AWS Glue Studio ist jetzt integriert mit AWS Glue Data Brew. AWS Glue Studio ist eine grafische Oberfläche, die das Erstellen, Ausführen und Überwachen von Extraktions-, Transformations- und Ladejobs (ETL) erleichtert AWS-Kleber. DataBrew ist ein visuelles Datenvorbereitungstool, mit dem Sie Daten bereinigen und normalisieren können, ohne Code schreiben zu müssen. Die über 200 bereitgestellten Transformationen können jetzt in einem visuellen Auftrag von AWS Glue Studio verwendet werden.
In DataBrew a Rezept ist eine Reihe von Datentransformationsschritten, die Sie interaktiv in der intuitiven visuellen Benutzeroberfläche erstellen können. In diesem Beitrag erfahren Sie, wie Sie ein Rezept in DataBrew erstellen und es dann als Teil eines visuellen ETL-Auftrags in AWS Glue Studio anwenden.
Bestehende DataBrew-Benutzer profitieren ebenfalls von dieser Integration: Sie können Ihre Rezepte jetzt als Teil eines größeren visuellen Workflows mit allen anderen von AWS Glue Studio bereitgestellten Komponenten ausführen und außerdem die erweiterte Auftragskonfiguration und die neueste Version der AWS Glue-Engine verwenden .
Diese Integration bringt den bestehenden Benutzern beider Tools deutliche Vorteile:
- Sie haben in AWS Glue Studio eine zentrale End-to-End-Ansicht des gesamten ETL-Diagramms
- Sie können interaktiv ein Rezept definieren, Werte, Statistiken und Verteilung auf der DataBrew-Konsole sehen und dann diese getestete und versionierte Verarbeitungslogik in visuellen AWS Glue Studio-Jobs wiederverwenden
- Sie können mehrere DataBrew-Rezepte in einem AWS Glue ETL-Auftrag oder sogar mehrere Aufträge mithilfe von AWS Glue-Workflows orchestrieren
- DataBrew-Rezepte können jetzt AWS Glue-Auftragsfunktionen wie Lesezeichen für die inkrementelle Datenverarbeitung, automatische Wiederholungsversuche, automatische Skalierung oder das Gruppieren kleiner Dateien für mehr Effizienz nutzen
Lösungsüberblick
In unserem fiktiven Anwendungsfall besteht die Anforderung darin, einen für diesen Beitrag erstellten synthetischen Datensatz zu medizinischen Ansprüchen zu bereinigen, in den absichtlich einige Datenqualitätsprobleme eingeführt wurden, um die DataBrew-Funktionen zur Datenaufbereitung zu demonstrieren. Anschließend werden die Schadensdaten in den Katalog aufgenommen (damit sie für Analysten sichtbar sind), nachdem sie mit einigen relevanten Details zu den entsprechenden medizinischen Anbietern aus einer separaten Quelle angereichert wurden.
Die Lösung besteht aus einem visuellen Auftrag von AWS Glue Studio, der zwei CSV-Dateien mit Ansprüchen bzw. Anbietern liest. Der Job wendet ein Rezept des ersten an, um die Qualitätsprobleme zu beheben, wählt Spalten aus dem zweiten aus, verbindet beide Datensätze und speichert schließlich das Ergebnis Amazon Simple Storage-Service (Amazon S3), Erstellen einer Tabelle im Katalog, damit die Ausgabedaten von anderen Tools wie verwendet werden können Amazonas Athena.
Erstellen Sie ein DataBrew-Rezept
Beginnen Sie mit der Registrierung des Datenspeichers für die Schadensakte. Dadurch können Sie das Rezept in seinem interaktiven Editor unter Verwendung der tatsächlichen Daten erstellen, sodass Sie das Ergebnis der Transformationen bewerten können, während Sie sie definieren.
- Laden Sie die Schadens-CSV-Datei über den folgenden Link herunter: alabama_claims_data_Jun2023.csv.
- Wählen Sie in der DataBrew-Konsole Datensätze im Navigationsbereich und wählen Sie dann aus Neuen Datensatz verbinden.
- Wählen Sie die Option Datei-Upload.
- Aussichten für Datensatzname, eingeben
Alabama claims. - Aussichten für Wählen Sie eine Datei zum Hochladen aus, wählen Sie die Datei aus, die Sie gerade auf Ihren Computer heruntergeladen haben.
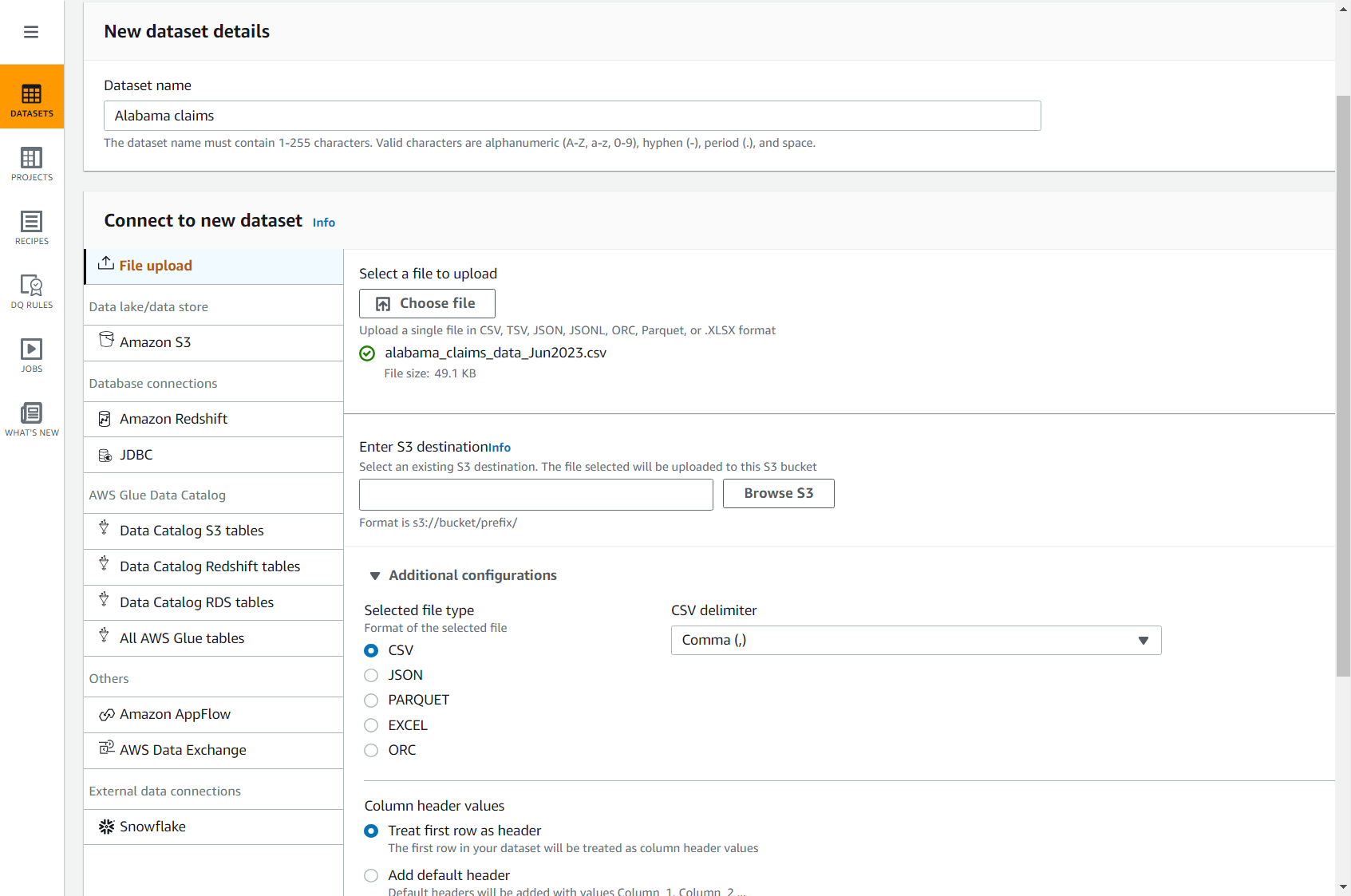
- Aussichten für S3-Ziel eingeben, geben Sie einen Bucket in Ihrem Konto und Ihrer Region ein oder navigieren Sie zu diesem.
- Belassen Sie die restlichen Optionen standardmäßig (CSV getrennt durch Komma und mit Kopfzeile) und schließen Sie die Datensatzerstellung ab.
- Auswählen Projekt im Navigationsbereich und wählen Sie dann aus Projekt anlegen.
- Aussichten für Projektname, nenne es
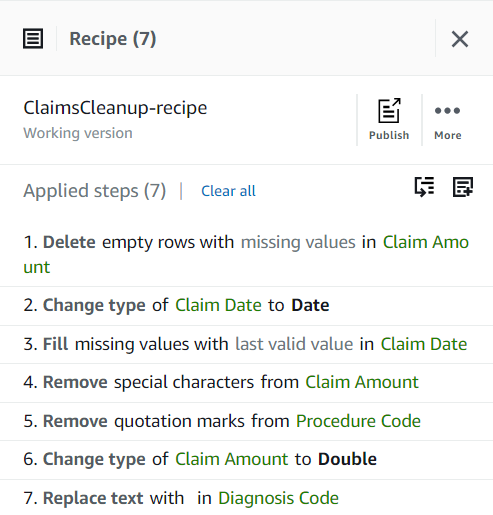
ClaimsCleanup. - Der RezeptdetailsZ. Angehängtes Rezept, wählen Neues Rezept erstellen, nenne es
ClaimsCleanup-recipeund wählen Sie dieAlabama claimsDatensatz, den Sie gerade erstellt haben.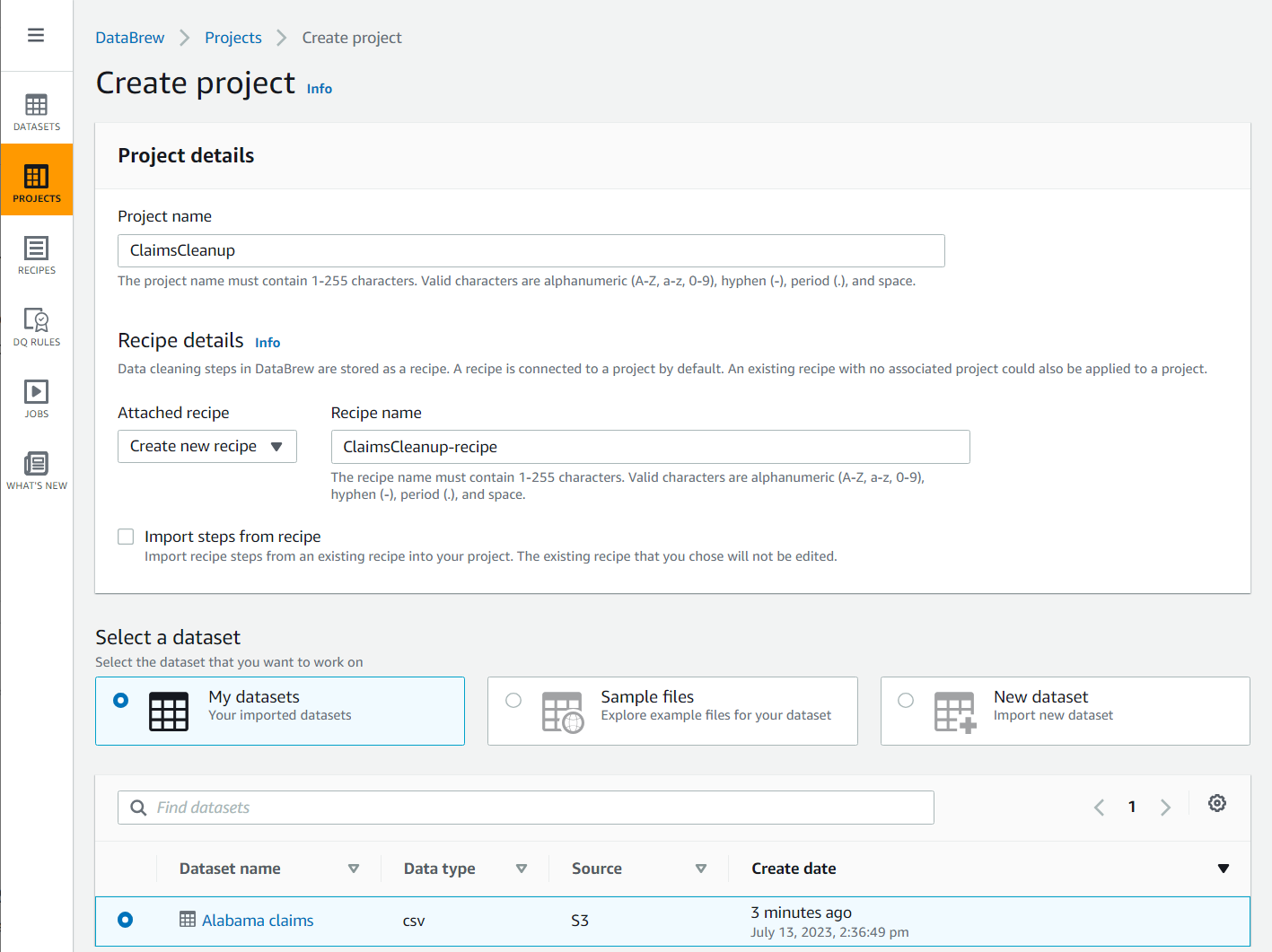
- Wählen Sie ein Rolle geeignet für DataBrew oder erstellen Sie ein neues und schließen Sie die Projekterstellung ab.
Dadurch wird eine Sitzung mit einer konfigurierbaren Teilmenge der Daten erstellt. Nachdem die Sitzung initialisiert wurde, können Sie feststellen, dass einige Zellen ungültige oder fehlende Werte aufweisen.
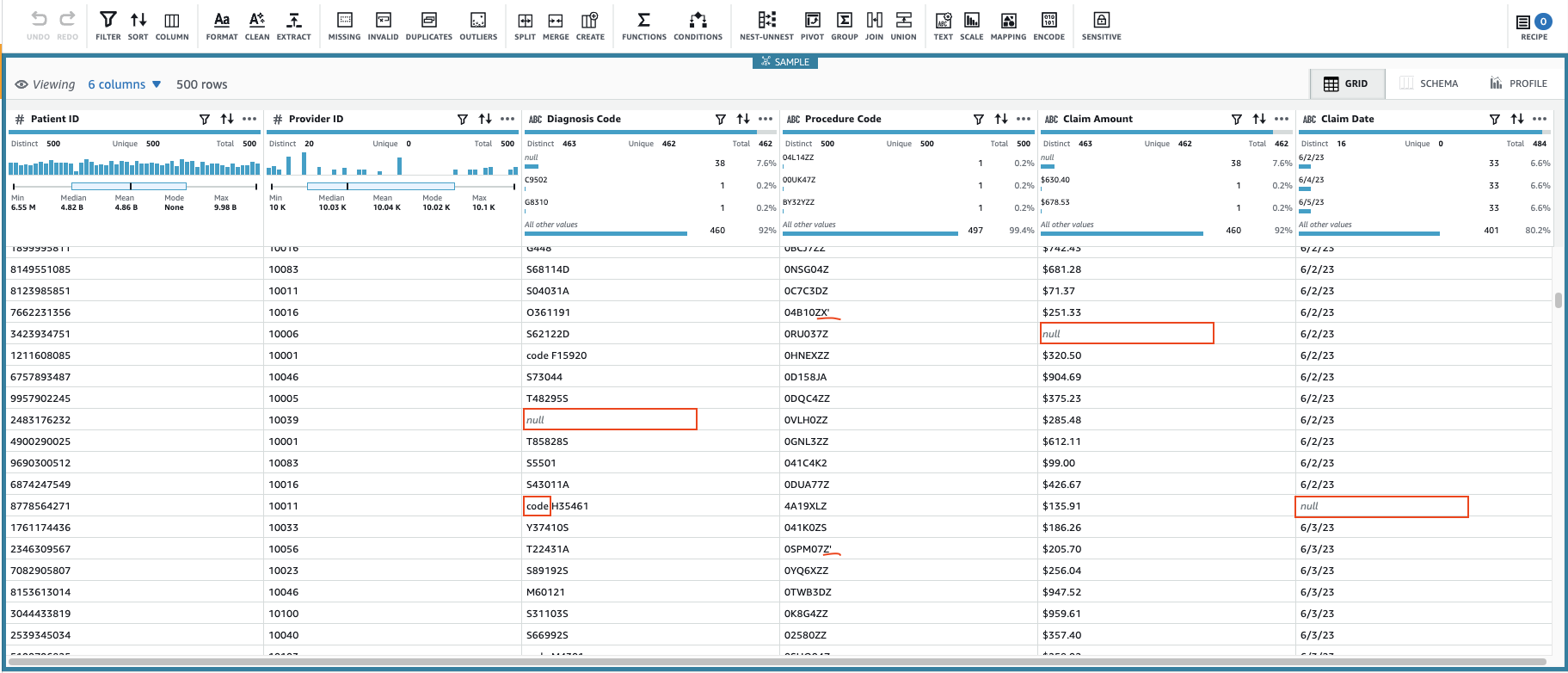
Zusätzlich zu den fehlenden Werten in den Spalten Diagnosecode, Anspruchsbetrag und Anspruchsdatum, einige Werte in den Daten haben einige zusätzliche Zeichen: Diagnosecode Werten wird manchmal „Code“ vorangestellt (Leerzeichen eingeschlossen) und Verfahrenscode Auf Werte folgen manchmal einfache Anführungszeichen.
Anspruchsbetrag Für einige Berechnungen werden wahrscheinlich Werte verwendet, also konvertieren Sie sie in Zahlen und Anspruchsdaten sollte in den Datumstyp konvertiert werden.
Nachdem wir nun die zu behebenden Datenqualitätsprobleme identifiziert haben, müssen wir entscheiden, wie wir mit jedem einzelnen Fall umgehen.
Es gibt mehrere Möglichkeiten, Rezeptschritte hinzuzufügen, unter anderem über das Spaltenkontextmenü, die Symbolleiste oben oder über die Rezeptzusammenfassung. Mit der letzten Methode können Sie nach dem angegebenen Schritttyp suchen, um das in diesem Beitrag erstellte Rezept zu reproduzieren.
Anspruchsbetrag ist für diesen Anwendungsfall von wesentlicher Bedeutung, und die Entscheidung besteht darin, solche Zeilen zu entfernen.
- Fügen Sie den Schritt hinzu Fehlende Werte entfernen.
- Aussichten für Quellenspalte, wählen Anspruchsbetrag.
- Behalten Sie die Standardaktion bei Zeilen mit fehlenden Werten löschen und wählen Sie Bewerbung um sie zu speichern.
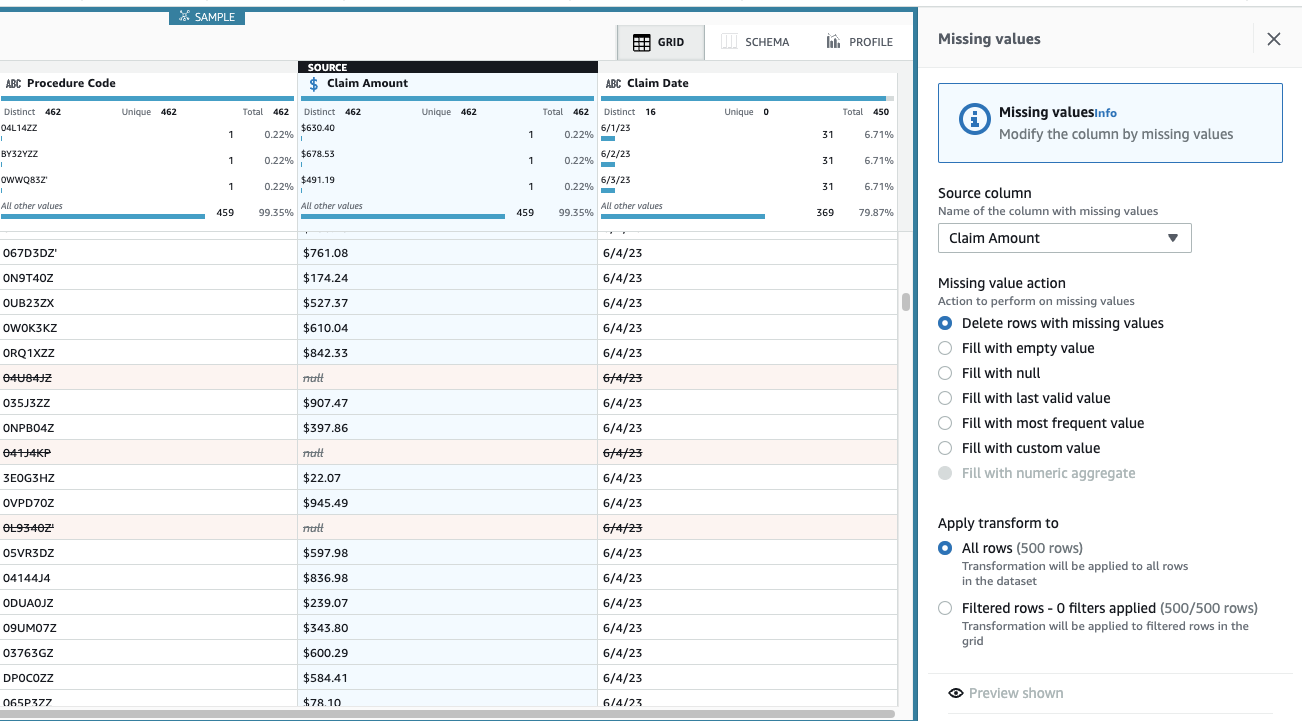
Die Ansicht wird jetzt aktualisiert, um die Schrittanwendung widerzuspiegeln, und die Zeilen mit fehlenden Beträgen sind nicht mehr vorhanden.
Diagnosecode kann leer sein, daher wird dies akzeptiert, aber im Fall von Anspruchsdatum, wir wollen eine vernünftige Schätzung haben. Die Zeilen in den Daten sind in chronologischer Reihenfolge sortiert, sodass Sie fehlende Daten mithilfe des in der Vorschau angezeigten gültigen Werts aus den vorherigen Zeilen errechnen können. Unter der Annahme, dass es für jeden Tag Ansprüche gibt, bestünde der größte Fehler darin, ihn dem Vorschautag zuzuordnen, wenn es der erste Anspruch an diesem Tag wäre, dem das Datum fehlt; Zur Veranschaulichung betrachten wir diesen potenziellen Fehler als akzeptabel.
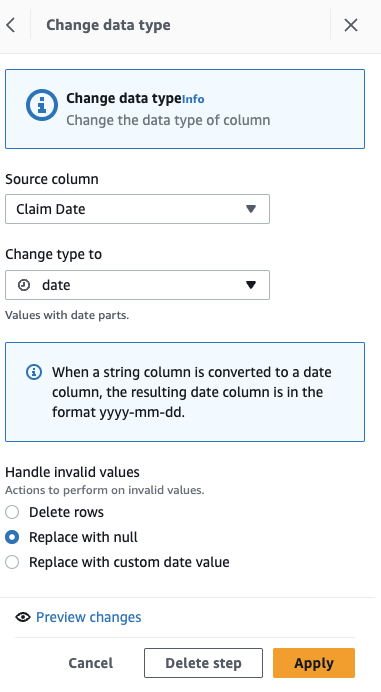
Konvertieren Sie zunächst die Spalte vom Typ „String“ in den Typ „Datum“.
- Fügen Sie den Schritt hinzu Typ ändern.
- Auswählen
Anspruchsdatum als Spalte und Datum als Typ, dann wählen Sie Bewerbung.
- Um nun die Imputation fehlender Daten durchzuführen, fügen Sie den Schritt hinzu Füllen Sie fehlende Werte aus oder imputieren Sie sie.
- Wählen Sie als Aktion „Mit letztem gültigen Wert füllen“ aus und wählen Sie Anspruchsdatum als Quelle.
- Auswählen
Vorschau von Änderungen Um es zu validieren, wählen Sie dann Bewerbung um den Schritt zu speichern.
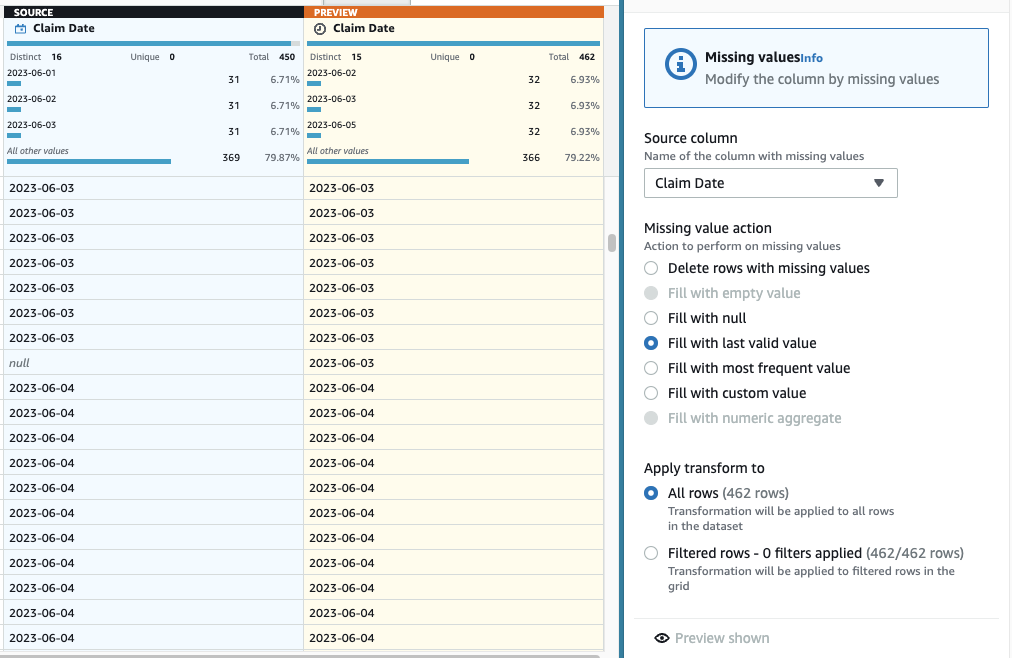
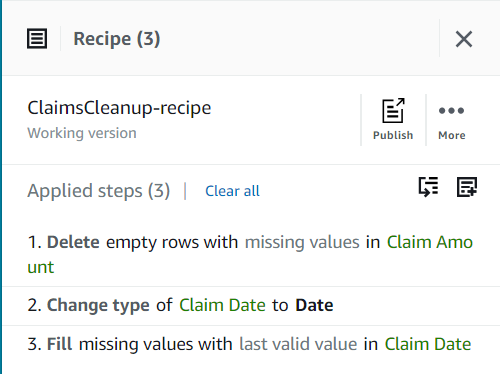
Bisher sollte Ihr Rezept aus drei Schritten bestehen, wie im folgenden Screenshot gezeigt.
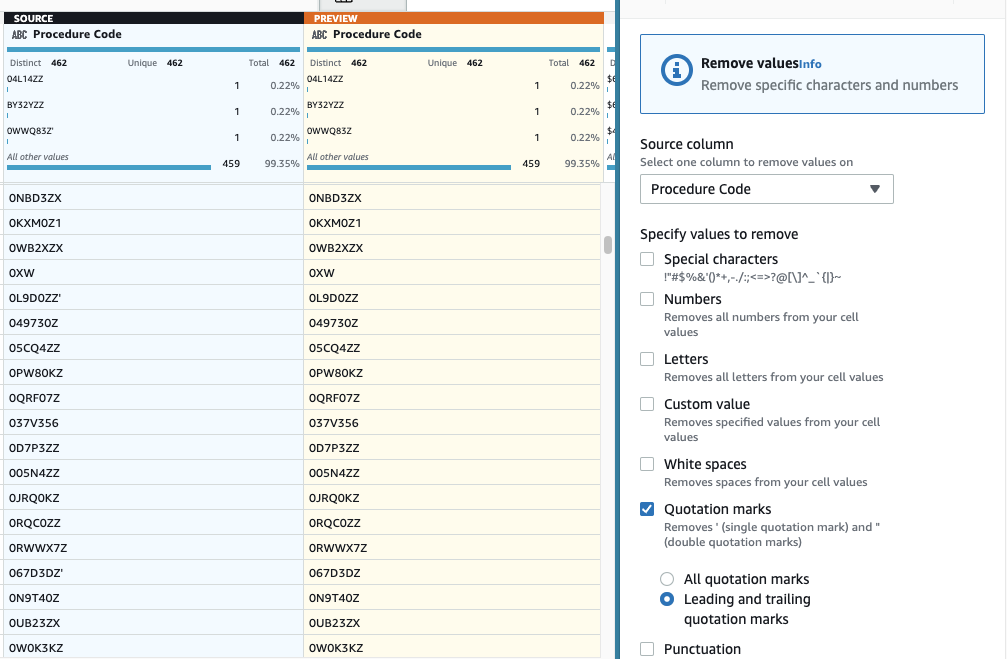
- Als nächstes fügen Sie den Schritt hinzu Anführungszeichen entfernen.
- Wähle die Verfahrenscode Spalte und wählen Sie Führende und nachgestellte Anführungszeichen.
- Überprüfen Sie in der Vorschau, ob der gewünschte Effekt erzielt wird, und wenden Sie den neuen Schritt an.
- Fügen Sie den Schritt hinzu Sonderzeichen entfernen.
- Wähle die Anspruchsbetrag Spalte und um genauer zu sein, wählen Sie aus Benutzerdefinierte Sonderzeichen und gib ein
$für Geben Sie benutzerdefinierte Sonderzeichen ein.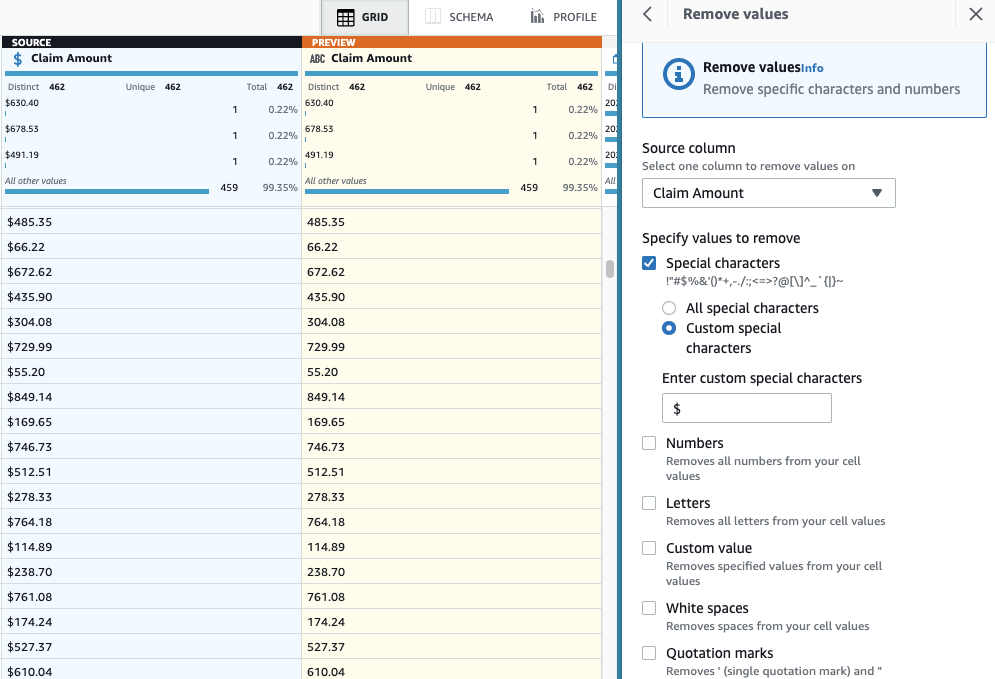
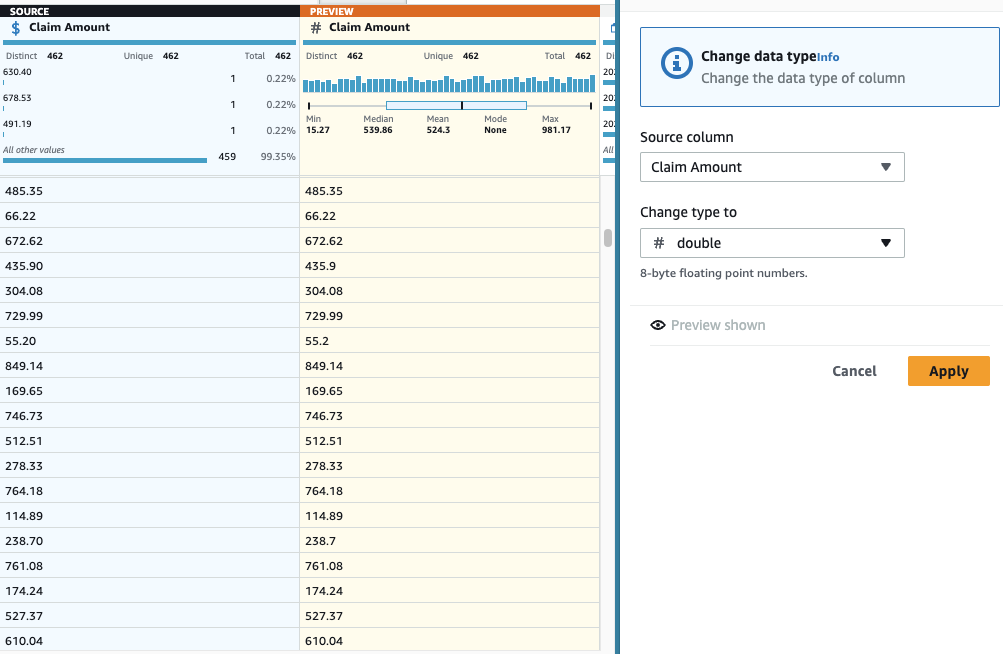
- Hinzufügen Typ ändern Treten Sie auf die Säule Anspruchsbetrag und wählen Sie doppelt als Typ.
- Um im letzten Schritt das überflüssige „code“-Präfix zu entfernen, fügen Sie a hinzu Wert oder Muster ersetzen Schritt.
- Wählen Sie die Spalte aus DiagnosecodeUnd für Geben Sie einen benutzerdefinierten Wert ein, eingeben
code(mit einem Leerzeichen am Ende).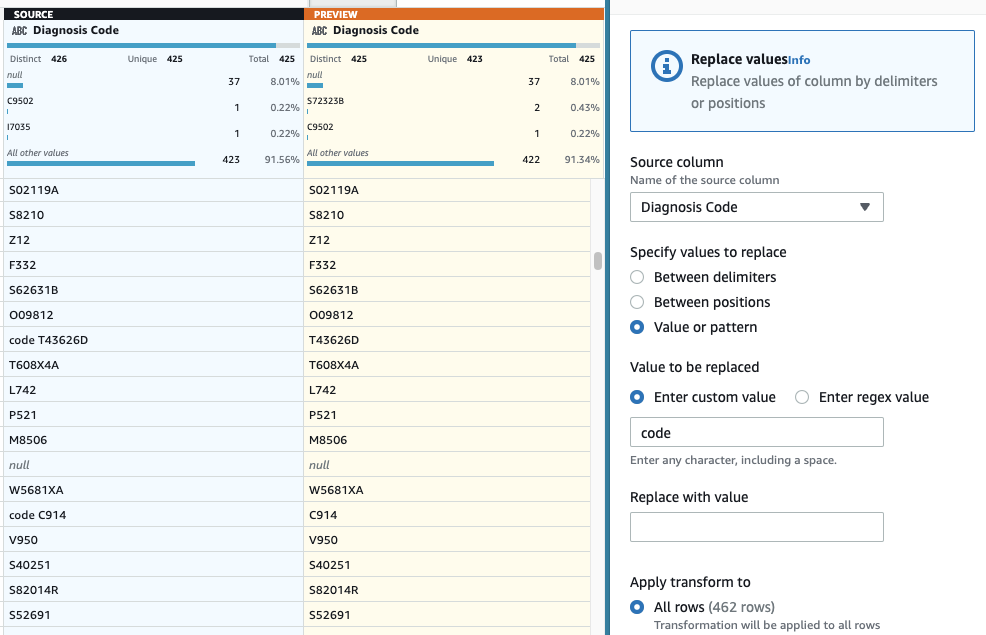
Nachdem Sie nun alle im Beispiel identifizierten Datenqualitätsprobleme behoben haben, veröffentlichen Sie das Projekt als Rezept.
- Auswählen
Veröffentlichen der Rezept Geben Sie eine optionale Beschreibung ein und schließen Sie die Veröffentlichung ab.
Bei jeder Veröffentlichung wird eine andere Version des Rezepts erstellt. Später können Sie auswählen, welche Version des Rezepts Sie verwenden möchten.
Erstellen Sie einen visuellen ETL-Auftrag in AWS Glue Studio
Als Nächstes erstellen Sie den Job, der das Rezept verwendet. Führen Sie die folgenden Schritte aus:
- Wählen Sie in der AWS Glue Studio-Konsole Visuelles ETL im Navigationsbereich.
- Auswählen Visuell mit einer leeren Leinwand und erstellen Sie den visuellen Job.
- Ersetzen Sie oben im Job „Job ohne Titel“ durch einen Namen Ihrer Wahl.
- Auf dem Job Details Geben Sie auf der Registerkarte eine Rolle an, die der Job verwenden soll.
Dies muss ein sein AWS Identity and Access Management and (ICH BIN) Rolle geeignet für AWS Glue mit Berechtigungen für Amazon S3 und den AWS Glue Data Catalog. Beachten Sie, dass die zuvor für DataBrew verwendete Rolle nicht für Ausführungsjobs verwendbar ist und daher nicht im aufgeführt wird IAM-Rolle Dropdown-Menü hier.
Wenn Sie zuvor nur DataBrew-Jobs verwendet haben, beachten Sie, dass Sie in AWS Glue Studio Leistungs- und Kosteneinstellungen auswählen können, einschließlich Worker-Größe, automatische Skalierung usw Flexible Ausführung, sowie die neueste AWS Glue 4.0-Laufzeit nutzen und von den damit verbundenen erheblichen Leistungsverbesserungen profitieren. Für diesen Job können Sie die Standardeinstellungen verwenden, jedoch aus Gründen der Sparsamkeit die gewünschte Anzahl an Arbeitskräften reduzieren. Für dieses Beispiel reichen zwei Arbeiter aus. - Auf dem visuell Fügen Sie auf der Registerkarte eine S3-Quelle hinzu und benennen Sie sie
Providers. - Aussichten für S3-URL, eingeben
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.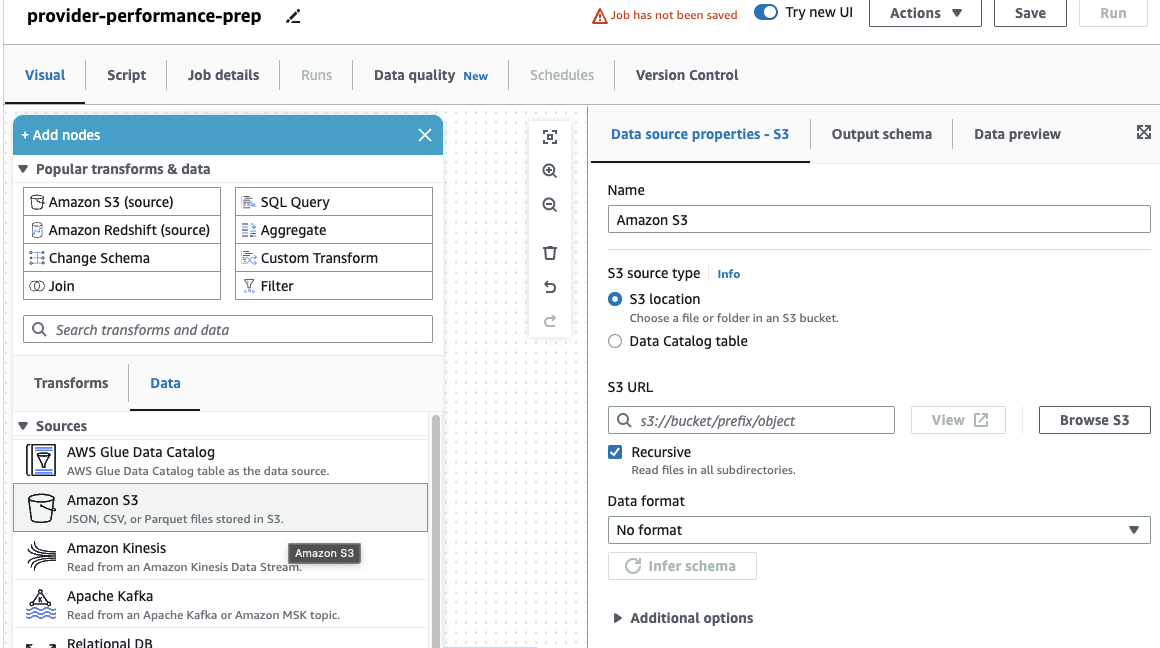
- Wählen Sie das Format als CSV und wählen Sie Schema ableiten.
Jetzt ist das Schema auf der aufgeführt Ausgabeschema Registerkarte mithilfe des Dateikopfes.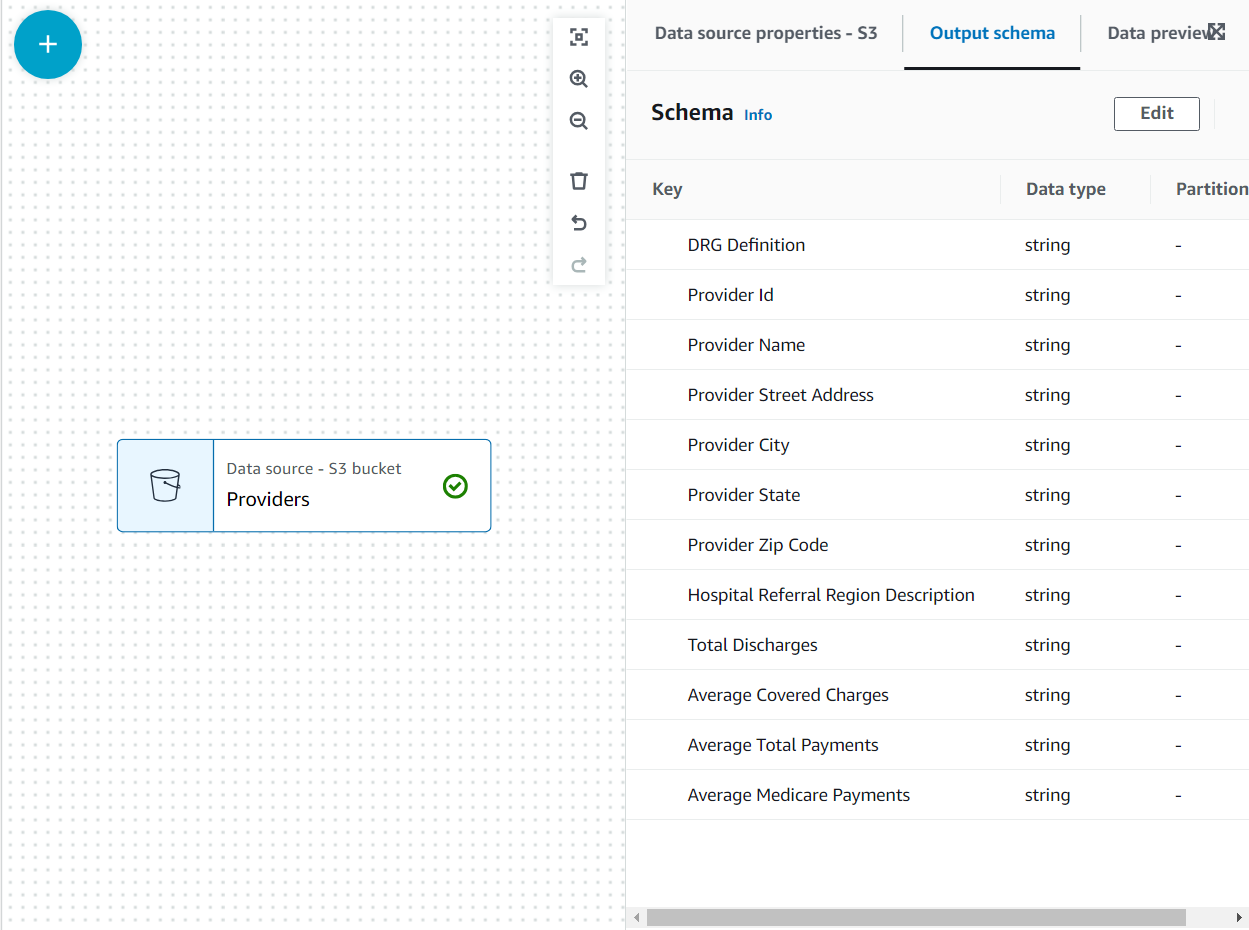
In diesem Anwendungsfall lautet die Entscheidung, dass nicht alle Spalten im Anbieterdatensatz benötigt werden, sodass wir den Rest verwerfen können.
- Mit der Anbieter Knoten ausgewählt, fügen Sie einen hinzu Drop-Felder transformieren (wenn Sie den übergeordneten Knoten nicht ausgewählt haben, hat er keinen; weisen Sie in diesem Fall den übergeordneten Knoten manuell zu).
- Wählen Sie anschließend alle Felder aus Postleitzahl des Anbieters.
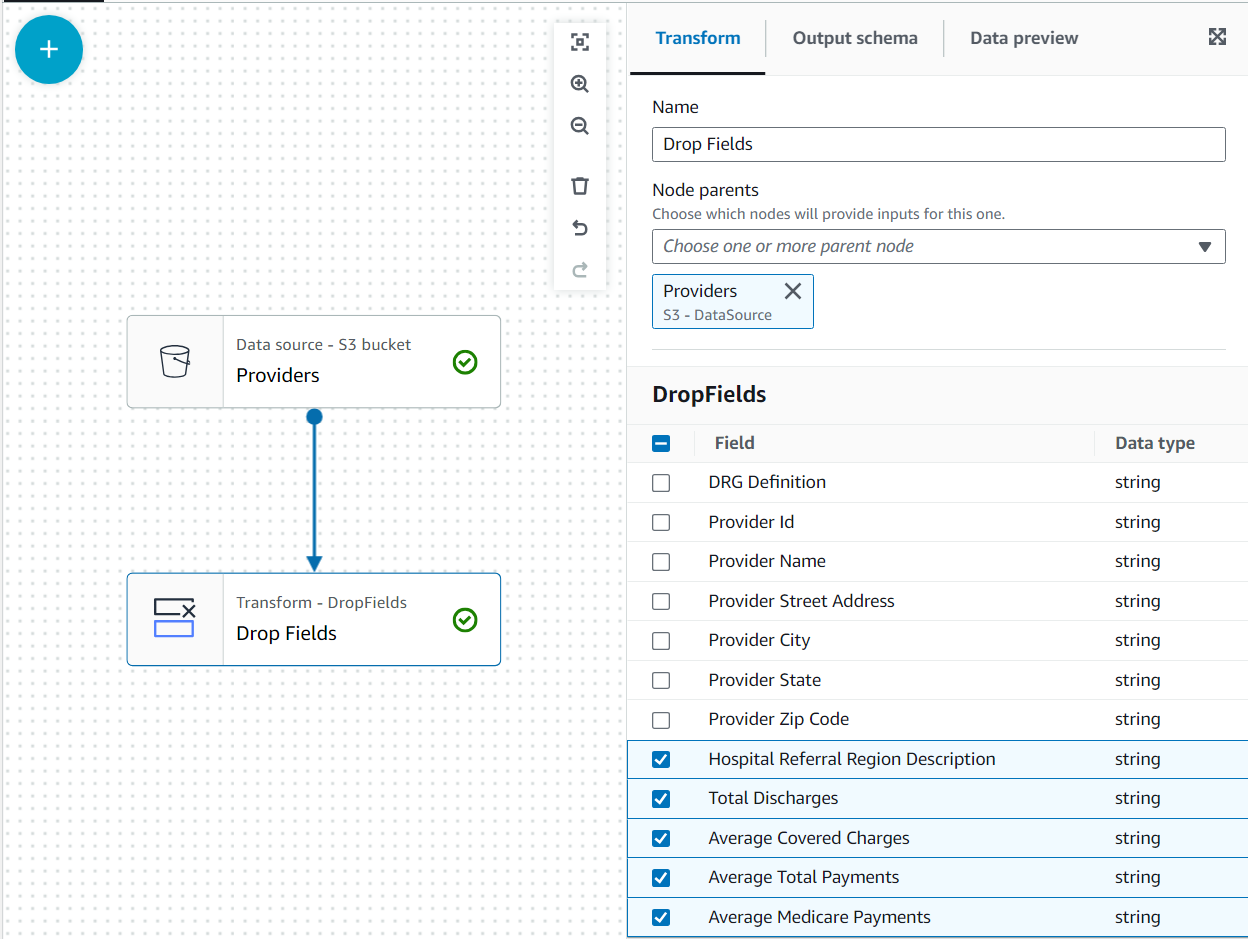
Später werden diese Daten durch die Ansprüche für den Bundesstaat Alabama ergänzt, der den Anbieter nutzt; Für diesen zweiten Datensatz ist jedoch nicht der angegebene Status vorhanden. Wir können die Kenntnis der Daten nutzen, um den Join zu optimieren, indem wir die Daten filtern, die wir wirklich benötigen.
- Hinzufügen Filter als Kind verwandeln von Drop-Felder.
- Benenne es
Alabama providersund fügen Sie eine Bedingung hinzu, die der Staat erfüllen mussAL.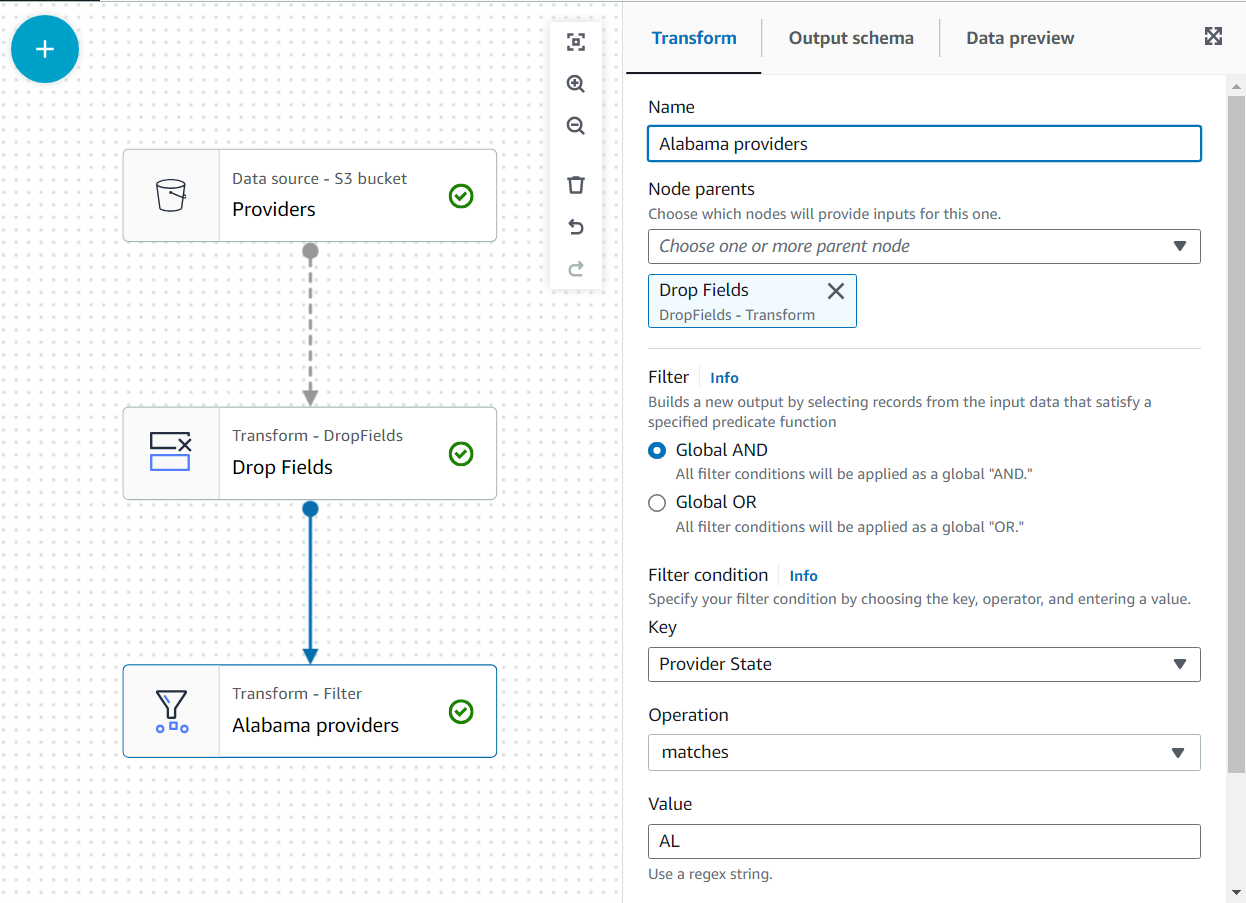
- Fügen Sie die zweite Quelle (eine neue S3-Quelle) hinzu und benennen Sie sie
Alabama claims. - Zum eingeben des S3-URL, öffnen Sie DataBrew auf einer separaten Browser-Registerkarte, wählen Sie im Navigationsbereich „Datensätze“ und kopieren Sie in der Tabelle den in der Tabelle angezeigten Speicherort für Alabama behauptet (Kopieren Sie den Text, der mit s3:// beginnt, nicht den zugehörigen http-Link). Kehren Sie dann zum visuellen Job zurück und fügen Sie ihn als ein S3-URL; Wenn es richtig ist, sehen Sie es in der Ausgabeschema Klicken Sie auf die Registerkarte, um die aufgelisteten Datenfelder anzuzeigen.
- Wählen Sie das CSV-Format und leiten Sie das Schema ab, wie Sie es mit der anderen Quelle getan haben.
- Suchen Sie als untergeordnetes Element dieser Quelle im Knoten hinzufügen Menü für
recipeund wählen Sie Rezept zur Datenvorbereitung.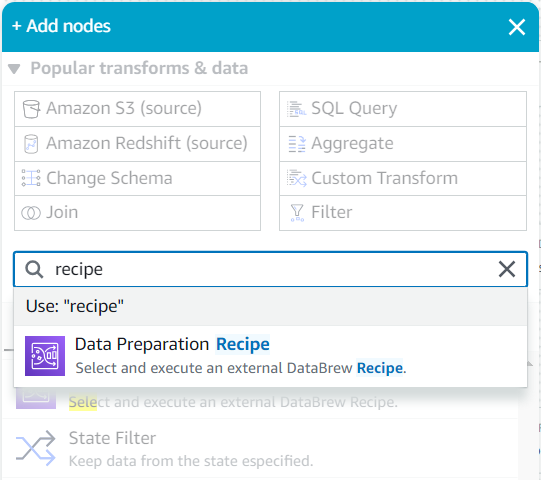
- Geben Sie in den Eigenschaften dieses neuen Knotens den Namen ein
Claim cleanup recipeund wählen Sie das Rezept und die Version aus, die Sie zuvor veröffentlicht haben. - Sie können die Rezeptschritte hier überprüfen und den Link zu DataBrew verwenden, um bei Bedarf Änderungen vorzunehmen.
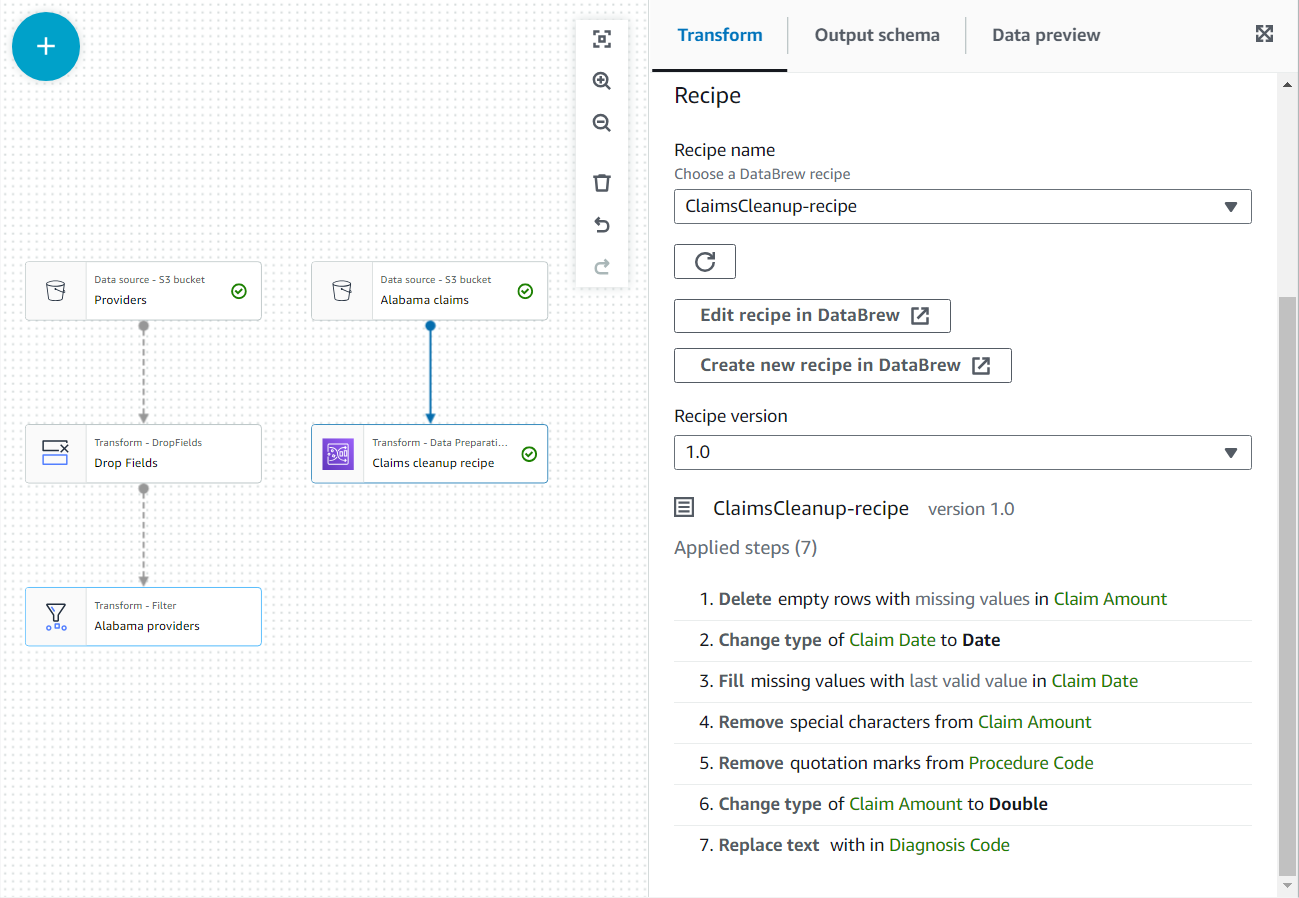
- Hinzufügen Bewirb dich bei uns! Knoten und wählen Sie beide aus Alabama-Anbieter und Beanspruchen Sie Reinigungsrezepte als Elternteil.
- Fügen Sie eine Join-Bedingung hinzu, die der Anbieter-ID aus beiden Quellen entspricht.
- Fügen Sie als letzten Schritt einen S3-Knoten als Ziel hinzu (beachten Sie, dass der erste bei der Suche aufgeführte Knoten die Quelle ist; stellen Sie sicher, dass Sie die Version auswählen, die als Ziel aufgeführt ist).
- Behalten Sie in der Knotenkonfiguration das Standardformat JSON bei und geben Sie eine S3-URL ein, auf die die Jobrolle schreiben darf.
Stellen Sie außerdem die Datenausgabe als Tabelle im Katalog zur Verfügung.
- Im Data Catalog-Aktualisierungsoptionen Wählen Sie im Abschnitt die zweite Option aus Erstellen Sie eine Tabelle im Datenkatalog und aktualisieren Sie bei nachfolgenden Ausführungen das Schema und fügen Sie neue Partitionen hinzu, und wählen Sie dann eine Datenbank aus, für die Sie die Berechtigung zum Erstellen von Tabellen haben.
- Weisen
alabama_claimsals Namen und wählen Sie Anspruchsdatum als Partitionsschlüssel (dies dient der Veranschaulichung; eine kleine Tabelle wie diese benötigt eigentlich keine Partitionen, wenn später keine weiteren Daten hinzugefügt werden).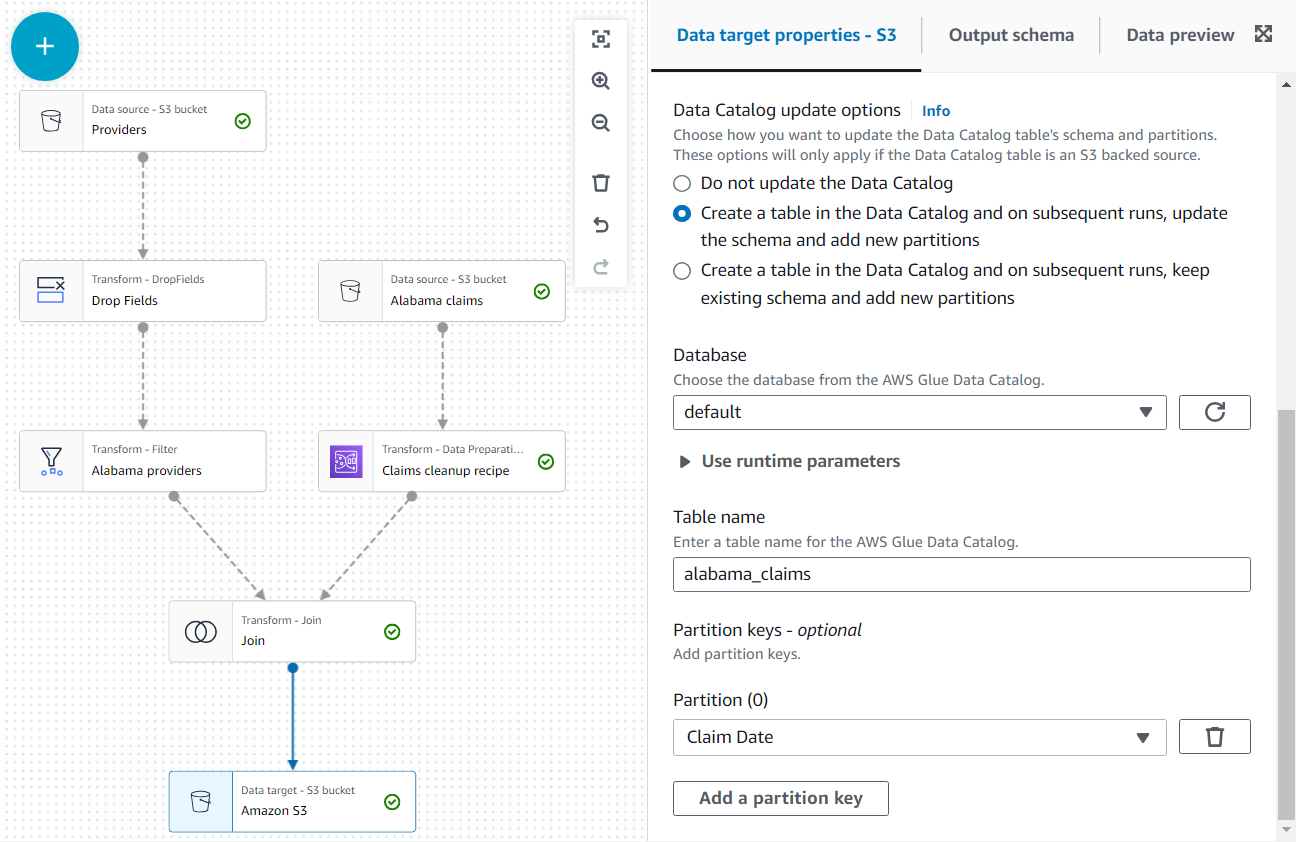
- Jetzt können Sie den Job speichern und ausführen.
- Auf dem Läuft Auf der Registerkarte „Job-ID“ können Sie den Prozess verfolgen und detaillierte Jobkennzahlen anzeigen.
Der Auftrag sollte einige Minuten dauern.
- Wenn der Auftrag abgeschlossen ist, navigieren Sie zur Athena-Konsole.
- Suchen Sie nach der Tabelle
alabama_claimsin der von Ihnen ausgewählten Datenbank und wählen Sie über das Kontextmenü Vorschautabelle, wodurch eine einfache SELECT * SQL-Anweisung für die Tabelle ausgeführt wird.
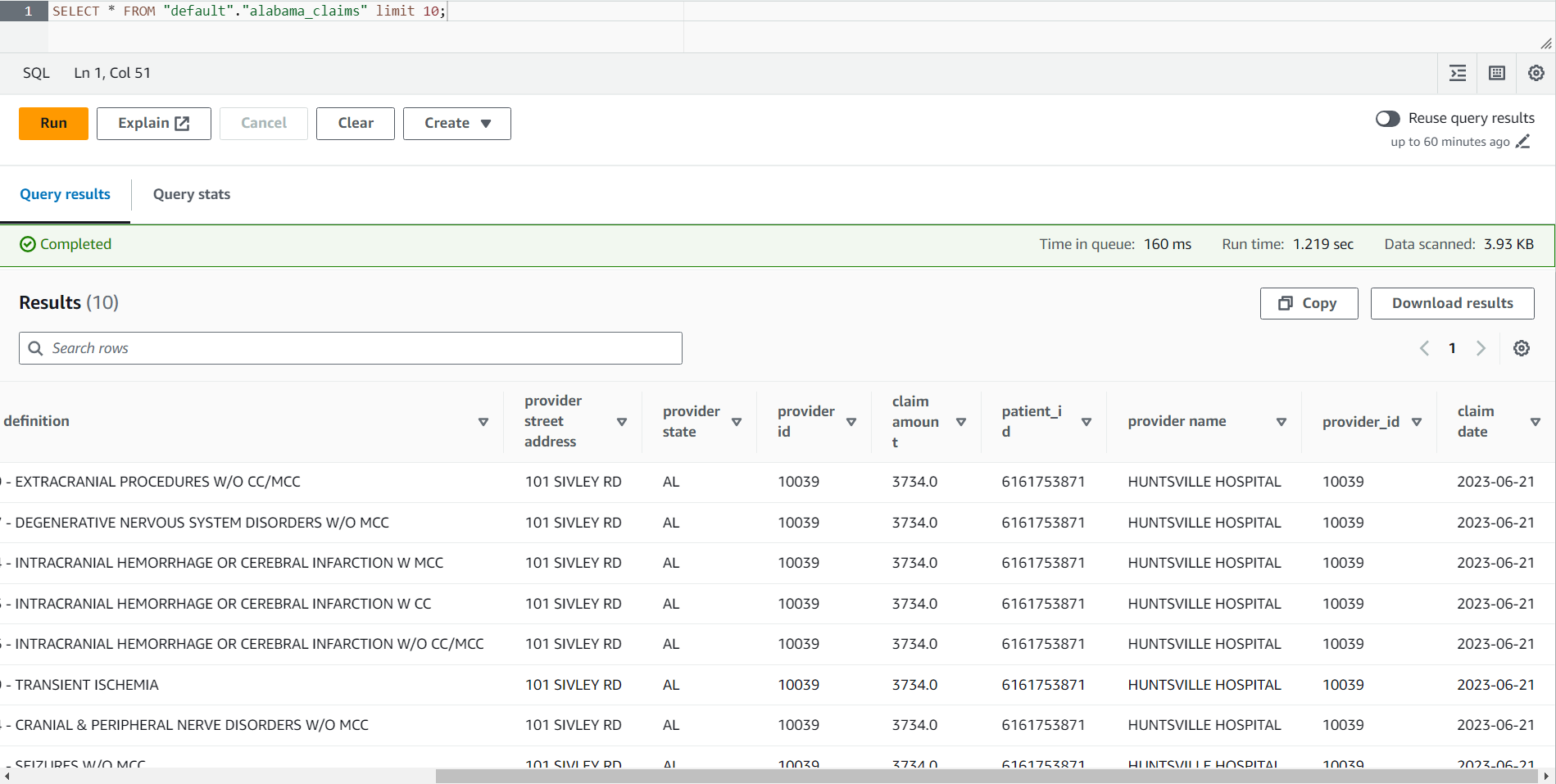
Im Ergebnis des Auftrags können Sie sehen, dass die Daten durch das DataBrew-Rezept bereinigt und durch den AWS Glue Studio-Join angereichert wurden.
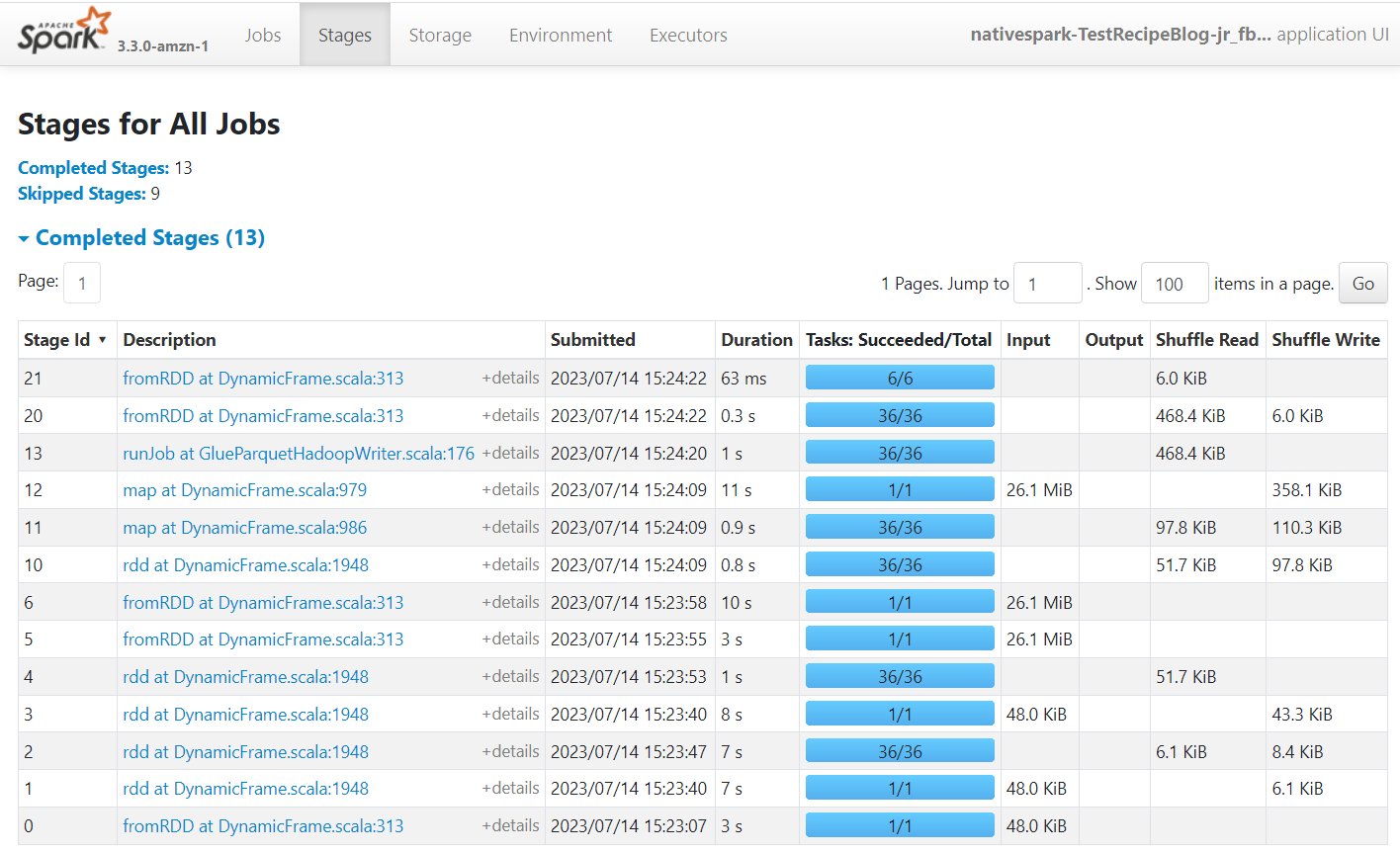
Apache Spark ist die Engine, die die in AWS Glue Studio erstellten Jobs ausführt. Wenn Sie die Spark-Benutzeroberfläche in den von ihr erstellten Ereignisprotokollen verwenden, können Sie Einblicke in den Auftragsplan und die Ausführung erhalten, die Ihnen dabei helfen können, die Leistung Ihres Auftrags und potenzielle Leistungsengpässe zu verstehen. Für diesen Auftrag an einem großen Datensatz können Sie damit beispielsweise die Auswirkungen einer expliziten Filterung des Anbieterstatus vor der Verknüpfung vergleichen oder ermitteln, ob Sie vom Hinzufügen einer Autobalance-Transformation zur Verbesserung der Parallelität profitieren können.
Standardmäßig speichert der Job die Apache Spark-Ereignisprotokolle unter dem Pfad s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Um die Jobs anzuzeigen, müssen Sie einen Verlaufsserver installieren eine der verfügbaren Methoden.
Aufräumen
Wenn Sie diese Lösung nicht mehr benötigen, können Sie die auf Amazon S3 generierten Dateien, die durch den Job erstellte Tabelle, das DataBrew-Rezept und den AWS Glue-Job löschen.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie mit AWS DataBrew mithilfe des bereitgestellten interaktiven Editors ein Rezept erstellen und das veröffentlichte Rezept dann als Teil eines visuellen ETL-Jobs in AWS Glue Studio verwenden können. Wir haben einige Beispiele für häufige Aufgaben beigefügt, die bei der Datenvorbereitung und der Aufnahme von Daten in AWS Glue Catalog-Tabellen erforderlich sind.
In diesem Beispiel wurde ein einzelnes Rezept im visuellen Job verwendet, es ist jedoch möglich, mehrere Rezepte in verschiedenen Teilen des ETL-Prozesses zu verwenden und dasselbe Rezept in mehreren Jobs wiederzuverwenden.
Mit diesen AWS Glue-Lösungen können Sie effektiv fortschrittliche ETL-Pipelines erstellen, die einfach zu erstellen und zu warten sind, ganz ohne Code schreiben zu müssen. Sie können noch heute damit beginnen, Lösungen zu entwickeln, die beide Tools kombinieren.
Über die Autoren
 Michail Smirnov ist Senior Software Dev Engineer im AWS Glue-Team und Teil des AWS Glue DataBrew-Entwicklungsteams. Außerhalb der Arbeit lernt er gerne Gitarre und reist mit seiner Familie.
Michail Smirnov ist Senior Software Dev Engineer im AWS Glue-Team und Teil des AWS Glue DataBrew-Entwicklungsteams. Außerhalb der Arbeit lernt er gerne Gitarre und reist mit seiner Familie.
 Gonzalo herreros ist Senior Big Data Architect im AWS Glue-Team. Mit Sitz in Dublin, Irland, verhilft er Kunden zum Erfolg mit Big-Data-Lösungen auf Basis von AWS Glue. In seiner Freizeit spielt er gerne Brettspiele und fährt Rad.
Gonzalo herreros ist Senior Big Data Architect im AWS Glue-Team. Mit Sitz in Dublin, Irland, verhilft er Kunden zum Erfolg mit Big-Data-Lösungen auf Basis von AWS Glue. In seiner Freizeit spielt er gerne Brettspiele und fährt Rad.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :hast
- :Ist
- :nicht
- $UP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Fähig
- Über Uns
- akzeptabel
- akzeptiert
- Zugang
- Konto
- Action
- präsentieren
- hinzufügen
- hinzugefügt
- Hinzufügen
- Zusatz
- Adresse
- advanced
- Nach der
- Alabama
- Alle
- erlauben
- ebenfalls
- Amazon
- Amazon Web Services
- Beträge
- an
- Business Analysten
- und
- jedem
- Apache
- Apache Funken
- Anwendung
- Bewerbung
- SIND
- AS
- damit verbundenen
- At
- Autor
- Auto
- automatische
- verfügbar
- AWS
- AWS-Kleber
- Zurück
- basierend
- BE
- Bevor
- Sein
- Nutzen
- Vorteile
- Big
- Big Data
- leer
- Tafel
- Brettspiele
- bookmarks
- beide
- Brings
- Browser
- bauen
- aber
- by
- CAN
- Fähigkeiten
- Häuser
- Katalog
- Die Zellen
- zentralisierte
- Übernehmen
- Änderungen
- Zeichen
- der
- Wahl
- Auswählen
- Anspruch
- aus aller Welt
- Code
- Kolonne
- Spalten
- kombinieren
- Kommen
- gemeinsam
- vergleichen
- abschließen
- Komponenten
- Computer
- Zustand
- Konfiguration
- Geht davon
- besteht
- Konsul (Console)
- Kontext
- verkaufen
- umgewandelt
- und beseitigen Muskelschwäche
- Dazugehörigen
- Kosten
- könnte
- erstellen
- erstellt
- Erstellen
- Schaffung
- Original
- Kunden
- technische Daten
- Datenaufbereitung
- Datenverarbeitung
- Datenqualität
- Datenbase
- Datensätze
- Datum
- Datum
- Tag
- Deal
- entscheidet
- Entscheidung
- Standard
- zeigen
- Beschreibung
- erwünscht
- detailliert
- Details
- Entwickler
- Entwicklung
- Entwicklungsteam
- DID
- anders
- deutlich
- Verteilung
- do
- Tut nicht
- Dabei
- Dollar
- doppelt
- Drop
- dublin
- jeder
- Einfache
- Herausgeber
- bewirken
- effektiv
- ermöglicht
- Ende
- Motor
- Ingenieur
- angereichert
- bereichernd
- Enter
- Fehler
- essential
- Äther (ETH)
- bewerten
- Sogar
- Event
- Jedes
- jeden Tag
- Beispiel
- Beispiele
- vorhandenen
- extra
- Extrakt
- Familie
- weit
- Eigenschaften
- wenige
- Felder
- Reichen Sie das
- Mappen
- füllen
- Filter
- Filterung
- Endlich
- Vorname
- gefolgt
- Folgende
- Aussichten für
- Format
- für
- weiter
- Games
- erzeugt
- ABSICHT
- mehr
- Haben
- he
- Hilfe
- hilft
- hier
- seine
- Geschichte
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- IAM
- ID
- identifiziert
- identifizieren
- Identitätsschutz
- if
- Impact der HXNUMXO Observatorien
- zu unterstützen,
- Verbesserungen
- in
- das
- inklusive
- Einschließlich
- angegeben
- Varianten des Eingangssignals:
- Einblicke
- installieren
- Instanz
- integriert
- Integration
- interaktive
- Interesse
- Interessen
- Schnittstelle
- in
- eingeführt
- intuitiv
- Irland
- Probleme
- IT
- SEINE
- Job
- Jobs
- join
- beigetreten
- jpg
- JSON
- nur
- Behalten
- Wesentliche
- Wissen
- grosse
- größer
- höchste
- Nachname
- später
- neueste
- lernen
- Verlassen
- Gefällt mir
- wahrscheinlich
- LINK
- Gelistet
- Belastung
- Standorte
- Logik
- länger
- halten
- um
- MACHT
- manuell
- Spiel
- sowie medizinische
- MENÜ
- Methode
- Methoden
- Metrik
- Minuten
- Kommt demnächst...
- Überwachen
- mehr
- mehrere
- sollen
- Name
- Navigieren
- Menü
- Need
- erforderlich
- Bedürfnisse
- Neu
- nicht
- Knoten
- Notiz..
- jetzt an
- Anzahl
- of
- on
- EINEM
- einzige
- XNUMXh geöffnet
- Optimieren
- Option
- Optionen
- or
- Auftrag
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- aussen
- übrig
- Gesamt-
- Brot
- Teil
- Teile
- Weg
- Leistung
- Durchführung
- Erlaubnis
- Berechtigungen
- Plan
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- möglich
- Post
- Potenzial
- Vorbereitung
- Vorspann
- Previews
- Prozessdefinierung
- Verarbeitung
- produziert
- Projekt
- immobilien
- vorausgesetzt
- Versorger
- Anbieter
- bietet
- Publikationen
- veröffentlichen
- veröffentlicht
- Zweck
- Zwecke
- Qualität
- Zitate
- wirklich
- vernünftig
- Rezept
- Rezepte
- Veteran
- reflektieren
- Region
- Registrieren
- relevant
- entfernen
- ersetzen
- angefordert
- falls angefordert
- Anforderung
- beziehungsweise
- REST
- Folge
- Die Ergebnisse
- Wiederverwendung
- Überprüfen
- Rollen
- Führen Sie
- läuft
- gleich
- Speichern
- Skalieren
- Skalierung
- Suche
- Zweite
- Abschnitt
- sehen
- Sehen
- ausgewählt
- getrennte
- Lösungen
- Sitzung
- kompensieren
- Einstellungen
- sollte
- zeigte
- gezeigt
- Schild
- signifikant
- Einfacher
- Single
- Größe
- klein
- So
- bis jetzt
- Software
- Lösung
- Lösungen
- einige
- Quelle
- Quellen
- Raumfahrt
- Spark
- besondere
- spezifisch
- angegeben
- SQL
- Anfang
- Beginnen Sie
- Bundesstaat
- Erklärung
- Statistiken
- Schritt
- Shritte
- Lagerung
- speichern
- einfach
- Schnur
- Studio Adressen
- Folge
- Erfolg haben
- so
- geeignet
- ZUSAMMENFASSUNG
- sicher
- synthetisch
- Tabelle
- Nehmen
- Target
- und Aufgaben
- Team
- getestet
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- Der Staat
- Sie
- dann
- Dort.
- fehlen uns die Worte.
- nach drei
- Zeit
- zu
- heute
- Werkzeug
- Werkzeuge
- Top
- verfolgen sind
- Transformieren
- Transformation
- Transformationen
- Reise
- XNUMX
- tippe
- ui
- für
- verstehen
- Aktualisierung
- aktualisiert
- URL
- verwendbar
- -
- Anwendungsfall
- benutzt
- Nutzer
- verwendet
- Verwendung von
- BESTÄTIGEN
- Wert
- Werte
- überprüfen
- Version
- Anzeigen
- sichtbar
- wollen
- wurde
- Wege
- we
- Netz
- Web-Services
- GUT
- waren
- wann
- welche
- werden wir
- mit
- ohne
- Arbeiten
- Arbeiter
- Arbeiter
- Arbeitsablauf.
- würde
- schreiben
- Schreiben
- U
- Ihr
- Zephyrnet
- PLZ