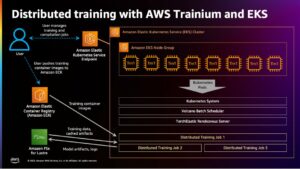
Large Language Model (LLM) -koulutuksen suosio on kasvanut viime vuoden aikana useiden suosittujen mallien, kuten Llama 2, Falcon ja Mistral, julkaisun myötä. Asiakkaat esikouluttavat ja hienosäätävät LLM:itä, joiden parametrit vaihtelevat 1 miljardista yli 175 miljardiin parametriin optimoidakseen mallin suorituskyvyn sovelluksille eri aloilla terveydenhuollosta rahoitukseen ja markkinointiin.
Suorittavien mallien kouluttaminen tässä mittakaavassa voi olla haaste. Erittäin tarkat LLM:t voivat vaatia teratavuja harjoitustietoa ja tuhansia tai jopa miljoonia tunteja kiihdytinlaskenta-aikaa saavuttaakseen tavoitetarkkuuden. Saattaakseen koulutuksen loppuun ja tuoda tuotteita markkinoille ajoissa asiakkaat luottavat rinnakkaisuustekniikoihin jakaakseen tämän valtavan työtaakan jopa tuhansien kiihdytinlaitteiden kesken. Näitä rinnakkaistekniikoita voi kuitenkin olla vaikea käyttää: erilaiset tekniikat ja kirjastot ovat yhteensopivia vain tiettyjen työkuormien kanssa tai rajoittuvat tiettyihin malliarkkitehtuureihin, koulutussuorituskyky voi olla erittäin herkkä epäselville kokoonpanoille, ja tekniikan taso kehittyy nopeasti. Tämän seurauksena koneoppimisen harjoittajien on valmistauduttava viikkoja skaalaamaan LLM-työkuormituksensa suuriin GPU-ryhmiin.
Tässä viestissä korostamme uusia ominaisuuksia Amazon Sage Maker mallin rinnakkaiskirjasto (SMP), joka yksinkertaistaa laajaa mallin koulutusprosessia ja auttaa sinua kouluttamaan LLM:itä nopeammin. Käsittelemme erityisesti SMP-kirjaston uuden yksinkertaistetun käyttökokemuksen, joka perustuu avoimen lähdekoodin PyTorch Fully Sharded Data Parallel (FSDP) API:iin, laajennetun tensorin rinnakkaistoiminnon, joka mahdollistaa satojen miljardien parametrien harjoitusmallit, sekä suorituskyvyn optimoinnit, jotka vähentävät mallin koulutusaikaa. ja maksaa jopa 20 %.
Lisätietoja SageMaker-mallin rinnakkaiskirjastosta on kohdassa SageMaker-mallin rinnakkaiskirjasto v2 dokumentointi. Voit myös viitata meidän esimerkkimuistikirjoja päästä alkuun.
Uusia ominaisuuksia, jotka yksinkertaistavat ja nopeuttavat suurten mallien koulutusta
Tässä viestissä käsitellään uusimpia ominaisuuksia, jotka sisältyvät SageMaker-mallin rinnakkaiskirjaston v2.0-julkaisuun. Nämä ominaisuudet parantavat kirjaston käytettävyyttä, laajentavat toimintoja ja nopeuttavat harjoittelua. Seuraavissa osioissa teemme yhteenvedon uusista ominaisuuksista ja keskustelemme siitä, kuinka voit käyttää kirjastoa suuren mallin harjoittelun nopeuttamiseen.
SMP:n kohdistaminen avoimen lähdekoodin PyTorchin kanssa
Vuoden 2020 julkaisustaan lähtien SMP on mahdollistanut korkean suorituskyvyn laajamittaisen koulutuksen SageMaker-laskentaesiintymistä. Tällä SMP:n uusimmalla suurella versiolla kirjasto yksinkertaistaa käyttökokemusta kohdistamalla API:t avoimen lähdekoodin PyTorchin kanssa.
PyTorch tarjoaa Täysin jaetun tiedon rinnakkaisuus (FSDP) sen päämenetelmänä suuren koulutustyömäärän tukemiseksi monissa tietokonelaitteissa. Kuten seuraavassa koodinpätkässä osoitetaan, SMP:n päivitetyt API:t tekniikoille, kuten sirpaloitujen tietojen rinnakkaisuus, heijastavat PyTorchin vastaavia. Voit yksinkertaisesti juosta import torch.sagemaker ja käytä sitä tilalle torch.
Näiden SMP:n API-päivitysten avulla voit nyt toteuttaa SageMakerin ja SMP-kirjaston suorituskykyedut ilman olemassa olevien PyTorch FSDP -koulutuskomentosarjojesi uudistamista. Tämä paradigma mahdollistaa myös saman koodipohjan käyttämisen tiloissa harjoitellessa kuin SageMakerissa, mikä yksinkertaistaa useissa ympäristöissä harjoittelevien asiakkaiden käyttökokemusta.
Lisätietoja SMP:n ottamisesta käyttöön olemassa olevien PyTorch FSDP -koulutuskomentosarjojesi kanssa on kohdassa Aloita SMP:n käyttö.
Tensorin rinnakkaisuuden integrointi mahdollistaa harjoittelun massiivisilla klustereilla
Tämä SMP-julkaisu laajentaa myös PyTorch FSDP:n ominaisuuksia sisältämään tensorin rinnakkaistekniikat. Yksi ongelma, kun käytät sirpaloitua dataa yhdensuuntaisuudella, on se, että voit kohdata konvergenssiongelmia, kun suurennat klusterin kokoa. Tämä johtuu siitä, että parametrien, liukuvärien ja optimoijan tilan jakaminen tietojen rinnakkaisissa riveissä lisää myös globaalia eräkokoa. suurilla klustereilla tämä globaali eräkoko voidaan työntää kynnyksen yli, jonka alapuolelle malli lähentyisi. Sinun on otettava käyttöön ylimääräinen rinnakkaistekniikka, joka ei vaadi globaalin eräkoon kasvattamista klusterin skaalauksen aikana.
Tämän ongelman lieventämiseksi SMP v2.0 esittelee mahdollisuuden muodostaa sirpaloitujen tietojen rinnakkaisuus tensorin rinnakkaisuudella. Tensorin rinnakkaisuus mahdollistaa klusterin koon kasvamisen muuttamatta globaalia eräkokoa tai vaikuttamatta mallin konvergenssiin. Tämän ominaisuuden avulla voit turvallisesti lisätä koulutuksen suorituskykyä luomalla klustereita, joissa on 256 solmua tai enemmän.
Nykyään tensorin rinnakkaisuus PyTorch FSDP:n kanssa on saatavilla vain SMP v2:ssa. SMP v2:n avulla voit ottaa tämän tekniikan käyttöön muutaman rivin koodinvaihdolla ja vapauttaa vakaan harjoittelun jopa suurissa klustereissa. SMP v2 integroituu Muuntaja moottori tensorin rinnakkaisuuden toteuttamiseen ja tekee siitä yhteensopivan PyTorchin FSDP API:iden kanssa. Voit ottaa PyTorch FSDP:n ja SMP-tensorin rinnakkaisuuden käyttöön samanaikaisesti tekemättä muutoksia PyTorch-malliisi tai PyTorch FSDP -kokoonpanoon. Seuraavat koodinpätkät osoittavat, kuinka SMP-määrityssanakirja määritetään JSON-muodossa ja lisätään SMP-alustusmoduuli torch.sagemaker.init(), joka hyväksyy taustaohjelmassa olevan määrityssanakirjan, kun aloitat harjoitustyön, harjoitusskriptiisi.
SMP-kokoonpano on seuraava:
Käytä harjoitusskriptissäsi seuraavaa koodia:
Lisätietoja tensorin rinnakkaisuuden käyttämisestä SMP:ssä on kohdassa tensorin rinnakkaisuus osa dokumentaatiostamme.
Käytä edistyneitä ominaisuuksia nopeuttaaksesi mallin harjoittelua jopa 20 %
Sen lisäksi, että SMP mahdollistaa hajautetun koulutuksen satojen esiintymien klustereissa, se tarjoaa myös optimointitekniikoita, jotka voivat nopeuttaa mallin koulutusta jopa 20 %. Tässä osiossa korostamme muutamia näistä optimoinneista. Lisätietoja saat osoitteesta ydinominaisuudet osa dokumentaatiostamme.
Hybridi sirpalointi
Jaettujen tietojen rinnakkaisuus on muistia säästävä hajautettu koulutustekniikka, joka jakaa mallin tilan (malliparametrit, gradientit ja optimointitilat) eri laitteille. Tämän pienemmän muistitilan ansiosta voit sovittaa suuremman mallin klusteriisi tai kasvattaa eräkokoa. Sirpaloitujen tietojen rinnakkaisuus lisää kuitenkin myös koulutustyösi viestintävaatimuksia, koska sirpaloituja malliartefakteja kerätään usein eri laitteista harjoituksen aikana. Tällä tavalla sirpalointiaste on tärkeä konfiguraatio, joka kompensoi muistin kulutusta ja tiedonsiirtokustannuksia.
PyTorch FSDP -sirpaleet mallintavat artefakteja oletuksena kaikissa klusterisi kiihdytinlaitteissa. Harjoittelutyöstäsi riippuen tämä sirpalointimenetelmä voi lisätä viestintäkustannuksia ja luoda pullonkaulan. Tämän helpottamiseksi SMP-kirjasto tarjoaa PyTorch FSDP:n päälle määritettävän hybridi-shared datan rinnakkaisuuden. Tämän ominaisuuden avulla voit määrittää sharding-asteen, joka on optimaalinen harjoitustyökuormituksellesi. Yksinkertaisesti määritä jakoaste määrityksen JSON-objektissa ja sisällytä se SMP-harjoitusskriptiisi.
SMP-kokoonpano on seuraava:
Lisätietoja sirpaloitujen hybriditietojen rinnakkaisuuden eduista on kohdassa AWS:n jättimäisen mallikoulutuksen lähes lineaarinen skaalaus. Lisätietoja hybridiharjoituksen toteuttamisesta olemassa olevan FSDP-koulutusskriptin kanssa on kohdassa hybridi jaetun datan rinnakkaisuus dokumentaatiossamme.
Käytä AWS-infrastruktuurille optimoituja SMDDP-kollektiivisia viestintätoimintoja
Voit käyttää SMP-kirjastoa SageMaker hajautetun tiedon rinnakkaisuuden (SMDDP) kirjasto nopeuttaaksesi hajautettua harjoitteluasi. SMDDP sisältää optimoidun AllGather kollektiivinen viestintätoiminto, joka on suunniteltu parhaaseen suorituskykyyn SageMaker p4d- ja p4de-kiihdytetyissä tapauksissa. Hajautetussa koulutuksessa kollektiivisia viestintätoimintoja käytetään tietojen synkronointiin GPU-työntekijöiden välillä. AllGather on yksi keskeisistä kollektiivisista viestintäoperaatioista, joita tyypillisesti käytetään sirpaloidussa datan rinnakkaisuudessa kerroksen parametrien materialisoimiseksi ennen eteenpäin- ja taaksepäinlaskennan vaiheita. Viestinnän pullonkaulaa koskevissa koulutustehtävissä nopeammat kollektiiviset toiminnot voivat vähentää koulutusaikaa ja -kustannuksia ilman, että konvergenssiin kohdistuu sivuvaikutuksia.
Jotta voit käyttää SMDDP-kirjastoa, sinun tarvitsee vain lisätä kaksi riviä koodia harjoitusskriptiin:
SMP:n lisäksi SMDDP tukee avoimen lähdekoodin PyTorch FSDP:tä ja DeepSpeediä. Lisätietoja SMDDP-kirjastosta on kohdassa Suorita hajautettu koulutus SageMaker-hajautetun tiedon rinnakkaisuuskirjaston avulla.
Aktivoinnin purkaminen
Tyypillisesti malliharjoittelun eteenpäinkulku laskee aktivaatiot jokaisessa tasossa ja säilyttää ne GPU-muistissa, kunnes vastaavan tason siirto taaksepäin päättyy. Nämä tallennetut aktivaatiot voivat kuluttaa huomattavasti GPU-muistia harjoituksen aikana. Aktivoinnin purkaminen on tekniikka, joka sen sijaan siirtää nämä tensorit suorittimen muistiin eteenpäinsiirron jälkeen ja hakee ne myöhemmin takaisin GPU:lle, kun niitä tarvitaan. Tämä lähestymistapa voi vähentää huomattavasti GPU-muistin käyttöä harjoittelun aikana.
Vaikka PyTorch tukee aktivoinnin purkamista, sen toteutus on tehotonta ja voi aiheuttaa GPU:t olemaan käyttämättömänä, kun aktivaatiot haetaan takaisin suorittimesta taaksepäin siirron aikana. Tämä voi aiheuttaa merkittävää suorituskyvyn heikkenemistä käytettäessä aktivoinnin purkamista.
SMP v2 tarjoaa optimoidun aktivointialgoritmin, joka voi parantaa harjoituksen suorituskykyä. SMP:n toteutus esihakee aktivaatiot ennen kuin niitä tarvitaan GPU:ssa, mikä vähentää joutoaikaa.
Koska SMP on rakennettu PyTorchin sovellusliittymien päälle, optimoidun aktivoinnin purkamisen mahdollistaminen vaatii vain muutaman koodirivin muutoksen. Lisää vain siihen liittyvät asetukset (sm_activation_offloading ja activation_loading_horizon parametrit) ja sisällytä ne harjoitusohjelmaasi.
SMP-kokoonpano on seuraava:
Käytä harjoitusskriptissä seuraavaa koodia:
Lisätietoja avoimen lähdekoodin PyTorchin tarkistuspistetyökaluista aktivoinnin purkamiseen on osoitteessa checkpoint_wrapper.py komentosarja PyTorch GitHub -varastossa ja Aktivoinnin tarkistuspiste PyTorch-blogiviestissä Multimodaalisten perusmallien skaalaus TorchMultimodalissa ja Pytorch Distributed. Lisätietoja SMP:n optimoidusta aktivoinnin purkamisesta on kohdassa aktivoinnin purkaminen osa dokumentaatiostamme.
Hybridin sirpaloinnin, SMDDP:n ja aktivoinnin purkamisen lisäksi SMP tarjoaa lisäoptimointeja, jotka voivat nopeuttaa suurta mallin harjoittelua. Tämä sisältää optimoidun aktivoinnin tarkistuspisteen, viivästyneen parametrin alustuksen ja muut. Lisätietoja saat osoitteesta ydinominaisuudet osa dokumentaatiostamme.
Yhteenveto
Kun tietojoukot, mallikoot ja koulutusklusterit kasvavat jatkuvasti, tehokas hajautettu koulutus on yhä tärkeämpää oikea-aikaisen ja edullisen mallin ja tuotteen toimittamisen kannalta. SageMaker-mallin rinnakkaiskirjaston uusin julkaisu auttaa sinua saavuttamaan tämän vähentämällä koodin muutosta ja mukauttamalla PyTorch FSDP API:iden kanssa, mahdollistaen massiivisten klustereiden koulutuksen tensorin rinnakkaisuuden ja optimointien avulla, jotka voivat lyhentää harjoitusaikaa jopa 20%.
Aloita SMP v2:n käyttö tutustumalla artikkeliimme dokumentointi ja meidän näytekannettavat.
Tietoja Tekijät
 Robert Van Dusen on vanhempi tuotepäällikkö Amazon SageMakerissa. Hän johtaa puitteita, kääntäjiä ja optimointitekniikoita syväoppimisen koulutukseen.
Robert Van Dusen on vanhempi tuotepäällikkö Amazon SageMakerissa. Hän johtaa puitteita, kääntäjiä ja optimointitekniikoita syväoppimisen koulutukseen.
 Luis Quintela on AWS SageMaker -mallin rinnakkaiskirjaston Software Developer Manager. Vapaa-ajallaan hänet löytää Harleylla ratsastamassa SF Bayn alueella.
Luis Quintela on AWS SageMaker -mallin rinnakkaiskirjaston Software Developer Manager. Vapaa-ajallaan hänet löytää Harleylla ratsastamassa SF Bayn alueella.
 Gautam Kumar on ohjelmistosuunnittelija, jolla on AWS AI Deep Learning. Hän on intohimoinen tekoälyn työkalujen ja järjestelmien rakentamiseen. Vapaa-ajallaan hän harrastaa pyöräilyä ja kirjojen lukemista.
Gautam Kumar on ohjelmistosuunnittelija, jolla on AWS AI Deep Learning. Hän on intohimoinen tekoälyn työkalujen ja järjestelmien rakentamiseen. Vapaa-ajallaan hän harrastaa pyöräilyä ja kirjojen lukemista.
 Rahul Huilgol on vanhempi ohjelmistokehitysinsinööri hajautetussa syväoppimisessa Amazon Web Services -palvelussa.
Rahul Huilgol on vanhempi ohjelmistokehitysinsinööri hajautetussa syväoppimisessa Amazon Web Services -palvelussa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-model-parallel-library-now-accelerates-pytorch-fsdp-workloads-by-up-to-20/
- :on
- :On
- $ YLÖS
- 1
- 10
- 100
- 14
- 16
- 2020
- 7
- 8
- 9
- a
- kyky
- Meistä
- kiihdyttää
- kiihtyi
- kiihdyttää
- kiihdytin
- hyväksyy
- tarkkuus
- tarkka
- Saavuttaa
- poikki
- Aktivointi
- aktivoinnit
- lisätä
- Lisäksi
- lisä-
- kehittynyt
- etuja
- vaikuttavat
- edullinen
- Jälkeen
- AI
- algoritmi
- algoritmit
- tasaus
- Kaikki
- mahdollistaa
- yksin
- Myös
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- ja
- Kaikki
- API
- sovellukset
- lähestymistapa
- OVAT
- ALUE
- Art
- AS
- liittyvä
- At
- saatavissa
- AWS
- takaisin
- taustaosa
- pohja
- Lahti
- BE
- koska
- ennen
- alle
- Hyödyt
- PARAS
- Jälkeen
- Miljardi
- miljardeja
- Blogi
- Kirjat
- Rakentaminen
- rakentaa
- rakennettu
- by
- CAN
- kyvyt
- Aiheuttaa
- tietty
- haaste
- muuttaa
- Muutokset
- muuttuviin
- Cluster
- koodi
- koodikanta
- Kollektiivinen
- Viestintä
- yhteensopiva
- täydellinen
- laskeminen
- Laskea
- Konfigurointi
- kuluttaa
- kulutus
- jatkaa
- suppenee
- Lähentyminen
- Ydin
- vastaava
- Hinta
- voisi
- kattaa
- prosessori
- luoda
- kriittinen
- Asiakkaat
- tiedot
- aineistot
- syvä
- syvä oppiminen
- oletusarvo
- Aste
- Myöhässä
- toimitus
- osoittivat
- Riippuen
- suunniteltu
- Kehittäjä
- Kehitys
- Laitteet
- eri
- vaikea
- pohtia
- jakaa
- jaettu
- hajautettu koulutus
- dokumentointi
- ei
- aikana
- kukin
- vaikutukset
- tehokas
- mahdollistaa
- käytössä
- mahdollistaa
- mahdollistaa
- kohdata
- insinööri
- nauttia
- valtava
- ympäristöissä
- Eetteri (ETH)
- Jopa
- kehittyvä
- olemassa
- Laajentaa
- laajeni
- laajenee
- experience
- haukka
- nopeampi
- Ominaisuus
- Ominaisuudet
- Haettu
- harvat
- rahoittaa
- sovittaa
- jälkeen
- seuraa
- Jalanjälki
- varten
- muoto
- Eteenpäin
- löytyi
- perusta
- puitteet
- usein
- alkaen
- täysin
- toiminnallisuus
- kokosi
- saada
- GitHub
- Global
- GPU
- GPU
- kaltevuudet
- Kasvaa
- he
- terveydenhuollon
- auttaa
- auttaa
- korkea suorituskyky
- Korostaa
- erittäin
- hänen
- TUNTIA
- Miten
- Miten
- Kuitenkin
- HTML
- HTTPS
- Sadat
- Hybridi
- Idle
- täytäntöönpano
- täytäntöönpanosta
- tuoda
- tärkeä
- parantaa
- in
- sisältää
- mukana
- sisältää
- sisällyttää
- Kasvaa
- Lisäykset
- yhä useammin
- teollisuuden
- tehoton
- tiedot
- tapauksia
- sen sijaan
- integroi
- tulee
- Esittelee
- IT
- SEN
- Job
- Työpaikat
- jpg
- json
- vain
- Kieli
- suuri
- laaja
- suurempi
- Sukunimi
- Viime vuonna
- myöhemmin
- uusin
- Viimeisin julkaisu
- käynnistää
- kerros
- Liidit
- OPPIA
- oppiminen
- kirjastot
- Kirjasto
- linjat
- liekki
- kone
- koneoppiminen
- tärkein
- merkittävä
- TEE
- Tekeminen
- johtaja
- tapa
- monet
- Marketing
- massiivinen
- toteutua
- Muisti
- menetelmä
- miljoonia
- peili
- lieventää
- malli
- mallit
- moduuli
- lisää
- liikkuu
- moninkertainen
- täytyy
- syntyperäinen
- Tarve
- tarvitaan
- Uusi
- Uudet ominaisuudet
- Nro
- solmut
- nyt
- Nvidia
- objekti
- of
- pois
- Tarjoukset
- on
- ONE
- vain
- avata
- avoimen lähdekoodin
- toiminta
- Operations
- optimaalinen
- optimointi
- Optimoida
- optimoitu
- or
- Muuta
- meidän
- yli
- paradigma
- Parallel
- parametri
- parametrit
- erityinen
- kulkea
- intohimoinen
- suorituskyky
- Paikka
- Platon
- Platonin tietotieto
- PlatonData
- Suosittu
- suosio
- Kirje
- valmistelu
- Ongelma
- ongelmia
- prosessi
- Tuotteet
- tuotepäällikkö
- Tuotteemme
- työntää
- pytorch
- nopeasti
- alainen
- rivit
- Lukeminen
- ymmärtää
- vähentää
- vähentämällä
- katso
- vapauta
- luottaa
- säilytyspaikka
- edellyttää
- vaatimukset
- Vaatii
- rajoitettu
- johtua
- ratsastus
- ajaa
- turvallisesti
- sagemaker
- sama
- Asteikko
- skaalaus
- käsikirjoitus
- skriptejä
- Osa
- osiot
- nähdä
- vanhempi
- sensible
- Palvelut
- setti
- useat
- sirpaleinen
- sharding
- yhteinen
- näyttää
- puoli
- merkittävä
- yksinkertaistettu
- yksinkertaistetaan
- yksinkertaistaa
- yksinkertaistaminen
- yksinkertaisesti
- samanaikaisesti
- Koko
- koot
- pienempiä
- pätkä
- Tuotteemme
- ohjelmistokehitys
- Software Engineer
- lähde
- viettää
- splits
- vakaa
- Alkaa
- alkoi
- Osavaltio
- Valtiot
- Askeleet
- tallennettu
- merkittävästi
- niin
- yhteenveto
- Tukea
- Tukee
- kiihtyi
- järjestelmät
- Kohde
- tekniikka
- tekniikat
- että
- -
- Valtion
- heidän
- Niitä
- Nämä
- ne
- tätä
- ne
- tuhansia
- kynnys
- suoritusteho
- aika
- ajankohtainen
- että
- työkalut
- ylin
- taskulamppu
- kaupat
- Juna
- koulutus
- muuntajat
- totta
- kaksi
- tyypillisesti
- avata
- asti
- päivitetty
- Päivitykset
- käytettävyys
- Käyttö
- käyttää
- käytetty
- käyttäjä
- Käyttäjäkokemus
- käyttämällä
- versio
- kautta
- Tapa..
- we
- verkko
- verkkopalvelut
- viikkoa
- kun
- joka
- vaikka
- KUKA
- with
- ilman
- työntekijöitä
- olisi
- kääri
- vuosi
- te
- Sinun
- zephyrnet