Con EMR de Amazon 6.15, lanzamos Formación del lago AWS Controles de acceso detallados (FGAC) basados en formatos de tabla abierta (OTF), incluidos Apache Hudi, Apache Iceberg y Delta Lake. Esto le permite simplificar la seguridad y la gobernanza sobre lagos de datos transaccionales proporcionando controles de acceso en permisos a nivel de tabla, columna y fila con sus trabajos de Apache Spark. Muchas grandes empresas buscan utilizar su lago de datos transaccionales para obtener información y mejorar la toma de decisiones. Puede construir una arquitectura de casa en el lago utilizando Amazon EMR integrado con Lake Formation para FGAC. Esta combinación de servicios le permite realizar análisis de datos en su lago de datos transaccionales al tiempo que garantiza un acceso seguro y controlado.
El componente del servidor de registros de Amazon EMR admite la funcionalidad de filtrado de datos a nivel de tabla, columna, fila, celda y atributo anidado. Amplía la compatibilidad con los formatos Hive, Apache Hudi, Apache Iceberg y Delta Lake para operaciones de lectura (incluidos viajes en el tiempo y consultas incrementales) y escritura (en declaraciones DML como INSERT). Además, con la versión 6.15, Amazon EMR introduce protección de control de acceso para la interfaz web de su aplicación, como Spark History Server en el clúster, Yarn Timeline Server y la interfaz de usuario de Yarn Resource Manager.
En esta publicación, demostramos cómo implementar FGAC en apache hudi tablas que utilizan Amazon EMR integrado con Lake Formation.
Caso de uso del lago de datos de transacciones
Los clientes de Amazon EMR suelen utilizar formatos de tabla abierta para respaldar sus necesidades de viajes en el tiempo y transacciones ACID en un lago de datos. Al preservar las versiones históricas, el viaje en el tiempo del lago de datos proporciona beneficios como auditoría y cumplimiento, recuperación y reversión de datos, análisis reproducible y exploración de datos en diferentes momentos.
Otro caso de uso popular del lago de datos de transacciones es la consulta incremental. La consulta incremental se refiere a una estrategia de consulta que se centra en procesar y analizar solo los datos nuevos o actualizados dentro de un lago de datos desde la última consulta. La idea clave detrás de las consultas incrementales es utilizar metadatos o mecanismos de seguimiento de cambios para identificar los datos nuevos o modificados desde la última consulta. Al identificar estos cambios, el motor de consultas puede optimizar la consulta para procesar solo los datos relevantes, lo que reduce significativamente el tiempo de procesamiento y los requisitos de recursos.
Resumen de la solución
En esta publicación, demostramos cómo implementar FGAC en tablas de Apache Hudi usando Amazon EMR en Nube informática elástica de Amazon (Amazon EC2) integrado con Lake Formation. Apache Hudi es un marco de lago de datos transaccional de código abierto que simplifica enormemente el procesamiento de datos incremental y el desarrollo de canalizaciones de datos. Esta nueva característica de FGAC es compatible con todos los OTF. Además de hacer una demostración con Hudi aquí, realizaremos un seguimiento de otras tablas OTF en otros blogs. Usamos ordenadores portátiles in Estudio Amazon SageMaker para leer y escribir datos de Hudi a través de diferentes permisos de acceso de usuarios a través de un clúster EMR. Esto refleja escenarios de acceso a datos del mundo real; por ejemplo, si un usuario de ingeniería necesita acceso completo a los datos para solucionar problemas en una plataforma de datos, mientras que es posible que los analistas de datos solo necesiten acceder a un subconjunto de esos datos que no contienen información de identificación personal (PII). ). Integración con Lake Formation a través del Rol de tiempo de ejecución de Amazon EMR Además, le permite mejorar su postura de seguridad de datos y simplifica la administración del control de datos para las cargas de trabajo de Amazon EMR. Esta solución garantiza un entorno seguro y controlado para el acceso a los datos, satisfaciendo las diversas necesidades y requisitos de seguridad de los diferentes usuarios y roles en una organización.
El siguiente diagrama ilustra la arquitectura de la solución.
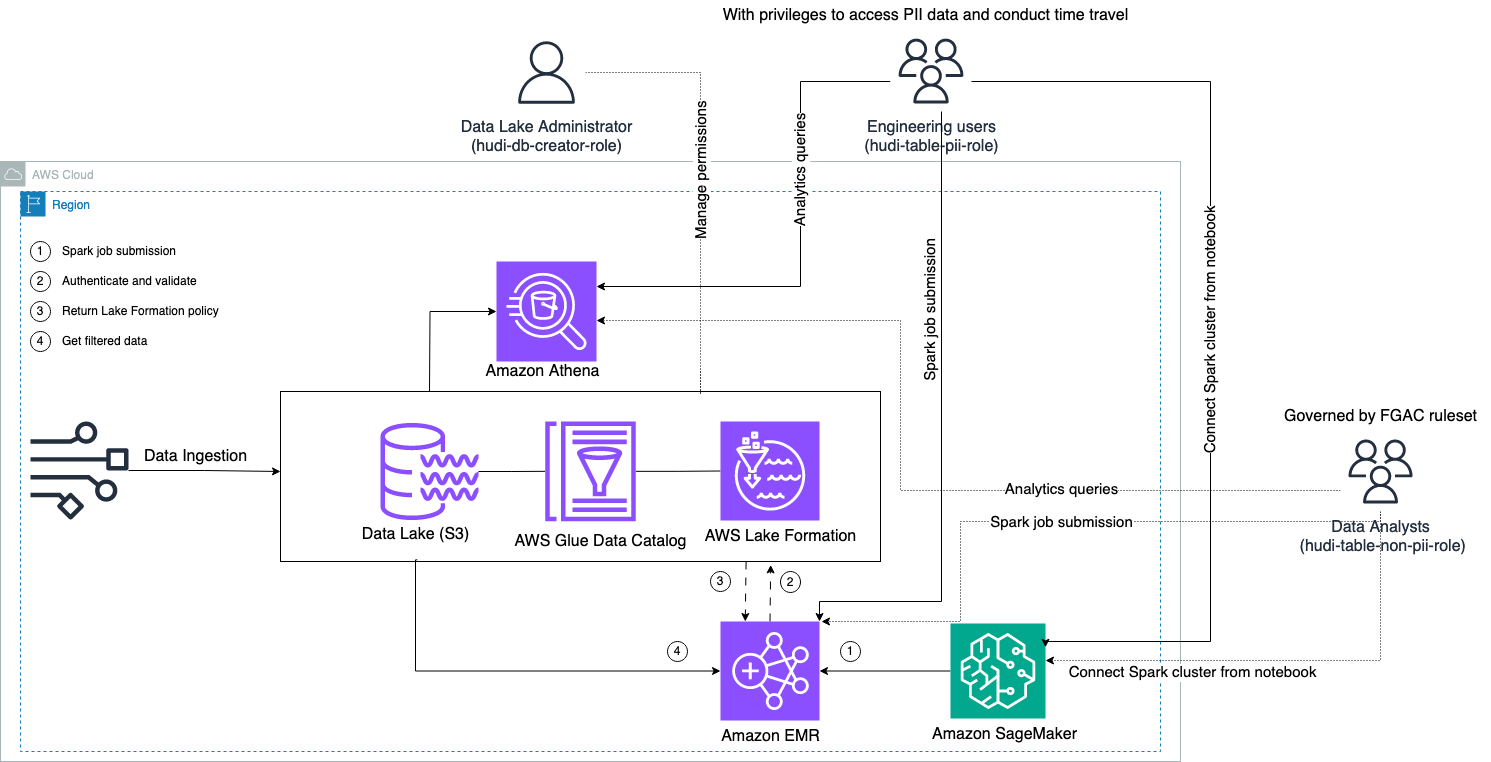
Llevamos a cabo un proceso de ingesta de datos para insertar (actualizar e insertar) un conjunto de datos de Hudi en un Servicio de almacenamiento simple de Amazon (Amazon S3) y conservar o actualizar el esquema de la tabla en el Pegamento AWS Catálogo de datos. Sin movimiento de datos, podemos consultar la tabla Hudi gobernada por Lake Formation a través de varios servicios de AWS, como Atenea amazónica, AmazonEMR y Amazon SageMaker.
Cuando los usuarios envían un trabajo de Spark a través de cualquier punto final del clúster EMR (EMR Steps, Livy, EMR Studio y SageMaker), Lake Formation valida sus privilegios e indica al clúster EMR que filtre datos confidenciales, como datos PII.
Esta solución tiene tres tipos diferentes de usuarios con diferentes niveles de permisos para acceder a los datos de Hudi:
- rol-creador-hudi-db – Lo utiliza el administrador del lago de datos que tiene privilegios para realizar operaciones DDL, como crear, modificar y eliminar objetos de la base de datos. Pueden definir reglas de filtrado de datos en Lake Formation para el control de acceso a datos a nivel de fila y columna. Estas reglas del FGAC garantizan que el lago de datos esté seguro y cumpla con las normas de privacidad de datos requeridas.
- hudi-table-pii-rol – Esto lo utilizan los usuarios de ingeniería. Los usuarios de ingeniería son capaces de realizar viajes en el tiempo y consultas incrementales tanto en Copy-on-Write (CoW) como en Merge-on-Read (MoR). También tienen privilegios para acceder a datos de PII en función de cualquier marca de tiempo.
- hudi-table-non-pii-rol – Esto lo utilizan los analistas de datos. Los derechos de acceso a los datos de los analistas de datos se rigen por reglas autorizadas por la FGAC controladas por los administradores del lago de datos. No tienen visibilidad en las columnas que contienen datos PII como nombres y direcciones. Además, no pueden acceder a filas de datos que no cumplan determinadas condiciones. Por ejemplo, los usuarios sólo pueden acceder a filas de datos que pertenecen a su país.
Requisitos previos
Puedes descargar los tres cuadernos utilizados en esta publicación desde Repositorio GitHub.
Antes de implementar la solución, asegúrese de tener lo siguiente:
Complete los siguientes pasos para configurar sus permisos:
- Inicie sesión en su cuenta de AWS con su usuario administrador de IAM.
Asegúrate de estar en elus-east-1Región.
- Cree un depósito S3 en el
us-east-1Región (por ejemplo,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
A continuación, habilitamos Lake Formation mediante cambiando el modelo de permiso predeterminado.
- Inicie sesión en la consola de Lake Formation como usuario administrador.
- Elige Configuración del catálogo de datos bajo Administración en el panel de navegación.
- under Permisos predeterminados para bases de datos y tablas recién creadas, deseleccionar Use solo el control de acceso de IAM para nuevas bases de datos y Use solo el control de acceso de IAM para tablas nuevas en bases de datos nuevas.
- Elige Guardar.
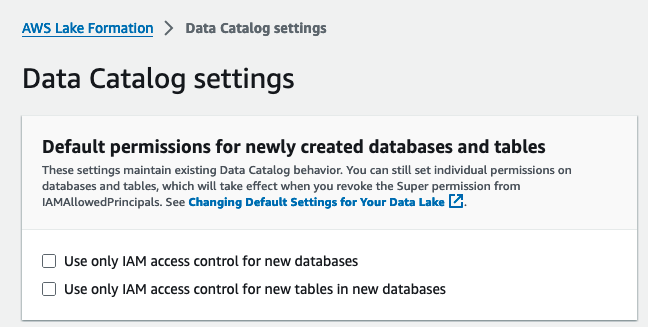
Alternativamente, debe revocar IAMAllovedPrincipals en los recursos (bases de datos y tablas) creados si inició Lake Formation con la opción predeterminada.
Finalmente, creamos un par de claves para Amazon EMR.
- En la consola de Amazon EC2, elija Pares de claves en el panel de navegación.
- Elige Crear par de claves.
- Nombre, introduzca un nombre (por ejemplo
emr-fgac-hudi-keypair). - Elige Crear par de claves.
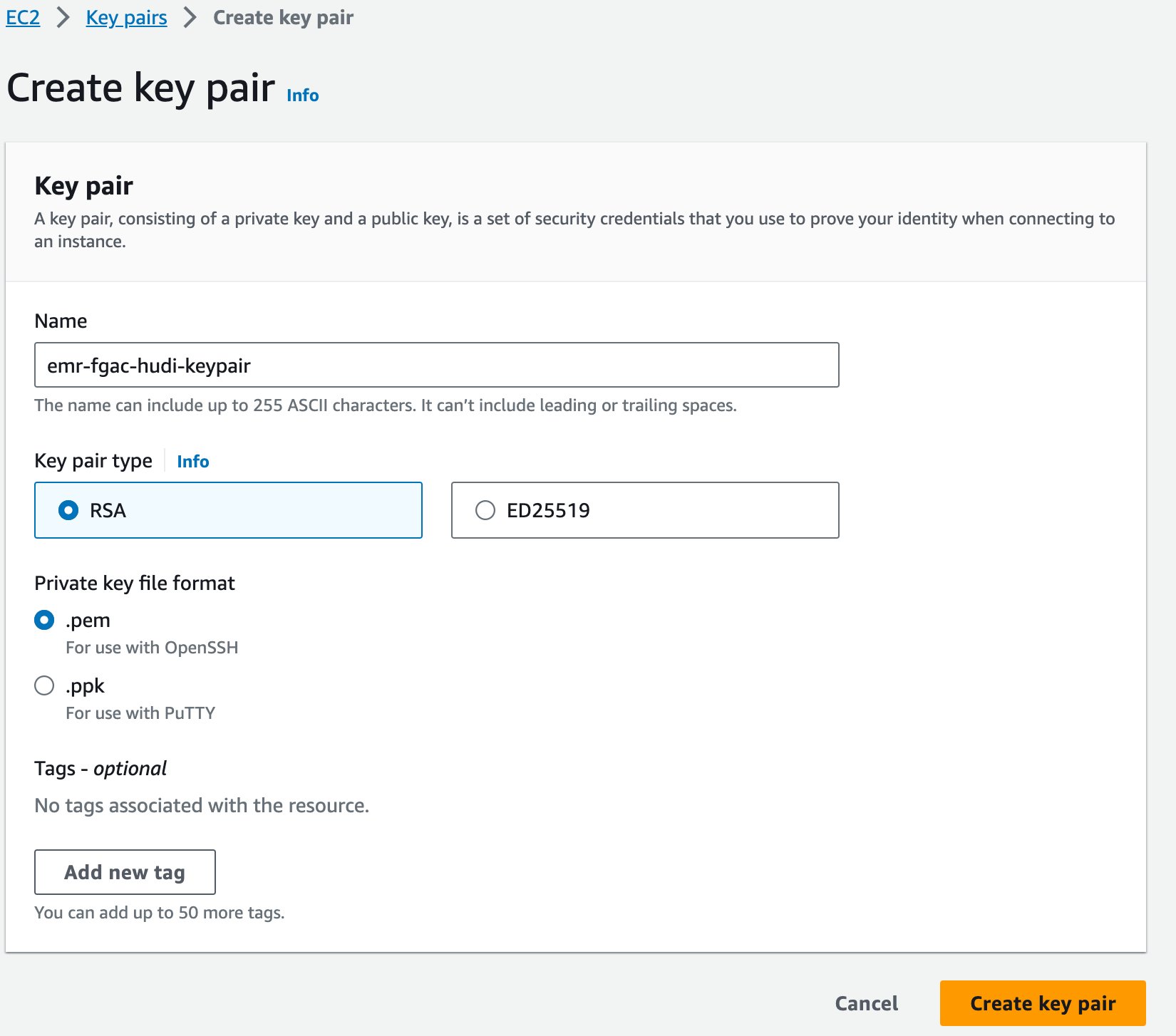
El par de claves generado (para esta publicación, emr-fgac-hudi-keypair.pem) se guardará en su computadora local.
A continuación, creamos un Nube de AWS9 entorno de desarrollo interactivo (IDE).
- En la consola de AWS Cloud9, elija Entornos en el panel de navegación.
- Elige Crear ambiente.
- Nombre¸ ingrese un nombre (por ejemplo,
emr-fgac-hudi-env). - Mantenga las otras configuraciones como predeterminadas.
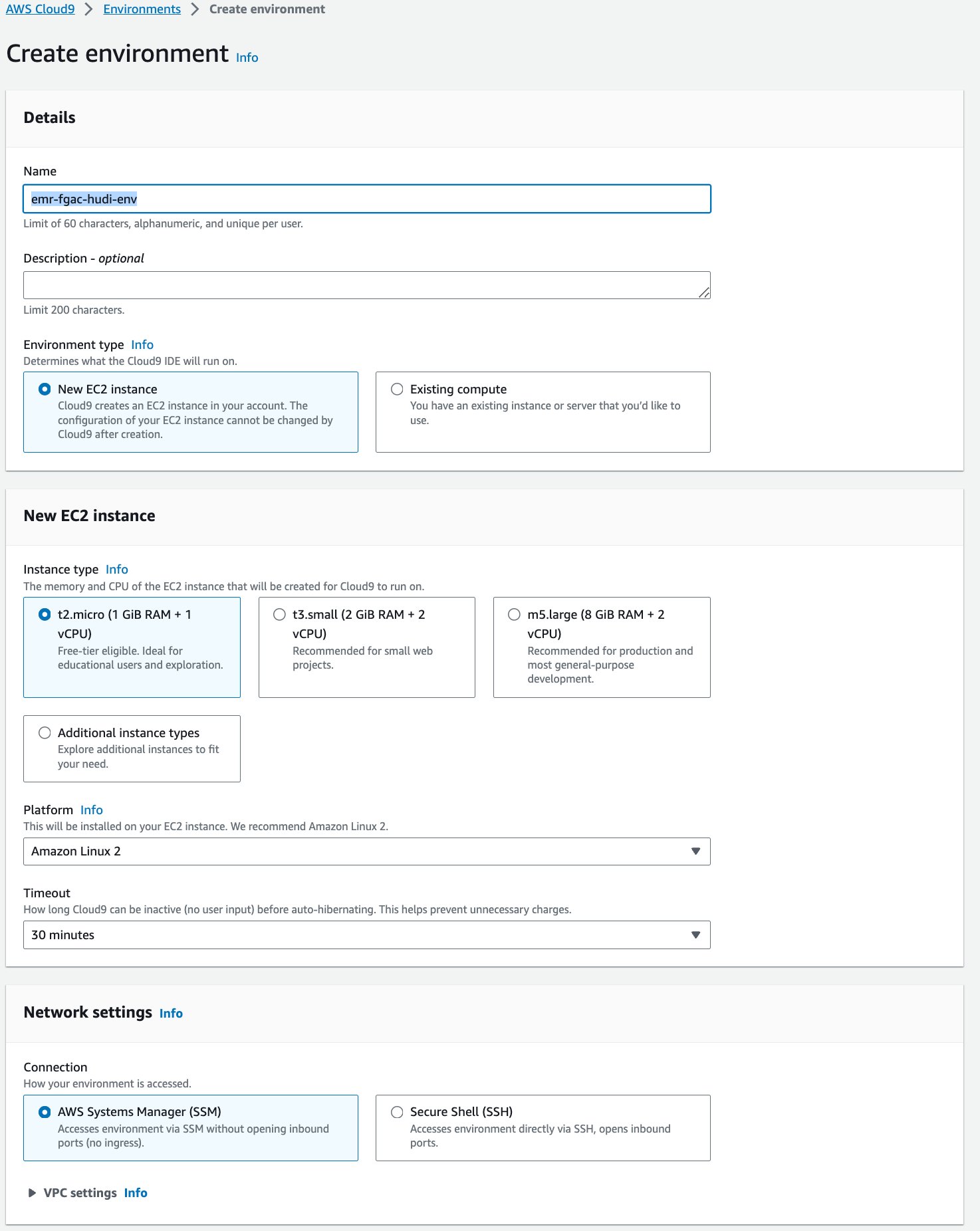
- Elige Crear.
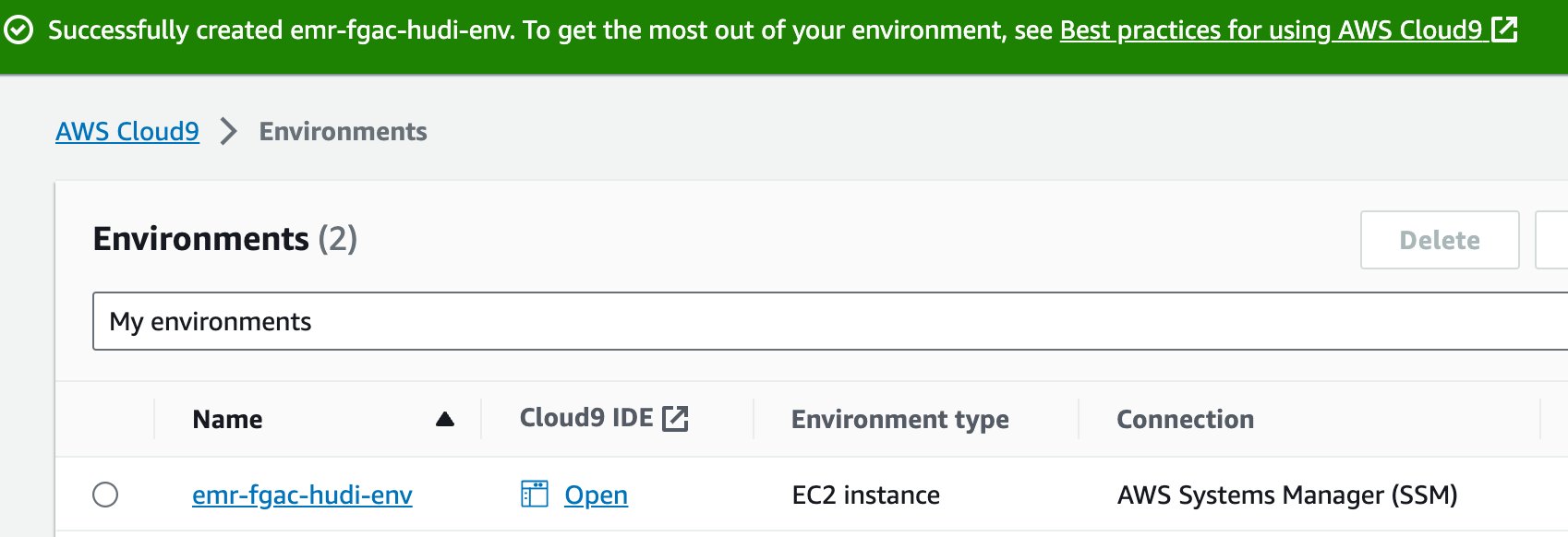
- Cuando el IDE esté listo, elija Abierto Para abrirlo.
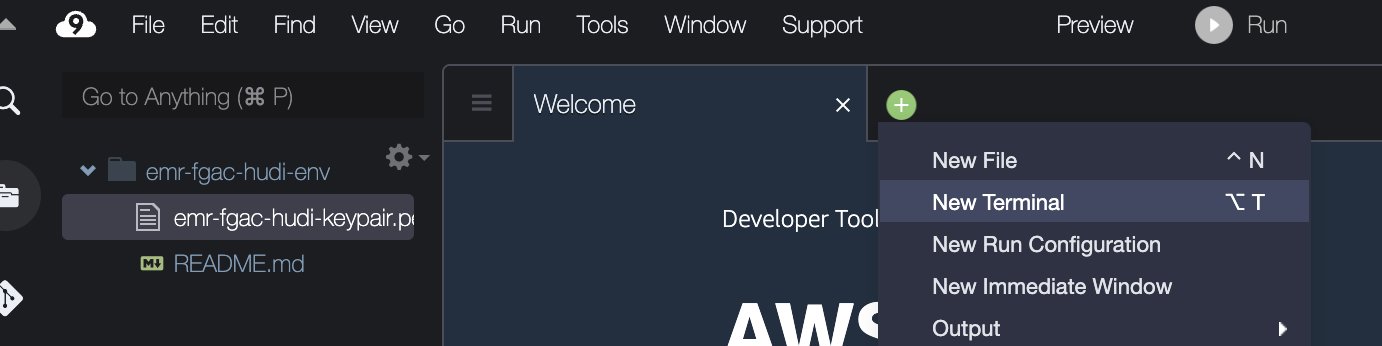
- En el IDE de AWS Cloud9, en el Archive menú, seleccione Cargar archivos locales.

- Cargue el archivo del par de claves (
emr-fgac-hudi-keypair.pem). - Elija el signo más y elija Nueva terminal.
- En la terminal, ingrese las siguientes líneas de comando:
Tenga en cuenta que el código de ejemplo es una prueba de concepto únicamente con fines de demostración. Para los sistemas de producción, utilice una autoridad de certificación (CA) confiable para emitir certificados. Referirse a Proporcionar certificados para cifrar datos en tránsito con cifrado de Amazon EMR para obtener más detalles.
Implemente la solución a través de AWS CloudFormation
Proporcionamos un Formación en la nube de AWS Plantilla que configura automáticamente los siguientes servicios y componentes:
- Un depósito S3 para el lago de datos. Contiene el conjunto de datos TPC-DS de muestra.
- Un clúster EMR con configuración de seguridad y DNS público habilitado.
- Roles de IAM en tiempo de ejecución de EMR con permisos específicos de Lake Formation:
- -hudi-db-creador-rol – Esta función se utiliza para crear tablas y bases de datos de Apache Hudi.
- -hudi-table-pii-role – Esta función proporciona permiso para consultar todas las columnas de las tablas de Hudi, incluidas las columnas con PII.
- -hudi-table-non-pii-rol – Esta función proporciona permiso para consultar tablas de Hudi que han filtrado columnas de PII por Lake Formation.
- Roles de ejecución de SageMaker Studio que permiten a los usuarios asumir sus roles de tiempo de ejecución de EMR correspondientes.
- Recursos de red como VPC, subredes y grupos de seguridad.
Complete los siguientes pasos para implementar los recursos:
- Elige Pila de creación rápida para iniciar la pila de CloudFormation.
- Nombre de pila, ingrese un nombre de pila (por ejemplo,
rsv2-emr-hudi-blog). - Par de claves Ec2, ingrese el nombre de su par de claves.
- Tiempo de inactividad, ingrese un tiempo de inactividad para el clúster EMR para evitar pagar por el clúster cuando no se esté utilizando.
- InitS3Bucket, ingrese el nombre del depósito S3 que creó para guardar el archivo .zip del certificado de cifrado de Amazon EMR.
- S3CertsZip, ingrese el URI de S3 del archivo .zip del certificado de cifrado de Amazon EMR.
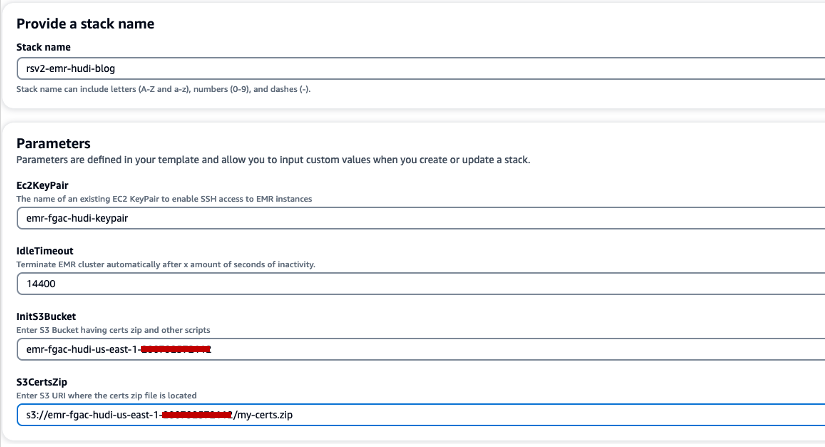
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Crear pila.
La implementación de la pila de CloudFormation tarda unos 10 minutos.
Configurar Lake Formation para la integración de Amazon EMR
Complete los siguientes pasos para configurar Lake Formation:
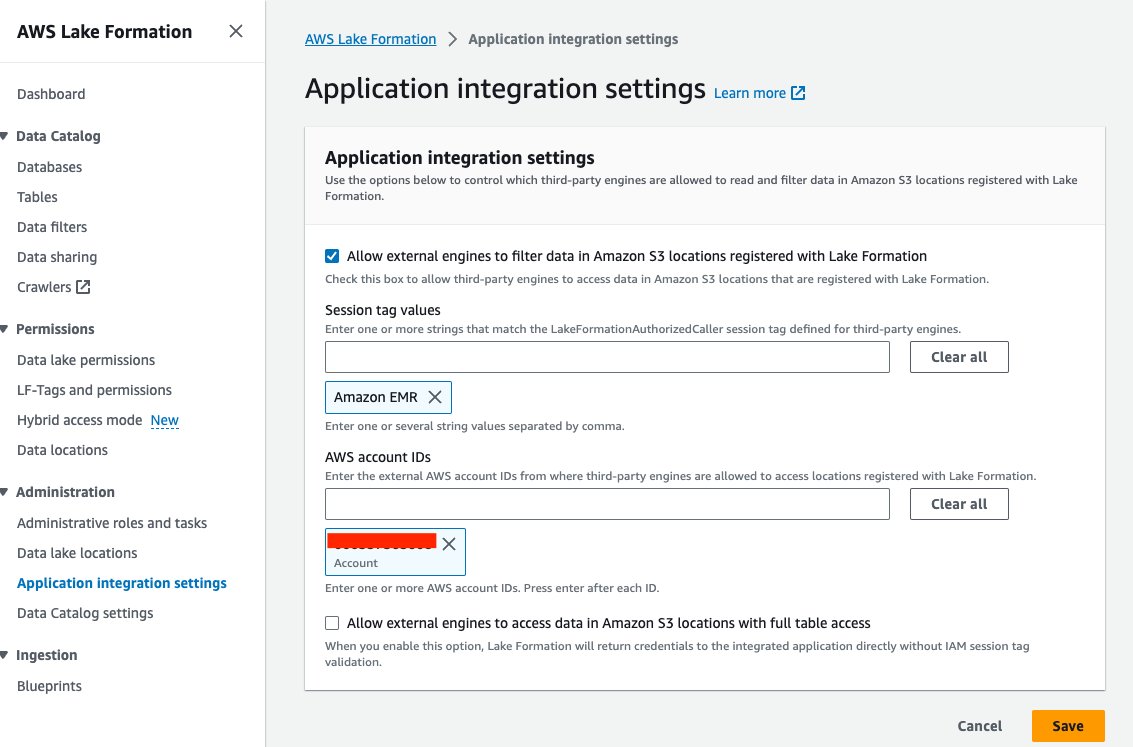
- En la consola de Lake Formation, elija Configuración de integración de aplicaciones bajo Administración en el panel de navegación.
- Seleccione Permitir que motores externos filtren datos en ubicaciones de Amazon S3 registradas con Lake Formation.
- Elige EMR de Amazon para Valores de etiqueta de sesión.
- Introduzca su ID de cuenta de AWS para ID de cuenta de AWS.
- Elige Guardar.
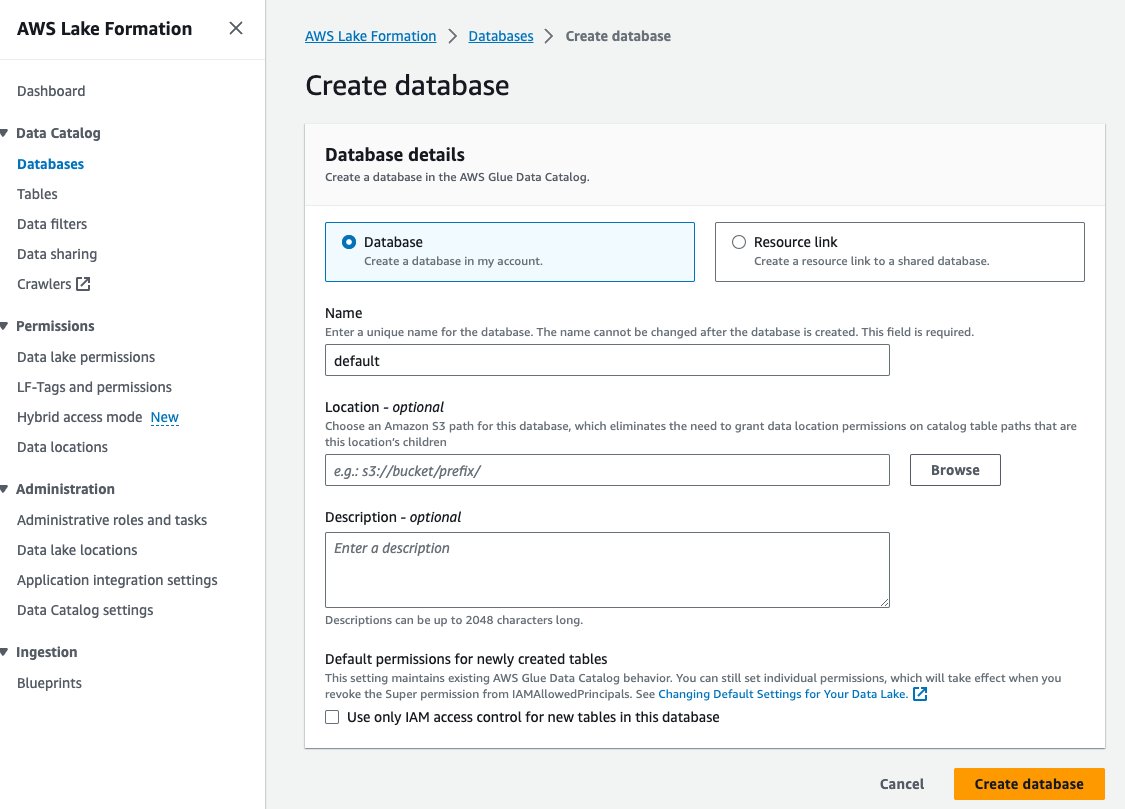
- Elige Bases de datos bajo Catálogo de datos en el panel de navegación.
- Elige Crear base de datos.
- Nombre, ingrese predeterminado.
- Elige Crear base de datos.
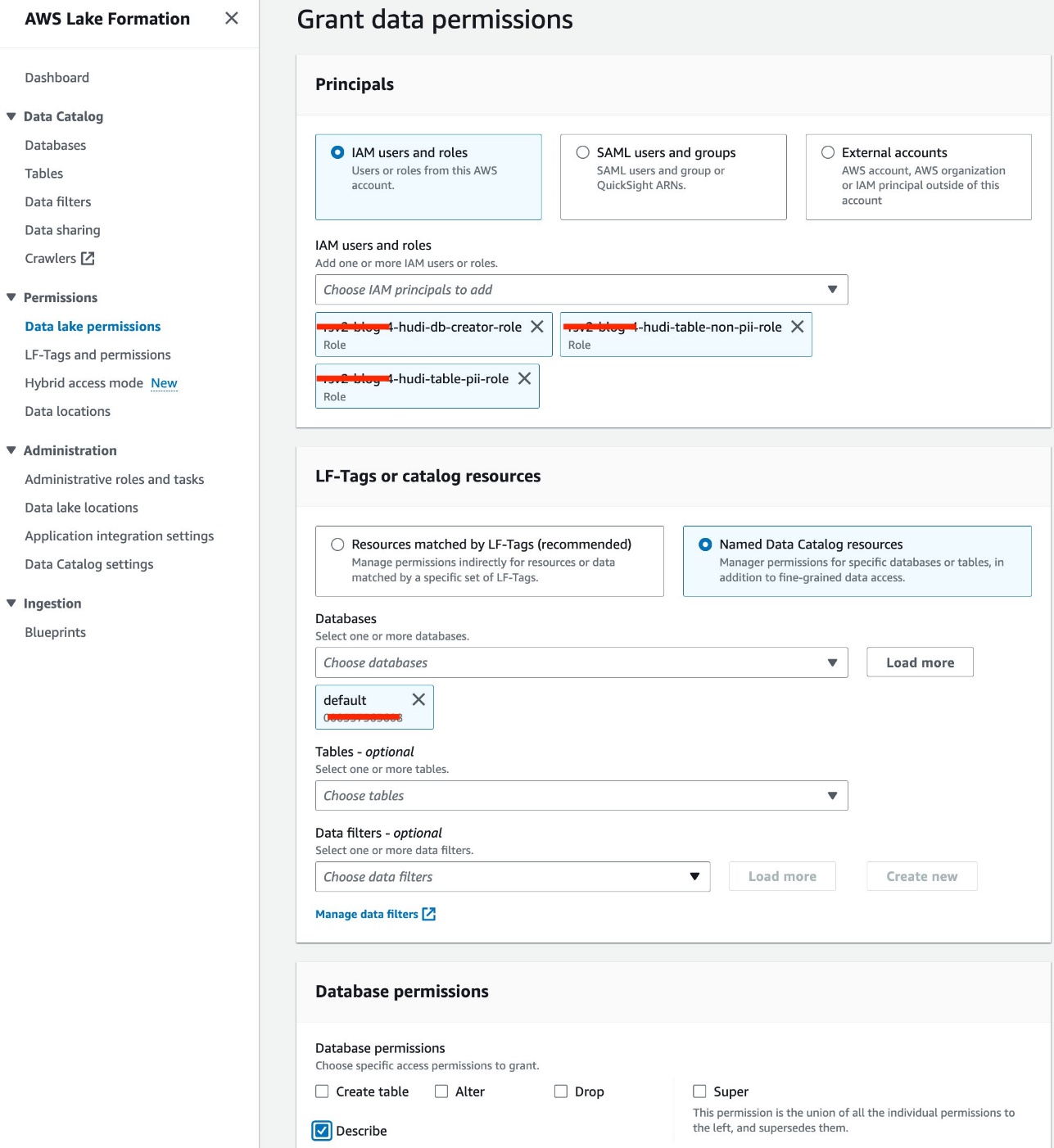
- Elige Permisos del lago de datos bajo Permisos en el panel de navegación.
- Elige Grant.
- Seleccione Usuarios y roles de IAM.
- Elija sus roles de IAM.
- Bases de datos, elija predeterminado.
- Permisos de la base de datos, seleccione Describir.
- Elige Grant.
Copie el archivo JAR de Hudi a Amazon EMR HDFS
A use Hudi con cuadernos Jupyter, debe completar los siguientes pasos para el clúster de EMR, que incluye copiar un archivo JAR de Hudi desde el directorio local de Amazon EMR a su almacenamiento HDFS, de modo que pueda configurar una sesión de Spark para usar Hudi:
- Autorizar el tráfico SSH entrante (puerto 22).
- Copie el valor de DNS público del nodo principal (por ejemplo, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) del clúster EMR Resumen .
- Vuelva al terminal AWS Cloud9 anterior que utilizó para crear el par de claves EC2.
- Ejecute el siguiente comando para SSH en el nodo principal de EMR. Reemplace el marcador de posición con su nombre de host DNS de EMR:
- Ejecute el siguiente comando para copiar el archivo JAR de Hudi a HDFS:
Cree la base de datos y las tablas de Hudi en Lake Formation
Ahora estamos listos para crear la base de datos y las tablas de Hudi con FGAC habilitado por la función de tiempo de ejecución de EMR. El Función de tiempo de ejecución de EMR es una función de IAM que puede especificar cuando envía un trabajo o una consulta a un clúster de EMR.
Conceder permiso al creador de la base de datos
Primero, otorguemos permiso al creador de la base de datos de Lake Formation para<STACK-NAME>-hudi-db-creator-role:
- Inicie sesión en su cuenta de AWS como administrador.
- En la consola de Lake Formation, elija Funciones y tareas administrativas bajo Administración en el panel de navegación.
- Confirme que su usuario de inicio de sesión de AWS se haya agregado como administrador del lago de datos.
- En Creador de base de datos sección, elija Grant.
- Usuarios y roles de IAM, escoger
<STACK-NAME>-hudi-db-creator-role. - Permisos de catálogo, seleccione Crear base de datos.
- Elige Grant.
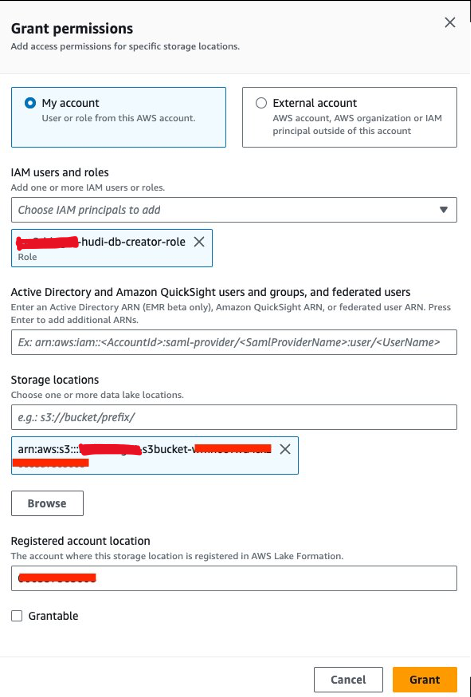
Registre la ubicación del lago de datos
A continuación, registremos la ubicación del lago de datos S3 en Lake Formation:
- En la consola de Lake Formation, elija Ubicaciones de data lake bajo Administración en el panel de navegación.
- Elige Registrar ubicación.
- Ruta de Amazon S3Elegir Explorar y elija el depósito S3 del lago de datos. (
<STACK_NAME>s3bucket-XXXXXXX) creado a partir de la pila de CloudFormation. - Rol de IAM, escoger
<STACK-NAME>-hudi-db-creator-role. - modo de permiso, seleccione Formación del lago.
- Elige Registrar ubicación.
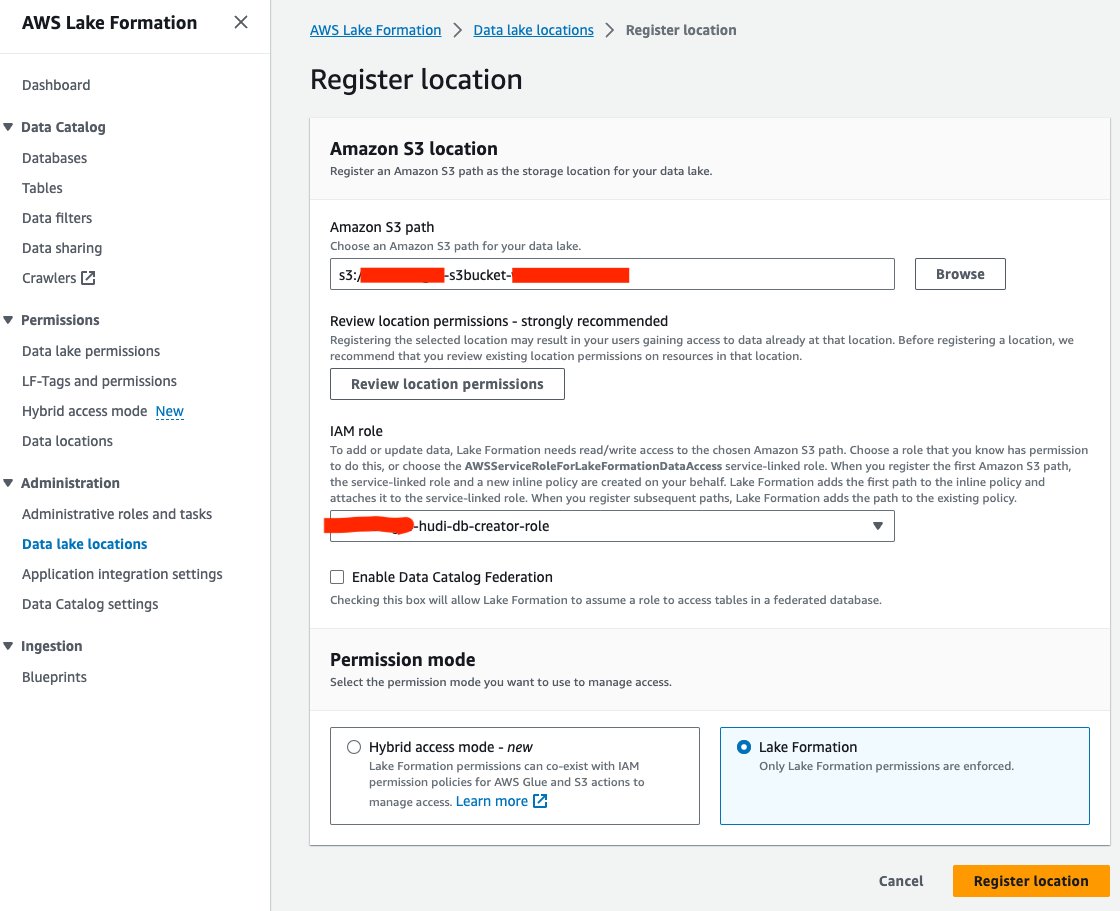
Conceder permiso de ubicación de datos
A continuación, debemos conceder<STACK-NAME>-hudi-db-creator-roleel permiso de ubicación de datos:
- En la consola de Lake Formation, elija Ubicaciones de datos bajo Permisos en el panel de navegación.
- Elige Grant.
- Usuarios y roles de IAM, escoger
<STACK-NAME>-hudi-db-creator-role. - Ubicaciones de almacenamiento, ingrese al depósito S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Elige Grant.
Conéctese al clúster EMR
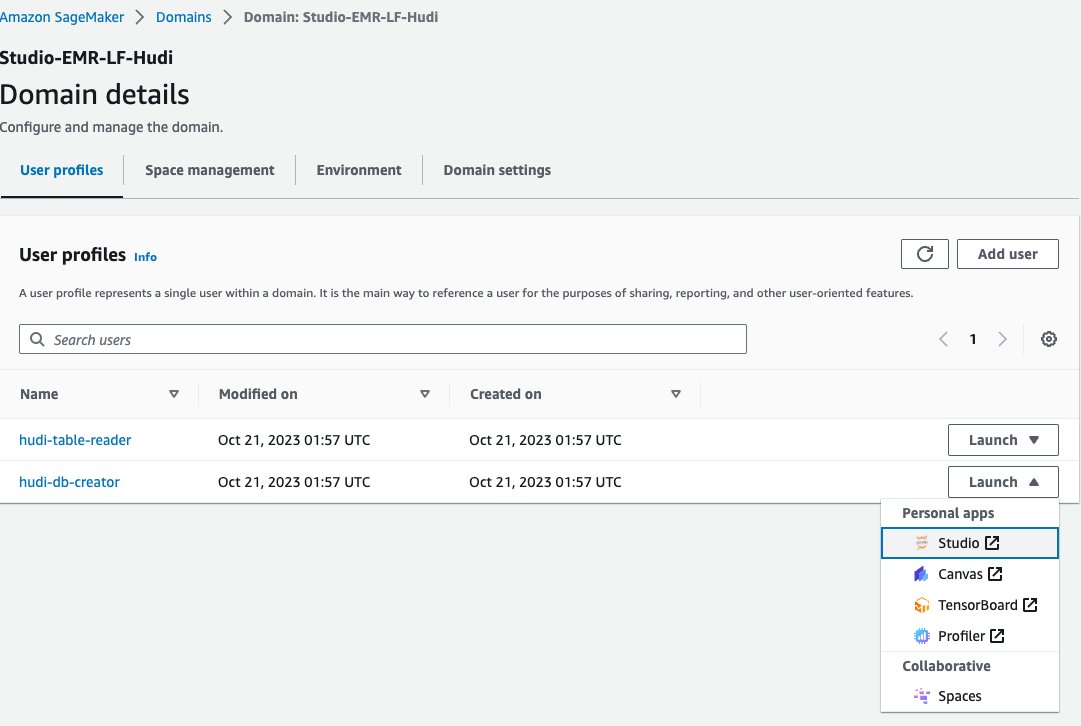
Ahora, usemos un cuaderno Jupyter en SageMaker Studio para conectarnos al clúster de EMR con la función de tiempo de ejecución de EMR del creador de la base de datos:
- En la consola de SageMaker, elija dominios en el panel de navegación.
- Elige el dominio
<STACK-NAME>-Studio-EMR-LF-Hudi. - En Más información menú al lado del perfil de usuario
<STACK-NAME>-hudi-db-creator, escoger creativo.
- Descarga el cuaderno rsv2-hudi-db-creator-cuaderno.
- Elija el icono de carga.
- Elija el cuaderno Jupyter descargado y elija Abierto.
- Abra el cuaderno cargado.
- Imagen, escoger chispamagia.
- Núcleo, escoger PySpark.
- Deje las otras configuraciones por defecto y elija Seleccione.
- Elige Médico para conectarse al clúster EMR.

- Elija el EMR en el clúster EC2 (
<STACK-NAME>-EMR-Cluster) creado con la pila de CloudFormation. - Elige Contacto.
- Rol de ejecución de EMR, escoger
<STACK-NAME>-hudi-db-creator-role. - Elige Contacto.
Crear base de datos y tablas.
Ahora puede seguir los pasos del cuaderno para crear la base de datos y las tablas de Hudi. Los pasos principales son los siguientes:
- Cuando inicie el portátil, configure
“spark.sql.catalog.spark_catalog.lf.managed":"true"para informar a Spark que spark_catalog está protegido por Lake Formation. - Cree tablas Hudi utilizando el siguiente Spark SQL.
- Inserte datos de la tabla de origen en las tablas de Hudi.
- Inserte datos nuevamente en las tablas de Hudi.
Consultar las tablas de Hudi a través de Lake Formation con FGAC
Después de crear la base de datos y las tablas de Hudi, estará listo para consultar las tablas utilizando un control de acceso detallado con Lake Formation. Hemos creado dos tipos de tablas Hudi: Copiar en escritura (COW) y Combinar en lectura (MOR). La tabla COW almacena datos en formato de columnas (Parquet) y cada actualización crea una nueva versión de los archivos durante una escritura. Esto significa que para cada actualización, Hudi reescribe el archivo completo, lo que puede consumir más recursos pero proporciona un rendimiento de lectura más rápido. MOR, por otro lado, se introduce para casos en los que COW puede no ser óptimo, particularmente para cargas de trabajo con muchos cambios o escritura. En una tabla MOR, cada vez que hay una actualización, Hudi escribe solo la fila del registro modificado, lo que reduce el costo y permite escrituras de baja latencia. Sin embargo, el rendimiento de lectura puede ser más lento en comparación con las tablas COW.
Conceder permiso de acceso a la tabla
Usamos el rol IAM<STACK-NAME>-hudi-table-pii-rolepara consultar Hudi COW y MOR que contienen columnas PII. Primero otorgamos permiso de acceso a la mesa a través de Lake Formation:
- En la consola de Lake Formation, elija Permisos del lago de datos bajo Permisos en el panel de navegación.
- Elige Grant.
- Elige
<STACK-NAME>-hudi-table-pii-rolepara Usuarios y roles de IAM. - Elija el
rsv2_blog_hudi_db_1base de datos para Bases de datos. - Mesas, elija las cuatro tablas Hudi que creó en el cuaderno de Jupyter.
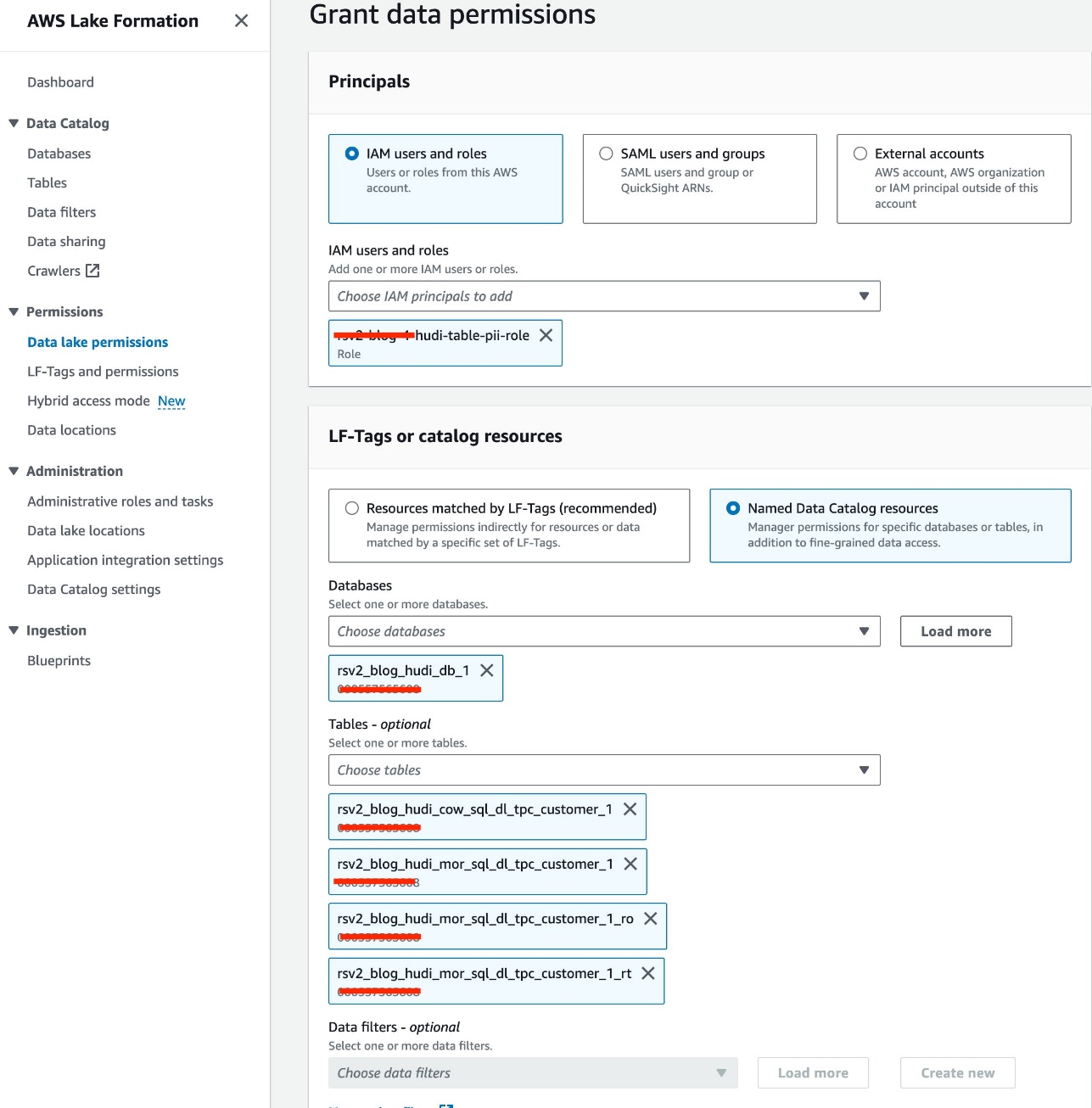
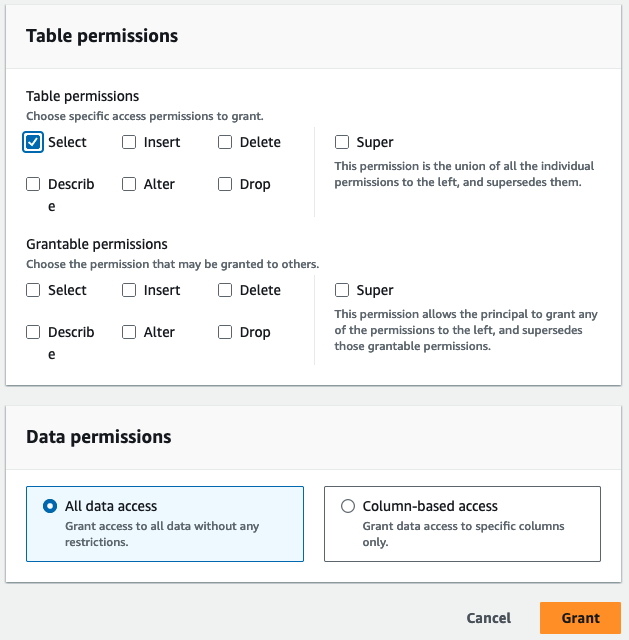
- Permisos de mesa, seleccione Seleccione.
- Elige Grant.
Consultar columnas de PII
Ahora está listo para ejecutar el cuaderno para consultar las tablas de Hudi. Sigamos pasos similares a la sección anterior para ejecutar el cuaderno en SageMaker Studio:
- En la consola de SageMaker, vaya a la
<STACK-NAME>-Studio-EMR-LF-Hudidominio. - En Más información menú al lado del
<STACK-NAME>-hudi-table-readerperfil de usuario, elija creativo. - Sube el cuaderno descargado rsv2-hudi-table-pii-lector-cuaderno.
- Abra el cuaderno cargado.
- Repita los pasos de configuración del notebook y conéctese al mismo clúster EMR, pero use la función
<STACK-NAME>-hudi-table-pii-role.
En la etapa actual, el clúster EMR habilitado para FGAC necesita consultar la columna de tiempo de confirmación de Hudi para realizar consultas incrementales y viajes en el tiempo. No es compatible con la sintaxis de "marca de tiempo a partir" de Spark y Spark.read(). Estamos trabajando activamente para incorporar soporte para ambas acciones en futuras versiones de Amazon EMR con FGAC habilitado.
Ahora puedes seguir los pasos en el cuaderno. A continuación se detallan algunos pasos destacados:
- Ejecute una consulta de instantánea.
- Ejecute una consulta incremental.
- Ejecute una consulta de viaje en el tiempo.
- Ejecute consultas de tablas MOR optimizadas para lectura y en tiempo real.
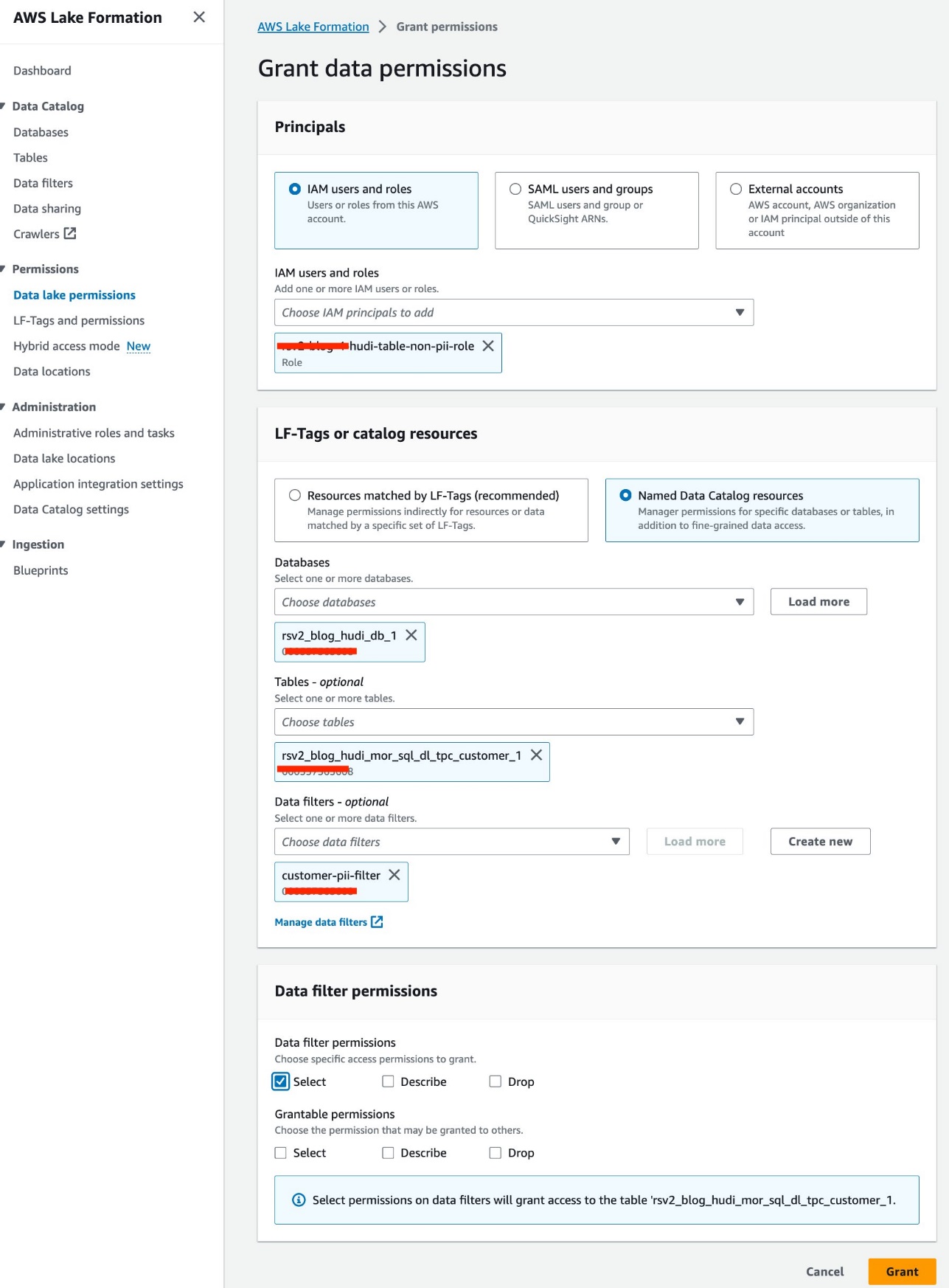
Consulta las tablas de Hudi con filtros de datos a nivel de columna y de fila
Usamos el rol IAM<STACK-NAME>-hudi-table-non-pii-rolepara consultar tablas de Hudi. Esta función no puede consultar ninguna columna que contenga PII. Usamos los filtros de datos a nivel de columna y a nivel de fila de Lake Formation para implementar un control de acceso detallado:
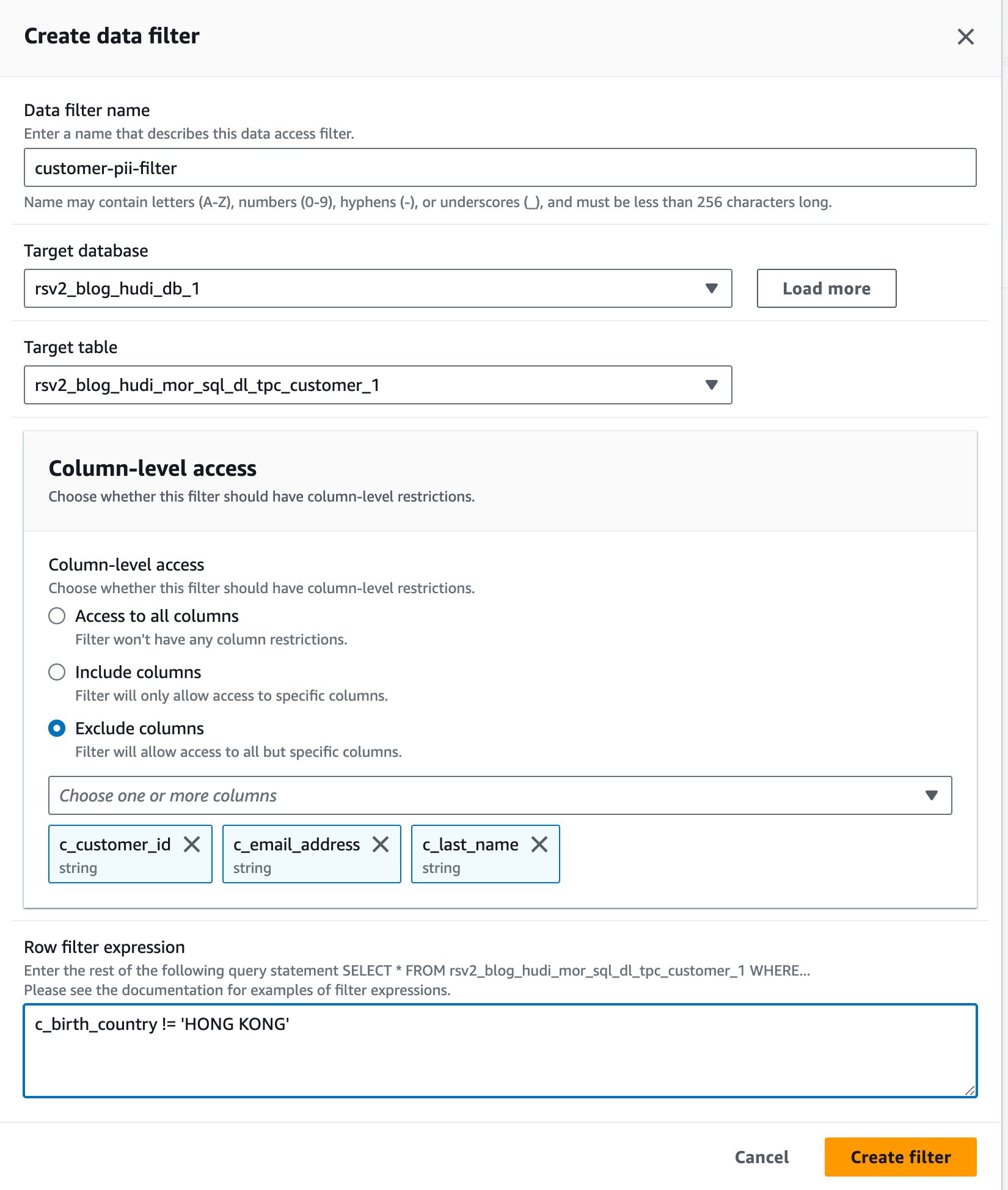
- En la consola de Lake Formation, elija Filtros de datos bajo Catálogo de datos en el panel de navegación.
- Elige Crear nuevo filtro.
- Nombre del filtro de datos, introduzca
customer-pii-filter. - Elige
rsv2_blog_hudi_db_1para Base de datos de destino. - Elige
rsv2_blog_hudi_mor_sql_dl_customer_1para Tabla de destino. - Seleccione Excluir columnas Y elige la
c_customer_id,c_email_addressyc_last_namecolumnas - Participar
c_birth_country != 'HONG KONG'para Expresión de filtro de fila. - Elige Crear filtro.
- Elige Permisos del lago de datos bajo Permisos en el panel de navegación.
- Elige Grant.
- Elige
<STACK-NAME>-hudi-table-non-pii-rolepara Usuarios y roles de IAM. - Elige
rsv2_blog_hudi_db_1para Bases de datos. - Elige
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1para Mesas. - Elige
customer-pii-filterpara Filtros de datos. - Permisos de filtro de datos, seleccione Seleccione.
- Elige Grant.
Sigamos pasos similares para ejecutar el cuaderno en SageMaker Studio:
- En la consola de SageMaker, navegue hasta el dominio.
Studio-EMR-LF-Hudi. - En Más información menú para el
hudi-table-readerperfil de usuario, elija creativo. - Sube el cuaderno descargado Cuaderno-lector-rsv2-hudi-table-non-pii y elige Abierto.
- Repita los pasos de configuración del portátil y conéctese al mismo clúster de EMR, pero seleccione la función
<STACK-NAME>-hudi-table-non-pii-role.
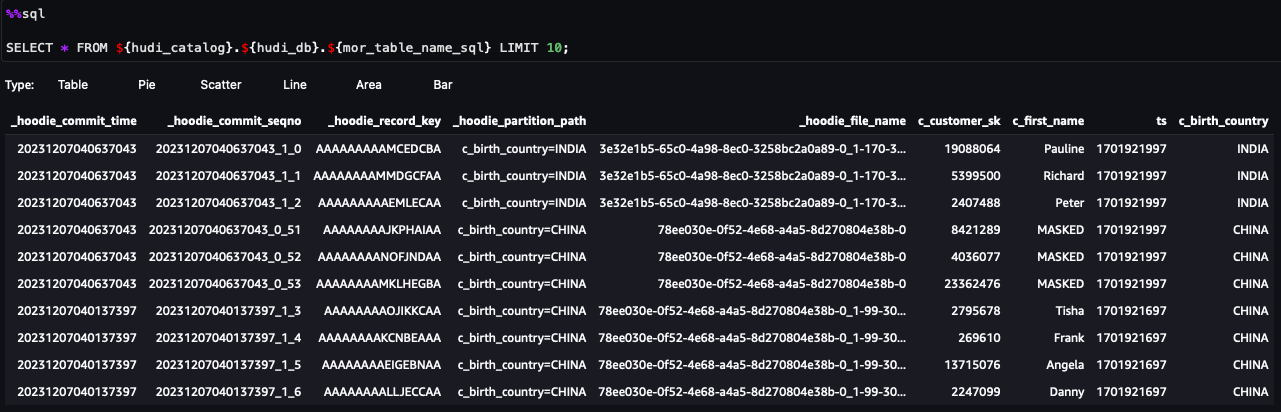
Ahora puedes seguir los pasos en el cuaderno. En los resultados de la consulta, puede ver que se ha aplicado FGAC a través del filtro de datos de Lake Formation. El rol no puede ver las columnas de PIIc_customer_id,c_last_nameyc_email_address. Además, las filas deHONG KONGhan sido filtrados.
Limpiar
Una vez que haya terminado de experimentar con la solución, le recomendamos limpiar los recursos con los siguientes pasos para evitar costos inesperados:
- Cierre las aplicaciones de SageMaker Studio para los perfiles de usuario.
El clúster de EMR se eliminará automáticamente después del valor de tiempo de espera inactivo.
- Eliminar el Sistema de archivos elástico de Amazon (Amazon EFS) volumen creado para el dominio.
- Vaciar los cubos S3 creado por la pila de CloudFormation.
- En la consola de AWS CloudFormation, elimine la pila.
Conclusión
En esta publicación, utilizamos Apachi Hudi, un tipo de tablas OTF, para demostrar esta nueva característica para aplicar un control de acceso detallado en Amazon EMR. Puede definir permisos granulares en Lake Formation para tablas OTF y aplicarlos mediante consultas Spark SQL en clústeres de EMR. También puede utilizar funciones de lago de datos transaccionales, como ejecutar consultas instantáneas, consultas incrementales, viajes en el tiempo y consultas DML. Tenga en cuenta que esta nueva característica cubre todas las tablas OTF.
Esta característica se lanza a partir de la versión 6.15 de Amazon EMR en total. Regiones donde Amazon EMR está disponible. Con la integración de Amazon EMR con Lake Formation, puede administrar y procesar big data con confianza, desbloqueando conocimientos y facilitando la toma de decisiones informadas mientras mantiene la seguridad y la gobernanza de los datos.
Para obtener más información, consulte Habilite la formación de lagos con Amazon EMR y no dude en ponerse en contacto con sus arquitectos de soluciones de AWS, quienes pueden ayudarlo en su viaje de datos.
Sobre la autora
 Raimundo Lai es un arquitecto de soluciones senior que se especializa en atender las necesidades de clientes de grandes empresas. Su experiencia radica en ayudar a los clientes a migrar sistemas empresariales y bases de datos complejos a AWS y construir plataformas de lagos de datos y almacenamiento de datos empresariales. Raymond se destaca en la identificación y el diseño de soluciones para casos de uso de IA/ML, y se centra particularmente en las soluciones sin servidor de AWS y el diseño de arquitectura basada en eventos.
Raimundo Lai es un arquitecto de soluciones senior que se especializa en atender las necesidades de clientes de grandes empresas. Su experiencia radica en ayudar a los clientes a migrar sistemas empresariales y bases de datos complejos a AWS y construir plataformas de lagos de datos y almacenamiento de datos empresariales. Raymond se destaca en la identificación y el diseño de soluciones para casos de uso de IA/ML, y se centra particularmente en las soluciones sin servidor de AWS y el diseño de arquitectura basada en eventos.
 Bin Wang, PhD, es arquitecto sénior de soluciones analíticas especialistas en AWS y cuenta con más de 12 años de experiencia en la industria del aprendizaje automático, con un enfoque particular en la publicidad. Posee experiencia en procesamiento de lenguaje natural (NLP), sistemas de recomendación, diversos algoritmos de ML y operaciones de ML. Le apasiona profundamente aplicar técnicas de ML/DL y big data para resolver problemas del mundo real.
Bin Wang, PhD, es arquitecto sénior de soluciones analíticas especialistas en AWS y cuenta con más de 12 años de experiencia en la industria del aprendizaje automático, con un enfoque particular en la publicidad. Posee experiencia en procesamiento de lenguaje natural (NLP), sistemas de recomendación, diversos algoritmos de ML y operaciones de ML. Le apasiona profundamente aplicar técnicas de ML/DL y big data para resolver problemas del mundo real.
 Aditya Shah es ingeniero de desarrollo de software en AWS. Está interesado en bases de datos y motores de almacenamiento de datos y ha trabajado en optimizaciones de rendimiento, cumplimiento de seguridad y cumplimiento de ACID para motores como Apache Hive y Apache Spark.
Aditya Shah es ingeniero de desarrollo de software en AWS. Está interesado en bases de datos y motores de almacenamiento de datos y ha trabajado en optimizaciones de rendimiento, cumplimiento de seguridad y cumplimiento de ACID para motores como Apache Hive y Apache Spark.
 Melodía yang es arquitecto sénior de soluciones de Big Data para Amazon EMR en AWS. Es una líder analítica experimentada que trabaja con clientes de AWS para brindar orientación sobre las mejores prácticas y asesoramiento técnico a fin de ayudarlos a tener éxito en la transformación de datos. Sus áreas de interés son los marcos de código abierto y la automatización, la ingeniería de datos y DataOps.
Melodía yang es arquitecto sénior de soluciones de Big Data para Amazon EMR en AWS. Es una líder analítica experimentada que trabaja con clientes de AWS para brindar orientación sobre las mejores prácticas y asesoramiento técnico a fin de ayudarlos a tener éxito en la transformación de datos. Sus áreas de interés son los marcos de código abierto y la automatización, la ingeniería de datos y DataOps.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Nuestra Empresa
- de la máquina
- Mi Cuenta
- reconocer
- acciones
- activamente
- adicional
- Adicionalmente
- direcciones
- Admin
- administradores
- Publicidad
- consejos
- Después
- de nuevo
- AI / ML
- algoritmos
- Todos
- permitir
- permitido
- permite
- junto al
- también
- Amazon
- Amazon EC2
- EMR de Amazon
- Amazon Web Services
- an
- análisis
- Analistas
- Analítico
- Analytics
- el análisis de
- y
- cualquier
- APACHE
- Apache Spark
- Aplicación
- aplicada
- Aplicá
- La aplicación de
- arquitectos
- arquitectura
- somos
- áreas
- en torno a
- AS
- ayudar
- Ayuda
- ayudando
- asumir
- At
- auditoría
- autoridad
- autorizado
- automáticamente
- Automatización
- Hoy Disponibles
- evitar
- AWS
- Nube de AWS9
- Formación en la nube de AWS
- Formación del lago AWS
- Atrás
- basado
- BE
- esto
- detrás de
- "Ser"
- beneficios
- además de
- MEJOR
- Big
- Big Data
- Blogs
- jactancia
- ambas
- build
- pero
- by
- CA
- PUEDEN
- capaz
- llevar
- .
- case
- cases
- catalogar
- abastecimiento
- a ciertos
- certificado
- certificados
- de Padi
- el cambio
- cambiado
- Cambios
- China
- Elige
- Limpieza
- Cloud9
- Médico
- código
- Columna
- Columnas
- COM
- combinación
- hacer
- Empresas
- en comparación con
- completar
- compliance
- componente
- componentes
- Calcular
- computadora
- concepto
- condiciones
- Conducir
- con confianza
- Configuración
- Contacto
- Consola
- construcción
- contacte
- que no contengo
- contiene
- control
- controlado
- controles
- proceso de copiar
- Correspondiente
- Cost
- Precio
- país
- cubre suministros para
- Para crear
- creado
- crea
- Creamos
- creador
- Current
- personalizado
- Clientes
- datos
- acceso a los datos
- análisis de los datos
- Lago de datos
- Plataforma de datos
- privacidad de datos
- proceso de datos
- seguridad de datos
- almacenamiento de datos
- Base de datos
- bases de datos
- Toma de Decisiones
- profundamente
- Predeterminado
- definir
- Delta
- demostrar
- vas demostrando
- desplegar
- despliegue
- Diseño
- diseño
- detalles
- Desarrollo
- una experiencia diferente
- distinto
- diverso
- dns
- do
- sí
- No
- dominio
- hecho
- No
- DE INSCRIPCIÓN
- descargar
- impulsados
- durante
- cada una
- más
- habilitar
- facilita
- permite
- cifrado
- final
- criterios de valoración
- hacer cumplir
- Motor
- ingeniero
- Ingeniería
- motores
- garantizar
- asegura
- asegurando que
- Participar
- Empresa
- clientes empresariales
- Todo
- Entorno
- Éter (ETH)
- Evento
- Cada
- ejemplo
- ejecución
- existe
- experience
- experimentado
- Experiencia
- exploración
- Se extiende
- externo
- facilitando
- más rápida
- Feature
- Caracteristicas
- sentir
- Archive
- archivos
- filtrar
- filtración
- filtros
- Nombre
- Focus
- se centra
- seguir
- siguiendo
- siguiente
- formato
- formación
- Digital XNUMXk
- Marco conceptual
- marcos
- Gratuito
- Desde
- Cumplir
- ser completados
- a la fatiga
- promover
- futuras
- Obtén
- generado
- gobierno
- gobernado
- conceder
- muy
- Grupo procesos
- Grupo
- guía
- mano
- Tienen
- he
- aquí
- esta página
- Destacado
- su
- histórico
- historia
- Colmena
- Hong
- 香港
- Hogar
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- AMI
- ICON
- ID
- idea
- Identifique
- identificar
- Idle
- if
- ilustra
- implementar
- mejorar
- in
- incluye
- Incluye
- incorporando
- incrementales
- India
- energético
- informar
- información
- informó
- Las opciones de entrada
- Insights
- COMPLETAMENTE
- Integración
- integración
- interactivo
- interesado
- intereses
- Interfaz
- interno
- dentro
- intrincado
- Introducido
- Presenta
- IT
- SUS
- Trabajos
- Empleo
- jpg
- Cuaderno Jupyter
- Clave
- Kong
- lago
- idioma
- large
- Apellido
- lanzamiento
- lanzado
- líder
- APRENDE:
- se encuentra
- como
- LIMITE LAS
- líneas
- local
- Ubicación
- encontrar una oficina
- Inicie sesión
- gran
- para lograr
- gestionan
- gestionado
- Management
- gerente
- muchos
- Puede..
- significa
- los mecanismos de
- reunión
- Menú
- metadatos
- podría
- migrar
- minutos
- ML
- Algoritmos ML
- modificado
- más,
- movimiento
- nombre
- nombres
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- Navegar
- Navegación
- ¿ Necesita ayuda
- Nuevo
- nueva función
- recién
- Next
- nlp
- nodo
- nota
- cuaderno
- ordenadores portátiles
- ahora
- objetos
- of
- a menudo
- on
- ONE
- , solamente
- habiertos
- de código abierto
- openssl
- Operaciones
- óptimo
- Optimización
- Optión
- Opciones
- or
- solicite
- organización
- Otro
- salir
- Más de
- par
- cristal
- particular
- particularmente
- apasionado
- pago
- actuación
- realizar
- permiso
- permisos
- Personalmente
- Doctor en Filosofía
- pii
- marcador de posición
- plataforma
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- más
- puntos
- Popular
- posee
- Publicación
- conservación
- anterior
- primario
- política de privacidad
- privilegio
- privilegios
- problemas
- tratamiento
- Producción
- Mi Perfil
- Perfiles
- prueba
- prueba de concepto
- protegido
- Protección
- proporcionar
- proporciona un
- proporcionando
- público
- fines
- consultas
- Leer
- Reading
- ready
- mundo real
- en tiempo real
- recomiendan
- grabar
- recuperación
- reduce
- la reducción de
- remitir
- se refiere
- refleja
- región
- registrarte
- registrado
- reglamentos
- ,
- Estrenos
- reemplazar
- Requisitos
- Requisitos
- Recurso
- muchos recursos
- Recursos
- resultado
- Resultados
- derechos
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- FILA
- rsa
- reglas
- Ejecutar
- correr
- sabio
- mismo
- Guardar
- Sección
- seguro
- asegurado
- EN LINEA
- ver
- EL EQUIPO
- selecciona
- mayor
- sensible
- servidor
- Sin servidor
- Servicios
- Sesión
- set
- Sets
- ajustes
- Configure
- ella
- firmar
- significativamente
- similares
- sencillos
- simplifica
- simplificar
- desde
- Instantánea
- So
- Software
- Desarrollo de software ad-hoc
- a medida
- Soluciones
- RESOLVER
- algo
- Fuente
- Spark
- especialista
- se especializa
- SQL
- montón
- Etapa
- comienzo
- fundó
- Comience a
- declaraciones
- pasos
- STORAGE
- tiendas
- Estrategia
- Cordón
- estudio
- enviar
- subredes
- comercial
- tal
- RESUMEN
- SOPORTE
- soportes
- seguro
- sintaxis
- Todas las funciones a su disposición
- mesa
- ETIQUETA
- toma
- Técnico
- técnicas
- plantilla
- terminal
- esa
- El
- La Fuente
- su
- Les
- luego
- Ahí.
- Estas
- ellos
- así
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- el tiempo de viaje
- calendario
- a
- Seguimiento
- transaccional
- transaccional
- tránsito
- viajes
- verdadero
- de confianza
- Ts
- dos
- tipo
- tipos
- ui
- bajo
- Inesperado
- desconocido
- desbloqueo
- Actualizar
- actualizado
- defensa
- subido
- URI
- utilizan el
- caso de uso
- usado
- Usuario
- usuarios
- usando
- valida
- propuesta de
- diversos
- versión
- vía
- la visibilidad
- volumen
- Manejo de
- Almacenamiento
- we
- web
- servicios web
- cuando
- mientras
- que
- mientras
- QUIENES
- seguirá
- dentro de
- trabajado
- trabajando
- escribir
- años
- Usted
- tú
- zephyrnet
- cero
- Zip