Amazon SageMaker Studio tarjoaa täysin hallitun ratkaisun datatieteilijöille koneoppimismallien (ML) interaktiiviseen rakentamiseen, kouluttamiseen ja käyttöönottoon. Amazon SageMaker muistikirjatyöt salli datatieteilijöiden käyttää muistikirjojaan pyynnöstä tai aikataulun mukaan muutamalla napsautuksella SageMaker Studiossa. Tämän julkaisun myötä voit ajaa muistikirjoja ohjelmallisesti töinä käyttämällä tarjoamia sovellusliittymiä Amazon SageMaker -putkistot, ML-työnkulun orkestrointiominaisuus Amazon Sage Maker. Lisäksi voit luoda monivaiheisen ML-työnkulun useilla riippuvaisilla muistikirjoilla näiden sovellusliittymien avulla.
SageMaker Pipelines on natiivi työnkulun organisointityökalu ML-putkien rakentamiseen, jotka hyödyntävät suoraa SageMaker-integraatiota. Jokainen SageMaker-putki koostuu vaiheet, jotka vastaavat yksittäisiä tehtäviä, kuten käsittelyä, koulutusta tai tietojenkäsittelyä käyttämällä Amazonin EMR. SageMaker-muistikirjatyöt ovat nyt saatavilla sisäänrakennettuna vaihetyyppinä SageMaker-putkistossa. Tämän muistikirjan työvaiheen avulla voit helposti ajaa muistikirjoja töinä vain muutaman koodirivin avulla Amazon SageMaker Python SDK. Lisäksi voit yhdistää useita riippuvaisia muistikirjoja luodaksesi työnkulun ohjattujen asyklisten kuvaajien (DAG) muodossa. Voit sitten suorittaa näitä muistikirjatöitä tai DAG:ita ja hallita ja visualisoida niitä SageMaker Studion avulla.
Datatieteilijät käyttävät tällä hetkellä SageMaker Studiota Jupyter-muistikirjojensa vuorovaikutteiseen kehittämiseen ja käyttävät sitten SageMaker-muistikirjoja ajaakseen näitä muistikirjoja ajoitettuina töinä. Nämä työt voidaan suorittaa välittömästi tai toistuvan aikataulun mukaan ilman, että tietotyöntekijöiden tarvitsee muuttaa koodia Python-moduuleiksi. Joitakin yleisiä käyttötapauksia tämän tekemiseen ovat:
- Pitkät juoksumuistikirjat taustalla
- Säännöllisesti käynnissä oleva mallipäätelmä raporttien luomiseksi
- Laajentuminen pienten näytetietojoukkojen valmistuksesta petatavun mittakaavan ison datan käsittelyyn
- Mallien uudelleenkoulutus ja käyttöönotto tietyllä tahdilla
- Töiden ajoitus mallin laadun tai tiedon ajautuman seurantaan
- Parametritilan tutkiminen parempien mallien saamiseksi
Vaikka tämä toiminto tekee tietotyöntekijöiden helpoksi automatisoida itsenäisiä muistikirjoja, ML-työnkulut koostuvat usein useista muistikirjoista, joista jokainen suorittaa tietyn tehtävän monimutkaisilla riippuvuuksilla. Esimerkiksi muistikirjassa, joka valvoo mallitietojen ajautumista, tulisi olla esivaihe, joka mahdollistaa uusien tietojen poimimisen, muuntamisen ja lataamisen (ETL) ja käsittelyn sekä mallin päivityksen ja koulutuksen jälkeinen vaihe, jos huomattava ajautuminen havaitaan. . Lisäksi datatieteilijät saattavat haluta käynnistää koko työnkulun toistuvasti päivittääkseen mallin uusien tietojen perusteella. Jotta voit helposti automatisoida muistikirjasi ja luoda tällaisia monimutkaisia työnkulkuja, SageMaker-muistikirjatyöt ovat nyt saatavilla vaiheena SageMaker Pipelinesissä. Tässä viestissä näytämme, kuinka voit ratkaista seuraavat käyttötapaukset muutamalla koodirivillä:
- Käytä itsenäistä muistikirjaa ohjelmallisesti välittömästi tai toistuvan aikataulun mukaan
- Luo monivaiheisia kannettavien työnkulkuja DAG:ina jatkuvaa integrointia ja jatkuvaa toimitusta (CI/CD) varten, joita voidaan hallita SageMaker Studion käyttöliittymän kautta.
Ratkaisun yleiskatsaus
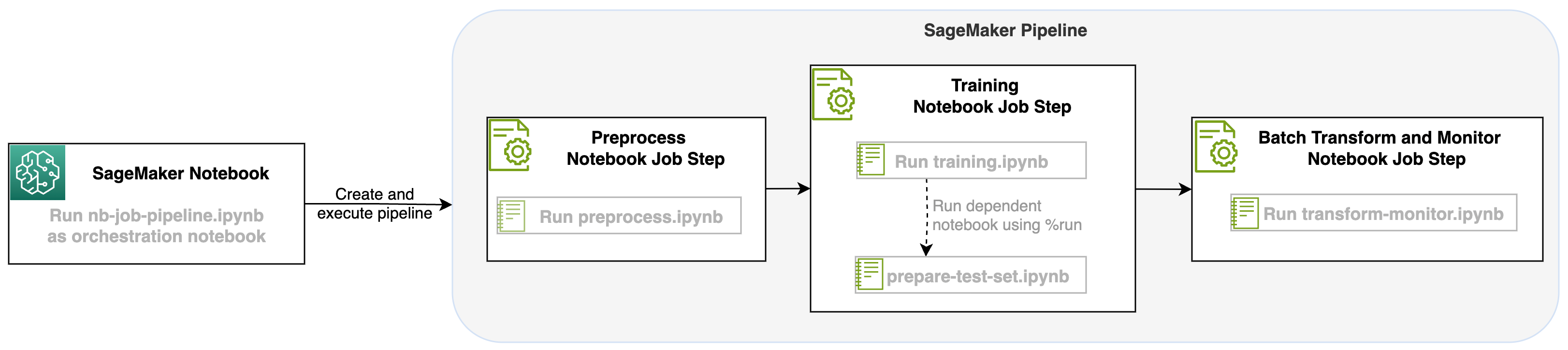
Seuraava kaavio havainnollistaa ratkaisumme arkkitehtuuria. Voit käyttää SageMaker Python SDK:ta yksittäisen muistikirjatyön tai työnkulun suorittamiseen. Tämä ominaisuus luo SageMaker-harjoitustyön kannettavan tietokoneen käyttöä varten.
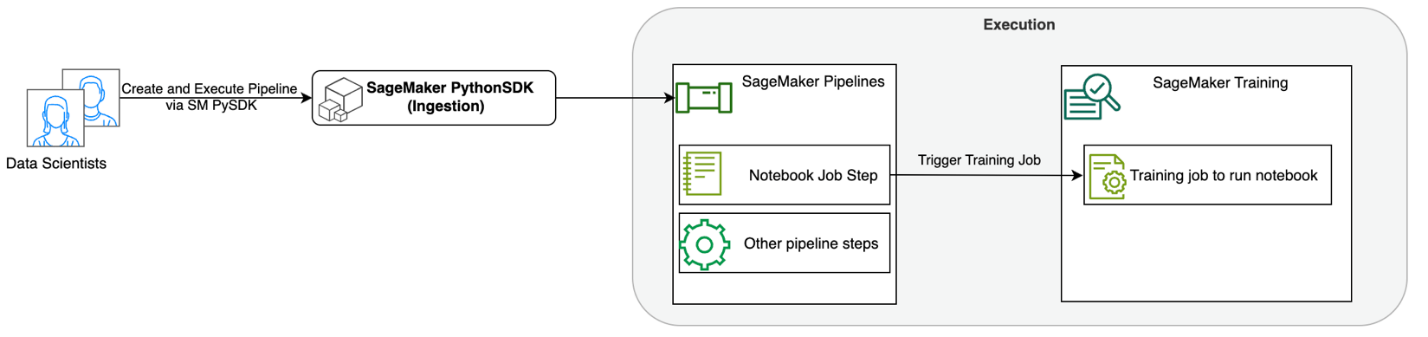
Seuraavissa osioissa käymme läpi mallin ML-käyttötapauksen ja esittelemme vaiheet muistikirjatöiden työnkulun luomiseksi, parametrien siirtämiseksi eri muistikirjan vaiheiden välillä, työnkulun ajoittamiseen ja sen seurantaan SageMaker Studion kautta.
Tämän esimerkin ML-ongelmaamme varten rakennamme tunteiden analyysimallia, joka on eräänlainen tekstin luokittelutehtävä. Tunnelmaanalyysin yleisimpiä sovelluksia ovat sosiaalisen median seuranta, asiakastuen hallinta ja asiakaspalautteen analysointi. Tässä esimerkissä käytetty tietojoukko on Stanford Sentiment Treebank (SST2) -tietojoukko, joka koostuu elokuva-arvosteluista sekä kokonaisluvusta (0 tai 1), joka ilmaisee arvostelun positiivisen tai negatiivisen mielipiteen.
Seuraava on esimerkki a data.csv tiedosto, joka vastaa SST2-tietojoukkoa, ja näyttää arvot sen kahdessa ensimmäisessä sarakkeessa. Huomaa, että tiedostossa ei saa olla otsikkoa.
| Sarake 1 | Sarake 2 |
| 0 | piilottaa uusia eritteitä vanhempien yksiköistä |
| 0 | ei sisällä nokkeluutta, vain työläitä |
| 1 | joka rakastaa hahmojaan ja viestii jotain melko kaunista ihmisluonnosta |
| 0 | on täysin tyytyväinen pysyäkseen samana koko ajan |
| 0 | pahimmilla nörttien koston kliseillä, joita elokuvantekijät voivat kaivaa |
| 0 | se on aivan liian traagista ansaitsemaan näin pinnallista kohtelua |
| 1 | osoittaa, että tällaisten hollywood-menestysfilmien, kuten patrioottipelien, ohjaaja voi silti tuottaa pienen, henkilökohtaisen elokuvan, jossa on tunnekuormitus. |
Tässä ML-esimerkissä meidän on suoritettava useita tehtäviä:
- Suorita ominaisuussuunnittelu valmistellaksesi tämä tietojoukko mallimme ymmärtämässä muodossa.
- Suorita toimintojen suunnittelun jälkeen koulutusvaihe, joka käyttää Transformersia.
- Määritä eräpäätelmä hienosäädetyn mallin avulla, jotta voit ennustaa tulevien uusien arvostelujen tunteen.
- Määritä tietojen seurantavaihe, jotta voimme säännöllisesti tarkkailla uusia tietojamme mahdollisten laadun poikkeamien varalta, mikä saattaa edellyttää mallin painojen uudelleenkouluttamista.
Tämän kannettavan työpaikan käynnistämisen SageMaker-putkien vaiheena voimme järjestää tämän työnkulun, joka koostuu kolmesta erillisestä vaiheesta. Jokainen työnkulun vaihe kehitetään eri muistikirjassa, joka muunnetaan sitten itsenäisiksi muistikirjan työvaiheiksi ja yhdistetään liukuhihnaksi:
- esikäsittely – Lataa julkinen SST2-tietojoukko osoitteesta Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ja luo CSV-tiedosto muistikirjaa varten vaiheessa 2. SST2-tietojoukko on tekstiluokittelutietojoukko, jossa on kaksi tunnistetta (0 ja 1) ja luokiteltava tekstisarake.
- koulutus – Ota muotoiltu CSV-tiedosto ja suorita hienosäätö BERT:llä tekstin luokittelua varten käyttämällä Transformers-kirjastoja. Käytämme osana tätä vaihetta testitietojen valmistelumuistikirjaa, joka on riippuvuus hienosäätö- ja eräpäättelyvaiheesta. Kun hienosäätö on valmis, tätä muistikirjaa ajetaan run magicilla ja se valmistelee testitietojoukon näytepäätelmien tekemiseksi hienosäädetyn mallin kanssa.
- Muuta ja valvo – Suorita eräpäättely ja määritä tietojen laatu mallin valvonnalla, jotta saat perustietojoukon ehdotuksen.
Käytä muistikirjoja
Tämän ratkaisun mallikoodi on saatavilla osoitteessa GitHub.
SageMaker-muistikirjan työvaiheen luominen on samanlainen kuin muiden SageMaker-putkilinjan vaiheiden luominen. Tässä muistikirjaesimerkissä käytämme SageMaker Python SDK:ta työnkulun järjestämiseen. Voit luoda muistikirjan vaiheen SageMaker Pipelinesissä määrittämällä seuraavat parametrit:
- Syötä muistikirja – Sen muistikirjan nimi, jota tämä muistikirjan vaihe ohjaa. Täällä voit siirtyä paikalliseen polkuun syöttömuistikirjaan. Vaihtoehtoisesti, jos tällä muistikirjalla on muita käynnissä olevia muistikirjoja, voit siirtää ne eteenpäin
AdditionalDependenciesmuistikirjan työvaiheen parametri. - Kuvan URI – Docker-kuva kannettavan tietokoneen työvaiheen takana. Tämä voi olla ennalta määritettyjä kuvia, jotka SageMaker jo tarjoaa, tai mukautettu kuva, jonka olet määrittänyt ja siirtänyt siihen Amazonin elastisten säiliörekisteri (Amazon ECR). Katso tuetut kuvat tämän viestin lopussa olevasta huomioista.
- Ytimen nimi – SageMaker Studiossa käyttämäsi ytimen nimi. Tämä ytimen tiedot on rekisteröity antamaasi kuvatiedostoon.
- Ilmentymän tyyppi (valinnainen) - Amazonin elastinen laskentapilvi (Amazon EC2) ilmentymätyyppi määrittämäsi ja ajettavan kannettavan työn takana.
- Parametrit (valinnainen) – Parametrit, jotka voit antaa ja jotka ovat käytettävissä kannettavassasi. Nämä voidaan määritellä avainarvo-pareina. Lisäksi näitä parametreja voidaan muokata erilaisten muistikirjan työajojen tai liukuhihnaajojen välillä.
Esimerkissämme on yhteensä viisi muistikirjaa:
- nb-job-pipeline.ipynb – Tämä on päämuistikirjamme, jossa määritämme prosessimme ja työnkulkumme.
- preprocess.ipynb – Tämä muistikirja on ensimmäinen askel työnkulussamme ja sisältää koodin, joka vetää julkisen AWS-tietojoukon ja luo siitä CSV-tiedoston.
- koulutus.ipynb – Tämä muistikirja on työnkulkumme toinen vaihe, ja se sisältää koodin edellisen vaiheen CSV:n ottamiseksi ja paikallisen koulutuksen ja hienosäädön suorittamiseksi. Tämä vaihe on myös riippuvainen
prepare-test-set.ipynbmuistikirja vetääksesi alas testitietojoukon näytepäätelmien tekemiseksi hienosäädetystä mallista. - ready-test-set.ipynb – Tämä muistikirja luo testitietojoukon, jota harjoitusmuistikirjamme käyttää toisessa liukuhihnavaiheessa ja käyttää näytepäätelmien tekemiseen hienosäädetyn mallin kanssa.
- transform-monitor.ipynb – Tämä muistikirja on kolmas vaihe työnkulussamme, ja se käyttää BERT-perusmallia ja suorittaa SageMaker-erämuunnostyön sekä määrittää tietojen laadun mallinvalvonnan avulla.
Seuraavaksi käymme läpi päämuistikirjan nb-job-pipeline.ipynb, joka yhdistää kaikki alamuistikirjat liukuhihnaksi ja suorittaa työnkulun päästä päähän. Huomaa, että vaikka seuraava esimerkki suorittaa muistikirjan vain kerran, voit myös ajoittaa liukuhihnan suorittamaan muistikirjan toistuvasti. Viitata SageMaker-ohjeet yksityiskohtaisia ohjeita.
Ensimmäisessä kannettavan tietokoneen työvaiheessa välitämme parametrin oletusarvoisen S3-alueen kanssa. Voimme käyttää tätä ämpäriä tyhjentämään mitä tahansa artefakteja, jotka haluamme saataville muita putkilinjan vaiheita varten. Ensimmäiselle muistikirjalle (preprocess.ipynb), vedämme AWS:n julkisen SST2-junatietojoukon alas ja luomme siitä koulutus-CSV-tiedoston, jonka siirrämme tähän S3-ämpäriin. Katso seuraava koodi:
Voimme sitten muuntaa tämän muistikirjan a NotebookJobStep seuraavalla koodilla päämuistikirjassamme:
Nyt kun meillä on malli-CSV-tiedosto, voimme aloittaa mallimme harjoittamisen harjoitusmuistikirjassamme. Harjoitusmuistikirjamme ottaa saman parametrin S3-ämpäriin ja vetää harjoitustietojoukon alas tästä paikasta. Sitten suoritamme hienosäädön käyttämällä Transformers trainer -objektia seuraavan koodinpätkän kanssa:
Hienosäädön jälkeen haluamme suorittaa eräpäätelmän nähdäksemme kuinka malli toimii. Tämä tehdään erillisellä muistikirjalla (prepare-test-set.ipynb) samassa paikallisessa polussa, joka luo testitietojoukon päättelemään koulutetun mallimme käyttöä. Voimme käyttää lisämuistikirjaa harjoitusmuistikirjassamme seuraavalla taikasolulla:
Määrittelemme tämän kannettavan tietokoneen ylimääräisen riippuvuuden kohdassa AdditionalDependencies parametri toisessa kannettavan työvaiheessamme:
Meidän on myös määritettävä, että harjoitusmuistikirjan työvaihe (vaihe 2) riippuu muistikirjan esikäsittelytyövaiheesta (vaihe 1) käyttämällä add_depends_on API-kutsu seuraavasti:
Viimeinen vaiheemme on, että BERT-malli suorittaa SageMaker Batch Transform -muunnoksen, samalla kun määrität tiedonkeruun ja laadun SageMaker Model Monitorin avulla. Huomaa, että tämä on eri asia kuin sisäänrakennetun laitteen käyttäminen Muuttaa or kaapata vaiheet putkilinjojen kautta. Tämän vaiheen muistikirjamme suorittaa samat API:t, mutta sitä seurataan muistikirjan työvaiheena. Tämä vaihe riippuu aiemmin määrittämästämme koulutustyövaiheesta, joten kuvaamme sen myös riippuvaisen_on-lipun avulla.
Kun työnkulkumme eri vaiheet on määritetty, voimme luoda ja suorittaa päästä päähän -putken:
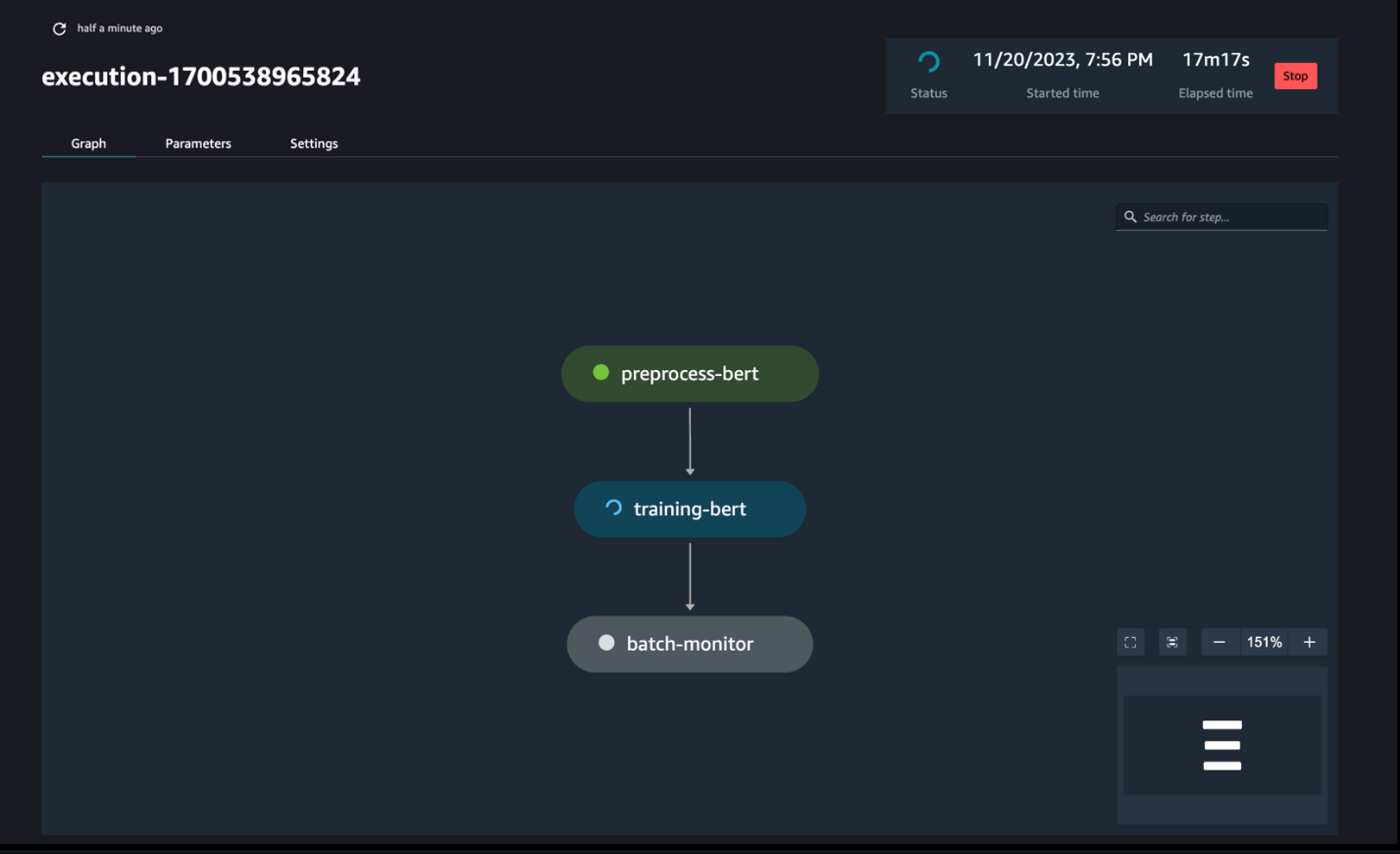
Tarkkaile putkilinjan kulkua
Voit seurata ja valvoa muistikirjan vaiheita SageMaker Pipelines DAG:n kautta, kuten seuraavassa kuvakaappauksessa näkyy.
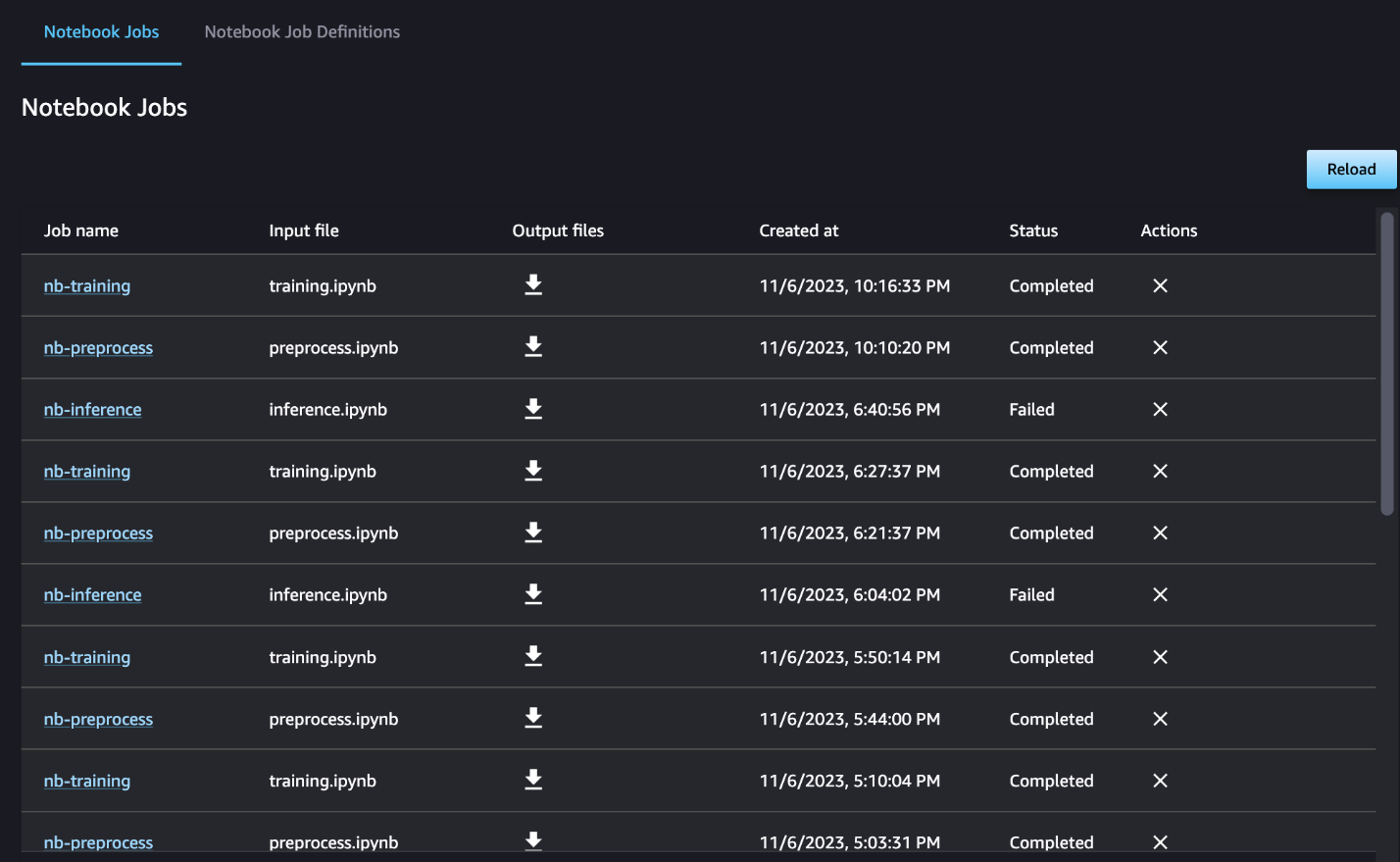
Voit myös halutessasi seurata yksittäisiä muistikirjan ajoja muistikirjan työn kojelaudassa ja vaihtaa SageMaker Studion käyttöliittymän kautta luotuja tulostiedostoja. Kun käytät tätä toimintoa SageMaker Studion ulkopuolella, voit määrittää käyttäjät, jotka voivat seurata ajon tilaa muistikirjan töiden hallintapaneelissa tunnisteiden avulla. Lisätietoja sisällytettävistä tunnisteista on kohdassa Tarkastele muistikirjatöitäsi ja lataa tulosteita Studion käyttöliittymän kojelaudassa.
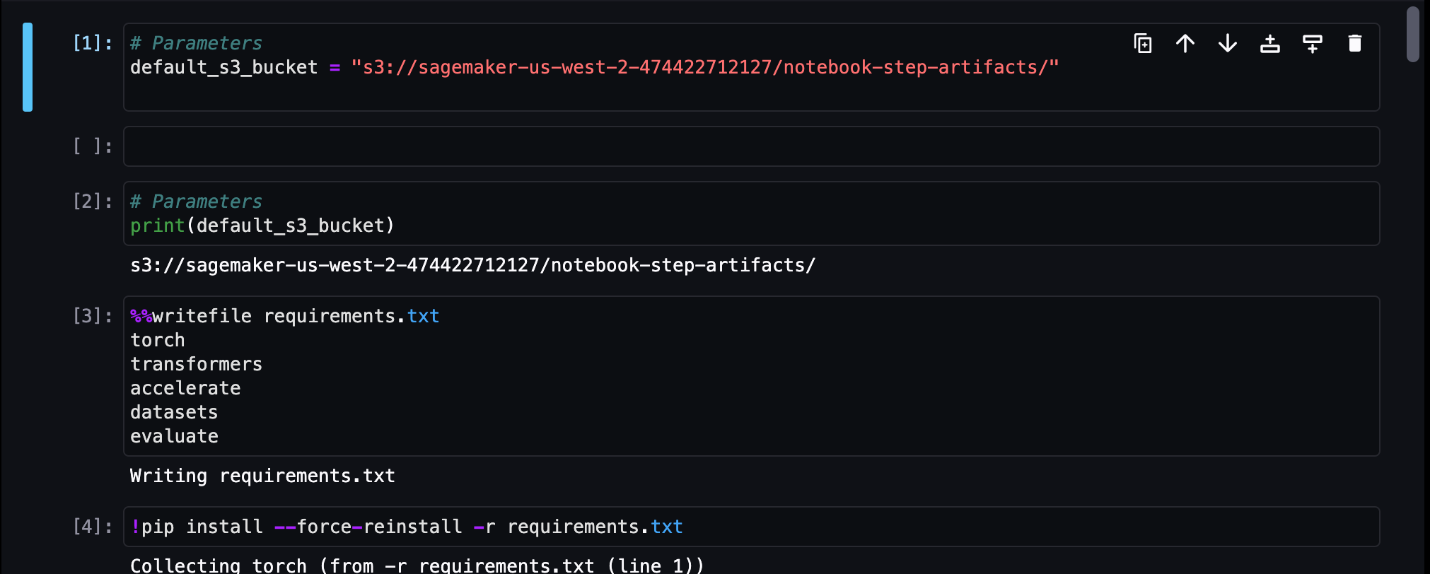
Tässä esimerkissä tulostamme tuloksena saadut muistikirjatyöt hakemistoon nimeltä outputs paikallisella polullasi putkilinjan ajokoodin kanssa. Kuten seuraavassa kuvakaappauksessa näkyy, tässä näet syöttömuistikirjan tulosteen ja myös kaikki kyseiselle vaiheelle määrittämäsi parametrit.
Puhdistaa
Jos noudatit esimerkkiämme, muista poistaa luotu liukuhihna, muistikirjatyöt ja esimerkkimuistikirjojen lataamat s3-tiedot.
Huomioita
Seuraavassa on joitain tärkeitä huomioita tästä ominaisuudesta:
- SDK-rajoitukset – Muistikirjan työvaihe voidaan luoda vain SageMaker Python SDK:n kautta.
- Kuvan rajoitukset – Muistikirjan työvaihe tukee seuraavia kuvia:
Yhteenveto
Tämän julkaisun myötä datatyöntekijät voivat nyt ohjelmallisesti käyttää muistikirjojaan muutamalla koodirivillä käyttämällä SageMaker Python SDK. Lisäksi voit luoda monimutkaisia monivaiheisia työnkulkuja kannettavien tietokoneiden avulla, mikä vähentää merkittävästi aikaa, joka kuluu siirtymiseen kannettavasta tietokoneesta CI/CD-putkiin. Liukuhihnan luomisen jälkeen voit käyttää SageMaker Studiota tarkastellaksesi ja suorittaaksesi DAG:ita putkistollesi sekä hallita ja vertailla ajoja. Olitpa ajoittamassa päästä päähän ML-työnkulkuja tai osaa niistä, suosittelemme kokeilemaan muistikirjapohjaisia työnkulkuja.
Tietoja kirjoittajista
 Anchit Gupta on vanhempi tuotepäällikkö Amazon SageMaker Studiossa. Hän keskittyy vuorovaikutteisten datatieteen ja tietotekniikan työnkulkujen mahdollistamiseen SageMaker Studio IDE:ssä. Vapaa-ajallaan hän nauttii ruoanlaitosta, lauta-/korttipelien pelaamisesta ja lukemisesta.
Anchit Gupta on vanhempi tuotepäällikkö Amazon SageMaker Studiossa. Hän keskittyy vuorovaikutteisten datatieteen ja tietotekniikan työnkulkujen mahdollistamiseen SageMaker Studio IDE:ssä. Vapaa-ajallaan hän nauttii ruoanlaitosta, lauta-/korttipelien pelaamisesta ja lukemisesta.
 Ram Vegiraju on ML-arkkitehti SageMaker Service -tiimin kanssa. Hän keskittyy auttamaan asiakkaita rakentamaan ja optimoimaan AI/ML-ratkaisujaan Amazon SageMakerissa. Vapaa-ajallaan hän rakastaa matkustamista ja kirjoittamista.
Ram Vegiraju on ML-arkkitehti SageMaker Service -tiimin kanssa. Hän keskittyy auttamaan asiakkaita rakentamaan ja optimoimaan AI/ML-ratkaisujaan Amazon SageMakerissa. Vapaa-ajallaan hän rakastaa matkustamista ja kirjoittamista.
 Edward Sun on vanhempi SDE, joka työskentelee SageMaker Studiossa Amazon Web Services -palvelussa. Hän on keskittynyt rakentamaan interaktiivista ML-ratkaisua ja yksinkertaistamaan asiakaskokemusta integroidakseen SageMaker Studion suosittuihin tietotekniikan ja ML-ekosysteemin teknologioihin. Vapaa-ajallaan Edward on suuri retkeily-, vaellus- ja kalastusfani ja nauttii perheensä kanssa viettämisestä.
Edward Sun on vanhempi SDE, joka työskentelee SageMaker Studiossa Amazon Web Services -palvelussa. Hän on keskittynyt rakentamaan interaktiivista ML-ratkaisua ja yksinkertaistamaan asiakaskokemusta integroidakseen SageMaker Studion suosittuihin tietotekniikan ja ML-ekosysteemin teknologioihin. Vapaa-ajallaan Edward on suuri retkeily-, vaellus- ja kalastusfani ja nauttii perheensä kanssa viettämisestä.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :on
- :On
- :missä
- $ YLÖS
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Meistä
- saatavilla
- asykliset
- lisä-
- Lisäksi
- Etu
- Jälkeen
- AI / ML
- Kaikki
- mahdollistaa
- pitkin
- jo
- Myös
- Vaikka
- Amazon
- Amazon EC2
- Amazon Sage Maker
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analyysi
- analysointi
- ja
- Kaikki
- api
- API
- sovellukset
- arkkitehtuuri
- OVAT
- AS
- At
- automatisoida
- saatavissa
- AWS
- pohja
- perustua
- Lähtötilanne
- BE
- kaunis
- ollut
- takana
- ovat
- Paremmin
- välillä
- Iso
- rakentaa
- Rakentaminen
- sisäänrakennettu
- mutta
- by
- soittaa
- nimeltään
- retkeily
- CAN
- kaapata
- tapaus
- tapauksissa
- solu
- merkkejä
- luokittelu
- koodi
- Sarake
- Pylväät
- yhdistää
- Tulla
- Yhteinen
- verrata
- täydellinen
- monimutkainen
- kokoonpanossa
- Sisältää
- Laskea
- Suorittaa
- kytketty
- näkökohdat
- muodostuu
- Kontti
- sisältää
- jatkuva
- muuntaa
- muunnetaan
- ruoanlaitto
- vastaava
- voisi
- luoda
- luotu
- luo
- Luominen
- Tällä hetkellä
- asiakassuhde
- asiakas
- asiakaskokemus
- Asiakaspalvelu
- Asiakkaat
- PÄIVÄ
- kojelauta
- tiedot
- tietojen seuranta
- Tietojen valmistelu
- tietojenkäsittely
- tiedon laatu
- tietojenkäsittely
- aineistot
- oletusarvo
- määritellä
- määritelty
- toimitus
- Kysyntä
- riippuvuudet
- riippuvuus
- riippuvainen
- riippuu
- sijoittaa
- levityspinnalta
- yksityiskohtainen
- yksityiskohdat
- kehittää
- kehitetty
- eri
- ohjata
- suunnattu
- Johtaja
- selvä
- Satamatyöläinen
- tekee
- tehty
- alas
- download
- dumpata
- kukin
- helposti
- ekosysteemi
- Edward
- mahdollistaa
- mahdollistaa
- kannustaa
- loppu
- päittäin
- Tekniikka
- Koko
- aikakausi
- Eetteri (ETH)
- esimerkki
- suorittaa
- teloitus
- experience
- lisää
- uute
- perhe
- tuuletin
- paljon
- Ominaisuus
- palaute
- harvat
- filee
- Asiakirjat
- Elokuva
- elokuvantekijät
- Etunimi
- Kalastus
- viisi
- keskityttiin
- keskittyy
- seurannut
- jälkeen
- seuraa
- varten
- muoto
- muoto
- alkaen
- täysin
- toiminnallisuus
- Lisäksi
- Pelit
- tuottaa
- kaaviot
- Olla
- he
- auttaa
- auttaa
- hänen
- tätä
- retkeily
- hänen
- Hollywood
- Miten
- HTML
- http
- HTTPS
- ihmisen
- if
- havainnollistaa
- kuva
- kuvien
- heti
- tuoda
- tärkeä
- in
- sisältää
- itsenäinen
- ilmaisee
- henkilökohtainen
- panos
- esimerkki
- ohjeet
- yhdistää
- integraatio
- vuorovaikutteinen
- tulee
- IT
- SEN
- Job
- Työpaikat
- jpg
- vain
- Merkki
- tarrat
- Sukunimi
- käynnistää
- oppiminen
- kirjastot
- linja
- linjat
- kuormitus
- paikallinen
- sijainti
- Pitkät
- rakastaa
- kone
- koneoppiminen
- taika-
- tärkein
- TEE
- hoitaa
- onnistui
- johto
- johtaja
- Media
- Ansio
- ehkä
- ML
- malli
- mallit
- muokattu
- Moduulit
- monitori
- seuranta
- näytöt
- lisää
- eniten
- liikkua
- elokuva
- moninkertainen
- täytyy
- nimi
- syntyperäinen
- Tarve
- tarvitaan
- negatiivinen
- Uusi
- Nro
- huomata
- muistikirja
- kannettavat tietokoneet
- nyt
- objekti
- of
- usein
- on
- ONE
- vain
- Optimoida
- or
- orkestrointi
- Muut
- meidän
- ulos
- ulostulo
- lähdöt
- ulkopuolella
- paria
- parametri
- parametrit
- osa
- kulkea
- Ohimenevä
- polku
- suorittaa
- esittävä
- henkilöstö
- putki
- Platon
- Platonin tietotieto
- PlatonData
- pelaa
- Suosittu
- positiivinen
- Kirje
- ennustaa
- valmistelu
- Valmistella
- valmistelee
- valmistelee
- edellinen
- aiemmin
- Ongelma
- käsittely
- Tuotteet
- tuotepäällikkö
- toimittaa
- mikäli
- tarjoaa
- julkinen
- Vetää
- tarkoituksiin
- Työnnä
- työntää
- Python
- laatu
- nopeammin
- R
- pikemminkin
- Lue
- Lukeminen
- toistuva
- vähentämällä
- Refaktori
- katso
- kirjattu
- säännöllisesti
- jäädä
- TOISTUVASTI
- edellyttää
- Saatu ja
- arviot
- Arvostelut
- ajaa
- juoksu
- toimii
- sagemaker
- SageMaker-putkistot
- sama
- vakuuttunut
- aikataulu
- suunniteltu
- Suunnitellut työt
- aikataulutus
- tiede
- tutkijat
- sdk
- Toinen
- Osa
- osiot
- nähdä
- nähneet
- vanhempi
- näkemys
- erillinen
- palvelu
- Palvelut
- Istunto
- setti
- asetus
- useat
- muotoinen
- hän
- shouldnt
- näyttää
- näyteikkuna
- esitetty
- Näytä
- merkittävä
- merkittävästi
- samankaltainen
- Yksinkertainen
- yksinkertaistaminen
- single
- pieni
- pienempiä
- pätkä
- So
- sosiaalinen
- sosiaalinen media
- ratkaisu
- Ratkaisumme
- SOLVE
- jonkin verran
- jotain
- Tila
- erityinen
- menot
- itsenäinen
- Stanford
- Alkaa
- Tila
- Vaihe
- Askeleet
- Yhä
- Levytila
- suora
- studio
- niin
- aurinko
- tuki
- Tuetut
- Tukee
- varma
- ottaa
- vie
- Tehtävä
- tehtävät
- joukkue-
- Technologies
- testi
- teksti
- Tekstiluokitus
- että
- -
- heidän
- Niitä
- sitten
- Nämä
- kolmas
- tätä
- ne
- kolmella
- Kautta
- aika
- että
- yhdessä
- liian
- työkalu
- Yhteensä
- raita
- Juna
- koulutettu
- koulutus
- Muuttaa
- muuntajat
- Matkustaminen
- laukaista
- VUORO
- kaksi
- tyyppi
- ui
- ymmärtää
- Päivitykset
- us
- käyttää
- käyttölaukku
- käytetty
- Käyttäjät
- käyttötarkoituksiin
- käyttämällä
- Hyödyntämällä
- arvot
- eri
- kautta
- Näytä
- havainnollistaa
- kävellä
- haluta
- we
- verkko
- verkkopalvelut
- kun
- onko
- joka
- vaikka
- KUKA
- tulee
- with
- sisällä
- ilman
- työntekijöitä
- työnkulku
- työnkulkuja
- työskentely
- pahin
- kirjoittaminen
- te
- Sinun
- zephyrnet