Samalla kun Roblox on kasvanut yli 16 vuoden aikana, on kasvanut miljoonia mukaansatempaavia 3D-yhteiskokemuksia tukevan teknisen infrastruktuurin laajuus ja monimutkaisuus. Tukemiemme koneiden määrä on yli kolminkertaistunut viimeisen kahden vuoden aikana, noin 36,000 30:sta 2021 mennessä lähes 145,000 1,000:een tänään. Näiden aina päällä olevien elämysten tukeminen ihmisille kaikkialla maailmassa vaatii yli XNUMX sisäistä palvelua. Auttaaksemme meitä hallitsemaan kustannuksia ja verkon latenssia otamme käyttöön ja hallitsemme näitä koneita osana räätälöityä ja hybridi-yksityistä pilviinfrastruktuuria, joka toimii ensisijaisesti tiloissa.
Infrastruktuurimme tukee tällä hetkellä yli 70 miljoonaa päivittäistä aktiivista käyttäjää ympäri maailmaa, mukaan lukien sisällöntuottajat, jotka luottavat Robloxin talous yrityksilleen. Kaikki nämä miljoonat ihmiset odottavat erittäin korkeaa luotettavuutta. Kokemustemme mukaansatempaavan luonteen vuoksi viiveet tai latenssit sietävät erittäin vähän, puhumattakaan katkoksista. Roblox on kommunikaatio- ja yhteydenpitoalusta, jossa ihmiset kohtaavat mukaansatempaavia 3D-kokemuksia. Kun ihmiset kommunikoivat avatareina mukaansatempaavassa tilassa, pienetkin viiveet tai häiriöt ovat havaittavissa paremmin kuin tekstiketjussa tai neuvottelupuhelussa.
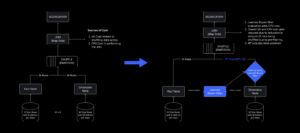
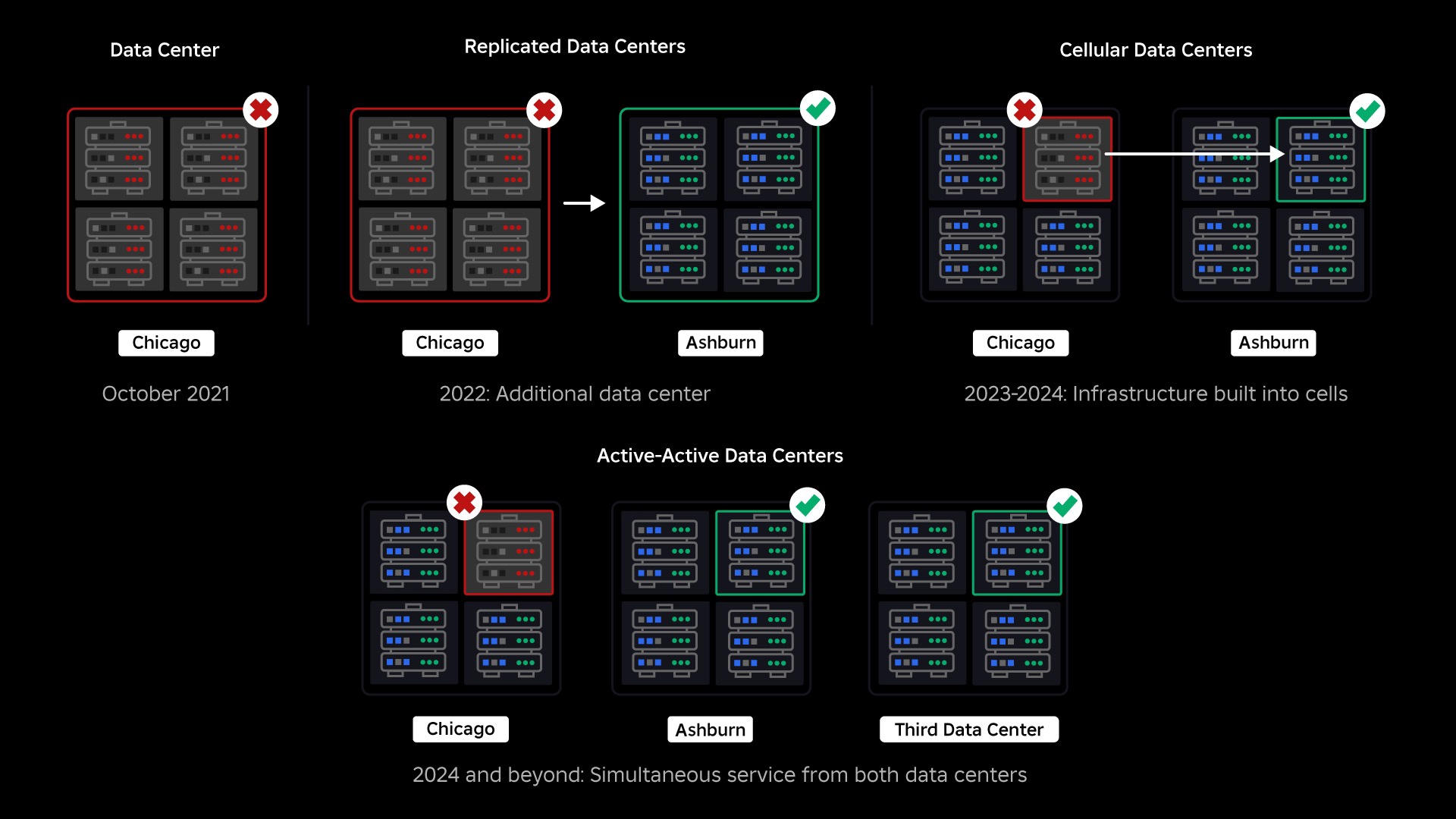
Lokakuussa 2021 koimme järjestelmän laajuisen käyttökatkon. Se alkoi pienestä, yhden palvelinkeskuksen yhdessä komponentissa oli ongelma. Mutta se levisi nopeasti tutkiessamme ja johti lopulta 73 tunnin seisokkiin. Tuolloin jaoimme molemmat yksityiskohtia tapahtuneesta ja joitain varhaisista oppimistamme ongelmasta. Siitä lähtien olemme tutkineet näitä oppeja ja pyrkineet lisäämään infrastruktuurimme kestävyyttä kaikissa suurissa järjestelmissä ilmeneville häiriötyypeille, jotka johtuvat tekijöistä, kuten äärimmäisistä liikennepiikistä, säästä, laitteistovioista, ohjelmistovirheistä tai vain ihmiset tekevät virheitä. Kun näitä vikoja ilmenee, miten voimme varmistaa, että yksittäisen komponentin tai komponenttiryhmän ongelma ei leviä koko järjestelmään? Tämä kysymys on ollut keskiössämme viimeiset kaksi vuotta, ja vaikka työ on käynnissä, tähän mennessä tekemämme on jo tuottanut tulosta. Esimerkiksi vuoden 2023 ensimmäisellä puoliskolla säästimme 125 miljoonaa sitoutumistuntia kuukaudessa vuoden 2022 ensimmäiseen puoliskoon verrattuna. Tänään jaamme jo tekemämme työn sekä pidemmän aikavälin visiomme rakentamisesta kestävämpi infrastruktuurijärjestelmä.
Backstopin rakentaminen
Suurissa infrastruktuurijärjestelmissä pieniä vikoja tapahtuu monta kertaa päivässä. Jos yhdessä koneessa on ongelma ja se on poistettava käytöstä, se on hallittavissa, koska useimmat yritykset ylläpitävät useita taustapalveluitaan. Joten kun yksittäinen esiintymä epäonnistuu, muut ottavat työtaakan. Näiden toistuvien virheiden korjaamiseksi pyynnöt asetetaan yleensä yrittämään automaattisesti uudelleen, jos ne saavat virheen.
Tästä tulee haastavaa, kun järjestelmä tai henkilö yrittää uudelleen liian aggressiivisesti, mikä voi olla tapa pienimuotoisille epäonnistumisille levitä koko infrastruktuurin kautta muihin palveluihin ja järjestelmiin. Jos verkko tai käyttäjä yrittää tarpeeksi jatkuvasti uudelleen, se ylikuormittaa lopulta kyseisen palvelun jokaisen esiintymän ja mahdollisesti myös muut järjestelmät maailmanlaajuisesti. Vuoden 2021 katkoksemme oli seurausta jostakin, joka on melko yleistä suurissa järjestelmissä: vika alkaa pienestä ja leviää sitten järjestelmän läpi ja kasvaa niin nopeasti, että sitä on vaikea ratkaista ennen kuin kaikki kaatuu.
Katkoshetkellä meillä oli yksi aktiivinen palvelinkeskus (jossa sen sisällä olevat komponentit toimivat varmuuskopioina). Tarvitsimme mahdollisuuden siirtyä manuaalisesti uuteen palvelinkeskukseen, kun ongelma kaatui nykyisen. Ensimmäinen prioriteettimme oli varmistaa, että meillä on Robloxin varmuuskopiointi, joten rakensimme varmuuskopion uuteen palvelinkeskukseen, joka sijaitsee eri maantieteellisellä alueella. Tämä lisäsuojaa pahimmalle mahdolliselle skenaariolle: katkos leviää niin paljon konesalin komponentteihin, että siitä tulee täysin käyttökelvoton. Meillä on nyt yksi palvelinkeskus, joka käsittelee työkuormia (aktiivinen) ja yksi valmiustilassa, joka toimii varmuuskopiona (passiivinen). Pitkän aikavälin tavoitteemme on siirtyä tästä aktiivi-passiivisesta kokoonpanosta aktiiviseen-aktiiviseen kokoonpanoon, jossa molemmat palvelinkeskukset käsittelevät työkuormia, ja kuormituksen tasapainotin jakaa pyynnöt niiden välillä latenssin, kapasiteetin ja kunnon perusteella. Kun tämä on paikoillaan, odotamme koko Robloxin olevan vieläkin korkeampi luotettavuus ja pystymme epäonnistumaan lähes välittömästi useiden tuntien sijaan. 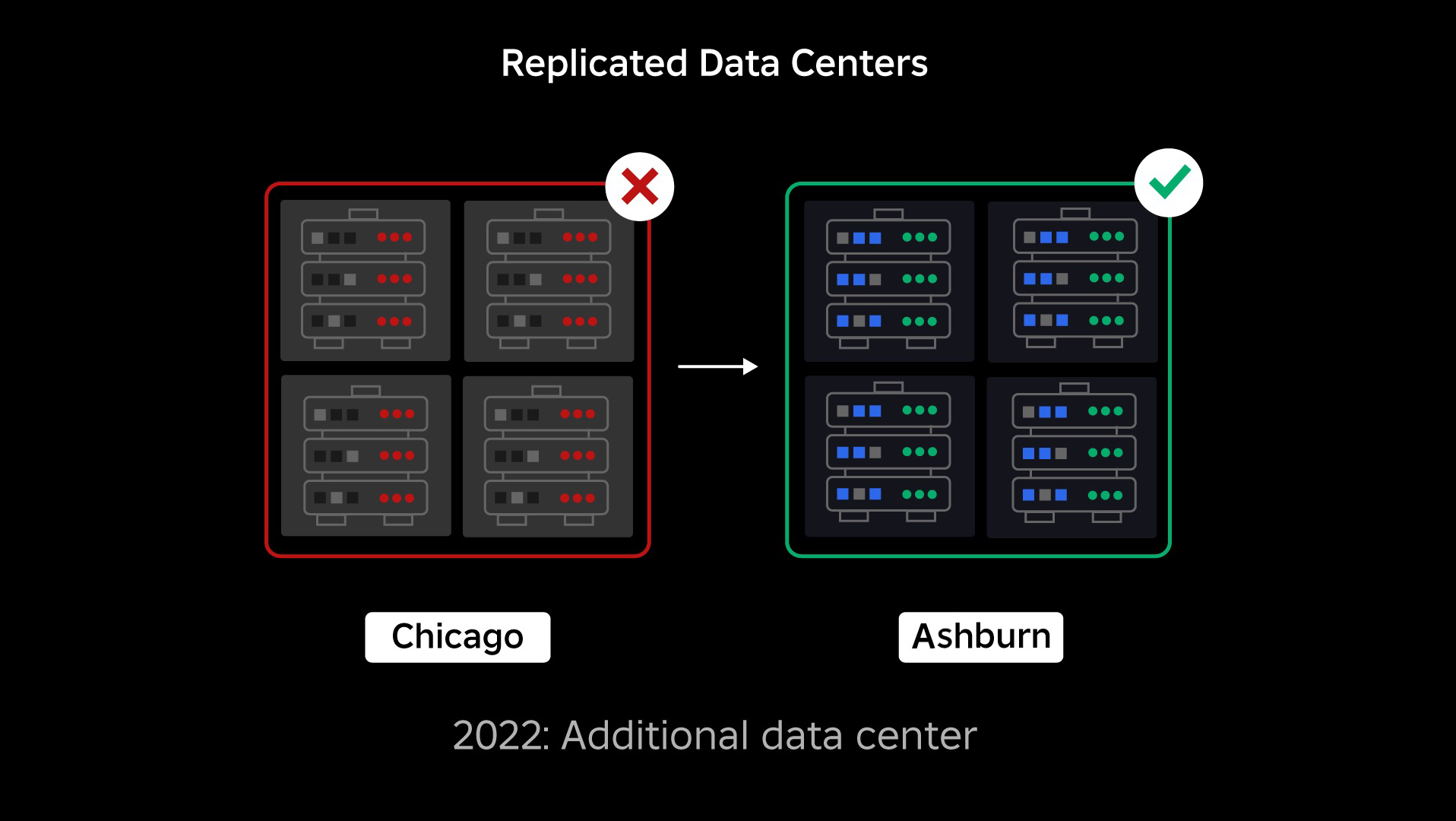
Siirtyminen matkapuhelininfrastruktuuriin
Seuraava prioriteettimme oli luoda vahvat räjähdysseinät jokaisen palvelinkeskuksen sisään vähentääksemme mahdollisuutta, että koko palvelinkeskus epäonnistuu. Solut (jotkut yritykset kutsuvat niitä klustereiksi) ovat pohjimmiltaan joukko koneita, ja niiden avulla luomme nämä seinät. Toistamme palvelut sekä solujen sisällä että niiden välillä lisäten redundanssia. Lopulta haluamme, että kaikki Robloxin palvelut toimivat soluissa, jotta ne voivat hyötyä sekä vahvoista räjähdysseinistä että redundanssista. Jos solu ei enää toimi, se voidaan turvallisesti deaktivoida. Solujen välinen replikointi mahdollistaa palvelun jatkamisen, kun solua korjataan. Joissakin tapauksissa solun korjaus voi tarkoittaa solun täydellistä uudelleenjärjestelyä. Yksittäisen koneen tai pienen konejoukon pyyhkiminen ja uudelleenkäyttö on eri teollisuudenaloilla melko yleistä, mutta näin tekeminen koko solulle, joka sisältää ~1,400 XNUMX konetta, ei ole.
Jotta tämä toimisi, näiden solujen on oltava suurelta osin yhtenäisiä, jotta voimme siirtää työkuormia nopeasti ja tehokkaasti solusta toiseen. Olemme asettaneet tiettyjä vaatimuksia, jotka palveluiden on täytettävä, ennen kuin ne toimivat solussa. Palvelut on esimerkiksi säilytettävä säiliöissä, mikä tekee niistä paljon kannettavampia ja estää ketään tekemästä konfiguraatiomuutoksia käyttöjärjestelmätasolla. Olemme omaksuneet soluille infrastruktuurin koodina -filosofian: sisällytämme lähdekoodivarastoon määritelmän kaikesta solussa olevasta, jotta voimme rakentaa sen nopeasti uudelleen alusta käyttämällä automaattisia työkaluja.
Kaikki palvelut eivät tällä hetkellä täytä näitä vaatimuksia, joten olemme pyrkineet auttamaan palvelujen omistajia täyttämään ne mahdollisuuksien mukaan, ja olemme rakentaneet uusia työkaluja, joiden avulla palveluiden siirtäminen soluihin on helppoa, kun se on valmis. Esimerkiksi uusi käyttöönottotyökalumme "raidoi" automaattisesti palvelun käyttöönoton solujen välillä, joten palvelun omistajien ei tarvitse miettiä replikointistrategiaa. Tämä kurinalaisuus tekee siirtoprosessista paljon haastavamman ja aikaa vievämmän, mutta pitkän aikavälin voitto on järjestelmä, jossa:
- On paljon helpompaa hillitä vika ja estää sen leviäminen muihin soluihin;
- Infrastruktuuriinsinöörimme voivat olla tehokkaampia ja liikkua nopeammin; ja
- Insinöörien, jotka rakentavat tuotetason palvelut, jotka lopulta otetaan käyttöön soluissa, ei tarvitse tietää tai huolehtia siitä, missä soluissa heidän palvelunsa toimivat.
Isompien haasteiden ratkaiseminen
Samoin kuin palo-ovia käytetään hillitsemään liekkejä, solut toimivat vahvoina räjähdysseininä infrastruktuurissamme, mikä auttaa pitämään hallinnassa minkä tahansa ongelman, joka laukaisee vian yhdessä solussa. Lopulta kaikki Robloxin muodostavat palvelut otetaan käyttöön redundantti solujen sisällä ja niiden välillä. Kun tämä työ on valmis, ongelmat voivat silti levitä riittävän laajalle, jotta koko solu ei toimi, mutta ongelman olisi erittäin vaikeaa levitä solun ulkopuolelle. Ja jos onnistumme tekemään soluista vaihdettavia, palautuminen on huomattavasti nopeampaa koska voimme siirtyä toiseen soluun ja estää ongelman vaikuttamasta loppukäyttäjiin.
Tämä on hankalaa, kun nämä solut erotetaan toisistaan riittävästi, jotta virheiden leviämisen mahdollisuus vähenee samalla kun asiat pysyvät toimivina ja toimivina. Monimutkaisessa infrastruktuurijärjestelmässä palvelujen on kommunikoitava toistensa kanssa kyselyjen, tietojen, työkuormien jne. jakamiseksi. Kun kopioimme nämä palvelut soluiksi, meidän on harkittava, kuinka hallitsemme ristiinviestintää. Ihanteellisessa maailmassa ohjaamme liikennettä yhdestä epäterveestä solusta muihin terveisiin soluihin. Mutta kuinka me hallitsemme "kuoleman kyselyn" - sellaisen aiheuttaen solu olla epäterveellinen? Jos ohjaamme kyselyn toiseen soluun, se voi aiheuttaa sen, että solu muuttuu epäterveeksi juuri sillä tavalla, jota yritämme välttää. Meidän on löydettävä mekanismeja "hyvän" liikenteen siirtämiseksi epäterveellisistä soluista samalla, kun havaitaan ja tukahdutetaan liikenne, joka aiheuttaa solujen epäterveellistä kehitystä.
Lyhyellä aikavälillä olemme ottaneet käyttöön kopiot laskentapalveluista jokaiseen laskentasoluun, jotta useimmat palvelinkeskuksen pyynnöt voidaan palvella yhdellä solulla. Jaamme myös kuormitusta solujen välillä. Tarkasteltaessa pidemmälle olemme alkaneet rakentaa seuraavan sukupolven palveluiden etsintäprosessia, jota hyödyntää palveluverkko, jonka toivomme saavan päätökseen vuonna 2024. Tämän ansiosta voimme ottaa käyttöön kehittyneitä käytäntöjä, jotka mahdollistavat solujen välisen viestinnän vain silloin, kun se ei vaikuta negatiivisesti vikasietosoluihin. Vuonna 2024 on myös tulossa menetelmä riippuvien pyyntöjen ohjaamiseksi samassa solussa olevaan palveluversioon, mikä minimoi solujen välisen liikenteen ja vähentää siten virheiden solujen välisen leviämisen riskiä.
Huipussaan yli 70 prosenttia taustapalveluliikenteestämme palvellaan solujen ulkopuolella, ja olemme oppineet paljon solujen luomisesta, mutta odotamme lisää tutkimusta ja testausta jatkaessamme palveluidemme siirtoa vuoteen 2024 ja pidemmälle. Edistyessämme nämä räjähdysseinät vahvistuvat jatkuvasti.
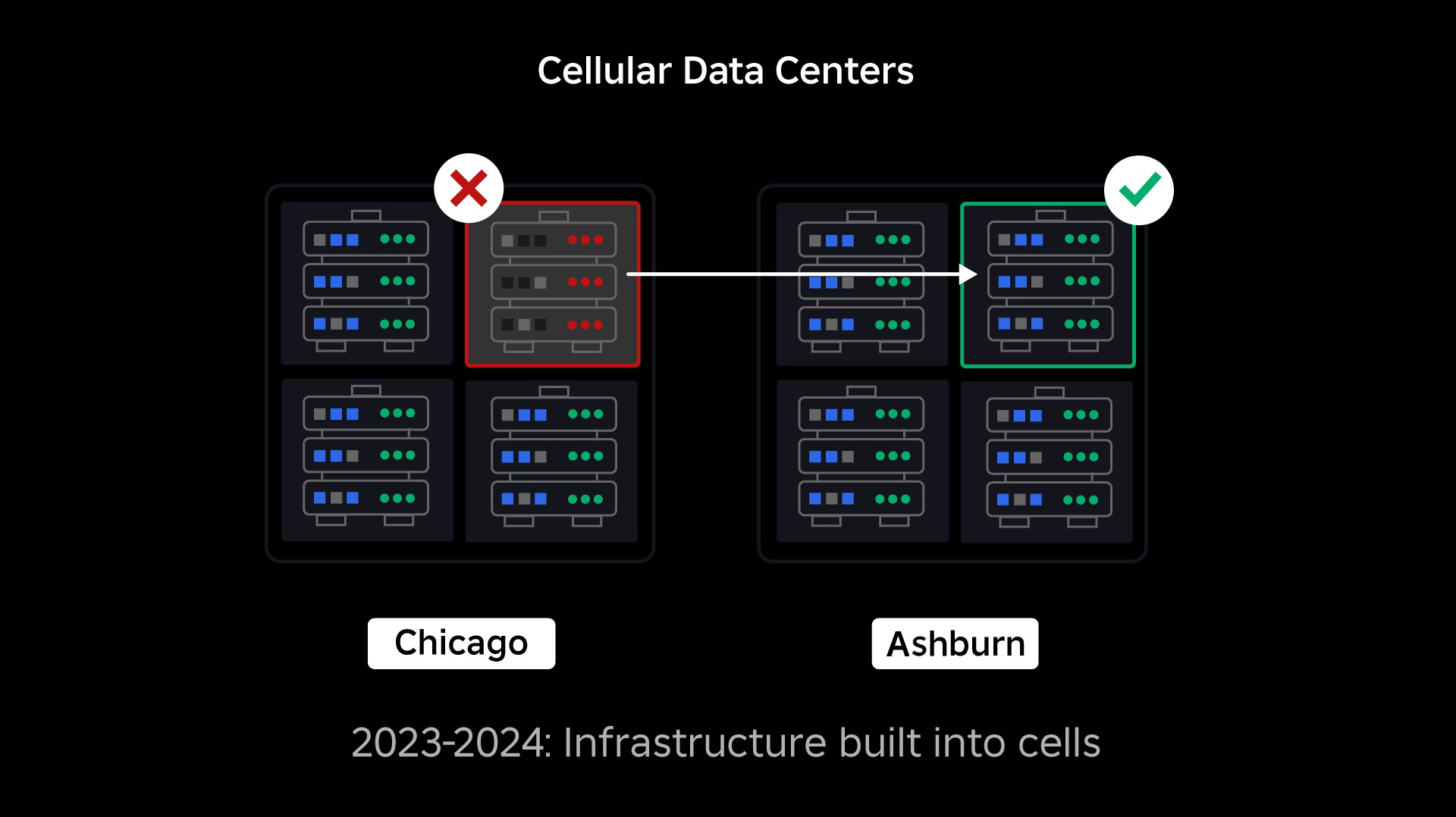
Aina käytössä olevan infrastruktuurin siirto
Roblox on maailmanlaajuinen alusta, joka tukee käyttäjiä kaikkialla maailmassa, joten emme voi siirtää palveluita ruuhka-ajan tai "seisokkien aikana", mikä vaikeuttaa entisestään kaikkien koneidemme siirtämistä soluihin ja palveluitamme toimimaan näissä soluissa. . Meillä on miljoonia aina päällä olevia kokemuksia, joita on edelleen tuettava, vaikka siirrämmekin niitä käyttäviä koneita ja niitä tukevia palveluita. Kun aloitimme tämän prosessin, meillä ei ollut kymmeniä tuhansia koneita, jotka vain istuivat käyttämättöminä ja käytettävissämme siirtämään näitä työkuormia.
Meillä oli kuitenkin pieni määrä lisäkoneita, jotka ostettiin tulevaa kasvua ennakoiden. Aluksi rakensimme uusia soluja näiden koneiden avulla ja siirsimme sitten työkuormat niihin. Arvostamme tehokkuutta ja luotettavuutta, joten sen sijaan, että lähtisimme ostamaan lisää koneita, kun "varakoneet" loppuivat, rakensimme lisää soluja pyyhkimällä ja varaamalla uudelleen koneet, joista olimme siirtyneet. Siirsimme sitten työkuormat uudelleen varustetuille koneille ja aloitimme prosessin alusta. Tämä prosessi on monimutkainen – kun koneita vaihdetaan ja ne vapautuvat rakennettavaksi soluihin, ne eivät vapaudu ihanteellisella ja järjestelmällisellä tavalla. Ne ovat fyysisesti pirstoutuneet tietohalleihin, joten meidän on varattava ne osittaisesti, mikä edellyttää laitteistotason eheytysprosessia, jotta laitteiston sijainnit pysyvät kohdakkain suurien fyysisten vikaalueiden kanssa.
Osa infrastruktuurin suunnittelutiimistämme on keskittynyt siirtämään olemassa olevia työkuormia vanhasta eli "solua edeltävästä" ympäristöstämme soluihin. Tämä työ jatkuu, kunnes olemme siirtäneet tuhansia erilaisia infrastruktuuripalveluita ja tuhansia taustapalveluita hiljattain rakennettuihin soluihin. Odotamme tämän kestävän koko ensi vuoden ja mahdollisesti jopa vuoteen 2025 johtuen joistakin monimutkaisista tekijöistä. Ensinnäkin tämä työ vaatii vahvan työkalun rakentamisen. Tarvitsemme esimerkiksi työkaluja, jotka tasapainottavat automaattisesti suuren määrän palveluita, kun otamme käyttöön uuden solun – vaikuttamatta käyttäjiimme. Olemme myös nähneet palveluita, jotka on rakennettu infrastruktuuriamme koskevilla oletuksilla. Meidän on tarkistettava näitä palveluita, jotta ne eivät ole riippuvaisia asioista, jotka voivat muuttua tulevaisuudessa, kun siirrymme soluihin. Olemme myös ottaneet käyttöön sekä tavan etsiä tunnettuja suunnittelumalleja, jotka eivät toimi hyvin matkapuhelinarkkitehtuurin kanssa, että menetelmällisen testausprosessin jokaiselle siirretylle palvelulle. Nämä prosessit auttavat meitä välttämään käyttäjien kohtaamat ongelmat, jotka johtuvat palvelun yhteensopimattomuudesta solujen kanssa.
Nykyään solujen hallinnassa on lähes 30,000 99.99 konetta. Se on vain murto-osa koko laivastostamme, mutta se on toistaiseksi ollut erittäin sujuvaa ilman negatiivista vaikutusta pelaajiin. Perimmäisenä tavoitteemme on, että järjestelmämme saavuttavat 0.01 prosentin käyttäjien käytettävyyden joka kuukausi, mikä tarkoittaa, että häiritsisimme enintään XNUMX prosenttia käyttötuneista. Toimialan laajuisia seisokkeja ei voida täysin eliminoida, mutta tavoitteemme on vähentää kaikkia Roblox-seisokkeja siinä määrin, että se on lähes huomaamaton.
Tulevaisuuden turvaa skaalautuessamme
Vaikka varhaiset ponnistelumme ovat osoittautuneet onnistuneiksi, työmme solujen parissa on kaukana valmiista. Robloxin skaalautuessa jatkamme työtämme parantaaksemme järjestelmien tehokkuutta ja joustavuutta tämän ja muiden teknologioiden avulla. Menettelyn myötä alustasta tulee entistä kestävämpi ongelmille, ja kaikkien esiintyvien ongelmien pitäisi vähitellen muuttua vähemmän näkyviksi ja häiritseviksi alustamme käyttäjille.
Yhteenvetona, tähän mennessä meillä on:
- Rakensi toisen datakeskuksen ja saavuti onnistuneesti aktiivisen/passiivisen tilan.
- Loimme soluja aktiivisissa ja passiivisissa datakeskuksissamme ja siirsimme onnistuneesti yli 70 prosenttia taustapalveluliikenteestämme näihin soluihin.
- Aseta vaatimukset ja parhaat käytännöt, joita meidän on noudatettava pitääksemme kaikki solut yhtenäisinä jatkaessamme muun infrastruktuurimme siirtoa.
- Aloitti jatkuvan prosessin rakentaa vahvempia "räjähdysseiniä" solujen väliin.
Kun näistä soluista tulee enemmän vaihtokelpoisia, solujen välinen ylikuuluminen vähenee. Tämä avaa meille erittäin mielenkiintoisia mahdollisuuksia valvonnan, vianmäärityksen ja jopa työkuormien automaattisen siirtämisen automatisoinnin lisäämisessä.
Syyskuussa aloitimme myös aktiivisten/aktiivisten kokeilujen suorittamisen palvelinkeskuksissamme. Tämä on toinen mekanismi, jota testaamme parantaaksemme luotettavuutta ja minimoidaksemme vikasietoaikoja. Nämä kokeet auttoivat tunnistamaan useita järjestelmän suunnittelumalleja, jotka liittyvät suurelta osin tietojen saatavuuteen ja joita meidän on työstettävä uudelleen pyrkiessämme muuttumaan täysin aktiiviseksi. Kaiken kaikkiaan kokeilu oli riittävän onnistunut, jotta se jäi toimimaan rajoitetun määrän käyttäjiämme varten.
Olemme innoissamme voidessamme viedä tätä työtä eteenpäin parantaaksemme tehokkuutta ja joustavuutta alustalle. Tämä soluja ja aktiivisesti aktiivista infrastruktuuria koskeva työ yhdessä muiden ponnistelujemme kanssa mahdollistaa sen, että voimme kasvaa luotettavaksi ja tehokkaaksi apuohjelmaksi miljoonille ihmisille ja jatkaa skaalaamista työskennellessämme miljardin ihmisen yhdistämiseksi todellisuudessa. aika.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- kyky
- pystyy
- Meistä
- pääsy
- Saavuttaa
- saavutettu
- poikki
- Toimia
- toimiva
- aktiivinen
- lisä-
- lisä-
- osoite
- hyväksytty
- uudelleen
- aggressiivisesti
- linjassa
- Kaikki
- sallia
- yksin
- pitkin
- jo
- Myös
- an
- ja
- Toinen
- ennakoida
- ennakointi
- Kaikki
- joku
- suunnilleen
- arkkitehtuuri
- OVAT
- noin
- AS
- oletukset
- At
- Automatisoitu
- automaattisesti
- Automaatio
- saatavissa
- avatarit
- välttää
- Back-end
- Varmuuskopiointi
- swing
- tasapainotus
- perustua
- BE
- koska
- tulevat
- tulee
- tulossa
- ollut
- ennen
- alkaneet
- ovat
- hyödyttää
- PARAS
- parhaat käytännöt
- välillä
- Jälkeen
- Iso
- suurempi
- Miljardi
- Blogi
- sekä
- tuoda
- toi
- Bugs
- rakentaa
- Rakentaminen
- rakennettu
- yritykset
- mutta
- Ostaminen
- by
- soittaa
- CAN
- ei voi
- Koko
- tapauksissa
- Aiheuttaa
- aiheutti
- aiheuttaen
- solu
- Solut
- huokoinen
- keskus
- keskuksissa
- tietty
- haastava
- muuttaa
- Muutokset
- lähellä
- pilvi
- pilvi infrastruktuuri
- koodi
- Tulla
- tuleva
- Yhteinen
- tiedottaa
- viestiä
- Viestintä
- Yritykset
- verrattuna
- täydellinen
- täysin
- monimutkainen
- monimutkaisuus
- komponentti
- osat
- Laskea
- tietojenkäsittely
- Konferenssi
- Konfigurointi
- kytkeä
- liitäntä
- sisältää
- sisältää
- jatkaa
- jatkuu
- jatkuva
- ohjaus
- kappaletta
- kustannukset
- voisi
- luoda
- Luominen
- luojat
- Tällä hetkellä
- Erikoisvalmisteinen
- päivittäin
- tiedot
- tietojen käyttö
- Data Center
- datakeskukset
- Päivämäärä
- päivä
- määritelmä
- Aste
- viiveet
- riippua
- riippuvainen
- sijoittaa
- käyttöön
- käyttöönotto
- Malli
- suunnittelumalleja
- DID
- eri
- vaikea
- suuntaamisen
- löytö
- Häiritä
- häiritsevä
- jako-
- do
- ei
- tekee
- verkkotunnuksia
- tehty
- Dont
- ovet
- alas
- seisokkeja
- ajo
- kaksi
- aikana
- kukin
- Varhainen
- helpompaa
- helppo
- tehokkuus
- tehokas
- tehokkaasti
- ponnisteluja
- eliminoitu
- mahdollistaa
- loppu
- sitoumus
- Tekniikka
- Engineers
- tarpeeksi
- varmistaa
- Koko
- täysin
- ympäristö
- virhe
- virheet
- olennaisesti
- jne.
- Jopa
- lopulta
- Joka
- kaikki
- esimerkki
- innoissaan
- olemassa
- odottaa
- kokenut
- Elämykset
- kokeilu
- kokeiluja
- äärimmäinen
- erittäin
- tekijät
- FAIL
- ei ole
- epäonnistuu
- Epäonnistuminen
- epäonnistumisia
- melko
- paljon
- Muoti
- nopeampi
- Löytää
- Tulipalo
- Etunimi
- LAIVASTON
- Keskittää
- keskityttiin
- seurata
- varten
- Eteenpäin
- jae
- hajanainen
- Ilmainen
- tiheä
- alkaen
- koko
- täysin
- toiminnallinen
- edelleen
- tulevaisuutta
- tulevaa kasvua
- yleensä
- maantieteellinen
- saada
- saada
- tietty
- Global
- Maailmanlaajuisesti
- Go
- tavoite
- Goes
- menee
- suurempi
- Ryhmä
- Kasvaa
- täysikasvuinen
- Kasvu
- HAD
- Puoli
- kahva
- Käsittely
- tapahtua
- Kova
- Palvelimet
- Olla
- pää
- terveys
- terve
- auttaa
- auttanut
- Korkea
- korkeampi
- toivoa
- TUNTIA
- Miten
- Miten
- Kuitenkin
- HTTPS
- Ihmiset
- Hybridi
- ihanteellinen
- tunnistaa
- if
- mukaansatempaava
- Vaikutus
- vaikuttavia
- toteuttaa
- täytäntöön
- parantaa
- in
- sisältää
- Mukaan lukien
- yhteensopimaton
- Kasvaa
- lisää
- yhä useammin
- henkilökohtainen
- teollisuus
- tiedot
- Infrastruktuuri
- sisällä
- esimerkki
- tapauksia
- välittömästi
- mielenkiintoinen
- sisäinen
- tulee
- kysymys
- kysymykset
- IT
- kesäkuu
- vain
- Pitää
- pito
- Tietää
- tunnettu
- suuri
- laaja
- suureksi osaksi
- Viive
- oppinut
- jättää
- jättäen
- Perintö
- vähemmän
- antaa
- Taso
- velkarahalla
- pitää
- rajallinen
- kuormitus
- sijaitsevat
- sijainnit
- pitkän aikavälin
- kauemmin
- näköinen
- Erä
- Matala
- kone
- Koneet
- ylläpitää
- tehdä
- TEE
- Tekeminen
- hoitaa
- onnistui
- käsin
- monet
- max-width
- tarkoittaa
- merkitys
- mekanismi
- mekanismit
- Tavata
- verkko
- menetelmä
- järjestelmällinen
- ehkä
- vaeltaa
- siirtyneet
- siirtyvät
- muutto
- miljoona
- miljoonia
- minimoida
- vähäinen
- virheitä
- seuranta
- Kuukausi
- lisää
- tehokkaampi
- eniten
- liikkua
- paljon
- moninkertainen
- täytyy
- luonto
- lähes
- Tarve
- tarvitaan
- negatiivinen
- negatiivisesti
- verkko
- Uusi
- hiljattain
- seuraava
- seuraavan sukupolven
- Nro
- nyt
- numero
- numerot
- tapahtua
- lokakuu
- of
- pois
- on
- kerran
- ONE
- jatkuva
- vain
- Mahdollisuudet
- Tilaisuus
- or
- OS
- Muut
- Muuta
- meidän
- ulos
- sähkökatkos
- seisokkien
- yli
- yleinen
- omistajat
- osa
- passiivinen
- Ohi
- kuviot
- maksaa
- Peak
- Ihmiset
- varten
- prosentti
- esittävä
- sitkeästi
- henkilö
- filosofia
- fyysinen
- fyysisesti
- poimia
- Paikka
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- soitin
- politiikkaa
- kannettava
- osa
- mahdollisuus
- mahdollinen
- mahdollisesti
- mahdollisesti
- käytännöt
- estää
- estää
- pääasiallisesti
- prioriteetti
- yksityinen
- prosessi
- Prosessit
- Edistyminen
- asteittain
- eteneminen
- suojaus
- osoittautumassa
- säännös
- osti
- Työnnä
- kyselyt
- kysymys
- nopeasti
- pikemminkin
- valmis
- todellinen
- reaaliaikainen
- tasapainottaa
- elpyminen
- kääntää
- vähentää
- alue
- luotettavuus
- luotettava
- luottaa
- korjaus
- korvataan
- replikointi
- säilytyspaikka
- pyynnöt
- vaatimukset
- Vaatii
- tutkimus
- kimmoisuus
- kimmoisa
- ratkaisee
- REST
- johtua
- johtanut
- tarkistaa
- Riski
- Roblox
- luja
- ajaa
- juoksu
- toimii
- turvallisesti
- sama
- tallennettu
- Asteikko
- skenaario
- raapia
- Haku
- Toinen
- nähneet
- erottamalla
- syyskuu
- palveli
- palvelu
- Palvelut
- palvelevat
- setti
- useat
- Jaa:
- yhteinen
- jakaminen
- siirtää
- VAIHTO
- Lyhyt
- shouldnt
- merkittävästi
- koska
- single
- Istuminen
- pieni
- sujuvaa
- So
- niin kaukana
- Tuotteemme
- jonkin verran
- jotain
- hienostunut
- lähde
- lähdekoodi
- Tila
- piikkarit
- levitä
- leviäminen
- Alkaa
- alkoi
- alkaa
- Tila
- Yhä
- Strategia
- vahva
- vahvempi
- Opiskelu
- menestyä
- onnistunut
- Onnistuneesti
- YHTEENVETO
- tuki
- Tuetut
- Tukea
- Tukee
- järjestelmä
- järjestelmät
- ottaa
- otettava
- joukkue-
- Tekninen
- Technologies
- kymmeniä
- termi
- ehdot
- Testaus
- teksti
- kuin
- että
- -
- Tulevaisuus
- maailma
- heidän
- Niitä
- sitten
- Siellä.
- siten
- Nämä
- ne
- asiat
- ajatella
- tätä
- ne
- tuhansia
- Kautta
- kauttaaltaan
- aika
- kertaa
- että
- tänään
- yhdessä
- toleranssi
- liian
- työkalu
- työkalut
- Yhteensä
- kohti
- liikenne
- siirtyminen
- liipaisu
- yrittää
- kaksi
- tyypit
- lopullinen
- Lopulta
- poistoista
- asti
- käyttämätön
- päälle
- Päällä
- us
- käytetty
- käyttäjä
- Käyttäjät
- käyttämällä
- hyödyllisyys
- arvo
- versio
- hyvin
- näkyvä
- visio
- haluta
- oli
- Tapa..
- we
- Sää
- HYVIN
- olivat
- Mitä
- mikä tahansa
- kun
- joka
- vaikka
- KUKA
- leveä
- tulee
- pyyhkiminen
- with
- sisällä
- Referenssit
- työskenteli
- työskentely
- maailman-
- huoli
- olisi
- vuosi
- vuotta
- zephyrnet