Con el lanzamiento de la función de búsqueda neuronal para Servicio Amazon OpenSearch En OpenSearch 2.9, ahora es sencillo integrarlo con modelos de IA/ML para impulsar la búsqueda semántica y otros casos de uso. OpenSearch Service ha admitido la búsqueda léxica y vectorial desde la introducción de su función k-vecino más cercano (k-NN) en 2020; sin embargo, configurar la búsqueda semántica requería crear un marco para integrar modelos de aprendizaje automático (ML) para la ingesta y la búsqueda. La función de búsqueda neuronal facilita la transformación de texto a vector durante la ingesta y la búsqueda. Cuando utiliza una consulta neuronal durante la búsqueda, la consulta se traduce en una incrustación de vectores y se usa k-NN para devolver las incrustaciones de vectores más cercanas del corpus.
Para utilizar la búsqueda neuronal, debe configurar un modelo de ML. Recomendamos configurar conectores AI/ML para los servicios AI y ML de AWS (como Amazon SageMaker or lecho rocoso del amazonas) o alternativas de terceros. A partir de la versión 2.9 de OpenSearch Service, los conectores AI/ML se integran con la búsqueda neuronal para simplificar y poner en funcionamiento la traducción de su corpus de datos y consultas a incrustaciones de vectores, eliminando así gran parte de la complejidad de la hidratación y la búsqueda de vectores.
En esta publicación, demostramos cómo configurar conectores AI/ML para modelos externos a través de la consola del servicio OpenSearch.
Descripción general de la solución
Específicamente, esta publicación lo guiará para conectarse a un modelo en SageMaker. Luego, lo guiaremos en el uso del conector para configurar la búsqueda semántica en OpenSearch Service como ejemplo de un caso de uso compatible mediante la conexión a un modelo de ML. Las integraciones de Amazon Bedrock y SageMaker actualmente son compatibles con la interfaz de usuario de la consola de OpenSearch Service, y la lista de integraciones propias y de terceros compatibles con la interfaz de usuario seguirá creciendo.
Para cualquier modelo que no sea compatible con la interfaz de usuario, puede configurarlo utilizando las API disponibles y la Planos de aprendizaje automático. Para obtener más información, consulte Introducción a los modelos OpenSearch. Puede encontrar planos para cada conector en el Repositorio de ML Commons en GitHub.
Requisitos previos
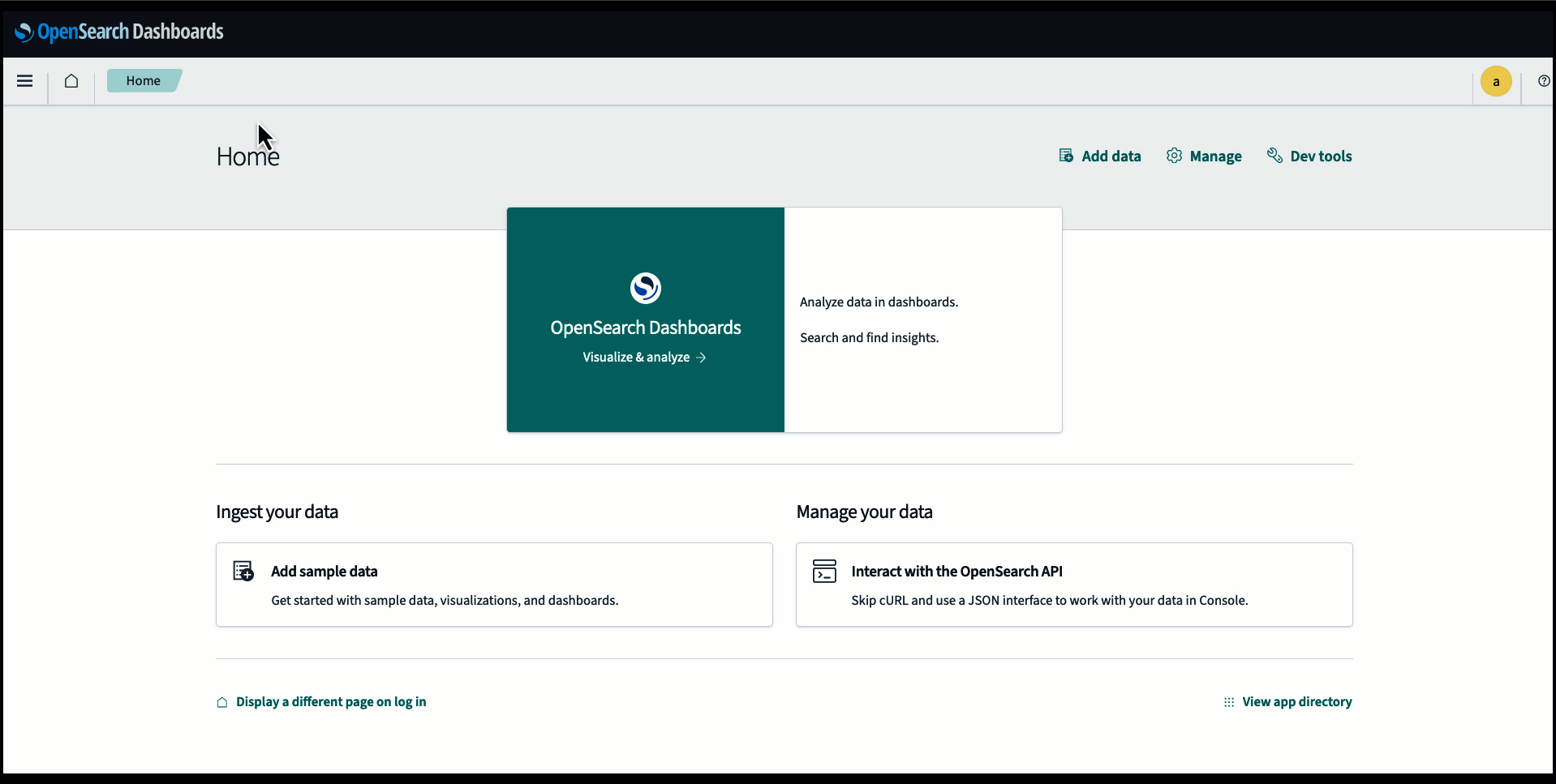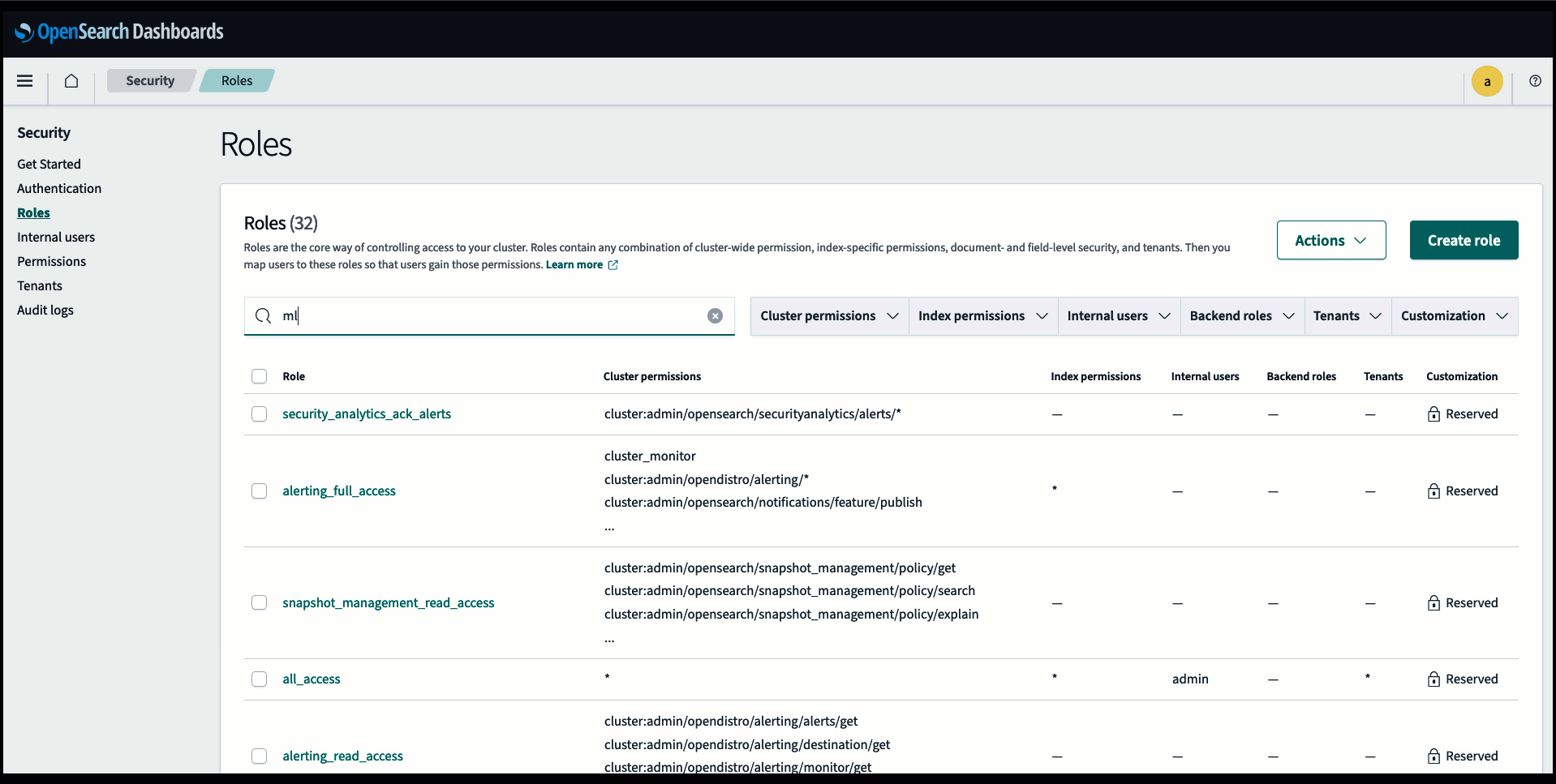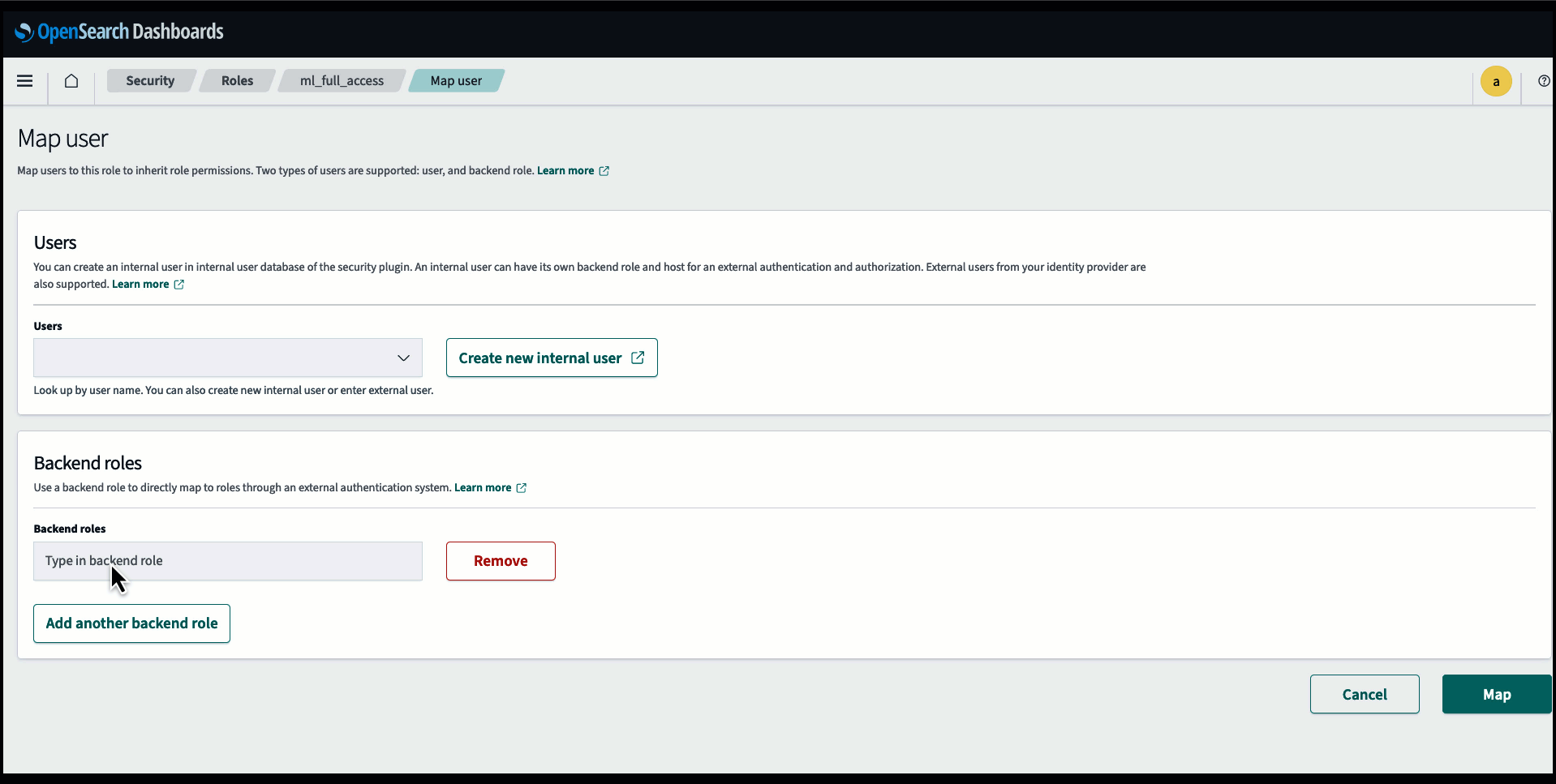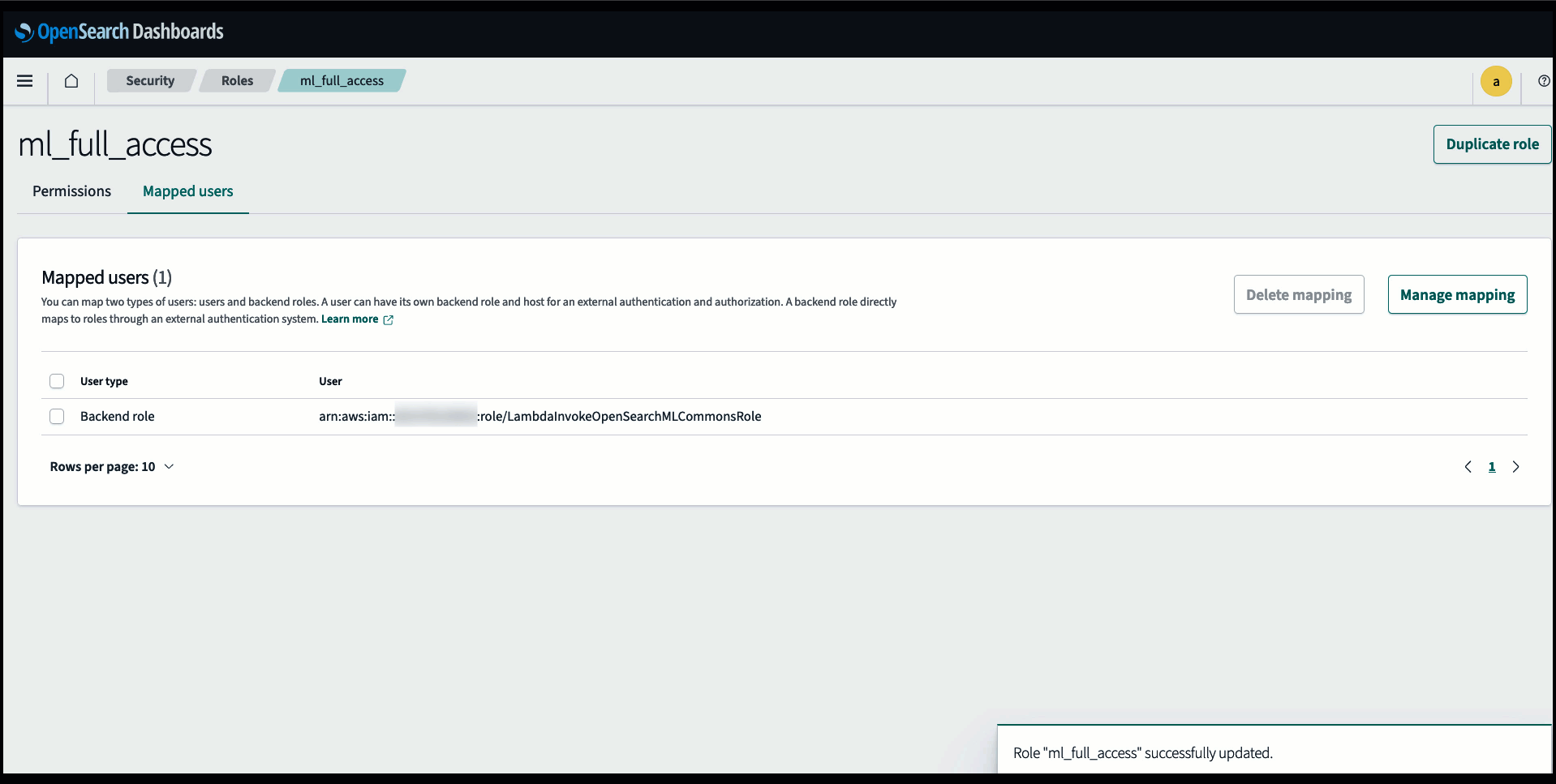
Antes de conectar el modelo a través de la consola del servicio OpenSearch, cree un dominio del servicio OpenSearch. Mapear un Gestión de identidades y accesos de AWS (IAM) rol por nombre LambdaInvokeOpenSearchMLCommonsRole como función de backend en el ml_full_access rol usando el complemento de seguridad en OpenSearch Dashboards, como se muestra en el siguiente video. El flujo de trabajo de integraciones del servicio OpenSearch está precargado para utilizar el LambdaInvokeOpenSearchMLCommonsRole Función de IAM de forma predeterminada para crear el conector entre el dominio del servicio OpenSearch y el modelo implementado en SageMaker. Si utiliza una función de IAM personalizada en las integraciones de la consola del servicio OpenSearch, asegúrese de que la función personalizada esté asignada como función de backend con ml_full_access permisos antes de implementar la plantilla.
Implementar el modelo utilizando AWS CloudFormation
El siguiente vídeo muestra los pasos para utilizar la consola de OpenSearch Service para implementar un modelo en cuestión de minutos en Amazon SageMaker y generar el ID del modelo a través de los conectores AI. El primer paso es elegir Integraciones en el panel de navegación de la consola de AWS de OpenSearch Service, que dirige a una lista de integraciones disponibles. La integración se configura a través de una interfaz de usuario, que le solicitará las entradas necesarias.
Para configurar la integración, solo necesita proporcionar el punto final del dominio del servicio OpenSearch y proporcionar un nombre de modelo para identificar de forma única la conexión del modelo. De forma predeterminada, la plantilla implementa el modelo de transformadores de oraciones Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Cuando tu elijas Crear pila, serás dirigido al Formación en la nube de AWS consola. La plantilla de CloudFormation implementa la arquitectura que se detalla en el siguiente diagrama.

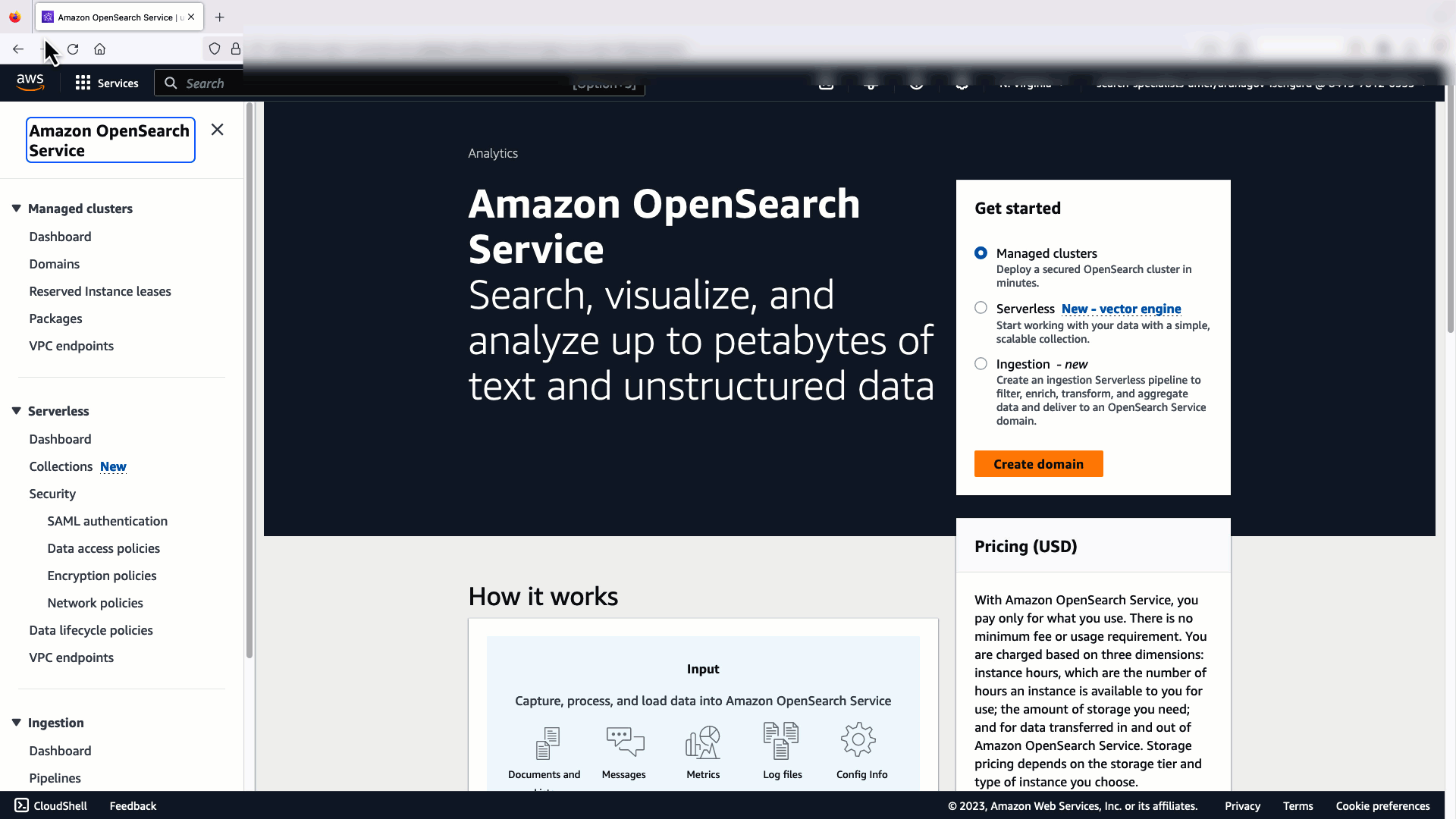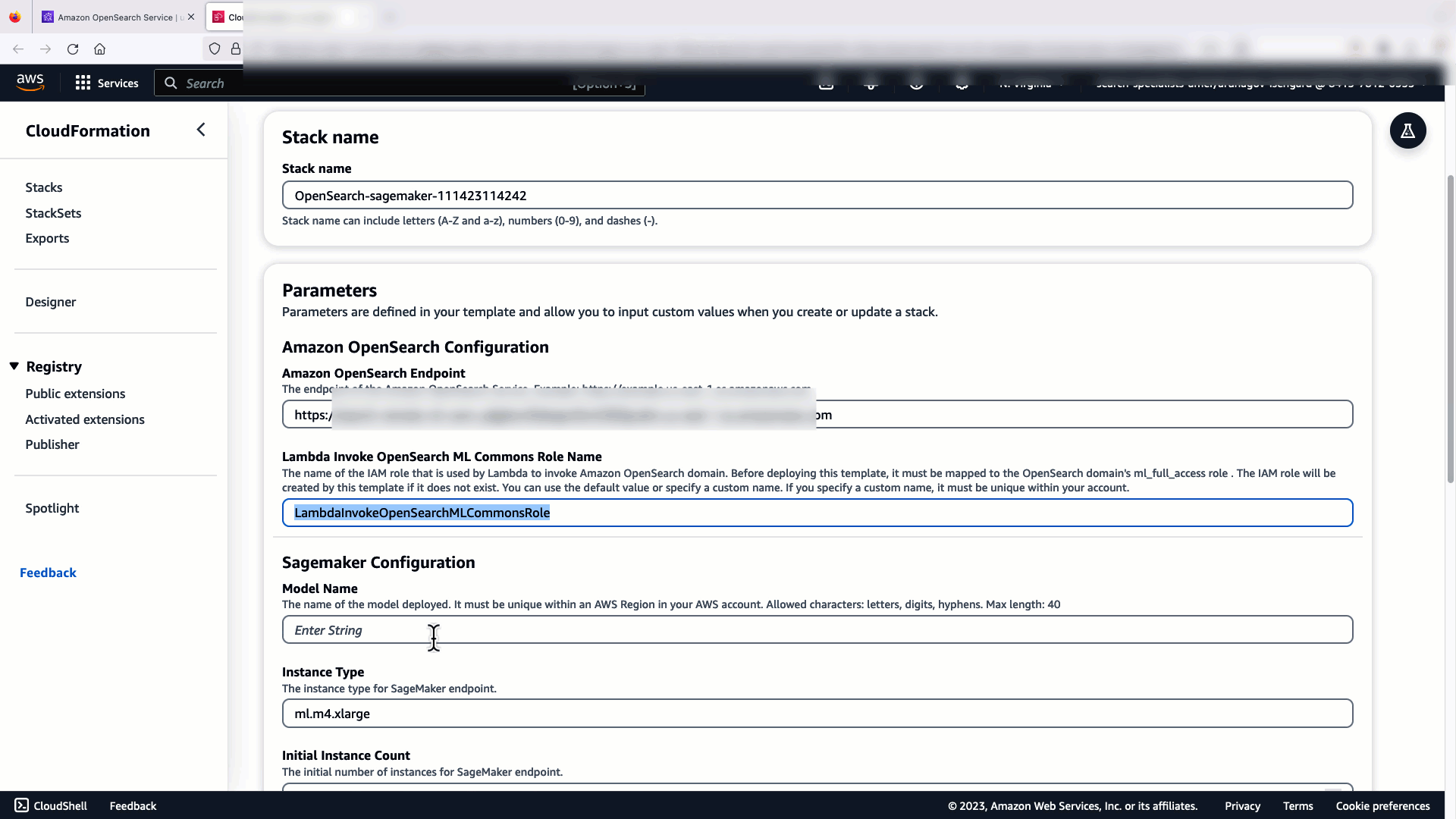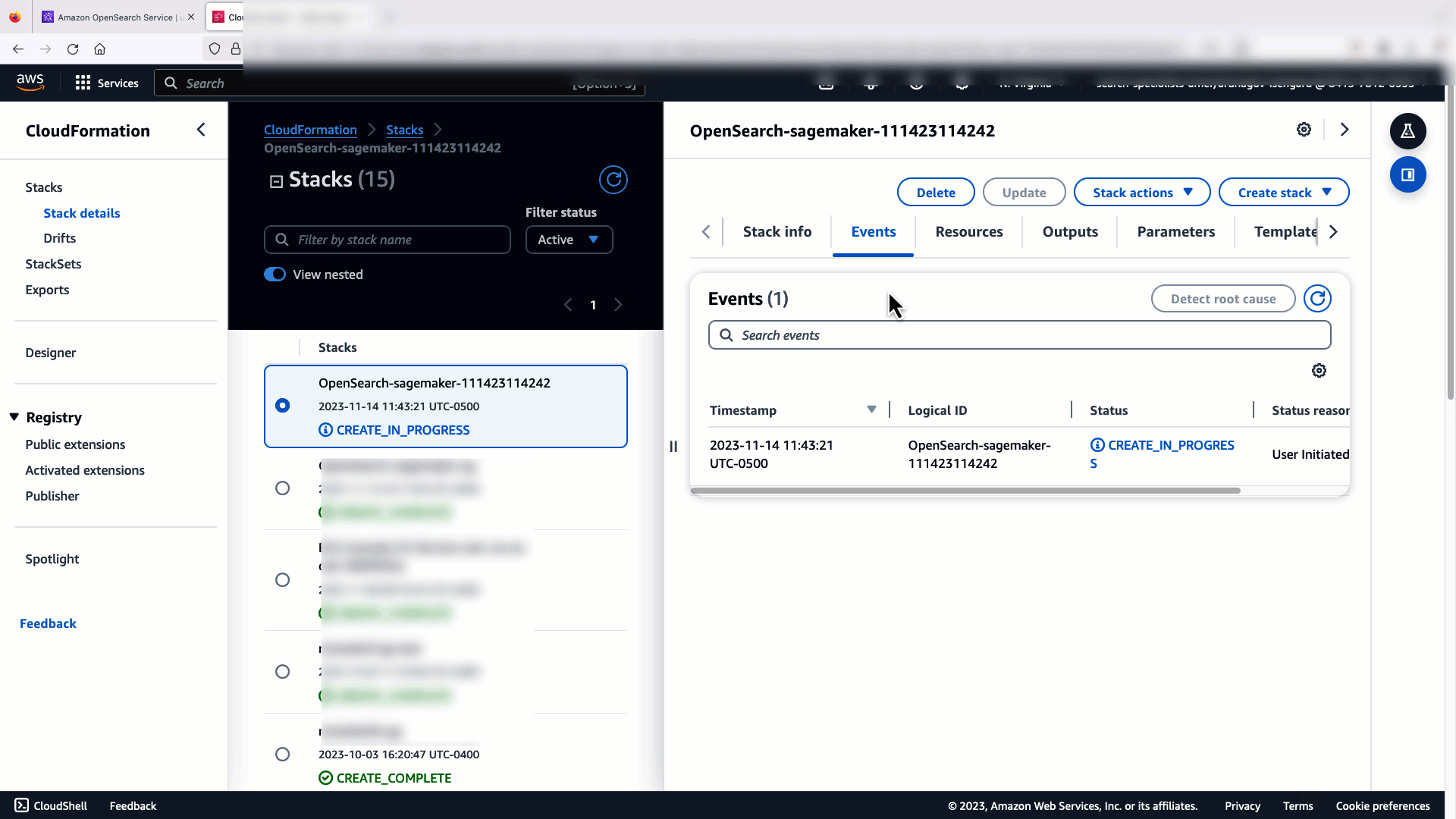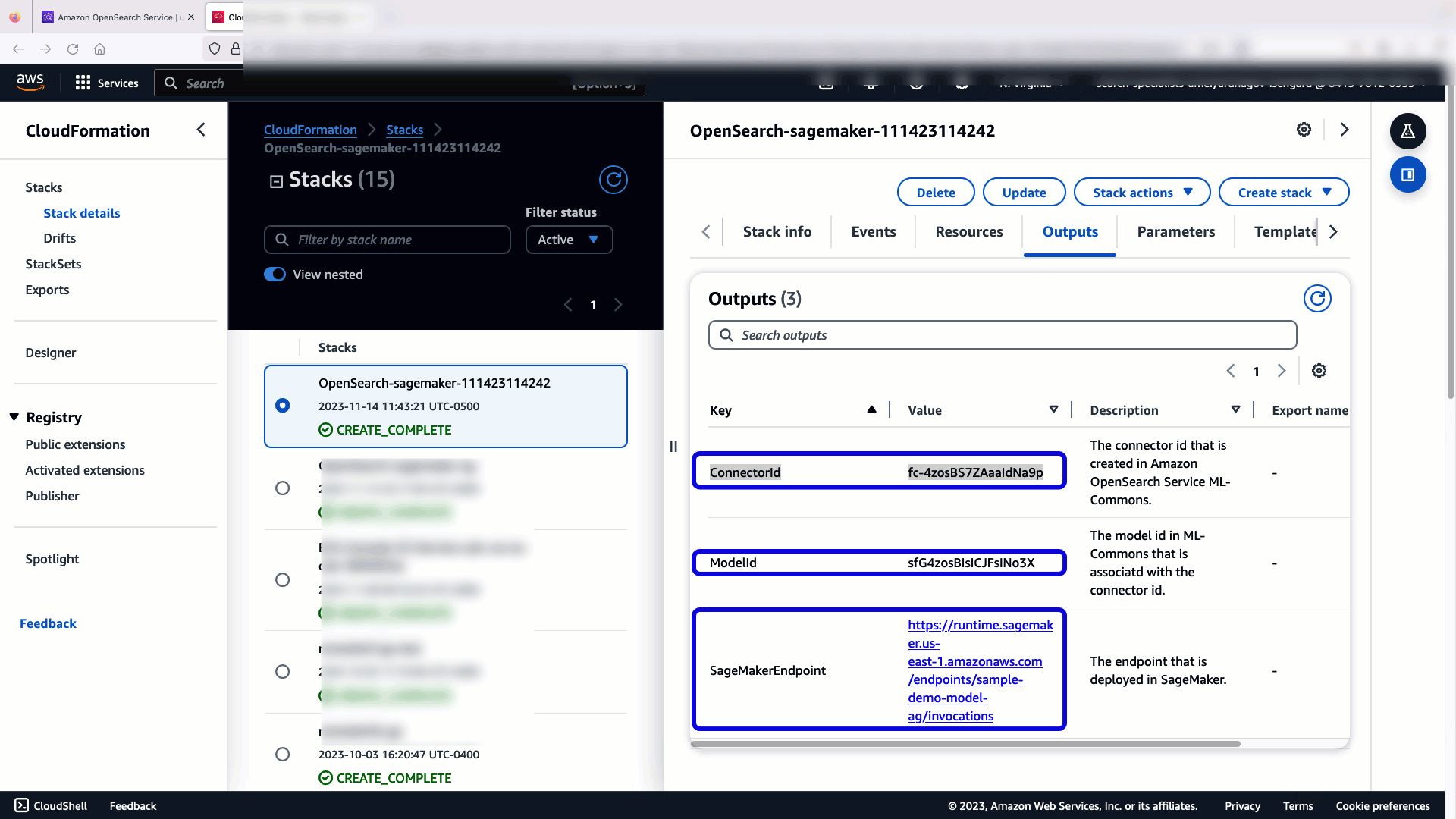
La pila de CloudFormation crea una AWS Lambda aplicación que implementa un modelo de Servicio de almacenamiento simple de Amazon (Amazon S3), crea el conector y genera el ID del modelo en la salida. Luego puede utilizar este ID de modelo para crear un índice semántico.
Si el modelo predeterminado All-MiniLM-L6-v2 no cumple con su propósito, puede implementar cualquier modelo de incrustación de texto de su elección en el modelo host elegido (SageMaker o Amazon Bedrock) proporcionando los artefactos de su modelo como un objeto S3 accesible. Alternativamente, puede seleccionar una de las siguientes modelos de lenguaje previamente entrenados e implementarlo en SageMaker. Para obtener instrucciones para configurar su punto final y sus modelos, consulte Imágenes disponibles de Amazon SageMaker.
SageMaker es un servicio totalmente administrado que reúne un amplio conjunto de herramientas para permitir un aprendizaje automático de alto rendimiento y bajo costo para cualquier caso de uso, brindando beneficios clave como monitoreo de modelos, alojamiento sin servidor y automatización del flujo de trabajo para capacitación e implementación continuas. SageMaker le permite alojar y administrar el ciclo de vida de los modelos de incrustación de texto y utilizarlos para impulsar consultas de búsqueda semántica en OpenSearch Service. Cuando está conectado, SageMaker aloja sus modelos y el servicio OpenSearch se utiliza para realizar consultas basadas en los resultados de inferencia de SageMaker.
Ver el modelo implementado a través de OpenSearch Dashboards
Para verificar que la plantilla de CloudFormation haya implementado correctamente el modelo en el dominio del servicio OpenSearch y obtener el ID del modelo, puede utilizar la API REST GET de ML Commons a través de las herramientas de desarrollo de OpenSearch Dashboards.
La API REST de GET _plugins ahora proporciona API adicionales para ver también el estado del modelo. El siguiente comando le permite ver el estado de un modelo remoto:
Como se muestra en la siguiente captura de pantalla, un DEPLOYED El estado en la respuesta indica que el modelo se implementó correctamente en el clúster del servicio OpenSearch.

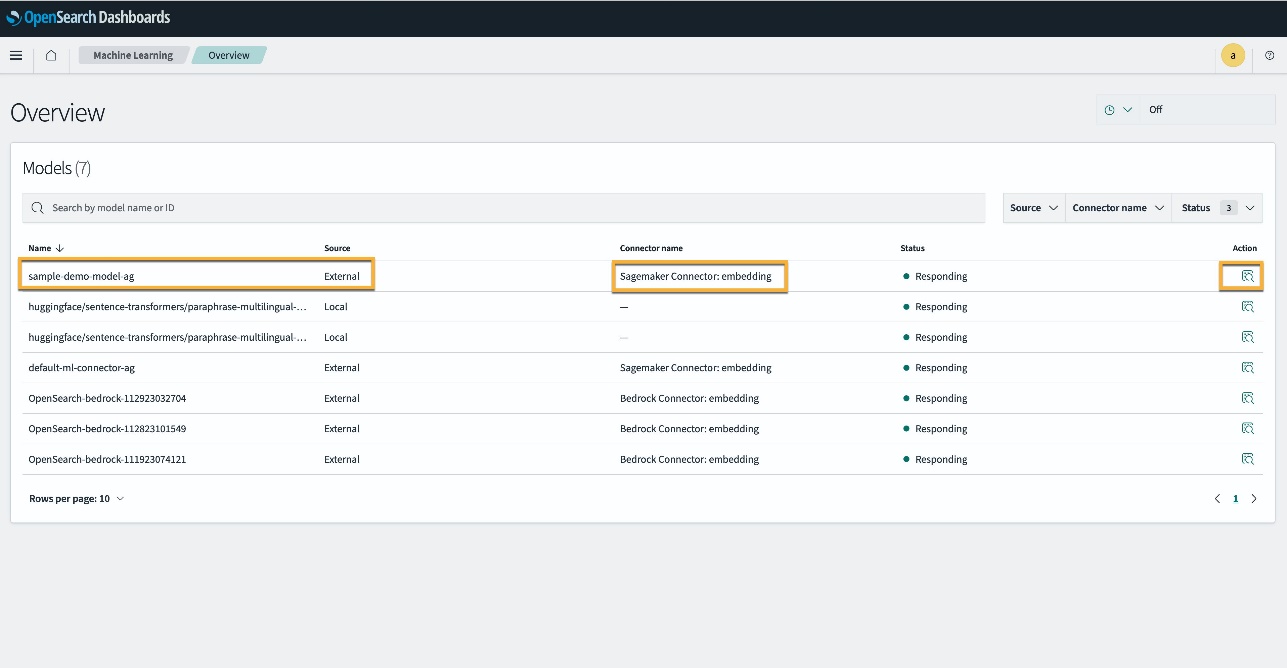
Alternativamente, puede ver el modelo implementado en su dominio de servicio OpenSearch usando el Aprendizaje automático (Machine learning & LLM) página de paneles de OpenSearch.

Esta página enumera la información del modelo y los estados de todos los modelos implementados.

Cree la tubería neuronal utilizando la ID del modelo.
Cuando el estado del modelo se muestra como DEPLOYED en Dev Tools o verde y Responder En OpenSearch Dashboards, puede utilizar el ID del modelo para crear su canal de ingesta neuronal. La siguiente canalización de ingesta se ejecuta en las herramientas de desarrollo de OpenSearch Dashboards de su dominio. Asegúrese de reemplazar el ID del modelo con el ID único generado para el modelo implementado en su dominio.

Cree el índice de búsqueda semántica utilizando la canalización neuronal como canalización predeterminada
Ahora puede definir su mapeo de índice con la canalización predeterminada configurada para usar la nueva canalización neuronal que creó en el paso anterior. Asegúrese de que los campos vectoriales estén declarados como knn_vector y las dimensiones son apropiadas para el modelo que se implementa en SageMaker. Si ha conservado la configuración predeterminada para implementar el modelo MiniLM-L6-v2 en SageMaker, mantenga la siguiente configuración como está y ejecute el comando en Dev Tools.

Ingerir documentos de muestra para generar vectores.
Para esta demostración, puede ingerir el muestra del catálogo de productos de demostración minorista al nuevo semantic_demostore índice. Reemplace el nombre de usuario, la contraseña y el punto final del dominio con la información de su dominio e ingiera los datos sin procesar en el servicio OpenSearch:

Validar el nuevo índice semantic_demostore
Ahora que ha incorporado su conjunto de datos al dominio del servicio OpenSearch, valide si los vectores requeridos se generan mediante una búsqueda simple para recuperar todos los campos. Validar si los campos definidos como knn_vectors tener los vectores requeridos.

Compare la búsqueda léxica y la búsqueda semántica impulsada por la búsqueda neuronal utilizando la herramienta Comparar resultados de búsqueda
El proyecto Herramienta Comparar resultados de búsqueda en OpenSearch Dashboards está disponible para cargas de trabajo de producción. Puedes navegar hasta el Comparar resultados de búsqueda y compare los resultados de la consulta entre la búsqueda léxica y la búsqueda neuronal configurada para utilizar el ID del modelo generado anteriormente.

Limpiar
Puede eliminar los recursos que creó siguiendo las instrucciones de esta publicación eliminando la pila de CloudFormation. Esto eliminará los recursos de Lambda y el depósito de S3 que contienen el modelo que se implementó en SageMaker. Complete los siguientes pasos:
- En la consola de AWS CloudFormation, navegue hasta la página de detalles de su pila.
- Elige Borrar.

- Elige Borrar para confirmar.

Puede monitorear el progreso de eliminación de la pila en la consola de AWS CloudFormation.
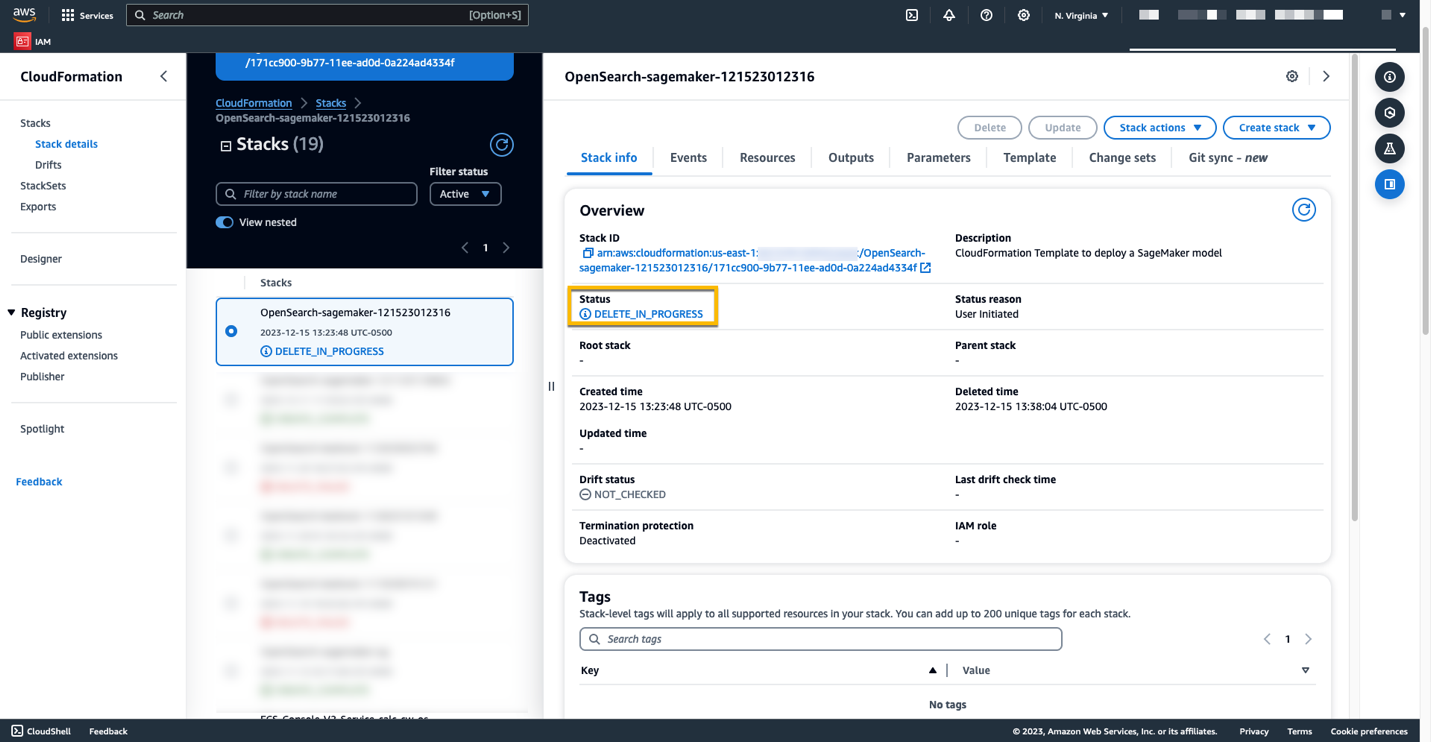
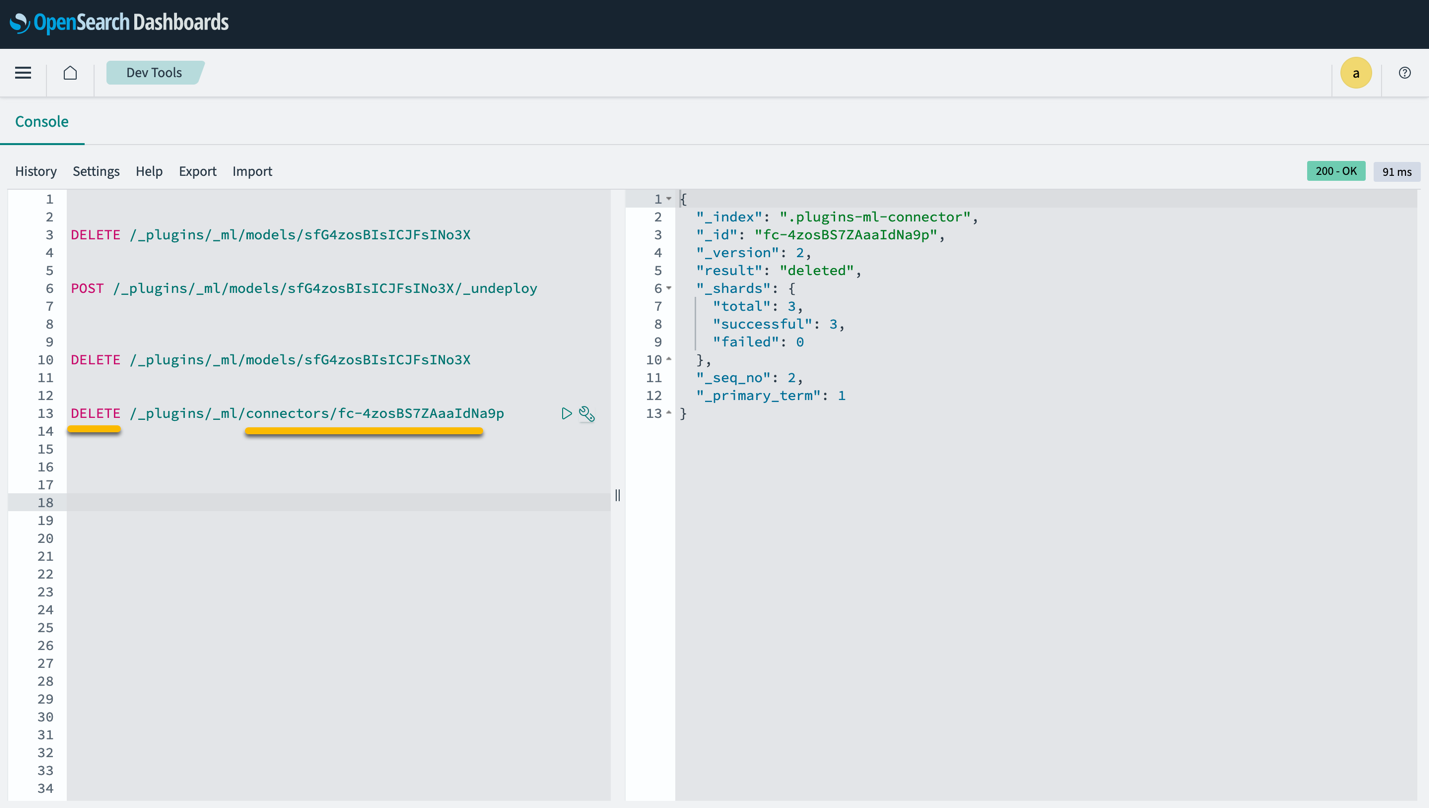
Tenga en cuenta que eliminar la pila de CloudFormation no elimina el modelo implementado en el dominio de SageMaker ni el conector AI/ML creado. Esto se debe a que estos modelos y el conector se pueden asociar con múltiples índices dentro del dominio. Para eliminar específicamente un modelo y su conector asociado, utilice las API del modelo como se muestra en las siguientes capturas de pantalla.
En primer lugar, undeploy el modelo de la memoria del dominio del servicio OpenSearch:

Luego puedes eliminar el modelo del índice de modelos:

Por último, elimine el conector del índice de conectores:
Conclusión
En esta publicación, aprendió cómo implementar un modelo en SageMaker, crear el conector AI/ML usando la consola del servicio OpenSearch y crear el índice de búsqueda neuronal. La capacidad de configurar conectores AI/ML en OpenSearch Service simplifica el proceso de hidratación de vectores al hacer que las integraciones con modelos externos sean nativas. Puede crear un índice de búsqueda neuronal en minutos utilizando la canalización de ingesta neuronal y la búsqueda neuronal que utiliza la ID del modelo para generar la incrustación del vector sobre la marcha durante la ingesta y la búsqueda.
Para obtener más información sobre estos conectores AI/ML, consulte Conectores de IA de Amazon OpenSearch Service para servicios de AWS, Integraciones de plantillas de AWS CloudFormation para búsqueda semánticay Creación de conectores para plataformas ML de terceros.
Acerca de los autores
 Aruna Govindaraju es un arquitecto de soluciones especializado en Amazon OpenSearch y ha trabajado con muchos motores de búsqueda comerciales y de código abierto. Le apasiona la búsqueda, la relevancia y la experiencia del usuario. Su experiencia en correlacionar las señales del usuario final con el comportamiento de los motores de búsqueda ha ayudado a muchos clientes a mejorar su experiencia de búsqueda.
Aruna Govindaraju es un arquitecto de soluciones especializado en Amazon OpenSearch y ha trabajado con muchos motores de búsqueda comerciales y de código abierto. Le apasiona la búsqueda, la relevancia y la experiencia del usuario. Su experiencia en correlacionar las señales del usuario final con el comportamiento de los motores de búsqueda ha ayudado a muchos clientes a mejorar su experiencia de búsqueda.
 David Braun es gerente principal de productos en AWS enfocado en OpenSearch.
David Braun es gerente principal de productos en AWS enfocado en OpenSearch.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :posee
- :es
- :no
- $ UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- capacidad
- Nuestra Empresa
- de la máquina
- accesible
- Adicionales
- AI
- AI / ML
- Todos
- permite
- también
- alternativas
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- y
- cualquier
- abejas
- API
- Aplicación
- adecuado
- arquitectura
- somos
- AS
- asociado
- At
- Automatización
- Hoy Disponibles
- AWS
- Formación en la nube de AWS
- Backend
- basado
- BE
- porque
- comportamiento
- beneficios
- entre
- ambas
- Trae
- general
- build
- Construir la
- by
- PUEDEN
- case
- cases
- catalogar
- manera?
- Elige
- elegido
- Médico
- completo
- Los comunes
- comparar
- completar
- complejidad
- Configuración
- configurado
- Configurando
- Confirmar
- conectado
- Conectándote
- conexión
- Consola
- que no contengo
- continue
- continuo
- correlacionando
- Para crear
- creado
- crea
- En la actualidad
- personalizado
- Clientes
- de los tableros
- datos
- Predeterminado
- definir
- se define
- entregar
- De demostración
- demostrar
- demuestra
- desplegar
- desplegado
- Desplegando
- despliegue
- despliega
- descripción
- detallado
- detalles
- Dev
- Dimensiones
- dimensiones
- documentos
- No
- dominio
- durante
- cada una
- Más temprano
- fácil
- ya sea
- incrustación
- habilitar
- Punto final
- Motor
- motores
- garantizar
- Éter (ETH)
- ejemplo
- experience
- Experiencia
- externo
- Cara
- facilita
- Feature
- Terrenos
- Encuentre
- Nombre
- centrado
- siguiendo
- Marco conceptual
- Desde
- completamente
- generar
- generado
- genera
- obtener
- gif
- GitHub
- Verde
- Crecer
- guía
- Tienen
- ayudado
- aquí
- Alto rendimiento
- fortaleza
- hosting
- anfitriones
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- AbrazandoCara
- hidratación
- AMI
- ID
- Identifique
- Identidad
- if
- mejorar
- in
- índice
- índices
- Indica
- información
- entradas
- Instrucciones
- integrar
- integración
- integraciones
- dentro
- Introducción
- IT
- SUS
- jpg
- json
- Guardar
- Clave
- idioma
- lanzamiento
- APRENDE:
- aprendido
- aprendizaje
- ciclo de vida
- Lista
- Listas
- de bajo costo
- máquina
- máquina de aprendizaje
- para lograr
- Realizar
- gestionan
- gestionado
- gerente
- muchos
- mapa
- cartografía
- Salud Cerebral
- Método
- minutos
- ML
- modelo
- modelos
- Monitorear
- monitoreo
- más,
- mucho más
- múltiples
- debe
- nombre
- nativo
- Navegar
- Navegación
- necesario
- ¿ Necesita ayuda
- Neural
- Nuevo
- ahora
- objeto
- of
- on
- ONE
- , solamente
- habiertos
- de código abierto
- or
- Otro
- salida
- página
- cristal
- apasionado
- Contraseña
- permisos
- industrial
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- plugin
- Publicación
- industria
- alimentado
- anterior
- Director de la escuela
- Anterior
- procesadores
- Producto
- gerente de producto
- Producción
- Progreso
- propiedades
- proporcionar
- proporciona un
- proporcionando
- propósito
- consultas
- Crudo
- datos en bruto
- recomiendan
- remitir
- sanaciones
- la eliminación de
- reemplazar
- Requisitos
- Recursos
- respuesta
- RESTO
- Resultados
- el comercio minorista
- retenido
- volvemos
- Función
- rutas
- Ejecutar
- sabio
- capturas de pantalla
- Buscar
- motor de búsqueda
- Los motores de búsqueda
- EN LINEA
- ver
- selecciona
- ayudar
- Sin servidor
- de coches
- Servicios
- set
- ajustes
- ella
- mostrado
- Shows
- señales
- sencillos
- simplifica
- simplificar
- desde
- Soluciones
- Fuente
- especialista
- específicamente
- montón
- Comience a
- Estado
- paso
- pasos
- STORAGE
- Con éxito
- tal
- Soportado
- seguro
- plantilla
- texto
- esa
- El proyecto
- su
- Les
- luego
- de este modo
- Estas
- terceros.
- así
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a
- juntos
- Formación
- Traducción
- verdadero
- tipo
- ui
- único
- únicamente
- utilizan el
- caso de uso
- usado
- Usuario
- experiencia como usuario
- usando
- VALIDAR
- verificar
- versión
- vía
- Video
- Ver
- camina
- fue
- we
- web
- servicios web
- cuando
- que
- seguirá
- dentro de
- trabajado
- flujo de trabajo
- automatización del flujo de trabajo
- Usted
- tú
- zephyrnet