In 2022, wir haben Ihnen von den neuen Verbesserungen erzählt, die wir vorgenommen haben Amazon EMR-verwaltete Skalierung, was dazu beitrug, die Cluster-Auslastung zu verbessern und die Cluster-Kosten zu senken. Wir freuen uns, Ihnen im Jahr 2023 mitteilen zu können, dass das Amazon EMR-Team hart gearbeitet hat. Wir haben die Kundenanforderungen berücksichtigt und mehrere neue Funktionen eingeführt, um Ihr Amazon EMR auf EC2-Cluster-Kapazitätsmanagement und die Skalierungserfahrung zu verbessern.
Amazon EMR ist die Cloud-Big-Data-Lösung für Datenverarbeitung im Petabyte-Bereich, interaktive Analysen und maschinelles Lernen (ML) unter Verwendung von Open-Source-Frameworks wie Apache Funken, Apache Hive und Presto. Kunden fragten uns nach Funktionen, die das Kapazitätsmanagement und die Skalierungserfahrung ihres EMR auf EC2-Clustern, einschließlich ihrer großen, lang laufenden Cluster, weiter verbessern würden. Wir haben hart daran gearbeitet, diese Bedürfnisse zu erfüllen. Im Folgenden sind einige der wichtigsten Verbesserungen aufgeführt:
- Verbesserte Kundentransparenz und Flexibilität mit Bereitstellungs-Timeout für Spot-Instances
- Optimierte Aufgabenknoten-Skalierung für Amazon EMR auf EC2-Clustern, die mit Instanzgruppen gestartet wurden
- Verbesserte Job-Ausfallsicherheit mit verbessertem Schutz für Spark-Treiber
Lassen Sie uns tiefer eintauchen und die neuen Funktionen von Amazon EMR zu EC2 im Detail besprechen.
Verbesserte Kundentransparenz und Flexibilität mit Bereitstellungs-Timeout für Spot-Instances
Viele Kunden von Amazon EMR nutzen EC2-Spot-Instanzen für ihre EMR auf EC2-Clustern, um die Kosten zu senken. Spot-Instanzen sind Ersatzinstanzen Amazon Elastic Compute-Cloud (Amazon EC2) Rechenkapazität mit Rabatten von bis zu 90 % im Vergleich zum On-Demand-Preis. Amazon EMR bietet Ihnen die Möglichkeit, Ihren Cluster entweder manuell oder mithilfe von zu skalieren Automatische Skalierung. Sie können auch die Amazon EMR-verwaltete Skalierung Funktion zur automatischen Größenanpassung Ihres Clusters basierend auf Arbeitslast und Auslastung.
Um das Kundenerlebnis bei der Skalierung mit Spot-Instances zu verbessern, können Sie für EMR auf EC2-Clustern, die mit Instance-Flotten gestartet werden, jetzt ein Bereitstellungszeitlimit für Spot-Instances festlegen. Ein Bereitstellungszeitlimit weist Amazon EMR an, die Bereitstellung von Spot-Instance-Kapazität zu stoppen, wenn der Cluster während Cluster-Skalierungsvorgängen einen bestimmten Zeitschwellenwert überschreitet. Sie können das Zeitlimit für die Spot-Instance-Bereitstellung konfigurieren, damit die Größe von Clustern manuell oder mithilfe von Amazon EMR Managed Scaling und Auto Scaling geändert wird.
Um eine bessere Transparenz zu gewährleisten, sendet Amazon EMR außerdem Ereignisse nach Ablauf des Timeout-Zeitraums automatisch an eine Amazon CloudWatch-Ereignisse Strom. Mit diesen CloudWatch-Ereignissen können Sie Regeln erstellen, die Ereignisse nach einem bestimmten Muster abgleichen, und die Ereignisse dann an Ziele weiterleiten, um Maßnahmen zu ergreifen. Weitere Informationen finden Sie unter Passen Sie einen Bereitstellungs-Timeout-Zeitraum für die Cluster-Größenänderung in Amazon EMR an.
Nachfolgend finden Sie eine Zusammenfassung der Erfahrungen für verschiedene Szenarien, wenn Sie während der Größenänderung für Ihren Amazon EMR auf EC2-Cluster ein Bereitstellungs-Timeout konfigurieren
| Szenario | Erfahrungen |
| Amazon EMR ist in der Lage, die gewünschte Spot-Kapazität vor Ablauf des Bereitstellungs-Timeouts bereitzustellen | Amazon EMR skaliert den Cluster automatisch auf die gewünschte Kapazität und es sind keine Maßnahmen seitens des Kunden erforderlich |
| Amazon EMR kann keine Spot-Kapazität oder nur einen Teil der Spot-Kapazität bereitstellen und das Bereitstellungszeitlimit ist abgelaufen | Wenn Amazon EMR die erforderliche Spot-Kapazität nicht bereitstellen kann und das Bereitstellungszeitlimit abgelaufen ist, bricht Amazon EMR die Größenänderungsanforderung ab und stoppt seine Versuche, zusätzliche Spot-Kapazität bereitzustellen. Amazon EMR veröffentlicht Ereignisse auch in einem Amazon CloudWatch Events-Stream. Kunden können diese Ereignisse nutzen, um Regeln zu erstellen und entsprechende Maßnahmen zu ergreifen |
| Wenn die Spot-Instances in Ihren Amazon EMR auf EC2-Clustern unterbrochen werden, da Amazon EC2 sie zurück benötigt | Amazon EMR löst automatisch eine neue Größenänderungsanforderung aus, um Ihre Cluster neu auszubalancieren, indem Instances durch einen der verfügbaren Typen in Ihrem Cluster ersetzt werden. Amazon EMR verwendet außerdem dasselbe Zeitlimit für die Größenänderung der Bereitstellung, das im Cluster konfiguriert wurde. Es sind keine Maßnahmen seitens des Kunden erforderlich. |
Sie sollten die Kritikalität der Kapazitätsverfügbarkeit berücksichtigen, wenn Sie den Zeitüberschreitungswert für die Bereitstellung angeben:
- Wenn die Verfügbarkeit Ihrer Workload-Kapazität von entscheidender Bedeutung ist - Um sicherzustellen, dass die gewünschte Kapazität verfügbar ist, empfehlen wir, das Zeitlimit für die Größenänderung basierend auf der Zeit zu konfigurieren, die zum Ausführen der Anwendung und der Anwendungs-SLAs benötigt wird. Wenn das Anwendungs-SLA beispielsweise 60 Minuten beträgt und es 30 Minuten dauert, bis die Anwendung abgeschlossen ist, sollten Sie das Zeitlimit für die Größenänderung der Bereitstellung auf 30 Minuten oder weniger festlegen. Amazon EMR versucht, bis zum Ablauf des Timeouts (30 Minuten oder weniger) Spot-Kapazität bereitzustellen und ein CloudWatch-Ereignis zu veröffentlichen, damit Sie entsprechende Maßnahmen ergreifen können.
- Wenn Ihre Arbeitsbelastung zeitlich flexibel ist und die Kapazitätsverfügbarkeit keine Rolle spielt - Wenn die Arbeitslast zeitlich flexibel ist und die Kapazitätsverfügbarkeit kein Faktor ist, können Sie einen höheren Timeout-Wert für das Resize-Provisioning-Timeout konfigurieren, um die höchste Wahrscheinlichkeit für den Erhalt der gewünschten Spot-Kapazität sicherzustellen.
Optimierte Aufgabenknoten-Skalierung für Amazon EMR auf EC2-Clustern, die mit Instanzgruppen gestartet wurden
Instanzgruppen bieten eine einfachere Einrichtung zum Starten von EMR auf EC2-Clustern. Jeder mithilfe von Instanzgruppen gestartete Cluster kann bis zu 50 Instanzgruppen umfassen: eine primäre Instanzgruppe, die eine EC2-Instanz enthält, eine Kerninstanzgruppe, die eine oder mehrere EC2-Instanzen enthält, und bis zu 48 optionale Aufgabeninstanzgruppen. Sie können jede Instanzgruppe skalieren, indem Sie EC2-Instanzen manuell hinzufügen und entfernen, oder Sie können eine automatische Skalierung einrichten. Sie können auch die Amazon EMR Managed Scaling-Funktion verwenden, um die Größe Ihres Clusters basierend auf Arbeitslast und Auslastung automatisch anzupassen.
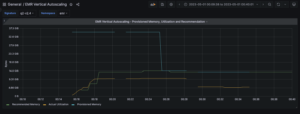
Um das Kundenerlebnis für Instanzgruppen auf EMR auf EC2-Clustern beim Hochskalieren von Aufgabenknoten mithilfe von Amazon EMR Managed Scaling zu verbessern, haben wir den verwalteten Skalierungsalgorithmus verbessert, um die Aufgabeninstanzgruppen auszuwählen, die die höchste Wahrscheinlichkeit haben, Kapazität zu erwerben. Wenn die verwaltete Skalierung außerdem nicht in der Lage ist, Kapazität mit einer einzelnen Aufgaben-Instanzgruppe zu erhalten, wechselt Amazon EMR automatisch zu einer anderen Aufgabengruppe und erfüllt die Kapazität durch die Verwendung mehrerer Aufgaben-Instanzgruppen, um Verzögerungen bei der Skalierung zu reduzieren. Je flexibler Sie also bei Ihren Instanztypen sind, desto höher sind die Chancen auf die Bereitstellung von Kapazität. Weitere Informationen finden Sie unter Best Practices zum Beispiel und Flexibilität der Availability Zone.
Verbesserte Job-Ausfallsicherheit mit verbessertem Schutz für Spark-Treiber
In 2022Um die Job-Ausfallsicherheit bei der Verwendung von Amazon EMR Managed Scaling zu verbessern, haben wir die verwaltete Skalierung dahingehend erweitert, dass sie Spark-Shuffle-Daten berücksichtigt. Dies verhindert eine Herunterskalierung von Instances, die Zwischen-Shuffle-Daten für Apache Spark speichern. Dies trägt dazu bei, erneute Jobversuche und Neuberechnungen zu vermeiden, was zu einer besseren Leistung und geringeren Kosten führt.
Um die Job-Ausfallsicherheit bei Verwendung von Amazon EMR Managed Scaling weiter zu verbessern, haben wir die verwaltete Skalierung weiter verbessert, um den Spark-Treiber zu berücksichtigen. Dadurch wird sichergestellt, dass Amazon EMR Managed Scaling beim Herunterskalieren des Clusters das Herunterskalieren von Knoten priorisiert, die nicht über einen verfügen Auf ihnen läuft ein aktiver Spark-Treiber. Dies trägt dazu bei, Auftragsfehler und Auftragswiederholungen zu minimieren, was dazu beiträgt, die Leistung weiter zu verbessern und die Kosten zu senken. Diese Erweiterung ist standardmäßig für EMR-Cluster aktiviert, die Amazon EMR-Versionen 5.34.0 und höher sowie Amazon EMR-Versionen 6.4.0 und höher verwenden.
Um zu bestätigen, auf welchen Knoten in Ihrem Cluster der Spark-Treiber ausgeführt wird, können Sie den Spark-Verlaufsserver besuchen und dort nach dem Treiber filtern Vollstrecker Registerkarte Ihrer Spark-Anwendungs-ID.
Zusammenfassung
In diesem Beitrag haben wir die Verbesserungen hervorgehoben, die wir im Kapazitätsmanagement und Amazon EMR Managed Scaling für EMR auf EC2-Clustern vorgenommen haben. Wir haben uns auf die Verbesserung der Job-Ausfallsicherheit, mehr Flexibilität und Transparenz bei der Bereitstellung von Spot-Instances sowie die Optimierung des Scale-Up-Erlebnisses bei der Verwendung verwalteter Skalierung mit Instance-Gruppen auf Amazon EMR auf EC2-Clustern konzentriert. Obwohl wir im Jahr 2023 bisher mehrere Funktionen eingeführt haben und das Innovationstempo weiter zunimmt, bleibt es Tag 1 und wir freuen uns darauf, von Ihnen zu hören, wie diese Funktionen Ihnen helfen, mehr Wert für Ihr Unternehmen zu erschließen. Wir laden Sie ein, diese neuen Funktionen auszuprobieren und uns über Ihr AWS-Kontoteam zu kontaktieren, wenn Sie weitere Kommentare haben.
Über die Autoren
 Sushant Majithia ist Hauptproduktmanager für EMR bei AWS.
Sushant Majithia ist Hauptproduktmanager für EMR bei AWS.
 Ankur Goyal ist ein SDM mit dem Amazon EMR Big Data Platform-Team. Er erstellt groß angelegte verteilte Anwendungen und Cluster-Optimierungsalgorithmen. Ankur interessiert sich für Themen wie Analytik, maschinelles Lernen und Prognosen.
Ankur Goyal ist ein SDM mit dem Amazon EMR Big Data Platform-Team. Er erstellt groß angelegte verteilte Anwendungen und Cluster-Optimierungsalgorithmen. Ankur interessiert sich für Themen wie Analytik, maschinelles Lernen und Prognosen.
 Matthäus Liem ist Senior Solution Architecture Manager bei AWS.
Matthäus Liem ist Senior Solution Architecture Manager bei AWS.
 Tarun Chanana ist ein SDM mit dem Amazon EMR Big Data Platform-Team.
Tarun Chanana ist ein SDM mit dem Amazon EMR Big Data Platform-Team.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- ChartPrime. Verbessern Sie Ihr Handelsspiel mit ChartPrime. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/capacity-management-and-amazon-emr-managed-scaling-improvements-for-amazon-emr-on-ec2-clusters/
- :hast
- :Ist
- :nicht
- $UP
- 1
- 100
- 11
- 2023
- 30
- 50
- 60
- 7
- 9
- a
- Fähig
- Über Uns
- beschleunigen
- Nach
- Konto
- erwerben
- Erwerb
- Action
- Aktionen
- aktiv
- Hinzufügen
- Zusätzliche
- Algorithmus
- Algorithmen
- ebenfalls
- Obwohl
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- Analytik
- und
- Ein anderer
- jedem
- Apache
- Apache Funken
- Anwendung
- Anwendungen
- angemessen
- Architektur
- SIND
- AS
- At
- Versuche
- Auto
- automatische
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Verfügbarkeit
- verfügbar
- bewusst
- AWS
- basierend
- BE
- war
- Bevor
- unten
- Besser
- Big
- Big Data
- baut
- by
- CAN
- capability
- Kapazität
- Chancen
- Auswählen
- Cloud
- Cloud-Big-Data
- Cluster
- Bemerkungen
- verglichen
- abschließen
- Berechnen
- konfiguriert
- Schichtannahme
- Folglich
- Geht davon
- enthält
- weiter
- Kernbereich
- Kosten
- Kosten
- erstellen
- kritisch
- Kunde
- Customer Experience
- Kunden
- technische Daten
- Datenplattform
- Datenverarbeitung
- Tag
- tiefer
- Standard
- Verzögerungen
- erwünscht
- Detail
- anders
- exklusive Rabatte
- diskutieren
- verteilt
- tauchen
- Nicht
- Fahrer
- im
- jeder
- entweder
- freigegeben
- zu steigern,
- verbesserte
- Erweiterung
- Verbesserungen
- gewährleisten
- sorgt
- Äther (ETH)
- Event
- Veranstaltungen
- Beispiel
- übersteigt
- ERFAHRUNGEN
- Ablauf
- Faktor
- weit
- Merkmal
- Eigenschaften
- Filter
- Finden Sie
- Flexibilität
- flexibel
- konzentriert
- Folgende
- Aussichten für
- vorwärts
- Gerüste
- für
- Erfüllen
- weiter
- Außerdem
- bekommen
- bekommen
- Gruppe an
- Gruppen
- glücklich
- hart
- Haben
- he
- Hörtests
- Hilfe
- dazu beigetragen,
- Unternehmen
- hilft
- höher
- höchste
- Besondere
- Geschichte
- Ultraschall
- HTML
- http
- HTTPS
- ID
- if
- zu unterstützen,
- Verbesserungen
- Verbesserung
- in
- das
- Einschließlich
- Innovation
- Instanz
- interaktive
- interessiert
- Mittel
- unterbrochen
- einladen
- IT
- Job
- Wesentliche
- grosse
- später
- starten
- ins Leben gerufen
- umwandeln
- LERNEN
- lernen
- weniger
- Wahrscheinlichkeit
- aussehen
- senken
- Maschine
- Maschinelles Lernen
- gemacht
- verwaltet
- Management
- Manager
- manuell
- Spiel
- Triff
- Minuten
- ML
- mehr
- mehrere
- erforderlich
- Bedürfnisse
- Neu
- Neue Funktionen
- nicht
- Fiber Node
- jetzt an
- of
- bieten
- angeboten
- Angebote
- on
- On-Demand
- EINEM
- einzige
- Open-Source-
- Einkauf & Prozesse
- Optimierung
- Optimierung
- or
- Organisationen
- Frieden
- Schnittmuster
- Leistung
- Zeit
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Post
- Praktiken
- verhindert
- gebühr
- primär
- Principal
- Verarbeitung
- Produkt
- Produkt-Manager
- Sicherheit
- die
- Bereitstellung
- veröffentlichen
- Neuverteilung
- empfehlen
- Veteran
- Reduziert
- siehe
- bleibt bestehen
- Entfernen
- berichten
- Anforderung
- falls angefordert
- Voraussetzungen:
- Straße
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Führen Sie
- Laufen
- gleich
- Skalieren
- vergrößern
- Skalierung
- SDM
- senden
- Senior
- Lösungen
- kompensieren
- Setup
- sollte
- Shuffle
- Single
- So
- bis jetzt
- Lösung
- einige
- Spark
- angegeben
- Spot
- Stoppen
- Stoppt
- speichern
- Strom
- so
- Schalter
- Nehmen
- nimmt
- Ziele
- Aufgabe
- Team
- erzählen
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Diese
- fehlen uns die Worte.
- diejenigen
- Schwelle
- Durch
- Zeit
- zu
- Themen
- aufnehmen
- Transparenz
- auslösen
- versuchen
- Typen
- öffnen
- bis
- us
- -
- Verwendung von
- Wert
- Besuchen Sie
- wurde
- we
- Netz
- Web-Services
- GUT
- wann
- welche
- werden wir
- mit
- Arbeiten
- gearbeitet
- würde
- U
- Ihr
- Zephyrnet