Tämä on yhteinen viesti, jonka ovat kirjoittaneet AWS ja Voxel51. Voxel51 on yritys, jonka takana on FiftyOne, avoimen lähdekoodin työkalupakki korkealaatuisten tietojoukkojen ja tietokonenäkömallien rakentamiseen.
Vähittäiskauppayritys rakentaa mobiilisovellusta, joka auttaa asiakkaita ostamaan vaatteita. Tämän sovelluksen luomiseksi he tarvitsevat korkealaatuisen tietojoukon, joka sisältää vaatekuvia, jotka on merkitty eri luokilla. Tässä viestissä näytämme, kuinka olemassa olevaa tietojoukkoa voidaan käyttää uudelleen tietojen puhdistamisen, esikäsittelyn ja esimerkinnän avulla nolla-luokittelumallilla Viisikymmentäyksi, ja säädä näitä tarroja Amazon SageMaker Ground Totuus.
Voit käyttää Ground Truthia ja FiftyOnea datamerkintäprojektin nopeuttamiseen. Havainnollistamme, kuinka näitä kahta sovellusta käytetään saumattomasti yhdessä luomaan korkealaatuisia merkittyjä tietojoukkoja. Esimerkkikäyttötapauksessamme työskentelemme kanssa Fashion200K tietojoukko, julkaistu ICCV 2017 -tapahtumassa.
Ratkaisun yleiskatsaus
Ground Truth on täysin itsenäinen ja hallittu datamerkintäpalvelu, joka antaa datatieteilijöille, koneoppimisen (ML) insinööreille ja tutkijoille mahdollisuuden rakentaa korkealaatuisia tietojoukkoja. Viisikymmentäyksi by vokseli51 on avoimen lähdekoodin työkalupakki tietokonenäön tietojoukkojen kuratoimiseen, visualisointiin ja arviointiin, jotta voit kouluttaa ja analysoida parempia malleja nopeuttamalla käyttötapauksiasi.
Seuraavissa osissa osoitamme, kuinka tehdä seuraavat:
- Visualisoi tietojoukko FiftyOnessa
- Puhdista tietojoukko suodatuksella ja kuvien kopioinnin poistamisella FiftyOnessa
- Esimerkinnät puhdistetuille tiedoille nolla-luokittelulla FiftyOnessa
- Merkitse pienempi kuratoitu tietojoukko Ground Truthilla
- Ruiskuta merkittyjä tuloksia Ground Truthista FiftyOneen ja tarkastele merkittyjä tuloksia FiftyOneen
Käytä tapauskatsausta
Oletetaan, että omistat vähittäismyyntiyrityksen ja haluat rakentaa mobiilisovelluksen antaakseen henkilökohtaisia suosituksia, joiden avulla käyttäjät voivat päättää, mitä pukea päällensä. Mahdolliset käyttäjät etsivät sovellusta, joka kertoo heille, mitkä heidän vaatekaappinsa sopivat hyvin yhteen. Näet tässä mahdollisuuden: jos tunnistat hyvät asut, voit käyttää tätä suosittelemaan uusia asusteita, jotka täydentävät asiakkaan jo omistamia vaatteita.
Haluat tehdä asioista mahdollisimman helppoa loppukäyttäjälle. Ihannetapauksessa jonkun sovellustasi käyttävän tarvitsee vain ottaa kuvia vaatekaappissaan olevista vaatteista, ja ML-mallisi tekevät taikuutensa kulissien takana. Voit kouluttaa yleiskäyttöisen mallin tai hienosäätää mallin kunkin käyttäjän yksilölliseen tyyliin antamalla jonkinlaista palautetta.
Ensin sinun on kuitenkin selvitettävä, minkä tyyppisiä vaatteita käyttäjä ottaa. Onko se paita? Housut? Tai jotain muuta? Loppujen lopuksi et todennäköisesti halua suositella asua, jossa on useita mekkoja tai useita hattuja.
Vastataksesi tähän alkuhaasteeseen haluat luoda koulutustietojoukon, joka koostuu kuvista erilaisista vaatteista, joissa on erilaisia kuvioita ja tyylejä. Jos haluat prototyyppiä rajoitetulla budjetilla, haluat käynnistää olemassa olevan tietojoukon.
Havainnollistaaksemme ja opastaaksemme prosessia tässä viestissä käytämme ICCV 200:ssä julkaistua Fashion2017K-tietojoukkoa. Se on vakiintunut ja hyvin siteerattu tietojoukko, mutta se ei sovellu suoraan käyttötapauksiisi.
Vaikka vaatteisiin on merkitty luokkia (ja alaluokkia) ja ne sisältävät erilaisia hyödyllisiä tunnisteita, jotka on poimittu alkuperäisistä tuotekuvauksista, tietoja ei merkitä järjestelmällisesti malli- tai tyylitiedoilla. Tavoitteesi on tehdä tästä olemassa olevasta tietojoukosta vankka koulutustietojoukko vaatteiden luokitusmalleille. Sinun on puhdistettava tiedot ja täydennettävä merkintäskeemaa tyylitunnisteilla. Ja haluat tehdä sen nopeasti ja mahdollisimman vähällä rahalla.
Lataa tiedot paikallisesti
Lataa ensin women.tar-zip-tiedosto ja labels-kansio (kaikki sen alikansioineen) noudattamalla Fashion200K-tietojoukon GitHub-arkisto. Kun olet purkanut ne molemmat, luo ylähakemisto fashion200k ja siirrä tarrat ja naisten kansiot tähän. Onneksi nämä kuvat on jo rajattu kohteen tunnistuksen rajoitusruutuihin, joten voimme keskittyä luokitteluun sen sijaan, että huolehdimme kohteen havaitsemisesta.
Huolimatta nimimerkistä "200K", poimimamme naisten hakemisto sisältää 338,339 200 kuvaa. Virallisen Fashion300,000K-tietojoukon luomiseksi tietojoukon tekijät indeksoivat yli XNUMX XNUMX tuotetta verkossa, ja vain tuotteet, joiden kuvaukset sisälsivät yli neljä sanaa, pääsivät eroon. Jos tuotteen kuvaus ei ole välttämätön, voimme käyttää kaikkia indeksoituja kuvia tarkoituksiinmme.
Katsotaanpa, miten nämä tiedot on järjestetty: naiset-kansiossa kuvat on järjestetty huipputason artikkelityypin (hameet, topit, housut, takit ja mekot) ja artikkelityypin alakategorioiden (puserot, t-paidat, pitkähihaiset) mukaan topit).
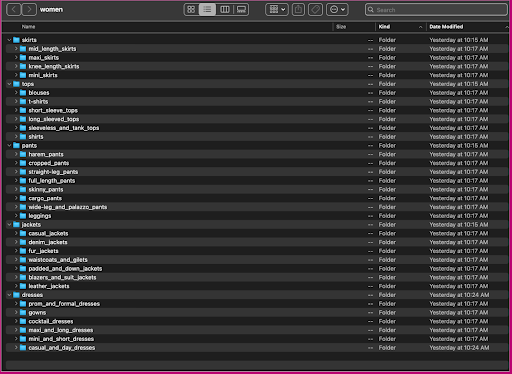
Alaluokkahakemistoissa on alihakemisto jokaiselle tuoteluettelolle. Jokainen näistä sisältää vaihtelevan määrän kuvia. Esimerkiksi cropped_pants -alaluokka sisältää seuraavat tuotelistaukset ja niihin liittyvät kuvat.
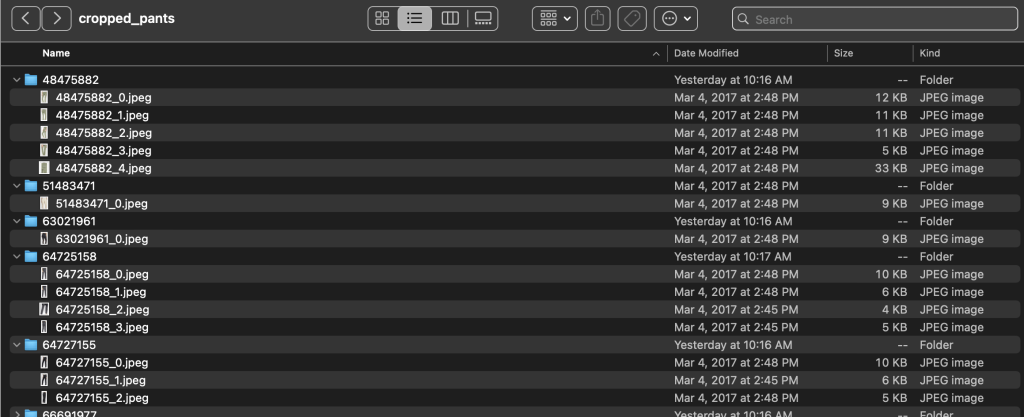
Tarrakansio sisältää tekstitiedoston jokaiselle ylimmän tason artikkelityypille sekä koulutus- että testiosuuksille. Jokaisessa näistä tekstitiedostoista on erillinen rivi jokaiselle kuvalle, joka määrittää suhteellisen tiedostopolun, pistemäärän ja tuotekuvauksen tagit.
Koska käytämme tietojoukkoa uudelleen, yhdistämme kaikki juna- ja testikuvat. Käytämme näitä korkealaatuisen sovelluskohtaisen tietojoukon luomiseen. Kun olemme saaneet tämän prosessin valmiiksi, voimme jakaa tuloksena olevan tietojoukon satunnaisesti uudeksi juna- ja testijakoiksi.
Lisää, tarkastele ja kuratoi tietojoukko FiftyOnessa
Jos et ole vielä tehnyt niin, asenna avoimen lähdekoodin FiftyOne pip:n avulla:
Paras käytäntö on tehdä se uudessa virtuaaliympäristössä (venv tai conda). Tuo sitten asiaankuuluvat moduulit. Tuo peruskirjasto, fiftyone, FiftyOne Brain, jossa on sisäänrakennetut ML-menetelmät, FiftyOne Zoo, josta lataamme mallin, joka luo meille zero-shot -etikettejä, ja ViewField, jonka avulla voimme suodattaa tehokkaasti tietoaineistomme tiedot:
Haluat myös tuoda glob- ja os Python-moduulit, jotka auttavat meitä työskentelemään polkujen ja kuvioiden täsmäytyksen kanssa hakemiston sisällön suhteen:
Nyt olemme valmiita lataamaan tietojoukon FiftyOneen. Ensin luodaan tietojoukko nimeltä fashion200k ja tehdään siitä pysyvä, jolloin voimme tallentaa laskennallisesti intensiivisten toimintojen tulokset, joten meidän tarvitsee laskea mainitut suureet vain kerran.
Voimme nyt iteroida kaikki alakategorian hakemistot ja lisätä kaikki kuvat tuotehakemistoista. Lisäämme jokaiseen näytteeseen FiftyOne-luokitustunnisteen, jonka kentän nimi on artikkelityyppi, joka täytetään kuvan ylimmän tason artikkeliluokalla. Lisäämme myös sekä luokka- että alaluokkatiedot tunnisteiksi:
Tässä vaiheessa voimme visualisoida tietojoukkomme FiftyOne-sovelluksessa käynnistämällä istunnon:
Voimme myös tulostaa yhteenvedon tietojoukosta Pythonissa suorittamalla print(dataset):
Voimme myös lisätä tunnisteita labels hakemisto tietojoukossamme oleviin näytteisiin:
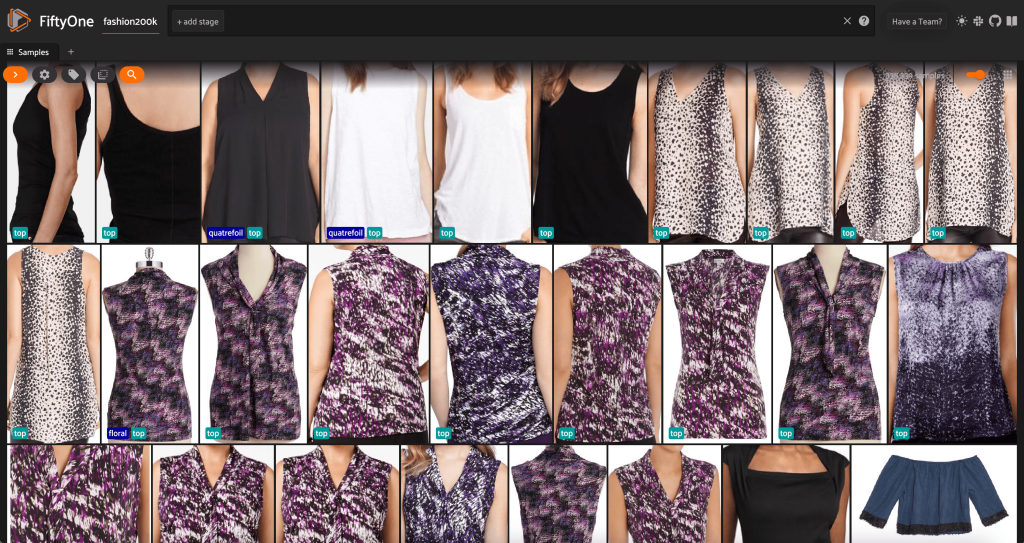
Kun tarkastellaan tietoja, muutama asia tulee selväksi:
- Jotkut kuvista ovat melko rakeisia ja niiden resoluutio on alhainen. Tämä johtuu todennäköisesti siitä, että nämä kuvat on luotu rajaamalla alkuperäisiä kuvia objektien tunnistuksen rajauslaatikoissa.
- Osa vaatteista on henkilön päällä ja osa on kuvattu yksinään. Nämä yksityiskohdat on koteloitu
viewpointomaisuutta. - Monet saman tuotteen kuvat ovat hyvin samankaltaisia, joten ainakaan aluksi useamman kuin yhden kuvan sisällyttäminen tuotetta kohden ei välttämättä lisää ennustusvoimaa. Suurimmaksi osaksi kunkin tuotteen ensimmäinen kuva (päättyy numeroon
_0.jpeg) on siistein.
Aluksi saatamme haluta harjoitella pukeutumistyylien luokittelumalliamme näiden kuvien kontrolloidulla osajoukolla. Tätä varten käytämme tuotteistamme korkearesoluutioisia kuvia ja rajoitamme katselumme yhteen edustavaan näytteeseen tuotetta kohden.
Ensin suodatamme pois matalaresoluutioiset kuvat. Käytämme compute_metadata() menetelmä kuvan leveyden ja korkeuden laskemiseksi ja tallentamiseksi pikseleinä jokaiselle tietojoukon kuvalle. Sitten käytämme FiftyOnea ViewField suodattaa kuvat pois vähimmäisleveys- ja korkeusarvojen perusteella. Katso seuraava koodi:
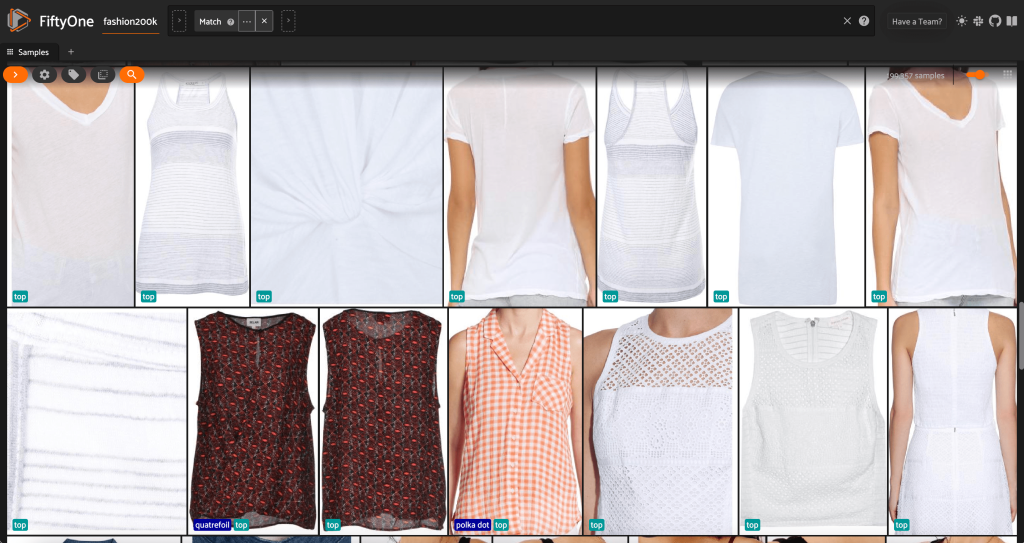
Tässä korkearesoluutioisessa osajoukossa on vajaat 200,000 XNUMX näytettä.
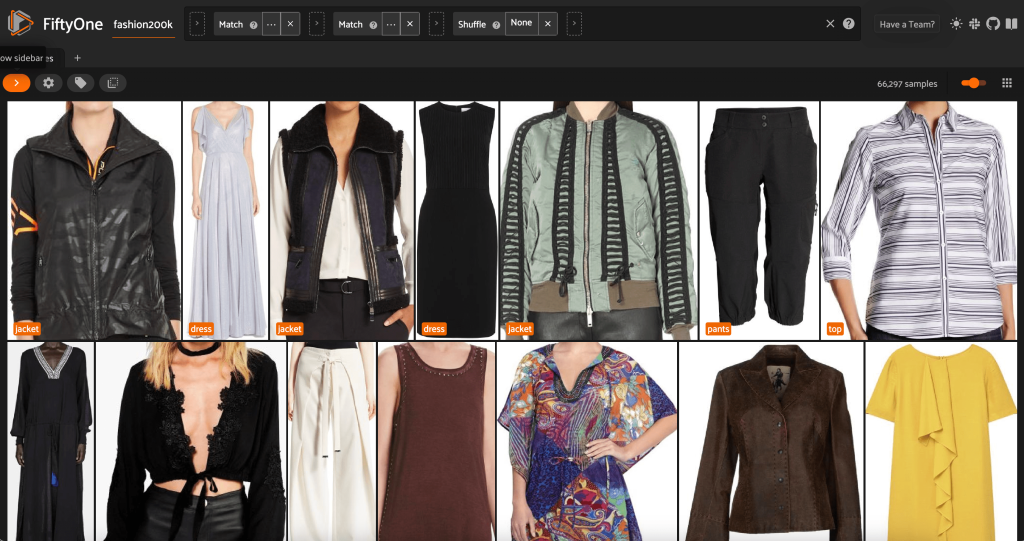
Tästä näkymästä voimme luoda tietojoukkoomme uuden näkymän, joka sisältää vain yhden edustavan näytteen (korkeintaan) jokaisesta tuotteesta. Käytämme ViewField jälleen kerran kuvion sovitus tiedostopoluille, jotka päättyvät _0.jpeg:
Tarkastellaan satunnaisesti sekoitettua kuvien järjestystä tässä osajoukossa:
Poista tarpeettomat kuvat tietojoukosta
Tämä näkymä sisältää 66,297 19 kuvaa eli hieman yli XNUMX % alkuperäisestä tietojoukosta. Kun katsomme näkymää, huomaamme kuitenkin, että on olemassa monia hyvin samankaltaisia tuotteita. Kaikkien näiden kopioiden säilyttäminen todennäköisesti vain lisää kustannuksia merkintä- ja mallikoulutuksemme parantamatta suorituskykyä merkittävästi. Sen sijaan päästään eroon lähes kaksoiskappaleista ja luodaan pienempi tietojoukko, joka sisältää edelleen saman rei'ityksen.
Koska nämä kuvat eivät ole tarkkoja kaksoiskappaleita, emme voi tarkistaa pikselikohtaista tasa-arvoa. Onneksi voimme käyttää FiftyOne Brainia tietojoukon puhdistamiseen. Erityisesti laskemme jokaiselle kuvalle upotuksen – pienempiulotteisen vektorin, joka edustaa kuvaa – ja etsimme sitten kuvia, joiden upotusvektorit ovat lähellä toisiaan. Mitä lähempänä vektorit ovat, sitä samankaltaisempia kuvat ovat.
Käytämme CLIP-mallia luodaksemme 512-ulotteisen upotusvektorin jokaiselle kuvalle ja tallennamme nämä upotukset tietojoukkomme näytteiden kenttäupotuksiin:
Sitten lasketaan upotusten välinen läheisyys käyttämällä kosinin samankaltaisuus, ja väittävät, että mitkä tahansa kaksi vektoria, joiden samankaltaisuus on suurempi kuin jokin kynnys, ovat todennäköisesti lähellä kaksoiskappaleita. Kosinin samankaltaisuuspisteet ovat alueella [0, 1], ja dataa tarkasteltaessa kynnysarvo thresh=0.5 näyttää olevan suurin piirtein oikea. Jälleen kerran, tämän ei tarvitse olla täydellinen. Muutama lähes kaksoiskuva ei todennäköisesti pilaa ennustuskykyämme, ja muutaman ei-kopio kuvan heittäminen pois ei vaikuta mallin suorituskykyyn olennaisesti.
Voimme tarkastella väitettyjä kaksoiskappaleita varmistaaksemme, että ne ovat todella tarpeettomia:
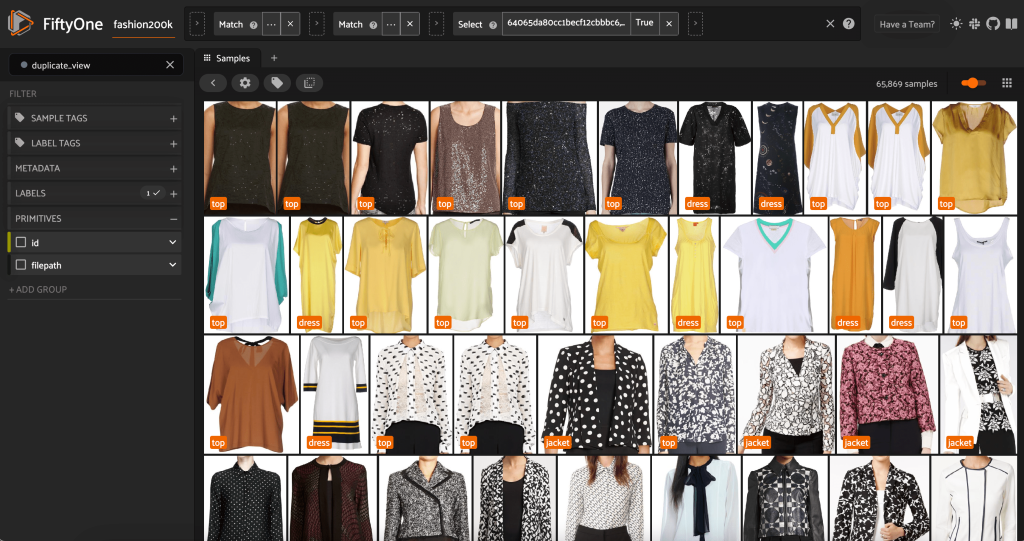
Kun olemme tyytyväisiä tulokseen ja uskomme, että nämä kuvat ovat todellakin lähellä kaksoiskappaleita, voimme valita jokaisesta samankaltaisesta näytesarjasta yhden näytteen säilytettäväksi ja jättää muut huomiotta:
Tässä näkymässä on nyt 3,729 200 kuvaa. Puhdistamalla tiedot ja tunnistamalla korkealaatuisen osajoukon Fashion300,000K-tietojoukosta FiftyOne antaa meille mahdollisuuden rajoittaa tarkennustamme yli 4,000 98 kuvasta hieman alle 90 XNUMX:een, mikä merkitsee XNUMX prosentin vähennystä. Pelkästään upotusten käyttäminen lähes päällekkäisten kuvien poistamiseen vähensi tarkasteltavien kuvien kokonaismäärää yli XNUMX %, mikä vaikutti vain vähän tai ei ollenkaan malleihin, joita opetetaan näillä tiedoilla.
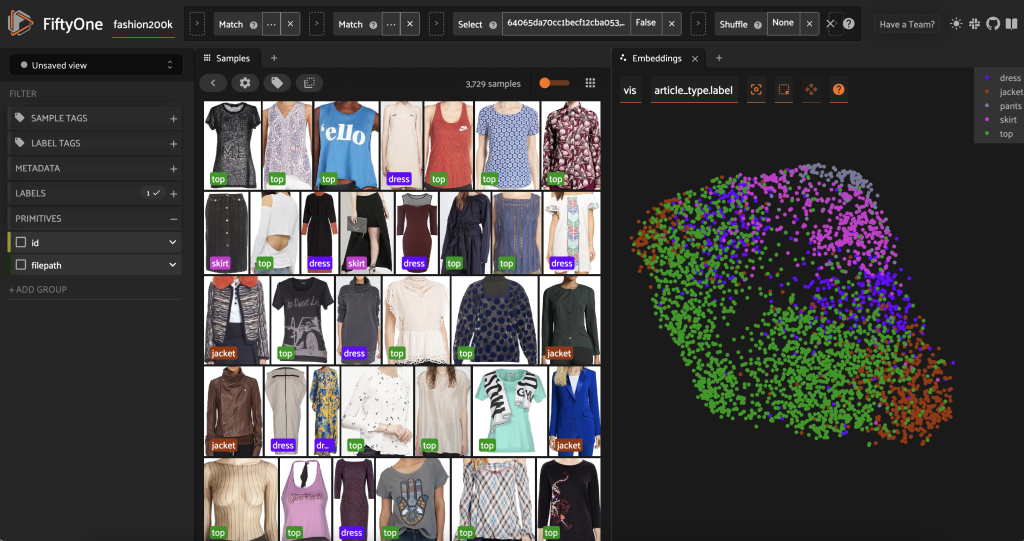
Ennen kuin esimerkinnät tämän osajoukon, voimme ymmärtää tietoja paremmin visualisoimalla jo laskemamme upotukset. Voimme käyttää FiftyOne Brainin sisäänrakennettua compute_visualization() -menetelmä, joka käyttää UMAP-tekniikkaa 512-ulotteisten upotusvektorien projisoimiseksi kaksiulotteiseen avaruuteen, jotta voimme visualisoida ne:
Avaamme uuden Upotuspaneeli FiftyOne-sovelluksessa ja värityksen artikkelityypin mukaan, ja voimme nähdä, että nämä upotukset koodaavat karkeasti käsitteen artikkelityypistä (muun muassa!).
Nyt olemme valmiita merkitsemään nämä tiedot valmiiksi.
Tarkastelemalla näitä erittäin ainutlaatuisia, korkearesoluutioisia kuvia voimme luoda kunnollisen alustavan luettelon tyyleistä, joita voidaan käyttää luokkina esimerkinnässämme nolla-shot -luokittelussa. Tavoitteemme näiden kuvien esimerkinnöissä ei ole välttämättä merkitä jokaista kuvaa oikein. Tavoitteemme on pikemminkin tarjota hyvä lähtökohta ihmiskirjoittajille, jotta voimme vähentää merkitsemisaikaa ja -kustannuksia.
Voimme sitten luoda nollakuvan luokittelumallin tälle sovellukselle. Käytämme CLIP-mallia, joka on yleiskäyttöinen malli, joka on koulutettu sekä kuviin että luonnolliseen kieleen. Instantoimme CLIP-mallin tekstikehotteella "Clothing in the style", jotta malli näyttää kuvan perusteella luokan, jolle "Clothing in the style [class]" sopii parhaiten. CLIP ei ole koulutettu vähittäismyynti- tai muotikohtaisiin tietoihin, joten tämä ei ole täydellinen, mutta se voi säästää etiketti- ja huomautuskustannuksissa.
Käytämme sitten tätä mallia supistetussa osajoukossamme ja tallennamme tulokset an article_style ala:
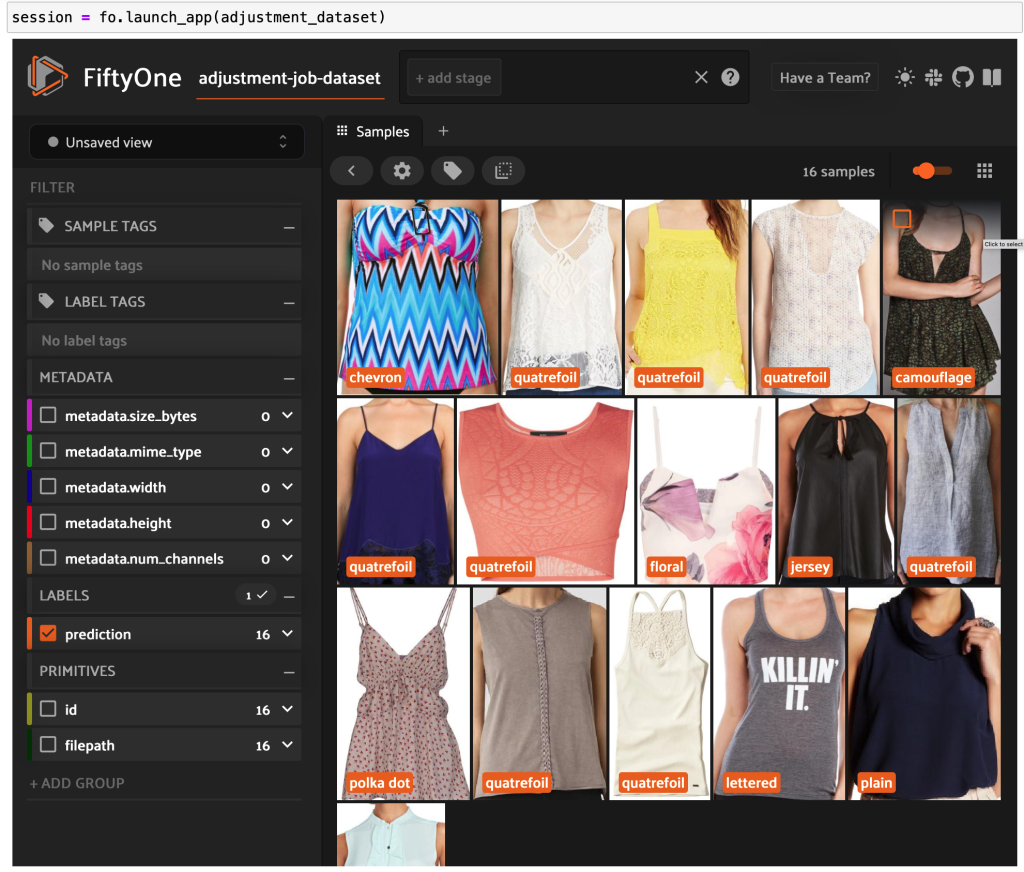
Kun käynnistämme FiftyOne-sovelluksen uudelleen, voimme visualisoida kuvat näillä ennustetuilla tyylitarroilla. Lajittelemme ennusteen luotettavuuden mukaan, jotta näemme luotettavimman tyylin ennusteet ensin:
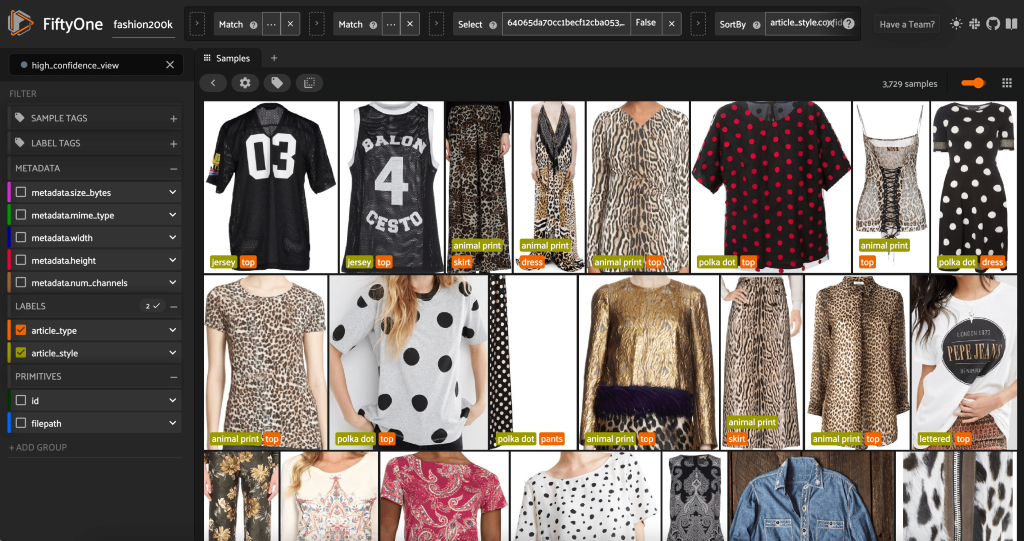
Voimme nähdä, että korkeimmat ennusteet näyttävät olevan "jersey", "eläinkuvio", "pilkku" ja "kirjaimilla" tyylejä. Tämä on järkevää, koska nämä tyylit ovat suhteellisen erilaisia. Näyttää myös siltä, että ennustetut tyylimerkinnät ovat suurimmaksi osaksi tarkkoja.
Voimme myös tarkastella alhaisimman luotettavuuden tyylien ennusteita:
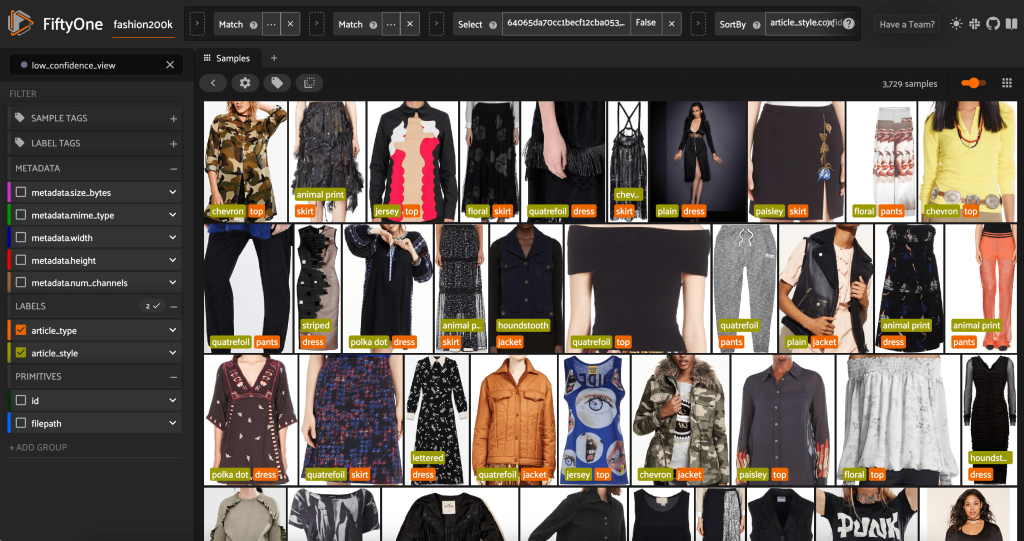
Joillekin näistä kuvista sopiva tyyliluokka on luettelossa, ja vaatekappale on merkitty väärin. Esimerkiksi ruudukon ensimmäisen kuvan tulee selvästi olla "naamiointi" eikä "chevron". Muissa tapauksissa tuotteet eivät kuitenkaan mahdu siististi tyylikategorioihin. Esimerkiksi toisen rivin toisen kuvan mekko ei ole aivan "raidallinen", mutta samoilla merkintävaihtoehdoilla myös ihmisen kirjoittaja on saattanut olla ristiriitainen. Kun rakennamme tietojoukkoamme, meidän on päätettävä, poistetaanko tällaiset reunatapaukset, lisätäänkö uusia tyyliluokkia vai laajennetaanko tietojoukkoa.
Vie lopullinen tietojoukko FiftyOnesta
Vie lopullinen tietojoukko seuraavalla koodilla:
Voimme viedä kansioon pienemmän tietojoukon, esimerkiksi 16 kuvaa 200kFashionDatasetExportResult-16Images. Luomme Ground Truth -säätötyön käyttämällä sitä:
Lataa tarkistettu tietojoukko, muunna tarramuoto Ground Truthiksi, lataa Amazon S3:een ja luo luettelotiedosto säätötyötä varten
Voimme muuntaa tietojoukon tarrat vastaamaan lähtöluettelokaavio Ground Truth -rajoituslaatikkotyöstä ja lähetä kuvat Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ämpäri käynnistääksesi a Ground Truth -säätötyö:
Lataa luettelotiedosto Amazon S3:een seuraavalla koodilla:
Luo korjattuja tyylikkäitä tarroja Ground Truthilla
Jos haluat merkitä tietosi tyylitunnisteilla Ground Truthin avulla, suorita tarvittavat vaiheet aloittaaksesi rajoituslaatikon merkintätyön noudattamalla kohdassa kuvattua menettelyä. Ground Truthin käytön aloittaminen opas tietojoukon kanssa samassa S3-ämpärissä.
- Luo SageMaker-konsolissa Ground Truth -merkintätyö.
- - asettaa Syötä tietojoukon sijainti olla manifest, jonka loimme edeltävissä vaiheissa.
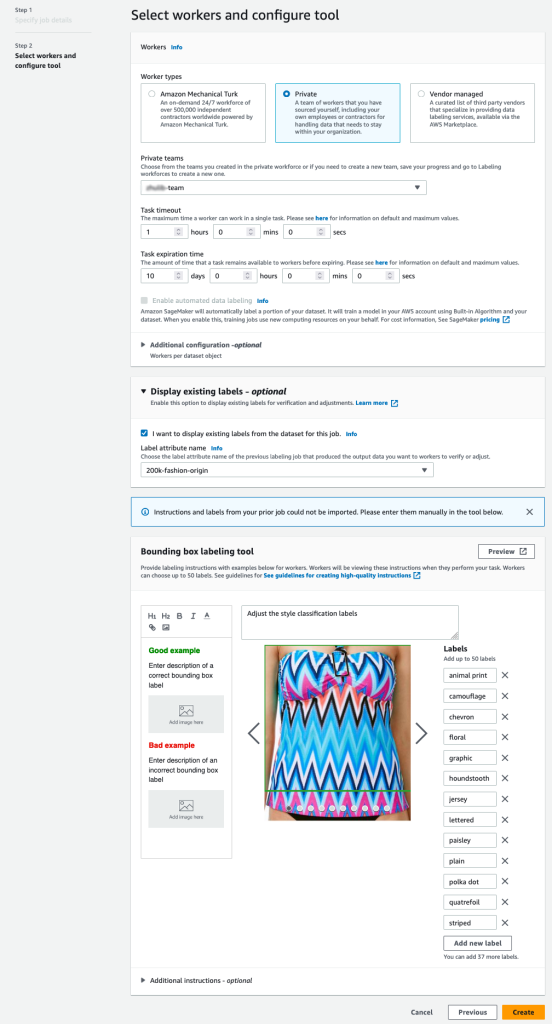
- Määritä S3-polku Lähtötietojoukon sijainti.
- varten IAM-rooli, valitse Anna mukautettu IAM-rooli RNA, syötä sitten rooli ARN.
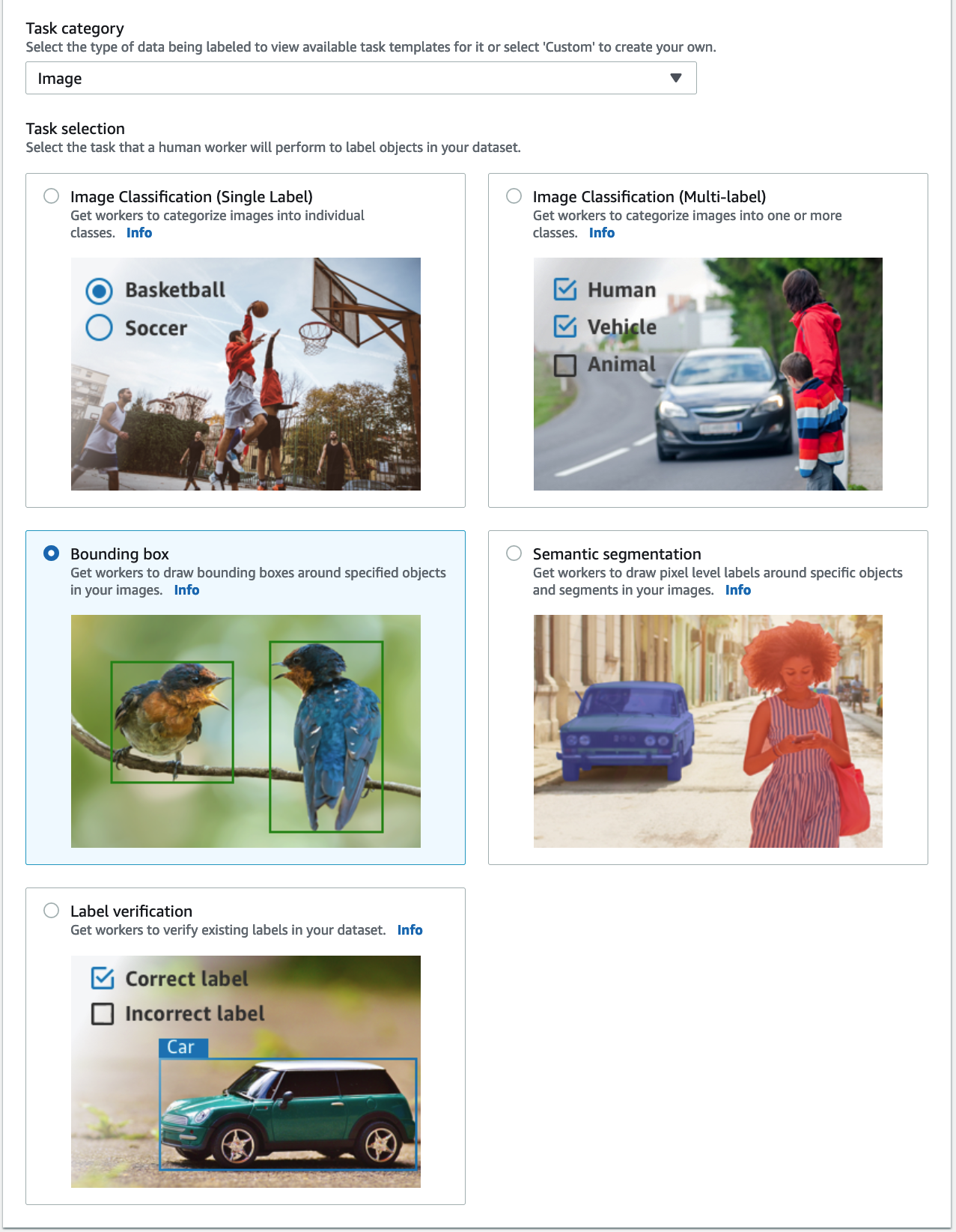
- varten Tehtäväluokka, valitse Kuva ja valitse Rajoituslaatikko.
- Valita seuraava.
- In työntekijät -osiossa valitse haluamasi työvoimatyyppi.
Voit valita työvoiman kautta Amazon Mechanical Turk, kolmannen osapuolen toimittajat tai oma yksityinen työvoimasi. Jos haluat lisätietoja työvoimavaihtoehdoistasi, katso Luo ja hallinnoi työvoimaa. - Laajentaa Olemassa olevien tarrojen näyttövaihtoehdot ja valitse Haluan näyttää nykyiset tunnisteet tämän työn tietojoukosta.
- varten Tunnisteen attribuutti nimi, valitse luettelosta nimi, joka vastaa tarroja, jotka haluat näyttää säädettäväksi.
Näet vain tunnisteiden määritteiden nimet, jotka vastaavat edellisissä vaiheissa valitsemaasi tehtävätyyppiä. - Syötä tunnisteet manuaalisesti Rajoituslaatikon merkintätyökalu.
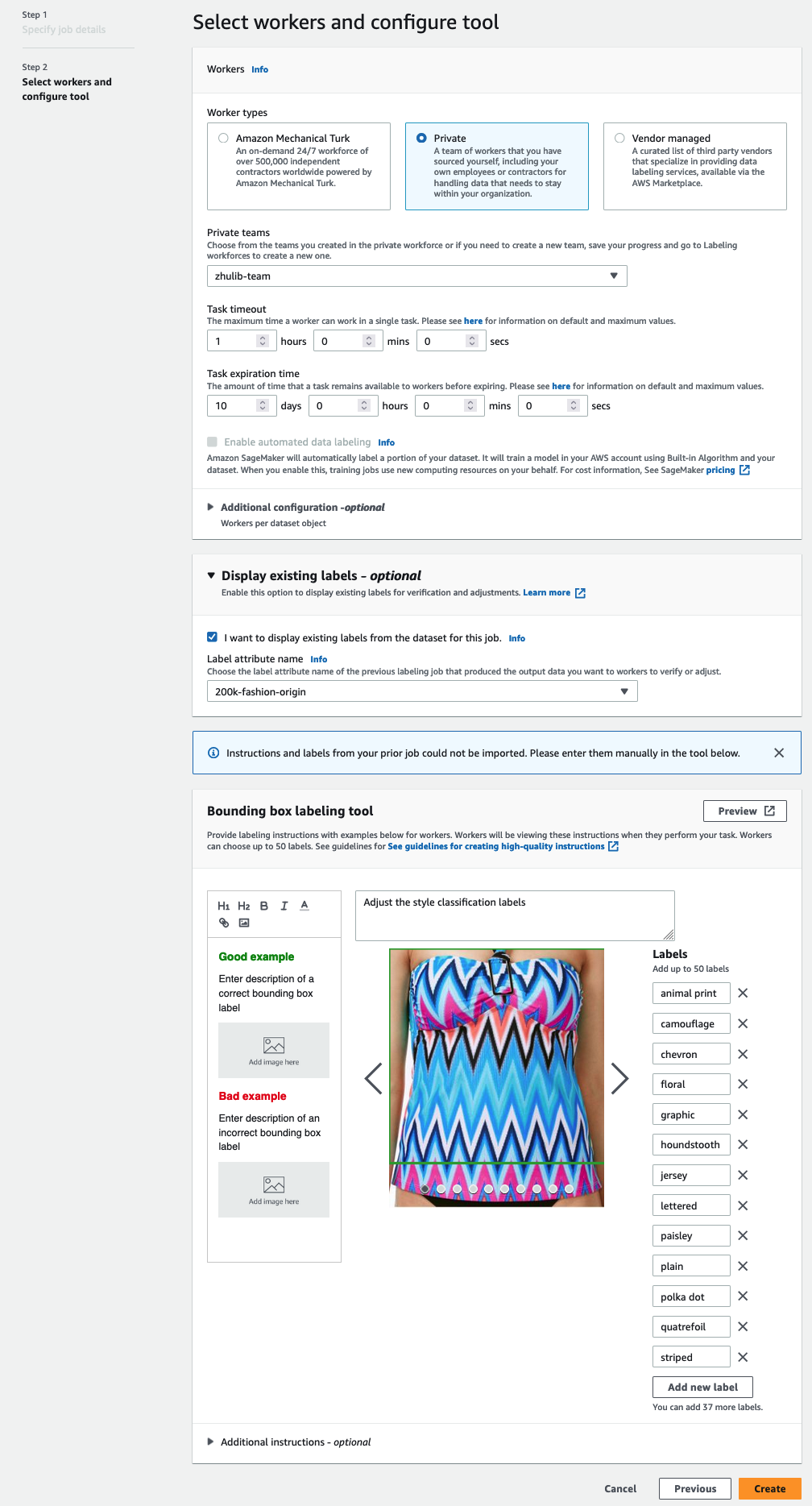 Tarrojen tulee sisältää samat tunnisteet, joita käytetään julkisessa tietojoukossa. Voit lisätä uusia tunnisteita. Seuraava kuvakaappaus näyttää, kuinka voit valita työntekijät ja määrittää työkalun merkintätyötäsi varten.
Tarrojen tulee sisältää samat tunnisteet, joita käytetään julkisessa tietojoukossa. Voit lisätä uusia tunnisteita. Seuraava kuvakaappaus näyttää, kuinka voit valita työntekijät ja määrittää työkalun merkintätyötäsi varten.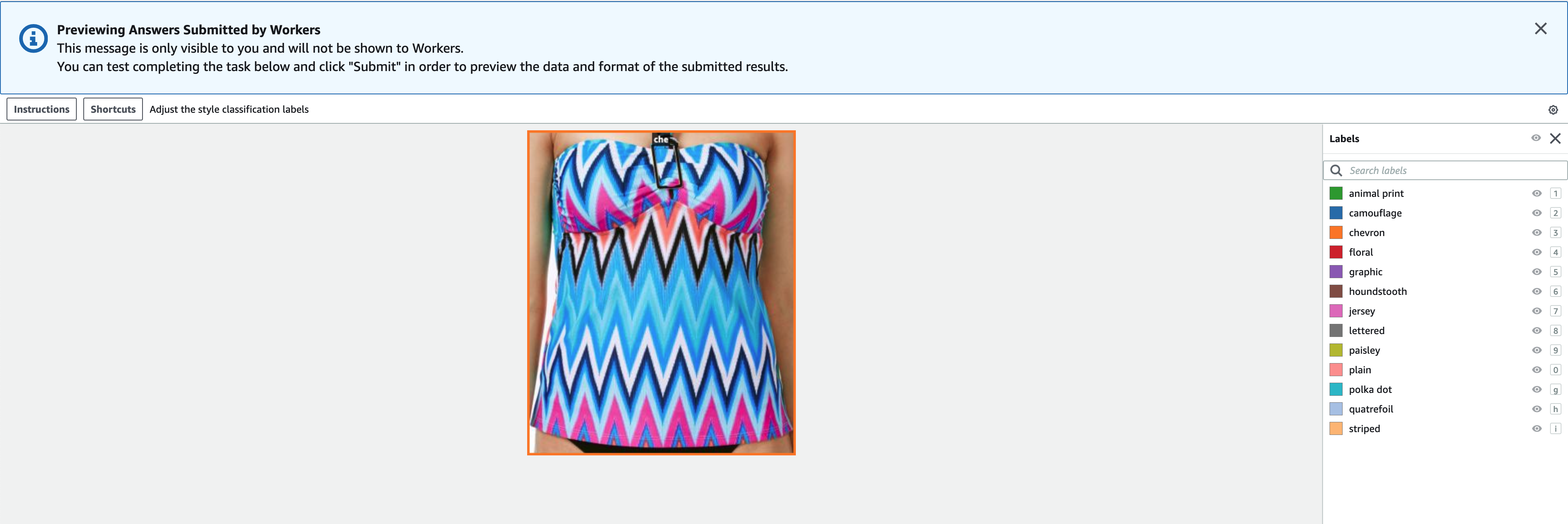
- Valita preview esikatsellaksesi kuvaa ja alkuperäisiä huomautuksia.
Olemme nyt luoneet Ground Truthiin etiketöintityön. Kun työmme on valmis, voimme ladata äskettäin luodut tunnistetiedot FiftyOneen. Ground Truth tuottaa lähtötiedot Ground Truth -lähtöluettelossa. Lisätietoja tulosluettelotiedostosta on kohdassa Rajoituslaatikon työn tulos. Seuraava koodi näyttää esimerkin tästä tulosluettelomuodosta:
Tarkista merkittyjä tuloksia Ground Truthista FiftyOnessa
Kun työ on valmis, lataa merkintätyön tulosluettelo Amazon S3:sta.
Lue tulosluettelotiedosto:
Luo FiftyOne-tietojoukko ja muunna luettelorivit tietojoukon näytteiksi:
Voit nyt nähdä korkealaatuisia merkittyjä tietoja Ground Truthista FiftyOnessa.
Yhteenveto
Tässä viestissä näytimme, kuinka luoda korkealaatuisia tietojoukkoja yhdistämällä teho Viisikymmentäyksi by vokseli51, avoimen lähdekoodin työkalupakki, jonka avulla voit hallita, seurata, visualisoida ja kuratoida tietojoukkoasi, ja Ground Truth, datamerkintäpalvelu, jonka avulla voit tehokkaasti ja tarkasti merkitä ML-järjestelmien koulutukseen tarvittavat tietojoukot tarjoamalla pääsyn useisiin rakennettuihin -tehtävämalleissa ja pääsy monipuoliseen työvoimaan Mechanical Turin, kolmannen osapuolen toimittajien tai oman yksityisen työvoimasi kautta.
Suosittelemme kokeilemaan tätä uutta toimintoa asentamalla FiftyOne-instanssi ja käyttämällä Ground Truth -konsolia aloittaaksesi. Lisätietoja Ground Truthista on kohdassa Label Data, Amazon SageMaker Data Labeling - usein kysytyt kysymykset, ja AWS-koneoppimisblogi.
Yhdistä Koneoppimis- ja tekoälyyhteisö jos sinulla on kysyttävää tai palautetta!
Liity FiftyOne-yhteisöön!
Liity tuhansien insinöörien ja datatieteilijöiden joukkoon, jotka jo käyttävät FiftyOnea ratkaistaksesi joitain haastavimmista tietokonenäön ongelmista tänään!
Tietoja Tekijät
Shalendra Chhabra on tällä hetkellä Amazon SageMaker Human-in-the-Loop (HIL) -palveluiden tuotehallinnan johtaja. Aiemmin Shalendra inkuboi ja johti kieli- ja keskustelutiedonhallintaa Microsoft Teams Meetingsissä, oli EIR Amazon Alexa Techstars Startup Acceleratorissa, tuote- ja markkinointijohtaja Discuss.io, Clipboardin tuote- ja markkinointijohtaja (Salesforcen ostama) ja Swypen johtava tuotepäällikkö (Nuancen osti). Yhteensä Shalendra on auttanut rakentamaan, toimittamaan ja markkinoimaan tuotteita, jotka ovat koskettaneet yli miljardia ihmistä.
Jacob Marks on koneoppimisen insinööri ja kehittäjäevankelista Voxel51:ssä, jossa hän auttaa tuomaan läpinäkyvyyttä ja selkeyttä maailman tietoihin. Ennen Voxel51:een liittymistään Jacob perusti startup-yrityksen auttaakseen nousevia muusikoita pitämään yhteyttä ja jakamaan luovaa sisältöä fanien kanssa. Sitä ennen hän työskenteli Google X:ssä, Samsung Researchissa ja Wolfram Researchissa. Edellisessä elämässä Jacob oli teoreettinen fyysikko ja suoritti tohtorintutkintonsa Stanfordissa, jossa hän tutki aineen kvanttivaiheita. Vapaa-ajallaan Jacob nauttii kiipeämisestä, juoksemisesta ja tieteisromaanien lukemisesta.
Jason Corso on Voxel51:n perustaja ja toimitusjohtaja. Hän ohjaa strategiaa, joka auttaa tuomaan läpinäkyvyyttä ja selkeyttä maailman tietoihin huippuluokan joustavien ohjelmistojen avulla. Hän on myös robotiikan, sähkötekniikan ja tietojenkäsittelytieteen professori Michiganin yliopistossa, jossa hän keskittyy huippuluokan ongelmiin tietokonenäön, luonnollisen kielen ja fyysisten alustojen risteyksessä. Vapaa-ajallaan Jason viettää aikaa perheensä kanssa, lukee, on luonnossa, pelaa lautapelejä ja tekee kaikenlaista luovaa toimintaa.
Brian Moore on Voxel51:n perustaja ja teknologiajohtaja, jossa hän johtaa teknistä strategiaa ja visiota. Hänellä on tohtorintutkinto sähkötekniikasta Michiganin yliopistosta, jossa hänen tutkimuksensa keskittyi tehokkaisiin algoritmeihin suuriin koneoppimisongelmiin, erityisesti tietokonenäkösovelluksiin. Vapaa-ajallaan hän nauttii sulkapallosta, golfista, patikoinnista ja leikkii kaksosyorkshirenterrieriensä kanssa.
Zhuling Bai on ohjelmistokehitysinsinööri Amazon Web Services -palvelussa. Hän kehittää laajamittaisia hajautettuja järjestelmiä koneoppimisongelmien ratkaisemiseksi.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoAiStream. Web3 Data Intelligence. Tietoa laajennettu. Pääsy tästä.
- Tulevaisuuden lyöminen Adryenn Ashley. Pääsy tästä.
- Osta ja myy osakkeita PRE-IPO-yhtiöissä PREIPO®:lla. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Meistä
- kiihdyttää
- kiihtyvä
- kiihdytin
- pääsy
- tarkka
- tarkasti
- hankittu
- toiminta
- lisätä
- lisää
- osoite
- Oikaistu
- Säätö
- Jälkeen
- uudelleen
- AI
- Alexa
- algoritmit
- Kaikki
- mahdollistaa
- yksin
- jo
- Myös
- Amazon
- amazon alexa
- Amazon Sage Maker
- Amazon SageMaker Ground Totuus
- Amazon Web Services
- keskuudessa
- an
- analysoida
- ja
- eläin
- Kaikki
- sovelluksen
- Hakemus
- sovellukset
- käyttää
- sopiva
- OVAT
- järjestetty
- artikkeli
- artikkelit
- AS
- liittyvä
- At
- Tekijät
- pois
- AWS
- pohja
- perustua
- BE
- koska
- tulevat
- ollut
- ennen
- takana
- kulissien takana
- ovat
- Uskoa
- PARAS
- Paremmin
- välillä
- Miljardi
- hallitus
- Lautapelit
- LUU
- Bootstrap
- sekä
- Laatikko
- laatikot
- Aivot
- Tauko
- tuoda
- toi
- talousarvio
- rakentaa
- Rakentaminen
- sisäänrakennettu
- mutta
- Ostetaan
- by
- CAN
- Kaappaaminen
- tapaus
- tapauksissa
- luokat
- Kategoria
- toimitusjohtaja
- haaste
- haastava
- tarkastaa
- Valita
- selkeys
- luokka
- luokat
- luokittelu
- Siivous
- selkeä
- selvästi
- asiakas
- Kiipeily
- lähellä
- lähempänä
- vaatteet
- Vaatetus
- Perustaja
- koodi
- yhdistää
- yhdistely
- yritys
- Täydentää
- täydellinen
- Suoritettuaan
- Laskea
- tietokone
- Tietojenkäsittelyoppi
- Tietokoneen visio
- Computer Vision -sovellukset
- luottamus
- luottavainen
- kytkeä
- harkinta
- Koostuu
- Console
- sisältää
- pitoisuus
- sisältö
- hallinnassa
- puhekielen
- muuntaa
- kappaletta
- Ydin
- korjattu
- vastaa
- Hinta
- kustannukset
- luoda
- luotu
- Luova
- Valtakirja
- CTO
- kuratoitu
- kuratointi
- Tällä hetkellä
- asiakassuhde
- asiakas
- Asiakkaat
- Leikkaus
- leikkaamisreuna
- tiedot
- aineistot
- päättää
- osoittaa
- Denimi
- syvyys
- kuvaus
- yksityiskohdat
- Detection
- Kehittäjä
- kehittämällä
- Kehitys
- eri
- suoraan
- hakemistot
- näyttö
- selvä
- jaettu
- hajautetut järjestelmät
- useat
- do
- ei
- Koira
- tekee
- tehty
- Dont
- DOT
- alas
- download
- kaksoiskappaleet
- e
- kukin
- helppo
- reuna
- vaikutus
- tehokas
- tehokkaasti
- Sähkötekniikka
- upottamisen
- syntymässä
- painotus
- työllistää
- valtuutetaan
- kapseloitu
- kannustaa
- loppu
- insinööri
- Tekniikka
- Engineers
- enter
- ympäristö
- tasa-arvo
- olennainen
- vakiintunut
- Eetteri (ETH)
- arviointiin
- Evankelista
- täsmälleen
- esimerkki
- olemassa
- vienti
- melko
- perhe
- fanit
- palaute
- harvat
- Kaunokirjallisuus
- ala
- Fields
- filee
- Asiakirjat
- suodattaa
- suodatus
- lopullinen
- Etunimi
- sovittaa
- joustava
- Keskittää
- keskityttiin
- keskittyy
- jälkeen
- varten
- muoto
- muoto
- Onneksi
- Perustettu
- neljä
- Ilmainen
- alkaen
- täysin
- toiminnallisuus
- Pelit
- yleinen tarkoitus
- tuottaa
- syntyy
- saada
- GitHub
- Antaa
- tietty
- tavoite
- golf
- hyvä
- suurempi
- ruudukko
- Maa
- Ryhmä
- ohjaavat
- onnellinen
- Olla
- he
- pää
- korkeus
- auttaa
- auttanut
- hyödyllinen
- auttaa
- tätä
- korkealaatuisia
- korkea resoluutio
- suurin
- erittäin
- retkeily
- hänen
- pitää
- Miten
- Miten
- Kuitenkin
- HTML
- http
- HTTPS
- ihmisen
- i
- IAM
- ID
- tunnistaa
- tunnistaminen
- ids
- if
- kuva
- kuvien
- Vaikutus
- tuoda
- parantaminen
- in
- Muilla
- Mukaan lukien
- virheellisesti
- inkuboitu
- tiedot
- ensimmäinen
- ensin
- asentaa
- asentaminen
- esimerkki
- sen sijaan
- ohjeet
- Älykkyys
- leikkauspiste
- tulee
- IT
- SEN
- jersey
- Job
- tuloaan
- yhteinen
- json
- vain
- Pitää
- pito
- Merkki
- merkinnät
- tarrat
- Kieli
- laaja
- käynnistää
- käynnistäminen
- johtaa
- Liidit
- OPPIA
- oppiminen
- vähiten
- Led
- vasemmalle
- Lets
- Kirjasto
- elämä
- pitää
- Todennäköisesti
- RAJOITA
- rajallinen
- linja
- linjat
- Lista
- listaus
- Ilmoitukset
- vähän
- Lives
- kuormitus
- katso
- näköinen
- Erä
- Matala
- kone
- koneoppiminen
- tehty
- taika-
- tehdä
- TEE
- hoitaa
- onnistui
- johto
- johtaja
- monet
- kartta
- markkinat
- Marketing
- ottelu
- matching
- aineellisesti
- asia
- Saattaa..
- mekaaninen
- Media
- kokoukset
- Meta
- Metadata
- menetelmä
- menetelmät
- Michigan
- Microsoft
- microsoft-tiimit
- ehkä
- minimi
- ML
- Puhelinnumero
- Mobiilisovellus
- malli
- mallit
- Moduulit
- lisää
- eniten
- liikkua
- paljon
- moninkertainen
- muusikot
- täytyy
- nimi
- nimetty
- nimet
- Luonnollinen
- Luonnollinen kieli
- luonto
- Lähellä
- välttämättä
- välttämätön
- Tarve
- tarpeet
- Uusi
- huomattavasti
- Käsite
- nyt
- Vivahde
- numero
- objekti
- Objektin tunnistus
- esineet
- of
- virallinen
- on
- kerran
- ONE
- verkossa
- vain
- avata
- avoimen lähdekoodin
- Operations
- Tilaisuus
- Vaihtoehdot
- or
- Järjestetty
- alkuperäinen
- OS
- Muut
- Muuta
- meidän
- ulos
- hahmoteltu
- ulostulo
- yli
- oma
- omistaa
- Pakkauksissa
- pariksi
- osa
- erityinen
- Ohi
- polku
- Kuvio
- kuviot
- täydellinen
- suorituskyky
- henkilö
- yksilöllinen
- Aineen vaiheet
- fyysinen
- poimia
- kuvat
- pleedi
- tavallinen
- Platforms
- Platon
- Platonin tietotieto
- PlatonData
- pelaa
- Kohta
- asutuilla
- mahdollinen
- Kirje
- teho
- harjoitusta.
- ennusti
- ennustus
- Ennusteet
- preview
- edellinen
- aiemmin
- Painaa
- Aikaisempi
- yksityinen
- todennäköisesti
- ongelmia
- prosessi
- Tuotteet
- tuotehallinta
- tuotepäällikkö
- Tuotteemme
- Opettaja
- projekti
- omaisuus
- mahdollinen
- prototyyppi
- toimittaa
- mikäli
- tarjoamalla
- julkinen
- booli
- tarkoituksiin
- Python
- Kvantti
- kysymykset
- nopeasti
- alue
- pikemminkin
- Lukeminen
- valmis
- suositella
- suosituksia
- vähentää
- Vähentynyt
- vähentäminen
- suhteellisesti
- julkaistu
- merkityksellinen
- poistaa
- edustaja
- edustavat
- tarvitaan
- tutkimus
- Tutkijat
- päätöslauselma
- rajoittaa
- johtua
- Saatu ja
- tulokset
- vähittäiskauppa
- palata
- arviot
- Eroon
- robotiikka
- luja
- Rooli
- karkeasti
- RIVI
- pilata
- juoksu
- sagemaker
- Said
- Salesforce
- sama
- Samsung
- Säästä
- kohtaukset
- tiede
- Tieteiskirjallisuus
- tutkijat
- pisteet
- saumattomasti
- Toinen
- Osa
- osiot
- nähdä
- näyttää
- näyttää
- valittu
- tunne
- erillinen
- palvelu
- Palvelut
- Istunto
- setti
- Jaa:
- hän
- shouldnt
- näyttää
- Näytä
- KYLLÄ
- samankaltainen
- Yksinkertainen
- pienempiä
- So
- Tuotteemme
- ohjelmistokehitys
- SOLVE
- jonkin verran
- Joku
- jotain
- Tila
- viettää
- menot
- jakaa
- splits
- Stanford
- Alkaa
- alkoi
- Aloita
- käynnistyksen
- käynnistyskiihdytin
- huippu-
- Askeleet
- Yhä
- Levytila
- verkkokaupasta
- Strategia
- tyyli
- tyylit
- YHTEENVETO
- Tuetut
- järjestelmät
- ottaa
- Tehtävä
- tiimit
- Tekninen
- TechStars
- kertoo
- malleja
- testi
- kuin
- että
- -
- heidän
- Niitä
- sitten
- teoreettinen
- Siellä.
- Nämä
- ne
- asiat
- ajatella
- kolmannen osapuolen
- tätä
- tuhansia
- kynnys
- Kautta
- Throwing
- aika
- että
- yhdessä
- työkalu
- työkalupakki
- ylin
- huipputaso
- Topit
- Yhteensä
- liikuttunut
- raita
- Juna
- koulutettu
- koulutus
- Muuttaa
- Läpinäkyvyys
- totta
- Totuus
- VUORO
- kaksi
- tyyppi
- tyypit
- varten
- ymmärtää
- unique
- yliopisto
- University of Michigan
- Päivitykset
- us
- käyttää
- käyttölaukku
- käytetty
- käyttäjä
- Käyttäjät
- käyttämällä
- arvot
- lajike
- eri
- myyjät
- todentaa
- hyvin
- kautta
- Näytä
- Virtual
- visio
- haluta
- oli
- we
- verkko
- verkkopalvelut
- HYVIN
- olivat
- Mitä
- kun
- onko
- joka
- wikipedia
- tulee
- with
- sisällä
- ilman
- Naiset
- sanoja
- Referenssit
- työskenteli
- työntekijöitä
- työvoima
- toimii
- maailman
- huoli
- olisi
- kirjoittaa
- X
- te
- Sinun
- zephyrnet
- Postinumero
- ZOO