Die University of Maryland, Baltimore County Bina-Labor ist ein multidisziplinäres Forschungslabor, das fortschrittliche Computer Vision, maschinelles Lernen (ML) und Fernerkundungstechniken einsetzt, um neue Erkenntnisse über unsere Umwelt, insbesondere in den arktischen und antarktischen Regionen, zu gewinnen. Die Arbeit des Labors wird durch NSF BIGDATA Awards (IIS-1947584, IIS-1838230), den NSF HDR Institute Award (OAC-2118285) und den unterstützt Amazon ML-Forschung Auszeichnung für den Klimawandel. Kürzlich wurde das Bina Lab von der National Science Foundation im Rahmen von Harnessing the Data Revolution (NSF HDR) mit der Förderung des Instituts für Harnessing Data and Model Revolution in the Polar Regions (bezeichnet als iHARP) ausgezeichnet. Um mehr zu erfahren und zu ML-Forschungsaktivitäten beizutragen, besuchen Sie die Website von iHARP unter i-harp.org.
iHARP arbeitet aktiv mit der NASA, Amazon Research und AWS zusammen, um fortschrittliche Forschung zur Datenanalyse und -modellierung in den arktischen und antarktischen Regionen unter Verwendung von Datenwissenschaft, ML und KI durchzuführen. Das Wissenschaftlerteam von iHARP unter der Leitung von Dr. Maryam Rahnemoonfar und Dr. Masoud Yari arbeitet daran, Dateneinblicke zu Trends im Zusammenhang mit der Dicke der Eisschilde, dem Grad der Schneeansammlung und der Schmelzgeschwindigkeit zu gewinnen. Alle diese Faktoren liefern wichtige Indikatoren für die Muster des Klimawandels. Der Prozess der Datenerfassung und -aufbereitung ist trotz erheblicher technologischer Fortschritte bei Fernerkundungstechniken weiterhin äußerst arbeitsintensiv. Die Herausforderungen werden durch die Notwendigkeit verschärft, riesige Mengen an über Jahre gesammelten Bildern zu sichten, um sinnvolle Musteränderungen zu erkennen. Darüber hinaus führen Bilder unterschiedlicher Qualität zu einer Verschlechterung des Analyseprozesses. Beim Training lokaler semantischer Segmentierungs- und Konturerkennungsmodelle konnten die iHARP-Forscher trotz umfassender Bildvorverarbeitungsaufgaben die Schichtgrenzen- und Konturvorhersagen nicht mit der erforderlichen Genauigkeit extrahieren.
Da die Demokratisierung von Technologien es ermöglicht, Deep-Learning-Training in der Cloud zu einem Bruchteil der Kosten und der Zeit im Vergleich zu On-Premises durchzuführen, beschlossen die iHARP-Forscher, ihre ML-Workflows darauf aufzubauen Amazon Sage Maker. Dies ermöglichte es dem Team, Skalierbarkeitsanforderungen zu erfüllen, seine bestehenden Auto-Labeling-Modelle zu verbessern und das aktive Lernen mit Menschen zu beschleunigen, was die Zusammenarbeit zwischen Fachwissenschaftlern und Datenwissenschaftlern ermöglichte. Das Endziel bestand darin, die Verfolgung der polaren Eisschicht genauer und weniger zeitaufwändig zu machen. In diesem Beitrag dokumentieren wir die Ergebnisse der Zusammenarbeit zwischen Forschern von iHARP und AWS zur Lösung des Anwendungsfalls der Eisanalyse in der Arktis. Konkret führen wir Sie durch die folgenden Themen:
- Was ist eine Eisanalyse in der Arktis?
- Ein Ansatz zur Verwendung von ML für die Eisanalyse in der Arktis
- Skalierbares ML mit SageMaker
- Aktiver Lernworkflow mit Amazon Augmented AI (Amazon A2I) und SageMaker
Was ist eine Eisanalyse in der Arktis?
Glaziologie ist ein Zweig der Umweltwissenschaften, der sich auf Eis und seine Eigenschaften konzentriert. 71 % unseres Planeten bestehen aus Wasser, daher spielt Eis eine wichtige Rolle bei der Auswirkung auf das globale Klima (mehr zu diesem Thema finden Sie in Sechs Auswirkungen des Verlusts des arktischen Eises auf alle). Das Abschmelzen der polaren Eiskappen (Arktis und Antarktis) führt dazu, dass unser Planet einer erhöhten Hitze ausgesetzt ist, da wir jetzt weniger Eis haben, um die Wärme zurück in den Weltraum zu reflektieren. Wenn Eis schmilzt, führt dies zu einem Anstieg des Meeresspiegelanstiegs (SLR), der ein globales Problem darstellt. Steigende Wasserstände können vor allem in Küstengebieten und auf Inseln zu gefährlichen Überschwemmungen führen.
Laut einer Studie der Vereinten Nationen aus dem Jahr 2019 haben Menschen eine durchschnittliche Lebenserwartung von 72.6 Jahren. Unsere Zeit auf diesem Planeten ist begrenzt. Nach dem Artikel Grundlagen zu EiskernenWir haben Zugang zu Eiskernaufzeichnungen (zylindrische Blöcke, die durch Eisplatten gebohrt wurden, wobei die jüngste Eisschicht oben und die älteste Schicht unten liegt), die mindestens 800,000 Jahre zurückreichen. Damit die Forschung effektiv ist, müssen wir auf so viele Daten wie möglich zugreifen und diese analysieren, um Zusammenhänge zwischen Veränderungen der Eisschichtmuster und vergangenen Klimaereignissen aufzudecken. Allerdings ist es für uns mathematisch unmöglich, alle verfügbaren Daten zu analysieren. Hier kommen ML und KI ins Spiel, um ein oder zwei neuronale Netze bereitzustellen, um die Dinge zu beschleunigen!
Was meinen wir also wirklich mit der Analyse von Eisdaten? Es ist der arbeitsintensive Prozess, Millionen oder sogar Milliarden von Radar-, Spektroskop- und Fotobildern, Tabellendaten und Klimadaten durchzugehen, um Eisschichten zu kartieren, nach Veränderungen der Eisschichten im Laufe der Zeit zu suchen, klimatische Ereignisse zu identifizieren und Muster zu finden die den Zusammenhang zwischen dem, was mit dem Eis passiert, und seinen Auswirkungen auf das Klima beweisen. Um diese Aufgabe zu beschleunigen, benötigen wir einen leistungsstarken Computer, die Fähigkeit, Bilder zu lesen, zu verstehen und zu interpretieren, die Fähigkeit, nach scheinbar winzigen Veränderungen in diesen Bildern zu suchen, die sich nach und nach über Tausende von Bildern abspielen, und die Fähigkeit, diese Veränderungen mit auffälligen Ereignissen in Zusammenhang zu bringen in mathematischen, tabellarischen und sensorischen Messwerten und mehr. Angesichts der jüngsten Fortschritte bei ML-Algorithmen und -Techniken und der Verfügbarkeit von Supercomputern zu einem Bruchteil der Kosten von Cloud Computing sind Wissenschaftler begierig darauf, cloudbasiertes ML zu nutzen, um arktische und antarktische Daten zu erforschen und zu extrahieren.
Einer der ersten und vielleicht wichtigsten Schritte bei der Analyse des arktischen Eises besteht darin, die verschiedenen Eisschichten mit beträchtlicher Genauigkeit zu unterscheiden. Dies liegt daran, dass dieser Schritt die übrigen Schritte im Prozess beeinflusst. Wir können dies erreichen, indem wir ein ML-Modell trainieren überwachtes Lernen um beispielsweise Eisschichten anhand von Radarbildern zu erkennen. Um die benötigte Genauigkeit zu erreichen, benötigen wir große Mengen annotierter Daten. Die Herausforderung bestand nicht in der Verfügbarkeit von Daten; Es gibt eine große Menge heterogener Radardaten aus den Polarregionen, die durch aufwendige Missionen gesammelt wurden. Während unserer Experimente stellten wir jedoch fest, dass die Qualität der Anmerkungen für diese Daten nicht ausreichte, um ein Modell mit der benötigten Genauigkeit zu trainieren. In den nächsten Abschnitten erklären wir Ihnen, wie wir diese Herausforderung gelöst haben.
Ein Ansatz zur arktischen Eisanalyse mittels ML
Auf der IEEE Big Data-Konferenz im Jahr 2019 veröffentlichten unsere Forscher Dr. Maryam und Dr. Masoud zusammen mit Kollegen von der University of Kansas und der University of Colorado das Papier Intelligente Verfolgung interner Eisschichten in Radardaten durch Multi-Scale-Learning. In diesem Artikel wurden Experimente mit ML, insbesondere Kantenerkennungsmodellen unter Verwendung von mehrskaligen Deep-Learning-Modellen (z. B. Holistically-Nested Edge Detection (HED)) detailliert beschrieben, um die Schichtgrenzen in Radarbildern von Eisschichten zu verfolgen. Die erweiterte Version dieser Forschung ist veröffentlicht in Deep Multi-Scale Learning zur automatischen Verfolgung interner Eisschichten in Radardaten im Journal of Glaciology im Jahr 2020.
Die NASA sammelt seit vielen Jahrzehnten Daten aus Polarregionen. NASAs ICESat und ICESat-2 und Betrieb IceBridge sind prominente Beispiele dieser Bemühungen. Die Operation IceBridge wurde 11 Jahre lang als Brücke zwischen den beiden ICESat-Missionen durchgeführt, um Polarvermessungen mithilfe luftgestützter Sensoren wie Radar zu sammeln. Der Vorteil der Verwendung von Radarsensoren besteht darin, dass ihre Wellen unter die Eisoberfläche eindringen können. Allerdings stellen diese Daten eine Momentaufnahme dar und sind an Geokoordinaten gebunden. Operation IceBridge lieferte Petabytes öffentlich verfügbarer Rohdaten und die manuelle Analyse war eine große Herausforderung. Die folgende Abbildung zeigt beispielsweise ein Radarbildsegment, das 2012 in Grönland aufgenommen wurde. Die horizontale Richtung ist die Flugbahn und die vertikale Richtung ist die Schneehöhe. Die Einheiten pro Bildpixel werden auf dem Bild angezeigt.

Die folgende Abbildung zeigt dasselbe Bild mit den manuell gezeichneten Ebenenanmerkungen. Die allererste Grenzlinie (als Schicht 1 markiert) ist die Schneeoberfläche; Jede darunter liegende Schicht stellt die jährliche Schneeansammlung der vergangenen Jahre dar. Unser Ziel ist es, die Schichten zu erkennen und schließlich die Dicke der Schichten zu berechnen, aber das war nur für ein Segment eines einzigen Frames! Wir wollten in der Lage sein, die Eisschichten in ganz Grönland zu skalieren und zu kartieren!

Im Wesentlichen möchten wir, dass unsere Modelle alle Ebenen vorhersagen können, wie in der folgenden Abbildung dargestellt (die das Originalbild und ein kommentiertes Bild aller Ebenen enthält). Dies ist ein Beispiel für ein Bild mit sehr engen und verblassten Ebenen. Es gibt jedoch noch andere Probleme, auf die Sie achten müssen, wie z. B. Rauschen und Artefakte, deren Diskussion den Rahmen dieses Beitrags sprengen würde.
 |
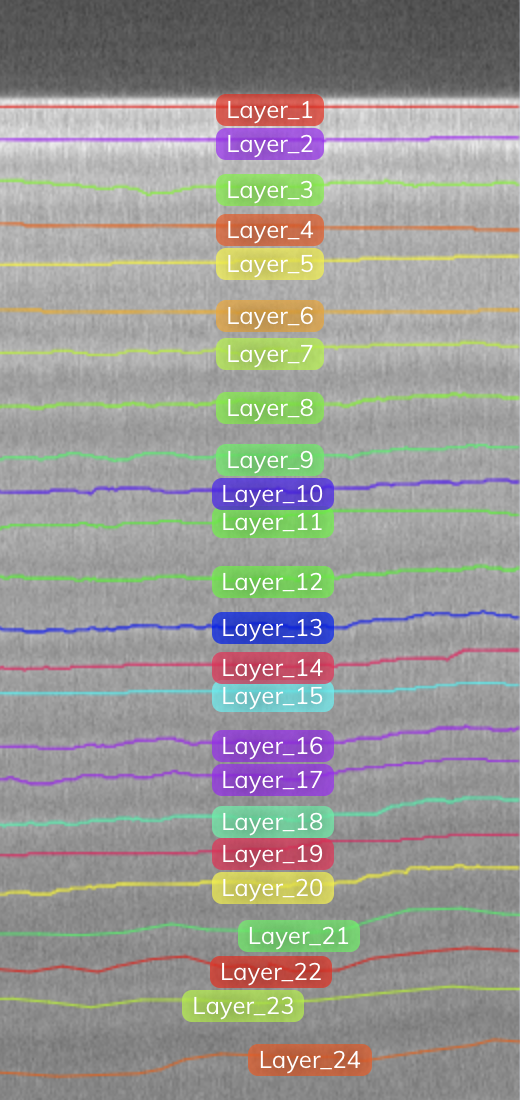 |
Zusammenfassend, in ihrem IEEE 2019- und JOG 2020-PapierDie Forscher zeichneten die folgenden Beobachtungen aus ihren Experimenten zur Wirksamkeit des Einsatzes von Deep Learning für die Kennzeichnung von Radarbildern auf:
- Die meisten der bekannten Deep-Learning-Ansätze funktionieren bei normalen Bildern sehr gut, es wurde jedoch festgestellt, dass sie bei Vorhandensein von Rauschen keine akzeptablen Ergebnisse liefern. Die Tatsache, dass Deep-Learning-Modelle nicht robust gegenüber Rauschen sind, wird in verschiedenen Arbeiten diskutiert.
- Transfer-Learning-Ansätze funktionieren bei Radarbildern nicht gut, wohingegen ein Training von Grund auf weitaus bessere Ergebnisse liefert.
- Das Training von Grund auf erfordert annotierte Daten, die von den Fachexperten bereitgestellt werden. Die Generierung guter synthetischer Daten könnte eine Lösung für den Mangel an annotierten Daten sein.
Basierend auf diesen Beobachtungen erkannten wir, dass wir bestimmte Überlegungen berücksichtigen mussten:
- Unser Datensatz während des Experiments wäre von geringer Größe (ungefähr 5,000 Bilder). Allerdings mussten wir die Architektur zukunftssicher machen, um sie bei Bedarf skalieren zu können.
- Wir mussten unsere bestehende halbautomatische Lösung zur Schichtverfolgung integrieren (unter Verwendung des im IEEE-Papier erwähnten Modells).
- Der Ansatz sollte einen teilweise annotierten Datensatz verwenden, den wir hatten (wir haben weder die Zeit noch die Ressourcen, um den Datensatz vollständig von Menschen zu kommentieren).
- Wir brauchten die Möglichkeit, ein aktives Lernframework bereitzustellen, damit sich das Modell mithilfe des Feedbacks menschlicher Prüfer weiterentwickeln kann. Der Ansatz des aktiven Lernens würde einen Mittelweg finden, der es Fachwissenschaftlern ermöglicht, Modellvorhersagen zu modifizieren.
Das Endziel bestand natürlich darin, die Modellgenauigkeit bei Schichtvorhersagen zu maximieren.
Skalierbares ML mit SageMaker
SageMaker ist ein vollständig verwalteter ML-Dienst. SageMaker bietet eine integrierte Jupyter-Umgebung zum Erstellen und Experimentieren sowie eine webbasierte visuelle Schnittstelle namens SageMaker-Studio, wo Sie alle ML-Entwicklungsschritte mit vollständigem Zugriff, Kontrolle und Sichtbarkeit durchführen können. SageMaker stellt die für Schulung und Hosting erforderliche Infrastruktur bereit und verwaltet sie. SageMaker bietet außerdem gängige ML-Algorithmen, die für die effiziente Ausführung extrem großer Datenmengen in einer verteilten Umgebung optimiert sind. Mit nativer Unterstützung für Bring-Your-Own-Algorithmen und Frameworks bietet SageMaker flexible verteilte Trainingsoptionen, die sich an individuelle Arbeitsabläufe anpassen. Schulung und Hosting werden nach Nutzungsminuten abgerechnet, ohne Mindestgebühren und ohne Vorabverpflichtungen.
Wir fanden, dass SageMaker aufgrund seiner Skalierbarkeit, seiner Flexibilität bei der Unterstützung unserer benutzerdefinierten ML-Algorithmen, der Tatsache, dass wir aufgrund der Benutzerfreundlichkeit schnell loslegen konnten, und, was noch wichtiger ist, der Möglichkeit, aktives Lernen mit Amazon einzurichten, für unsere Anforderungen gut geeignet ist A2I. Um die Experimente mit unserem semantischen Segmentierungsmodell mit SageMaker fortzusetzen, haben wir die folgende Architektur entworfen.

Bilder herunterladen und vorverarbeiten
Wir nutzen öffentlich verfügbare Daten. Für das Training unseres Modells haben wir die verfügbaren Radardaten verwendet Nationales Schnee & Eis Datenzentrum. Teilweise Anmerkungen zu den Eisschichten stehen zur Nutzung zur Verfügung. Allerdings sind nicht alle Ebenen in der Anmerkung vorhanden, was zu verzerrten Ergebnissen führen kann. Als ersten Schritt haben wir den Rohdatensatz in eine heruntergeladen Amazon Simple Storage-Service (Amazon S3) Eimer. Wir haben ein SageMaker Jupyter-Notebook bereitgestellt, mit dem wir die Bilder abgerufen und in das konvertiert haben RecordIO Format, das die Speicherung optimiert und das Streamen von Daten im Pipe-Modus für ein schnelleres Training ermöglicht. Die RecordIO-Dateien werden dann als Trainings- und Testdatensätze zurück in Amazon S3 hochgeladen.
Trainieren Sie das mehrskalige Layer-Tracking-Modell auf SageMaker
Wir haben eine Python-Datei als Einstiegspunkt erstellt, die den Code für unseren Multiskalen-Layer-Tracking-Algorithmus enthielt. Wir haben den SageMaker verwendet MXNet-Schätzer als Wrapper für unser CNN, und wir haben das verwendet SageMaker Python-SDK zum Initialisieren des Schätzers, zum Konfigurieren der Hyperparameter und zum Ausführen des Trainings. Wir haben eine Hyperparameteroptimierung mit dem SageMaker durchgeführt Automatischer Modelltuner um die optimalen Einstellungen zu ermitteln, die uns die besten Ergebnisse lieferten.
Hosten Sie das Modell auf SageMaker und führen Sie Vorhersagen aus
Nach Abschluss des Modelltrainings wurden die Artefakte von SageMaker automatisch an einen S3-Bucket gesendet. Bevor wir eine Massenvorhersage von Anmerkungen für unsere Bilder durchführen konnten, wollten wir in der experimentellen Phase einen Echtzeit-Endpunkt einrichten, Tests zur Vorhersagequalität durchführen und aktives Lernen ermöglichen. Um eine Echtzeit-Inferenz einzurichten, müssen wir zunächst hat das Modellpaket erstellt und dann hat eine Endpunktkonfiguration erstellt Darin wurde der Instanztyp angegeben, den wir zum Hosten wollten, sowie Details dazu, ob wir mehrere Versionen gleichzeitig ausführen wollten. Wir haben diese Option nicht ausgewählt, da wir uns noch in der experimentellen Phase befanden, aber weitere Einzelheiten finden Sie unter Bereitstellen eines Modells in Amazon SageMaker. Endlich haben wir hat den Endpunkt erstellt. Zum Ausführen von Vorhersagen haben wir einen vorverarbeiteten Testdatensatz mit Bildern verwendet, den wir an den gehosteten Endpunkt gesendet haben. Das Modell hat die JSON-Anmerkungen für die Ebenengrenzen aus unserem Eingabebild zurückgegeben, und wir haben die Anmerkungskoordinaten und das Bild in einem S3-Bucket gespeichert.
Natürlich war die Übertragung unseres Modells auf SageMaker der erste Schritt, aber dies gab uns die Grundlage, die wir brauchten, um schnell Innovationen zu entwickeln und unsere Experimente zu beschleunigen. Im nächsten Abschnitt zeigen wir Ihnen, wie wir Amazon A2I mit SageMaker verwendet haben, um einen voll funktionsfähigen aktiven Lernworkflow zu erstellen.
Richten Sie mit Amazon A2I einen aktiven Lernworkflow ein
Mit Amazon A2I können Sie ganz einfach eine menschliche Überprüfung in Ihren ML-Workflow integrieren. Amazon A2I bietet integrierte Arbeitsabläufe für die menschliche Überprüfung für gängige ML-Anwendungsfälle, wie z. B. Inhaltsmoderation und Textextraktion aus Dokumenten. Sie können auch Ihre eigenen Workflows für ML-Modelle erstellen, die auf SageMaker oder anderen Tools basieren. Mit Amazon A2I können Sie es menschlichen Prüfern ermöglichen, einzugreifen, wenn ein Modell nicht in der Lage ist, eine hochzuverlässige Vorhersage zu treffen oder seine Vorhersagen nicht fortlaufend zu prüfen. Amazon A2I bietet vorgefertigte Vorlagen um Aufgaben-UI-Seiten zum Überprüfen von Audio, Bildern, Text und Video zu erstellen, und Sie können die Vorlagen an Ihre Bedürfnisse anpassen. Für unseren Anwendungsfall haben wir eine benutzerdefinierte Flüssigkeitsvorlage mit a erstellt Crowd-Polyline Element. Dies ermöglichte die Implementierung von aktivem Lernen, da menschliche Prüfer (unsere Forscher) nun mit einer Aufgaben-Benutzeroberfläche (einer Webseite) interagieren konnten, um die folgenden Schritte auszuführen:
- Werten Sie das ursprüngliche, teilweise kommentierte Eingabebild aus.
- Vergleichen Sie die vorhergesagten Anmerkungen aus dem Modell mit dem ursprünglichen, teilweise kommentierten Eingabebild.
- Verwenden Sie die interaktive Aufgaben-Benutzeroberfläche, um die vorhergesagten Anmerkungen und Bilder zu aktualisieren oder zu ändern und sie zur erneuten Schulung einzureichen.
Zunächst führen wir Sie durch die Einrichtung einer menschlichen Überprüfung mit Amazon A2I. Anschließend zeigen wir Ihnen, wie Sie eine Umschulung ermöglichen und den aktiven Lernworkflow abschließen.
Erstellen Sie eine Arbeitsaufgabenvorlage
Stellen Sie zunächst alles sicher Voraussetzungen für Amazon A2I erfüllt sind. Dazu gehört das Einrichten von S3-Buckets für Eingabe und Ausgabe, AWS Identity and Access Management and (IAM)-Rollen und eine Belegschaft für die menschlichen Überprüfungsworkflows.
Als Nächstes erstellen wir die Aufgaben-Benutzeroberfläche mithilfe einer Worker-Aufgabenvorlage in SageMaker. Die Worker-Aufgabenvorlage ist eine HTML-Datei, die es ermöglicht, die Benutzeroberfläche an den Anwendungsfall der menschlichen Überprüfung anzupassen. Für den Einstieg bietet SageMaker eine breite Palette an HTML-Komponenten zum Erstellen einer benutzerdefinierten Worker-Benutzeroberfläche. Für diesen Anwendungsfall benötigen wir, dass der Prüfer in der Lage ist, Liniensegmente auf der Benutzeroberfläche zu aktualisieren, die den Schneeschichten in einem Bild entsprechen. Wir haben uns für die Verwendung der Crowd-Form- und Crowd-Polyline-Elemente entschieden. Das Crowd-Form-Element stellt grundlegende Steuerelemente für die Benutzeroberfläche bereit, beispielsweise das Senden von Ergebnissen. Das Crowd-Polyline-Element ermöglicht dem Benutzer die Interaktion mit Liniensegmenten auf der Benutzeroberfläche, die zum Anpassen von Linien an die einzelnen Schneeschichten verwendet werden.
Nachdem wir nun die zu verwendenden UI-Komponenten identifiziert haben, müssen wir die Modelldaten einschließen, mit denen über die UI interagiert werden soll. Die Crowd-Polyline-Komponente enthält Felder zum Ausfüllen des Anfangswerts, der Beschriftungen und des Quellbilds. Diese Felder werden zum Ausfüllen der Schneeschichtdaten sowie des Bildes der Schneeschichten verwendet. Nachdem die Worker-Benutzeroberfläche gerendert wurde, kann der Prüfer zusätzliche Liniensegmente bearbeiten und hinzufügen. Um den Prüfer zu unterstützen, haben wir neben dem Crowd-Polyline-Editor auch die ursprüngliche Modellausgabe und beschriftete Eingabebilder eingefügt.
Der folgende Screenshot zeigt die Aufgaben-Benutzeroberfläche bei Aktivierung.

Das Folgende ist ein Codeausschnitt der Vorlage:
Erstellen Sie den Arbeitsablauf für die menschliche Überprüfung
Nachdem die Aufgabenvorlage fertiggestellt ist, fahren wir mit der Erstellung des Arbeitsablaufs für die menschliche Überprüfung fort. Dies legt Folgendes fest:
- Die Belegschaft, an die Aufgaben gesendet werden
- Die im vorherigen Schritt erstellte Aufgabenvorlage
- Der Ergebnisausgabeort
Wir können den Workflow über die API oder die Amazon A2I-Konsole erstellen. Sehen Erstellen Sie einen Human Review Workflow für weitere Einzelheiten.
Starten Sie menschliche Überprüfungsschleifen
Zu diesem Zeitpunkt haben wir unsere Aufgabenvorlage und den Workflow für die menschliche Überprüfung erstellt, der definiert, wie unsere Überprüfungs-Benutzeroberfläche aussehen und funktionieren soll. Das Einleiten menschlicher Überprüfungsschleifen ist der letzte Schritt im Amazon A2I-Prozess. Für jeden Satz gekennzeichneter Daten und Bilder erstellen wir eine menschliche Prüfschleife, um die Umgebung für unsere Prüfer zu schaffen. Sehen Erstellen und starten Sie eine menschliche Schleife für einen benutzerdefinierten Aufgabentyp für weitere Einzelheiten.
Die einzelnen Gutachter erstellen ein Konto und melden sich an, um erstellte Gutachten durchzuführen. Anschließend wählen sie aus einer Liste der ihnen zugewiesenen Aufgaben aus, wie im folgenden Screenshot dargestellt.

Nachdem sie eine Aufgabe ausgewählt haben, sehen sie die Aufgaben-Benutzeroberfläche, die mithilfe der benutzerdefinierten HTML-Komponenten erstellt wurde. Schließlich übermittelt der Benutzer seine Aktualisierungen, nachdem er die Polylinien an die Schneeschichten angepasst hat.

Umschulung aktivieren
Das folgende Diagramm zeigt die aktualisierte Architektur mit implementiertem aktivem Lernen.

Da nun die menschliche Überprüfungsschleife zum Ändern von Anmerkungen eingerichtet ist, müssen wir die Ergebnisse an den Prozess zur Implementierung einer automatischen Neuschulung zurücksenden, nachdem eine kritische Masse an Bildern von den Überprüfern korrigiert wurde. Wenn wir diesen Schritt abschließen, ist unsere Architektur vollständig für aktives Lernen geeignet. In unserem Fall haben wir entschieden, dass nach jeweils 100 Bildkorrekturen ein erneutes Training ausgelöst werden soll. Die Bilder mit den überlagerten korrigierten Anmerkungen werden in einem S3-Bucket gespeichert, und wir speichern auch die Anmerkungskoordinaten zusammen mit ihrem entsprechenden S3-Bildpräfix in einem Amazon DynamoDB Tabelle zum einfachen Abrufen und Indexieren.
Fazit und nächste Schritte
In diesem Beitrag haben wir erläutert, wie wir mit SageMaker und Amazon A2I einen aktiven Lern-ML-Workflow zur Verbesserung der Annotationsgenauigkeit bei der Verfolgung der arktischen Eisschicht eingerichtet haben. Dies ist für uns ein fortlaufendes Experiment und wir planen, einen Begleitbeitrag zu veröffentlichen, um die Ergebnisse in Form eines hochpräzisen kommentierten Datensatzes polarer Eisschichten zu teilen. Wir sind immer auf der Suche nach Mitarbeitern. Wenn das also interessant klingt, schauen Sie bei uns vorbei i-HARP.org oder hinterlassen Sie uns Feedback in den Kommentaren.
Über die Autoren
 Prem Ranga ist bei AWS auf ML und KI spezialisiert und unterstützt Kunden mit Leidenschaft bei der Lösung von NLP-, CV- und Deep-Learning-Problemen. Prem baute die Alexa-gesteuerten Bierstationen in Houston und anderen Standorten. Prem ist ein Packt-Autor. Sie können über diese und andere Veröffentlichungen unter https://www.linkedin.com/in/premkr/ lesen.
Prem Ranga ist bei AWS auf ML und KI spezialisiert und unterstützt Kunden mit Leidenschaft bei der Lösung von NLP-, CV- und Deep-Learning-Problemen. Prem baute die Alexa-gesteuerten Bierstationen in Houston und anderen Standorten. Prem ist ein Packt-Autor. Sie können über diese und andere Veröffentlichungen unter https://www.linkedin.com/in/premkr/ lesen.
 Dr. Masoud Yari ist Forschungsprofessor am iHARP Data Science Institute und am Bina Lab am College of Engineering and Information Technology der University of Maryland, Baltimore County, MD. Seine Forschungsinteressen umfassen maschinelles Lernen, Computer Vision, Fernerkundung, mathematische Modellierung und dynamische Systeme. Seine Leidenschaft besteht darin, umsetzbare Erkenntnisse aus Daten zu gewinnen und interdisziplinäre Forschungsteams und Projekte zur Lösung von Umwelt- und humanitären Problemen zu leiten.
Dr. Masoud Yari ist Forschungsprofessor am iHARP Data Science Institute und am Bina Lab am College of Engineering and Information Technology der University of Maryland, Baltimore County, MD. Seine Forschungsinteressen umfassen maschinelles Lernen, Computer Vision, Fernerkundung, mathematische Modellierung und dynamische Systeme. Seine Leidenschaft besteht darin, umsetzbare Erkenntnisse aus Daten zu gewinnen und interdisziplinäre Forschungsteams und Projekte zur Lösung von Umwelt- und humanitären Problemen zu leiten.
 Brett Seib ist ein AWS Enterprise Solutions Architect mit Sitz in Austin, TX. Seine Leidenschaft gilt der Innovation und der Lösung geschäftlicher Herausforderungen gemeinsam mit Kunden. Brett verfügt über mehrere Jahre Erfahrung in der IoT- und Datenanalysebranche und unterstützt Kunden bei der Innovation mit Daten.
Brett Seib ist ein AWS Enterprise Solutions Architect mit Sitz in Austin, TX. Seine Leidenschaft gilt der Innovation und der Lösung geschäftlicher Herausforderungen gemeinsam mit Kunden. Brett verfügt über mehrere Jahre Erfahrung in der IoT- und Datenanalysebranche und unterstützt Kunden bei der Innovation mit Daten.
 Morgan Dutton ist AWS Technical Program Manager beim Amazon Augmented AI- und Mechanical Turk-Team mit Sitz in Seattle, WA. Sie arbeitet mit Kunden aus dem akademischen und öffentlichen Sektor zusammen, um deren Nutzung von Human-in-the-Loop-ML-Diensten zu beschleunigen. Morgan ist besonders an der Zusammenarbeit mit akademischen Kunden interessiert, um die Einführung von ML-Technologien durch Forscher, Studenten und Pädagogen zu unterstützen.
Morgan Dutton ist AWS Technical Program Manager beim Amazon Augmented AI- und Mechanical Turk-Team mit Sitz in Seattle, WA. Sie arbeitet mit Kunden aus dem akademischen und öffentlichen Sektor zusammen, um deren Nutzung von Human-in-the-Loop-ML-Diensten zu beschleunigen. Morgan ist besonders an der Zusammenarbeit mit akademischen Kunden interessiert, um die Einführung von ML-Technologien durch Forscher, Studenten und Pädagogen zu unterstützen.
 Maryam Rahnemoonfar, Ph.D., ist PI und Direktor des NSF Data Science Institute-iHARP, Direktor des Labors für Computer Vision und Fernerkundung (Bina-Labor) und außerordentlicher Professor für KI und Datenwissenschaft am College of Engineering and Information Technology, UMBC. Zu ihren Forschungsinteressen gehören Deep Learning, Computer Vision, Data Science, KI für soziale Zwecke, Fernerkundung und Dokumentenbildanalyse. Ihre Forschungsprojekte wurden durch mehrere Auszeichnungen gefördert, darunter den NSF HDR Institute Award, den NSF BIGDATA Award, den Amazon Academic Research Award, den Amazon Machine Learning Award, Microsoft und IBM.
Maryam Rahnemoonfar, Ph.D., ist PI und Direktor des NSF Data Science Institute-iHARP, Direktor des Labors für Computer Vision und Fernerkundung (Bina-Labor) und außerordentlicher Professor für KI und Datenwissenschaft am College of Engineering and Information Technology, UMBC. Zu ihren Forschungsinteressen gehören Deep Learning, Computer Vision, Data Science, KI für soziale Zwecke, Fernerkundung und Dokumentenbildanalyse. Ihre Forschungsprojekte wurden durch mehrere Auszeichnungen gefördert, darunter den NSF HDR Institute Award, den NSF BIGDATA Award, den Amazon Academic Research Award, den Amazon Machine Learning Award, Microsoft und IBM.
- '
- &
- 000
- 100
- 11
- 2019
- 2020
- 98
- Zugang
- Konto
- aktiv
- Aktivitäten
- Zusätzliche
- Adoption
- Vorteil
- AI
- Alexa
- Algorithmus
- Algorithmen
- Alle
- Zulassen
- Amazon
- Amazon Machine Learning
- Amazon Sage Maker
- unter
- Analyse
- Analytik
- Apache
- Bienen
- Architektur
- Arktis
- Artikel
- Audio-
- Prüfung
- Austin
- Automatisiert
- Verfügbarkeit
- AWS
- Baltimore
- Bier
- BESTE
- Big Data
- Große Daten
- BRIDGE
- bauen
- Building
- Geschäft
- Cambridge
- Fälle
- challenges
- Übernehmen
- Klimawandel
- Cloud
- Cloud Computing
- CNN
- Code
- Zusammenarbeit
- Hochschule
- Colorados
- Bemerkungen
- gemeinsam
- Komponente
- Computer Vision
- Computing
- Konferenz
- Inhalt
- inhaltliche Moderation
- fortsetzen
- weiter
- Korrekturen
- Grafschaft
- Erstellen
- Kunden
- technische Daten
- Datenanalyse
- Datenanalyse
- Datenwissenschaft
- tiefe Lernen
- Demand
- Entdeckung
- Entwicklung
- Direktor
- Unterlagen
- Edge
- Herausgeber
- Effektiv
- Endpunkt
- Entwicklung
- Unternehmen
- Enterprise-Lösungen
- Arbeitsumfeld
- Umwelt-
- Veranstaltungen
- ERFAHRUNGEN
- Experten
- Extraktion
- Honorare
- Felder
- Abbildung
- Endlich
- Vorname
- passen
- Flexibilität
- Flugkosten
- unten stehende Formular
- Format
- Foundation
- Unser Ansatz
- Funktion
- kapitalgedeckten
- Zukunft
- Global
- gut
- Hosting
- Ultraschall
- Hilfe
- HTTPS
- riesig
- Mensch in der Schleife
- humanitär
- IAM
- IBM
- EIS
- identifizieren
- Identitätsschutz
- IEEE
- Image
- Bildanalyse
- Einschließlich
- Erhöhung
- Branchen
- Information
- Informatik
- Infrastruktur
- Einblicke
- interaktive
- iot
- IT
- Jupyter Notizbuch
- Kansas
- Wissen
- Beschriftung
- Etiketten
- Arbeit
- grosse
- führen
- Leadership
- führenden
- LERNEN
- lernen
- LENDEN
- Niveau
- Limitiert
- Line
- Flüssigkeit
- Liste
- aus einer regionalen
- Maschinelles Lernen
- Making
- Karte
- Maryland
- Microsoft
- ML
- ML-Algorithmen
- Modell
- Modellieren
- schlauer bewegen
- NASA
- Netto-
- Neural
- Nlp
- Lärm
- Angebote
- Option
- Optionen
- Andere
- Papier
- Schnittmuster
- Personen
- Rohr
- Pixel
- Planet
- Prognose
- Prognosen
- Gegenwart
- Programm
- Projekte
- Beweis
- Öffentlichkeit
- Öffentlicher Sektor
- Publikationen
- veröffentlichen
- Python
- Qualität
- Radar
- Angebot
- Roh
- Rohdaten
- Echtzeit
- Aufzeichnungen
- Beziehungen
- Voraussetzungen:
- Forschungsprojekte
- Downloads
- REST
- Die Ergebnisse
- Umschulung
- Überprüfen
- Bewertungen
- Führen Sie
- Laufen
- sagemaker
- Skalierbarkeit
- Skalieren
- Wissenschaft
- Wissenschaftler
- WASSER
- Meereshöhe
- Seattle
- Sensoren
- Lösungen
- kompensieren
- Einstellung
- Teilen
- Einfacher
- Größe
- Schnappschuss
- .
- So
- Social Media
- Social Good
- Lösungen
- LÖSEN
- Raumfahrt
- spezialisiert
- Geschwindigkeit
- Stufe
- Anfang
- begonnen
- Lagerung
- speichern
- Streaming
- Studie
- Supercomputer
- Support
- Unterstützte
- Oberfläche
- synthetische Daten
- Systeme und Techniken
- Technische
- Techniken
- Technologies
- Technologie
- Test
- Tests
- Zeit
- Top
- Themen
- verfolgen sind
- Tracking
- Ausbildung
- Trends
- ui
- aufdecken
- Vereinigt
- vereinigte nationen
- Universität
- University of Maryland
- Aktualisierung
- Updates
- us
- Wert
- Geschwindigkeit
- Video
- Sichtbarkeit
- Seh-
- Ansehen
- Wasser
- Wellen
- Weben
- Webseite
- Arbeiten
- Arbeitsablauf.
- Belegschaft
- Werk
- Jahr


