Como prácticamente todos los clientes, desea gastar lo menos posible y obtener el mejor rendimiento posible. Esto significa que hay que prestar atención a la relación calidad-precio. Con Desplazamiento al rojo de Amazon, ¡puedes quedarte con tu pastel y comértelo también! Amazon Redshift ofrece un costo por usuario hasta 4.9 veces menor y una relación precio-rendimiento hasta 7.9 veces mejor que otros almacenes de datos en la nube en cargas de trabajo del mundo real utilizando técnicas avanzadas como el escalado de concurrencia para admitir cientos de usuarios simultáneos y codificación de cadenas mejorada para un rendimiento de consultas más rápido. , y Amazon Redshift sin servidor mejoras de rendimiento. Siga leyendo para comprender por qué la relación precio-rendimiento es importante y cómo la relación precio-rendimiento de Amazon Redshift es una medida de cuánto cuesta obtener un nivel particular de rendimiento de la carga de trabajo, es decir, el rendimiento de la inversión (ROI) del rendimiento.
Debido a que tanto el precio como el desempeño entran en el cálculo del precio-rendimiento, hay dos maneras de pensar en el precio-rendimiento. La primera forma es mantener el precio constante: si tiene 1 dólar para gastar, ¿cuánto rendimiento obtiene de su almacén de datos? Una base de datos con una mejor relación precio-rendimiento ofrecerá un mejor rendimiento por cada dólar gastado. Por lo tanto, al mantener el precio constante al comparar dos almacenes de datos que cuestan lo mismo, la base de datos con mejor relación precio-rendimiento ejecutará sus consultas más rápido.. La segunda forma de analizar la relación precio-rendimiento es mantener el rendimiento constante: si necesita que su carga de trabajo termine en 10 minutos, ¿cuánto le costará? Una base de datos con mejor relación calidad-precio ejecutará su carga de trabajo en 10 minutos a un costo menor. Por lo tanto, si se mantiene el rendimiento constante al comparar dos almacenes de datos de tamaño adecuado para ofrecer el mismo rendimiento, la base de datos con mejor relación precio-rendimiento costará menos y le permitirá ahorrar dinero.
Finalmente, otro aspecto importante de la relación precio-rendimiento es la previsibilidad. Saber cuánto costará su almacén de datos a medida que crezca el número de usuarios del mismo es crucial para la planificación. No solo debería ofrecer la mejor relación precio-rendimiento hoy en día, sino también escalar de manera predecible y ofrecer la mejor relación precio-rendimiento a medida que se agregan más usuarios y cargas de trabajo. Un almacén de datos ideal debería tener escala lineal—Lo ideal sería ampliar su almacén de datos para ofrecer el doble de rendimiento de consultas y costar el doble (o menos).
En esta publicación, compartimos resultados de rendimiento para ilustrar cómo Amazon Redshift ofrece una relación precio-rendimiento significativamente mejor en comparación con los principales almacenes de datos en la nube alternativos. Esto significa que si gasta la misma cantidad en Amazon Redshift que en uno de estos otros almacenes de datos, obtendrá un mejor rendimiento con Amazon Redshift. Alternativamente, si dimensiona su clúster Redshift para ofrecer el mismo rendimiento, verá costos más bajos en comparación con estas alternativas.
Precio-rendimiento para cargas de trabajo del mundo real
Puede utilizar Amazon Redshift para impulsar una amplia diversidad de cargas de trabajo, desde el procesamiento por lotes de informes complejos basados en extracción, transformación y carga (ETL) y análisis de transmisión en tiempo real hasta paneles de inteligencia empresarial (BI) de baja latencia que Necesita atender a cientos o incluso miles de usuarios al mismo tiempo con tiempos de respuesta inferiores a un segundo y todo lo demás. Una de las formas en que mejoramos continuamente la relación precio-rendimiento para nuestros clientes es revisar constantemente la telemetría de rendimiento de software y hardware de la flota de Redshift, buscando oportunidades y casos de uso de clientes en los que podamos mejorar aún más el rendimiento de Amazon Redshift.
Algunos ejemplos recientes de optimizaciones de rendimiento impulsadas por la telemetría de flotas incluyen:
- Optimizaciones de consultas de cadenas – Al analizar cómo Amazon Redshift procesó diferentes tipos de datos en la flota de Redshift, descubrimos que la optimización de consultas con muchas cadenas aportaría un beneficio significativo a las cargas de trabajo de nuestros clientes. (Discutimos esto con más detalle más adelante en esta publicación).
- Vistas materializadas automatizadas – Descubrimos que los clientes de Amazon Redshift suelen ejecutar muchas consultas que tienen patrones de subconsultas comunes. Por ejemplo, varias consultas diferentes pueden unir las mismas tres tablas utilizando la misma condición de unión. Amazon Redshift ahora puede crear y mantener automáticamente vistas materializadas y luego reescribir consultas de forma transparente para utilizar las vistas materializadas mediante el aprendizaje automático. vista materializada automatizada Función autónoma en Amazon Redshift. Cuando están habilitadas, las vistas materializadas automatizadas pueden aumentar de forma transparente el rendimiento de las consultas repetitivas sin la intervención del usuario. (Tenga en cuenta que las vistas materializadas automatizadas no se utilizaron en ninguno de los resultados de referencia analizados en esta publicación).
- Cargas de trabajo de alta concurrencia – Un caso de uso cada vez mayor que vemos es el uso de Amazon Redshift para atender cargas de trabajo similares a paneles. Estas cargas de trabajo se caracterizan por tiempos de respuesta de consultas deseados de segundos de un solo dígito o menos, con decenas o cientos de usuarios simultáneos ejecutando consultas simultáneamente con un patrón de uso puntiagudo y a menudo impredecible. El ejemplo prototípico de esto es un panel de BI respaldado por Amazon Redshift que tiene un pico de tráfico los lunes por la mañana, cuando una gran cantidad de usuarios comienzan su semana.
Las cargas de trabajo de alta concurrencia en particular tienen una aplicabilidad muy amplia: la mayoría de las cargas de trabajo de almacenamiento de datos funcionan de forma simultánea y no es raro que cientos o incluso miles de usuarios ejecuten consultas en Amazon Redshift al mismo tiempo. Amazon Redshift fue diseñado para mantener los tiempos de respuesta a las consultas predecibles y rápidos. Redshift Serverless hace esto automáticamente agregando y eliminando computación según sea necesario para mantener los tiempos de respuesta a las consultas rápidos y predecibles. Esto significa que un panel respaldado por Redshift Serverless que se carga rápidamente cuando uno o dos usuarios acceden a él continuará cargándose rápidamente incluso cuando muchos usuarios lo estén cargando al mismo tiempo.
Para simular este tipo de carga de trabajo, utilizamos un punto de referencia derivado de TPC-DS con un conjunto de datos de 100 GB. TPC-DS es un punto de referencia estándar de la industria que incluye una variedad de consultas típicas de almacenamiento de datos. En esta escala relativamente pequeña de 100 GB, las consultas en este punto de referencia se ejecutan en Redshift Serverless en un promedio de unos pocos segundos, lo que es representativo de lo que esperarían los usuarios que cargan un panel de BI interactivo. Realizamos entre 1 y 200 pruebas simultáneas de este punto de referencia, simulando entre 1 y 200 usuarios que intentaban cargar un panel al mismo tiempo. También repetimos la prueba con varios almacenes de datos en la nube alternativos populares que también admiten el escalamiento horizontal automático (si está familiarizado con la publicación Amazon Redshift continúa con su liderazgo en relación precio-rendimiento, no incluimos al competidor A porque no admite la ampliación automática). Medimos el tiempo promedio de respuesta a las consultas, es decir, cuánto tiempo esperaría un usuario hasta que finalizaran sus consultas (o se cargara su panel). Los resultados se muestran en el siguiente cuadro.
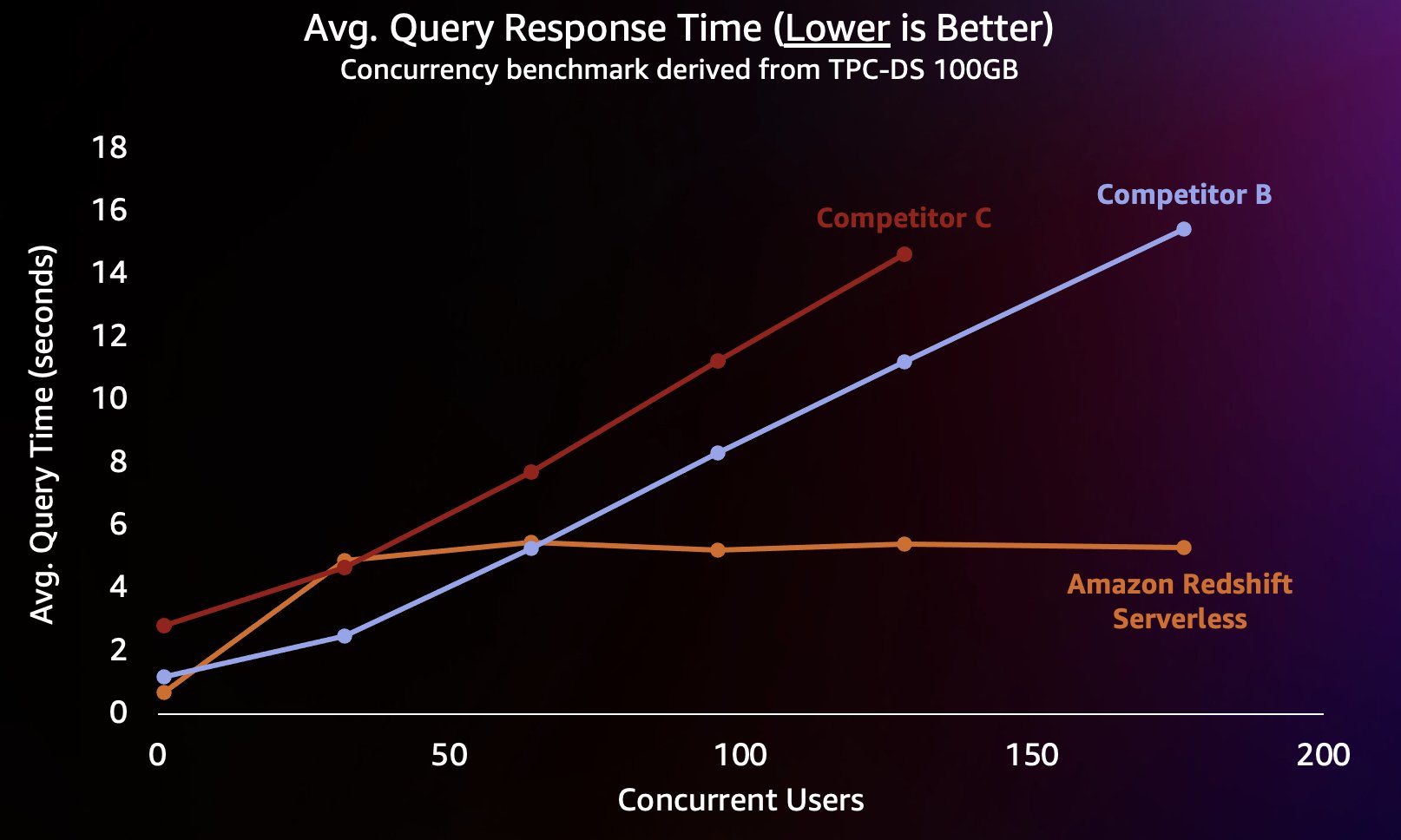
El competidor B escala bien hasta alrededor de 64 consultas simultáneas, momento en el que no puede proporcionar computación adicional y las consultas comienzan a ponerse en cola, lo que genera mayores tiempos de respuesta. Aunque el competidor C puede escalar automáticamente, lo hace a un menor rendimiento de consultas que Amazon Redshift y el competidor B y no puede mantener bajos los tiempos de ejecución de las consultas. Además, no admite consultas en cola cuando se queda sin cómputo, lo que le impide escalar más allá de aproximadamente 128 usuarios simultáneos. El sistema rechaza el envío de consultas adicionales más allá de esto.
Aquí, Redshift Serverless puede mantener el tiempo de respuesta de la consulta relativamente constante en alrededor de 5 segundos, incluso cuando cientos de usuarios ejecutan consultas al mismo tiempo. Los tiempos promedio de respuesta a las consultas de los competidores B y C aumentan constantemente a medida que aumenta la carga en los almacenes, lo que hace que los usuarios tengan que esperar más (hasta 16 segundos) para que regresen sus consultas cuando el almacén de datos está ocupado. Esto significa que si un usuario intenta actualizar un panel (que incluso puede enviar varias consultas simultáneas cuando se recarga), Amazon Redshift podría mantener los tiempos de carga del panel mucho más consistentes incluso si el panel lo cargan decenas o cientos de otras personas. usuarios al mismo tiempo.
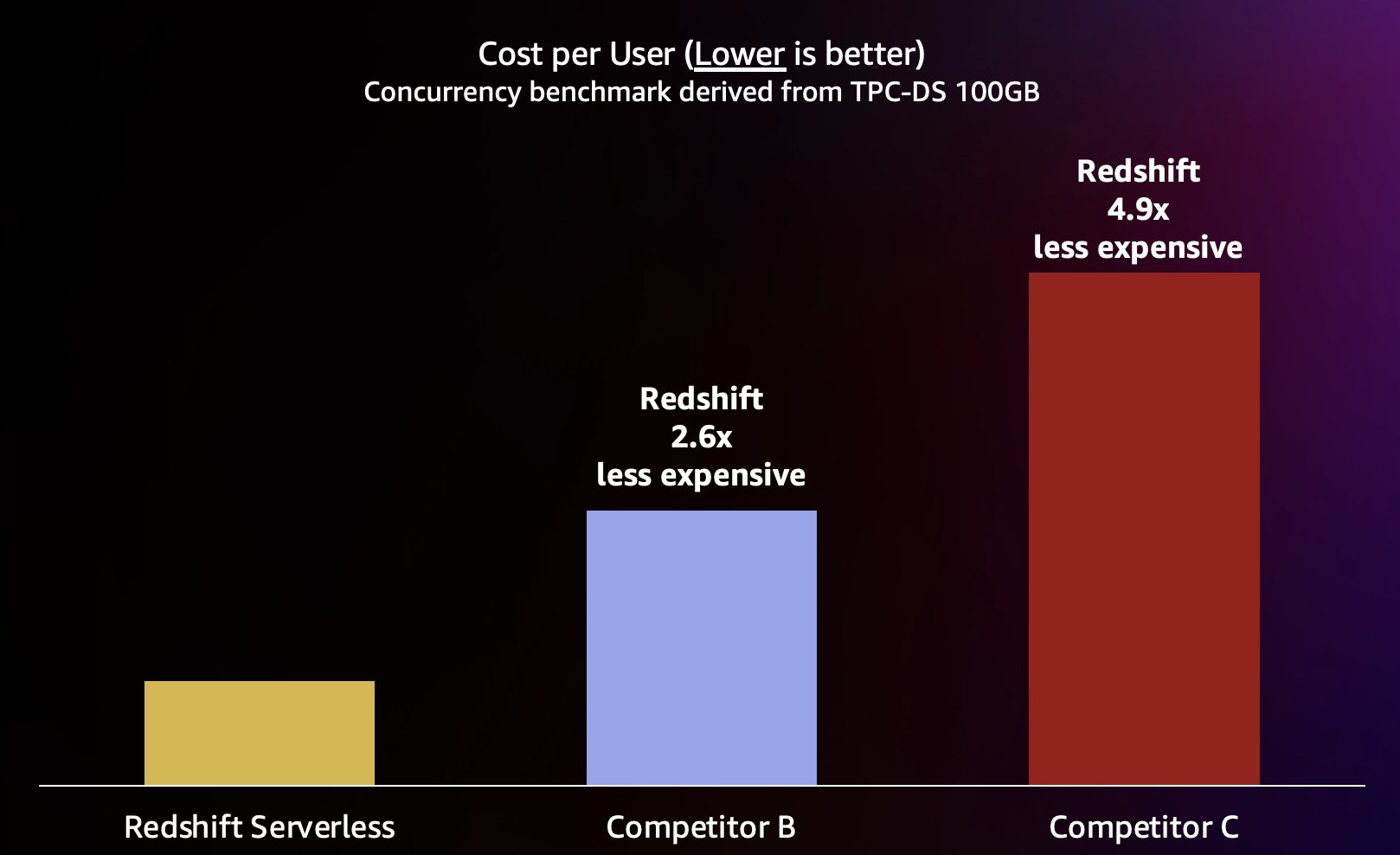
Debido a que Amazon Redshift puede ofrecer un rendimiento de consultas muy alto para consultas cortas (como escribimos en Amazon Redshift continúa con su liderazgo en relación precio-rendimiento), también es capaz de manejar estas concurrencias más altas cuando se escala de manera más eficiente y, por lo tanto, a un costo significativamente menor. Para cuantificar esto, analizamos la relación precio-rendimiento utilizando datos publicados. precios bajo demanda para cada uno de los almacenes de la prueba anterior, como se muestra en el siguiente cuadro. Vale la pena señalar que el uso Instancias reservadas (RI), especialmente las instancias reservadas de 3 años compradas con la opción de pago por adelantado, tienen el costo más bajo para ejecutar Amazon Redshift en clústeres aprovisionados, lo que resulta en la mejor relación precio-rendimiento en comparación con las opciones de instancias reservadas bajo demanda u otras.

Por lo tanto, Amazon Redshift no solo puede ofrecer un mejor rendimiento con mayor concurrencia, sino que también puede hacerlo a un costo significativamente menor. Cada punto de datos en el gráfico precio-rendimiento es equivalente al costo de ejecutar el punto de referencia en la simultaneidad especificada. Debido a que la relación precio-rendimiento es lineal, podemos dividir el costo de ejecutar el punto de referencia en cualquier concurrencia por la concurrencia (número de usuarios simultáneos en este gráfico) para saber cuánto cuesta agregar cada nuevo usuario para este punto de referencia en particular.
Los resultados anteriores son fáciles de replicar. Todas las consultas utilizadas en el punto de referencia están disponibles en nuestro Repositorio GitHub y el rendimiento se mide iniciando un almacén de datos, habilitando el escalado de simultaneidad en Amazon Redshift (o la función de escalado automático correspondiente en otros almacenes), cargando los datos listos para usar (sin ajuste manual ni configuración específica de la base de datos) y luego ejecutando un flujo simultáneo de consultas con simultaneidades de 1 a 200 en pasos de 32 en cada almacén de datos. El mismo repositorio de GitHub hace referencia a datos TPC-DS pregenerados (y no modificados) en Servicio de almacenamiento simple de Amazon (Amazon S3) a varias escalas utilizando el kit oficial de generación de datos TPC-DS.
Optimización de cargas de trabajo con muchas cadenas
Como se mencionó anteriormente, el equipo de Amazon Redshift busca continuamente nuevas oportunidades para ofrecer una relación precio-rendimiento aún mejor para nuestros clientes. Una mejora que lanzamos recientemente y que mejora significativamente el rendimiento es una optimización que acelera el rendimiento de las consultas sobre datos de cadenas. Por ejemplo, es posible que desee encontrar los ingresos totales generados por las tiendas minoristas ubicadas en la ciudad de Nueva York con una consulta como SELECT sum(price) FROM sales WHERE city = ‘New York’. Esta consulta aplica un predicado sobre datos de cadena (city = ‘New York’). Como puede imaginar, el procesamiento de datos de cadenas es omnipresente en las aplicaciones de almacenamiento de datos.
Para cuantificar la frecuencia con la que las cargas de trabajo de los clientes acceden a las cadenas, realizamos un análisis detallado del uso del tipo de datos de cadenas utilizando telemetría de flota de decenas de miles de clústeres de clientes administrados por Amazon Redshift. Nuestro análisis indica que en el 90% de los grupos, las columnas de cadenas constituyen al menos el 30% de todas las columnas, y en el 50% de los grupos, las columnas de cadenas constituyen al menos el 50% de todas las columnas. Además, la mayoría de todas las consultas ejecutadas en la plataforma de almacenamiento de datos en la nube de Amazon Redshift acceden a al menos una columna de cadena. Otro factor importante es que los datos de cadena suelen tener una cardinalidad baja, lo que significa que las columnas contienen un conjunto relativamente pequeño de valores únicos. Por ejemplo, aunque un orders La tabla que representa datos de ventas puede contener miles de millones de filas, una order_status La columna dentro de esa tabla puede contener solo unos pocos valores únicos en esos miles de millones de filas, como pending, in processy completed.
Al momento de escribir este artículo, la mayoría de las columnas de cadenas en Amazon Redshift están comprimidas con LZO or ZSTD algoritmos. Estos son buenos algoritmos de compresión de propósito general, pero no están diseñados para aprovechar datos de cadenas de baja cardinalidad. En particular, requieren que los datos se descompriman antes de ser operados y son menos eficientes en el uso del ancho de banda de la memoria del hardware. Para datos de baja cardinalidad, existe otro tipo de codificación que puede ser más óptima: BYTEDICTO. Esta codificación utiliza un esquema de codificación de diccionario que permite que el motor de la base de datos opere directamente sobre datos comprimidos sin necesidad de descomprimirlos primero.
Para mejorar aún más la relación precio-rendimiento para cargas de trabajo con muchas cadenas, Amazon Redshift ahora presenta mejoras de rendimiento adicionales que aceleran los escaneos y las evaluaciones de predicados, en comparación con columnas de cadenas de baja cardinalidad codificadas como BYTEDICT, entre 5 y 63 veces más rápido (consulte los resultados en la siguiente sección) en comparación con codificaciones de compresión alternativas como LZO o ZSTD. Amazon Redshift logra esta mejora de rendimiento vectorizando escaneos en columnas de cadena de baja cardinalidad, livianas, eficientes en CPU y codificadas con BYTEDICT. Estas optimizaciones del procesamiento de cadenas hacen un uso eficaz del ancho de banda de la memoria que ofrece el hardware moderno, lo que permite realizar análisis en tiempo real de los datos de las cadenas. Estas capacidades de rendimiento recientemente introducidas son óptimas para columnas de cadenas de baja cardinalidad (hasta unos pocos cientos de valores de cadena únicos).
Puede beneficiarse automáticamente de esta nueva mejora de cadena de alto rendimiento habilitando optimización automática de la mesa en su almacén de datos de Amazon Redshift. Si no tiene habilitada la optimización automática de tablas en sus tablas, puede recibir recomendaciones del Asesor de Amazon Redshift en la consola de Amazon Redshift sobre la idoneidad de una columna de cadena para la codificación BYTEDICT. También puede definir nuevas tablas que tengan columnas de cadena de baja cardinalidad con codificación BYTEDICT. Las mejoras de cadenas en Amazon Redshift ahora están disponibles en todas las regiones de AWS donde Amazon Redshift está disponible.
Resultados del rendimiento
Para medir el impacto en el rendimiento de nuestras mejoras de cadenas, generamos un conjunto de datos de 10 TB (Tera Byte) que constaba de datos de cadenas de baja cardinalidad. Generamos tres versiones de los datos utilizando cadenas cortas, medianas y largas, correspondientes a los percentiles 25, 50 y 75 de longitudes de cadenas de la telemetría de flotas de Amazon Redshift. Cargamos estos datos en Amazon Redshift dos veces, codificándolos en un caso usando compresión LZO y en otro usando compresión BYTEDICT. Finalmente, medimos el rendimiento de consultas que requieren un gran análisis y que devuelven muchas filas (90 % de la tabla), una cantidad media de filas (50 % de la tabla) y unas pocas filas (1 % de la tabla) por encima de estos niveles bajos. -conjuntos de datos de cadenas de cardinalidad. Los resultados de rendimiento se resumen en el siguiente cuadro.

Las consultas con predicados que coinciden con un alto porcentaje de filas experimentaron mejoras de 5 a 30 veces con la nueva codificación BYTEDICT vectorizada en comparación con LZO, mientras que las consultas con predicados que coinciden con un bajo porcentaje de filas experimentaron mejoras de 10 a 63 veces en este punto de referencia interno.
Redshift Serverless precio-rendimiento
Además de los resultados de rendimiento de alta concurrencia presentados en esta publicación, también utilizamos el punto de referencia Cloud Data Warehouse derivado de TPC-DS para comparar el precio-rendimiento de Redshift Serverless con otros almacenes de datos que utilizan un conjunto de datos más grande de 3 TB. Elegimos almacenes de datos que tenían precios similares, en este caso dentro del 10% de $32 por hora utilizando precios bajo demanda disponibles públicamente. Estos resultados muestran que, al igual que las instancias Amazon Redshift RA3, Redshift Serverless ofrece una mejor relación precio-rendimiento en comparación con otros almacenes de datos en la nube líderes. Como siempre, estos resultados se pueden replicar utilizando nuestros scripts SQL en nuestro Repositorio GitHub.

Le recomendamos que pruebe Amazon Redshift utilizando el suyo propio. prueba de concepto cargas de trabajo como la mejor manera de ver cómo Amazon Redshift puede satisfacer sus necesidades de análisis de datos.
Encuentre la mejor relación precio-rendimiento para sus cargas de trabajo
Los puntos de referencia utilizados en esta publicación se derivan del punto de referencia TPC-DS estándar de la industria y tienen las siguientes características:
- El esquema y los datos se utilizan sin modificaciones desde TPC-DS.
- Las consultas se generan utilizando el kit TPC-DS oficial con parámetros de consulta generados utilizando la semilla aleatoria predeterminada del kit TPC-DS. Las variantes de consulta aprobadas por TPC se utilizan para un almacén si el almacén no admite el dialecto SQL de la consulta TPC-DS predeterminada.
- La prueba incluye las 99 consultas TPC-DS SELECT. No incluye pasos de mantenimiento y rendimiento.
- Para la prueba de simultaneidad única de 3 TB, se ejecutaron tres ejecuciones de energía y se toma la mejor ejecución para cada almacén de datos.
- El precio-rendimiento para las consultas TPC-DS se calcula como el costo por hora (USD) multiplicado por el tiempo de ejecución del punto de referencia en horas, lo que equivale al costo de ejecutar el punto de referencia. Los precios bajo demanda publicados más recientes se utilizan para todos los almacenes de datos y no para los precios de instancias reservadas como se indicó anteriormente.
A esto lo llamamos el punto de referencia de Cloud Data Warehouse y usted puede reproducir fácilmente los resultados del punto de referencia anterior utilizando los scripts, consultas y datos disponibles en nuestro Repositorio GitHub. Se deriva de los puntos de referencia de TPC-DS como se describen en esta publicación y, como tal, no es comparable con los resultados de TPC-DS publicados, porque los resultados de nuestras pruebas no cumplen con la especificación oficial.
Conclusión
Amazon Redshift se compromete a ofrecer la mejor relación precio-rendimiento de la industria para la más amplia variedad de cargas de trabajo. Redshift Serverless escala linealmente con el mejor (más bajo) precio-rendimiento, admite cientos de usuarios simultáneos y mantiene tiempos de respuesta de consultas constantes. Según los resultados de las pruebas analizadas en esta publicación, Amazon Redshift tiene una relación precio-rendimiento hasta 2.6 veces mejor con el mismo nivel de simultaneidad en comparación con el competidor más cercano (competidor B). Como se mencionó anteriormente, el uso de Instancias reservadas con la opción de 3 años por adelantado le brinda el costo más bajo para ejecutar Amazon Redshift, lo que resulta en una relación precio-rendimiento aún mejor en comparación con el precio de las instancias bajo demanda que utilizamos en esta publicación. Nuestro enfoque para la mejora continua del rendimiento implica una combinación única de la obsesión del cliente por comprender los casos de uso de los clientes y sus cuellos de botella de escalabilidad asociados, junto con un análisis continuo de datos de la flota para identificar oportunidades para realizar optimizaciones significativas del rendimiento.
Cada carga de trabajo tiene características únicas, por lo que si recién estás comenzando, una prueba de concepto es la mejor manera de comprender cómo Amazon Redshift puede reducir sus costos y al mismo tiempo ofrecer un mejor rendimiento. Al ejecutar su propia prueba de concepto, es importante centrarse en las métricas correctas: rendimiento de consultas (cantidad de consultas por hora), tiempo de respuesta y relación precio-rendimiento. Puede tomar una decisión basada en datos ejecutando una prueba de concepto por su cuenta o con asistencia de AWS o un socio de consultoría e integración de sistemas.
Para mantenerse actualizado con los últimos desarrollos en Amazon Redshift, siga el Novedades de Amazon Redshift alimentarse.
Sobre los autores
 Stefan Gromoll es ingeniero de rendimiento sénior en el equipo de Amazon Redshift, donde es responsable de medir y mejorar el rendimiento de Redshift. En su tiempo libre le gusta cocinar, jugar con sus tres hijos y cortar leña.
Stefan Gromoll es ingeniero de rendimiento sénior en el equipo de Amazon Redshift, donde es responsable de medir y mejorar el rendimiento de Redshift. En su tiempo libre le gusta cocinar, jugar con sus tres hijos y cortar leña.
 Ravi Animi es líder senior de gestión de productos en el equipo de Amazon Redshift y gestiona varias áreas funcionales del servicio de almacenamiento de datos en la nube de Amazon Redshift, incluido el rendimiento, el análisis espacial, la ingesta de streaming y las estrategias de migración. Tiene experiencia con bases de datos relacionales, bases de datos multidimensionales, tecnologías de IoT, servicios de infraestructura informática y de almacenamiento y, más recientemente, como fundador de una startup que utiliza IA/aprendizaje profundo, visión por computadora y robótica.
Ravi Animi es líder senior de gestión de productos en el equipo de Amazon Redshift y gestiona varias áreas funcionales del servicio de almacenamiento de datos en la nube de Amazon Redshift, incluido el rendimiento, el análisis espacial, la ingesta de streaming y las estrategias de migración. Tiene experiencia con bases de datos relacionales, bases de datos multidimensionales, tecnologías de IoT, servicios de infraestructura informática y de almacenamiento y, más recientemente, como fundador de una startup que utiliza IA/aprendizaje profundo, visión por computadora y robótica.
 Amer Shah es ingeniero sénior en el equipo de servicio de Amazon Redshift.
Amer Shah es ingeniero sénior en el equipo de servicio de Amazon Redshift.
 Sanket Hase es gerente de desarrollo de software en el equipo de servicio de Amazon Redshift.
Sanket Hase es gerente de desarrollo de software en el equipo de servicio de Amazon Redshift.
 Orestis Polychroniou es ingeniero principal en el equipo de servicio de Amazon Redshift.
Orestis Polychroniou es ingeniero principal en el equipo de servicio de Amazon Redshift.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :posee
- :es
- :no
- :dónde
- $ UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Poder
- Nuestra Empresa
- acelera
- de la máquina
- visitada
- Logra
- a través de
- adicional
- la adición de
- adición
- Adicionales
- avanzado
- Ventaja
- proporcionado
- en contra
- algoritmos
- Todos
- permite
- también
- alternativa
- alternativas
- Aunque
- hacerlo
- Amazon
- Amazon Web Services
- cantidad
- an
- análisis
- Analytics
- el análisis de
- y
- Otra
- cualquier
- aplicaciones
- La aplicación de
- enfoque
- somos
- áreas
- en torno a
- AS
- aspecto
- asociado
- At
- auto
- Confirmación de Viaje
- Automático
- automáticamente
- Hoy Disponibles
- promedio
- AWS
- b
- Ancho de banda
- basado
- BE
- porque
- antes
- comenzar
- "Ser"
- los puntos de referencia
- es el beneficio
- MEJOR
- mejores
- entre
- Más allá de
- miles de millones
- ambas
- cuellos de botella
- Box
- llevar
- general
- inteligencia empresarial
- ocupado
- pero
- by
- TARTA
- calculado
- cálculo
- llamar al
- PUEDEN
- capacidades
- case
- cases
- características
- caracterizada
- Tabla
- el cortar
- eligió
- Ciudad
- Soluciones
- Médico
- Columna
- Columnas
- combinación
- comprometido
- Algunos
- comparable
- comparar
- en comparación con
- comparar
- competidor
- competidores
- integraciones
- cumplir
- Calcular
- computadora
- Visión por computador
- concepto
- competidor
- condición
- llevado a cabo
- consistente
- Consola
- constante
- constantemente
- constituir
- consultoría
- que no contengo
- continuamente
- continue
- continúa
- continuo
- continuamente
- cocinar
- Correspondiente
- Cost
- Precio
- acoplado
- Para crear
- crucial
- cliente
- Clientes
- página de información de sus operaciones
- de los tableros
- datos
- análisis de los datos
- Data Analytics
- proceso de datos
- conjunto de datos
- almacenamiento de datos
- almacenes de datos
- basada en datos
- Base de datos
- bases de datos
- conjuntos de datos
- Fecha
- Koops
- Predeterminado
- definir
- entregamos
- entregar
- entrega
- Derivado
- descrito
- diseñado
- deseado
- detalle
- detallado
- Desarrollo
- desarrollos
- una experiencia diferente
- directamente
- discutir
- discutido
- Diversidad
- dividir
- do
- sí
- No
- No
- impulsados
- cada una
- Más temprano
- pasan fácilmente
- comer
- Eficaz
- eficiente
- eficiente.
- facilita
- permitiendo
- fomentar
- Motor
- ingeniero
- mejorado
- Estrategias orientadas
- mejoras
- Participar
- Equivalente a
- especialmente
- Éter (ETH)
- evaluaciones
- Incluso
- todo
- ejemplo
- ejemplos
- esperar
- experience
- extraerlos
- factor
- familiar
- muchos
- RÁPIDO
- más rápida
- Feature
- pocos
- Finalmente
- Encuentre
- acabado
- Nombre
- FLOTA
- Focus
- seguir
- siguiendo
- encontrado
- fundador
- Desde
- funcional
- promover
- propósito general
- generado
- generación de AHSS
- obtener
- conseguir
- GitHub
- da
- va
- candidato
- Creciendo
- crece
- encargarse de
- Materiales
- Tienen
- es
- he
- Alta
- más alto
- su
- mantener
- tenencia
- horas.
- HORAS
- Cómo
- HTML
- http
- HTTPS
- cien
- Cientos
- ideal
- idealmente
- Identifique
- if
- ilustrar
- imagen
- Impacto
- importante
- aspecto importante
- mejorar
- mejorado
- es la mejora continua
- mejoras
- la mejora de
- in
- incluir
- incluye
- Incluye
- aumente
- aumentado
- Los aumentos
- Indica
- de la industria
- EN LA MINA
- ejemplo
- instancias
- integración
- Intelligence
- interactivo
- interno
- intervención
- dentro
- Introducido
- Presentamos
- inversión extranjera
- implica
- IOT
- IT
- SUS
- únete
- jpg
- solo
- Guardar
- kit
- Conocer
- large
- mayores
- luego
- más reciente
- últimos desarrollos
- lanzado
- lanzamiento
- líder
- líder
- aprendizaje
- menos
- menos
- Nivel
- ligero
- como
- pequeño
- carga
- carga
- cargas
- situados
- Largo
- por más tiempo
- Mira
- mirando
- Baja
- inferior
- más bajo
- mantener
- el mantenimiento de
- un mejor mantenimiento.
- Mayoría
- para lograr
- gestionado
- Management
- gerente
- gestiona
- manual
- muchos
- Match
- Cuestiones
- Puede..
- sentido
- significa
- medir
- mesurado
- medición
- mediano
- Conoce a
- Salud Cerebral
- mencionado
- podría
- migración
- minutos
- Moderno
- Lunes
- dinero
- más,
- Por otra parte
- MEJOR DE TU
- mucho más
- a saber
- ¿ Necesita ayuda
- Nuevo
- New York
- Ciudad de Nueva York
- recién
- Next
- no
- nota
- señaló
- señalando
- ahora
- número
- of
- oficial
- a menudo
- on
- On-Demand
- ONE
- , solamente
- funcionar
- operado
- Del Mañana
- óptimo
- optimización
- optimizando
- Optión
- Opciones
- or
- Otro
- nuestros
- salir
- Más de
- EL DESARROLLADOR
- parámetros
- particular
- Patrón de Costura
- .
- Pagar
- pago
- para
- porcentaje
- actuación
- planificar
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- punto
- Popular
- posible
- Publicación
- industria
- Previsible
- presentó
- evita
- precio
- cotización
- Director de la escuela
- procesado
- tratamiento
- Producto
- gestión de producto
- prueba
- prueba de concepto
- proporcionar
- en público
- publicado
- comprado
- consultas
- con rapidez
- azar
- Leer
- mundo real
- en tiempo real
- recepción
- reciente
- recientemente
- recomendaciones
- referencias
- regiones
- Rechazado..
- relativo
- relativamente
- la eliminación de
- repetido
- repetitivo
- replicado
- Informes
- representante
- que representa
- exigir
- reservados
- respuesta
- responsable
- resultante
- Resultados
- el comercio minorista
- volvemos
- ingresos
- una estrategia SEO para aparecer en las búsquedas de Google.
- Derecho
- robótica
- ROI
- Ejecutar
- correr
- corre
- ventas
- mismo
- Guardar
- Sierra
- Escalabilidad
- Escala
- escamas
- la ampliación
- escanea
- esquema
- guiones
- Segundo
- segundos
- Sección
- ver
- dispersores
- mayor
- ayudar
- Sin servidor
- de coches
- Servicios
- set
- Configure
- Varios
- Compartir
- En Corto
- tienes
- Mostrar
- mostrado
- importante
- significativamente
- Del mismo modo
- sencillos
- simultáneamente
- soltero
- Tamaño
- tamaño
- chica
- So
- Software
- Desarrollo de software ad-hoc
- Espacial
- especificación
- especificado
- velocidad
- pasar
- gastado
- espiga
- SQL
- comienzo
- fundó
- inicio
- quedarse
- continuamente
- pasos
- STORAGE
- tiendas
- sencillo
- estrategias
- stream
- en streaming
- Cordón
- enviar
- tal
- idoneidad
- SOPORTE
- Apoyar
- te
- mesa
- ¡Prepárate!
- toma
- equipo
- técnicas
- Tecnologías
- les digas
- tener
- test
- pruebas
- que
- esa
- La
- su
- luego
- Ahí.
- por lo tanto
- Estas
- ellos
- pensar
- así
- aquellos
- miles
- Tres
- rendimiento
- equipo
- veces
- a
- hoy
- Total
- tráfico
- Transformar
- transparentemente
- try
- tratando de
- Twice
- dos
- tipo
- tipos
- principiante
- ubicuo
- incapaz
- Poco común
- entender
- único
- imprevisible
- hasta
- us
- Uso
- USD
- utilizan el
- caso de uso
- usado
- Usuario
- usuarios
- usos
- usando
- Valores
- variedad
- diversos
- muy
- vistas
- virtualmente
- visión
- esperar
- quieres
- Manejo de
- fue
- Camino..
- formas
- we
- web
- servicios web
- semana
- WELL
- tuvieron
- ¿
- cuando
- mientras
- que
- mientras
- porque
- amplio
- seguirá
- dentro de
- sin
- valor
- se
- la escritura
- escribí
- york
- Usted
- tú
- zephyrnet