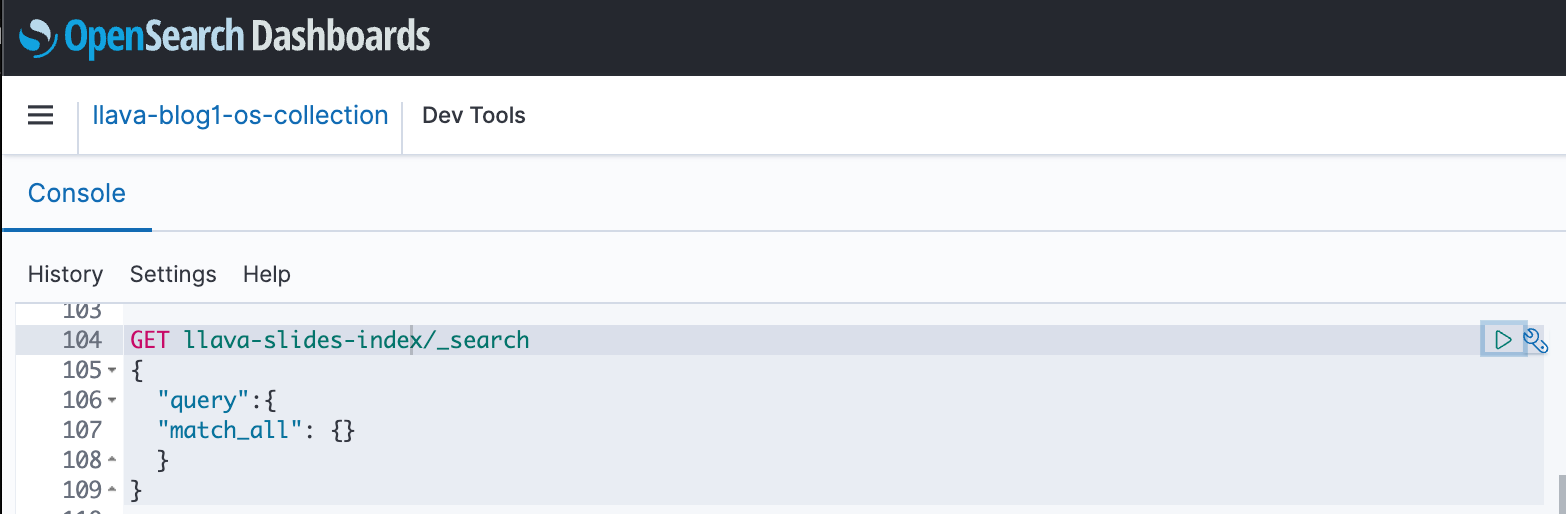
Puhdistaa
Vältä tulevia maksuja poistamalla luomasi resurssit. Voit tehdä tämän poistamalla pinon CloudFormation-konsolin kautta.

Poista lisäksi LLaVA-päätelmiä varten luotu SageMaker-päätelmäpäätepiste. Voit tehdä tämän poistamalla kommentin puhdistusvaiheesta 3_rag_inference.ipynb ja suoritat solun tai poistamalla päätepisteen SageMaker-konsolin kautta: valitse Päättely ja Endpoints navigointiruudussa, valitse sitten päätepiste ja poista se.
Yhteenveto
Yritykset luovat uutta sisältöä jatkuvasti, ja diakannet ovat yleinen mekanismi, jolla jaetaan ja levitetään tietoa sisäisesti organisaation kanssa ja ulkoisesti asiakkaiden kanssa tai konferensseissa. Ajan mittaan monipuolinen tieto voi jäädä hautautumaan muiden kuin tekstimuotojen, kuten kaavioiden ja taulukoiden, mukana näissä diapaketeissa. Voit käyttää tätä ratkaisua ja multimodaalisten FM-laitteiden, kuten Titan Multimodal Embeddings -mallin ja LLaVA:n, tehoa löytääksesi uutta tietoa tai löytääksesi uusia näkökulmia sisältöön diakannoissa.
Kannustamme sinua oppimaan lisää tutkimalla Amazon SageMaker JumpStart, Amazon Titan -malleja, Amazon Bedrock ja OpenSearch Service sekä rakentaa ratkaisu käyttämällä tässä viestissä tarjottua esimerkkitoteutusta.
Katso kaksi lisäpostausta osana tätä sarjaa. Osa 2 kattaa toisen lähestymistavan, jolla voit puhua diakannelle. Tämä lähestymistapa luo ja tallentaa LLaVA-päätelmiä ja käyttää näitä tallennettuja päätelmiä vastaamaan käyttäjien kyselyihin. Osassa 3 verrataan näitä kahta lähestymistapaa.
Tietoja kirjoittajista
 Amit Arora on AI- ja ML-asiantuntijaarkkitehti Amazon Web Servicesissä, ja hän auttaa yritysasiakkaita käyttämään pilvipohjaisia koneoppimispalveluita innovaatioiden nopeaan skaalaamiseen. Hän on myös dosentti MS-tietotiede- ja analytiikkaohjelmassa Georgetownin yliopistossa Washington DC:ssä.
Amit Arora on AI- ja ML-asiantuntijaarkkitehti Amazon Web Servicesissä, ja hän auttaa yritysasiakkaita käyttämään pilvipohjaisia koneoppimispalveluita innovaatioiden nopeaan skaalaamiseen. Hän on myös dosentti MS-tietotiede- ja analytiikkaohjelmassa Georgetownin yliopistossa Washington DC:ssä.
 Manju Prasad on vanhempi ratkaisuarkkitehti strategisten tilien parissa Amazon Web Services -palvelussa. Hän keskittyy tarjoamaan teknistä neuvontaa useilla eri aloilla, mukaan lukien tekoäly/ML teltta-M&E-asiakkaalle. Ennen AWS:lle tuloaan hän suunnitteli ja rakensi ratkaisuja finanssipalvelualan yrityksille ja myös startupille.
Manju Prasad on vanhempi ratkaisuarkkitehti strategisten tilien parissa Amazon Web Services -palvelussa. Hän keskittyy tarjoamaan teknistä neuvontaa useilla eri aloilla, mukaan lukien tekoäly/ML teltta-M&E-asiakkaalle. Ennen AWS:lle tuloaan hän suunnitteli ja rakensi ratkaisuja finanssipalvelualan yrityksille ja myös startupille.
 Archana Inapudi on AWS:n vanhempi ratkaisuarkkitehti, joka tukee strategisia asiakkaita. Hänellä on yli vuosikymmenen kokemus asiakkaiden auttamisesta data-analytiikka- ja tietokantaratkaisujen suunnittelussa ja rakentamisessa. Hän on intohimoinen teknologian käyttämisestä arvon tuottamiseksi asiakkaille ja liiketoiminnan tulosten saavuttamiseksi.
Archana Inapudi on AWS:n vanhempi ratkaisuarkkitehti, joka tukee strategisia asiakkaita. Hänellä on yli vuosikymmenen kokemus asiakkaiden auttamisesta data-analytiikka- ja tietokantaratkaisujen suunnittelussa ja rakentamisessa. Hän on intohimoinen teknologian käyttämisestä arvon tuottamiseksi asiakkaille ja liiketoiminnan tulosten saavuttamiseksi.
 Antara Raisa on AI- ja ML Solutions -arkkitehti Amazon Web Services -palvelussa, joka tukee strategisia asiakkaita Dallasista, Texasista. Hänellä on myös aikaisempaa kokemusta työskentelystä suurten yrityskumppaneiden kanssa AWS:ssä, jossa hän työskenteli kumppanin menestysratkaisuarkkitehtina digitaalisille alkuperäisasiakkaille.
Antara Raisa on AI- ja ML Solutions -arkkitehti Amazon Web Services -palvelussa, joka tukee strategisia asiakkaita Dallasista, Texasista. Hänellä on myös aikaisempaa kokemusta työskentelystä suurten yrityskumppaneiden kanssa AWS:ssä, jossa hän työskenteli kumppanin menestysratkaisuarkkitehtina digitaalisille alkuperäisasiakkaille.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- pystyy
- Meistä
- pääsy
- Accessed
- Tilit
- Saavuttaa
- Toiminta
- toimet
- säädökset
- lisätä
- lisä-
- lisäaine
- tulo
- vastaan
- AI
- AI / ML
- Kaikki
- sallia
- pitkin
- Myös
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- Analytics
- ja
- Toinen
- vastaus
- puhelinvastaaja
- vastauksia
- Kaikki
- api
- käyttää
- lähestymistapa
- lähestymistavat
- arkkitehtuuri
- OVAT
- AS
- kysyä
- Avustaja
- liittyvä
- At
- audio-
- täydennetty
- auth
- saatavissa
- välttää
- AWS
- AWS-pilven muodostuminen
- perustua
- BE
- ollut
- Paremmin
- välillä
- Miljardi
- elin
- rakentaa
- Rakentaminen
- rakennettu
- liiketoiminta
- by
- CAN
- kyvyt
- valmiudet
- kaappaa
- solu
- muuttunut
- maksut
- Valita
- valita
- asiakas
- koodi
- kokoelma
- kokoelmat
- kerääjä
- Sarake
- yhdistelmä
- yhdistely
- kommentit
- Yhteinen
- Yritykset
- vertailukelpoinen
- verrata
- verrattuna
- täydellinen
- Valmistunut
- osat
- käsite
- konferenssit
- Konfigurointi
- määritetty
- muodostuu
- Console
- sisältää
- sisälsi
- sisältää
- pitoisuus
- sisällön luominen
- muuntaa
- muunnetaan
- muuntaminen
- vastaava
- voisi
- kannet
- luoda
- luotu
- luo
- Luominen
- luominen
- Valtakirja
- asiakas
- Asiakkaat
- Dallas
- kojelauta
- mittaristot
- tiedot
- Data Analytics
- tietojenkäsittely
- tietokanta
- vuosikymmen
- kansi
- oletusarvo
- toimittaa
- Antaa
- osoittaa
- Riippuen
- sijoittaa
- käyttöön
- levityspinnalta
- lauennut
- kuvata
- Malli
- suunniteltu
- yksityiskohta
- yksityiskohtainen
- yksityiskohdat
- kaavio
- DICT
- DID
- ero
- eri
- Diffuusio
- digitaalinen
- Ulottuvuus
- mitat
- löytää
- keskusteltiin
- näyttö
- do
- asiakirjat
- ei
- verkkotunnuksia
- download
- lataukset
- aikana
- e
- kukin
- elementtejä
- upotettu
- upottamisen
- mahdollistaa
- käytössä
- koodattu
- kannustaa
- loppu
- päätepiste
- Moottori
- varmistaa
- yritys
- yritysasiakkaat
- virhe
- Eetteri (ETH)
- tapahtuma
- Tapahtumat
- tutkii
- esimerkki
- Paitsi
- poikkeus
- olemassa
- experience
- Tutkiminen
- laajentaa
- ulkoisesti
- uute
- perehtyneisyys
- Fields
- filee
- Asiakirjat
- taloudellinen
- rahoituspalvelut
- Löytää
- keskittyy
- seurata
- jälkeen
- seuraa
- varten
- muoto
- muoto
- perusta
- neljä
- Ilmainen
- alkaen
- koko
- täysin
- tulevaisuutta
- tuottaa
- syntyy
- synnyttää
- sukupolvi
- generatiivinen
- Generatiivinen AI
- Georgetown
- saada
- GitHub
- menee
- kaaviot
- ohjaus
- Olla
- he
- hyödyllinen
- auttaa
- tätä
- kätketty
- korkeampi
- Osumien
- isäntä
- isännöi
- hotellit
- isännät
- Miten
- Kuitenkin
- HTML
- http
- HTTPS
- Napa
- HalaaKasvot
- i
- IAM
- Identiteetti
- if
- havainnollistaa
- kuva
- kuvien
- heti
- toteuttaa
- täytäntöönpano
- työkoneet
- in
- sisältää
- sisältää
- Mukaan lukien
- indeksi
- Indeksit
- tiedot
- Innovaatio
- innovaatiot
- panos
- esimerkki
- tapauksia
- ohjeet
- olla vuorovaikutuksessa
- vuorovaikutus
- sisäisesti
- tulee
- investointi
- IT
- tuloaan
- jpg
- json
- kesäkuu
- Kieli
- suuri
- Viive
- käynnistää
- OPPIA
- oppiminen
- lehtori
- pitää
- LINK
- liekki
- paikallinen
- alentaa
- kone
- koneoppiminen
- tehdä
- hoitaa
- onnistui
- monet
- ottelu
- matching
- mekanismi
- valikko
- Metadata
- menetelmä
- ML
- yksityiskohtaiset
- malli
- mallit
- lisää
- eniten
- MS
- moninkertainen
- nimi
- syntyperäinen
- Navigoida
- suunnistus
- Tarve
- Uusi
- Ei eristetty
- huomata
- muistikirja
- kannettavat tietokoneet
- ilmoitukset
- nyt
- numeroitu
- numerot
- esineet
- of
- kampanja
- on
- Tarpeen vaatiessa
- ONE
- vain
- avata
- avoimen lähdekoodin
- or
- organisaatio
- OS
- meidän
- ulos
- tuloksiin
- ulostulo
- yli
- lasi
- parametri
- parametrit
- osa
- hiukkanen
- kumppani
- kumppani
- osat
- Hyväksytty
- intohimoinen
- polku
- varten
- suorittaa
- suorituskyky
- suoritettu
- Oikeudet
- näkökulmia
- vaihe
- Fysiikka
- kuvat
- putki
- Platon
- Platonin tietotieto
- PlatonData
- politiikkaa
- Kirje
- Viestejä
- mahdollisesti
- teho
- voimakas
- Predictor
- esittää
- esitetty
- edellinen
- Aikaisempi
- prosessi
- jalostettu
- Prosessit
- käsittely
- Ohjelma
- ominaisuudet
- toimittaa
- mikäli
- tarjoaa
- tarjoamalla
- laittaa
- quarks
- kyselyt
- kysymys
- kysymys
- kysymykset
- nopea
- rätti
- alue
- nopeasti
- Lukeminen
- valmis
- todellinen maailma
- sai
- viitattu
- alue
- liittyvä
- merkityksellinen
- jäädä
- korvata
- pyyntö
- tarvitaan
- Esittelymateriaalit
- Vastata
- vastaus
- vasteet
- johtua
- Saatu ja
- tulokset
- haku
- palata
- Rikas
- roolit
- ajaa
- juoksu
- sagemaker
- SageMaker-johtopäätös
- sama
- sanoa
- Asteikko
- tiede
- kuvakaappauksia
- käsikirjoitus
- Haku
- Toinen
- Osa
- osiot
- sektori
- nähdä
- valita
- valitsemalla
- vanhempi
- Järjestys
- Sarjat
- serverless
- palvelee
- palvelu
- Palvelut
- Istunto
- Setit
- asetus
- settings
- Jaa:
- hän
- shouldnt
- esitetty
- Näytä
- samankaltainen
- Yksinkertainen
- yksinkertaisesti
- single
- Koko
- SLIDE
- Diat
- pätkä
- So
- ratkaisu
- Ratkaisumme
- jonkin verran
- lähde
- asiantuntija
- erityinen
- määritelty
- vakaa
- pino
- käynnistyksen
- Osavaltio
- Tila
- Vaihe
- Askeleet
- Levytila
- verkkokaupasta
- tallennettu
- varastot
- Strateginen
- jono
- myöhempi
- menestys
- Onnistuneesti
- niin
- Huippukokous
- Tukea
- varma
- taulukko
- ottaa
- Puhua
- tehtävät
- Tekninen
- Elektroniikka
- sapluuna
- malleja
- testi
- testit
- texas
- teksti
- teksti-
- että
- -
- tiedot
- heidän
- sitten
- Nämä
- tätä
- ne
- suoritusteho
- aika
- Titaani
- nimeltään
- että
- tämän päivän
- yhdessä
- toronto
- perinteisesti
- ylitys
- laukaista
- liipaisu
- totta
- yrittää
- VUORO
- kaksi
- tyyppi
- paljastaa
- ymmärtää
- ymmärtäminen
- yliopisto
- Päivitykset
- ladattu
- URL
- käyttää
- käytetty
- käyttäjä
- käyttötarkoituksiin
- käyttämällä
- arvo
- muuttuja
- lajike
- versio
- kautta
- Video
- Näytä
- visio
- visuaalinen
- Washington
- tavalla
- we
- verkko
- verkkopalvelut
- HYVIN
- Mitä
- Mikä on
- joka
- vaikka
- tulee
- with
- sisällä
- työskenteli
- työnkulku
- työskentely
- te
- Sinun
- zephyrnet