In den letzten Jahren haben Large Language Models (LLMs) als herausragende Werkzeuge an Bedeutung gewonnen, die in der Lage sind, Texte mit beispielloser Kompetenz zu verstehen, zu generieren und zu bearbeiten. Ihre potenziellen Anwendungen reichen von Konversationsagenten bis hin zur Inhaltserstellung und dem Informationsabruf und versprechen, alle Branchen zu revolutionieren. Die Nutzung dieses Potenzials bei gleichzeitiger Gewährleistung der verantwortungsvollen und effektiven Nutzung dieser Modelle hängt jedoch vom entscheidenden Prozess der LLM-Bewertung ab. Eine Evaluierung ist eine Aufgabe zur Messung der Qualität und Verantwortung der Ergebnisse eines LLM- oder generativen KI-Dienstes. Bei der Bewertung von LLMs geht es nicht nur um den Wunsch, die Leistung eines Modells zu verstehen, sondern auch um die Notwendigkeit, verantwortungsvolle KI zu implementieren und das Risiko der Bereitstellung von Fehlinformationen oder voreingenommenen Inhalten zu verringern und die Entstehung schädlicher, unsicherer, böswilliger und unethischer Inhalte zu minimieren Inhalt. Darüber hinaus kann die Evaluierung von LLMs auch dazu beitragen, Sicherheitsrisiken zu mindern, insbesondere im Zusammenhang mit zeitnahen Datenmanipulationen. Bei LLM-basierten Anwendungen ist es von entscheidender Bedeutung, Schwachstellen zu identifizieren und Schutzmaßnahmen zu implementieren, die vor potenziellen Verstößen und unbefugten Manipulationen von Daten schützen.
Durch die Bereitstellung wesentlicher Tools zur Evaluierung von LLMs mit einer unkomplizierten Konfiguration und einem Ein-Klick-Ansatz, Amazon SageMaker klären Die LLM-Evaluierungsfunktionen gewähren Kunden Zugang zu den meisten der oben genannten Vorteile. Mit diesen Tools besteht die nächste Herausforderung darin, die LLM-Bewertung in den Lebenszyklus von Machine Learning and Operation (MLOps) zu integrieren, um Automatisierung und Skalierbarkeit im Prozess zu erreichen. In diesem Beitrag zeigen wir Ihnen, wie Sie die Amazon SageMaker Clarify LLM-Bewertung mit Amazon SageMaker Pipelines integrieren, um eine LLM-Bewertung im großen Maßstab zu ermöglichen. Darüber hinaus stellen wir hier ein Codebeispiel zur Verfügung GitHub Repository, um den Benutzern die Durchführung paralleler Multi-Modell-Bewertungen im großen Maßstab zu ermöglichen, unter Verwendung von Beispielen wie Llama2-7b-f, Falcon-7b und fein abgestimmten Llama2-7b-Modellen.
Wer muss eine LLM-Bewertung durchführen?
Jeder, der ein vorab trainiertes LLM trainiert, verfeinert oder einfach verwendet, muss es genau auswerten, um das Verhalten der von diesem LLM unterstützten Anwendung beurteilen zu können. Basierend auf diesem Grundsatz können wir Benutzer generativer KI, die LLM-Evaluierungsfunktionen benötigen, in drei Gruppen einteilen, wie in der folgenden Abbildung dargestellt: Modellanbieter, Feinabstimmungsgeräte und Verbraucher.
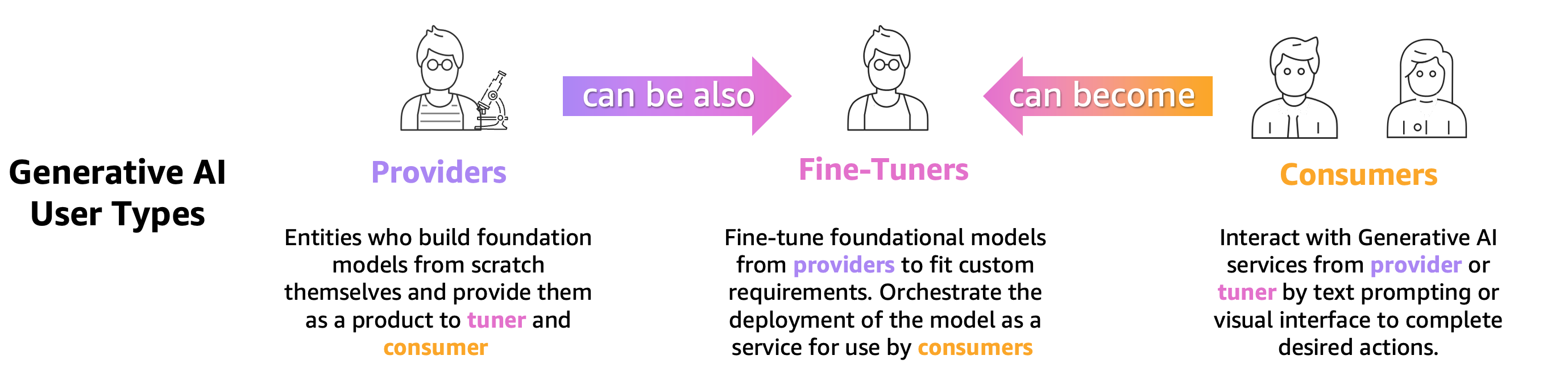
- Anbieter des Foundational Model (FM). Trainieren Sie Modelle, die für allgemeine Zwecke geeignet sind. Diese Modelle können für viele nachgelagerte Aufgaben verwendet werden, beispielsweise zur Merkmalsextraktion oder zum Generieren von Inhalten. Jedes trainierte Modell muss mit vielen Aufgaben verglichen werden, nicht nur um seine Leistung zu bewerten, sondern auch um es mit anderen vorhandenen Modellen zu vergleichen, um Bereiche zu identifizieren, die verbessert werden müssen, und schließlich um die Fortschritte auf diesem Gebiet im Auge zu behalten. Modellanbieter müssen außerdem das Vorhandensein etwaiger Verzerrungen prüfen, um die Qualität des Ausgangsdatensatzes und das korrekte Verhalten ihres Modells sicherzustellen. Das Sammeln von Evaluierungsdaten ist für Modellanbieter von entscheidender Bedeutung. Darüber hinaus müssen diese Daten und Kennzahlen erfasst werden, um künftige Vorschriften einzuhalten. ISO 42001 , der Executive Order der Biden-Administration und EU-KI-Gesetz Entwickeln Sie Standards, Tools und Tests, um sicherzustellen, dass KI-Systeme sicher und vertrauenswürdig sind. Beispielsweise hat das EU-KI-Gesetz die Aufgabe, Informationen darüber bereitzustellen, welche Datensätze für das Training verwendet werden, welche Rechenleistung zum Ausführen des Modells erforderlich ist, Modellergebnisse anhand öffentlicher/industrieller Standard-Benchmarks zu melden und Ergebnisse interner und externer Tests auszutauschen.
- Modell Feinstimmer bestimmte Aufgaben lösen möchten (z. B. Stimmungsklassifizierung, Zusammenfassung, Beantwortung von Fragen) sowie vortrainierte Modelle zur Übernahme domänenspezifischer Aufgaben. Sie benötigen von Modellanbietern generierte Bewertungsmetriken, um das richtige vorab trainierte Modell als Ausgangspunkt auszuwählen.
Sie müssen ihre fein abgestimmten Modelle anhand ihres gewünschten Anwendungsfalls mit aufgabenspezifischen oder domänenspezifischen Datensätzen bewerten. Häufig müssen sie ihre privaten Datensätze kuratieren und erstellen, da öffentlich verfügbare Datensätze, selbst solche, die für eine bestimmte Aufgabe entwickelt wurden, die für ihren jeweiligen Anwendungsfall erforderlichen Nuancen möglicherweise nicht ausreichend erfassen.
Die Feinabstimmung ist schneller und kostengünstiger als eine vollständige Schulung und erfordert eine schnellere operative Iteration für die Bereitstellung und das Testen, da in der Regel viele Kandidatenmodelle generiert werden. Die Auswertung dieser Modelle ermöglicht eine kontinuierliche Modellverbesserung, Kalibrierung und Fehlerbehebung. Beachten Sie, dass Feinabstimmungsspezialisten zu Konsumenten ihrer eigenen Modelle werden können, wenn sie reale Anwendungen entwickeln. - Modell Verbraucher oder Modellbereitsteller bedienen und überwachen allgemeine oder fein abgestimmte Modelle in der Produktion mit dem Ziel, ihre Anwendungen oder Dienste durch die Einführung von LLMs zu verbessern. Die erste Herausforderung für sie besteht darin, sicherzustellen, dass das gewählte LLM ihren spezifischen Bedürfnissen, Kosten und Leistungserwartungen entspricht. Die Interpretation und das Verständnis der Ergebnisse des Modells sind ein anhaltendes Problem, insbesondere wenn es um Datenschutz und Datensicherheit geht (z. B. für die Prüfung von Risiken und Compliance in regulierten Branchen wie dem Finanzsektor). Eine kontinuierliche Modellbewertung ist von entscheidender Bedeutung, um die Verbreitung von Vorurteilen oder schädlichen Inhalten zu verhindern. Durch die Implementierung eines robusten Überwachungs- und Bewertungsrahmens können Modellkonsumenten Regressionen in LLMs proaktiv erkennen und angehen und so sicherstellen, dass diese Modelle ihre Wirksamkeit und Zuverlässigkeit im Laufe der Zeit beibehalten.
So führen Sie eine LLM-Bewertung durch
Eine effektive Modellbewertung umfasst drei grundlegende Komponenten: ein oder mehrere FMs oder fein abgestimmte Modelle zur Bewertung der Eingabedatensätze (Eingabeaufforderungen, Gespräche oder regelmäßige Eingaben) und die Bewertungslogik.
Um die Modelle für die Bewertung auszuwählen, müssen verschiedene Faktoren berücksichtigt werden, darunter Dateneigenschaften, Problemkomplexität, verfügbare Rechenressourcen und das gewünschte Ergebnis. Der Eingabedatenspeicher stellt die Daten bereit, die zum Trainieren, Feinabstimmen und Testen des ausgewählten Modells erforderlich sind. Es ist wichtig, dass dieser Datenspeicher gut strukturiert, repräsentativ und von hoher Qualität ist, da die Leistung des Modells stark von den Daten abhängt, aus denen es lernt. Schließlich definieren Bewertungslogiken die Kriterien und Metriken, die zur Bewertung der Modellleistung verwendet werden.
Zusammen bilden diese drei Komponenten einen zusammenhängenden Rahmen, der die strenge und systematische Bewertung von Modellen für maschinelles Lernen gewährleistet und letztendlich zu fundierten Entscheidungen und Verbesserungen der Modelleffektivität führt.
Modellbewertungstechniken sind nach wie vor ein aktives Forschungsgebiet. Viele öffentliche Benchmarks und Frameworks wurden in den letzten Jahren von der Forschergemeinschaft erstellt, um ein breites Spektrum an Aufgaben und Szenarien abzudecken, wie z KLEBER, Sekundenkleber, HELM, MMLU und BIG-Bank. Diese Benchmarks verfügen über Bestenlisten, mit denen bewertete Modelle verglichen und gegenübergestellt werden können. Benchmarks wie HELM zielen auch darauf ab, Metriken zu bewerten, die über Genauigkeitsmaße wie Präzision oder F1-Score hinausgehen. Der HELM-Benchmark umfasst Metriken für Fairness, Bias und Toxizität, die für die Gesamtbewertung des Modells gleichermaßen wichtig sind.
Alle diese Benchmarks umfassen eine Reihe von Metriken, die messen, wie das Modell bei einer bestimmten Aufgabe abschneidet. Die bekanntesten und gebräuchlichsten Metriken sind ROT (Rückruforientierte Zweitbesetzung zur Gisting-Bewertung), BLAU (BiLingual Evaluation Understudy), oder METEOR (Metrik zur Bewertung der Übersetzung mit expliziter ORdering). Diese Metriken dienen als nützliches Werkzeug für die automatisierte Auswertung und liefern quantitative Maße für die lexikalische Ähnlichkeit zwischen generiertem Text und Referenztext. Sie erfassen jedoch nicht die gesamte Bandbreite der menschenähnlichen Sprachgenerierung, einschließlich semantischem Verständnis, Kontext oder stilistischen Nuancen. HELM bietet beispielsweise keine Evaluierungsdetails, die für bestimmte Anwendungsfälle relevant sind, keine Lösungen zum Testen benutzerdefinierter Eingabeaufforderungen und keine leicht interpretierbaren Ergebnisse, die von Nicht-Experten verwendet werden können, da der Prozess kostspielig, nicht einfach zu skalieren und nur für bestimmte Aufgaben geeignet sein kann.
Darüber hinaus erfordert die Erzielung einer menschenähnlichen Sprachgenerierung häufig die Einbeziehung von Human-in-the-Loop, um qualitative Bewertungen und menschliches Urteilsvermögen zu liefern, die die automatisierten Genauigkeitsmetriken ergänzen. Die menschliche Bewertung ist eine wertvolle Methode zur Bewertung von LLM-Ergebnissen, sie kann jedoch auch subjektiv und anfällig für Voreingenommenheit sein, da verschiedene menschliche Bewerter möglicherweise unterschiedliche Meinungen und Interpretationen zur Textqualität haben. Darüber hinaus kann die menschliche Beurteilung ressourcenintensiv und kostspielig sein und viel Zeit und Mühe erfordern.
Lassen Sie uns näher darauf eingehen, wie Amazon SageMaker Clarify die einzelnen Punkte nahtlos miteinander verbindet und Kunden bei der Durchführung einer gründlichen Modellbewertung und -auswahl unterstützt.
LLM-Bewertung mit Amazon SageMaker Clarify
Amazon SageMaker Clarify hilft Kunden bei der Automatisierung der Metriken, einschließlich, aber nicht beschränkt auf, Genauigkeit, Robustheit, Toxizität, Stereotypisierung und Faktenwissen für die Automatisierung sowie Stil, Kohärenz, Relevanz für die menschenbasierte Bewertung und Bewertungsmethoden, indem es einen Rahmen zur Bewertung von LLMs bereitstellt und LLM-basierte Dienste wie Amazon Bedrock. Als vollständig verwalteter Dienst vereinfacht SageMaker Clarify die Verwendung von Open-Source-Bewertungsframeworks innerhalb von Amazon SageMaker. Kunden können für ihre Szenarien relevante Bewertungsdatensätze und -metriken auswählen und diese mit eigenen Prompt-Datensätzen und Bewertungsalgorithmen erweitern. SageMaker Clarify liefert Bewertungsergebnisse in mehreren Formaten, um verschiedene Rollen im LLM-Workflow zu unterstützen. Datenwissenschaftler können detaillierte Ergebnisse mit SageMaker Clarify-Visualisierungen in Notizbüchern, SageMaker-Modellkarten und PDF-Berichten analysieren. In der Zwischenzeit können Betriebsteams Amazon SageMaker GroundTruth verwenden, um von SageMaker Clarify identifizierte Hochrisikoelemente zu überprüfen und zu kommentieren. Zum Beispiel durch Stereotypisierung, Toxizität, entkommene PII oder geringe Genauigkeit.
Anschließend werden Anmerkungen und verstärkendes Lernen eingesetzt, um potenzielle Risiken zu mindern. Menschenfreundliche Erläuterungen zu den identifizierten Risiken beschleunigen den manuellen Überprüfungsprozess und senken dadurch die Kosten. Zusammenfassende Berichte bieten Geschäftsinteressenten vergleichende Benchmarks zwischen verschiedenen Modellen und Versionen und erleichtern so eine fundierte Entscheidungsfindung.
Die folgende Abbildung zeigt das Framework zur Bewertung von LLMs und LLM-basierten Diensten:

Die Amazon SageMaker Clarify LLM-Bewertung ist eine Open-Source-FMEval-Bibliothek (Foundation Model Evaluation), die von AWS entwickelt wurde, um Kunden bei der einfachen Bewertung von LLMs zu unterstützen. Alle Funktionen wurden auch in Amazon SageMaker Studio integriert, um seinen Benutzern eine LLM-Bewertung zu ermöglichen. In den folgenden Abschnitten stellen wir die Integration der Amazon SageMaker Clarify LLM-Bewertungsfunktionen mit SageMaker Pipelines vor, um eine LLM-Bewertung im großen Maßstab mithilfe von MLOps-Prinzipien zu ermöglichen.
Amazon SageMaker MLOps-Lebenszyklus
Als der Beitrag „MLOps Foundation Roadmap für Unternehmen mit Amazon SageMaker“ beschreibt, dass MLOps die Kombination von Prozessen, Menschen und Technologie ist, um ML-Anwendungsfälle effizient zu produzieren.
Die folgende Abbildung zeigt den End-to-End-MLOps-Lebenszyklus:

Eine typische Reise beginnt damit, dass ein Datenwissenschaftler ein Proof-of-Concept-Notebook (PoC) erstellt, um zu beweisen, dass ML ein Geschäftsproblem lösen kann. Während der gesamten Proof of Concept (PoC)-Entwicklung obliegt es dem Datenwissenschaftler, die geschäftlichen Key Performance Indicators (KPIs) in Modellmetriken für maschinelles Lernen umzuwandeln, wie z. B. Präzision oder Falsch-Positiv-Rate, und einen begrenzten Testdatensatz zu verwenden, um diese auszuwerten Metriken. Datenwissenschaftler arbeiten mit ML-Ingenieuren zusammen, um Code von Notebooks in Repositorys zu übertragen und mithilfe von Amazon SageMaker Pipelines ML-Pipelines zu erstellen, die verschiedene Verarbeitungsschritte und -aufgaben, einschließlich Vorverarbeitung, Schulung, Evaluierung und Nachbearbeitung, miteinander verbinden und gleichzeitig kontinuierlich neue Produktion integrieren Daten. Die Bereitstellung von Amazon SageMaker Pipelines basiert auf Repository-Interaktionen und der Aktivierung der CI/CD-Pipeline. Die ML-Pipeline verwaltet leistungsstärkste Modelle, Containerbilder, Bewertungsergebnisse und Statusinformationen in einem Modellregister, in dem Modellbeteiligte die Leistung bewerten und auf der Grundlage von Leistungsergebnissen und Benchmarks über den Übergang zur Produktion entscheiden, gefolgt von der Aktivierung einer weiteren CI/CD-Pipeline für Staging und Produktionsbereitstellung. Sobald es in der Produktion ist, nutzen ML-Konsumenten das Modell über anwendungsgesteuerte Inferenz durch direkten Aufruf oder API-Aufrufe, mit Feedbackschleifen an Modellbesitzer für die fortlaufende Leistungsbewertung.
Amazon SageMaker Clarify und MLOps-Integration
Nach dem MLOps-Lebenszyklus produzieren Feinabstimmungsspezialisten oder Benutzer von Open-Source-Modellen fein abgestimmte Modelle oder FM mithilfe von Amazon SageMaker Jumpstart und MLOps-Diensten, wie in beschrieben Implementieren von MLOps-Praktiken mit vortrainierten Amazon SageMaker JumpStart-Modellen. Dies führte zu einer neuen Domäne für Foundation Model Operations (FMOps) und LLM Operations (LLMOps). FMOps/LLMOps: Operationalisieren Sie generative KI und Unterschiede mit MLOps.
Die folgende Abbildung zeigt den End-to-End-LLMOps-Lebenszyklus:
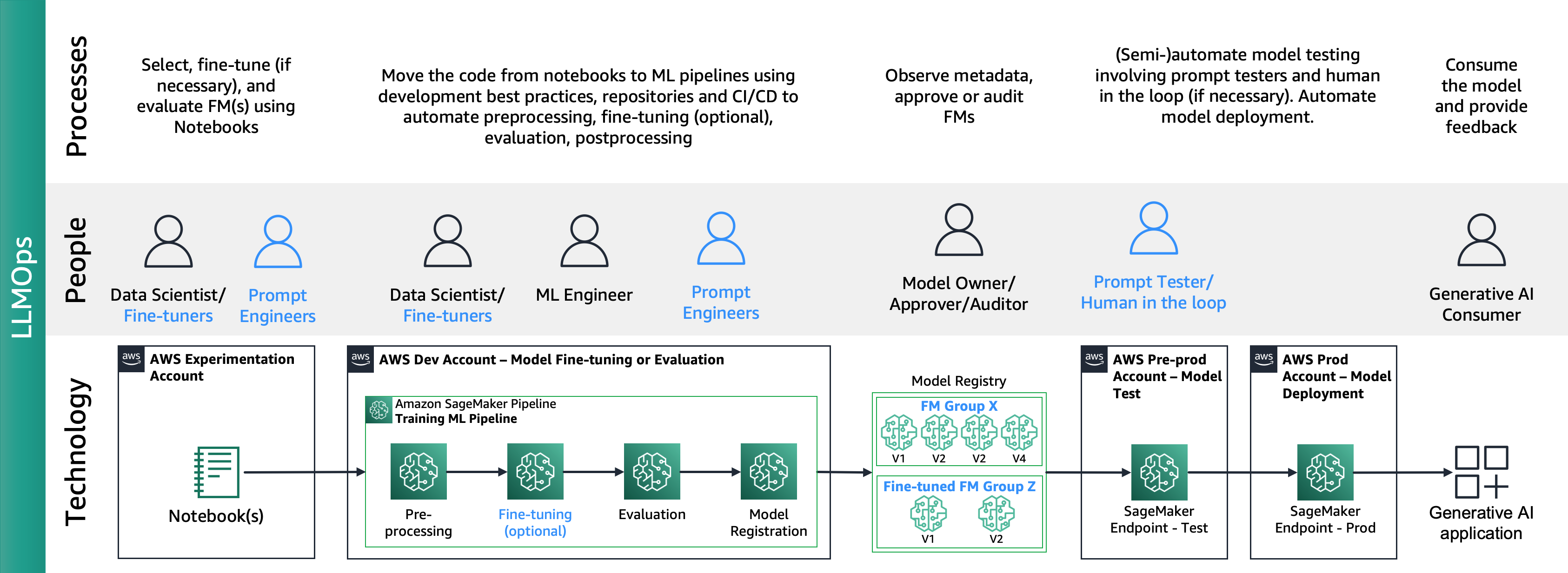
Bei LLMOps bestehen die Hauptunterschiede zu MLOps in der Modellauswahl und Modellbewertung, die unterschiedliche Prozesse und Metriken umfassen. In der ersten Experimentierphase wählen die Datenwissenschaftler (oder Feinabstimmungskräfte) das FM aus, das für einen bestimmten Anwendungsfall der generativen KI verwendet wird.
Dies führt häufig zum Testen und zur Feinabstimmung mehrerer FMs, von denen einige zu vergleichbaren Ergebnissen führen können. Nach der Auswahl des Modells bzw. der Modelle sind die Prompt-Ingenieure dafür verantwortlich, die erforderlichen Eingabedaten und erwarteten Ergebnisse für die Bewertung vorzubereiten (z. B. Eingabeaufforderungen, die Eingabedaten und Abfragen umfassen) und Metriken wie Ähnlichkeit und Toxizität zu definieren. Zusätzlich zu diesen Metriken müssen Datenwissenschaftler oder Feinabstimmungsspezialisten die Ergebnisse validieren und das geeignete FM auswählen, nicht nur im Hinblick auf Präzisionsmetriken, sondern auch im Hinblick auf andere Funktionen wie Latenz und Kosten. Anschließend können sie ein Modell auf einem SageMaker-Endpunkt bereitstellen und seine Leistung in kleinem Maßstab testen. Während die Experimentierphase einen unkomplizierten Prozess umfassen kann, erfordert der Übergang zur Produktion, dass Kunden den Prozess automatisieren und die Robustheit der Lösung verbessern. Daher müssen wir uns eingehend mit der Automatisierung der Evaluierung befassen, um Testern eine effiziente Evaluierung im großen Maßstab zu ermöglichen und eine Echtzeitüberwachung der Modelleingabe und -ausgabe zu implementieren.
Automatisieren Sie die FM-Auswertung
Amazon SageMaker Pipelines automatisieren alle Phasen der Vorverarbeitung, FM-Feinabstimmung (optional) und Auswertung im großen Maßstab. Angesichts der während des Experimentierens ausgewählten Modelle müssen Prompt-Ingenieure eine größere Anzahl von Fällen abdecken, indem sie viele Prompts vorbereiten und diese in einem bestimmten Speicher-Repository namens Prompt-Katalog speichern. Weitere Informationen finden Sie unter FMOps/LLMOps: Operationalisieren Sie generative KI und Unterschiede mit MLOps. Dann können Amazon SageMaker Pipelines wie folgt strukturiert werden:
Szenario 1 – Mehrere FMs bewerten: In diesem Szenario können die FMs den Geschäftsanwendungsfall ohne Feinabstimmung abdecken. Die Amazon SageMaker-Pipeline besteht aus den folgenden Schritten: Datenvorverarbeitung, parallele Auswertung mehrerer FMs, Modellvergleich und Auswahl basierend auf Genauigkeit und anderen Eigenschaften wie Kosten oder Latenz, Registrierung ausgewählter Modellartefakte und Metadaten.
Das folgende Diagramm veranschaulicht diese Architektur.

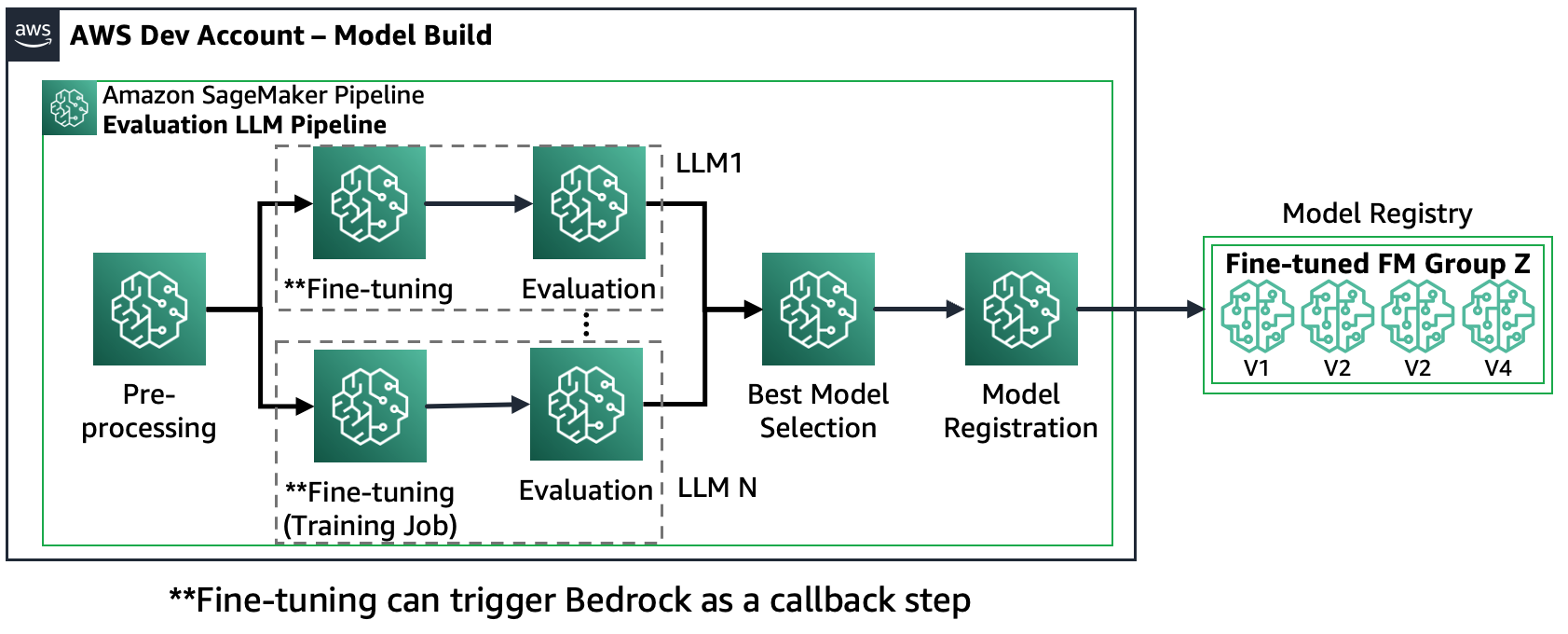
Szenario 2 – Feinabstimmung und Bewertung mehrerer FMs: In diesem Szenario ist die Amazon SageMaker-Pipeline ähnlich wie Szenario 1 aufgebaut, führt jedoch parallel sowohl Feinabstimmungs- als auch Bewertungsschritte für jedes FM durch. Das am besten abgestimmte Modell wird im Modellregister registriert.
Das folgende Diagramm veranschaulicht diese Architektur.
Szenario 3 – Bewerten Sie mehrere FMs und fein abgestimmte FMs: Dieses Szenario ist eine Kombination aus der Bewertung von Allzweck-FMs und fein abgestimmten FMs. In diesem Fall möchten die Kunden prüfen, ob ein fein abgestimmtes Modell eine bessere Leistung erbringen kann als ein Allzweck-FM.
Die folgende Abbildung zeigt die resultierenden SageMaker-Pipeline-Schritte.
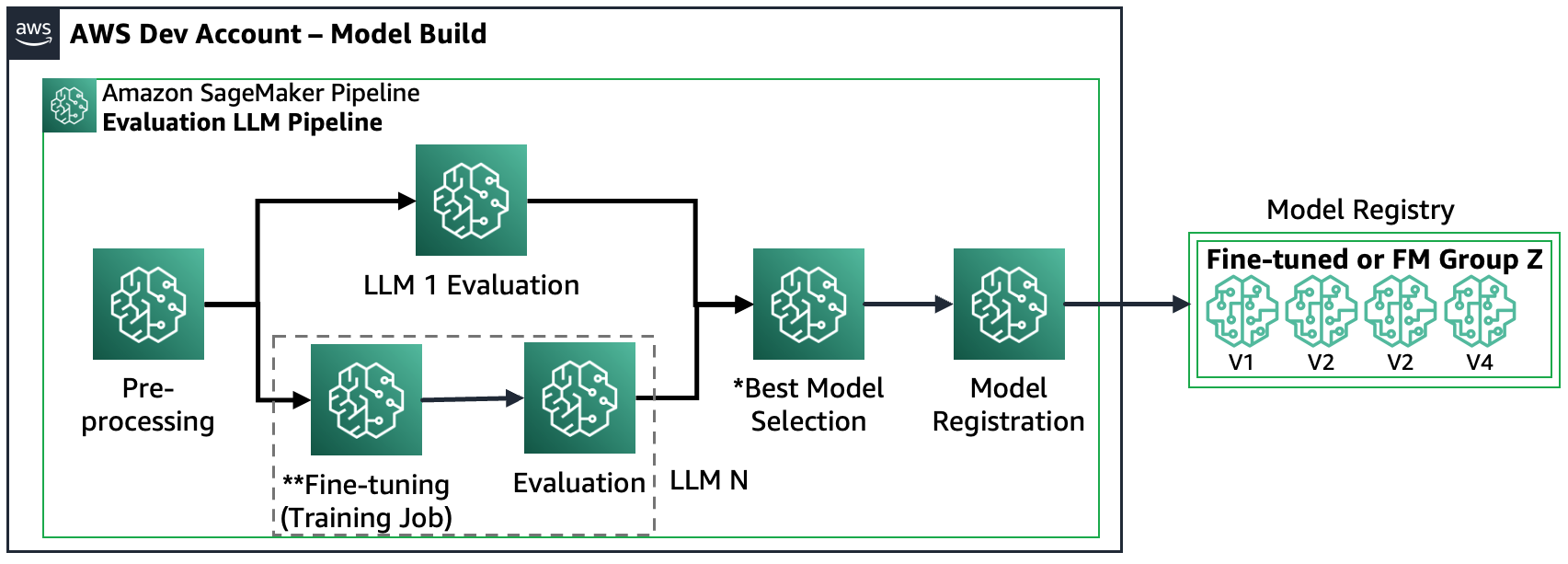
Beachten Sie, dass die Modellregistrierung zwei Mustern folgt: (a) Speichern eines Open-Source-Modells und von Artefakten oder (b) Speichern eines Verweises auf ein proprietäres FM. Weitere Informationen finden Sie unter FMOps/LLMOps: Operationalisieren Sie generative KI und Unterschiede mit MLOps.
Lösungsüberblick
Um Ihren Einstieg in die LLM-Bewertung im großen Maßstab zu beschleunigen, haben wir eine Lösung entwickelt, die die Szenarien sowohl mit Amazon SageMaker Clarify als auch mit dem neuen Amazon SageMaker Pipelines SDK implementiert. Das Codebeispiel, einschließlich Datensätzen, Quellnotizbüchern und SageMaker-Pipelines (Schritte und ML-Pipeline), ist auf verfügbar GitHub. Um diese Beispiellösung zu entwickeln, haben wir zwei FMs verwendet: Llama2 und Falcon-7B. In diesem Beitrag konzentrieren wir uns hauptsächlich auf die Schlüsselelemente der SageMaker Pipeline-Lösung, die sich auf den Evaluierungsprozess beziehen.
Auswertungskonfiguration: Zum Zweck der Standardisierung des Bewertungsverfahrens haben wir eine YAML-Konfigurationsdatei (evaluation_config.yaml) erstellt, die die notwendigen Details für den Bewertungsprozess enthält, einschließlich des Datensatzes, der Modelle und der während des Bewertungsprozesses auszuführenden Algorithmen Evaluierungsschritt der SageMaker-Pipeline. Das folgende Beispiel veranschaulicht die Konfigurationsdatei:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Bewertungsschritt: Das neue SageMaker Pipeline SDK bietet Benutzern die Flexibilität, benutzerdefinierte Schritte im ML-Workflow mithilfe des Python-Dekorators „@step“ zu definieren. Daher müssen die Benutzer ein einfaches Python-Skript erstellen, das die Auswertung wie folgt durchführt:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker-Pipeline: Nachdem der Benutzer die erforderlichen Schritte wie Datenvorverarbeitung, Modellbereitstellung und Modellbewertung erstellt hat, muss er die Schritte mithilfe des SageMaker Pipeline SDK miteinander verknüpfen. Das neue SDK generiert den Workflow automatisch, indem es die Abhängigkeiten zwischen verschiedenen Schritten interpretiert, wenn eine SageMaker-Pipeline-Erstellungs-API aufgerufen wird, wie im folgenden Beispiel gezeigt:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()Das Beispiel implementiert die Bewertung eines einzelnen FM, indem der anfängliche Datensatz vorverarbeitet, das Modell bereitgestellt und die Bewertung ausgeführt wird. Der generierte Pipeline-gerichtete azyklische Graph (DAG) ist in der folgenden Abbildung dargestellt.
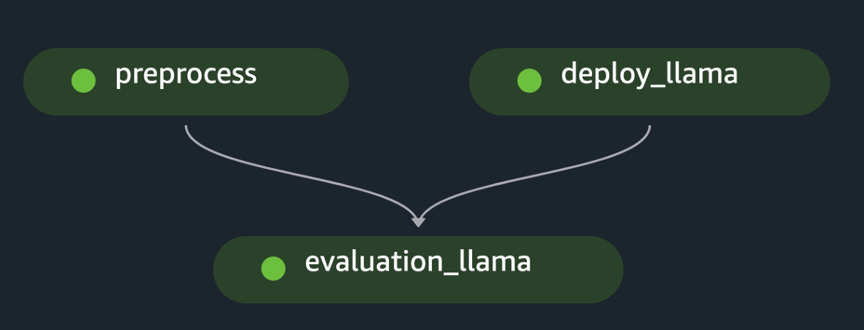
Nach einem ähnlichen Ansatz und durch Verwendung und Anpassung des Beispiels in Optimieren Sie LLaMA 2-Modelle auf SageMaker JumpStarthaben wir die Pipeline erstellt, um ein fein abgestimmtes Modell zu bewerten, wie in der folgenden Abbildung dargestellt.

Durch die Verwendung der vorherigen SageMaker-Pipeline-Schritte als „Lego“-Blöcke haben wir die Lösung für Szenario 1 und Szenario 3 entwickelt, wie in den folgenden Abbildungen dargestellt. Konkret die GitHub Das Repository ermöglicht dem Benutzer die parallele Evaluierung mehrerer FMs oder die Durchführung komplexerer Evaluierungen, bei denen die Evaluierung sowohl grundlegender als auch fein abgestimmter Modelle kombiniert wird.

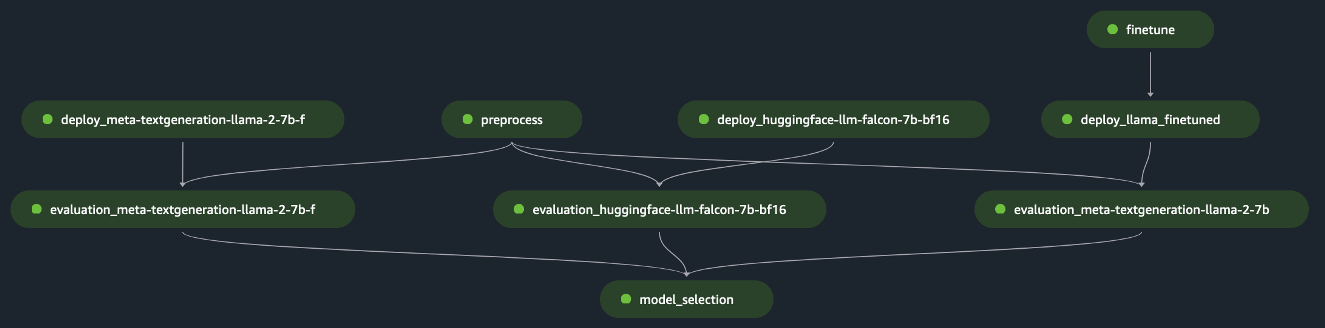
Zu den weiteren im Repository verfügbaren Funktionen gehören die folgenden:
- Generierung dynamischer Bewertungsschritte: Unsere Lösung generiert alle notwendigen Auswertungsschritte dynamisch auf Basis der Konfigurationsdatei, um Anwendern die Auswertung beliebig vieler Modelle zu ermöglichen. Wir haben die Lösung erweitert, um eine einfache Integration neuer Modelltypen wie Hugging Face oder Amazon Bedrock zu unterstützen.
- Verhindern Sie die erneute Bereitstellung von Endpunkten: Wenn bereits ein Endpunkt vorhanden ist, überspringen wir den Bereitstellungsprozess. Dadurch kann der Benutzer Endpunkte mit FMs zur Evaluierung wiederverwenden, was zu Kosteneinsparungen und einer kürzeren Bereitstellungszeit führt.
- Endpunktbereinigung: Nach Abschluss der Evaluierung stellt die SageMaker-Pipeline die bereitgestellten Endpunkte außer Betrieb. Diese Funktionalität kann erweitert werden, um den besten Modellendpunkt am Leben zu erhalten.
- Modellauswahlschritt: Wir haben einen Platzhalter für den Modellauswahlschritt hinzugefügt, der die Geschäftslogik der endgültigen Modellauswahl erfordert, einschließlich Kriterien wie Kosten oder Latenz.
- Schritt zur Modellregistrierung: Das beste Modell kann als neue Version einer bestimmten Modellgruppe in der Amazon SageMaker Model Registry registriert werden.
- Warmer Pool: Mit von SageMaker verwalteten Warmpools können Sie die bereitgestellte Infrastruktur nach Abschluss eines Auftrags beibehalten und wiederverwenden, um die Latenz für sich wiederholende Arbeitslasten zu reduzieren
Die folgende Abbildung veranschaulicht diese Funktionen und ein Beispiel für eine Multimodell-Evaluierung, das die Benutzer mithilfe unserer Lösung einfach und dynamisch erstellen können GitHub Repository.

Wir haben die Datenaufbereitung absichtlich aus dem Rahmen gelassen, da sie in einem anderen Beitrag ausführlicher beschrieben wird, einschließlich Prompt-Katalogdesigns, Prompt-Vorlagen und Prompt-Optimierung. Weitere Informationen und zugehörige Komponentendefinitionen finden Sie unter FMOps/LLMOps: Operationalisieren Sie generative KI und Unterschiede mit MLOps.
Zusammenfassung
In diesem Beitrag haben wir uns auf die Automatisierung und Operationalisierung der LLM-Bewertung im großen Maßstab mithilfe der LLM-Bewertungsfunktionen von Amazon SageMaker Clarify und Amazon SageMaker Pipelines konzentriert. Neben theoretischen Architekturentwürfen finden Sie hier auch Beispielcode GitHub Repository (mit Llama2- und Falcon-7B-FMs), um Kunden die Entwicklung eigener skalierbarer Bewertungsmechanismen zu ermöglichen.
Die folgende Abbildung zeigt die Modellbewertungsarchitektur.
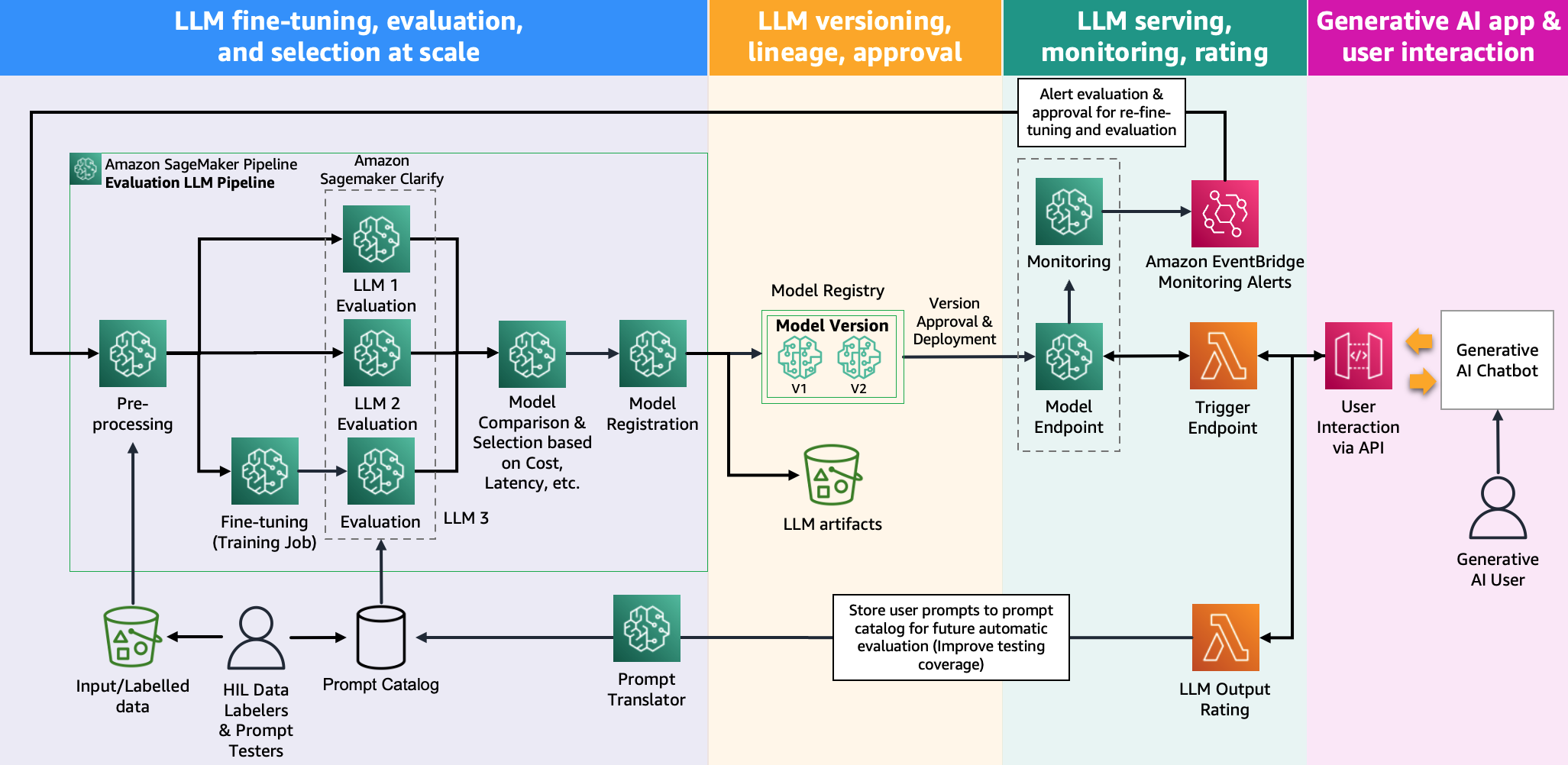
In diesem Beitrag haben wir uns auf die Operationalisierung der LLM-Bewertung im großen Maßstab konzentriert, wie auf der linken Seite der Abbildung dargestellt. In Zukunft werden wir uns auf die Entwicklung von Beispielen konzentrieren, die den End-to-End-Lebenszyklus von FMs bis zur Produktion erfüllen, indem wir die in beschriebene Richtlinie befolgen FMOps/LLMOps: Operationalisieren Sie generative KI und Unterschiede mit MLOps. Dazu gehört die LLM-Bereitstellung, Überwachung, Speicherung der Ausgabebewertung, die schließlich eine automatische Neubewertung und Feinabstimmung auslöst, und schließlich die Verwendung von Human-in-the-Loop für die Arbeit an gekennzeichneten Daten oder Eingabeaufforderungskatalogen.
Über die Autoren
 Dr. Sokratis Kartakis ist ein leitender Lösungsarchitekt für maschinelles Lernen und Operations-Spezialisten für Amazon Web Services. Sokratis konzentriert sich darauf, Unternehmenskunden die Industrialisierung ihrer Lösungen für maschinelles Lernen (ML) und generative KI zu ermöglichen, indem sie AWS-Services nutzen und ihr Betriebsmodell, d. h. MLOps/FMOps/LLMOps-Grundlagen, und Transformations-Roadmap unter Nutzung bewährter Entwicklungspraktiken gestalten. Er hat mehr als 15 Jahre damit verbracht, innovative End-to-End-ML- und KI-Lösungen auf Produktionsebene in den Bereichen Energie, Einzelhandel, Gesundheit, Finanzen, Motorsport usw. zu erfinden, zu entwerfen, zu leiten und umzusetzen.
Dr. Sokratis Kartakis ist ein leitender Lösungsarchitekt für maschinelles Lernen und Operations-Spezialisten für Amazon Web Services. Sokratis konzentriert sich darauf, Unternehmenskunden die Industrialisierung ihrer Lösungen für maschinelles Lernen (ML) und generative KI zu ermöglichen, indem sie AWS-Services nutzen und ihr Betriebsmodell, d. h. MLOps/FMOps/LLMOps-Grundlagen, und Transformations-Roadmap unter Nutzung bewährter Entwicklungspraktiken gestalten. Er hat mehr als 15 Jahre damit verbracht, innovative End-to-End-ML- und KI-Lösungen auf Produktionsebene in den Bereichen Energie, Einzelhandel, Gesundheit, Finanzen, Motorsport usw. zu erfinden, zu entwerfen, zu leiten und umzusetzen.
 Jagdeep Singh Soni ist Senior Partner Solutions Architect bei AWS mit Sitz in den Niederlanden. Er nutzt seine Leidenschaft für DevOps, GenAI und Builder-Tools, um sowohl Systemintegratoren als auch Technologiepartnern zu helfen. Jagdeep nutzt seinen Hintergrund in der Anwendungsentwicklung und Architektur, um Innovationen in seinem Team voranzutreiben und neue Technologien zu fördern.
Jagdeep Singh Soni ist Senior Partner Solutions Architect bei AWS mit Sitz in den Niederlanden. Er nutzt seine Leidenschaft für DevOps, GenAI und Builder-Tools, um sowohl Systemintegratoren als auch Technologiepartnern zu helfen. Jagdeep nutzt seinen Hintergrund in der Anwendungsentwicklung und Architektur, um Innovationen in seinem Team voranzutreiben und neue Technologien zu fördern.
 Riccardo Gatti ist ein Senior Startup Solution Architect mit Sitz in Italien. Er ist ein technischer Berater für Kunden und hilft ihnen, ihr Geschäft auszubauen, indem er die richtigen Tools und Technologien auswählt, um innovativ zu sein, schnell zu skalieren und innerhalb von Minuten global zu agieren. Er hatte schon immer eine Leidenschaft für maschinelles Lernen und generative KI und hat diese Technologien im Laufe seiner beruflichen Laufbahn in verschiedenen Bereichen studiert und angewendet. Er ist Moderator und Herausgeber des italienischen AWS-Podcasts „Casa Startup“, der sich den Geschichten von Startup-Gründern und neuen technologischen Trends widmet.
Riccardo Gatti ist ein Senior Startup Solution Architect mit Sitz in Italien. Er ist ein technischer Berater für Kunden und hilft ihnen, ihr Geschäft auszubauen, indem er die richtigen Tools und Technologien auswählt, um innovativ zu sein, schnell zu skalieren und innerhalb von Minuten global zu agieren. Er hatte schon immer eine Leidenschaft für maschinelles Lernen und generative KI und hat diese Technologien im Laufe seiner beruflichen Laufbahn in verschiedenen Bereichen studiert und angewendet. Er ist Moderator und Herausgeber des italienischen AWS-Podcasts „Casa Startup“, der sich den Geschichten von Startup-Gründern und neuen technologischen Trends widmet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 100
- 9
- a
- Über Uns
- beschleunigen
- Zugang
- Genauigkeit
- genau
- Erreichen
- Erreichen
- über
- Handlung
- Aktivierung
- aktiv
- azyklisch
- hinzugefügt
- Zusatz
- zusätzlich
- Adresse
- angemessen
- Verwaltung
- Die Annahme
- Adoption
- Fortschritte
- Berater
- Nach der
- gegen
- Agenten
- AI
- KI-Gesetz
- KI-Systeme
- Ziel
- Anvisieren
- Algorithmus
- Algorithmen
- Richtet sich aus
- lebendig
- Alle
- erlaubt
- bereits
- ebenfalls
- immer
- Amazon
- Amazon Sage Maker
- Amazon SageMaker-JumpStart
- Amazon SageMaker-Pipelines
- Amazon SageMaker-Studio
- Amazon Web Services
- an
- analysieren
- und
- Ein anderer
- beantworten
- jedem
- Bienen
- Anwendung
- Anwendungsentwicklung
- Anwendungen
- angewandt
- gilt
- Ansatz
- angemessen
- Architektur
- SIND
- Bereiche
- Argument
- AS
- beurteilen
- Beurteilung
- Bewertung
- Einschätzungen
- At
- Wirtschaftsprüfung
- automatisieren
- Automatisiert
- automatische
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Automation
- verfügbar
- AWS
- b
- Hintergrund
- basierend
- basic
- BE
- weil
- werden
- war
- Verhalten
- Benchmark
- Benchmarking
- Benchmarks
- Vorteile
- BESTE
- Besser
- zwischen
- Beyond
- vorspannen
- voreingenommen
- Vorurteile
- Blockiert
- beide
- Verstöße
- Breite
- bringen
- bauen
- Baumeister
- Geschäft
- aber
- by
- namens
- Aufrufe
- CAN
- Kandidat
- Fähigkeiten
- fähig
- Erfassung
- Karten
- Karriere
- Häuser
- Fälle
- Katalog
- sicher
- challenges
- Charakteristik
- billiger
- aus der Ferne überprüfen
- Auswählen
- gewählt
- Einstufung
- klassifizieren
- reinigen
- Code
- zusammenhängend
- zusammenarbeiten
- Kombination
- Vereinigung
- gemeinsam
- community
- vergleichbar
- vergleichen
- verglichen
- Vergleich
- Ergänzung
- Abschluss
- Komplex
- Komplexität
- Compliance
- entsprechen
- Komponente
- Komponenten
- umfassend
- rechnerisch
- Berechnen
- konzept
- Hautpflegeprobleme
- Leiten
- Leitung
- dirigiert
- Konfiguration
- Vernetz Dich
- Connects
- betrachtet
- besteht
- konstruieren
- KUNDEN
- Container
- enthält
- Inhalt
- Kontext
- ständig
- kontinuierlich
- Kontrast
- Konversations
- Gespräche
- verkaufen
- und beseitigen Muskelschwäche
- Kosten
- Einsparmaßnahmen
- teuer werden
- Kosten
- Abdeckung
- erstellen
- erstellt
- Erstellen
- Schaffung
- Kriterien
- kritischem
- wichtig
- Original
- Kunden
- TAG
- technische Daten
- Datenaufbereitung
- Datenwissenschaftler
- Datensicherheit
- Datensatz
- Datenmanipulation
- Datensätze
- datetime
- entscheidet
- Decision Making
- Entscheidungen
- gewidmet
- tief
- Tieftauchgang
- Standard
- definieren
- Definitionen
- liefert
- Demand
- Abhängigkeiten
- hängt
- einsetzen
- Einsatz
- Bereitstellen
- Einsatz
- Tiefe
- beschrieben
- bezeichnet
- entworfen
- Entwerfen
- Designs
- Verlangen
- erwünscht
- detailliert
- Details
- entwickeln
- entwickelt
- Entwicklung
- Entwicklung
- DevOps
- Unterschiede
- anders
- Direkt
- gerichtet
- tauchen
- verschieden
- do
- Tut nicht
- Domain
- Domains
- Antrieb
- im
- dynamisch
- e
- jeder
- leicht
- Einfache
- Herausgeber
- Effektiv
- Wirksamkeit
- effizient
- effizient
- Anstrengung
- entweder
- Elemente
- sonst
- beschäftigt
- ermöglichen
- ermöglicht
- ermöglichen
- End-to-End
- Endpunkt
- Endpunkte
- Energie
- Ingenieure
- zu steigern,
- gewährleisten
- sorgt
- Gewährleistung
- Unternehmen
- Unternehmenskunden
- Unternehmen
- Epoche
- gleichermaßen
- insbesondere
- essential
- etc
- Äther (ETH)
- EU
- bewerten
- Bewerten
- Auswerten
- Auswertung
- Sogar
- schließlich
- Beispiel
- Beispiele
- Exekutive
- vorhandenen
- Erwartungen
- erwartet
- beschleunigen
- erweitern
- verlängert
- extern
- Extraktion
- f1
- Gesicht
- erleichtern
- Faktoren
- Sachliche
- Fairness
- Stürze
- falsch
- berühmt
- FAST
- beschleunigt
- Merkmal
- Einzigartige
- Feedback
- wenige
- Feld
- Abbildung
- Zahlen
- Reichen Sie das
- Finale
- Endlich
- Finanzen
- Revolution
- Finanzsektor
- Vorname
- Flexibilität
- Setzen Sie mit Achtsamkeit
- konzentriert
- konzentriert
- gefolgt
- Folgende
- folgt
- Aussichten für
- unten stehende Formular
- Foundation
- Foundations
- Gründer
- Unser Ansatz
- Gerüste
- häufig
- für
- Erfüllung
- voller
- Funktionsumfang
- Funktionalität
- fundamental
- Außerdem
- Zukunft
- Sammlung
- Allgemeines
- allgemeiner Zweck
- erzeugen
- erzeugt
- erzeugt
- Erzeugung
- Generation
- generativ
- Generative KI
- bekommen
- gegeben
- Global
- Go
- gewähren
- Graph
- Gruppe an
- Gruppen
- persönlichem Wachstum
- Pflege
- schädlich
- Nutzen
- Haben
- mit
- he
- Gesundheit
- schwer
- Hilfe
- Unternehmen
- hilft
- GUTE
- hohes Risiko
- Scharniere
- seine
- Halten
- Gastgeber
- Ultraschall
- Hilfe
- aber
- HTML
- HTTPS
- human
- i
- IAM
- identifiziert
- identifiziert
- identifizieren
- if
- zeigt
- Bilder
- implementieren
- Umsetzung
- implementiert
- importieren
- Bedeutung
- Verbesserung
- Verbesserungen
- in
- das
- Dazu gehören
- Einschließlich
- Incorporated
- einarbeiten
- Anzeigen
- Branchen
- Information
- informiert
- Infrastruktur
- Anfangs-
- wir innovieren
- Innovation
- innovativ
- Varianten des Eingangssignals:
- Eingänge
- integrieren
- Integration
- absichtlich
- Interaktionen
- intern
- in
- einführen
- aufgerufen
- beteiligen
- beteiligt
- beinhaltet
- Beteiligung
- ISO
- IT
- Italienisch
- Italien
- Artikel
- Iteration
- SEINE
- Job
- Reise
- jpg
- Behalten
- gehalten
- Wesentliche
- Wissen
- Sprache
- grosse
- größer
- Nachname
- zuletzt
- Latency
- führen
- Bestenlisten
- führenden
- lernen
- links
- lassen
- Nutzung
- Bibliothek
- Lebenszyklus
- Gefällt mir
- Limitiert
- LINK
- Lama
- Standorte
- Logik
- Sneaker
- Maschine
- Maschinelles Lernen
- Main
- halten
- unterhält
- verwaltet
- manipulieren
- Manipulationen
- manuell
- viele
- Kann..
- Mittlerweile
- messen
- Maßnahmen
- Mechanismen
- Metadaten
- Methode
- Methoden
- Metrisch
- Metrik
- minimieren
- Minuten
- Fehlinformationen
- Mildern
- mildernd
- ML
- MLOps
- Modell
- für
- Modulen
- Überwachen
- Überwachung
- mehr
- vor allem warme
- motiviert
- Motorsport
- viel
- mehrere
- sollen
- Name
- notwendig,
- Need
- Bedürfnisse
- Niederlande
- Neu
- Neue Technologien
- weiter
- Nicht-Experten
- beachten
- Notizbuch
- Laptops
- Abschattung
- Anzahl
- of
- bieten
- vorgenommen,
- on
- einmal
- EINEM
- laufend
- einzige
- Open-Source-
- die
- Betrieb
- Einkauf & Prozesse
- Meinungen
- Optimierung
- or
- OS
- Andere
- UNSERE
- Ergebnis
- Ergebnisse
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- hervorragend
- übrig
- Gesamt-
- besitzen
- Besitzer
- Parallel
- Parameter
- besondere
- besonders
- Partner
- Leidenschaft & KREATIVITÄT
- leidenschaftlich
- Weg
- Muster
- Personen
- ausführen
- Leistung
- Leistungen
- führt
- Phase
- pii
- Pipeline
- Ort
- Platzhalter
- Plato
- Datenintelligenz von Plato
- PlatoData
- PoC
- Podcast
- Points
- Pool
- Pools
- Post
- Nachbearbeitung
- Potenzial
- Werkzeuge
- angetriebene
- Praktiken
- Präzision
- Vorbereitung
- Vorbereitung
- Präsenz
- verhindern
- früher
- primär
- Principal
- Grundsätze
- Datenschutz
- privat
- Aufgabenstellung:
- Verfahren
- Prozessdefinierung
- anpassen
- Verarbeitung
- Produktion
- Progression
- Bedeutung
- Versprechen
- fördern
- Eingabeaufforderungen
- Beweis
- Proof of Concept
- Fortpflanzung
- immobilien
- Eigentums-
- Risiken zu minimieren
- Belegen
- die
- Anbieter
- bietet
- Bereitstellung
- Öffentlichkeit
- öffentlich
- Zweck
- Python
- qualitativ
- Qualität
- quantitativ
- Frage
- Angebot
- Bewerten
- Wertung
- echt
- realen Welt
- Echtzeit
- Veteran
- Reduziert
- Reduzierung
- siehe
- Referenz
- eingetragen
- Registrierung:
- Registratur
- Regression
- regulär
- geregelt
- regulierte Branchen
- Vorschriften
- Verstärkung lernen
- bezogene
- Relevanz
- relevant
- Zuverlässigkeit
- repetitiv
- berichten
- Reporting
- Meldungen
- Quelle
- Vertreter
- falls angefordert
- erfordert
- Forschungsprojekte
- Forscher
- ressourcenintensiv
- Downloads
- Verantwortung
- für ihren Verlust verantwortlich.
- was zu
- Die Ergebnisse
- Einzelhandel
- behalten
- Rückkehr
- Wiederverwendung
- Überprüfen
- Revolutionierung
- Recht
- rigoros
- Auferstanden
- Risiko
- Risiken
- Fahrplan
- robust
- Robustheit
- Rollen
- Rollen
- Führen Sie
- Laufen
- läuft
- s
- Safe
- Schutzmaßnahmen
- sagemaker
- SageMaker-Pipelines
- Ersparnisse
- Skalierbarkeit
- skalierbaren
- Skalieren
- Szenario
- Szenarien
- Wissenschaftler
- Wissenschaftler
- Umfang
- Ergebnis
- Skript
- Sdk
- nahtlos
- Abschnitte
- Bibliotheken
- Verbindung
- Sicherheitdienst
- Sicherheitsrisiken
- wählen
- ausgewählt
- Auswahl
- Auswahl
- Senior
- Gefühl
- brauchen
- Lösungen
- Dienst
- Sitzung
- kompensieren
- Gestaltung
- Teilen
- erklären
- gezeigt
- Konzerte
- Seite
- signifikant
- ähnlich
- Vereinfacht
- einfach
- da
- Single
- klein
- Lösung
- Lösungen
- LÖSEN
- einige
- Quelle
- Spannweite
- Spezialist
- spezifisch
- speziell
- verbrachte
- Aufführung
- Stakeholder
- Standardisierung
- Normen
- Stanford
- Beginnen Sie
- beginnt
- Anfang
- Status
- Schritt
- Shritte
- Immer noch
- Lagerung
- speichern
- Geschichten
- einfach
- strukturierte
- sucht
- Studio Adressen
- Stil
- Anschließend
- so
- ZUSAMMENFASSUNG
- Support
- System
- Systeme und Techniken
- Schneiderei
- Aufgabe
- und Aufgaben
- Team
- Teams
- Technische
- Techniken
- technologische
- Technologies
- Technologie
- Vorlagen
- Test
- Tester
- Testen
- Tests
- Text
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- ihr
- Sie
- dann
- theoretisch
- damit
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- nach drei
- Durch
- während
- Zeit
- zu
- gemeinsam
- Werkzeug
- Werkzeuge
- verfolgen sind
- Training
- trainiert
- Ausbildung
- schult Ehrenamtliche
- Transformation
- Übergang
- Übergang
- Übersetzungen
- Trends
- auslösen
- was immer dies auch sein sollte.
- vertrauenswürdig
- XNUMX
- Typen
- typisch
- Letztlich
- unbefugt
- verstehen
- Verständnis
- beispiellos
- anstehende
- -
- Anwendungsfall
- benutzt
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- gewöhnlich
- Nutzen
- BESTÄTIGEN
- wertvoll
- verschiedene
- Version
- lebenswichtig
- Sicherheitslücken
- wollen
- warm
- we
- Netz
- Web-Services
- GUT
- waren
- Was
- wann
- welche
- während
- WHO
- breit
- Große Auswahl
- Wikipedia
- werden wir
- mit
- .
- ohne
- Arbeiten
- Arbeitsablauf.
- arbeiten,
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- YAML
- Jahr
- Ausbeute
- U
- Ihr
- Zephyrnet