Amazon RedShift ist ein vollständig verwaltetes Cloud-Data-Warehouse im Petabyte-Bereich, das von Zehntausenden Kunden genutzt wird, um täglich Exabytes an Daten zu verarbeiten, um ihre Analysearbeitslast zu steigern. Mithilfe eines dimensionalen Modells können Sie Ihre Daten strukturieren, Geschäftsprozesse messen und schnell wertvolle Erkenntnisse gewinnen. Amazon Redshift bietet integrierte Funktionen, um den Prozess der Modellierung, Orchestrierung und Berichterstellung anhand eines dimensionalen Modells zu beschleunigen.
In diesem Beitrag diskutieren wir, wie man ein Dimensionsmodell implementiert, insbesondere das Kimball-Methodik. Wir besprechen die Implementierungsdimensionen und Fakten innerhalb von Amazon Redshift. Wir zeigen, wie man Extrahieren, Transformieren und Laden (ELT) durchführt, einen Integrationsprozess, der sich darauf konzentriert, die Rohdaten aus einem Data Lake in eine Staging-Schicht zu übertragen, um die Modellierung durchzuführen. Insgesamt vermittelt Ihnen der Beitrag ein klares Verständnis für die Verwendung der dimensionalen Modellierung in Amazon Redshift.
Lösungsüberblick
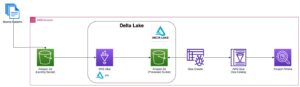
Das folgende Diagramm zeigt die Lösungsarchitektur.

In den folgenden Abschnitten diskutieren und demonstrieren wir zunächst die Schlüsselaspekte des Dimensionsmodells. Anschließend erstellen wir mithilfe von Amazon Redshift einen Data Mart mit einem dimensionalen Datenmodell einschließlich Dimensions- und Faktentabellen. Daten werden mithilfe von geladen und bereitgestellt COPY Mit dem Befehl werden die Daten in den Dimensionen geladen MERGE Aussage und Fakten werden mit den Dimensionen verknüpft, aus denen Erkenntnisse abgeleitet werden. Wir planen das Laden der Dimensionen und Fakten mithilfe des Amazon Redshift-Abfrage-Editor V2. Zuletzt verwenden wir Amazon QuickSight um Einblicke in die modellierten Daten in Form eines QuickSight-Dashboards zu gewinnen.
Für diese Lösung verwenden wir einen Beispieldatensatz (normalisiert), der von Amazon Redshift für den Verkauf von Veranstaltungstickets bereitgestellt wird. Für diesen Beitrag haben wir den Datensatz zur Vereinfachung und zu Demonstrationszwecken eingegrenzt. Die folgenden Tabellen zeigen beispielhaft die Daten zu Ticketverkäufen und Veranstaltungsorten.


Nach Angaben des Kimball-Methode zur dimensionalen ModellierungBeim Entwerfen eines dimensionalen Modells gibt es vier wichtige Schritte:
- Identifizieren Sie den Geschäftsprozess.
- Geben Sie die Körnung Ihrer Daten an.
- Identifizieren und implementieren Sie die Dimensionen.
- Fakten erkennen und umsetzen.
Darüber hinaus fügen wir zu Demonstrationszwecken einen fünften Schritt hinzu, der darin besteht, Geschäftsereignisse zu melden und zu analysieren.
Voraussetzungen:
Für diese exemplarische Vorgehensweise sollten Sie die folgenden Voraussetzungen erfüllen:
Identifizieren Sie den Geschäftsprozess
Vereinfacht ausgedrückt bedeutet die Identifizierung des Geschäftsprozesses die Identifizierung eines messbaren Ereignisses, das Daten innerhalb einer Organisation generiert. Normalerweise verfügen Unternehmen über eine Art operatives Quellsystem, das ihre Daten im Rohformat generiert. Dies ist ein guter Ausgangspunkt, um verschiedene Quellen für einen Geschäftsprozess zu identifizieren.
Der Geschäftsprozess wird dann als persistiert Datamart in Form von Dimensionen und Fakten. Wenn wir unseren zuvor erwähnten Beispieldatensatz betrachten, können wir deutlich erkennen, dass der Geschäftsprozess die Verkäufe für eine bestimmte Veranstaltung sind.
Ein häufiger Fehler besteht darin, Abteilungen eines Unternehmens als Geschäftsprozess zu verwenden. Die Daten (Geschäftsprozess) müssen abteilungsübergreifend integriert werden, in diesem Fall kann das Marketing auf die Vertriebsdaten zugreifen. Die Identifizierung des richtigen Geschäftsprozesses ist von entscheidender Bedeutung – ein falscher Schritt kann Auswirkungen auf den gesamten Data Mart haben (es kann zu Duplikaten der Körnung und zu falschen Metriken in den Abschlussberichten kommen).
Geben Sie die Körnung Ihrer Daten an
Bei der Deklaration der Körnung handelt es sich um die eindeutige Identifizierung eines Datensatzes in Ihrer Datenquelle. Die Körnung wird in der Faktentabelle verwendet, um die Daten genau zu messen und Ihnen eine weitere Zusammenfassung zu ermöglichen. In unserem Beispiel könnte dies eine Einzelposition im Verkaufsprozess sein.
In unserem Anwendungsfall kann ein Verkauf anhand des Transaktionszeitpunkts, zu dem der Verkauf stattfand, eindeutig identifiziert werden. Dies wird die atomarste Ebene sein.

Identifizieren und implementieren Sie die Dimensionen
Ihre Dimensionstabelle beschreibt Ihre Faktentabelle und ihre Attribute. Wenn Sie den beschreibenden Kontext Ihres Geschäftsprozesses identifizieren, speichern Sie den Text in einer separaten Tabelle und berücksichtigen dabei die Struktur der Faktentabelle. Beim Verknüpfen der Dimensionstabelle mit der Faktentabelle sollte der Faktentabelle nur eine einzige Zeile zugeordnet sein. In unserem Beispiel verwenden wir die folgende Tabelle, um sie in eine Dimensionstabelle zu unterteilen. Diese Felder beschreiben die Fakten, die wir messen werden.
Beim Entwerfen der Struktur des Dimensionsmodells (des Schemas) können Sie entweder ein erstellen Star or Schneeflocke Schema. Die Struktur sollte eng am Geschäftsprozess ausgerichtet sein; Daher eignet sich für unser Beispiel am besten ein Sternschema. Die folgende Abbildung zeigt unser Entity-Relationship-Diagramm (ERD).

In den folgenden Abschnitten beschreiben wir die Schritte zur Implementierung der Dimensionen.
Stellen Sie die Quelldaten bereit
Bevor wir die Dimensionstabelle erstellen und laden können, benötigen wir Quelldaten. Daher stellen wir die Quelldaten in einer Staging- oder temporären Tabelle bereit. Dies wird oft als bezeichnet Staging-Schicht, die Rohkopie der Quelldaten. Dazu verwenden wir in Amazon Redshift die COPY-Befehl um die Daten aus dem öffentlichen S3-Bucket „dimensional-modeling-in-amazon-redshift“ zu laden, der sich auf dem befindet us-east-1 Region. Beachten Sie, dass der COPY-Befehl ein verwendet AWS Identity and Access Management and (IAM) Rolle mit Zugriff auf Amazon S3. Die Rolle muss sein mit dem Cluster verbunden. Führen Sie die folgenden Schritte aus, um die Quelldaten bereitzustellen:
- erstellen Sie
venueQuelltabelle:
- Laden Sie die Veranstaltungsortdaten:
- erstellen Sie
salesQuelltabelle:
- Laden Sie die Daten der Verkaufsquelle:
- erstellen Sie
calendarTabelle:
- Laden Sie die Kalenderdaten:
Erstellen Sie die Dimensionstabelle
Die Gestaltung der Dimensionstabelle kann von Ihren Geschäftsanforderungen abhängen – müssen Sie beispielsweise Änderungen an den Daten im Laufe der Zeit verfolgen? Es gibt sieben verschiedene Dimensionstypen. Für unser Beispiel verwenden wir Typ 1 weil wir historische Veränderungen nicht verfolgen müssen. Weitere Informationen zu Typ 2 finden Sie unter Vereinfachen Sie das Laden von Daten in sich langsam ändernde Typ-2-Dimensionen in Amazon Redshift. Die Dimensionstabelle wird mit einem Primärschlüssel, einem Ersatzschlüssel und einigen zusätzlichen Feldern denormalisiert, um Änderungen an der Tabelle anzuzeigen. Siehe den folgenden Code:
Ein paar Hinweise zur Erstellung der Dimensionstabellenerstellung:
- Die Feldnamen werden in wirtschaftsfreundliche Namen umgewandelt
- Unser Primärschlüssel ist
VenueID, die wir verwenden, um einen Ort, an dem der Verkauf stattgefunden hat, eindeutig zu identifizieren - Es werden zwei zusätzliche Zeilen hinzugefügt, die angeben, wann ein Datensatz eingefügt und aktualisiert wurde (um Änderungen zu verfolgen).
- Wir verwenden ein AUTO-Verteilungsstil Amazon Redshift die Verantwortung zu übertragen, den Vertriebsstil auszuwählen und anzupassen
Ein weiterer wichtiger Faktor, der bei der Dimensionsmodellierung berücksichtigt werden muss, ist die Verwendung von Ersatzschlüssel. Ersatzschlüssel sind künstliche Schlüssel, die bei der dimensionalen Modellierung verwendet werden, um jeden Datensatz in einer Dimensionstabelle eindeutig zu identifizieren. Sie werden normalerweise als sequentielle Ganzzahl generiert und haben im Geschäftsbereich keine Bedeutung. Sie bieten mehrere Vorteile, wie z. B. die Gewährleistung der Eindeutigkeit und die Verbesserung der Leistung bei Verknüpfungen, da sie normalerweise kleiner als natürliche Schlüssel sind und sich als Ersatzschlüssel im Laufe der Zeit nicht ändern. Dadurch können wir konsistent sein und Fakten und Dimensionen einfacher zusammenführen.
In Amazon Redshift werden Ersatzschlüssel normalerweise mit dem Schlüsselwort IDENTITY erstellt. Die vorhergehende CREATE-Anweisung erstellt beispielsweise eine Dimensionstabelle mit a VenueSkey Ersatzschlüssel. Der VenueSkey Die Spalte wird automatisch mit eindeutigen Werten gefüllt, wenn der Tabelle neue Zeilen hinzugefügt werden. Diese Spalte kann dann verwendet werden, um die Veranstaltungsorttabelle mit der zu verbinden FactSaleTransactions Tabelle.
Ein paar Tipps zum Entwerfen von Ersatzschlüsseln:
- Verwenden Sie einen kleinen Datentyp mit fester Breite für den Ersatzschlüssel. Dadurch wird die Leistung verbessert und der Speicherplatz reduziert.
- Verwenden Sie das Schlüsselwort IDENTITY oder generieren Sie den Ersatzschlüssel mithilfe eines sequentiellen oder GUID-Werts. Dadurch wird sichergestellt, dass der Ersatzschlüssel eindeutig ist und nicht geändert werden kann.
Laden Sie die Dim-Tabelle mit MERGE
Es gibt zahlreiche Möglichkeiten, Ihre Dim-Tabelle zu laden. Bestimmte Faktoren müssen berücksichtigt werden – zum Beispiel Leistung, Datenvolumen und möglicherweise SLA-Ladezeiten. Mit dem MERGE Mit der Anweisung führen wir einen Upsert durch, ohne dass mehrere Einfüge- und Aktualisierungsbefehle angegeben werden müssen. Sie können das einrichten MERGE Aussage in a gespeicherte Prozedur um die Daten zu füllen. Anschließend planen Sie die programmgesteuerte Ausführung der gespeicherten Prozedur über den Abfrageeditor, was wir später in diesem Beitrag demonstrieren. Der folgende Code erstellt eine gespeicherte Prozedur namens SalesMart.DimVenueLoad:
Ein paar Hinweise zum Dimensionsladen:
- Wenn ein Datensatz zum ersten Mal eingefügt wird, werden das eingefügte Datum und das Aktualisierungsdatum eingetragen. Wenn sich Werte ändern, werden die Daten aktualisiert und das Aktualisierungsdatum spiegelt das Datum der Änderung wider. Das eingefügte Datum bleibt erhalten.
- Da die Daten von Geschäftsanwendern verwendet werden, müssen wir ggf. NULL-Werte durch geschäftsgerechtere Werte ersetzen.
Fakten erkennen und umsetzen
Nachdem wir nun unser Getreide als Verkaufsereignis zu einem bestimmten Zeitpunkt deklariert haben, speichert unsere Faktentabelle die numerischen Fakten für unseren Geschäftsprozess.
Wir haben die folgenden numerischen Fakten zur Messung identifiziert:
- Anzahl der pro Verkauf verkauften Tickets
- Provision für den Verkauf
Die Tatsache umsetzen
Es gibt drei Arten von Faktentabellen (Transaktionsfaktentabelle, periodische Snapshot-Faktentabelle und akkumulierende Snapshot-Faktentabelle). Jeder bietet eine andere Sicht auf den Geschäftsprozess. Für unser Beispiel verwenden wir eine Transaktionsfaktentabelle. Führen Sie die folgenden Schritte aus:
- Erstellen Sie die Faktentabelle
Es wird ein eingefügtes Datum mit einem Standardwert hinzugefügt, das angibt, ob und wann ein Datensatz geladen wurde. Dies können Sie beim Neuladen der Faktentabelle nutzen, um die bereits geladenen Daten zu entfernen und Duplikate zu vermeiden.
Das Laden der Faktentabelle besteht aus einer einfachen Einfügeanweisung, die Ihre zugehörigen Dimensionen verbindet. Wir schließen uns dem an DimVenue erstellte Tabelle, die unseren Sachverhalt beschreibt. Dies ist eine bewährte Methode, die jedoch optional ist Kalenderdatum Dimensionen, die es dem Endbenutzer ermöglichen, in der Faktentabelle zu navigieren. Die Daten können entweder bei einem neuen Verkauf oder täglich geladen werden; Hier bietet sich das eingefügte Datum bzw. Ladedatum an.
Wir laden die Faktentabelle mithilfe einer gespeicherten Prozedur und verwenden einen Datumsparameter.
- Erstellen Sie die gespeicherte Prozedur mit dem folgenden Code. Um die gleiche Datenintegrität beizubehalten, die wir beim Dimensionsladen angewendet haben, ersetzen wir NULL-Werte, falls vorhanden, durch geschäftsgerechtere Werte:
- Laden Sie die Daten, indem Sie die Prozedur mit dem folgenden Befehl aufrufen:
Planen Sie das Laden der Daten
Wir können jetzt den Modellierungsprozess automatisieren, indem wir die gespeicherten Prozeduren im Amazon Redshift Query Editor V2 planen. Führen Sie die folgenden Schritte aus:
- Wir rufen zuerst den Dimensionsladevorgang auf und nachdem der Dimensionsladevorgang erfolgreich ausgeführt wurde, beginnt der Faktenladevorgang:
Wenn das Laden der Dimension fehlschlägt, wird das Laden der Fakten nicht ausgeführt. Dies stellt die Konsistenz der Daten sicher, da wir die Faktentabelle nicht mit veralteten Dimensionen laden möchten.
- Um die Belastung einzuplanen, wählen Sie Ablauf im Abfrageeditor V2.

- Wir planen, dass die Abfrage jeden Tag um 5:00 Uhr ausgeführt wird.
- Optional können Sie durch Aktivieren Fehlerbenachrichtigungen hinzufügen Amazon Simple Notification Service (Amazon SNS)-Benachrichtigungen.

Berichten und analysieren Sie die Daten in Amazon Quicksight
QuickSight ist ein Business-Intelligence-Dienst, der es einfach macht, Erkenntnisse zu liefern. Als vollständig verwalteter Dienst können Sie mit QuickSight ganz einfach interaktive Dashboards erstellen und veröffentlichen, auf die Sie dann von jedem Gerät aus zugreifen und die Sie in Ihre Anwendungen, Portale und Websites integrieren können.
Wir nutzen unseren Data Mart, um die Fakten visuell in Form eines Dashboards darzustellen. Informationen zu den ersten Schritten und zur Einrichtung von QuickSight finden Sie unter Erstellen eines Datensatzes mithilfe einer Datenbank, die nicht automatisch erkannt wird.
Nachdem Sie Ihre Datenquelle in QuickSight erstellt haben, fügen wir die modellierten Daten (Data Mart) basierend auf unserem Ersatzschlüssel zusammen skey. Wir verwenden diesen Datensatz, um den Data Mart zu visualisieren.

Unser End-Dashboard enthält die Erkenntnisse des Data Mart und beantwortet kritische Geschäftsfragen, wie z. B. die Gesamtprovision pro Veranstaltungsort und die Termine mit den höchsten Umsätzen. Der folgende Screenshot zeigt das Endprodukt des Data Mart.

Aufräumen
Um künftige Kosten zu vermeiden, löschen Sie alle Ressourcen, die Sie im Rahmen dieses Beitrags erstellt haben.
Zusammenfassung
Mit unserem haben wir nun erfolgreich einen Data Mart implementiert DimVenue, DimCalendar und FactSaleTransactions Tische. Unser Lager ist nicht vollständig; Wenn wir den Data Mart mit mehr Fakten erweitern und mehr Marts implementieren können und wenn der Geschäftsprozess und die Anforderungen im Laufe der Zeit wachsen, wächst auch das Data Warehouse. In diesem Beitrag haben wir einen umfassenden Überblick über das Verständnis und die Implementierung der dimensionalen Modellierung in Amazon Redshift gegeben.
Beginnen Sie mit Ihrem Amazon RedShift Dimensionsmodell heute.
Über die Autoren
 Bernard Verster ist ein erfahrener Cloud-Ingenieur mit langjähriger Erfahrung in der Erstellung skalierbarer und effizienter Datenmodelle, der Definition von Datenintegrationsstrategien und der Gewährleistung von Datenverwaltung und -sicherheit. Seine Leidenschaft liegt darin, Daten zu nutzen, um Erkenntnisse zu gewinnen und sie gleichzeitig an den Geschäftsanforderungen und -zielen auszurichten.
Bernard Verster ist ein erfahrener Cloud-Ingenieur mit langjähriger Erfahrung in der Erstellung skalierbarer und effizienter Datenmodelle, der Definition von Datenintegrationsstrategien und der Gewährleistung von Datenverwaltung und -sicherheit. Seine Leidenschaft liegt darin, Daten zu nutzen, um Erkenntnisse zu gewinnen und sie gleichzeitig an den Geschäftsanforderungen und -zielen auszurichten.
 Abhishek Pfanne ist ein WWSO-Spezialist für SA-Analytics, der mit Kunden des öffentlichen Sektors von AWS India arbeitet. Er arbeitet mit Kunden zusammen, um datengesteuerte Strategien zu definieren, Deep-Dive-Sitzungen zu Analyse-Anwendungsfällen anzubieten und skalierbare und leistungsstarke Analyseanwendungen zu entwerfen. Er verfügt über 12 Jahre Erfahrung und begeistert sich für Datenbanken, Analysen und KI/ML. Er ist ein begeisterter Reisender und versucht, die Welt durch die Linse seiner Kamera einzufangen.
Abhishek Pfanne ist ein WWSO-Spezialist für SA-Analytics, der mit Kunden des öffentlichen Sektors von AWS India arbeitet. Er arbeitet mit Kunden zusammen, um datengesteuerte Strategien zu definieren, Deep-Dive-Sitzungen zu Analyse-Anwendungsfällen anzubieten und skalierbare und leistungsstarke Analyseanwendungen zu entwerfen. Er verfügt über 12 Jahre Erfahrung und begeistert sich für Datenbanken, Analysen und KI/ML. Er ist ein begeisterter Reisender und versucht, die Welt durch die Linse seiner Kamera einzufangen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- LiveBuzz
- beschleunigen
- Zugang
- Zugriff
- genau
- über
- Handlung
- hinzufügen
- hinzugefügt
- Zusätzliche
- Nach der
- AI / ML
- ausrichten
- ausrichten
- erlauben
- erlaubt
- bereits
- am
- Amazon
- Amazon Web Services
- an
- Analyse
- Analytische
- Analytik
- analysieren
- und
- beantworten
- jedem
- Anwendungen
- angewandt
- angemessen
- Architektur
- SIND
- künstlich
- AS
- Aspekte
- damit verbundenen
- At
- Attribute
- Auto
- automatisieren
- Im Prinzip so, wie Sie es von Google Maps kennen.
- vermeiden
- AWS
- b
- basierend
- BE
- weil
- beginnen
- Vorteile
- BESTE
- eingebaut
- Geschäft
- Business Intelligence
- Business Process
- Geschäftsprozesse
- aber
- by
- Kalender
- rufen Sie uns an!
- namens
- Aufruf
- Kamera
- CAN
- Erfassung
- Häuser
- Fälle
- Verursachen
- sicher
- Übernehmen
- geändert
- Änderungen
- Ändern
- Charakter
- Gebühren
- Auswählen
- klar
- eng
- Cloud
- Code
- Kolonne
- kommt
- Provision
- gemeinsam
- Unternehmen
- Unternehmen
- abschließen
- Geht davon
- konsistent
- besteht
- Kontext
- und beseitigen Muskelschwäche
- könnte
- erstellen
- erstellt
- schafft
- Erstellen
- Schaffung
- kritischem
- Kunden
- Unterricht
- Armaturenbrett
- Dashboards
- technische Daten
- Datenintegration
- Datensee
- Data Warehouse
- datengesteuerte
- Datengesteuerte Strategie
- Datenbase
- Datenbanken
- Datum
- Datum
- datetime
- Tag
- tief
- Tieftauchgang
- Standard
- Definition
- Übergeben
- zeigen
- Abteilungen
- Abgeleitet
- beschreiben
- Design
- Entwerfen
- Detail
- Gerät
- anders
- Abmessungen
- Größe
- diskutieren
- deutlich
- Verteilung
- do
- Domain
- erledigt
- Nicht
- nach unten
- Antrieb
- Duplikate
- jeder
- Früher
- leicht
- Einfache
- Herausgeber
- effizient
- entweder
- eingebettet
- ermöglichen
- ermöglichen
- Ende
- End-to-End
- greift ein
- Ingenieur
- gewährleisten
- sorgt
- Gewährleistung
- Ganz
- Einheit
- Äther (ETH)
- Event
- Veranstaltungen
- Jedes
- jeden Tag
- Beispiel
- Beispiele
- Erweitern Sie die Funktionalität der
- ERFAHRUNGEN
- erfahrensten
- Belichtung
- Extrakt
- Tatsache
- Faktor
- Faktoren
- Fakten
- scheitert
- Scheitern
- Eigenschaften
- wenige
- Feld
- Felder
- fünfte
- Abbildung
- Filter
- Finale
- Vorname
- erstes Mal
- passen
- konzentriert
- Folgende
- Aussichten für
- unten stehende Formular
- Format
- vier
- für
- voll
- weiter
- Zukunft
- Gewinnen
- erzeugen
- erzeugt
- erzeugt
- bekommen
- bekommen
- ABSICHT
- gegeben
- gut
- Governance
- Wachsen Sie über sich hinaus
- praktisch
- Haben
- he
- höchste
- seine
- historisch
- Urlaub
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- IAM
- identifiziert
- identifizieren
- Identifizierung
- Identitätsschutz
- if
- zeigt
- Impact der HXNUMXO Observatorien
- implementieren
- umgesetzt
- Umsetzung
- wichtig
- zu unterstützen,
- Verbesserung
- in
- Einschließlich
- Indien
- zeigen
- Anzeige
- Info
- Einblicke
- integriert
- Integration
- Integrität
- Intelligenz
- interaktive
- in
- IT
- SEINE
- join
- beigetreten
- Beitritt
- Joins
- jpg
- Behalten
- Aufbewahrung
- Wesentliche
- Tasten
- See
- Sprache
- später
- neueste
- Schicht
- links
- Lens
- Lasst uns
- Niveau
- Line
- Belastung
- Laden
- Belastungen
- located
- suchen
- gemacht
- MACHT
- verwaltet
- Marketing
- abgestimmt
- Bedeutung
- messen
- erwähnt
- Merge
- Metrik
- Geist / Bewusstsein
- Fehler
- Modell
- Modellieren
- Modellieren
- für
- Monat
- mehr
- vor allem warme
- mehrere
- Namen
- Natürliche
- Navigieren
- Need
- benötigen
- Bedürfnisse
- Neu
- Notizen
- Benachrichtigung
- Benachrichtigungen
- jetzt an
- und viele
- of
- bieten
- vorgenommen,
- on
- einzige
- Betriebs-
- or
- Organisation
- UNSERE
- übrig
- Gesamt-
- Parameter
- Teil
- leidenschaftlich
- für
- ausführen
- Leistung
- vielleicht
- periodisch
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- Points
- besiedelt
- Post
- Werkzeuge
- Praxis
- Voraussetzungen
- Gegenwart
- primär
- Verfahren
- Verfahren
- Prozessdefinierung
- anpassen
- Produkt
- die
- vorausgesetzt
- bietet
- Öffentlichkeit
- veröffentlichen
- Zwecke
- Fragen
- schnell
- erhöhen
- Roh
- Rohdaten
- Rekord
- Aufzeichnungen
- Veteran
- bezeichnet
- spiegelt
- Region
- Beziehung
- bleibt bestehen
- entfernen
- ersetzen
- berichten
- Reporting
- Meldungen
- Voraussetzungen:
- Downloads
- Verantwortung
- Rollen
- Rollen
- REIHE
- Führen Sie
- läuft
- Salz
- Vertrieb
- gleich
- Beispieldatensatz
- skalierbaren
- Zeitplan
- Planung
- Abschnitte
- Bibliotheken
- Sicherheitdienst
- sehen
- getrennte
- dient
- Lösungen
- Sessions
- kompensieren
- mehrere
- sollte
- erklären
- Konzerte
- Einfacher
- Einfachheit
- Single
- Langsam
- klein
- kleinere
- Schnappschuss
- So
- verkauft
- Lösung
- einige
- Quelle
- Quellen
- Raumfahrt
- Spezialist
- spezifisch
- speziell
- Stufe
- Aufführung
- Star
- begonnen
- Beginnen Sie
- Erklärung
- Schritt
- Shritte
- Lagerung
- speichern
- gelagert
- Strategien
- Strategie
- Struktur
- erfolgreich
- Erfolgreich
- so
- System
- Tabelle
- vorübergehend
- Zehn
- AGB
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- die Welt
- ihr
- dann
- Dort.
- deswegen
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- Tausende
- Durch
- Ticket
- Ticketverkauf
- Tickets
- Zeit
- mal
- Zeitstempel
- Tipps
- zu
- heute
- gemeinsam
- nahm
- Gesamt
- verfolgen sind
- Transaktion
- Transformieren
- verwandelt
- Reisende
- tippe
- Typen
- typisch
- Verständnis
- einzigartiges
- einzigartig
- Einzigartigkeit
- unbekannt
- Aktualisierung
- aktualisiert
- us
- Anwendungsbereich
- -
- Anwendungsfall
- benutzt
- Nutzer
- verwendet
- Verwendung von
- gewöhnlich
- wertvoll
- Wert
- Werte
- verschiedene
- Veranstaltungsort
- Veranstaltungsorte
- Anzeigen
- Volumen
- Walkthrough
- wollen
- Warehouse
- wurde
- Wege
- we
- Netz
- Web-Services
- Webseiten
- Woche
- wann
- welche
- während
- werden wir
- mit
- .
- ohne
- arbeiten,
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- Falsch
- Jahr
- Jahr
- U
- Ihr
- Zephyrnet