Während OpenAI ChatGPT den ganzen Sauerstoff aus dem 24-Stunden-Nachrichtenzyklus saugt, hat Google leise ein neues KI-Modell vorgestellt, das Videos generieren kann, wenn Video-, Bild- und Texteingaben gegeben werden. Der neue Google Dreamix AI-Videoeditor bringt generierte Videos jetzt näher an die Realität.
Laut den auf GitHub veröffentlichten Recherchen bearbeitet Dreamix das Video basierend auf einem Video und einer Textaufforderung. Das resultierende Video behält seine Treue zu Farbe, Haltung, Objektgröße und Kamerapose bei, was zu einem zeitlich konsistenten Video führt. Im Moment kann Dreamix keine Videos nur aus einer Eingabeaufforderung generieren, es kann jedoch vorhandenes Material nehmen und das Video mithilfe von Texteingabeaufforderungen modifizieren.
Google verwendet Videodiffusionsmodelle für Dreamix, ein Ansatz, der erfolgreich für die meisten Videobildbearbeitungen angewendet wurde, die wir in Bild-KIs wie DALL-E2 oder der Open-Source-Version Stable Diffusion sehen.
Der Ansatz besteht darin, das Eingangsvideo stark zu reduzieren, künstliches Rauschen hinzuzufügen und es dann in einem Videodiffusionsmodell zu verarbeiten, das dann eine Texteingabe verwendet, um daraus ein neues Video zu generieren, das einige Eigenschaften des Originalvideos beibehält und andere entsprechend neu rendert zur Texteingabe.
Das Videoverbreitungsmodell bietet eine vielversprechende Zukunft, die eine neue Ära für die Arbeit mit Videos einläuten könnte.

Im folgenden Video verwandelt Dreamix beispielsweise den fressenden Affen (links) in einen tanzenden Bären (rechts), wenn die Aufforderung „Ein Bär, der zu fröhlicher Musik tanzt und springt und seinen ganzen Körper bewegt“ gegeben wird.
In einem weiteren Beispiel unten verwendet Dreamix ein einzelnes Foto als Vorlage (wie bei Bild-zu-Video) und daraus wird dann über eine Eingabeaufforderung ein Objekt in einem Video animiert. Kamerabewegungen sind auch in der neuen Szene oder einer anschließenden Zeitrafferaufnahme möglich.
In einem anderen Beispiel verwandelt Dreamix den Orang-Utan in einem Wasserbecken (links) in einen Orang-Utan mit orangefarbenem Haar, der in einem schönen Badezimmer badet.
„Während Diffusionsmodelle erfolgreich für die Bildbearbeitung angewendet wurden, haben dies nur sehr wenige Arbeiten für die Videobearbeitung getan. Wir präsentieren die erste diffusionsbasierte Methode, die in der Lage ist, eine textbasierte Bewegungs- und Erscheinungsbearbeitung von allgemeinen Videos durchzuführen.“
Laut dem Google-Forschungspapier verwendet Dreamix ein Videodiffusionsmodell, um zum Zeitpunkt der Inferenz die räumlich-zeitlichen Informationen mit niedriger Auflösung aus dem Originalvideo mit neuen, hochauflösenden Informationen zu kombinieren, die es synthetisiert hat, um sie an der Leittextaufforderung auszurichten.
Google sagte, es habe diesen Ansatz gewählt, weil „um High-Fidelity für das Originalvideo zu erhalten, einige seiner hochauflösenden Informationen beibehalten werden müssen, fügen wir eine Vorstufe zur Feinabstimmung des Modells auf dem Originalvideo hinzu, wodurch die Wiedergabetreue erheblich gesteigert wird“.
Nachfolgend finden Sie eine Videoübersicht über die Funktionsweise von Dreamix.
[Eingebetteten Inhalt]
Wie Dreamix-Videodiffusionsmodelle funktionieren
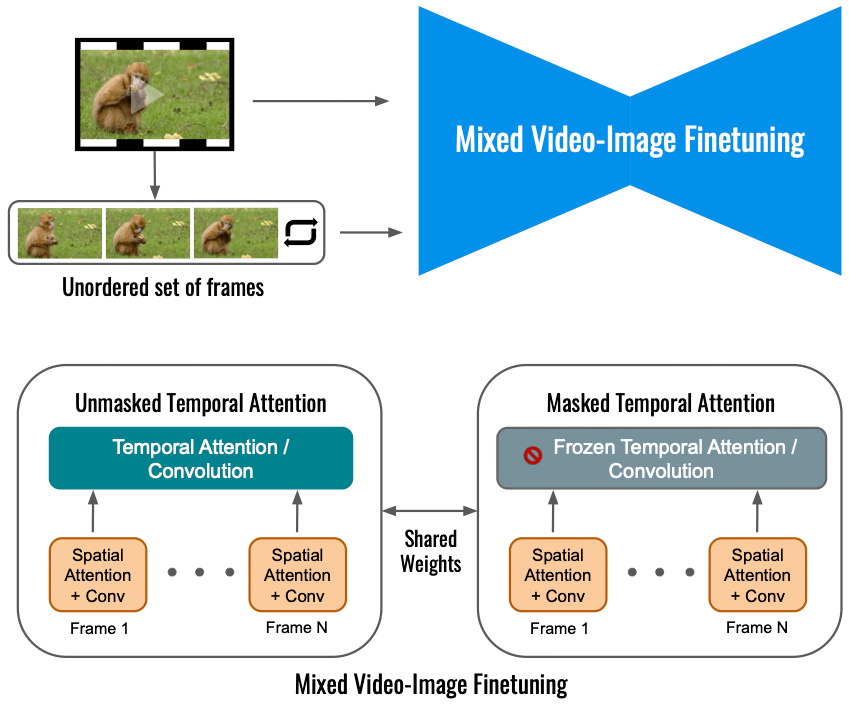
Laut Google begrenzt die Feinabstimmung des Videodiffusionsmodells für Dreamix allein auf das Eingangsvideo das Ausmaß der Bewegungsänderung. Stattdessen verwenden wir ein gemischtes Objektiv, das neben dem ursprünglichen Objektiv (unten links) auch auf den ungeordneten Satz von Frames abstimmt. Dies geschieht durch die Verwendung von „maskierter zeitlicher Aufmerksamkeit“, wodurch verhindert wird, dass die zeitliche Aufmerksamkeit und Faltung fein abgestimmt werden (unten rechts). Dies ermöglicht das Hinzufügen von Bewegung zu einem statischen Video.
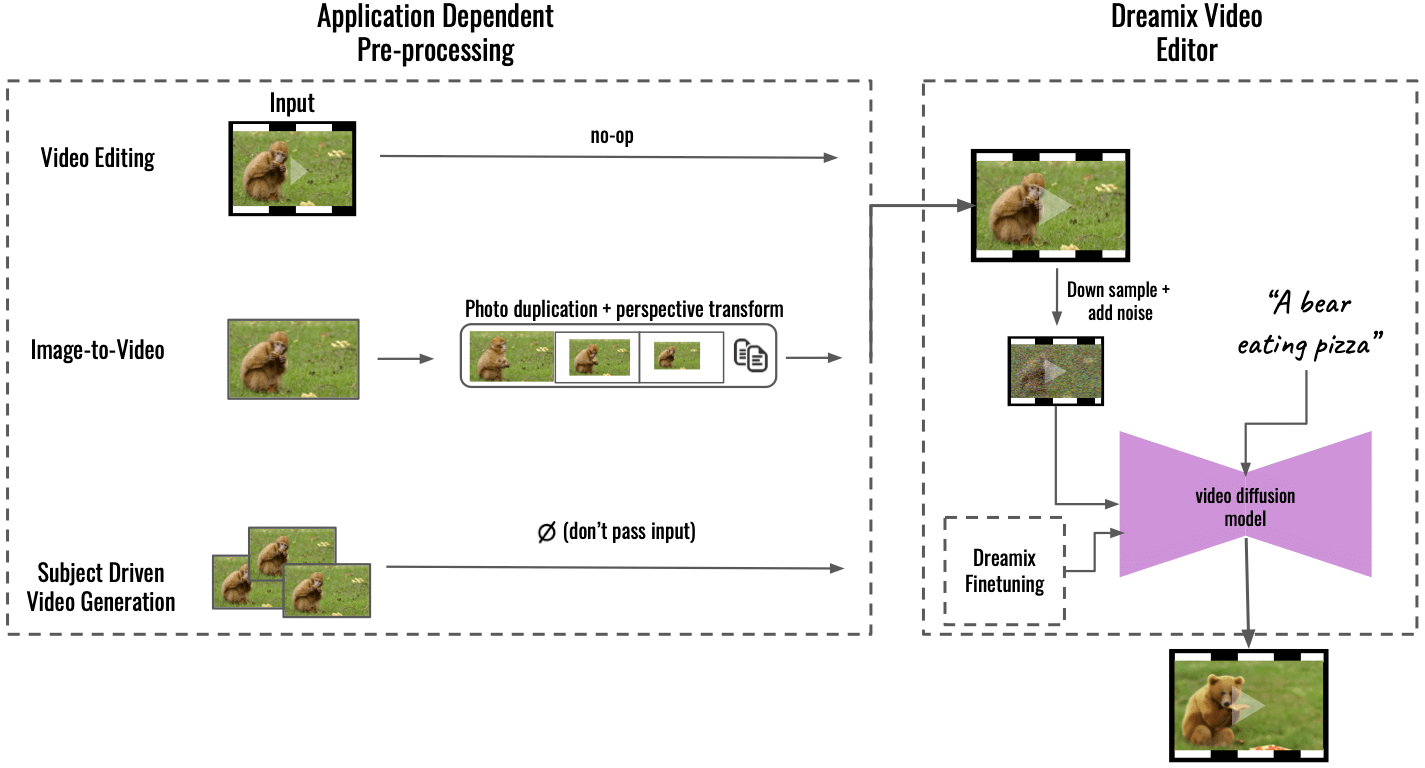
„Unser Verfahren unterstützt mehrere Anwendungen durch eine anwendungsabhängige Vorverarbeitung (links), die die Eingangsinhalte in ein einheitliches Videoformat umwandelt. Für Bild-zu-Video wird das Eingangsbild dupliziert und mithilfe von perspektivischen Transformationen transformiert, wodurch ein grobes Video mit etwas Kamerabewegung synthetisiert wird. Bei der themenbezogenen Videogenerierung entfällt die Eingabe – allein die Feinabstimmung sorgt für die Wiedergabetreue. Dieses grobe Video wird dann mit unserem allgemeinen „Dreamix Video Editor“ (rechts) bearbeitet: Wir beschädigen das Video zuerst durch Downsampling, gefolgt von Rauschen. Wir wenden dann das fein abgestimmte textgeführte Videodiffusionsmodell an, das das Video auf die endgültige räumlich-zeitliche Auflösung hochskaliert“, schrieb Dream weiter GitHub.
Sie können das Forschungspapier unten lesen.
Google Dreamix- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Fähig
- Nach
- AI
- ai Video
- AI-powered
- Alle
- erlaubt
- allein
- und
- Ein anderer
- Anwendungen
- angewandt
- Jetzt bewerben
- Ansatz
- künstlich
- Aufmerksamkeit
- basierend
- Denken Sie
- schön
- weil
- Sein
- unten
- Körper
- Stärkung
- Boden
- Brings
- Kamera
- kann keine
- österreichische Unternehmen
- Übernehmen
- ChatGPT
- näher
- Farbe
- kombinieren
- konsistent
- Inhalt
- Erstellen
- Zyklus
- Tanzen
- Rundfunk
- Traum
- Herausgeber
- eingebettet
- Era
- Beispiel
- vorhandenen
- wenige
- Treue
- Finale
- Vorname
- gefolgt
- Format
- für
- Zukunft
- Allgemeines
- erzeugen
- erzeugt
- Generation
- gif
- GitHub
- gegeben
- Haarfarbe
- schwer
- hochauflösenden
- Ultraschall
- aber
- HTTPS
- Image
- Bilder
- in
- Information
- Eingabe
- beantragen müssen
- IT
- startet
- Grenzen
- unterhält
- Ihres Materials
- max
- Methode
- gemischt
- Modell
- für
- ändern
- Moment
- vor allem warme
- Bewegung
- Bewegungen
- ziehen um
- mehrere
- Musik
- Neu
- News
- Lärm
- Objekt
- Ziel
- Angebote
- Open-Source-
- OpenAI
- Orange
- Original
- Anders
- Überblick
- Sauerstoff
- Papier
- ausführen
- Perspektive
- Plato
- Datenintelligenz von Plato
- PlatoData
- Pool
- möglich
- Gegenwart
- Verhütung
- Verarbeitung
- aussichtsreich
- immobilien
- veröffentlicht
- ruhig
- Lesen Sie mehr
- Realität
- Einspielung vor
- Reduzierung
- erfordert
- Forschungsprojekte
- Auflösung
- was zu
- Halte
- Said
- Szene
- kompensieren
- bedeutend
- Single
- Größe
- So
- einige
- stabil
- Stufe
- Folge
- Erfolgreich
- so
- Unterstützt
- Nehmen
- Vorlage
- Das
- Zeit
- zu
- Transformationen
- verwandelt
- enthüllt
- -
- Video
- Videos
- Wasser
- welche
- arbeiten,
- Werk
- Youtube
- Zephyrnet











