
Bild vom Autor | Bing Image Creator
Puppe 2.0 ist ein Open-Source-LLM (Large Language Model), das auf Anweisungen basiert und anhand eines von Menschen erstellten Datensatzes verfeinert wurde. Es kann sowohl für Forschungs- als auch für kommerzielle Zwecke verwendet werden.
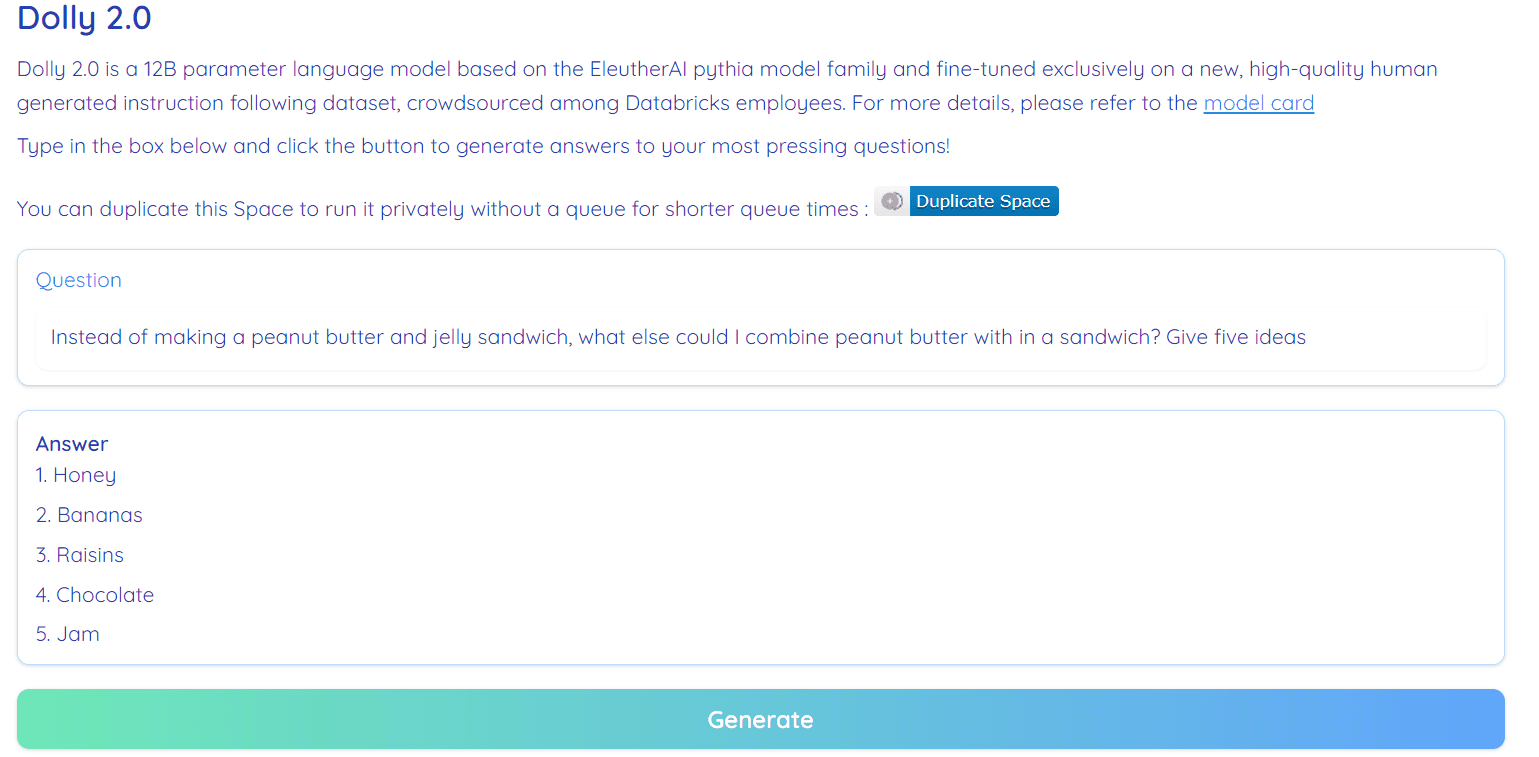
Bild aus Umarmender Gesichtsraum von RamAnanth1
Zuvor hat das Databricks-Team veröffentlicht Puppe 1.0, LLM, das eine ChatGPT-ähnliche Fähigkeit zur Befehlsverfolgung aufweist und weniger als 30 US-Dollar für das Training kostet. Es wurde der Datensatz des Stanford Alpaca-Teams verwendet, der unter einer eingeschränkten Lizenz (nur Forschung) stand.
Dolly 2.0 hat dieses Problem durch eine Feinabstimmung des 12B-Parameter-Sprachmodells gelöst (Pythia) auf eine hochwertige, von Menschen erstellte Anweisung im folgenden Datensatz, der von einem Datbricks-Mitarbeiter gekennzeichnet wurde. Sowohl das Modell als auch der Datensatz stehen für die kommerzielle Nutzung zur Verfügung.
Dolly 1.0 wurde anhand eines Stanford Alpaca-Datensatzes trainiert, der mithilfe der OpenAI-API erstellt wurde. Der Datensatz enthält die Ausgabe von ChatGPT und verhindert, dass jemand ihn als Konkurrenz zu OpenAI verwendet. Kurz gesagt, Sie können auf der Grundlage dieses Datensatzes keinen kommerziellen Chatbot oder keine Sprachanwendung erstellen.
Die meisten der neuesten Modelle, die in den letzten Wochen auf den Markt kamen, litten unter den gleichen Problemen, z Alpaka, Koala, GPT4All und Vicuna. Um dies zu umgehen, müssen wir neue qualitativ hochwertige Datensätze erstellen, die für kommerzielle Zwecke verwendet werden können, und genau das hat das Databricks-Team mit dem Datensatz „databricks-dolly-15k“ getan.
Der neue Datensatz enthält 15,000 hochwertige, von Menschen gekennzeichnete Eingabeaufforderungs-/Antwortpaare, die zum Entwerfen von Anweisungen zur Optimierung großer Sprachmodelle verwendet werden können. Der databricks-dolly-15k Der Datensatz wird mitgeliefert Creative Commons Attribution-ShareAlike 3.0 Unported License, was es jedem ermöglicht, es zu verwenden, zu ändern und eine kommerzielle Anwendung darauf zu erstellen.
Wie wurde der Datensatz databricks-dolly-15k erstellt?
Die OpenAI-Forschung Krepppapier gibt an, dass das ursprüngliche InstructGPT-Modell anhand von 13,000 Eingabeaufforderungen und Antworten trainiert wurde. Mithilfe dieser Informationen begann das Databricks-Team mit der Arbeit daran, und es stellte sich heraus, dass das Generieren von 13 Fragen und Antworten eine schwierige Aufgabe war. Sie können keine synthetischen Daten oder generative KI-Daten verwenden und müssen auf jede Frage originelle Antworten generieren. Hier haben sie beschlossen, 5,000 Mitarbeiter von Databricks einzusetzen, um von Menschen generierte Daten zu erstellen.
Die Databricks haben einen Wettbewerb ins Leben gerufen, bei dem die 20 besten Labeler eine große Auszeichnung erhalten würden. An diesem Wettbewerb nahmen 5,000 Databricks-Mitarbeiter teil, die sich sehr für LLMs interessierten
Der Dolly-v2-12b ist kein hochmodernes Modell. In einigen Bewertungsbenchmarks schneidet es schlechter ab als Dolly-v1-6b. Dies könnte an der Zusammensetzung und Größe der zugrunde liegenden Feinabstimmungsdatensätze liegen. Die Dolly-Modellfamilie befindet sich in der aktiven Entwicklung, sodass Sie in Zukunft möglicherweise eine aktualisierte Version mit besserer Leistung sehen werden.
Kurz gesagt, das Modell dolly-v2-12b hat eine bessere Leistung erbracht als EleutherAI/gpt-neox-20b und EleutherAI/pythia-6.9b.

Bild aus Kostenloser Dolly
Dolly 2.0 ist 100 % Open Source. Es enthält Trainingscode, Datensatz, Modellgewichte und Inferenzpipeline. Alle Komponenten sind für den gewerblichen Einsatz geeignet. Sie können das Modell auf Hugging Face Spaces ausprobieren Dolly V2 von RamAnanth1.
Bild aus Gesicht umarmen
Ressource:
Dolly 2.0-Demo: Dolly V2 von RamAnanth1
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, Modelle für maschinelles Lernen zu erstellen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und schreibt technische Blogs zu maschinellem Lernen und Data-Science-Technologien. Abid hat einen Master-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Vision ist es, ein KI-Produkt mit einem grafisch-neuronalen Netzwerk für Schüler zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :hast
- :Ist
- :nicht
- $UP
- 000
- 1
- 20
- a
- Fähigkeit
- aktiv
- AI
- Alle
- erlaubt
- Alternative
- an
- und
- Antworten
- jemand
- Bienen
- Anwendung
- SIND
- um
- Autor
- verfügbar
- Auszeichnung
- basierend
- BE
- Benchmarks
- Berkeley
- Besser
- Big
- Bing
- Blogs
- beide
- bauen
- Building
- by
- CAN
- kann keine
- Zertifzierte
- Chatbot
- ChatGPT
- Code
- kommerziell
- Unterhaus
- konkurrieren
- Komponenten
- enthält
- Inhalt
- Inhaltserstellung
- Wettbewerb
- Kosten
- erstellen
- erstellt
- Schaffung
- Zur Zeit
- technische Daten
- Datenwissenschaft
- Datenwissenschaftler
- Databricks
- Datensätze
- entschieden
- Grad
- Demo
- Design
- Entwicklung
- DID
- schwer
- Puppe
- Mitarbeiter
- Mitarbeiter
- Entwicklung
- Auswertung
- Jedes
- Exponate
- Gesicht
- Familie
- wenige
- Fokussierung
- Folgende
- Aussichten für
- für
- Zukunft
- erzeugen
- Erzeugung
- generativ
- bekommen
- Graph
- Graph Neuronales Netzwerk
- Haben
- he
- hochwertige
- hält
- HTML
- HTTPS
- Krankheit
- Image
- in
- Information
- interessiert
- Problem
- Probleme
- IT
- jpg
- KDnuggets
- Sprache
- grosse
- Nachname
- neueste
- lernen
- Lizenz
- Gefällt mir
- Maschine
- Maschinelles Lernen
- Management
- Master
- geistig
- Geisteskrankheit
- könnte
- Modell
- für
- ändern
- Need
- Netzwerk
- Neural
- neuronale Netzwerk
- Neu
- of
- on
- einzige
- XNUMXh geöffnet
- Open-Source-
- OpenAI
- or
- Original
- Möglichkeiten für das Ausgangssignal:
- Paare
- Parameter
- teil
- Leistung
- Pipeline
- Plato
- Datenintelligenz von Plato
- PlatoData
- Produkt
- Professionell
- Zwecke
- Frage
- Fragen
- freigegeben
- Forschungsprojekte
- entschlossen
- eingeschränkt
- s
- gleich
- Wissenschaft
- Wissenschaftler
- kompensieren
- Short
- Größe
- So
- einige
- Quelle
- Raumfahrt
- Räume
- Stanford
- begonnen
- State-of-the-art
- Staaten
- Struggling
- Die Kursteilnehmer
- geeignet
- synthetisch
- synthetische Daten
- Aufgabe
- Team
- Technische
- Technologies
- Technologie
- Telekommunikations
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Zukunft
- vom Nutzer definierten
- fehlen uns die Worte.
- zu
- Top
- Training
- trainiert
- Ausbildung
- für
- zugrunde liegen,
- aktualisiert
- -
- benutzt
- Verwendung von
- Version
- Seh-
- wurde
- we
- Wochen
- waren
- Was
- welche
- WHO
- mit
- Arbeiten
- würde
- Schreiben
- U
- Zephyrnet










