En la marcha hacia sistemas más capaces, más rápidos, más pequeños y de menor potencia, la Ley de Moore dio vía libre al software durante más de 30 años aproximadamente exclusivamente en la evolución de los procesos de semiconductores. El hardware informático proporcionó métricas de rendimiento/área/potencia mejoradas cada año, lo que permitió que el software ampliara su complejidad y ofreciera más capacidad sin inconvenientes. Luego, las victorias fáciles se volvieron menos fáciles. Los procesos más avanzados continuaron generando un mayor número de puertas por unidad de área, pero las ganancias en rendimiento y potencia comenzaron a estabilizarse. Dado que nuestras expectativas de innovación no se detuvieron, los avances en la arquitectura de hardware se han vuelto más importantes para tomar el relevo.

Impulsores para aumentar el número de núcleos
Un primer paso en esta dirección utilizó CPU multinúcleo para acelerar el rendimiento total mediante subprocesamiento o virtualización de una combinación de tareas simultáneas entre núcleos, reduciendo la energía según fuera necesario al dejar inactivos o apagar los núcleos inactivos. El multinúcleo es estándar hoy en día y una tendencia hacia el uso de muchos núcleos (incluso más CPU en un chip) ya es evidente en las opciones de instancias de servidor disponibles en plataformas en la nube de AWS, Azure, Alibaba y otros.
Las arquitecturas de múltiples núcleos son un paso adelante, pero el paralelismo a través de los clústeres de CPU es de grano grueso y tiene sus propios límites de rendimiento y potencia, gracias a la ley de Amdahl. Las arquitecturas se volvieron más heterogéneas y se agregaron aceleradores para imágenes, audio y otras necesidades especializadas. Los aceleradores de IA también han impulsado el paralelismo detallado, pasando a matrices sistólicas y otras técnicas de dominio específico. Lo cual funcionó bastante bien hasta que apareció ChatGPT con 175 mil millones de parámetros y GPT-3 evolucionó a GPT-4 con 100 billones de parámetros (órdenes de magnitud más complejos que los sistemas de IA actuales), lo que obligó a funciones de aceleración aún más especializadas dentro de los aceleradores de IA.
En un frente diferente, los sistemas multisensor en aplicaciones automotrices ahora se están integrando en SoC únicos para mejorar la conciencia ambiental y el PPA. Aquí, los nuevos niveles de autonomía en la automoción dependen de fusionar entradas de múltiples tipos de sensores dentro de un solo dispositivo, en subsistemas que se replican 2X, 4X u 8X.
Según Michał Siwinski (CMO de Arteris), una muestra de más de un mes de discusiones con múltiples equipos de diseño en una amplia gama de aplicaciones sugiere que esos equipos están recurriendo activamente a mayores recuentos de núcleos para cumplir con los objetivos de capacidad, rendimiento y potencia. Me dice que también ven que esta tendencia se está acelerando. Los avances en los procesos todavía ayudan con el número de puertas de SoC, pero la responsabilidad de cumplir los objetivos de rendimiento y energía ahora está firmemente en manos de los arquitectos.
Más núcleos, más interconexión
Más núcleos en un chip implican más conexiones de datos entre esos núcleos. Dentro de un acelerador entre elementos de procesamiento vecinos, hasta caché local, aceleradores para matrices dispersas y otros manejos especializados. Agregue conectividad jerárquica entre los mosaicos del acelerador y los buses a nivel del sistema. Agregue conectividad para almacenamiento de peso, descompresión, transmisión, recopilación y recompresión de peso en el chip. Agregue conectividad HBM para caché de trabajo. Agregue un motor de fusión si es necesario.
El clúster de control basado en CPU debe conectarse a cada uno de esos subsistemas replicados y a todas las funciones habituales: códecs, administración de memoria, isla de seguridad y raíz de confianza si corresponde, UCIe si es una implementación de múltiples chips, PCIe para E/S de gran ancho de banda. y Ethernet o fibra para redes.
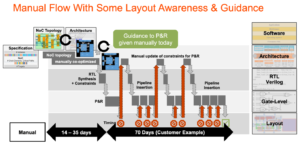
Hay mucha interconexión, con consecuencias directas para la comercialización del producto. En procesos por debajo de 16 nm, la infraestructura de NoC ahora contribuye entre un 10 y un 12 % del área. Aún más importante, como vía de comunicación entre núcleos, puede tener un impacto significativo en el rendimiento y la potencia. Existe un peligro real de que una implementación subóptima desperdicie el rendimiento de la arquitectura y las ganancias de energía esperadas, o peor aún, resulte en numerosos bucles de rediseño para converger. Sin embargo, encontrar una buena implementación en un plano de SoC complejo todavía depende de optimizaciones lentas de prueba y error en cronogramas de diseño ya ajustados. Necesitamos dar el salto al diseño de NoC con conciencia física, para garantizar el rendimiento total y el soporte de energía de jerarquías de NoC complejas, y debemos hacer estas optimizaciones más rápido.
Los diseños NoC físicamente conscientes mantienen la ley de Moore en marcha
Puede que la ley de Moore no esté muerta, pero los avances actuales en rendimiento y potencia provienen de la arquitectura y la interconexión de NoC más que del proceso. La arquitectura está impulsando más núcleos de aceleradores, más aceleradores dentro de aceleradores y más replicación de subsistemas en chips. Todo ello aumenta la complejidad de la interconexión en chip. A medida que los diseños aumentan el número de núcleos y pasan a procesar geometrías de 16 nm y menos, las numerosas interconexiones NoC que abarcan el SoC y sus subsistemas solo pueden soportar todo el potencial de estos diseños complejos si se implementan de manera óptima frente a limitaciones físicas y de tiempo, a través de una red físicamente consciente. en el diseño de chips.
Si también te preocupan estas tendencias, quizás quieras saber más sobre la tecnología IP Arteris FlexNoC 5 AQUÍ.
Comparte esta publicación a través de:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :es
- $ UP
- 100
- a
- Nuestra Empresa
- acelerar
- acelerador
- aceleración
- acelerador
- aceleradores
- a través de
- activamente
- avanzado
- avances
- en contra
- AI
- Sistemas de IA
- Alibaba
- Todos
- Permitir
- ya haya utilizado
- y
- Aparecido
- aplicaciones
- adecuado
- arquitectura
- somos
- Reservada
- AS
- At
- audio
- automotor
- Hoy Disponibles
- conciencia
- AWS
- Azure
- Ancho de banda
- BE
- a las que has recomendado
- a continuación
- entre
- mil millones
- transmisión
- Autobuses
- by
- cache
- PUEDEN
- capaz
- ChatGPT
- chip
- Soluciones
- Médico
- CMO
- cómo
- Comunicación
- integraciones
- complejidad
- Calcular
- competidor
- Contacto
- Conexiones
- Conectividad
- Consecuencias
- restricciones
- continuado
- control
- converger
- Core
- CPU
- PELIGRO
- datos
- muerto
- entregamos
- liberado
- depende
- Diseño
- diseños
- dispositivo
- una experiencia diferente
- de reservas
- dirección
- discusiones
- DE INSCRIPCIÓN
- desventajas
- cada una
- Temprano en la
- elementos
- Motor
- Entorno
- Incluso
- Cada
- evolución
- evolución
- Expandir
- las expectativas
- esperado
- más rápida
- Caracteristicas
- la búsqueda de
- firmemente
- adelante
- Gratuito
- Desde
- frontal o trasero
- ser completados
- funciones
- fusión
- Ganancias
- Goals
- candidato
- garantizamos
- Manejo
- Manos
- Materiales
- Tienen
- ayuda
- esta página
- Alta
- más alto
- Carretera
- HTTPS
- imagen
- Impacto
- implementación
- implementado
- importante
- mejorado
- in
- inactivo
- aumente
- creciente
- EN LA MINA
- Innovation
- ejemplo
- Integración
- IP
- isla
- IT
- SUS
- saltar
- de derecho criminal
- APRENDE:
- Nivel
- límites
- local
- Lote
- para lograr
- Management
- Marzo
- Matrix
- max-ancho
- Conoce a
- reunión
- Salud Cerebral
- Métrica
- podría
- Mes
- más,
- movimiento
- emocionante
- múltiples
- ¿ Necesita ayuda
- del sistema,
- red
- Nuevo
- numeroso
- of
- on
- Opciones
- en pedidos de venta.
- Otro
- Otros
- EL DESARROLLADOR
- parámetros
- actuación
- los libros físicos
- Físicamente
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Publicación
- posible
- industria
- Alimentación
- bastante
- en costes
- tratamiento
- Producto
- puramente
- empujó
- Emprendedor
- distancia
- más bien
- real
- la reducción de
- replicado
- replicación
- responsabilidad
- resultado
- VIAJE
- raíz
- Safety
- semiconductor
- importante
- desde
- soltero
- flojo
- lento
- menores
- So
- Software
- matriz dispersa
- especializado
- Spotlight
- estándar
- fundó
- paso
- Sin embargo
- Detener
- STORAGE
- Sugiere
- SOPORTE
- te
- Todas las funciones a su disposición
- tareas
- equipos
- técnicas
- Tecnología
- decirles
- esa
- La
- Estas
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- rendimiento
- sincronización
- a
- hoy
- de hoy
- Total
- Tendencia
- Tendencias
- Trillones
- Confía en
- Turning
- tipos
- bajo
- unidad
- vía
- peso
- WELL
- que
- amplio
- Amplia gama
- seguirá
- TRIUNFOS
- dentro de
- trabajando
- año
- años
- zephyrnet