In 2021 und 2020, wir haben Ihnen von den neuen Funktionen in erzählt Amazon RedShift die es einfacher, schneller und kostengünstiger machen, alle Ihre Daten zu analysieren und umfassende und aussagekräftige Erkenntnisse zu gewinnen. Im Jahr 2022 freuen wir uns, Ihnen mitteilen zu können, dass das Amazon Redshift-Team hart gearbeitet hat. Wir haben von den Kundenanforderungen rückwärts gearbeitet und mehrere neue Funktionen angekündigt, um die Analyse all Ihrer Daten einfacher, schneller und kostengünstiger zu machen. Dieser Beitrag behandelt einige dieser neuen Funktionen.
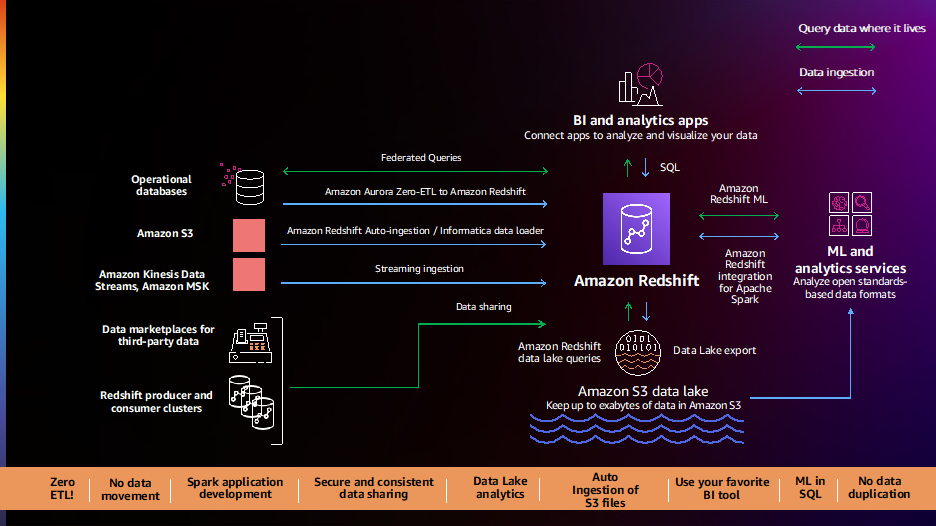
Bei AWS besteht unsere Strategie für Daten und Analysen darin, Ihnen eine Moderne Datenarchitektur das hilft Ihnen, sich von Datensilos zu befreien; über speziell entwickelte Daten, Analysen, maschinelles Lernen (ML) und künstliche Intelligenz verfügen, um das richtige Tool für den richtigen Job zu verwenden; und verfügen über offene, kontrollierte, sichere und vollständig verwaltete Dienste, um Analysen für alle verfügbar zu machen. Innerhalb der modernen Datenarchitektur von AWS bleibt Amazon Redshift als Cloud Data Warehouse eine Schlüsselkomponente, die es Ihnen ermöglicht, komplexe SQL-Analysen in großem Umfang und mit hoher Leistung auf Terabyte bis Petabyte an strukturierten und unstrukturierten Daten auszuführen und die Erkenntnisse über beliebte Business Intelligence ( BI) und Analysetools. Wir arbeiten weiterhin von den Kundenanforderungen rückwärts und haben 2022 über 40 Funktionen in Amazon Redshift eingeführt, um Kunden bei ihren wichtigsten Data-Warehousing-Anwendungsfällen zu unterstützen, darunter:
- Self-Service-Analysen
- Einfache Datenaufnahme
- Datenaustausch und Zusammenarbeit
- Datenwissenschaft und maschinelles Lernen
- Sichere und zuverlässige Analytik
- Analyse der besten Preisleistung
Lassen Sie uns tiefer eintauchen und die neuen Amazon Redshift-Funktionen in diesen Bereichen besprechen.
Self-Service-Analysen
Kunden sagen uns immer wieder, dass Daten und Analysen allgegenwärtig werden und jeder in ihrem Unternehmen Analysen benötigt. Wir haben angekündigt Amazon Redshift ohne Server (in der Vorschau) im Jahr 2021, um Analysen in Sekundenschnelle auszuführen und zu skalieren, ohne eine Data-Warehouse-Infrastruktur bereitstellen und verwalten zu müssen. Im Juli 2022 gaben wir die bekannt allgemeine Verfügbarkeit von Redshift Serverless, und seitdem haben Tausende von Kunden, darunter Peloton, Broadridge Financials und NextGen Healthcare, es verwendet, um ihre Daten schnell und einfach zu analysieren. Amazon Redshift Serverless stellt die Data Warehouse-Kapazität automatisch bereit und skaliert sie intelligent, um eine hohe Leistung für alle Ihre Analysen bereitzustellen, und Sie zahlen nur für die Rechenleistung, die für die Dauer der Workloads auf Sekundenbasis verwendet wird. Seit GA haben wir Funktionen wie hinzugefügt Ressourcen-Tagging, vereinfachte Überwachung und Verfügbarkeit in zusätzlichen AWS-Regionen, um die Abrechnung weiter zu vereinfachen und die Reichweite auf mehr Regionen weltweit auszudehnen.
Im Jahr 2021 haben wir Amazon Redshift Query Editor V2 eingeführt, ein kostenloses webbasiertes Tool für Datenanalysten, Data Scientists und Entwickler, um Daten in Amazon Redshift Data Warehouses und Data Lakes zu untersuchen, zu analysieren und gemeinsam daran zu arbeiten. Im Jahr 2022 erhielt der Abfrageeditor V2 zusätzliche Verbesserungen wie z Notebook-Unterstützung für eine verbesserte Zusammenarbeit beim Verfassen, Organisieren und Kommentieren von Abfragen; Benutzerzugriff durch Anmeldedaten des Identitätsanbieters (IdP). für Single-Sign-On; und die Möglichkeit, mehrere Abfragen gleichzeitig auszuführen, um die Entwicklerproduktivität zu verbessern.
Autonomics ist ein weiterer Bereich, in dem wir aktiv daran arbeiten, ML-basierte Optimierungen einzusetzen und Kunden ein selbstlernendes und selbstoptimierendes Data Warehouse bereitzustellen. Im Jahr 2022 haben wir die allgemeine Verfügbarkeit von angekündigt Automatisierte materialisierte Ansichten (AutoMVs) zur Verbesserung der Leistung von Abfragen (Reduzierung der Gesamtlaufzeit) ohne Benutzeraufwand durch automatisches Erstellen und Verwalten materialisierter Ansichten. AutoMVs in Kombination mit automatischer Aktualisierung, inkrementeller Aktualisierung und automatischer Umschreibung von Abfragen für materialisierte Ansichten machten materialisierte Ansichten wartungsfrei und bieten Ihnen automatisch eine schnellere Leistung. zusätzlich automatische Tabellenoptimierung (ATO)-Fähigkeit zur Schemaoptimierung und automatisches Workload-Management (Auto-WLM)-Funktion zur Workload-Optimierung wurde weiter verbessert, um die Abfrageleistung zu verbessern.
Einfache Datenaufnahme
Kunden teilen uns mit, dass ihre Daten über mehrere Datenquellen wie Transaktionsdatenbanken, Data Warehouses, Data Lakes und Big-Data-Systeme verteilt sind. Sie wollen die Flexibilität, diese Daten mit No-Code/Low-Code-, Zero-ETL-Datenpipelines zu integrieren oder diese Daten vor Ort zu analysieren, ohne sie zu verschieben. Kunden berichten uns, dass ihre aktuellen Datenpipelines komplex, manuell, unflexibel und langsam sind, was zu unvollständigen, inkonsistenten und veralteten Ansichten der Daten führt und die Einblicke einschränkt. Kunden haben uns nach einem besseren Weg in die Zukunft gefragt, und wir freuen uns, eine Reihe neuer Funktionen zur Vereinfachung und Automatisierung von Datenpipelines ankündigen zu können.
Amazon Aurora Zero-ETL-Integration mit Amazon Redshift (Vorschau) ermöglicht es Ihnen, Analysen und ML nahezu in Echtzeit auf Petabytes von Transaktionsdaten auszuführen. Es bietet eine No-Code-Lösung zum Erstellen von Transaktionsdaten aus mehreren Amazonas-Aurora Datenbanken, die innerhalb von Sekunden nach dem Schreiben in Aurora in Amazon Redshift Data Warehouses verfügbar sind, sodass keine komplexen Datenpipelines erstellt und gewartet werden müssen. Mit dieser Funktion können Aurora-Kunden auch auf Amazon Redshift-Funktionen wie komplexe SQL-Analysen, integriertes ML, Datenfreigabe und föderierten Zugriff auf mehrere Datenspeicher und Data Lakes zugreifen. Diese Funktion ist jetzt in der Vorschau für verfügbar Amazon Aurora MySQL-kompatible Edition Version 3 (mit MySQL 8.0-Kompatibilität) und Sie können Zugriff auf die Vorschau anfordern.
Amazon Redshift wird jetzt unterstützt Automatisches Kopieren von Amazon S3 (Vorschau), um das Laden von Daten zu vereinfachen Amazon Simple Storage-Service (Amazon S3) in Amazon Redshift. Sie können jetzt kontinuierliche Dateiaufnahmeregeln (Kopieraufträge) einrichten, um Ihre Amazon S3-Pfade zu verfolgen und automatisch neue Dateien zu laden, ohne dass zusätzliche Tools oder benutzerdefinierte Lösungen erforderlich sind. Kopieraufträge können über Systemtabellen überwacht werden, und sie verfolgen automatisch zuvor geladene Dateien und schließen sie vom Aufnahmeprozess aus, um eine Datenduplizierung zu verhindern. Diese Funktion ist jetzt in der Vorschau verfügbar; Sie können diese Funktion ausprobieren, indem Sie mithilfe der Vorschauspur einen neuen Cluster erstellen.
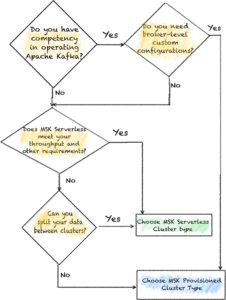
Kunden teilen uns immer wieder mit, dass sie sofortige Echtzeitanalysen benötigen, und wir freuen uns, dies ankündigen zu können allgemeine Verfügbarkeit von Unterstützung für die Aufnahme von Streaming in Amazon Redshift für Amazon Kinesis-Datenströme und Amazon Managed Streaming für Apache Kafka (Amazon MSK). Diese Funktion eliminiert die Notwendigkeit, Streaming-Daten in Amazon S3 bereitzustellen, bevor sie in Amazon Redshift aufgenommen werden, sodass Sie eine geringe Latenz erreichen können, die in Sekunden gemessen wird, während Sie Hunderte von Megabyte an Streaming-Daten pro Sekunde in Ihre Data Warehouses aufnehmen. Sie können SQL innerhalb von Amazon Redshift verwenden, um eine Verbindung zu mehreren Kinesis-Datenströmen oder MSK-Themen herzustellen und Daten aus diesen direkt aufzunehmen, automatisch aktualisierende materialisierte Streaming-Ansichten mit Transformationen über den Streams zu erstellen, um direkt auf Streaming-Daten zuzugreifen, und Echtzeitdaten mit historischen Daten zu kombinieren Daten für bessere Einblicke. Beispielsweise hat Adobe die Amazon Redshift-Streaming-Erfassung als Teil seiner Adobe Experience Platform integriert, um in Echtzeit den Web- und Anwendungs-Clickstream und Sitzungsdaten für verschiedene Anwendungen wie CRM- und Kundensupport-Anwendungen zu erfassen und zu analysieren.
Kunden haben uns mitgeteilt, dass sie eine einfache, sofort einsatzbereite Integration zwischen Amazon Redshift, BI- und ETL-Tools (Extrahieren, Transformieren und Laden) und Geschäftsanwendungen wie Salesforce und Marketo wünschen. Wir freuen uns, die allgemeine Verfügbarkeit von bekannt zu geben Informatica Data Loader für Amazon Redshift, mit dem Sie Informatica Data Loader kostenlos für das Hochgeschwindigkeits- und Hochvolumen-Laden von Daten in Amazon Redshift verwenden können. Sie können einfach die Option Informatica Data Loader in der Amazon Redshift-Konsole auswählen. Sobald Sie in Informatica Data Loader sind, können Sie eine Verbindung zu Quellen wie Salesforce oder Marketo herstellen, Amazon Redshift als Ziel auswählen und mit dem Laden Ihrer Daten beginnen.
Datenaustausch und Zusammenarbeit
Kunden teilen uns immer wieder mit, dass sie alle ihre Erst- und Drittanbieterdaten analysieren und die umfassenden datengesteuerten Erkenntnisse ihren Kunden, Partnern und Lieferanten zur Verfügung stellen möchten. Wir haben 2021 neue Funktionen eingeführt, wie z Datenübertragung und AWS Data Exchange-Integration, um es Ihnen zu erleichtern, alle Ihre Daten zu analysieren und sie innerhalb und außerhalb Ihrer Organisationen zu teilen.
Ein großartiges Beispiel für einen Kunden, der Datenaustausch nutzt, ist Orion. Orion bietet Echtzeit-Data-as-a-Service (DaaS)-Lösungen für Kunden in der Finanzdienstleistungsbranche, wie z. B. Vermögensverwaltungs-, Vermögensverwaltungs- und Anlageverwaltungsanbieter. Sie verfügen über mehr als 2,500 Datenquellen, bei denen es sich hauptsächlich um SQL Server-Datenbanken handelt, die sich sowohl vor Ort als auch in AWS befinden. Daten werden mithilfe von Kafka-Connectors in Amazon Redshift gestreamt. Sie haben einen Producer-Cluster, der all diese Daten empfängt und dann Data Sharing verwendet, um Daten in Echtzeit für die Zusammenarbeit freizugeben. Dies ist eine Multi-Tenant-Architektur, die mehrere Clients bedient. Angesichts der Sensibilität ihrer Daten ist die gemeinsame Nutzung von Daten eine Möglichkeit, die Arbeitslast zwischen Clustern zu isolieren und diese Daten auch sicher für Endbenutzer freizugeben.
Im Jahr 2022 haben wir weiter in diesen Bereich investiert, um die Leistung, Governance und Entwicklerproduktivität mit neuen Funktionen zu verbessern, um die gemeinsame Nutzung und Zusammenarbeit an Daten einfacher, einfacher und schneller zu machen.
Da Kunden umfangreiche Konfigurationen für die gemeinsame Nutzung von Daten erstellen, haben sie nach vereinfachter Governance und Sicherheit für gemeinsam genutzte Daten gefragt, und wir fügen hinzu zentralisierte Zugriffskontrolle mit AWS Lake Formation für Amazon Redshift Datashares, um die gemeinsame Nutzung von Live-Daten über mehrere Amazon Redshift Data Warehouses hinweg zu ermöglichen. Mit dieser Funktion unterstützt Amazon Redshift jetzt eine vereinfachte Verwaltung von Amazon Redshift-Datenfreigaben durch die Verwendung von AWS Lake-Formation als zentrales Fenster zur zentralen Verwaltung von Daten oder Berechtigungen für Datashares. Sie können Berechtigungen anzeigen, ändern und prüfen, einschließlich der Sicherheit auf Zeilen- und Spaltenebene für die Tabellen und Ansichten in den Amazon Redshift-Datashares, indem Sie Lake Formation-APIs und die verwenden AWS-Managementkonsoleund ermöglichen, dass die Amazon Redshift-Datashares von anderen Amazon Redshift-Data Warehouses erkannt und genutzt werden.
Datenwissenschaft und maschinelles Lernen
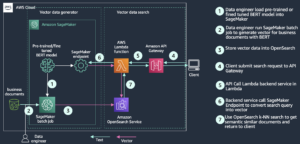
Kunden teilen uns immer wieder mit, dass sie möchten, dass ihre Daten- und Analysesysteme ihnen helfen, eine Vielzahl von Fragen zu beantworten, von den Vorgängen in ihrem Unternehmen (deskriptive Analytik) bis hin zu den Gründen dafür (diagnostische Analytik) und was in Zukunft passieren wird (prädiktive Analytik). Amazon Redshift bietet Funktionen wie komplexe SQL-Analysen, Data Lake-Analysen und Amazon Redshift ML für Kunden, ihre Daten zu analysieren und aussagekräftige Erkenntnisse zu gewinnen. Rotverschiebung ML integriert Amazon Redshift mit Amazon Sage Maker, ein vollständig verwalteter ML-Dienst, mit dem Sie ML-Modelle mit vertrauten SQL-Befehlen erstellen, trainieren und bereitstellen können.
Kunden haben uns auch um eine bessere Integration zwischen Amazon Redshift und Apache Spark gebeten, daher freuen wir uns, dies ankündigen zu können Amazon Redshift-Integration für Apache Spark um Data Warehouses für Spark-basierte Anwendungen leicht zugänglich zu machen. Jetzt können Entwickler, die AWS-Analyse- und ML-Dienste wie z Amazon EMR, AWS-Kleber, und SageMaker kann mühelos Apache Spark-Anwendungen erstellen, die aus ihren Amazon Redshift Data Warehouses lesen und in sie schreiben. Amazon EMR und AWS Glue verpacken den Redshift-Spark-Konnektor, sodass Sie von Ihren Spark-basierten Anwendungen aus problemlos eine Verbindung zu Ihrem Data Warehouse herstellen können. Sie können mehrere Pushdown-Funktionen für Vorgänge wie Sortieren, Aggregieren, Begrenzen, Verbinden und Skalarfunktionen verwenden, sodass nur die relevanten Daten aus Ihrem Amazon Redshift-Data Warehouse in die verbrauchende Spark-Anwendung verschoben werden. Sie können Ihre Anwendungen auch sicherer machen, indem Sie sie verwenden AWS Identity and Access Management and (IAM)-Anmeldeinformationen zum Herstellen einer Verbindung mit Amazon Redshift.
Sichere und zuverlässige Analytik
Kunden sagen uns immer wieder, dass ihre Data Warehouses unternehmenskritische Systeme sind, die hohe Verfügbarkeit, Zuverlässigkeit und Sicherheit benötigen. In diesem Bereich haben wir 2022 eine Reihe neuer Funktionen eingeführt.
Amazon Redshift wird jetzt unterstützt Multi-AZ-Bereitstellungen (in der Vorschau) für instanzbasierte RA3-Cluster, die es ermöglichen, Ihr Data Warehouse in mehreren AWS-Availability Zones gleichzeitig auszuführen und den kontinuierlichen Betrieb in unvorhergesehenen Ausfallszenarien in der gesamten Availability Zone zu ermöglichen. Multi-AZ-Unterstützung ist bereits für Redshift Serverless verfügbar. Eine Amazon Redshift Multi-AZ-Bereitstellung ermöglicht Ihnen die Wiederherstellung im Falle eines Ausfalls der Availability Zone ohne Benutzereingriff. Auf ein Amazon Redshift Multi-AZ Data Warehouse wird als einzelnes Data Warehouse mit einem Endpunkt zugegriffen und hilft Ihnen, die Leistung zu maximieren, indem die Workload-Verarbeitung automatisch auf mehrere Availability Zones verteilt wird. Es sind keine Anwendungsänderungen erforderlich, um die Geschäftskontinuität bei unvorhergesehenen Ausfällen aufrechtzuerhalten.
Im Jahr 2022 haben wir Funktionen wie rollenbasierte Zugriffskontrolle, Sicherheit auf Zeilenebene und Datenmaskierung (in der Vorschau) eingeführt, um Ihnen die Zugriffsverwaltung zu erleichtern und zu entscheiden, wer Zugriff auf welche Daten hat, einschließlich der Verschleierung personenbezogener Daten (PII ) wie Kreditkartennummern.
Sie können verwenden rollenbasierte Zugriffskontrolle (RBAC) Kontrolle des Endbenutzerzugriffs auf Daten auf breiter oder granularer Ebene basierend auf der beruflichen Rolle und den Berechtigungen eines Endbenutzers. Mit RBAC können Sie eine Rolle mit SQL erstellen, der Rolle eine Sammlung detaillierter Berechtigungen erteilen und diese Rolle dann Endbenutzern zuweisen. Rollen können Berechtigungen auf Objektebene, Spaltenebene und Systemebene erteilt werden. Darüber hinaus führt RBAC vorkonfigurierte Systemrollen für DBAs, Operatoren, Sicherheitsadministratoren oder benutzerdefinierte Rollen ein.
Sicherheit auf Zeilenebene (RLS) vereinfacht das Design und die Implementierung eines differenzierten Zugriffs auf die Zeilen in Tabellen. Mit RLS können Sie den Zugriff auf eine Teilmenge von Zeilen innerhalb einer Tabelle basierend auf der Jobrolle oder den Berechtigungen der Benutzer mit SQL einschränken.
Amazon Redshift-Unterstützung für Dynamische Datenmaskierung (DDM), das jetzt in der Vorschauversion verfügbar ist, ermöglicht es Ihnen, den Schutz personenbezogener Daten wie Sozialversicherungsnummern, Kreditkartennummern und Telefonnummern in Ihrem Amazon Redshift Data Warehouse zu vereinfachen. Mit dynamischer Datenmaskierung kontrollieren Sie den Zugriff auf Ihre Daten durch einfache SQL-basierte Maskierungsrichtlinien, die bestimmen, wie Amazon Redshift vertrauliche Daten zum Zeitpunkt der Abfrage an den Benutzer zurückgibt. Sie können Maskierungsrichtlinien erstellen, um konsistente, formaterhaltende und irreversible maskierte Datenwerte zu definieren. Sie können eine Maskierungsrichtlinie auf eine bestimmte Spalte oder Spaltenliste in einer Tabelle anwenden. Außerdem können Sie flexibel auswählen, wie die maskierten Daten angezeigt werden. Beispielsweise können Sie die Daten vollständig ausblenden, teilweise reelle Werte durch Platzhalterzeichen ersetzen oder Ihre eigene Methode zum Maskieren der Daten mithilfe von SQL-Ausdrücken, Python oder definieren AWS Lambda benutzerdefinierte Funktionen. Darüber hinaus können Sie eine bedingte Maskierungsrichtlinie basierend auf anderen Spalten anwenden, die die Spaltendaten in einer Tabelle basierend auf den Werten in einer oder mehreren unterschiedlichen Spalten selektiv schützt.
Wir haben auch Verbesserungen für angekündigt Überwachungsprotokollierung, native Integration mit Microsoft Azure Active Directoryund Unterstützung für Standard-IAM-Rollen in weiteren Regionen, um das Sicherheitsmanagement weiter zu vereinfachen.
Analyse der besten Preisleistung
Kunden sagen uns immer wieder, dass sie schnelle und kostengünstige Data Warehouses benötigen, die in jeder Größenordnung eine hohe Leistung bieten und gleichzeitig die Kosten niedrig halten. Ab Tag 1 seit Der Start von Amazon Redshift im Jahr 2012, haben wir einen datengesteuerten Ansatz gewählt und mithilfe von Flottentelemetrie einen Cloud-Data-Warehouse-Service aufgebaut, der Ihnen in jeder Größenordnung das beste Preis-Leistungs-Verhältnis bietet. Im Laufe der Jahre haben wir uns weiterentwickelt Die Architektur von Amazon Redshift und gestartete Funktionen wie Redshift-verwalteter Speicher (RMS) zur Trennung von Speicher und Rechenleistung, Amazon Redshift-Spektrum für Data-Lake-Abfragen, automatische Tabellenoptimierung zur physikalischen Schemaoptimierung, automatisches Workload-Management Workloads zu priorisieren und die richtige Rechenleistung und den richtigen Arbeitsspeicher zuzuweisen, Clustergröße ändern um Rechenleistung und Speicher vertikal zu skalieren, und Parallelitätsskalierung um Berechnungen dynamisch heraus- oder hineinzuskalieren Leistungsbenchmarks weiterhin die Preis-Leistungs-Führerschaft von Amazon Redshift demonstrieren.
Im Jahr 2022 haben wir neue Funktionen hinzugefügt, z. B. die allgemeine Verfügbarkeit von Gleichzeitigkeitsskalierung für Schreibvorgänge wie COPY, INSERT, UPDATE und DELETE, um praktisch unbegrenzt gleichzeitige Benutzer und Abfragen zu unterstützen. Wir haben auch Leistungsverbesserungen für die zeichenfolgenbasierte Datenverarbeitung durch vektorisierte Scans über leichtgewichtige, CPU-effiziente, wörterbuchcodierte Zeichenfolgenspalten eingeführt, wodurch die Datenbank-Engine direkt mit komprimierten Daten arbeiten kann.
Wir haben auch Unterstützung für SQL-Operatoren wie z MERGE (Einzeloperator für Einfügungen oder Aktualisierungen); CONNECY_BY (für hierarchische Abfragen); GRUPPIERUNGSSETS, ROLLUP und CUBE (für mehrdimensionale Berichterstattung); und die Größe des SUPER-Datentyps auf 16 MB erhöht, um Ihnen die Migration von älteren Data Warehouses zu Amazon Redshift zu erleichtern.
Zusammenfassung
Unsere Kunden sagen uns immer wieder, dass Daten und Analysen für sie weiterhin höchste Priorität haben und dass die Notwendigkeit, in diesen Zeiten kosteneffektiv mehr geschäftlichen Nutzen aus ihren Daten zu ziehen, ausgeprägter ist als zu jeder anderen Zeit in der Vergangenheit. Amazon Redshift als Ihr Cloud Data Warehouse ermöglicht es Ihnen, komplexe SQL-Analysen mit Skalierbarkeit und Leistung auf Terabyte bis Petabyte an strukturierten und unstrukturierten Daten auszuführen und die Erkenntnisse über beliebte BI- und Analysetools allgemein verfügbar zu machen.
Obwohl wir im Jahr 40 über 2022 Funktionen eingeführt haben und sich das Innovationstempo weiter beschleunigt, bleibt es Tag 1, und wir freuen uns darauf, von Ihnen zu hören, wie diese Funktionen Ihnen helfen, mehr Wert für Ihre Organisationen zu erschließen. Wir laden Sie ein, diese neuen Funktionen auszuprobieren und sich über Ihr AWS-Kontoteam mit uns in Verbindung zu setzen, wenn Sie weitere Kommentare haben.
Über den Autor
 Manan Goel ist ein Product Go-To-Market Leader für AWS Analytics Services, einschließlich Amazon Redshift bei AWS. Er verfügt über mehr als 25 Jahre Erfahrung und ist mit Datenbanken, Data Warehousing, Business Intelligence und Analytik bestens vertraut. Manan hat einen MBA der Duke University und einen BS in Elektronik und Kommunikationstechnik.
Manan Goel ist ein Product Go-To-Market Leader für AWS Analytics Services, einschließlich Amazon Redshift bei AWS. Er verfügt über mehr als 25 Jahre Erfahrung und ist mit Datenbanken, Data Warehousing, Business Intelligence und Analytik bestens vertraut. Manan hat einen MBA der Duke University und einen BS in Elektronik und Kommunikationstechnik.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- Fähigkeit
- Über Uns
- beschleunigen
- Zugang
- Zugriff auf Daten
- Zugriff
- zugänglich
- Konto
- Erreichen
- über
- aktiv
- aktiv
- hinzugefügt
- Zusatz
- Zusätzliche
- zusätzlich
- Adobe
- Alle
- erlaubt
- bereits
- Amazon
- Amazon EMR
- Business Analysten
- Analytik
- analysieren
- Analyse
- und
- Bekannt geben
- angekündigt
- Ein anderer
- beantworten
- Apache
- Apache Funken
- APIs
- Anwendung
- Anwendungen
- Bewerben
- Ansatz
- Architektur
- Bereich
- Bereiche
- künstlich
- künstliche Intelligenz
- Vermögenswert
- Vermögensverwaltung
- Prüfung
- Aurora
- Autor
- Auto
- automatisieren
- automatische
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Verfügbarkeit
- verfügbar
- AWS
- AWS-Kleber
- Azure
- basierend
- Grundlage
- Werden
- Bevor
- Sein
- BESTE
- Besser
- zwischen
- Big
- Big Data
- Rechnungs-
- Break
- breit
- Broadridge
- bauen
- Building
- eingebaut
- Geschäft
- Geschäftsanwendungen
- Geschäftskontinuität
- Business Intelligence
- Fähigkeiten
- Kapazität
- Karte
- Häuser
- Fälle
- Änderungen
- Zeichen
- Auswählen
- Auswahl
- Kunden
- Cloud
- Cluster
- zusammenarbeiten
- Zusammenarbeit
- Sammlung
- Kolonne
- Spalten
- kombinieren
- kombiniert
- Bemerkungen
- Kommunikation
- Kompatibilität
- uneingeschränkt
- Komplex
- Komponente
- Berechnen
- Wettbewerber
- Vernetz Dich
- konsistent
- Konsul (Console)
- verbraucht
- fortsetzen
- weiter
- weiter
- kontinuierlich
- Smartgeräte App
- kostengünstiger
- Kosten
- deckt
- erstellen
- Erstellen
- Referenzen
- Kredit
- Kreditkarte
- Credits
- CRM
- Strom
- Original
- Kunde
- Kundensupport
- Kunden
- maßgeschneiderte
- technische Daten
- Data Exchange
- Datensee
- Datenverarbeitung
- Datenübertragung
- Data Warehouse
- Data Warehouse
- datengesteuerte
- Datenbase
- Datenbanken
- Tag
- tiefer
- Übergeben
- zeigen
- einsetzen
- Einsatz
- Design
- Bestimmen
- Entwickler:in / Unternehmen
- Entwickler
- anders
- Direkt
- entdeckt,
- entdeckt
- diskutieren
- verteilt
- verteilen
- Herzog
- Duke University
- im
- dynamisch
- einfacher
- leicht
- Herausgeber
- Anstrengung
- Elektronik
- eliminiert
- eliminieren
- ermöglichen
- ermöglicht
- ermöglichen
- Endpunkt
- Motor
- Entwicklung
- Äther (ETH)
- jedermann
- entwickelt
- Beispiel
- Austausch-
- aufgeregt
- Erweitern Sie die Funktionalität der
- ERFAHRUNGEN
- ERKUNDEN
- Ausdrücke
- Extrakt
- Scheitern
- vertraut
- FAST
- beschleunigt
- Merkmal
- Eigenschaften
- Reichen Sie das
- Mappen
- Revolution
- Finanzdienstleistungen
- Finanzen
- Finden Sie
- FLOTTE
- Flexibilität
- Ausbildung
- vorwärts
- Frei
- für
- voll
- Funktionen
- weiter
- Zukunft
- Allgemeines
- bekommen
- gif
- ABSICHT
- gegeben
- gibt
- Unterstützung
- Glas
- Zum Markt gehen
- Governance
- gewähren
- erteilt
- groß
- passieren
- glücklich
- hart
- mit
- Gesundheitswesen
- Hörtests
- Hilfe
- hilft
- Verbergen
- GUTE
- historisch
- hält
- Ultraschall
- Hilfe
- HTML
- HTTPS
- hunderte
- IAM
- Identitätsschutz
- Implementierung
- zu unterstützen,
- verbessert
- Verbesserungen
- in
- Einschließlich
- hat
- Energiegewinnung
- Information
- Infrastruktur
- Innovation
- Einsätze
- Einblicke
- integrieren
- integriert
- Integriert
- Integration
- Intelligenz
- Intervention
- eingeführt
- Stellt vor
- Investieren
- Investition
- einladen
- Isolierung
- IT
- Job
- Jobs
- join
- Juli
- kafka
- Behalten
- Aufbewahrung
- Wesentliche
- Kinesis-Datenströme
- See
- großflächig
- Latency
- starten
- ins Leben gerufen
- Führer
- Leadership
- lernen
- Legacy
- Niveau
- leicht
- LIMIT
- Liste
- leben
- Lebensdaten
- Belastung
- Ladeprogramm
- Laden
- aussehen
- Sneaker
- Maschine
- Maschinelles Lernen
- gemacht
- halten
- Wartung
- um
- Making
- verwalten
- verwaltet
- Management
- manuell
- Marketo
- Maske"
- Maximieren
- Memory
- migriert
- ML
- für
- modern
- ändern
- überwacht
- Überwachung
- mehr
- ziehen um
- mehrere
- MySQL
- nativen
- Need
- erforderlich
- Bedürfnisse
- Neu
- Neue Funktionen
- Anzahl
- Zahlen
- Angebote
- EINEM
- XNUMXh geöffnet
- betreiben
- Betrieb
- Einkauf & Prozesse
- Operator
- Betreiber
- Optimierung
- Option
- Organisation
- Organisationen
- Andere
- Ausfälle
- aussen
- besitzen
- Frieden
- Paket
- Brot
- Teil
- passt
- AUFMERKSAMKEIT
- Peloton
- Leistung
- Berechtigungen
- Persönlich
- Telefon
- physikalisch
- pii
- Ort
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- zufrieden
- Politik durchzulesen
- Datenschutzrichtlinien
- Beliebt
- Post
- größte treibende
- Vorausschauende Analytik
- verhindern
- Vorspann
- vorher
- Preis
- in erster Linie
- Priorität einräumen
- Prioritätsliste
- Prozessdefinierung
- Verarbeitung
- Hersteller
- Produkt
- PRODUKTIVITÄT
- Schutz
- die
- Versorger
- Anbieter
- bietet
- Bereitstellung
- Python
- Fragen
- schnell
- Angebot
- erreichen
- Lesen Sie mehr
- echt
- Echtzeit
- Echtzeitdaten
- erhält
- Entspannung
- Veteran
- Regionen
- relevant
- Zuverlässigkeit
- zuverlässig
- bleibt bestehen
- ersetzen
- berichten
- Reporting
- Voraussetzungen:
- eine Beschränkung
- was zu
- Rückgabe
- Überprüfen
- Umschreibung
- Reiches
- starr
- Rollen
- Rollen
- aufrollen
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Führen Sie
- Laufen
- sagemaker
- salesforce
- Skalieren
- Waage
- Skalierung
- Szenarien
- Wissenschaft
- Wissenschaftler
- Zweite
- Sekunden
- Verbindung
- sicher
- Sicherheitdienst
- empfindlich
- Sensitivität
- Serverlos
- dient
- Lösungen
- Sitzung
- kompensieren
- Sets
- mehrere
- Teilen
- von Locals geführtes
- ,,teilen"
- erklären
- Einfacher
- vereinfachte
- vereinfachen
- einfach
- gleichzeitig
- da
- Single
- Sitzend
- Größe
- langsam
- So
- Social Media
- Lösung
- Lösungen
- einige
- Quellen
- Spark
- spezifisch
- SQL
- Stufe
- Lagerung
- Läden
- Strategie
- gestreamt
- Streaming
- Ströme
- strukturierte
- strukturierte und unstrukturierte Daten
- so
- Super
- Lieferanten
- Support
- Unterstützt
- System
- Systeme und Techniken
- Tabelle
- Target
- Team
- Das
- Die Zukunft
- ihr
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- Tausende
- Durch
- Zeit
- mal
- zu
- Werkzeug
- Werkzeuge
- Top
- Themen
- Gesamt
- aufnehmen
- verfolgen sind
- Training
- Transaktion
- Transformieren
- Transformationen
- allgegenwärtig
- unvorhergesehen
- Universität
- unbegrenzt
- öffnen
- Aktualisierung
- Updates
- us
- -
- Mitglied
- Nutzer
- Verwendung
- Wert
- Werte
- verschiedene
- Version
- Anzeigen
- Ansichten
- praktisch
- Warehouse
- Lagerung
- Reichtum
- Vermögensverwaltung
- Netz
- Webbasiert
- Was
- Was ist
- welche
- während
- WHO
- breit
- Große Auswahl
- weit
- werden wir
- .
- ohne
- Arbeiten
- gearbeitet
- arbeiten,
- Das weltweit
- schreiben
- geschrieben
- Jahr
- Jahr
- Ihr
- Zephyrnet
- Zonen