Im Zeitalter von Big Data sind Unternehmen auf der ganzen Welt ständig auf der Suche nach innovativen Möglichkeiten, aus ihren riesigen Datenbeständen Mehrwert und Erkenntnisse zu gewinnen. Apache Funken bietet die nötige Skalierbarkeit und Geschwindigkeit, um große Datenmengen effizient zu verarbeiten.
Amazon EMR ist die branchenführende Cloud-Big-Data-Lösung für Datenverarbeitung im Petabyte-Bereich, interaktive Analysen und maschinelles Lernen (ML) unter Verwendung von Open-Source-Frameworks wie Apache Spark. Apache Hive und Presto. Amazon EMR ist der beste Ort, um Apache Spark auszuführen. Sie können schnell und mühelos verwaltete Spark-Cluster erstellen AWS-Managementkonsole, AWS-Befehlszeilenschnittstelle (AWS CLI) oder Amazon EMR API. Sie können auch zusätzliche Amazon EMR-Funktionen nutzen, einschließlich Fast Amazon Simple Storage-Service (Amazon S3) Konnektivität über das Amazon EMR File System (EMRFS), Integration mit dem Amazon EC2-Spot Markt und die AWS-Kleber Data Catalog und EMR Managed Scaling zum Hinzufügen oder Entfernen von Instanzen zu Ihrem Cluster. Amazon EMR-Studio ist eine integrierte Entwicklungsumgebung (IDE), die es Datenwissenschaftlern und Dateningenieuren erleichtert, Datentechnik und Datenwissenschaftsanwendungen, die in R, Python, Scala und PySpark geschrieben sind, zu entwickeln, zu visualisieren und zu debuggen. EMR Studio bietet vollständig verwaltete Jupyter-Notebooks und Tools wie Spark UI und YARN Timeline Service, um das Debuggen zu vereinfachen.
Um das in den Datenbeständen verborgene Potenzial auszuschöpfen, ist es wichtig, über die traditionelle Analyse hinauszugehen. Betreten Sie die generative KI, eine Spitzentechnologie, die ML mit Kreativität kombiniert, um menschenähnliche Texte, Grafiken und sogar Code zu generieren. Amazonas Grundgestein ist die einfachste Möglichkeit, generative KI-Anwendungen mit Basismodellen (FMs) zu erstellen und zu skalieren. Amazon Bedrock ist ein vollständig verwalteter Dienst, der FMs von Amazon und führenden KI-Unternehmen über eine API verfügbar macht, sodass Sie schnell mit einer Vielzahl von FMs auf dem Spielplatz experimentieren und eine einzige API für Schlussfolgerungen verwenden können, unabhängig von den von Ihnen gewählten Modellen Sie haben die Flexibilität, FMs verschiedener Anbieter zu nutzen und mit minimalen Codeänderungen über die neuesten Modellversionen auf dem Laufenden zu bleiben.
In diesem Beitrag untersuchen wir, wie Sie Ihre Datenanalysen mit generativer KI mithilfe von Amazon EMR, Amazon Bedrock und dem optimieren können pyspark-ai Bibliothek. Die pyspark-ai-Bibliothek ist ein englisches SDK für Apache Spark. Es nimmt Anweisungen in englischer Sprache entgegen und kompiliert sie in PySpark-Objekte wie DataFrames. Dies erleichtert die Arbeit mit Spark und ermöglicht Ihnen, sich auf die Wertschöpfung aus Ihren Daten zu konzentrieren.
Lösungsüberblick
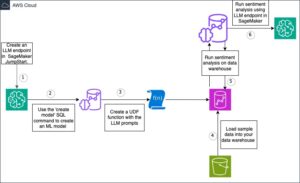
Das folgende Diagramm veranschaulicht die Architektur für die Verwendung generativer KI mit Amazon EMR und Amazon Bedrock.

EMR Studio ist eine webbasierte IDE für vollständig verwaltete Jupyter-Notebooks, die auf EMR-Clustern ausgeführt werden. Wir interagieren mit EMR Studio Workspaces, die mit einem laufenden EMR-Cluster verbunden sind, und führen das im Rahmen dieses Beitrags bereitgestellte Notebook aus. Wir benutzen das New Yorker Taxi Daten, um Einblicke in verschiedene Taxifahrten der Benutzer zu gewinnen. Wir stellen die Fragen in natürlicher Sprache zusätzlich zu den in Spark DataFrame geladenen Daten. Die pyspark-ai-Bibliothek verwendet dann den Amazon Titan Text FM von Amazon Bedrock, um eine SQL-Abfrage basierend auf der Frage in natürlicher Sprache zu erstellen. Die pyspark-ai-Bibliothek nimmt die SQL-Abfrage entgegen, führt sie mit Spark SQL aus und stellt dem Benutzer Ergebnisse zurück.
In dieser Lösung können Sie die erforderlichen Ressourcen in Ihrem AWS-Konto mit einem erstellen und konfigurieren AWS CloudFormation Vorlage. Die Vorlage erstellt die AWS-Kleber Datenbank und Tabellen, S3-Bucket, VPC und andere AWS Identity and Access Management and (IAM)-Ressourcen, die in der Lösung verwendet werden.
Die Vorlage soll die Verwendung von EMR Studio mit dem Paket pyspark-ai und Amazon Bedrock veranschaulichen und ist nicht für den Produktionseinsatz ohne Modifikation gedacht. Darüber hinaus verwendet die Vorlage die us-east-1 Region und funktioniert möglicherweise nicht ohne Änderung in anderen Regionen. Die Vorlage erstellt Ressourcen, die während ihrer Nutzung Kosten verursachen. Befolgen Sie die Bereinigungsschritte am Ende dieses Beitrags, um die Ressourcen zu löschen und unnötige Kosten zu vermeiden.
Voraussetzungen:
Bevor Sie den CloudFormation-Stack starten, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Ein AWS-Konto, das Zugriff auf AWS-Dienste bietet
- Ein IAM-Benutzer mit einem Zugriffsschlüssel und einem geheimen Schlüssel zum Konfigurieren der AWS CLI sowie Berechtigungen zum Erstellen einer IAM-Rolle, IAM-Richtlinien und Stacks in AWS CloudFormation
- Das Modell Titan Text G1 – Express befindet sich derzeit in der Vorschau, daher benötigen Sie Vorschauzugriff, um es im Rahmen dieses Beitrags verwenden zu können
Erstellen Sie Ressourcen mit AWS CloudFormation
Die CloudFormation erstellt die folgenden AWS-Ressourcen:
- Ein VPC-Stack mit privaten und öffentlichen Subnetzen zur Verwendung mit EMR Studio, Routing-Tabellen und NAT-Gateway.
- Ein EMR-Cluster mit installiertem Python 3.9. Wir verwenden eine Bootstrap-Aktion, um Python 3.9 und andere relevante Pakete wie pyspark-ai und Amazon Bedrock-Abhängigkeiten zu installieren. (Weitere Informationen finden Sie im Bootstrap-Skript.)
- Ein S3-Bucket für den EMR Studio Workspace und den Notebook-Speicher.
- IAM-Rollen und -Richtlinien für die Einrichtung von EMR Studio, den Zugriff auf Amazon Bedrock und die Ausführung von Notebooks
Führen Sie zunächst die folgenden Schritte aus:
- Auswählen
Stapel starten:

- Auswählen Ich erkenne an, dass diese Vorlage möglicherweise IAM-Ressourcen erstellt.
Die Fertigstellung des CloudFormation-Stacks dauert etwa 20–30 Minuten. Sie können den Fortschritt in der AWS CloudFormation-Konsole überwachen. Wenn der Status lautet CREATE_COMPLETEIhr AWS-Konto verfügt über die erforderlichen Ressourcen zur Implementierung dieser Lösung.
Erstellen Sie EMR Studio
Jetzt können Sie ein EMR Studio und einen Arbeitsbereich erstellen, um mit dem Notebook-Code zu arbeiten. Führen Sie die folgenden Schritte aus:
- Wählen Sie auf der EMR Studio-Konsole aus Studio erstellen.
- Geben Sie die Studioname as
GenAI-EMR-Studiound geben Sie eine Beschreibung ab. - Im Vernetzung und Sicherheit Geben Sie im Abschnitt Folgendes an:
- Aussichten für VPC, wählen Sie die VPC aus, die Sie als Teil des CloudFormation-Stacks erstellt haben, den Sie bereitgestellt haben. Rufen Sie die VPC-ID mithilfe der CloudFormation-Ausgaben für den VPCID-Schlüssel ab.
- Aussichten für Subnetze, wählen Sie alle vier Subnetze aus.
- Aussichten für Sicherheit und ZugangWählen Benutzerdefinierte Sicherheitsgruppe.
- Aussichten für Cluster-/Endpunkt-Sicherheitsgruppe, wählen
EMRSparkAI-Cluster-Endpoint-SG. - Aussichten für Arbeitsbereichssicherheitsgruppe, wählen
EMRSparkAI-Workspace-SG.
- Im Studio-Dienstrolle Geben Sie im Abschnitt Folgendes an:
- Aussichten für AuthentifizierungWählen AWS Identitäts- und Zugriffsverwaltung (IAM).
- Aussichten für AWS IAM-Servicerolle, wählen
EMRSparkAI-StudioServiceRole.
- Im Arbeitsplatzspeicher Durchsuchen Sie den Abschnitt und wählen Sie den S3-Bucket für die Speicherung aus
emr-sparkai-<account-id>. - Auswählen
Studio erstellen.

- Wenn das EMR Studio erstellt ist, wählen Sie den Link unten aus Studio-Zugriffs-URL um auf das Studio zuzugreifen.

- Wenn Sie im Studio sind, wählen Sie Arbeitsbereich erstellen.
- Speichern
emr-genaials Namen für den Arbeitsbereich und wählen Sie Arbeitsbereich erstellen. - Wenn der Arbeitsbereich erstellt wird, wählen Sie seinen Namen aus, um den Arbeitsbereich zu starten (stellen Sie sicher, dass Sie alle Popup-Blocker deaktiviert haben).

Big-Data-Analysen mit Apache Spark mit Amazon EMR und generativer KI
Nachdem wir nun die erforderliche Einrichtung abgeschlossen haben, können wir mit der Durchführung von Big-Data-Analysen mit Apache Spark mit Amazon EMR und generativer KI beginnen.
Als ersten Schritt laden wir ein Notebook, das den erforderlichen Code und Beispiele für die Arbeit mit dem Anwendungsfall enthält. Wir verwenden den Datensatz „NY Taxi“, der Details zu Taxifahrten enthält.
- Laden Sie die Notebook-Datei herunter NYTaxi.ipynb und laden Sie es in Ihren Arbeitsbereich hoch, indem Sie das Upload-Symbol auswählen.

- Nachdem das Notizbuch importiert wurde, öffnen Sie es und wählen Sie
PySparkals der Kernel.
PySpark KI Standardmäßig wird ChatGPT4.0 von OpenAI als LLM-Modell verwendet. Sie können jedoch auch Modelle von Amazon Bedrock einbinden. Amazon SageMaker-JumpStartund andere Modelle von Drittanbietern. In diesem Beitrag zeigen wir, wie Sie das Amazon Bedrock Titan-Modell für die SQL-Abfragegenerierung integrieren und mit Apache Spark in Amazon EMR ausführen.
- Um mit dem Notebook zu beginnen, müssen Sie den Arbeitsbereich einer Rechenschicht zuordnen. Wählen Sie dazu das aus Berechnen Symbol im Navigationsbereich und wählen Sie den vom CloudFormation-Stack erstellten EMR-Cluster aus.

- Konfigurieren Sie die Python-Parameter, um das aktualisierte Python 3.9-Paket mit Amazon EMR zu verwenden:
- Importieren Sie die erforderlichen Bibliotheken:
- Nachdem die Bibliotheken importiert wurden, können Sie das LLM-Modell aus Amazon Bedrock definieren. In diesem Fall verwenden wir amazon.titan-text-express-v1. Sie müssen die Region und die Amazon Bedrock-Endpunkt-URL basierend auf Ihrem Vorschauzugriff für das Titan Text G1 – Express-Modell eingeben.
- Verbinden Sie Spark AI mit dem Amazon Bedrock LLM-Modell für die Generierung von SQL-Abfragen basierend auf Fragen in natürlicher Sprache:
Hier haben wir Spark AI mit verbose=False; Sie können auch verbose=True festlegen, um weitere Details anzuzeigen.
Jetzt können Sie die NYC-Taxi-Daten in einem Spark-DataFrame lesen und die Leistungsfähigkeit der generativen KI in Spark nutzen.
- Sie können beispielsweise die Anzahl der Datensätze im Datensatz abfragen:
Wir erhalten folgende Antwort:
Spark AI verwendet intern LangChain und SQL-Kette, die die Komplexität vor Endbenutzern verbergen, die mit Abfragen in Spark arbeiten.
Das Notebook enthält einige weitere Beispielszenarien, um die Leistungsfähigkeit generativer KI mit Apache Spark und Amazon EMR zu erkunden.
Aufräumen
Leeren Sie den Inhalt des S3-Buckets emr-sparkai-<account-id>, löschen Sie den im Rahmen dieses Beitrags erstellten EMR Studio-Arbeitsbereich und löschen Sie dann den CloudFormation-Stack, den Sie bereitgestellt haben.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie Sie Ihre Big-Data-Analysen mithilfe von Apache Spark mit Amazon EMR und Amazon Bedrock optimieren können. Das PySpark AI-Paket ermöglicht es Ihnen, aus Ihren Daten aussagekräftige Erkenntnisse abzuleiten. Es trägt dazu bei, die Entwicklungs- und Analysezeit zu verkürzen, die Zeit zum Schreiben manueller Abfragen zu verkürzen und Ihnen die Möglichkeit zu geben, sich auf Ihren Geschäftsanwendungsfall zu konzentrieren.
Über die Autoren
 Saurabh Bhutyani ist Principal Analytics Specialist Solutions Architect bei AWS. Seine Leidenschaft gilt den neuen Technologien. Er kam 2019 zu AWS und arbeitet mit Kunden zusammen, um Architekturberatung für die Ausführung generativer KI-Anwendungsfälle, skalierbarer Analyselösungen und Datennetzarchitekturen mithilfe von AWS-Diensten wie Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation bereitzustellen. und Amazon DataZone.
Saurabh Bhutyani ist Principal Analytics Specialist Solutions Architect bei AWS. Seine Leidenschaft gilt den neuen Technologien. Er kam 2019 zu AWS und arbeitet mit Kunden zusammen, um Architekturberatung für die Ausführung generativer KI-Anwendungsfälle, skalierbarer Analyselösungen und Datennetzarchitekturen mithilfe von AWS-Diensten wie Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation bereitzustellen. und Amazon DataZone.
 Harter Vardhan ist ein AWS Senior Solutions Architect, spezialisiert auf Analysen. Er verfügt über mehr als 8 Jahre Erfahrung im Bereich Big Data und Data Science. Es ist ihm eine Leidenschaft, Kunden dabei zu helfen, Best Practices einzuführen und Erkenntnisse aus ihren Daten zu gewinnen.
Harter Vardhan ist ein AWS Senior Solutions Architect, spezialisiert auf Analysen. Er verfügt über mehr als 8 Jahre Erfahrung im Bereich Big Data und Data Science. Es ist ihm eine Leidenschaft, Kunden dabei zu helfen, Best Practices einzuführen und Erkenntnisse aus ihren Daten zu gewinnen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/use-generative-ai-with-amazon-emr-amazon-bedrock-and-english-sdk-for-apache-spark-to-unlock-insights/
- :hast
- :Ist
- :nicht
- $UP
- 1
- 10
- 100
- 107
- 11
- 20
- 200
- 2019
- 320
- 500
- 521
- 7
- 8
- 9
- 990
- a
- Über Uns
- Zugang
- Konto
- anerkennen
- Action
- hinzufügen
- Zusätzliche
- zusätzlich
- adoptieren
- AI
- KI-Anwendungsfälle
- Alle
- Zulassen
- erlaubt
- ebenfalls
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Sage Maker
- Amazon Web Services
- Beträge
- an
- Analyse
- Analytik
- und
- beantworten
- jedem
- Apache
- Apache Funken
- Bienen
- Anwendungen
- ca.
- architektonisch
- Architektur
- SIND
- Kunst
- AS
- fragen
- Partnerschaftsräte
- At
- verfügbar
- vermeiden
- AWS
- AWS CloudFormation
- AWS-Kleber
- AWS Lake-Formation
- Zurück
- basierend
- BESTE
- Best Practices
- Beyond
- Big
- Big Data
- Bootstrap
- bauen
- Geschäft
- aber
- Taste im nun erscheinenden Bestätigungsfenster nun wieder los.
- by
- CAN
- Häuser
- Fälle
- Katalog
- Kette
- Änderungen
- Gebühren
- Auswählen
- Auswahl
- Stadt
- Cloud
- Cloud-Big-Data
- Cluster
- Code
- vereint
- Unternehmen
- abschließen
- Abgeschlossene Verkäufe
- Komplexität
- Berechnen
- Sie
- Konnektivität
- Konsul (Console)
- ständig
- enthält
- Inhalt
- Kosten
- erstellen
- erstellt
- schafft
- Kreativität
- Zur Zeit
- Kunden
- innovativ, auf dem neuesten Stand
- technische Daten
- Datenanalyse
- Datenverarbeitung
- Datenwissenschaft
- Datenbase
- Datensätze
- Datum
- Standard
- definieren
- zeigen
- Abhängigkeiten
- Einsatz
- ableiten
- Beschreibung
- entworfen
- Details
- entwickeln
- Entwicklung
- anders
- behindert
- entdeckt,
- do
- effizient
- mühelos
- Ende
- Endpunkt
- Entwicklung
- Ingenieure
- Englisch
- gewährleisten
- Enter
- Eingabe
- Arbeitsumfeld
- Era
- essential
- Äther (ETH)
- Sogar
- Beispiel
- Beispiele
- ERFAHRUNGEN
- Experiment
- ERKUNDEN
- express
- Extrakt
- FAST
- Eigenschaften
- wenige
- Feld
- Reichen Sie das
- Finale
- Vorname
- Flexibilität
- Setzen Sie mit Achtsamkeit
- folgen
- Folgende
- Aussichten für
- Ausbildung
- Foundation
- vier
- Gerüste
- für
- voll
- g1
- sammler
- Tor
- erzeugen
- Generation
- generativ
- Generative KI
- bekommen
- Unterstützung
- Go
- die Vermittlung von Kompetenzen,
- Haben
- he
- Hilfe
- Unternehmen
- hilft
- versteckt
- Verbergen
- Ultraschall
- Hilfe
- http
- HTTPS
- i
- IAM
- ICON
- ID
- Identitätsschutz
- Identitäts- und Zugriffsverwaltung
- zeigt
- implementieren
- importieren
- in
- In anderen
- Einschließlich
- branchenführend
- Information
- innovativ
- Varianten des Eingangssignals:
- Einblicke
- installieren
- Instanzen
- Anleitung
- integrieren
- integriert
- Integration
- beabsichtigt
- interagieren
- interaktive
- innen
- in
- IT
- SEINE
- beigetreten
- jpg
- Behalten
- Wesentliche
- Wissen
- See
- Sprache
- grosse
- neueste
- starten
- Schicht
- führenden
- lernen
- Bibliotheken
- Bibliothek
- Gefällt mir
- Line
- LINK
- Belastung
- Maschine
- Maschinelles Lernen
- um
- MACHT
- verwaltet
- Management
- manuell
- Markt
- Kann..
- sinnvoll
- ineinander greifen
- minimal
- Minuten
- ML
- Modell
- für
- Überwachen
- mehr
- vor allem warme
- Name
- Natürliche
- Natürliche Sprache
- Menü
- notwendig,
- Need
- erforderlich
- Vernetzung
- Neu
- Neue Technologien
- Notizbuch
- Laptops
- jetzt an
- Anzahl
- NY
- NYC
- Objekte
- Beobachtung
- of
- Angebote
- on
- XNUMXh geöffnet
- Open-Source-
- or
- Organisationen
- Andere
- Ausgänge
- übrig
- Überblick
- Paket
- Pakete
- Brot
- Parameter
- Teil
- leidenschaftlich
- Durchführung
- Berechtigungen
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- Spielplatz
- Stecker
- Politik durchzulesen
- Pop-up
- Post
- Potenzial
- Werkzeuge
- Praktiken
- Vorspann
- Principal
- privat
- Prozessdefinierung
- Verarbeitung
- Produktion
- Fortschritt
- die
- vorausgesetzt
- Anbieter
- bietet
- Öffentlichkeit
- Python
- Abfragen
- Frage
- Fragen
- schnell
- R
- Lesen Sie mehr
- Aufzeichnungen
- Veteran
- Reduzierung
- siehe
- Ungeachtet
- Region
- Regionen
- relevant
- entfernen
- falls angefordert
- Downloads
- Antwort
- Die Ergebnisse
- Fahrten
- Rollen
- Rollen
- Straße
- Führen Sie
- Laufen
- läuft
- sagemaker
- Scala
- Skalierbarkeit
- skalierbaren
- Skalieren
- Skalierung
- Szenarien
- Wissenschaft
- Wissenschaftler
- Sdk
- Suche
- Die Geheime
- Sicherheitdienst
- sehen
- wählen
- Senior
- Lösungen
- kompensieren
- Setup
- erklären
- zeigte
- Einfacher
- vereinfachen
- Single
- So
- Lösung
- Lösungen
- Quelle
- Spark
- Spezialist
- spezialisieren
- Geschwindigkeit
- SQL
- Stapel
- Stacks
- Anfang
- begonnen
- Beginnen Sie
- Status
- Schritt
- Shritte
- Lagerung
- einfach
- Studio Adressen
- Subnetze
- so
- Aufladung
- sicher
- System
- Tabelle
- gemacht
- nimmt
- Technologies
- Technologie
- Vorlage
- Text
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- vom Nutzer definierten
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- fehlen uns die Worte.
- dachte
- Durch
- Zeit
- Timeline
- Titan
- zu
- Werkzeuge
- Top
- traditionell
- ui
- für
- öffnen
- aktualisiert
- URL
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- Wert
- Vielfalt
- verschiedene
- riesig
- visualisieren
- Weg..
- Wege
- we
- Netz
- Web-Services
- Webbasiert
- wann
- welche
- während
- werden wir
- mit
- .
- ohne
- Arbeiten
- arbeiten,
- Werk
- Das weltweit
- schreiben
- geschrieben
- Jahr
- York
- U
- Ihr
- Zephyrnet