Heutzutage verwalten Kunden riesige Datenmengen in ihrem Unternehmen Amazon Simple Storage-Service (Amazon S3) Data Lakes, die komplizierte Datenpipelines erfordern, um die Änderungen im Datenlayout kontinuierlich zu verstehen und sie den verbrauchenden Systemen zur Verfügung zu stellen. AWS-Kleber Crawler bieten eine unkomplizierte Möglichkeit, Daten im AWS Glue Data Catalog zu katalogisieren, wodurch die schwere Arbeit bei der Schemaverwaltung und Datenklassifizierung entfällt. AWS Glue-Crawler extrahieren das Datenschema und die Partitionen aus Amazon S3, um den Datenkatalog automatisch zu füllen und die Metadaten auf dem neuesten Stand zu halten.
Da die Daten jedoch im Laufe der Zeit exponentiell wachsen, kann die Anzahl der Partitionen in einer bestimmten Tabelle erheblich zunehmen. Weil Analysedienste mögen Amazonas Athena Wenn Sie eine Tabelle mit Millionen von Partitionen abfragen, erhöht sich die Zeit, die zum Abrufen der Partition benötigt wird, und kann zu einer Verlängerung der Abfragelaufzeit führen.
Heute wurde die AWS Glue-Crawler-Unterstützung erweitert, um automatisch Partitionsindizes für neu entdeckte Tabellen hinzuzufügen, um die Abfrageverarbeitung für den partitionierten Datensatz zu optimieren. Wenn der Crawler nun während einer Crawler-Ausführung eine neue Datenkatalogtabelle erstellt, erstellt er standardmäßig auch einen Partitionsindex mit der größten Permutation aller numerischen und Zeichenfolgentyp-Partitionsspalten als Schlüssel. Der Datenkatalog erstellt dann einen durchsuchbaren Index basierend auf diesen Schlüsseln und reduziert so die Zeit, die zum Abrufen und Filtern von Partitionsmetadaten für Tabellen mit Millionen von Partitionen erforderlich ist. Die Erstellung von Partitionsindizes kommt den auf Athena ausgeführten Analyse-Workloads zugute. Amazon EMR, Amazon Redshift-Spektrumund AWS Glue.
In diesem Beitrag beschreiben wir, wie Sie Partitionsindizes mit einem AWS Glue-Crawler erstellen und vergleichen die Verbesserung der Abfrageleistung beim Zugriff auf die gecrawlten Daten mit und ohne Partitionsindex von Athena.
Lösungsüberblick
Wir verwenden eine AWS CloudFormation Vorlage zum Erstellen unserer Lösungsressourcen. In den folgenden Schritten zeigen wir, wie Sie den AWS Glue-Crawler so konfigurieren, dass er mithilfe der AWS Glue-Konsole oder der einen Partitionsindex erstellt AWS-Befehlszeilenschnittstelle (AWS CLI). Anschließend vergleichen wir die Verbesserungen der Abfrageleistung mit Athena.
Voraussetzungen:
Um diesem Beitrag folgen zu können, müssen Sie Zugriff auf eine haben AWS Identity and Access Management and (IAM)-Administratorrolle zum Erstellen von Ressourcen mithilfe von AWS CloudFormation.
Richten Sie Ihre Lösungsressourcen ein
Die CloudFormation-Vorlage generiert die folgenden Ressourcen:
- IAM-Rollen und -Richtlinien
- Eine AWS Glue-Datenbank zur Speicherung des Schemas
- Ein AWS Glue-Crawler, der auf einen stark partitionierten Datensatz verweist
- Eine Athena-Arbeitsgruppe und ein Bucket zum Speichern von Abfrageergebnissen
Führen Sie die folgenden Schritte aus, um die Lösungsressourcen einzurichten:
- Melden Sie sich bei der AWS-Managementkonsole als IAM-Administrator.
- Auswählen
Stack starten So stellen Sie die CloudFormation-Vorlage bereit:

- Aussichten für DatenbanknameBehalten Sie die Standardeinstellung bei
blog_partition_index_crawlerdb.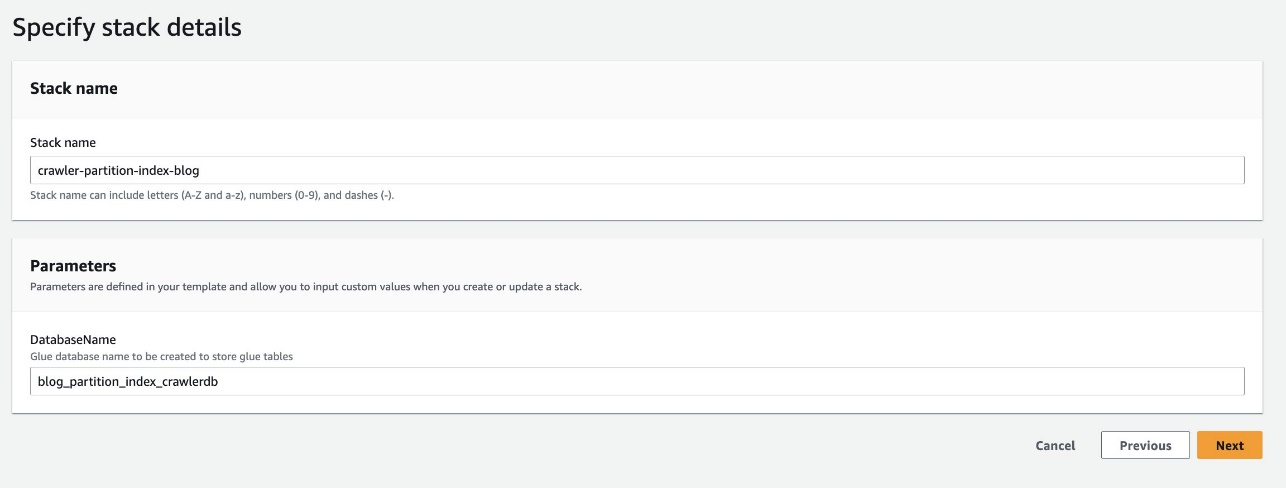
- Auswählen Weiter.
- Überprüfen Sie die Details auf der letzten Seite und wählen Sie Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt.
- Auswählen Stapel erstellen.
- Wenn der Stack vollständig ist, navigieren Sie in der AWS CloudFormation-Konsole zu der Ausgänge Registerkarte des Stapels.
- Notieren Sie sich die Werte von
DatabaseNameundGlueCrawlerName.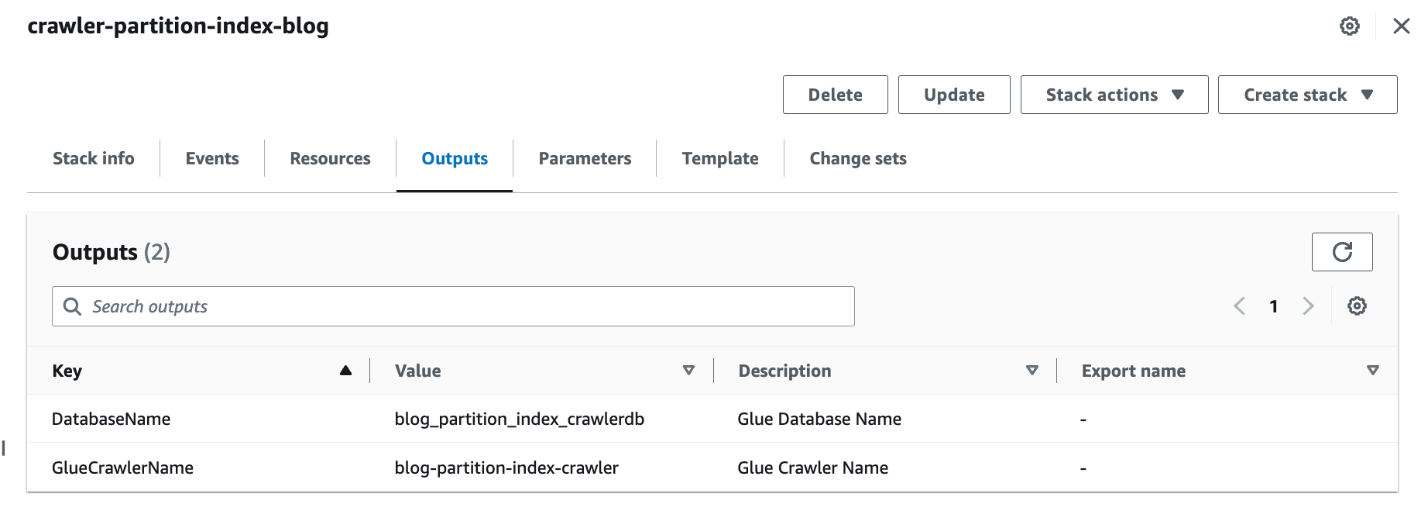
Für einige der von diesem Stack bereitgestellten Ressourcen fallen bei der Nutzung Kosten an.
Bearbeiten Sie den AWS Glue-Crawler und führen Sie ihn aus
Führen Sie die folgenden Schritte aus, um den AWS Glue-Crawler zu konfigurieren und auszuführen:
- Wählen Sie in der AWS Glue-Konsole aus Crawlers im Navigationsbereich.
- Suchen Sie den
crawler blog-partition-index-crawlerund wählen Sie Bearbeiten.
- Im Ausgabe und Zeitplanung festlegen Abschnitt, unter Erweiterte OptionenWählen Partitionsindizes automatisch erstellen.
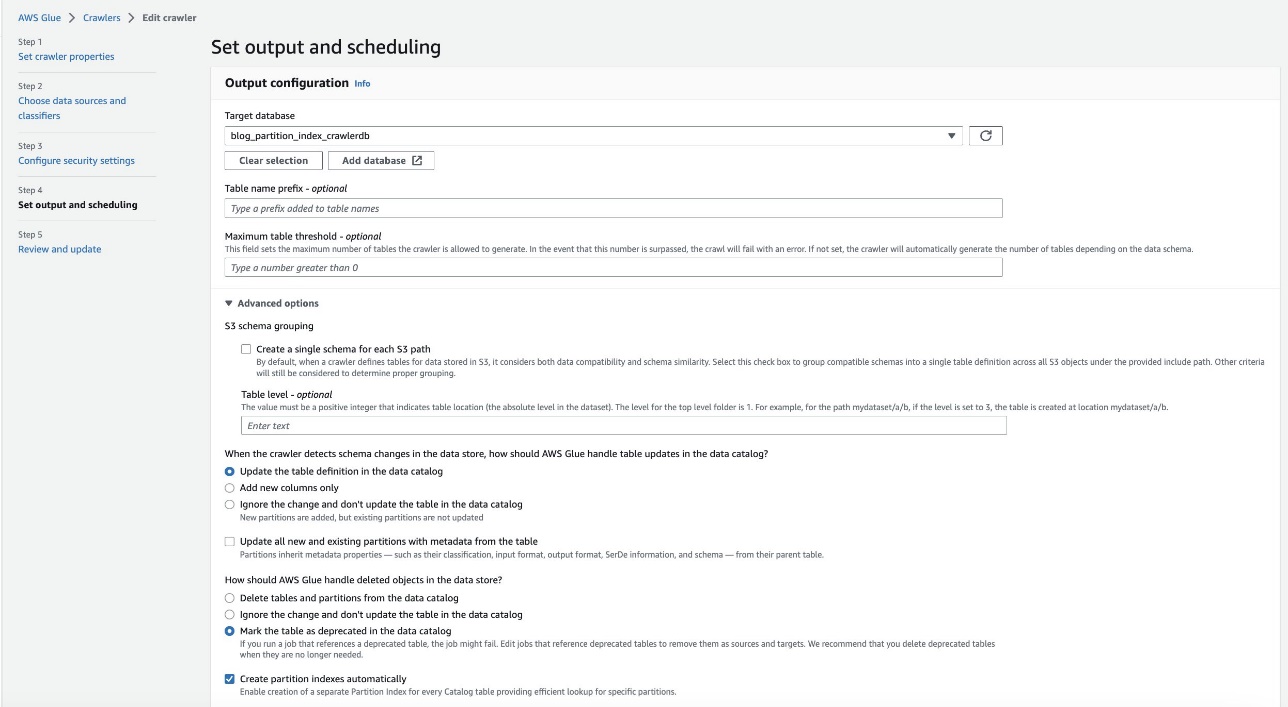
- Überprüfen und aktualisieren Sie die Crawler-Einstellungen.
Alternativ können Sie Ihren Crawler mithilfe der AWS CLI konfigurieren (geben Sie Ihre IAM-Rolle und Region an):
- Führen Sie nun den Crawler aus und stellen Sie sicher, dass die Crawler-Ausführung abgeschlossen ist.
Dies ist ein hochpartitionierter Datensatz, dessen Fertigstellung etwa 90 Minuten in Anspruch nimmt.
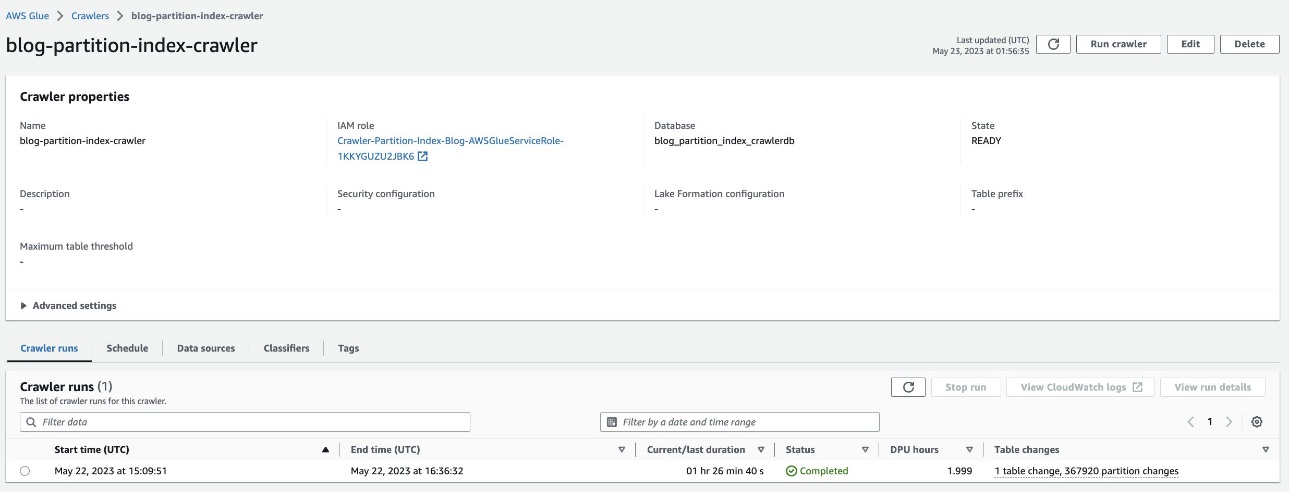
Überprüfen Sie die partitionierte Tabelle
In der AWS Glue-Datenbank blog_partition_index_crawlerdb, überprüfen Sie, ob die Tabelle highly_partitioned_table geschaffen.
Standardmäßig bestimmt der Crawler einen Index basierend auf der größten Permutation von Partitionsspalten gültiger Spaltentypen in derselben Reihenfolge von Partitionsspalten, die entweder numerisch oder Zeichenfolgen sind. Für die vom Crawler erstellte Tabelle (highly_partitioned_table), haben wir Partitionsspalten year (Zeichenfolge), month (Zeichenfolge), day (Zeichenfolge) und hour (String).
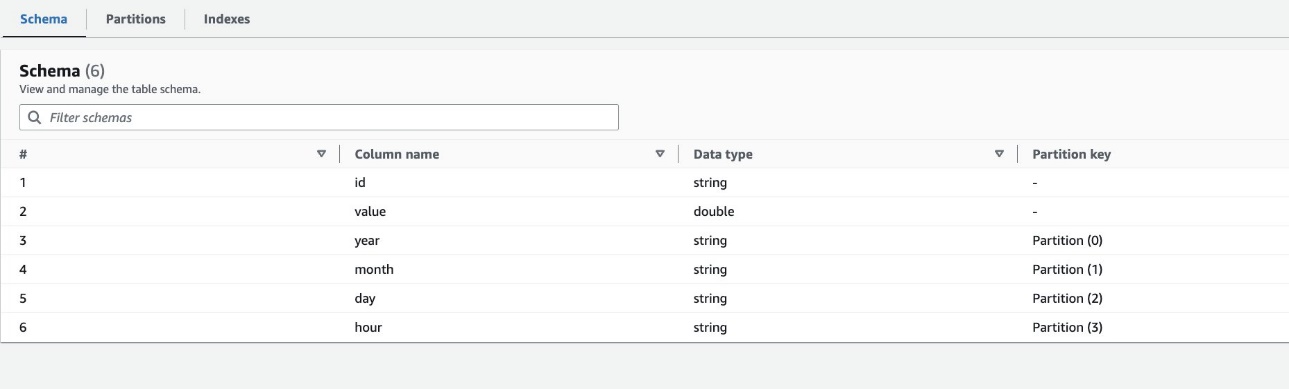
Basierend auf dieser Definition erstellte der Crawler einen Index für die Permutation von Jahr, Monat, Tag und Stunde. Der Crawler hat die Indizes mit dem Präfix erstellt crawler_ auf jedem standardmäßig erstellten Partitionsindex.
Überprüfen Sie dies, indem Sie zur Tabelle navigieren highly_partitioned_table auf der AWS Glue-Konsole und wählen Sie die aus Indizes Tab.
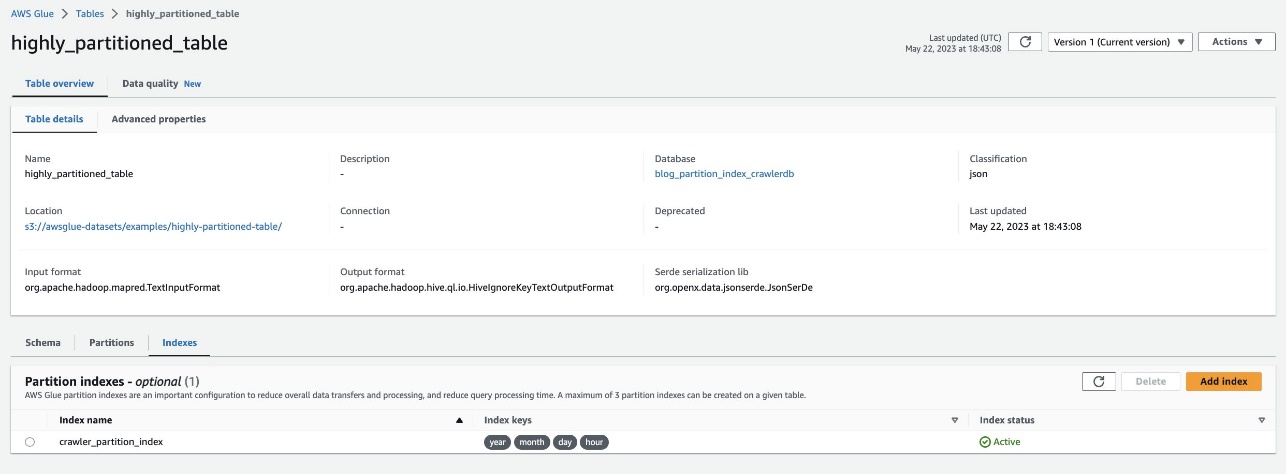
Der Crawler konnte die S3-Datenquelle crawlen und die Partitionsindizes für die Tabelle erfolgreich füllen.
Vergleichen Sie die Verbesserungen der Abfrageleistung mit Athena
Zuerst fragen wir die Tabelle in Athena ab, ohne den Partitionsindex zu verwenden. Führen Sie die folgenden Schritte aus, um die Tabellen mit Athena zu überprüfen:
- Wählen Sie auf der Athena-Konsole
crawler-primary-workgroupals Athena-Arbeitsgruppe und wählen Sie Bestätigen.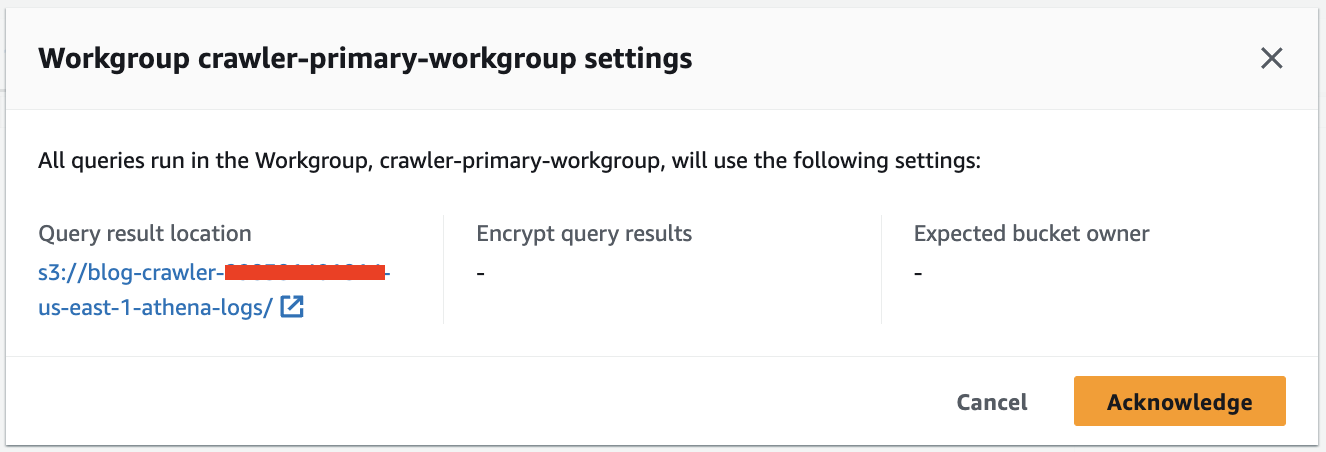
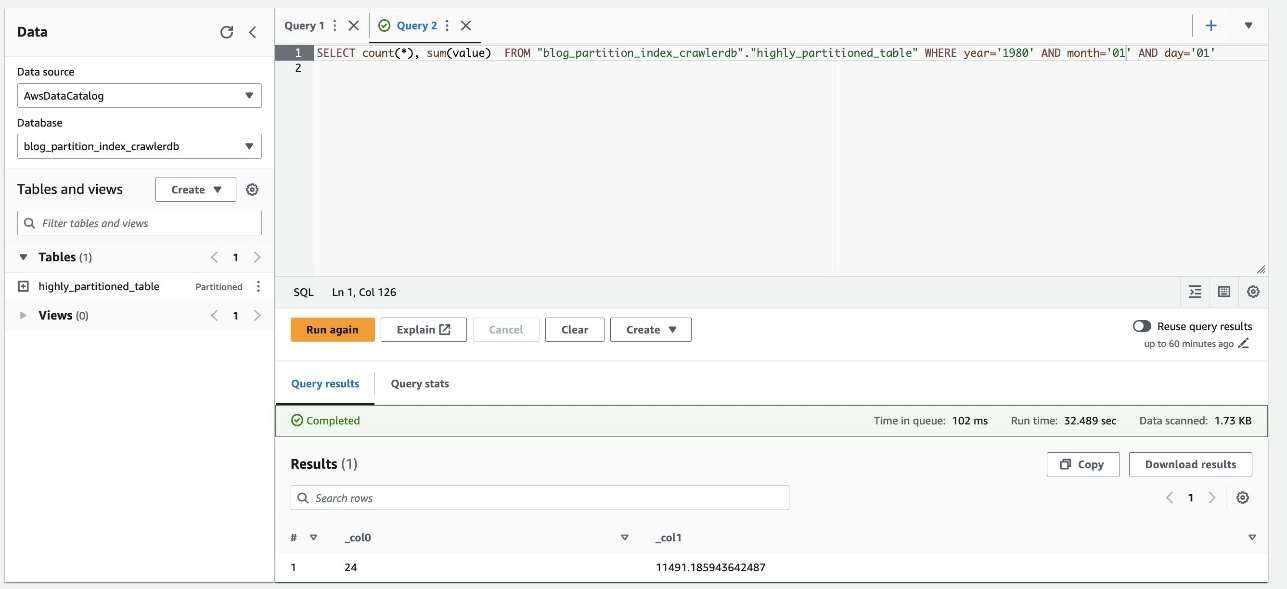
- Führen Sie die folgende Abfrage aus:
Der folgende Screenshot zeigt, dass die Abfrage etwa 32 Sekunden dauerte, ohne dass die Filterung mithilfe des Partitionsindex aktiviert war.
- Jetzt aktivieren wir den Partitionsindex für die Athena-Abfrage:
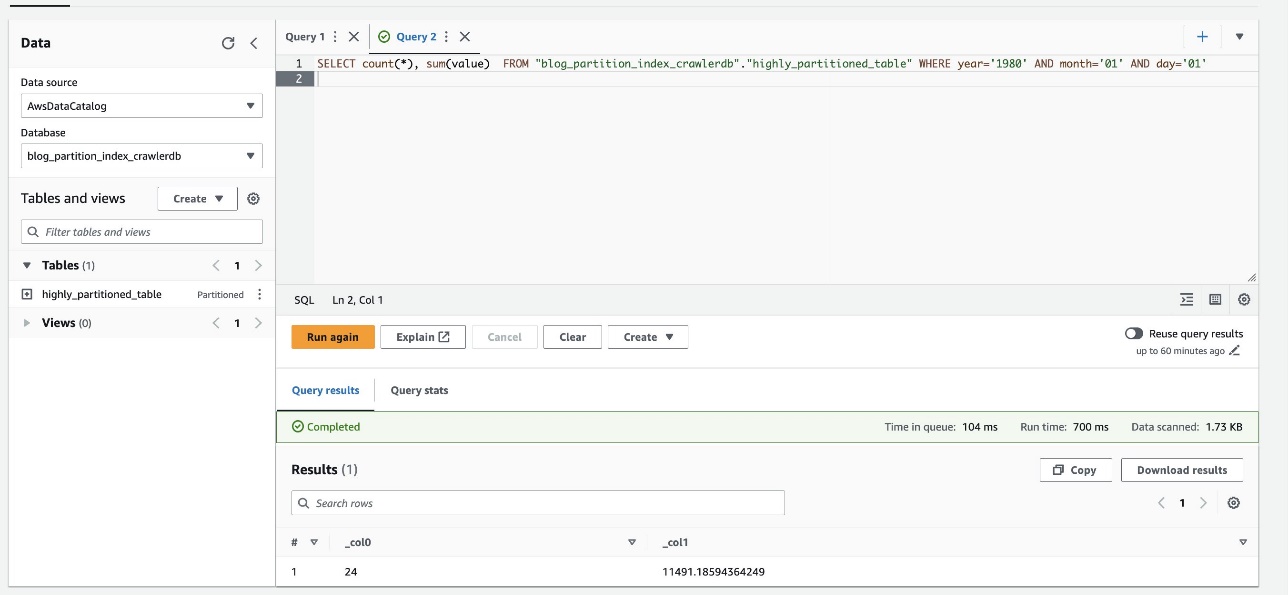
- Führen Sie die folgende Abfrage erneut aus und notieren Sie die Laufzeit:
Der folgende Screenshot zeigt, dass die Abfrage nur 700 Millisekunden dauerte, was viel schneller ist, wenn die Filterung mithilfe des Partitionsindex aktiviert ist.
Aufräumen
Um unerwünschte Belastungen Ihres AWS-Kontos zu vermeiden, können Sie die AWS-Ressourcen löschen:
- Melden Sie sich bei der CloudFormation-Konsole als IAM-Administrator an, der zum Erstellen des CloudFormation-Stacks verwendet wird.
- Löschen Sie den von Ihnen erstellten CloudFormation-Stack.
Zusammenfassung
In diesem Beitrag erklärten wir, wie man einen AWS-Crawler konfiguriert, um Partitionsindizes zu erstellen, und verglichen die Abfrageleistung beim Zugriff auf die Daten mit Indizes von Athena.
Wenn in der Tabelle keine Partitionsindizes vorhanden sind, lädt AWS Glue alle Partitionen der Tabelle und filtert dann die geladenen Partitionen, was zu einem ineffizienten Abruf von Metadaten führt. Analysedienste wie Redshift Spectrum, Amazon EMR und AWS Glue ETL Spark DataFrames können jetzt Indizes zum Abrufen von Partitionen verwenden, was zu einer erheblichen Abfrageleistung führt.
Weitere Informationen zu Partitionsindizes und der Abfrageleistung in verschiedenen Analyse-Engines finden Sie unter Verbessern Sie die Abfrageleistung von Amazon Athena mithilfe von AWS Glue Data Catalog-Partitionsindizes und Verbessern Sie die Abfrageleistung mit AWS Glue-Partitionsindizes.
Besonderer Dank geht an alle, die zum Start dieser Crawler-Funktion beigetragen haben: Yuhang Chen, Kyle Duong und Mita Gavade.
Über die Autoren
 Srividya Parthasarathy ist Senior Big Data Architect im AWS Lake Formation Team. Sie entwickelt gerne Data-Mesh-Lösungen und teilt sie mit der Community.
Srividya Parthasarathy ist Senior Big Data Architect im AWS Lake Formation Team. Sie entwickelt gerne Data-Mesh-Lösungen und teilt sie mit der Community.
 Sandeep Adwankar ist Senior Technical Product Manager bei AWS. Er lebt in der California Bay Area und arbeitet mit Kunden auf der ganzen Welt zusammen, um geschäftliche und technische Anforderungen in Produkte umzusetzen, die es Kunden ermöglichen, die Verwaltung, Sicherung und den Zugriff auf Daten zu verbessern.
Sandeep Adwankar ist Senior Technical Product Manager bei AWS. Er lebt in der California Bay Area und arbeitet mit Kunden auf der ganzen Welt zusammen, um geschäftliche und technische Anforderungen in Produkte umzusetzen, die es Kunden ermöglichen, die Verwaltung, Sicherung und den Zugriff auf Daten zu verbessern.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- EVM-Finanzen. Einheitliche Schnittstelle für dezentrale Finanzen. Hier zugreifen.
- Quantum Media Group. IR/PR verstärkt. Hier zugreifen.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :hast
- :Ist
- :Wo
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Fähig
- Zugang
- Zugriff
- Konto
- anerkennen
- über
- hinzufügen
- Administrator
- aufs Neue
- Alle
- entlang
- ebenfalls
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- Beträge
- an
- Analytische
- Analytik
- und
- jedem
- ca.
- SIND
- Bereich
- um
- AS
- At
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- vermeiden
- AWS
- AWS CloudFormation
- AWS-Kleber
- AWS Lake-Formation
- basierend
- Bucht
- weil
- war
- Vorteile
- Big
- Big Data
- Building
- Geschäft
- by
- Kalifornien
- CAN
- Katalog
- Verursachen
- Änderungen
- Gebühren
- chen
- Auswählen
- Auswahl
- Einstufung
- Kolonne
- Spalten
- kommt
- community
- vergleichen
- verglichen
- abschließen
- Konsul (Console)
- ständig
- beigetragen
- Kosten
- Crawler
- erstellen
- erstellt
- schafft
- Erstellen
- Schaffung
- Strom
- Kunden
- technische Daten
- Datenzugriff
- Datensee
- Datenbase
- Tag
- Standard
- zeigen
- einsetzen
- setzt ein
- beschreiben
- Details
- entschlossen
- entdeckt
- nach unten
- im
- effizient
- entweder
- ermöglichen
- freigegeben
- Motor (en)
- Äther (ETH)
- jedermann
- ergänzt
- erklärt
- exponentiell
- Extrakt
- Extrahieren Sie die Daten
- beschleunigt
- Merkmal
- Filter
- Filterung
- Filter
- Finale
- folgen
- Folgende
- Aussichten für
- Ausbildung
- für
- erzeugt
- gegeben
- Globus
- Wachsen Sie über sich hinaus
- persönlichem Wachstum
- Haben
- he
- schwer
- schweres Heben
- hoch
- Stunde
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- IAM
- Identitätsschutz
- zu unterstützen,
- Verbesserung
- Verbesserungen
- in
- Erhöhung
- Steigert
- Index
- Indizes
- ineffizient
- Information
- in
- IT
- jpg
- Behalten
- Aufbewahrung
- Tasten
- See
- höchste
- starten
- Layout
- Facelift
- Gefällt mir
- Line
- Belastungen
- um
- verwalten
- Management
- Manager
- ineinander greifen
- Metadaten
- könnte
- Millionen
- Minuten
- Monat
- mehr
- viel
- sollen
- Navigieren
- navigieren
- Menü
- erforderlich
- Neu
- neu
- nicht
- jetzt an
- Anzahl
- of
- on
- einzige
- Optimieren
- or
- Auftrag
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- übrig
- Seite
- Brot
- Weg
- Leistung
- Plato
- Datenintelligenz von Plato
- PlatoData
- Post
- Gegenwart
- Verarbeitung
- Produkt
- Produkt-Manager
- Produkte
- die
- Reduzierung
- Region
- falls angefordert
- Voraussetzungen:
- erfordert
- Downloads
- was zu
- Die Ergebnisse
- Rollen
- Rollen
- Führen Sie
- Laufen
- gleich
- Sekunden
- Abschnitt
- Verbindung
- Senior
- Lösungen
- kompensieren
- Einstellungen
- ,,teilen"
- sie
- Konzerte
- signifikant
- bedeutend
- Einfacher
- Lösung
- Lösungen
- Quelle
- Spark
- Spektrum
- Stapel
- Shritte
- Lagerung
- speichern
- einfach
- Schnur
- Erfolgreich
- Support
- Systeme und Techniken
- Tabelle
- Nehmen
- Team
- Technische
- Vorlage
- dank
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Zeit
- zu
- heutigen
- nahm
- Übersetzen
- was immer dies auch sein sollte.
- tippe
- Typen
- für
- verstehen
- unerwünscht
- Aktualisierung
- -
- benutzt
- Verwendung von
- Nutzen
- Wert
- Werte
- verschiedene
- riesig
- überprüfen
- Version
- wurde
- Weg..
- we
- Netz
- Web-Services
- wann
- welche
- WHO
- werden wir
- mit
- ohne
- Arbeitsgruppen
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- YAML
- Jahr
- U
- Ihr
- Zephyrnet