Servicio Amazon OpenSearch es un servicio administrado que facilita la protección, la implementación y el funcionamiento de OpenSearch y los clústeres de Elasticsearch heredados a escala en la nube de AWS. Amazon OpenSearch Service aprovisiona todos los recursos para su clúster, lo lanza y detecta y reemplaza automáticamente los nodos fallidos, lo que reduce la sobrecarga de las infraestructuras autogestionadas. El servicio le facilita realizar análisis de registros interactivos, monitoreo de aplicaciones en tiempo real, búsquedas en sitios web y más al ofrecer las últimas versiones de OpenSearch, soporte para 19 versiones de Elasticsearch (versiones 1.5 a 7.10) y capacidades de visualización impulsadas por OpenSearch Dashboards y Kibana (versiones 1.5 a 7.10).
En la última versión del software de servicio, hemos actualizado la lógica de asignación de fragmentos para que tenga en cuenta la carga, de modo que cuando los fragmentos se redistribuyen en caso de fallas en los nodos, el servicio impide que los nodos sobrevivientes se sobrecarguen con fragmentos previamente alojados en el nodo fallido. Esto es especialmente importante para que los dominios Multi-AZ proporcionen un rendimiento de clúster consistente y predecible.
Si desea obtener más información sobre la lógica de asignación de fragmentos en general, consulte Desmitificando la asignación de fragmentos de Elasticsearch.
El desafío
Se dice que un dominio de Amazon OpenSearch Service está "equilibrado" cuando la cantidad de nodos se distribuye por igual entre las zonas de disponibilidad configuradas y la cantidad total de fragmentos se distribuye por igual entre todos los nodos disponibles sin concentración de fragmentos de ningún índice en ninguno. nodo. Además, OpenSearch tiene una propiedad llamada "Conocimiento de zona" que, cuando está habilitada, garantiza que el fragmento principal y su réplica correspondiente se asignen en diferentes zonas de disponibilidad. Si tiene más de una copia de datos, tener varias zonas de disponibilidad proporciona una mejor disponibilidad y tolerancia a fallas. En el caso de que el dominio se escale o se escale o durante la falla de los nodos, OpenSearch redistribuye automáticamente los fragmentos entre los nodos disponibles mientras obedece las reglas de asignación basadas en el conocimiento de la zona.
Si bien el proceso de equilibrio de fragmentos garantiza que los fragmentos se distribuyan uniformemente en las zonas de disponibilidad, en algunos casos, si se produce un error inesperado en una sola zona, los fragmentos se reasignarán a los nodos supervivientes. Esto podría resultar en que los nodos sobrevivientes se vean abrumados, lo que afectaría la estabilidad del clúster.
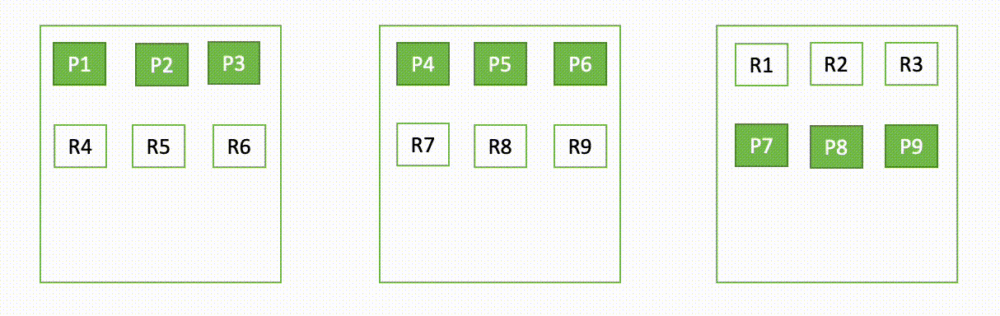
Por ejemplo, si un nodo en un clúster de tres nodos deja de funcionar, OpenSearch redistribuye los fragmentos no asignados, como se muestra en el siguiente diagrama. Aquí, "P" representa una copia de fragmento principal, mientras que "R" representa una copia de fragmento de réplica.

Este comportamiento del dominio se puede explicar en dos partes: durante la falla y durante la recuperación.
Durante la falla
Un dominio implementado en varias zonas de disponibilidad puede encontrar varios tipos de fallas durante su ciclo de vida.
Falla de zona completa
Un clúster puede perder una sola zona de disponibilidad debido a una variedad de razones y también a todos los nodos de esa zona. Hoy, el servicio intenta colocar los nodos perdidos en las restantes zonas de disponibilidad en buen estado. El servicio también intenta volver a crear los fragmentos perdidos en los nodos restantes sin dejar de seguir las reglas de asignación. Esto puede resultar en algunas consecuencias no deseadas.
- Cuando los fragmentos de la zona afectada se reasignan a zonas saludables, desencadenan recuperaciones de fragmentos que pueden aumentar las latencias a medida que consumen ciclos de CPU y ancho de banda de red adicionales.
- Para una configuración n-AZ, n-copia, (n>1), las Zonas de disponibilidad n-1 supervivientes se asignan con la n-ésima copia de fragmento, lo que puede ser indeseable ya que puede causar sesgo en la distribución de fragmentos, lo que también puede resultar en Tráfico desequilibrado entre nodos. Estos nodos pueden sobrecargarse, lo que provocaría más fallas.
Fallo de zona parcial
En el caso de una falla parcial de la zona o cuando el dominio pierde solo algunos de los nodos en una zona de disponibilidad, Amazon OpenSearch Service intenta reemplazar los nodos fallidos lo más rápido posible. Sin embargo, en caso de que se tarde demasiado en reemplazar los nodos, OpenSearch intenta asignar los fragmentos no asignados de esa zona a los nodos supervivientes de la zona de disponibilidad. Si el servicio no puede reemplazar los nodos en la zona de disponibilidad afectada, puede asignarlos en la otra zona de disponibilidad configurada, lo que puede sesgar aún más la distribución de fragmentos dentro y fuera de la zona. Esto nuevamente tiene consecuencias no deseadas.
- Si los nodos en el dominio no tienen suficiente espacio de almacenamiento para acomodar los fragmentos adicionales, el dominio puede bloquearse contra escritura, lo que afecta la operación de indexación.
- Debido a la distribución sesgada de los fragmentos, el dominio también puede experimentar un tráfico sesgado entre los nodos, lo que puede aumentar aún más las latencias o los tiempos de espera para las operaciones de lectura y escritura.
Recuperación
Hoy, para mantener el recuento de nodos deseado del dominio, Amazon OpenSearch Service lanza nodos de datos en las Zonas de disponibilidad saludables restantes, de forma similar a los escenarios descritos en la sección de fallas anterior. Para garantizar una distribución adecuada de los nodos en todas las zonas de disponibilidad después de un incidente de este tipo, AWS necesitaba una intervención manual.
Que esta cambiando
Para mejorar el manejo general de fallas y minimizar el impacto de las fallas en el estado y el rendimiento del dominio, Amazon OpenSearch Service está realizando los siguientes cambios:
- Conciencia de zona forzada: OpenSearch tiene una configuración de equilibrio de fragmentos preexistente llamada reconocimiento forzado que se usa para establecer las zonas de disponibilidad a las que se deben asignar fragmentos. Por ejemplo, si tiene un atributo de conciencia llamado zona y configura nodos en
zone1yzone2, puede usar la conciencia forzada para evitar que OpenSearch asigne réplicas si solo hay una zona disponible:
Con esta configuración de ejemplo, si inicia dos nodos con node.attr.zone establecido en zone1 y crea un índice con cinco fragmentos y una réplica, OpenSearch crea el índice y asigna los cinco fragmentos principales pero no las réplicas. Las réplicas solo se asignan una vez a los nodos con node.attr.zone establecido en zone2 están disponibles.
Amazon OpenSearch Service utilizará la configuración de reconocimiento forzado en dominios Multi-AZ para garantizar que los fragmentos solo se asignen de acuerdo con las reglas de reconocimiento de zona. Esto evitaría el aumento repentino de la carga en los nodos de las zonas de disponibilidad en buen estado.
- Asignación de fragmentos con reconocimiento de carga: Amazon OpenSearch Service tendrá en cuenta factores como la capacidad aprovisionada, la capacidad real y el total de copias de fragmentos para calcular si algún nodo está sobrecargado con más fragmentos según el promedio esperado de fragmentos por nodo. Evitaría la asignación de fragmentos cuando cualquier nodo haya asignado un recuento de fragmentos que supere este límite.
Note que cualquier sin asignar primario la copia todavía se permitiría en el nodo sobrecargado para evitar que el clúster pierda datos de forma inminente.
De manera similar, para abordar el problema de la recuperación manual (como se describe en la sección Recuperación anterior), Amazon OpenSearch Service también está realizando cambios en su componente de escalado interno. Con los cambios más recientes implementados, Amazon OpenSearch Service no lanzará nodos en las zonas de disponibilidad restantes, incluso cuando pase por el escenario de falla descrito anteriormente.
Visualización del comportamiento actual y nuevo
Por ejemplo, un dominio de Amazon OpenSearch Service está configurado con 3-AZ, 6 nodos de datos, 12 fragmentos primarios y 24 fragmentos de réplica. El dominio se aprovisiona en AZ-1, AZ-2 y AZ-3, con dos nodos en cada una de las zonas.
Asignación de fragmentos actual:
Número total de fragmentos: 12 principales + 24 réplicas = 36 fragmentos
Número de zonas de disponibilidad: 3
Número de fragmentos por zona (la conciencia de la zona es verdadera): 36/3 = 12
Número de nodos por zona de disponibilidad: 2
Número de fragmentos por nodo: 12/2 = 6
El siguiente diagrama proporciona una representación visual de la configuración del dominio. Los círculos indican el recuento de fragmentos asignados al nodo. Amazon OpenSearch Service asignará seis fragmentos por nodo.

Durante una falla de zona parcial, donde falla un nodo en AZ-3, el nodo fallido se asigna a la zona restante y los fragmentos en la zona se redistribuyen en función de los nodos disponibles. Después de los cambios descritos anteriormente, el clúster no creará un nuevo nodo ni redistribuirá fragmentos después de la falla del nodo.

En el diagrama anterior, con la pérdida de un nodo en AZ-3, Amazon OpenSearch Service intentaría lanzar la capacidad de reemplazo en la misma zona. Sin embargo, debido a alguna interrupción, la zona podría verse afectada y no podría iniciar el reemplazo. En tal caso, el servicio intenta lanzar una capacidad deficitaria en otra zona saludable, lo que podría generar un desequilibrio de zona entre las zonas de disponibilidad. Los fragmentos de la zona afectada se rellenan en el nodo superviviente de la misma zona. Sin embargo, con el nuevo comportamiento, el servicio intentaría lanzar capacidad en la misma zona pero evitaría lanzar capacidad deficitaria en otras zonas para evitar el desequilibrio. El asignador de fragmentos también garantizaría que los nodos supervivientes no se sobrecarguen.

De manera similar, en caso de que se pierdan todos los nodos en AZ-3, o el AZ-3 se dañe, Amazon OpenSearch Service recupera los nodos perdidos en la zona de disponibilidad restante y también redistribuye los fragmentos en los nodos. Sin embargo, después de los nuevos cambios, Amazon OpenSearch Service no asignará nodos a la zona restante ni intentará reasignar fragmentos perdidos a la zona restante. Amazon OpenSearch Service esperará a que se produzca la recuperación y que el dominio vuelva a la configuración original después de la recuperación.
Si su dominio no cuenta con suficiente capacidad para resistir la pérdida de una zona de disponibilidad, es posible que experimente una caída en el rendimiento de su dominio. Por lo tanto, se recomienda enfáticamente seguir las mejores prácticas al dimensionar su dominio, lo que significa tener suficientes recursos aprovisionados para resistir la pérdida de una sola falla de la zona de disponibilidad.

Actualmente, una vez que el dominio se recupera, el servicio requiere una intervención manual para equilibrar la capacidad entre las zonas de disponibilidad, lo que también implica movimientos de fragmentos. Sin embargo, con el nuevo comportamiento, no se necesita intervención durante el proceso de recuperación porque la capacidad regresa a la zona afectada y los fragmentos también se asignan automáticamente a los nodos recuperados. Esto asegura que no haya prioridades contrapuestas sobre los recursos restantes.
Lo que puede esperar
Después de actualizar su dominio de Amazon OpenSearch Service a la última versión del software de servicio, los dominios que se han configurado con las mejores prácticas tendrá un rendimiento más predecible incluso después de perder uno o varios nodos de datos en una zona de disponibilidad. Habrá casos reducidos de sobreasignación de fragmentos en un nodo. Es una buena práctica aprovisionar suficiente capacidad para poder tolerar una falla de una sola zona.
En ocasiones, es posible que vea un dominio que se vuelve amarillo durante tales fallas inesperadas, ya que no asignaremos fragmentos de réplica a los nodos sobrecargados. Sin embargo, esto no significa que habrá pérdida de datos en un dominio bien configurado. Todavía nos aseguraremos de que todas las primarias estén asignadas durante las interrupciones. Existe una recuperación automatizada, que se encargará de equilibrar los nodos en el dominio y garantizar que las réplicas se asignen una vez que se recupere la falla.
Actualice el software de servicio de su dominio de Amazon OpenSearch Service para aplicar estos nuevos cambios a su dominio. Más detalles sobre el proceso de actualización del software de servicio están en el Documentación del servicio Amazon OpenSearch.
Conclusión
En esta publicación, vimos cómo Amazon OpenSearch Service mejoró recientemente la lógica para distribuir nodos y fragmentos en las zonas de disponibilidad durante las interrupciones zonales.
Este cambio ayudará al servicio a garantizar un rendimiento más consistente y predecible durante fallas de nodo o zonales. Los dominios no verán latencias aumentadas ni escribirán bloques durante el procesamiento de escrituras y lecturas, que solían aparecer antes debido a la asignación excesiva de fragmentos en los nodos.
Sobre los autores
 Bujtawar Khan es un ingeniero de software sénior que trabaja en Amazon OpenSearch Service. Está interesado en sistemas distribuidos y autónomos. Es un colaborador activo de OpenSearch.
Bujtawar Khan es un ingeniero de software sénior que trabaja en Amazon OpenSearch Service. Está interesado en sistemas distribuidos y autónomos. Es un colaborador activo de OpenSearch.
 Anshu Agarval es un ingeniero de software sénior que trabaja en AWS OpenSearch en Amazon Web Services. Le apasiona resolver problemas relacionados con la construcción de sistemas escalables y altamente confiables.
Anshu Agarval es un ingeniero de software sénior que trabaja en AWS OpenSearch en Amazon Web Services. Le apasiona resolver problemas relacionados con la construcción de sistemas escalables y altamente confiables.
 Shourya Dutta Biswas es un ingeniero de software que trabaja en AWS OpenSearch en Amazon Web Services. Le apasiona construir sistemas distribuidos altamente resilientes.
Shourya Dutta Biswas es un ingeniero de software que trabaja en AWS OpenSearch en Amazon Web Services. Le apasiona construir sistemas distribuidos altamente resilientes.
 Rishab Nahata es un ingeniero de software que trabaja en OpenSearch en Amazon Web Services. Le fascina resolver problemas en sistemas distribuidos. Es colaborador activo de OpenSearch.
Rishab Nahata es un ingeniero de software que trabaja en OpenSearch en Amazon Web Services. Le fascina resolver problemas en sistemas distribuidos. Es colaborador activo de OpenSearch.
 Ranjith Ramachandra es un Gerente de ingeniería que trabaja en Amazon OpenSearch Service en Amazon Web Services.
Ranjith Ramachandra es un Gerente de ingeniería que trabaja en Amazon OpenSearch Service en Amazon Web Services.
 jon manejador es un Arquitecto Principal Principal de Soluciones, especializado en tecnologías de búsqueda de AWS: Amazon CloudSearch y Amazon OpenSearch Service. Con sede en Palo Alto, ayuda a una amplia gama de clientes a implementar correctamente y funcionar bien sus cargas de trabajo de búsqueda y análisis de registros.
jon manejador es un Arquitecto Principal Principal de Soluciones, especializado en tecnologías de búsqueda de AWS: Amazon CloudSearch y Amazon OpenSearch Service. Con sede en Palo Alto, ayuda a una amplia gama de clientes a implementar correctamente y funcionar bien sus cargas de trabajo de búsqueda y análisis de registros.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/
- 1
- 10
- 100
- 7
- 9
- a
- Poder
- Nuestra Empresa
- arriba
- acomodar
- Conforme
- a través de
- lector activo
- Adicionales
- dirección
- Después
- Todos
- asignado
- asigna
- asignación
- Amazon
- Amazon Web Services
- Analytics
- y
- Otra
- Aplicación
- aplicada
- asigna
- atributos
- Confirmación de Viaje
- automáticamente
- autónomo
- disponibilidad
- Hoy Disponibles
- promedio
- conciencia
- AWS
- fondo
- Balance
- Ancho de banda
- basado
- porque
- se convierte en
- MEJOR
- y las mejores prácticas
- mejores
- entre
- Más allá de
- Bloques
- Trae
- general
- Construir la
- , que son
- Puede conseguir
- no puede
- capacidades
- Capacidad
- servicios sociales
- case
- cases
- Causa
- el cambio
- Cambios
- círculos
- Soluciones
- Médico
- compitiendo
- componente
- concentración
- Configuración
- Consecuencias
- consideración
- consistente
- contribuyente
- Correspondiente
- Para crear
- crea
- Current
- Clientes
- de ciclos
- datos
- De pérdida de datos
- DÉFICIT
- desplegar
- desplegado
- descrito
- detalles
- una experiencia diferente
- distribuir
- distribuidos
- sistemas distribuidos
- dominio
- dominios
- No
- DE INSCRIPCIÓN
- Soltar
- durante
- cada una
- Más temprano
- ingeniero
- Ingeniería
- suficientes
- garantizar
- asegura
- asegurando que
- igualmente
- especialmente
- Éter (ETH)
- Incluso
- Evento
- ejemplo
- esperado
- experience
- explicado
- factores importantes
- FALLO
- Fallidos
- falla
- Fracaso
- seguir
- siguiendo
- FORCE
- Desde
- funcionamiento
- promover
- General
- obtener
- conseguir
- gif
- Va
- candidato
- Manejo
- suceder
- es
- Salud
- saludable
- ayuda
- ayuda
- esta página
- altamente
- organizado
- Cómo
- Sin embargo
- HTML
- HTTPS
- desequilibrio
- Impacto
- impactados
- importante
- mejorar
- mejorado
- in
- En otra
- incidente
- aumente
- aumentado
- índice
- EN LA MINA
- infraestructura
- ejemplo
- interactivo
- interesado
- interno
- intervención
- IT
- más reciente
- lanzamiento
- pone en marcha
- lanzamiento
- Lead
- líder
- Legado
- LIMITE LAS
- carga
- Largo
- perder
- Pierde
- no logras
- de
- mantener
- para lograr
- HACE
- Realizar
- gestionado
- gerente
- manual
- muchos
- significa
- podría
- minimizando
- monitoreo
- más,
- movimientos
- múltiples
- ¿ Necesita ayuda
- Neither
- del sistema,
- Nuevo
- nodo
- Distribución de nodos
- nodos
- número
- que ofrece
- ONE
- funcionar
- Inteligente
- Operaciones
- solicite
- reconocida por
- Otro
- corte
- Cortes
- total
- abrumado
- Palo Alto
- partes
- apasionado
- realizar
- actuación
- realizar
- Colocar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- posible
- Publicación
- alimentado
- prácticas
- Previsible
- evitar
- previamente
- primario
- Director de la escuela
- problemas
- tratamiento
- apropiado
- perfecta
- proporcionar
- proporciona un
- provisión
- con rapidez
- distancia
- Leer
- en tiempo real
- razones
- recientemente
- recomendado
- Recupera
- recuperación
- Reducción
- la reducción de
- relacionado
- ,
- confianza
- restante
- reemplazar
- responder
- representación
- representa
- requiere
- resistente
- Recursos
- resultado
- volvemos
- devoluciones
- reglas
- Said
- mismo
- escalable
- Escala
- la ampliación
- escenarios
- Buscar
- Sección
- seguro
- de coches
- Servicios
- set
- Configure
- mostrado
- similares
- desde
- soltero
- SEIS
- sesgar
- So
- Software
- Ingeniero de Software
- Soluciones
- Resolver
- algo
- Espacio
- especializada
- Estabilidad
- comienzo
- Sin embargo
- STORAGE
- se mostró plenamente
- tal
- repentino
- suficiente
- SOPORTE
- Superficie
- Todas las funciones a su disposición
- ¡Prepárate!
- toma
- Tecnologías
- La
- su
- por lo tanto
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- rendimiento
- veces
- a
- hoy
- tolerancia
- demasiado
- Total
- tráfico
- detonante
- verdadero
- Turning
- tipos
- Inesperado
- Actualizar
- actualizado
- utilizan el
- Valores
- variedad
- visualización
- esperar
- web
- servicios web
- Página web
- que
- mientras
- seguirá
- dentro de
- sin
- trabajando
- se
- escribir
- tú
- zephyrnet
- zonas