Bild vom Autor
Es gibt viele Kurse und Ressourcen zum Thema maschinelles Lernen und Datenwissenschaft, aber nur sehr wenige zum Thema Datentechnik. Dies wirft einige Fragen auf. Ist es ein schwieriges Feld? Bietet es niedrige Löhne? Wird es nicht als genauso spannend angesehen wie andere Tech-Rollen? Die Realität sieht jedoch so aus, dass viele Unternehmen aktiv nach Data-Engineering-Talenten suchen und hohe Gehälter anbieten, die manchmal über 200,000 US-Dollar liegen. Dateningenieure spielen eine entscheidende Rolle als Architekten von Datenplattformen, indem sie die grundlegenden Systeme entwerfen und aufbauen, die es Datenwissenschaftlern und Experten für maschinelles Lernen ermöglichen, effektiv zu funktionieren.
Um diese Branchenlücke zu schließen, hat DataTalkClub ein transformatives und kostenloses Bootcamp eingeführt: „Data-Engineering-Zoomcamp„. Dieser Kurs soll Einsteigern und Profis, die ihre Karriere wechseln möchten, grundlegende Fähigkeiten und praktische Erfahrungen im Bereich Data Engineering vermitteln.
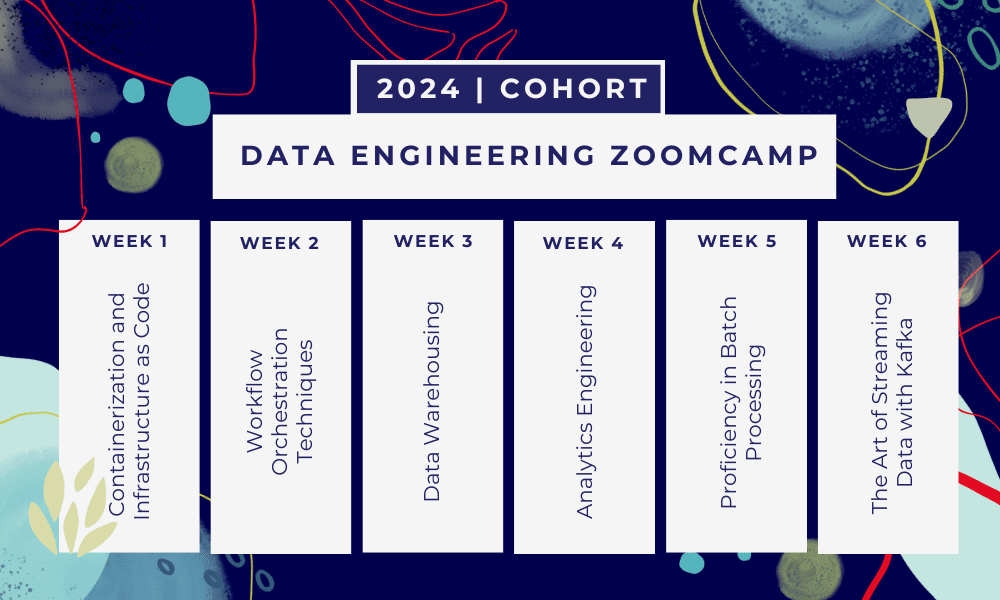
Dieser Kurs ist ein 6-wöchiges Bootcamp Hier lernen Sie in mehreren Kursen, Lesematerialien, Workshops und Projekten. Am Ende jedes Moduls erhalten Sie Hausaufgaben, mit denen Sie das Gelernte üben können.
- Woche 1: Einführung in GCP, Docker, Postgres, Terraform und Umgebungseinrichtung.
- Woche 2: Workflow-Orchestrierung mit Mage.
- Woche 3: Data Warehousing mit BigQuery und maschinelles Lernen mit BigQuery.
- Woche 4: Analytischer Ingenieur mit dbt, Google Data Studio und Metabase.
- Woche 5: Stapelverarbeitung mit Spark.
- Woche 6: Streaming mit Kafka.
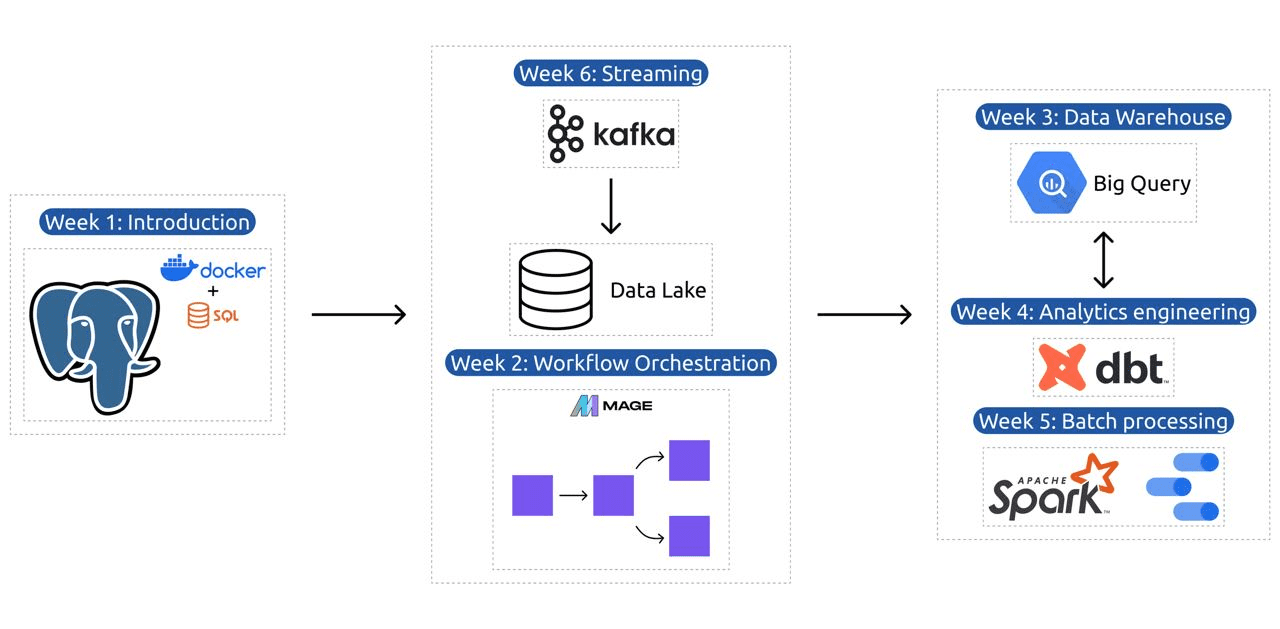
Bild aus DataTalksClub/data-engineering-zoomcamp
Der Lehrplan umfasst 6 Module, 2 Workshops und ein Projekt, das alles abdeckt, was Sie für die Ausbildung zum professionellen Dateningenieur benötigen.
Modul 1: Containerisierung und Infrastruktur als Code beherrschen
In diesem Modul lernen Sie Docker und Postgres kennen, angefangen bei den Grundlagen bis hin zu detaillierten Tutorials zum Erstellen von Datenpipelines, zum Ausführen von Postgres mit Docker und mehr.
Das Modul deckt auch wichtige Tools wie pgAdmin, Docker-Compose und SQL-Auffrischungsthemen ab, mit optionalen Inhalten zum Docker-Netzwerk und einer speziellen Anleitung für Linux-Benutzer des Windows-Subsystems. Am Ende führt Sie der Kurs in GCP und Terraform ein und vermittelt ein ganzheitliches Verständnis der Containerisierung und Infrastruktur als Code, die für moderne Cloud-basierte Umgebungen unerlässlich sind.
Modul 2: Techniken zur Workflow-Orchestrierung
Das Modul bietet eine detaillierte Untersuchung von Mage, einem innovativen Open-Source-Hybrid-Framework für Datentransformation und -integration. Dieses Modul beginnt mit den Grundlagen der Workflow-Orchestrierung und führt dann zu praktischen Übungen mit Mage, einschließlich der Einrichtung über Docker und dem Aufbau von ETL-Pipelines von der API zu Postgres und Google Cloud Storage (GCS) und dann zu BigQuery.
Die Mischung aus Videos, Ressourcen und praktischen Aufgaben des Moduls sorgt für ein umfassendes Lernerlebnis und vermittelt den Lernenden die Fähigkeiten, anspruchsvolle Daten-Workflows mit Mage zu verwalten.
Workshop 1: Strategien zur Datenaufnahme
Im ersten Workshop beherrschen Sie den Aufbau effizienter Datenaufnahme-Pipelines. Der Workshop konzentriert sich auf grundlegende Fähigkeiten wie das Extrahieren von Daten aus APIs und Dateien, das Normalisieren und Laden von Daten sowie inkrementelle Ladetechniken. Nach Abschluss dieses Workshops sind Sie in der Lage, wie ein Senior Data Engineer effiziente Datenpipelines zu erstellen.
Modul 3: Data Warehousing
Das Modul befasst sich eingehend mit der Datenspeicherung und -analyse und konzentriert sich auf Data Warehousing mit BigQuery. Es behandelt Schlüsselkonzepte wie Partitionierung und Clustering und geht auf die Best Practices von BigQuery ein. Das Modul befasst sich mit fortgeschrittenen Themen, insbesondere der Integration von maschinellem Lernen (ML) mit BigQuery, wobei die Verwendung von SQL für ML hervorgehoben wird und Ressourcen zur Optimierung von Hyperparametern, zur Funktionsvorverarbeitung und zur Modellbereitstellung bereitgestellt werden.
Modul 4: Analytics Engineering
Das Analyse-Engineering-Modul konzentriert sich auf die Erstellung eines Projekts mithilfe von dbt (Data Build Tool) mit einem vorhandenen Data Warehouse, entweder BigQuery oder PostgreSQL.
Das Modul umfasst die Einrichtung von dbt sowohl in Cloud- als auch lokalen Umgebungen, die Einführung von Analytics-Engineering-Konzepten, ETL vs. ELT und Datenmodellierung. Es behandelt auch erweiterte DBT-Funktionen wie inkrementelle Modelle, Tags, Hooks und Snapshots.
Abschließend stellt das Modul Techniken zur Visualisierung transformierter Daten mithilfe von Tools wie Google Data Studio und Metabase vor und bietet Ressourcen zur Fehlerbehebung und zum effizienten Laden von Daten.
Modul 5: Kenntnisse in der Stapelverarbeitung
Dieses Modul behandelt die Stapelverarbeitung mit Apache Spark, beginnend mit Einführungen in die Stapelverarbeitung und Spark sowie Installationsanweisungen für Windows, Linux und MacOS.
Es umfasst die Erkundung von Spark SQL und DataFrames, die Vorbereitung von Daten, die Durchführung von SQL-Operationen und das Verständnis der Spark-Interna. Schließlich endet es mit der Ausführung von Spark in der Cloud und der Integration von Spark in BigQuery.
Modul 6: Die Kunst des Daten-Streamings mit Kafka
Das Modul beginnt mit einer Einführung in Stream-Processing-Konzepte, gefolgt von einer ausführlichen Untersuchung von Kafka, einschließlich seiner Grundlagen, der Integration mit Confluent Cloud und praktischen Anwendungen unter Einbeziehung von Produzenten und Verbrauchern.
Das Modul behandelt auch die Kafka-Konfiguration und -Streams und behandelt Themen wie Stream-Joins, Tests, Windowing und die Verwendung von Kafka ksqldb & Connect. Darüber hinaus erweitert es seinen Fokus auf Python- und JVM-Umgebungen und bietet Faust für die Python-Stream-Verarbeitung, Pyspark – Structured Streaming und Scala-Beispiele für Kafka-Streams.
Workshop 2: Stream-Verarbeitung mit SQL
Sie lernen, Streaming-Daten mit RisingWave zu verarbeiten und zu verwalten, das eine kosteneffiziente Lösung mit einem PostgreSQL-ähnlichen Erlebnis bietet, um Ihre Stream-Verarbeitungsanwendungen zu stärken.
Projekt: Reale Data-Engineering-Anwendung
Das Ziel dieses Projekts besteht darin, alle Konzepte, die wir in diesem Kurs gelernt haben, umzusetzen, um eine End-to-End-Datenpipeline aufzubauen. Sie erstellen ein Dashboard, das aus zwei Kacheln besteht, indem Sie einen Datensatz auswählen, eine Pipeline für die Verarbeitung der Daten und deren Speicherung in einem Data Lake erstellen, eine Pipeline für die Übertragung der verarbeiteten Daten vom Data Lake in ein Data Warehouse erstellen und transformieren die Daten im Data Warehouse und bereiten sie für das Dashboard vor und erstellen schließlich ein Dashboard, um die Daten visuell darzustellen.
Kohortendetails 2024
- Anmeldung: Melde dich jetzt an
- Startdatum: 15. Januar 2024, 17:00 Uhr MEZ
- Selbstgesteuertes Lernen mit angeleiteter Unterstützung
- Kohortenordner mit Hausaufgaben und Fristen
- Interaktiv Slack-Community für Peer-Learning
Voraussetzungen:
- Grundlegende Programmier- und Befehlszeilenkenntnisse
- Grundlage in SQL
- Python: vorteilhaft, aber nicht zwingend erforderlich
Erfahrene Ausbilder begleiten Sie auf Ihrer Reise
- Ankush Khanna
- Victoria Perez Mola
- Alexej Grigorew
- Matt Palmer
- Luis Oliveira
- Michael Schuhmacher
Treten Sie unserer Kohorte 2024 bei und beginnen Sie mit einer großartigen Data-Engineering-Community zu lernen. Mit von Experten geleiteten Schulungen, praktischer Erfahrung und einem auf die Bedürfnisse der Branche zugeschnittenen Lehrplan vermittelt Ihnen dieses Bootcamp nicht nur die erforderlichen Fähigkeiten, sondern positioniert Sie auch an der Spitze einer lukrativen und gefragten Karriere. Melden Sie sich noch heute an und setzen Sie Ihre Wünsche in die Realität um!
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, Modelle für maschinelles Lernen zu erstellen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und schreibt technische Blogs zu maschinellem Lernen und Data-Science-Technologien. Abid hat einen Master-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Vision ist es, ein KI-Produkt mit einem grafisch-neuronalen Netzwerk für Schüler zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 1
- 15%
- 17
- 2024
- a
- Fähig
- Über uns
- aktiv
- zusätzlich
- Adressierung
- advanced
- Vorrückend
- Nach der
- AI
- Alle
- entlang
- ebenfalls
- erstaunlich
- an
- Analyse
- Analytische
- Analytik
- und
- und Infrastruktur
- Apache
- Apache Funken
- Bienen
- APIs
- Anwendungen
- Architekten
- SIND
- Kunst
- AS
- At
- verfügbar
- Grundlagen
- BE
- werden
- Werden
- Anfänger
- vorteilhaft
- BESTE
- Best Practices
- Bigquery
- Blend
- Blogs
- beide
- bauen
- Building
- aber
- by
- Karriere
- Karriere
- Zertifzierte
- Cloud
- Cloud-Speicher
- Clustering
- Code
- Programmierung
- Kohorte
- community
- Unternehmen
- Abschluss
- umfassend
- Konzepte
- schließt ab
- Konfiguration
- Confluent
- Vernetz Dich
- betrachtet
- Bestehend
- konstruieren
- KUNDEN
- enthält
- Inhalt
- Inhaltserstellung
- Kurs
- Kurse
- deckt
- erstellen
- Erstellen
- Schaffung
- wichtig
- Zur Zeit
- Curriculum
- Armaturenbrett
- technische Daten
- Dateningenieur
- Datensee
- Datenwissenschaft
- Datenwissenschaftler
- Datenspeichervorrichtung
- Data Warehouse
- Datum
- Grad
- Einsatz
- entworfen
- Entwerfen
- detailliert
- schwer
- Docker
- jeder
- effektiv
- effizient
- entweder
- ermächtigen
- ermöglichen
- Ende
- End-to-End
- Ingenieur
- Entwicklung
- Ingenieure
- einschreiben
- sorgt
- Arbeitsumfeld
- Umgebungen
- essential
- Äther (ETH)
- alles
- Beispiele
- unterhaltsame Programmpunkte
- vorhandenen
- ERFAHRUNGEN
- Experten
- Exploration
- Möglichkeiten sondieren
- erweitert
- Merkmal
- Eigenschaften
- Einzigartige
- wenige
- Feld
- Mappen
- Endlich
- Vorname
- Setzen Sie mit Achtsamkeit
- konzentriert
- Fokussierung
- gefolgt
- Aussichten für
- Vordergrund
- Grundlegender
- Unser Ansatz
- Frei
- für
- Funktion
- Grundlagen
- Lücke
- GCP
- gegeben
- Cumolocity
- Graph
- Graph Neuronales Netzwerk
- geführt
- praktische
- Haben
- he
- Hervorheben
- seine
- hält
- ganzheitliche
- Hausaufgaben
- Haken
- aber
- HTTPS
- Hybrid
- Hyperparameter-Tuning
- Krankheit
- implementieren
- in
- eingehende
- Dazu gehören
- Einschließlich
- inkremental
- Energiegewinnung
- Infrastruktur
- innovativ
- Installation
- Anleitung
- Integration
- Integration
- in
- eingeführt
- Stellt vor
- Einführung
- Einleitung
- Einführungen
- Beteiligung
- IT
- SEINE
- Januar
- Joins
- kafka
- KDnuggets
- Wesentliche
- See
- führenden
- LERNEN
- gelernt
- Lerner
- lernen
- Gefällt mir
- Line
- linux
- Laden
- aus einer regionalen
- suchen
- liebt
- Sneaker
- lukrativ
- Maschine
- Maschinelles Lernen
- MacOS
- verwalten
- Management
- Alle Tauchgäste müssen eine Tauchversicherung vorweisen,
- viele
- Master
- Mastering
- Materialien
- geistig
- Geisteskrankheit
- ML
- Modell
- Modellieren
- für
- modern
- Modulen
- Module
- mehr
- mehrere
- notwendig,
- Need
- erforderlich
- Bedürfnisse
- Netzwerk
- Vernetzung
- Neural
- neuronale Netzwerk
- Ziel
- of
- bieten
- Angebote
- on
- einzige
- Open-Source-
- Einkauf & Prozesse
- or
- Orchesterbearbeitung
- Andere
- UNSERE
- Palmer
- besonders
- Weg
- AUFMERKSAMKEIT
- Peer
- Durchführung
- Pipeline
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- für einige Positionen
- Postgresql
- Praktisch
- Praktische Anwendungen
- Praxis
- Praktiken
- Vorbereitung
- Gegenwart
- Prozessdefinierung
- verarbeitet
- Verarbeitung
- Producers
- Produkt
- Professionell
- Profis
- Fortschritt
- Projekt
- Projekte
- bietet
- Bereitstellung
- Python
- Fragen
- wirft
- Lesebrillen
- realen Welt
- Realität
- Downloads
- Rollen
- Rollen
- Laufen
- s
- Gehälter
- Scala
- Wissenschaft
- Wissenschaftler
- Wissenschaftler
- auf der Suche nach
- Auswahl
- Senior
- Einstellung
- Setup
- Fähigkeiten
- locker
- Lösung
- einige
- manchmal
- anspruchsvoll
- Spark
- besondere
- SQL
- Anfang
- Beginnen Sie
- Lagerung
- Strom
- Streaming
- Ströme
- strukturierte
- Struggling
- Die Kursteilnehmer
- Studio Adressen
- wesentlich
- so
- Support
- Schalter
- Systeme und Techniken
- zugeschnitten
- Athleten
- und Aufgaben
- Tech
- Technische
- Techniken
- Technologies
- Technologie
- Telekommunikations
- Terraform
- Testen
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Grundlagen
- dann
- fehlen uns die Worte.
- Durch
- zu
- heute
- Werkzeug
- Werkzeuge
- Themen
- Ausbildung
- Übertragen
- Transformieren
- Transformation
- Transformativ
- verwandelt
- Transformieren
- Tutorials
- XNUMX
- Verständnis
- USD
- -
- Nutzer
- Verwendung von
- Ve
- sehr
- Videos
- Seh-
- visuell
- vs
- Warehouse
- Lagerung
- we
- Was
- welche
- WHO
- werden wir
- Fenster
- mit
- Arbeitsablauf.
- Workflows
- Werkstatt
- Workshops
- Schreiben
- U
- Ihr
- Zephyrnet










