Geodaten sind Daten über bestimmte Orte auf der Erdoberfläche. Es kann ein geografisches Gebiet als Ganzes oder ein mit einem geografischen Gebiet verbundenes Ereignis darstellen. In einigen Branchen ist die Analyse von Geodaten gefragt. Dabei geht es darum, aus räumlicher Sicht zu verstehen, wo die Daten vorhanden sind und warum sie dort vorhanden sind.
Es gibt zwei Arten von Geodaten: Vektordaten und Rasterdaten. Rasterdaten sind eine Matrix von Zellen, die als Gitter dargestellt werden und hauptsächlich Fotos und Satellitenbilder darstellen. In diesem Beitrag konzentrieren wir uns auf Vektordaten, die als geografische Koordinaten des Breiten- und Längengrads sowie als Linien und Polygone (Flächen) dargestellt werden, die sie verbinden oder umfassen. Vektordaten haben eine Vielzahl von Anwendungsfällen bei der Ableitung von Mobilitätserkenntnissen. Mobile Benutzerdaten sind eine solche Komponente und werden hauptsächlich aus der geografischen Position mobiler Geräte mithilfe von GPS oder von App-Herausgebern mithilfe von SDKs oder ähnlichen Integrationen abgeleitet. Für die Zwecke dieses Beitrags bezeichnen wir diese Daten als Mobilitätsdaten.
Dies ist eine zweiteilige Serie. In diesem ersten Beitrag stellen wir Mobilitätsdaten, ihre Quellen und ein typisches Schema dieser Daten vor. Anschließend besprechen wir die verschiedenen Anwendungsfälle und untersuchen, wie Sie AWS-Services zum Bereinigen der Daten nutzen können, wie maschinelles Lernen (ML) dabei helfen kann und wie Sie die Daten bei der Generierung von Bildern und Erkenntnissen ethisch nutzen können. Der zweite Beitrag wird eher technischer Natur sein und diese Schritte im Detail sowie Beispielcode behandeln. Dieser Beitrag enthält keinen Beispieldatensatz oder Beispielcode, sondern behandelt vielmehr die Verwendung der Daten, nachdem sie von einem Datenaggregator gekauft wurden.
Sie können verwenden Geodatenfunktionen von Amazon SageMaker um Mobilitätsdaten auf einer Basiskarte zu überlagern und eine mehrschichtige Visualisierung bereitzustellen, um die Zusammenarbeit zu erleichtern. Der GPU-gestützte interaktive Visualizer und die Python-Notebooks bieten eine nahtlose Möglichkeit, Millionen von Datenpunkten in einem einzigen Fenster zu erkunden und Erkenntnisse und Ergebnisse auszutauschen.
Quellen und Schema
Es gibt nur wenige Quellen für Mobilitätsdaten. Abgesehen von GPS-Pings und App-Herausgebern werden auch andere Quellen zur Erweiterung des Datensatzes genutzt, etwa WLAN-Zugangspunkte, Gebotsstromdaten, die über die Bereitstellung von Anzeigen auf Mobilgeräten gewonnen werden, und bestimmte von Unternehmen platzierte Hardware-Sender (z. B. in physischen Geschäften). ). Für Unternehmen ist es oft schwierig, diese Daten selbst zu sammeln, daher kaufen sie sie möglicherweise von Datenaggregatoren. Datenaggregatoren sammeln Mobilitätsdaten aus verschiedenen Quellen, bereinigen sie, fügen Rauschen hinzu und stellen die Daten täglich für bestimmte geografische Regionen zur Verfügung. Aufgrund der Art der Daten selbst und weil sie schwer zu beschaffen sind, können Genauigkeit und Qualität dieser Daten erheblich schwanken. Es liegt an den Unternehmen, dies anhand von Kennzahlen wie täglich aktiven Benutzern, gesamten täglichen Pings usw. zu bewerten und zu überprüfen. und durchschnittliche tägliche Pings pro Gerät. Die folgende Tabelle zeigt, wie ein typisches Schema eines täglichen Datenfeeds aussehen kann, der von Datenaggregatoren gesendet wird.
| Attribut | Beschreibung |
| Id oder MAID | Mobile Advertising ID (MAID) des Geräts (gehasht) |
| lat | Breitengrad des Geräts |
| lng | Längengrad des Geräts |
| Geohash | Geohash-Standort des Geräts |
| Gerätetyp | Betriebssystem des Geräts = IDFA oder GAID |
| horizontale_genauigkeit | Genauigkeit der horizontalen GPS-Koordinaten (in Metern) |
| Zeitstempel | Zeitstempel des Ereignisses |
| ip | IP-Adresse |
| alt | Höhe des Geräts (in Metern) |
| Geschwindigkeit | Geschwindigkeit des Geräts (in Metern/Sekunde) |
| Land | Zweistelliger ISO-Code für das Herkunftsland |
| Zustand | Codes, die den Staat darstellen |
| Stadt | Codes, die die Stadt darstellen |
| zipcode | Postleitzahl, wo die Geräte-ID zu sehen ist |
| Träger | Träger des Geräts |
| Gerätehersteller | Hersteller des Geräts |
Anwendungsszenarien
Mobilitätsdaten finden weitreichende Anwendungen in verschiedenen Branchen. Im Folgenden sind einige der häufigsten Anwendungsfälle aufgeführt:
- Dichtemetriken – Die Analyse des Fußgängerverkehrs kann mit der Bevölkerungsdichte kombiniert werden, um Aktivitäten und Besuche von Points of Interest (POIs) zu beobachten. Diese Metriken vermitteln ein Bild davon, wie viele Geräte oder Benutzer ein Unternehmen aktiv anhalten und mit ihm interagieren. Dies kann weiter zur Standortauswahl oder sogar zur Analyse von Bewegungsmustern rund um eine Veranstaltung (z. B. Personen, die zu einem Spieltag reisen) verwendet werden. Um solche Erkenntnisse zu gewinnen, durchlaufen die eingehenden Rohdaten einen Extraktions-, Transformations- und Ladeprozess (ETL), um Aktivitäten oder Interaktionen aus dem kontinuierlichen Strom von Gerätestandort-Pings zu identifizieren. Wir können Aktivitäten analysieren, indem wir vom Benutzer oder Mobilgerät vorgenommene Stopps identifizieren, indem wir Pings mithilfe von ML-Modellen gruppieren Amazon Sage Maker.
- Reisen und Flugbahnen – Der tägliche Standort-Feed eines Geräts kann als Sammlung von Aktivitäten (Stopps) und Fahrten (Bewegung) ausgedrückt werden. Ein Aktivitätspaar kann eine Reise zwischen ihnen darstellen, und die Verfolgung der Reise durch das sich bewegende Gerät im geografischen Raum kann zur Kartierung der tatsächlichen Flugbahn führen. Flugbahnmuster von Benutzerbewegungen können zu interessanten Erkenntnissen wie Verkehrsmuster, Kraftstoffverbrauch, Stadtplanung und mehr führen. Es kann auch Daten liefern, um die Route von Werbepunkten wie einer Werbetafel zu analysieren, die effizientesten Lieferrouten zur Optimierung von Lieferkettenabläufen zu identifizieren oder Evakuierungsrouten bei Naturkatastrophen (z. B. Hurrikan-Evakuierung) zu analysieren.
- Einzugsgebietsanalyse - Ein Einzugsgebiet bezieht sich auf Orte, von denen ein bestimmter Bereich seine Besucher anzieht, bei denen es sich um Kunden oder potenzielle Kunden handeln kann. Einzelhandelsunternehmen können diese Informationen nutzen, um den optimalen Standort für die Eröffnung einer neuen Filiale zu bestimmen oder festzustellen, ob zwei Filialstandorte zu nahe beieinander liegen und sich die Einzugsgebiete überschneiden und sich gegenseitig behindern. Sie können auch herausfinden, woher die tatsächlichen Kunden kommen, potenzielle Kunden identifizieren, die auf dem Weg zur Arbeit oder nach Hause durch die Gegend kommen, ähnliche Besuchskennzahlen für Wettbewerber analysieren und vieles mehr. Marketing-Tech- (MarTech) und Advertisement-Tech-Unternehmen (AdTech) können diese Analyse auch nutzen, um Marketingkampagnen zu optimieren, indem sie die Zielgruppe in der Nähe des Geschäfts einer Marke identifizieren oder Geschäfte nach ihrer Leistung für Außenwerbung ordnen.
Es gibt mehrere andere Anwendungsfälle, darunter die Generierung von Standortinformationen für Gewerbeimmobilien, die Ergänzung von Satellitenbilddaten mit Besucherzahlen, die Identifizierung von Lieferzentren für Restaurants, die Bestimmung der Evakuierungswahrscheinlichkeit in der Nachbarschaft, die Erkennung von Bewegungsmustern von Menschen während einer Pandemie und mehr.
Herausforderungen und ethischer Gebrauch
Die ethische Nutzung von Mobilitätsdaten kann zu vielen interessanten Erkenntnissen führen, die Unternehmen dabei helfen können, ihre Abläufe zu verbessern, effektives Marketing zu betreiben oder sogar einen Wettbewerbsvorteil zu erzielen. Um diese Daten ethisch zu nutzen, müssen mehrere Schritte befolgt werden.
Es beginnt bereits bei der Datenerhebung selbst. Obwohl die meisten Mobilitätsdaten frei von persönlich identifizierbaren Informationen (PII) wie Name und Adresse bleiben, müssen Datenerfasser und -aggregatoren die Zustimmung des Benutzers einholen, um ihre Daten zu sammeln, zu verwenden, zu speichern und weiterzugeben. Datenschutzgesetze wie DSGVO und CCPA müssen eingehalten werden, da sie Benutzern die Möglichkeit geben, zu bestimmen, wie Unternehmen ihre Daten verwenden dürfen. Dieser erste Schritt ist ein wesentlicher Schritt in Richtung einer ethischen und verantwortungsvollen Nutzung von Mobilitätsdaten, aber es kann noch mehr getan werden.
Jedem Gerät wird eine gehashte Mobile Advertising ID (MAID) zugewiesen, die zur Verankerung der einzelnen Pings dient. Dies kann durch die Verwendung weiter verschleiert werden Amazon Macie, Amazon S3-Objekt Lambda, Amazon verstehenoder sogar die AWS Glue Studio PII-Transformation erkennen. Weitere Informationen finden Sie unter Gängige Techniken zur Erkennung von PHI- und PII-Daten mithilfe von AWS Services.
Abgesehen von PII sollten Überlegungen angestellt werden, um den Heimatstandort des Benutzers sowie andere sensible Orte wie Militärstützpunkte oder Kultstätten zu verschleiern.
Der letzte Schritt für eine ethische Nutzung besteht darin, nur aggregierte Metriken aus Amazon SageMaker abzuleiten und zu exportieren. Dies bedeutet, dass Kennzahlen wie die durchschnittliche Anzahl oder die Gesamtzahl der Besucher im Gegensatz zu individuellen Reisemustern erhoben werden; Abrufen täglicher, wöchentlicher, monatlicher oder jährlicher Trends; oder die Indexierung von Mobilitätsmustern anhand öffentlich verfügbarer Daten wie Volkszählungsdaten.
Lösungsüberblick
Wie bereits erwähnt, sind die AWS-Services, die Sie für die Analyse von Mobilitätsdaten verwenden können, die Geodatenfunktionen Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend und Amazon SageMaker. Die Geodatenfunktionen von Amazon SageMaker erleichtern Datenwissenschaftlern und ML-Ingenieuren das Erstellen, Trainieren und Bereitstellen von Modellen mithilfe von Geodaten. Sie können große Geodatensätze effizient transformieren oder anreichern, die Modellerstellung mit vorab trainierten ML-Modellen beschleunigen und Modellvorhersagen und Geodaten auf einer interaktiven Karte mithilfe von 3D-beschleunigten Grafiken und integrierten Visualisierungstools erkunden.
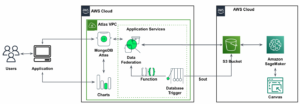
Die folgende Referenzarchitektur zeigt einen Workflow unter Verwendung von ML mit Geodaten.
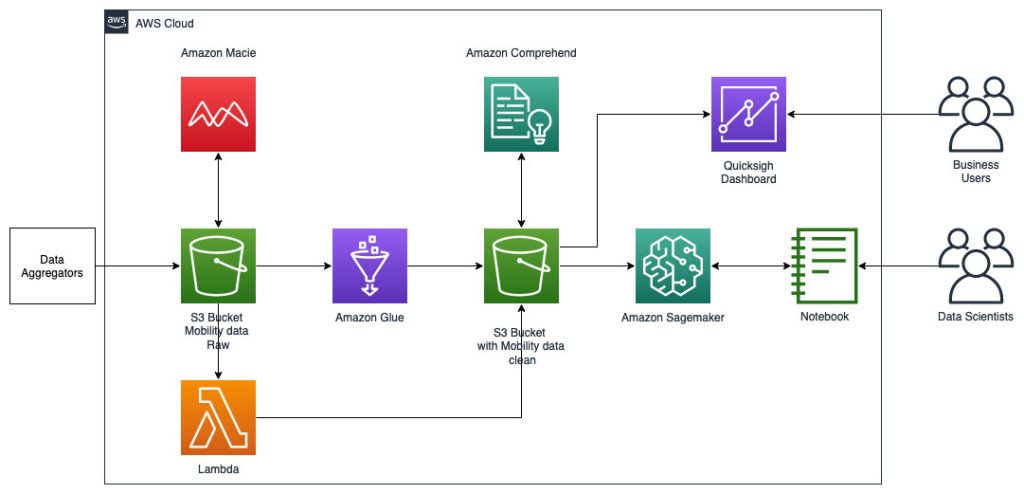
In diesem Workflow werden Rohdaten aus verschiedenen Datenquellen aggregiert und in einem gespeichert Amazon Simple Storage-Service (S3) Eimer. Amazon Macie wird in diesem S3-Bucket verwendet, um personenbezogene Daten zu identifizieren und zu löschen. Anschließend wird AWS Glue verwendet, um die Rohdaten zu bereinigen und in das erforderliche Format umzuwandeln. Anschließend werden die geänderten und bereinigten Daten in einem separaten S3-Bucket gespeichert. Für Datentransformationen, die über AWS Glue nicht möglich sind, verwenden Sie AWS Lambda um die Rohdaten zu ändern und zu bereinigen. Wenn die Daten bereinigt sind, können Sie Amazon SageMaker verwenden, um ML-Modelle auf den vorbereiteten Geodaten zu erstellen, zu trainieren und bereitzustellen. Sie können auch die verwenden Geodatenverarbeitungsjobs Funktion der Geodatenfunktionen von Amazon SageMaker zur Vorverarbeitung der Daten – zum Beispiel mithilfe einer Python-Funktion und SQL-Anweisungen, um Aktivitäten aus den Rohmobilitätsdaten zu identifizieren. Datenwissenschaftler können diesen Prozess durchführen, indem sie eine Verbindung über Amazon SageMaker-Notizbücher herstellen. Sie können auch verwenden Amazon QuickSight um Geschäftsergebnisse und andere wichtige Kennzahlen aus den Daten zu visualisieren.
Geodatenfunktionen und Geodatenverarbeitungsaufträge von Amazon SageMaker
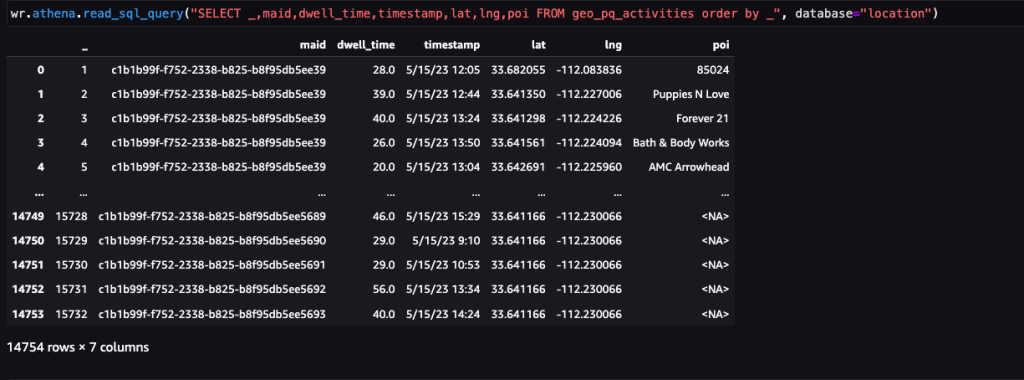
Nachdem die Daten abgerufen und mit einem täglichen Feed in Amazon S3 eingespeist und von sensiblen Daten bereinigt wurden, können sie mit einem in Amazon SageMaker importiert werden Amazon SageMaker-Studio Notizbuch mit einem Geodatenbild. Der folgende Screenshot zeigt ein Beispiel täglicher Geräte-Pings, die als CSV-Datei in Amazon S3 hochgeladen und dann in einen Pandas-Datenrahmen geladen wurden. Das Amazon SageMaker Studio-Notizbuch mit Geodatenbild ist mit Geodatenbibliotheken wie GDAL, GeoPandas, Fiona und Shapely vorinstalliert und erleichtert die Verarbeitung und Analyse dieser Daten.
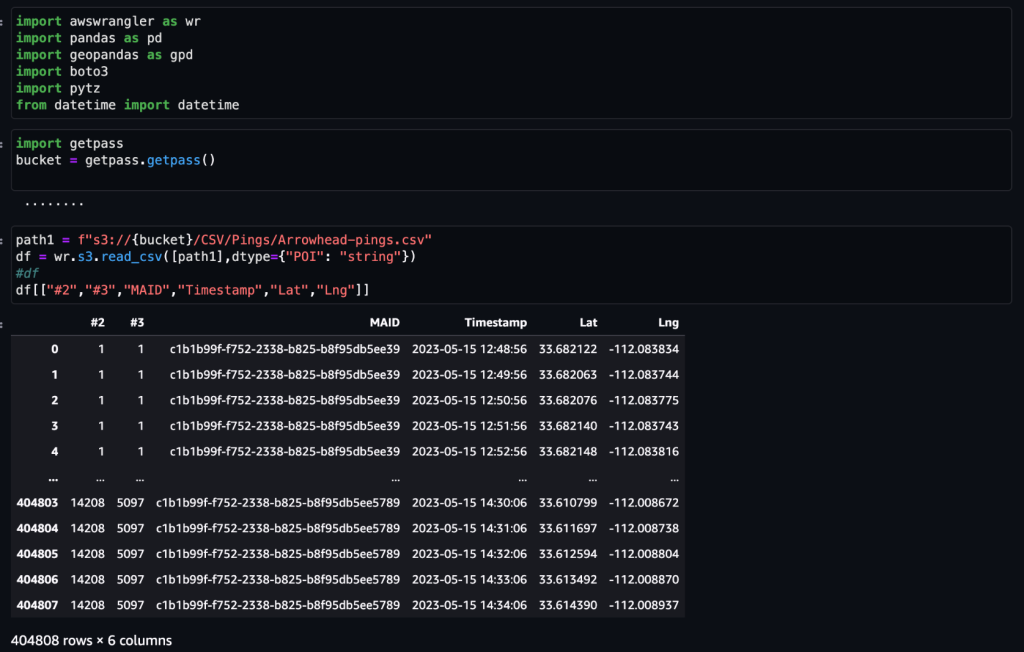
Dieser Beispieldatensatz enthält etwa 400,000 tägliche Geräte-Pings von 5,000 Geräten an 14,000 einzelnen Orten, die von Benutzern aufgezeichnet wurden, die am 15. Mai 2023 die Arrowhead Mall, einen beliebten Einkaufszentrumkomplex in Phoenix, Arizona, besuchten. Der vorherige Screenshot zeigt eine Teilmenge der Spalten im Datenschema. Der MAID Die Spalte stellt die Geräte-ID dar, und jedes MAID generiert jede Minute Pings, die den Breiten- und Längengrad des Geräts weitergeben, die in der Beispieldatei als aufgezeichnet werden Lat machen Lng Säulen.
Im Folgenden finden Sie Screenshots aus dem Kartenvisualisierungstool der Geodatenfunktionen von Amazon SageMaker auf Basis von Foursquare Studio. Sie zeigen die Anordnung der Pings von Geräten, die das Einkaufszentrum zwischen 7:00 und 6:00 Uhr besuchen.
Der folgende Screenshot zeigt Pings aus dem Einkaufszentrum und den umliegenden Gebieten.

Das Folgende zeigt Pings aus verschiedenen Geschäften im Einkaufszentrum.
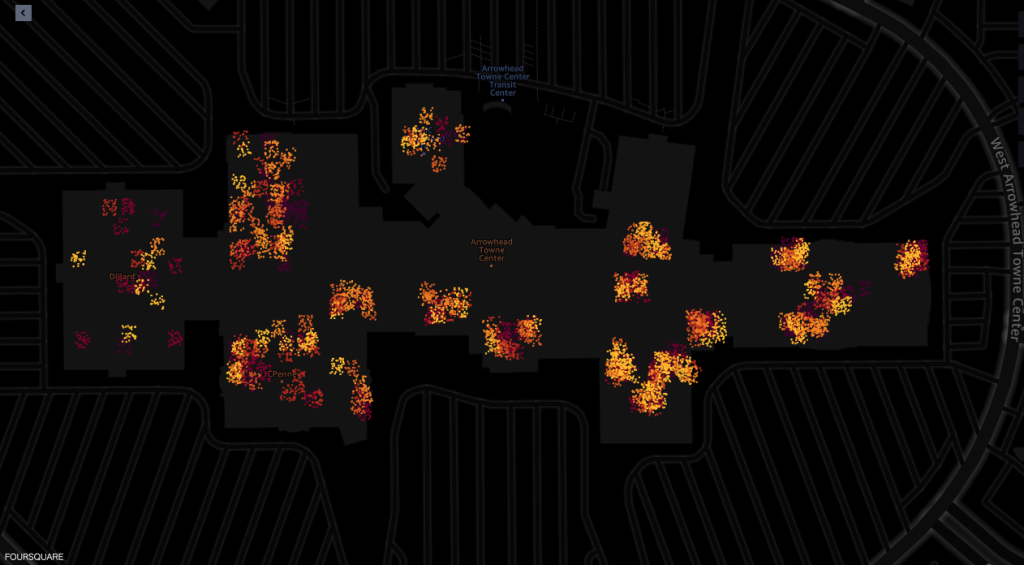
Jeder Punkt in den Screenshots stellt einen Ping von einem bestimmten Gerät zu einem bestimmten Zeitpunkt dar. Eine Gruppe von Pings stellt beliebte Orte dar, an denen sich Geräte versammelten oder anhielten, beispielsweise Geschäfte oder Restaurants.
Als Teil des anfänglichen ETL können diese Rohdaten mit AWS Glue in Tabellen geladen werden. Sie können einen AWS Glue-Crawler erstellen, um das Schema der Daten und Formulartabellen zu identifizieren, indem Sie auf den Rohdatenspeicherort in Amazon S3 als Datenquelle verweisen.

Wie oben erwähnt, stellen die Rohdaten (die täglichen Geräte-Pings) auch nach dem ersten ETL einen kontinuierlichen Strom von GPS-Pings dar, die den Gerätestandort angeben. Um aus diesen Daten umsetzbare Erkenntnisse zu gewinnen, müssen wir Stopps und Fahrten (Trajektorien) identifizieren. Dies kann mit der erreicht werden Geodatenverarbeitungsjobs Funktion der Geodatenfunktionen von SageMaker. Amazon SageMaker-Verarbeitung nutzt eine vereinfachte, verwaltete Erfahrung auf SageMaker, um Datenverarbeitungs-Workloads mit dem speziell entwickelten Geodaten-Container auszuführen. Die zugrunde liegende Infrastruktur für einen SageMaker-Verarbeitungsauftrag wird vollständig von SageMaker verwaltet. Diese Funktion ermöglicht die Ausführung von benutzerdefiniertem Code für auf Amazon S3 gespeicherte Geodaten, indem ein Geodaten-ML-Container für einen SageMaker-Verarbeitungsauftrag ausgeführt wird. Sie können benutzerdefinierte Vorgänge für offene oder private Geodaten ausführen, indem Sie benutzerdefinierten Code mit Open-Source-Bibliotheken schreiben, und den Vorgang mithilfe von SageMaker-Verarbeitungsaufträgen im großen Maßstab ausführen. Der Container-basierte Ansatz erfüllt Anforderungen rund um die Standardisierung der Entwicklungsumgebung mit häufig verwendeten Open-Source-Bibliotheken.
Um solch große Arbeitslasten auszuführen, benötigen Sie einen flexiblen Rechencluster, der von Dutzenden von Instanzen zur Verarbeitung eines Stadtblocks bis zu Tausenden von Instanzen für die Verarbeitung auf globaler Ebene skaliert werden kann. Die manuelle Verwaltung eines DIY-Rechenclusters ist langsam und teuer. Diese Funktion ist besonders hilfreich, wenn der Mobilitätsdatensatz mehr als ein paar Städte, mehrere Bundesstaaten oder sogar Länder umfasst, und kann für die Durchführung eines zweistufigen ML-Ansatzes verwendet werden.
Der erste Schritt besteht darin, den DBSCAN-Algorithmus (Density-based Spatial Clustering of Applications with Noise) zu verwenden, um Stopps aus Pings zu gruppieren. Der nächste Schritt besteht darin, die Methode der Support Vector Machines (SVMs) zu verwenden, um die Genauigkeit der identifizierten Haltestellen weiter zu verbessern und auch Haltestellen mit Interaktionen mit einem POI von Haltestellen ohne POI (z. B. Zuhause oder Arbeit) zu unterscheiden. Sie können den SageMaker-Verarbeitungsjob auch verwenden, um Fahrten und Trajektorien aus den täglichen Gerätepings zu generieren, indem Sie aufeinanderfolgende Stopps identifizieren und den Pfad zwischen den Quell- und Zielstopps zuordnen.
Nach der maßstabsgetreuen Verarbeitung der Rohdaten (tägliche Gerätepings) mit Geodatenverarbeitungsaufträgen sollte der neue Datensatz mit der Bezeichnung „Stopps“ das folgende Schema haben.
| Attribut | Beschreibung |
| Id oder MAID | Mobile Advertising-ID des Geräts (gehasht) |
| lat | Breitengrad des Schwerpunkts des Stoppclusters |
| lng | Längengrad des Schwerpunkts des Stoppclusters |
| Geohash | Geohash-Standort des POI |
| Gerätetyp | Betriebssystem des Geräts (IDFA oder GAID) |
| Zeitstempel | Startzeit des Stopps |
| Verweilzeit | Verweildauer des Stopps (in Sekunden) |
| ip | IP-Adresse |
| alt | Höhe des Geräts (in Metern) |
| Land | Zweistelliger ISO-Code für das Herkunftsland |
| Zustand | Codes, die den Staat darstellen |
| Stadt | Codes, die die Stadt darstellen |
| zipcode | Postleitzahl des Ortes, an dem die Geräte-ID angezeigt wird |
| Träger | Träger des Geräts |
| Gerätehersteller | Hersteller des Geräts |
Stopps werden durch Clustering der Pings pro Gerät konsolidiert. Dichtebasiertes Clustering wird mit Parametern wie einem Stoppschwellenwert von 300 Sekunden und einem Mindestabstand zwischen Stopps von 50 Metern kombiniert. Diese Parameter können je nach Anwendungsfall angepasst werden.
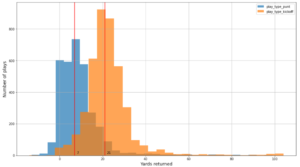
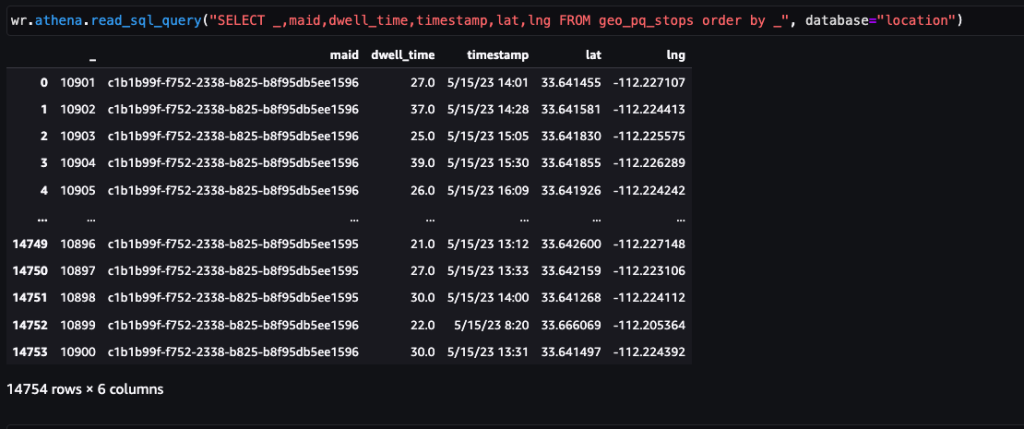
Der folgende Screenshot zeigt etwa 15,000 identifizierte Stopps aus 400,000 Pings. Eine Teilmenge des vorherigen Schemas ist ebenfalls vorhanden, in der Spalte Dwell Time stellt die Stoppdauer dar und die Lat machen Lng Die Spalten stellen den Breiten- und Längengrad der Schwerpunkte des Haltestellenclusters pro Gerät und Standort dar.
Nach ETL werden die Daten im Parquet-Dateiformat gespeichert, einem spaltenorientierten Speicherformat, das die Verarbeitung großer Datenmengen erleichtert.
Der folgende Screenshot zeigt die aus Pings pro Gerät konsolidierten Stopps im Einkaufszentrum und in den umliegenden Bereichen.

Nach der Identifizierung von Haltestellen kann dieser Datensatz mit öffentlich verfügbaren POI-Daten oder benutzerdefinierten POI-Daten speziell für den Anwendungsfall verknüpft werden, um Aktivitäten wie die Interaktion mit Marken zu identifizieren.
Der folgende Screenshot zeigt die identifizierten Haltestellen an wichtigen POIs (Geschäften und Marken) in der Arrowhead Mall.
Die Postleitzahlen des Heimatorts wurden verwendet, um den Heimatstandort jedes Besuchers zu maskieren, um die Privatsphäre zu wahren, falls dieser Teil seiner Reise im Datensatz ist. Der Breiten- und Längengrad sind in solchen Fällen die jeweiligen Koordinaten des Schwerpunkts der Postleitzahl.
Der folgende Screenshot ist eine visuelle Darstellung solcher Aktivitäten. Das linke Bild zeigt die Haltestellen der Geschäfte und das rechte Bild vermittelt einen Eindruck vom Grundriss des Einkaufszentrums selbst.

Dieser resultierende Datensatz kann auf verschiedene Arten visualisiert werden, die wir in den folgenden Abschnitten diskutieren.
Dichtemetriken
Wir können die Aktivitäts- und Besuchsdichte berechnen und visualisieren.
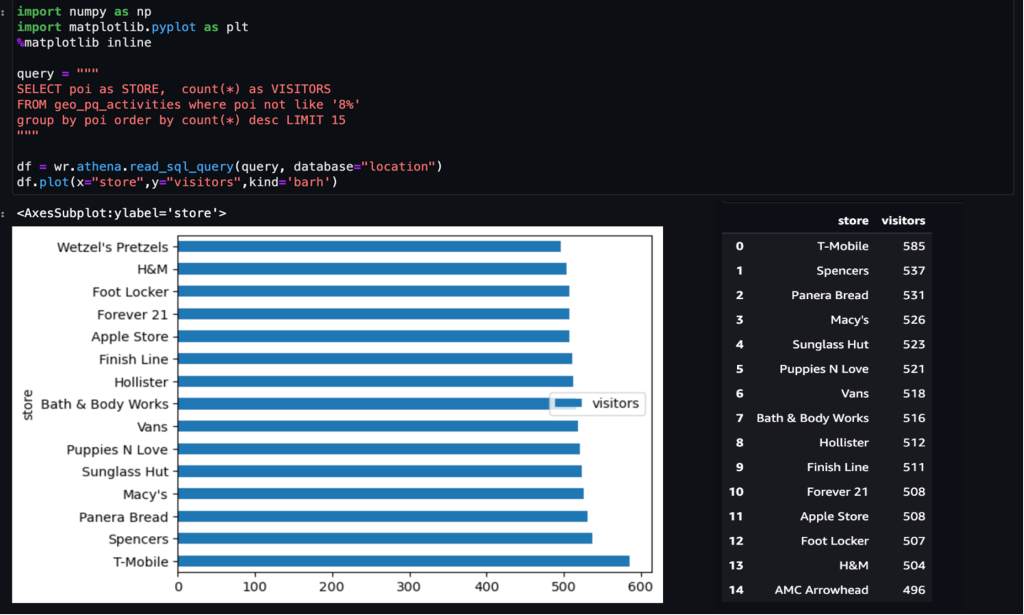
Beispiel 1 – Der folgende Screenshot zeigt die 15 am häufigsten besuchten Geschäfte im Einkaufszentrum.
Beispiel 2 – Der folgende Screenshot zeigt die Anzahl der Besuche im Apple Store pro Stunde.

Reisen und Flugbahnen
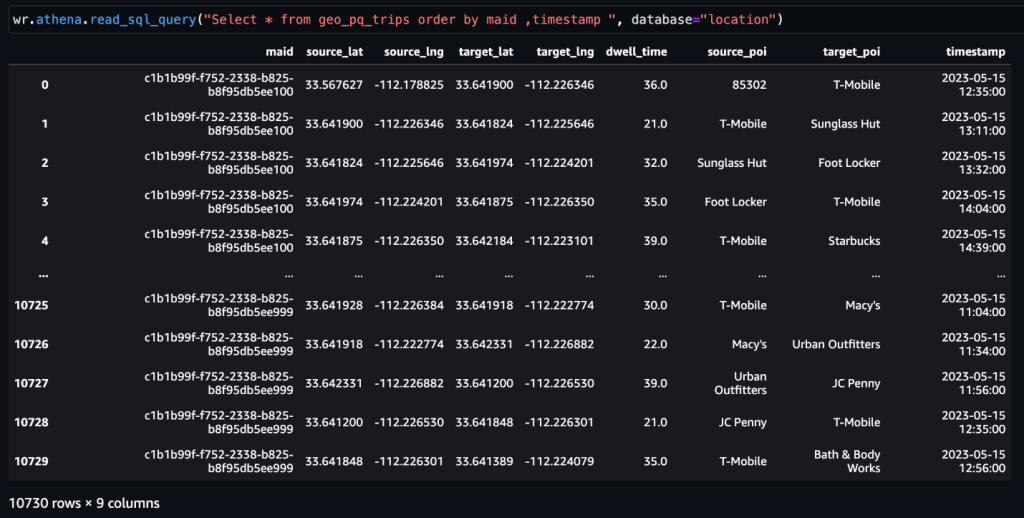
Wie bereits erwähnt, stellt ein Paar aufeinanderfolgender Aktivitäten eine Reise dar. Mit dem folgenden Ansatz können wir Fahrten aus den Aktivitätsdaten ableiten. Hier werden Fensterfunktionen mit SQL verwendet, um die zu generieren trips Tabelle, wie im Screenshot gezeigt.

Nach dem trips Wird eine Tabelle erstellt, können Fahrten zu einem POI ermittelt werden.
Beispiel 1 – Der folgende Screenshot zeigt die Top-10-Stores, die den Fußgängerverkehr zum Apple Store leiten.

Beispiel 2 – Der folgende Screenshot zeigt alle Fahrten zur Arrowhead Mall.

Beispiel 3 – Das folgende Video zeigt die Bewegungsmuster innerhalb der Mall.

Beispiel 4 – Das folgende Video zeigt die Bewegungsmuster außerhalb des Einkaufszentrums.
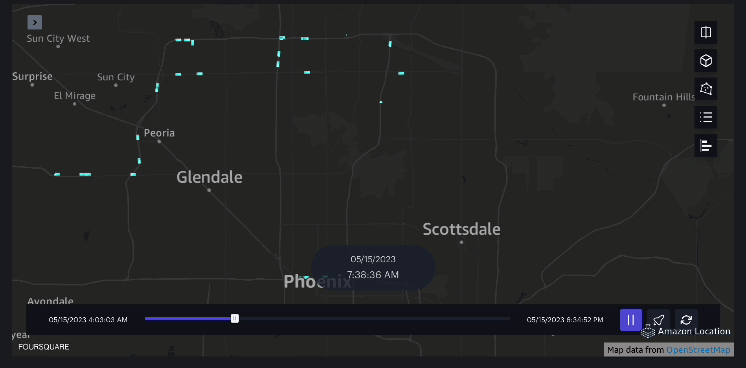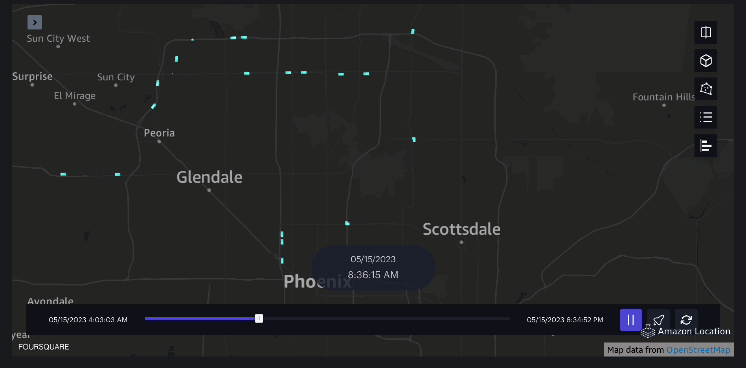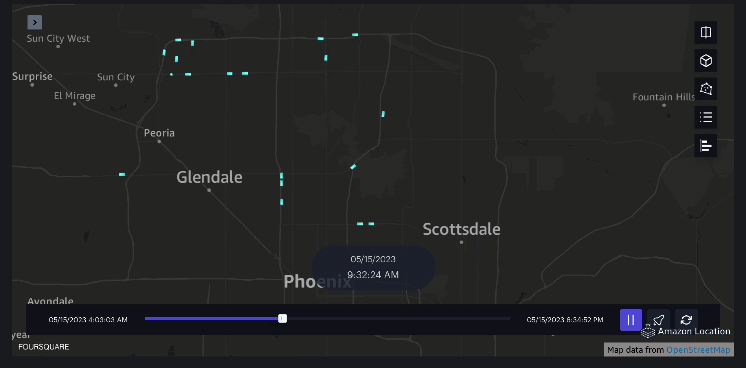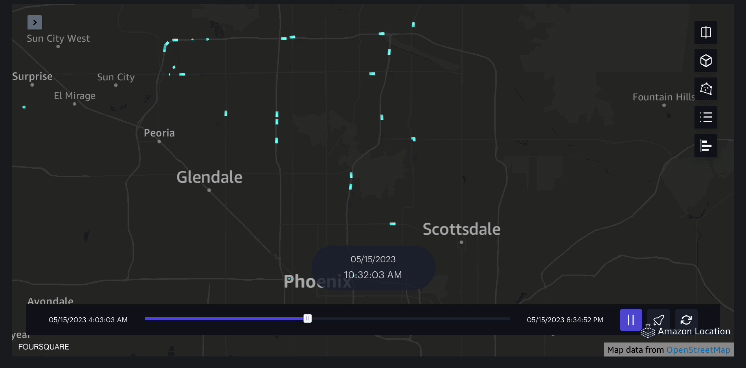
Einzugsgebietsanalyse
Wir können alle Besuche eines POI analysieren und das Einzugsgebiet bestimmen.
Beispiel 1 – Der folgende Screenshot zeigt alle Besuche im Macy’s Store.

Beispiel 2 – Der folgende Screenshot zeigt die Top-10-Postleitzahlen des Heimatgebiets (Grenzen hervorgehoben), von denen aus die Besuche erfolgten.

Datenqualitätsprüfung
Mithilfe von QuickSight-Dashboards und Datenanalysen können wir den täglich eingehenden Datenfeed auf Qualität überprüfen und Anomalien erkennen. Der folgende Screenshot zeigt ein Beispiel-Dashboard.

Zusammenfassung
Mobilitätsdaten und ihre Analyse zur Gewinnung von Kundeneinblicken und zur Erlangung von Wettbewerbsvorteilen bleiben ein Nischenbereich, da es schwierig ist, einen konsistenten und genauen Datensatz zu erhalten. Diese Daten können Unternehmen jedoch dabei helfen, Kontext zu bestehenden Analysen hinzuzufügen und sogar neue Erkenntnisse über Kundenbewegungsmuster zu gewinnen. Die Geodatenfunktionen und Geodatenverarbeitungsaufträge von Amazon SageMaker können dabei helfen, diese Anwendungsfälle zu implementieren und Erkenntnisse auf intuitive und zugängliche Weise abzuleiten.
In diesem Beitrag haben wir gezeigt, wie Sie mithilfe von AWS-Diensten die Mobilitätsdaten bereinigen und dann die Geodatenfunktionen von Amazon SageMaker verwenden, um mithilfe von ML-Modellen abgeleitete Datensätze wie Haltestellen, Aktivitäten und Fahrten zu generieren. Anschließend nutzten wir die abgeleiteten Datensätze, um Bewegungsmuster zu visualisieren und Erkenntnisse zu gewinnen.
Sie können auf zwei Arten mit den Geodatenfunktionen von Amazon SageMaker beginnen:
Um mehr zu erfahren, besuchen Sie Geodatenfunktionen von Amazon SageMaker machen Erste Schritte mit Amazon SageMaker Geospatial. Besuchen Sie auch unsere GitHub Repo, das mehrere Beispielnotizbücher zu den Geodatenfunktionen von Amazon SageMaker enthält.
Über die Autoren
 Jimy Matthews ist ein AWS-Lösungsarchitekt mit Fachkenntnissen in der KI/ML-Technologie. Jimy hat seinen Sitz in Boston und arbeitet mit Unternehmenskunden bei der Transformation ihres Geschäfts durch die Einführung der Cloud zusammen und hilft ihnen beim Aufbau effizienter und nachhaltiger Lösungen. Er hat eine Leidenschaft für seine Familie, Autos und Mixed Martial Arts.
Jimy Matthews ist ein AWS-Lösungsarchitekt mit Fachkenntnissen in der KI/ML-Technologie. Jimy hat seinen Sitz in Boston und arbeitet mit Unternehmenskunden bei der Transformation ihres Geschäfts durch die Einführung der Cloud zusammen und hilft ihnen beim Aufbau effizienter und nachhaltiger Lösungen. Er hat eine Leidenschaft für seine Familie, Autos und Mixed Martial Arts.
 Girish Keshav ist Lösungsarchitekt bei AWS und unterstützt Kunden bei ihrer Cloud-Migration bei der Modernisierung und sicheren und effizienten Ausführung von Workloads. Er arbeitet mit Leitern von Technologieteams zusammen, um sie in den Bereichen Anwendungssicherheit, maschinelles Lernen, Kostenoptimierung und Nachhaltigkeit zu unterstützen. Er hat seinen Sitz in San Francisco und liebt das Reisen, Wandern, Sport schauen und die Erkundung von Craft-Brauereien.
Girish Keshav ist Lösungsarchitekt bei AWS und unterstützt Kunden bei ihrer Cloud-Migration bei der Modernisierung und sicheren und effizienten Ausführung von Workloads. Er arbeitet mit Leitern von Technologieteams zusammen, um sie in den Bereichen Anwendungssicherheit, maschinelles Lernen, Kostenoptimierung und Nachhaltigkeit zu unterstützen. Er hat seinen Sitz in San Francisco und liebt das Reisen, Wandern, Sport schauen und die Erkundung von Craft-Brauereien.
 Ramesh-Anlegestelle ist ein leitender Leiter der Lösungsarchitektur, der sich darauf konzentriert, AWS-Unternehmenskunden bei der Monetarisierung ihrer Datenbestände zu unterstützen. Er berät Führungskräfte und Ingenieure beim Entwurf und Aufbau hoch skalierbarer, zuverlässiger und kosteneffizienter Cloud-Lösungen mit besonderem Schwerpunkt auf maschinellem Lernen, Daten und Analysen. In seiner Freizeit genießt er die Natur, radelt und wandert mit seiner Familie.
Ramesh-Anlegestelle ist ein leitender Leiter der Lösungsarchitektur, der sich darauf konzentriert, AWS-Unternehmenskunden bei der Monetarisierung ihrer Datenbestände zu unterstützen. Er berät Führungskräfte und Ingenieure beim Entwurf und Aufbau hoch skalierbarer, zuverlässiger und kosteneffizienter Cloud-Lösungen mit besonderem Schwerpunkt auf maschinellem Lernen, Daten und Analysen. In seiner Freizeit genießt er die Natur, radelt und wandert mit seiner Familie.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 10
- 100
- 14
- 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Über uns
- oben
- beschleunigen
- beschleunigt
- Zugang
- zugänglich
- erreichen
- Genauigkeit
- genau
- erreicht
- aktiv
- aktiv
- Aktivitäten
- präsentieren
- hinzufügen
- Adresse
- haftete
- Bereinigt
- Die Annahme
- Siehe Werbung
- Vorteil
- Werbung
- Marketings
- Nach der
- Aggregator
- Aggregatoren
- AI / ML
- Hilfe
- Algorithmus
- Alle
- neben
- ebenfalls
- Obwohl
- am
- Amazon
- Amazon verstehen
- Amazon Sage Maker
- Geodaten von Amazon SageMaker
- Amazon SageMaker-Studio
- Amazon Web Services
- Beträge
- an
- Analysen
- Analyse
- Analytik
- analysieren
- Analyse
- Moderator
- machen
- jedem
- auseinander
- App
- Apple
- Anwendung
- Anwendungssicherheit
- Anwendungen
- Ansatz
- ca.
- Architektur
- SIND
- Bereich
- Bereiche
- Arizona
- um
- Kunst
- AS
- Details
- zugewiesen
- damit verbundenen
- At
- erreichen
- Publikum
- vermehren
- verfügbar
- durchschnittlich
- AWS
- AWS-Kleber
- Base
- basierend
- Grundlage
- BE
- weil
- war
- Sein
- zwischen
- Gebot
- Blockieren
- Boston
- Grenzen
- Marken
- bauen
- Building
- eingebaut
- Geschäft
- Unternehmen
- aber
- by
- Berechnen
- namens
- Kampagnen
- CAN
- Kann bekommen
- Fähigkeiten
- Autos
- Häuser
- Fälle
- CCPA
- Die Zellen
- Volkszählung
- Volkszählungsdaten
- Kette
- aus der Ferne überprüfen
- Orte
- Stadt
- reinigen
- Menu
- Cloud
- Cluster
- Clustering
- Code
- Codes
- Zusammenarbeit
- sammeln
- Sammlung
- Sammler
- Kolonne
- Spalten
- kombiniert
- kommt
- Kommen
- kommerziell
- Gewerbeimmobilien
- gemeinsam
- häufig
- Unternehmen
- wettbewerbsfähig
- Konkurrenz
- Komplex
- Komponente
- begreifen
- Berechnen
- Sich zusammenschliessen
- aufeinanderfolgenden
- Zustimmung
- Überlegungen
- konsistent
- Verbrauch
- Container
- enthält
- Kontext
- kontinuierlich
- Kosten
- Ländern
- Land
- Abdeckung
- deckt
- Handwerk
- Crawler
- erstellen
- Original
- Kunde
- Kunden
- Unterricht
- Armaturenbrett
- Dashboards
- technische Daten
- Datenpunkte
- Datenschutz
- Datenverarbeitung
- Datensätze
- Tag
- Lieferanten
- weisen nach, dass
- Dichte
- darstellend
- einsetzen
- Derivat
- ableiten
- Abgeleitet
- Design
- Reiseziele
- Detail
- entdecken
- Bestimmen
- entschlossen
- Festlegung
- Entwicklung
- Gerät
- Geräte
- schwer
- Direkt
- Katastrophen
- entdecken
- diskutieren
- Abstand
- unterscheiden
- Diy
- die
- erledigt
- DOT
- zieht
- zwei
- Dauer
- im
- jeder
- Früher
- einfacher
- Einfache
- Effektiv
- effizient
- effizient
- Anstrengung
- ermächtigen
- ermöglicht
- umfassend
- Engagement
- Engagements
- Eingriff
- Ingenieure
- bereichern
- Unternehmen
- Unternehmenskunden
- Arbeitsumfeld
- insbesondere
- Sommer
- Äther (ETH)
- ethisch
- Sogar
- Event
- Jedes
- Beispiel
- Führungskräfte
- vorhandenen
- existiert
- teuer
- ERFAHRUNGEN
- Expertise
- ERKUNDEN
- Möglichkeiten sondieren
- exportieren
- zum Ausdruck gebracht
- Extrakt
- Familie
- Merkmal
- Fed
- wenige
- Reichen Sie das
- Finale
- Finden Sie
- fiona
- Vorname
- flexibel
- Setzen Sie mit Achtsamkeit
- konzentriert
- gefolgt
- Folgende
- Fuß
- Aussichten für
- unten stehende Formular
- Format
- Foursquare
- FRAME
- Francisco cisco~~POS=HEADCOMP
- Frei
- für
- Treibstoff
- voll
- Funktion
- Funktionen
- weiter
- gewinnen
- Spiel
- gesammelt
- DSGVO
- erzeugen
- erzeugt
- erzeugt
- Erzeugung
- geographisch
- geographisch
- Geodaten-ML
- bekommen
- bekommen
- gif
- gegeben
- gibt
- Goes
- gps
- Grafik
- groß
- Großartige Natur
- Gitter
- Guide
- Hardware
- gehasht
- Haben
- he
- Hilfe
- hilfreich
- Unternehmen
- hilft
- hier
- Besondere
- hoch
- Wandern
- seine
- Startseite
- Horizontale
- Stunde
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- Naben
- Hurrikan
- ID
- Idee
- identifiziert
- identifizieren
- Identifizierung
- IDFA
- if
- Image
- implementieren
- wichtig
- zu unterstützen,
- in
- Einschließlich
- Eingehende
- Anzeige
- Krankengymnastik
- Branchen
- Information
- Infrastruktur
- Anfangs-
- innerhalb
- Einblicke
- Instanzen
- Integrationen
- Intelligenz
- interaktive
- Interesse
- interessant
- in
- einführen
- intuitiv
- beinhaltet
- IT
- SEINE
- selbst
- Job
- Jobs
- beigetreten
- Reise
- jpg
- grosse
- großflächig
- Breite
- Gesetze
- Schicht
- Layout
- führen
- Führer
- Führung
- LERNEN
- lernen
- links
- Bibliotheken
- Gefällt mir
- Wahrscheinlichkeit
- Linien
- Belastung
- Standorte
- Standorte
- aussehen
- aussehen wie
- liebt
- Maschine
- Maschinelles Lernen
- Maschinen
- gemacht
- halten
- Dur
- um
- MACHT
- verwaltet
- flächendeckende Gesundheitsprogramme
- manuell
- viele
- Karte
- Mapping
- Landkarten
- Marketing
- Marketing-Kampagnen
- Marketing-Technologie
- MarTech
- kriegerisch
- Maske"
- Matrix
- Kann..
- Mittel
- erwähnt
- Methode
- Metrik
- Migration
- Militär
- Millionen
- Minimum
- Minute
- gemischt
- ML
- Mobil
- Mobilgerät
- mobile Geräte
- Mobilität
- Modell
- für
- modernisieren
- geändert
- ändern
- monetarisieren
- monatlich
- mehr
- vor allem warme
- meist
- schlauer bewegen
- Bewegung
- Bewegungen
- ziehen um
- mehrere
- Vielzahl
- sollen
- Name
- Natürliche
- Natur
- Need
- Bedürfnisse
- Neu
- weiter
- Nische
- Lärm
- Notizbuch
- Laptops
- Anzahl
- Zahlen
- Objekt
- beobachten
- erhalten
- erhalten
- beschaffen
- aufgetreten
- of
- vorgenommen,
- on
- EINEM
- einzige
- XNUMXh geöffnet
- Open-Source-
- Betrieb
- Einkauf & Prozesse
- entgegengesetzt
- optimal
- Optimierung
- Optimieren
- or
- Organisationen
- Andere
- UNSERE
- Ergebnisse
- im Freien
- aussen
- übrig
- Paar
- Pandas
- Pandemie
- Parameter
- Teil
- besonders
- passieren
- leidenschaftlich
- Weg
- Muster
- Personen
- für
- ausführen
- Leistung
- Persönlich
- Perspektive
- Phönix
- Fotografien
- physikalisch
- ein Bild
- pii
- Klingeln
- platziert
- Länder/Regionen
- Planung
- Plato
- Datenintelligenz von Plato
- PlatoData
- pm
- Points
- Punkte
- Beliebt
- Bevölkerung
- Position
- möglich
- Post
- Potenzial
- mögliche Kunden
- angetriebene
- vor
- Prognosen
- Gegenwart
- Datenschutz
- Datenschutzgesetze
- privat
- Prozessdefinierung
- Verarbeitung
- produziert
- die
- öffentlich
- Verlag
- Kauf
- gekauft
- Zweck
- Python
- Qualität
- Rang
- lieber
- Roh
- Rohdaten
- echt
- Immobilien
- aufgezeichnet
- siehe
- Referenz
- bezieht sich
- Regionen
- zuverlässig
- bleibt bestehen
- vertreten
- Darstellung
- vertreten
- Darstellen
- representiert
- falls angefordert
- diejenigen
- für ihren Verlust verantwortlich.
- Restaurants
- was zu
- Die Ergebnisse
- Einzelhandel
- Recht
- Straße
- Routen
- Führen Sie
- Laufen
- sagemaker
- Beispieldatensatz
- San
- San Francisco
- Satellit
- Satellitenbilder
- skalierbaren
- Skalieren
- Wissenschaftler
- Screenshots
- SDKS
- nahtlos
- Zweite
- Sekunden
- Abschnitte
- sicher
- Sicherheitdienst
- Auswahl
- Senior
- empfindlich
- geschickt
- getrennte
- Modellreihe
- Dienstleistungen
- Dienst
- mehrere
- Teilen
- Shopping
- sollte
- gezeigt
- Konzerte
- ähnlich
- Einfacher
- vereinfachte
- Single
- am Standort
- langsam
- So
- Lösungen
- Löst
- einige
- gesucht
- Quelle
- Quellen
- Raumfahrt
- räumlich
- spezifisch
- Sports
- Flecken
- SQL
- Standardisierung
- begonnen
- beginnt
- Aussagen
- Staaten
- Schritt
- Shritte
- Stoppen
- gestoppt
- Einstellung
- Stoppt
- Lagerung
- speichern
- gelagert
- Läden
- einfach
- Strom
- Studio Adressen
- wesentlich
- so
- liefern
- Supply Chain
- Support
- Oberfläche
- Umgebung
- Nachhaltigkeit
- nachhaltiger
- System
- Tabelle
- gemacht
- Teams
- Tech
- Technische
- Techniken
- Technologie
- Zehn
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Gegend
- Die Quelle
- ihr
- Sie
- sich
- dann
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- Tausende
- Schwelle
- Durch
- Zeit
- zu
- auch
- Werkzeug
- Werkzeuge
- Top
- Top 10
- Gesamt
- gegenüber
- Tracing
- der Verkehr
- Training
- Flugbahn
- Transformieren
- Transformationen
- Sender
- reisen
- Reise
- Trends
- Ausflug
- XNUMX
- Typen
- typisch
- zugrunde liegen,
- Verständnis
- einzigartiges
- hochgeladen
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- Nutzen
- verschiedene
- überprüfen
- Video
- Besuchen Sie
- besucht
- Besucher
- Besuche
- visuell
- Visualisierung
- visualisieren
- Visuals
- vs
- beobachten
- Weg..
- Wege
- we
- Netz
- Web-Services
- wöchentlich
- GUT
- Was
- wann
- welche
- WHO
- ganze
- warum
- Wi-fi
- weit verbreitet
- werden wir
- Fenster
- mit
- ohne
- Arbeiten
- Arbeitsablauf.
- Werk
- Schreiben
- jährlich
- U
- Ihr
- Zephyrnet
- PLZ