Automatisierte Datenanalyse (ADA) auf AWS ist eine AWS-Lösung, die es Ihnen ermöglicht, über eine einfache und intuitive Benutzeroberfläche in wenigen Minuten aussagekräftige Erkenntnisse aus Daten abzuleiten. ADA bietet eine AWS-native Datenanalyseplattform, die von Datenanalysten sofort für eine Vielzahl von Anwendungsfällen verwendet werden kann. Mit ADA können Teams verschiedene Datensätze aus einer Reihe von Datenquellen erfassen, transformieren, verwalten und abfragen, ohne dass spezielle technische Kenntnisse erforderlich sind. ADA bietet eine Reihe von vorgefertigte Steckverbinder um Daten aus einer Vielzahl von Quellen aufzunehmen, einschließlich Amazon Simple Storage-Service (Amazon S3), Amazon Kinesis-Datenströme, Amazon CloudWatch, Amazon CloudTrail und Amazon DynamoDB sowie viele andere.
ADA bietet eine grundlegende Plattform, die von Datenanalysten in einer Vielzahl von Anwendungsfällen verwendet werden kann, darunter IT, Finanzen, Marketing, Vertrieb und Sicherheit. Der sofort einsatzbereite CloudWatch-Datenkonnektor von ADA ermöglicht die Datenaufnahme aus CloudWatch-Protokollen im selben AWS-Konto, in dem ADA bereitgestellt wurde, oder von einem anderen AWS-Konto.
In diesem Beitrag zeigen wir, wie ein Anwendungsentwickler oder Anwendungstester ADA nutzen kann, um betriebliche Erkenntnisse über in AWS ausgeführte Anwendungen abzuleiten. Wir zeigen auch, wie Sie mit der ADA-Lösung eine Verbindung zu verschiedenen Datenquellen in AWS herstellen können. Wir zuerst Bereitstellung der ADA-Lösung in ein AWS-Konto und Richten Sie die ADA-Lösung ein durch schaffen Datenprodukte Verwendung von Datenkonnektoren. Anschließend verwenden wir die ADA Query Workbench, um die einzelnen Datensätze zu verbinden und die korrelierten Daten mithilfe der vertrauten Structured Query Language (SQL) abzufragen, um Erkenntnisse zu gewinnen. Wir zeigen auch, wie ADA in Business-Intelligence-Tools (BI) wie Tableau integriert werden kann, um die Daten zu visualisieren und Berichte zu erstellen.
Lösungsüberblick
In diesem Abschnitt stellen wir die Lösungsarchitektur für die Demo vor und erläutern den Workflow. Zu Demonstrationszwecken wird die maßgeschneiderte Anwendung mit einem simuliert AWS Lambda Funktion, die Anmeldungen ausgibt Apache-Protokollformat in einem voreingestellten Intervall mit Amazon EventBridge. Dieses Standardformat kann von vielen verschiedenen Webservern erstellt und von vielen Protokollanalyseprogrammen gelesen werden. Die Anwendungsprotokolle (Lambda-Funktion) werden an eine CloudWatch-Protokollgruppe gesendet. Die historischen Anwendungsprotokolle werden zu Referenz- und Abfragezwecken in einem S3-Bucket gespeichert. Eine Nachschlagetabelle mit einer Liste von HTTP-Status-Codes zusammen mit den Beschreibungen wird in einer DynamoDB-Tabelle gespeichert. Diese drei dienen als Quellen, aus denen Daten zur Korrelation, Abfrage und Analyse in ADA aufgenommen werden. Wir Bereitstellung der ADA-Lösung in ein AWS-Konto und ADA einrichten. Wir erstellen dann die Datenprodukte innerhalb der ADA für die CloudWatch-Protokollgruppe, S3-Eimer und DynamoDB. Während die Datenprodukte konfiguriert werden, stellt ADA Datenpipelines bereit, um die Daten aus den Quellen aufzunehmen. Mit der ADA Query Workbench können Sie die erfassten Daten mithilfe von reinem SQL zur Fehlerbehebung bei Anwendungen oder zur Problemdiagnose abfragen.
Das folgende Diagramm bietet einen Überblick über die Architektur und den Workflow der Verwendung von ADA, um Einblicke in Anwendungsprotokolle zu gewinnen.
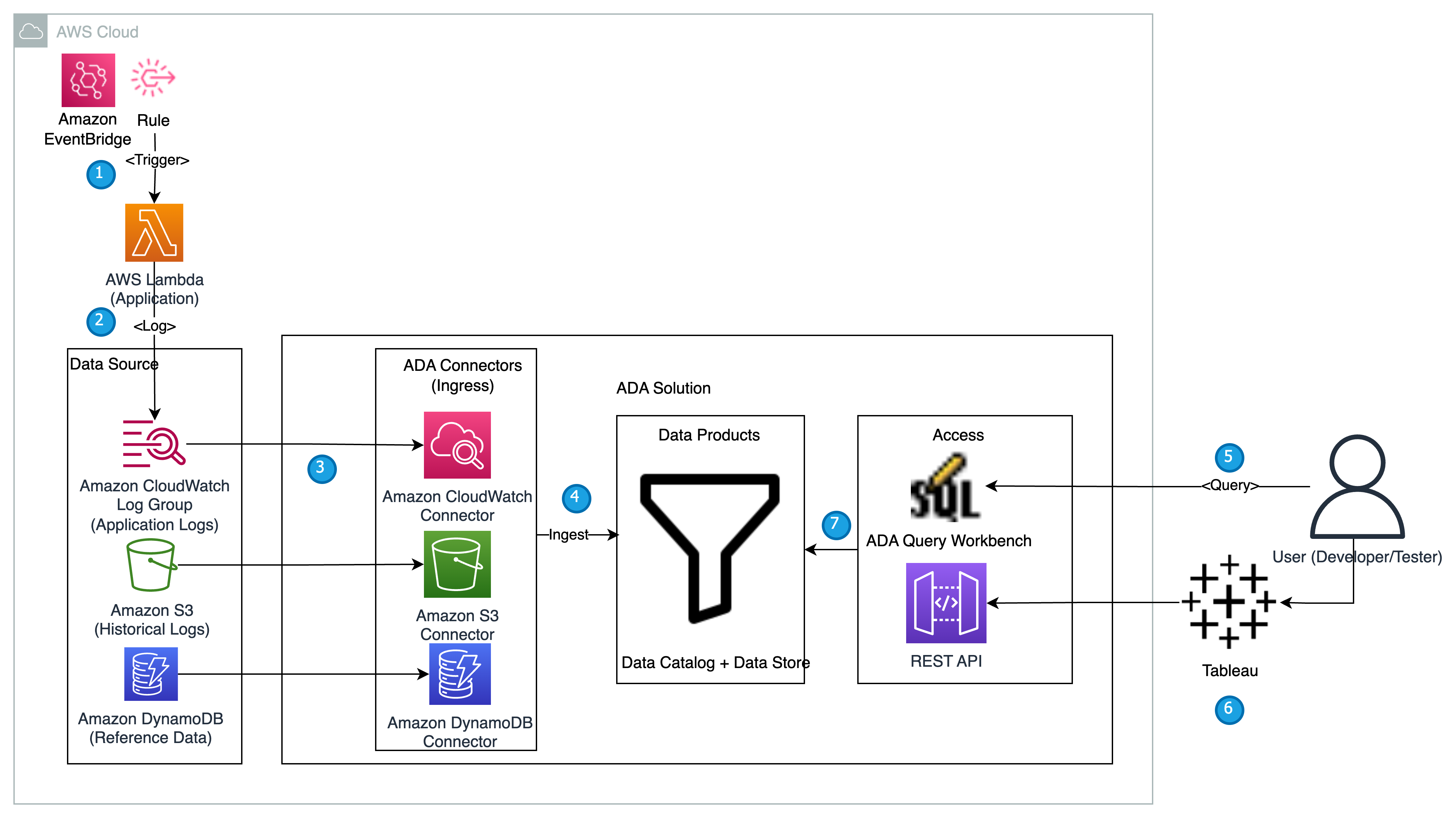
Der Workflow umfasst die folgenden Schritte:
- Eine Lambda-Funktion soll mithilfe von EventBridge in 2-Minuten-Intervallen ausgelöst werden.
- Die Lambda-Funktion gibt Protokolle aus, die in einer angegebenen CloudWatch-Protokollgruppe unter gespeichert werden
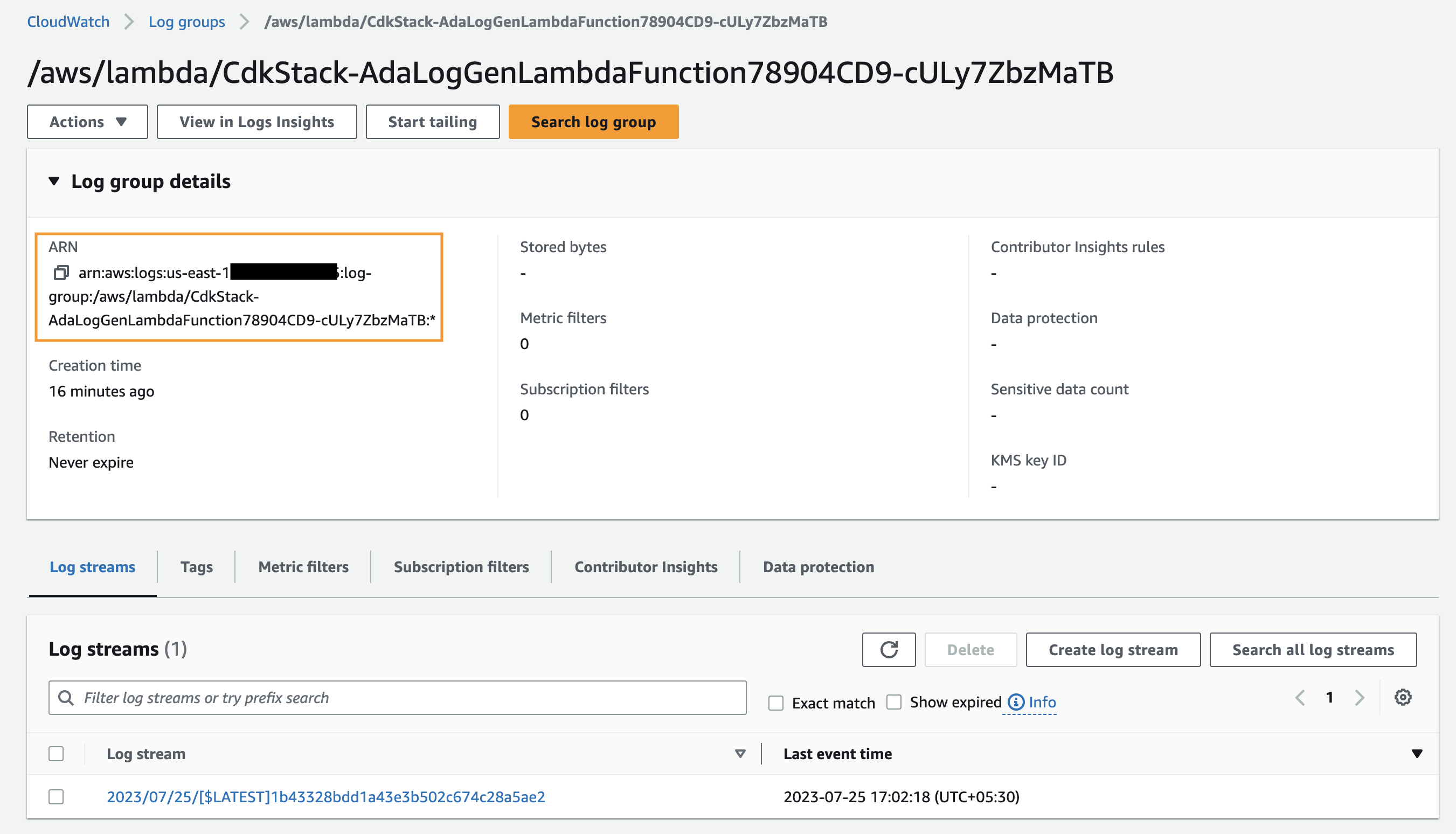
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Die Anwendungsprotokolle werden mithilfe des Apache Log Format-Schemas generiert, aber in der CloudWatch-Protokollgruppe im JSON-Format gespeichert. - Die Datenprodukte für CloudWatch, Amazon S3 und DynamoDB werden in ADA erstellt. Das CloudWatch-Datenprodukt stellt eine Verbindung zur CloudWatch-Protokollgruppe her, in der die Anwendungsprotokolle (Lambda-Funktion) gespeichert werden. Der Amazon S3-Connector stellt eine Verbindung zu einem S3-Bucket-Ordner her, in dem die historischen Protokolle gespeichert werden. Der DynamoDB-Connector stellt eine Verbindung zu einer DynamoDB-Tabelle her, in der die von der Anwendung angegebenen Statuscodes und historischen Protokolle gespeichert werden.
- Für jedes Datenprodukt stellt ADA die Datenpipeline-Infrastruktur bereit, um Daten aus den Quellen aufzunehmen. Wenn die Datenaufnahme abgeschlossen ist, können Sie Abfragen mit SQL über die ADA Query Workbench schreiben.
- Sie können sich beim ADA-Portal anmelden und SQL-Abfragen über die Query Workbench verfassen, um Einblicke in die Anwendungsprotokolle zu erhalten. Sie können die Abfrage optional speichern und mit anderen ADA-Benutzern in derselben Domäne teilen. Die ADA-Abfragefunktion wird unterstützt von Amazonas Athena, ein serverloser, interaktiver Analysedienst, der eine vereinfachte und flexible Möglichkeit zur Analyse von Petabytes an Daten bietet.
- Tableau ist für den Zugriff auf die ADA-Datenprodukte über ADA-Ausgangsendpunkte konfiguriert. Anschließend erstellen Sie ein Dashboard mit zwei Diagrammen. Das erste Diagramm ist eine Heatmap, die die Prävalenz von HTTP-Fehlercodes im Zusammenhang mit den Anwendungs-API-Endpunkten zeigt. Das zweite Diagramm ist ein Balkendiagramm, das die zehn wichtigsten Anwendungs-APIs mit der Gesamtzahl der HTTP-Fehlercodes aus den historischen Daten zeigt.
Voraussetzungen:
Für diesen Beitrag müssen Sie die folgenden Voraussetzungen erfüllen:
- Installieren Sie das AWS-Befehlszeilenschnittstelle (AWS-CLI), AWS Cloud-Entwicklungskit (AWS-CDK) Voraussetzungen, TypeScript-spezifisch Voraussetzungen und git.
- Deploy die ADA-Lösung in Ihrem AWS-Konto im
us-east-1Region.- Geben Sie beim Starten des ADA eine Administrator-E-Mail-Adresse an AWS CloudFormation Stapel. Dies ist erforderlich, damit ADA das Root-Benutzerkennwort senden kann. Wenn die Multi-Faktor-Authentifizierung (MFA) aktiviert ist, ist eine Administrator-Telefonnummer erforderlich, um eine Einmalpasswortnachricht zu erhalten. Für diese Demo ist MFA nicht aktiviert.
- Erstellen Sie die Beispielanwendung und stellen Sie sie bereit (verfügbar unter GitHub Repo)-Lösung, damit die folgenden Ressourcen in Ihrem Konto bereitgestellt werden können
us-east-1Region:- Eine Lambda-Funktion, die die Protokollierungsanwendung simuliert, und eine EventBridge-Regel, die die Anwendungsfunktion in 2-Minuten-Intervallen aufruft.
- Ein S3-Bucket mit den relevanten Bucket-Richtlinien und einer CSV-Datei, die die historischen Anwendungsprotokolle enthält.
- Eine DynamoDB-Tabelle mit den Suchdaten.
- Relevant AWS Identity and Access Management and (IAM) Rollen und Berechtigungen, die für die Dienste erforderlich sind.
- Optional installieren Tableau Desktop, ein BI-Drittanbieter. Für diesen Beitrag verwenden wir Tableau Desktop Version 2021.2. Die Verwendung einer lizenzierten Version der Tableau Desktop-Anwendung ist mit Kosten verbunden. Weitere Einzelheiten finden Sie im Tableau-Lizenzierung Informationen.
Stellen Sie ADA bereit und richten Sie es ein
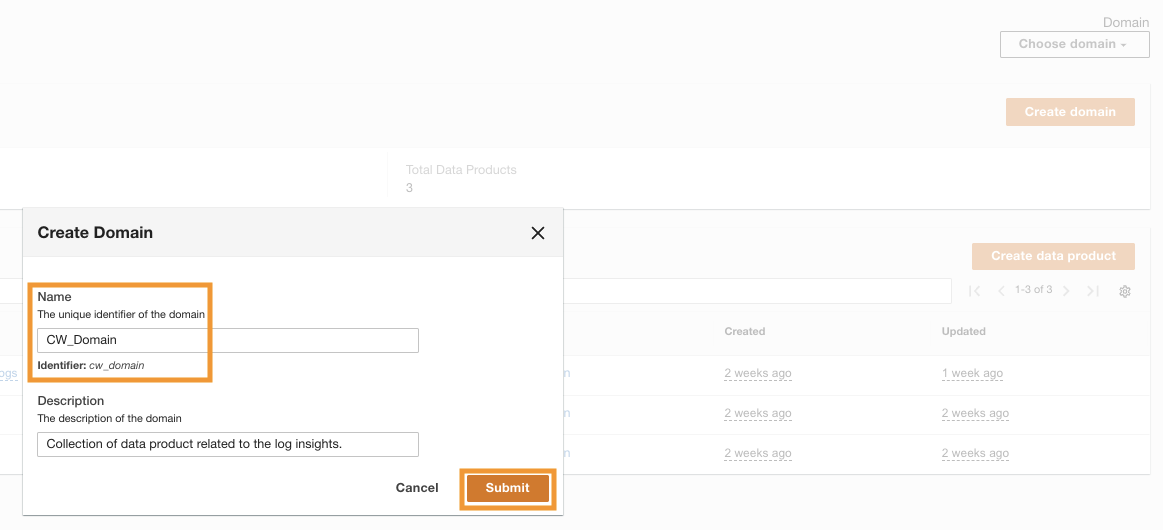
Nachdem ADA erfolgreich bereitgestellt wurde, können Sie es tun Einloggen Verwenden Sie dazu die bei der Installation angegebene Administrator-E-Mail. Anschließend erstellen Sie eine Domain namens CW_Domain. Eine Domäne ist eine benutzerdefinierte Sammlung von Datenprodukten. Eine Domäne könnte beispielsweise ein Team oder ein Projekt sein. Domänen bieten Benutzern eine strukturierte Möglichkeit, ihre Datenprodukte zu organisieren und Zugriffsberechtigungen zu verwalten.
- Wählen Sie auf der ADA-Konsole Domains im Navigationsbereich.
- Auswählen Domäne erstellen.
- Geben Sie einen Namen ein (
CW_Domain) und Beschreibung, dann wählen Sie Absenden.
Richten Sie die Beispielanwendungsinfrastruktur mit AWS CDK ein
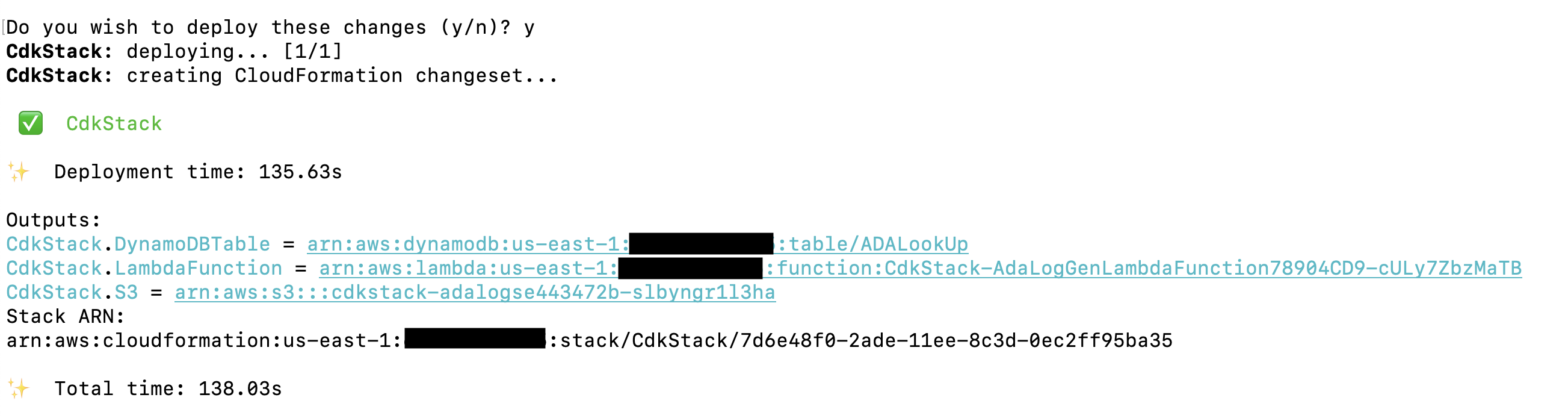
Die AWS CDK-Lösung, die die Demoanwendung bereitstellt, wird auf gehostet GitHub. Die Schritte zum Klonen des Repos und zum Einrichten des AWS CDK-Projekts werden in diesem Abschnitt detailliert beschrieben. Stellen Sie sicher, dass Sie diese Befehle ausführen, bevor Sie sie ausführen konfigurieren Ihre AWS-Anmeldeinformationen. Erstellen Sie einen Ordner, öffnen Sie das Terminal und navigieren Sie zu dem Ordner, in dem die AWS CDK-Lösung installiert werden muss. Führen Sie den folgenden Code aus:
Diese Schritte führen die folgenden Aktionen aus:
- Installieren Sie die Bibliotheksabhängigkeiten
- Erstellen Sie das Projekt
- Generieren Sie eine gültige CloudFormation-Vorlage
- Stellen Sie den Stack mit AWS CloudFormation in Ihrem AWS-Konto bereit
Die Bereitstellung dauert etwa 1–2 Minuten und erstellt die DynamoDB-Nachschlagetabelle, die Lambda-Funktion und den S3-Bucket, der die historischen Protokolldateien als Ausgaben enthält. Kopieren Sie diese Werte in eine Textbearbeitungsanwendung, z. B. Notepad.
Erstellen Sie ADA-Datenprodukte
Für diese Demo erstellen wir drei verschiedene Datenprodukte, eines für jede Datenquelle, die Sie abfragen, um betriebliche Erkenntnisse zu gewinnen. Ein Datenprodukt ist ein Datensatz (eine Sammlung von Daten wie eine Tabelle oder eine CSV-Datei), der erfolgreich in ADA importiert wurde und abgefragt werden kann.
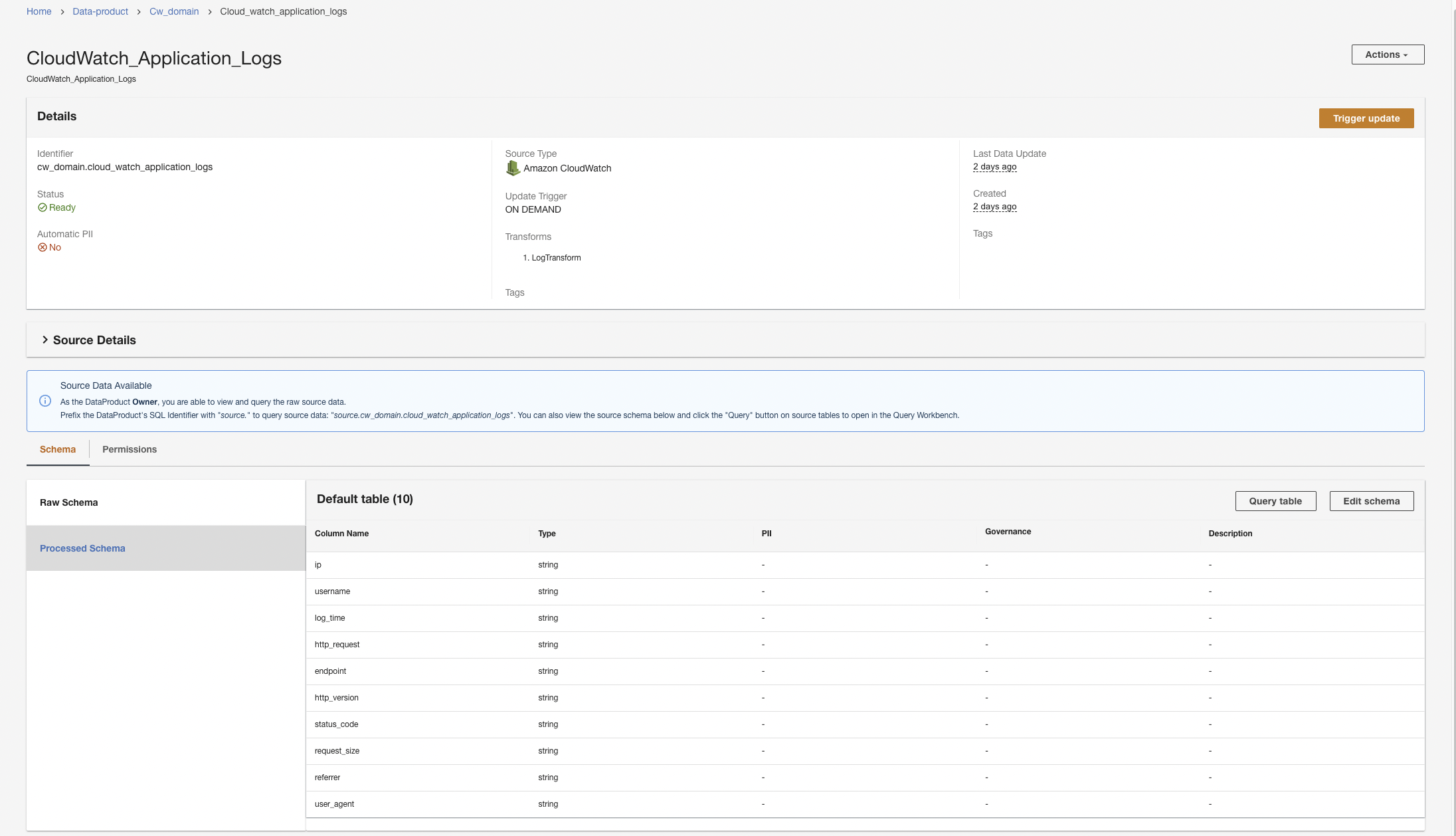
Erstellen Sie ein CloudWatch-Datenprodukt
Zuerst erstellen wir ein Datenprodukt für die Anwendungsprotokolle, indem wir ADA so einrichten, dass es die CloudWatch-Protokollgruppe für die Beispielanwendung aufnimmt (Lambda-Funktion). Benutzen Sie die CdkStack.LambdaFunction Ausgabe, um den Lambda-Funktions-ARN abzurufen und den entsprechenden CloudWatch-Protokollgruppen-ARN auf der CloudWatch-Konsole zu finden.
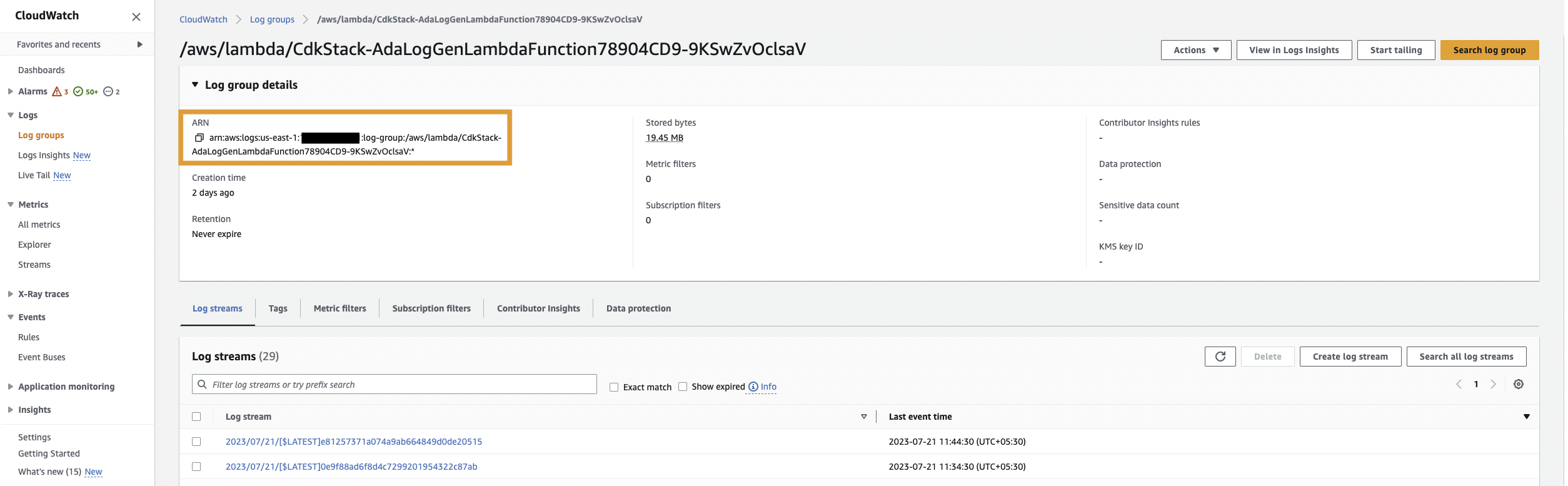
Führen Sie dann die folgenden Schritte aus:
- Navigieren Sie in der ADA-Konsole zur ADA-Domäne und erstellen Sie ein CloudWatch-Datenprodukt.
- Aussichten für Name und VornameGeben Sie einen Namen ein.
- Aussichten für Quelle Typ, wählen Amazon CloudWatch.
- Deaktivieren Automatische PII.
ADA verfügt über eine Funktion, die beim Import automatisch personenbezogene Daten (PII) erkennt und standardmäßig aktiviert ist. Für diese Demo deaktivieren wir diese Option für das Datenprodukt, da die Erkennung von PII-Daten nicht Gegenstand dieser Demo ist.
- Auswählen
Weiter.
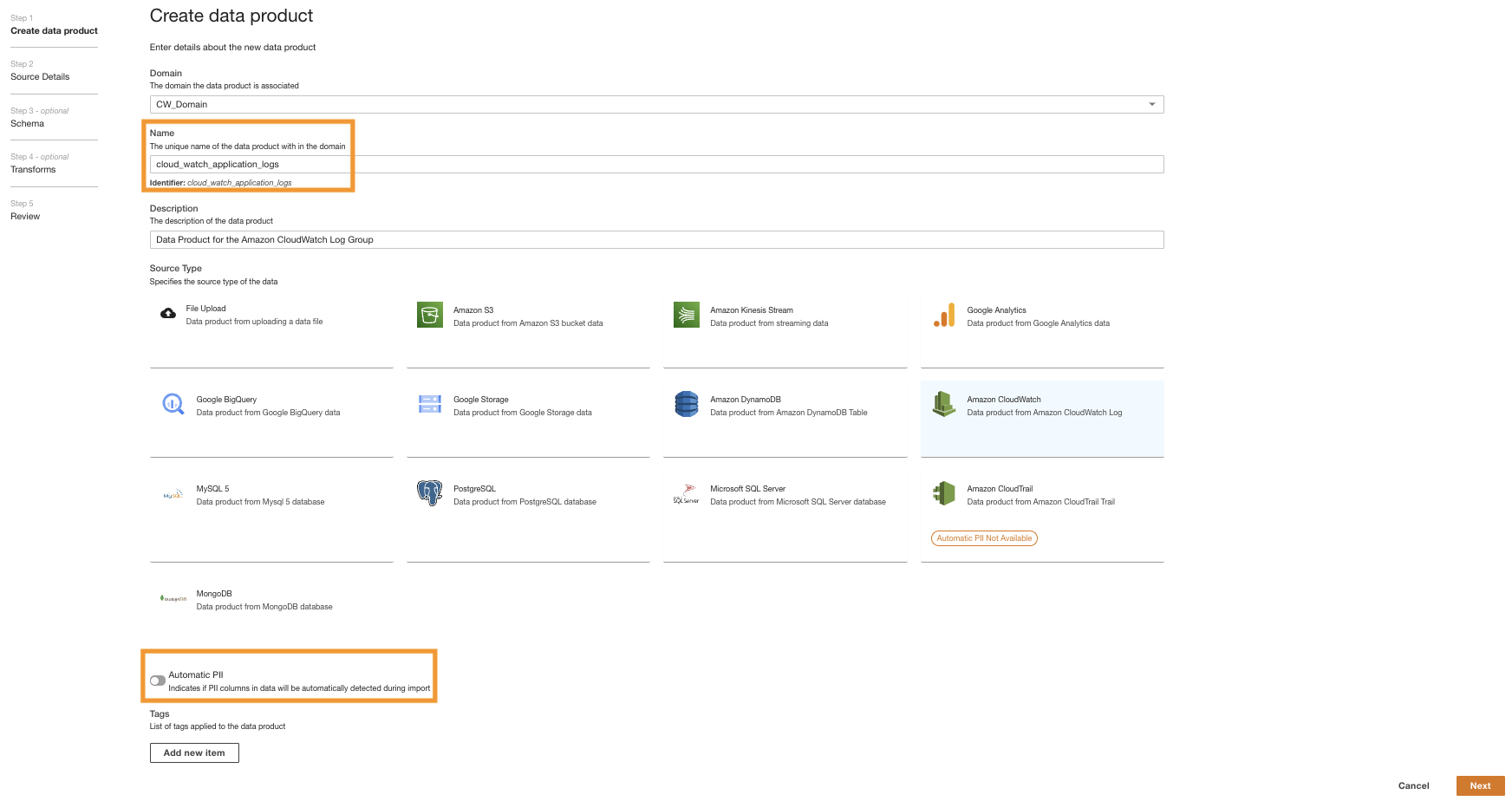
- Suchen Sie nach dem aus dem vorherigen Schritt kopierten CloudWatch-Protokollgruppen-ARN und wählen Sie ihn aus.

- Kopieren Sie den Protokollgruppen-ARN.
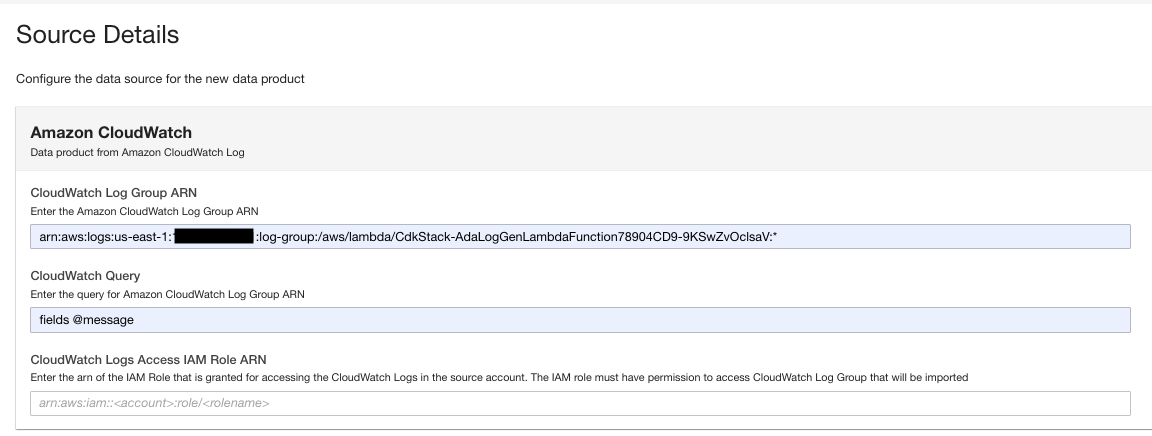
- Geben Sie auf der Datenproduktseite den Protokollgruppen-ARN ein.
- Aussichten für CloudWatch-AbfrageGeben Sie eine Abfrage ein, die ADA von der Protokollgruppe erhalten soll.
In dieser Demo fragen wir das Feld „@message“ ab, da wir daran interessiert sind, die Anwendungsprotokolle von der Protokollgruppe abzurufen.
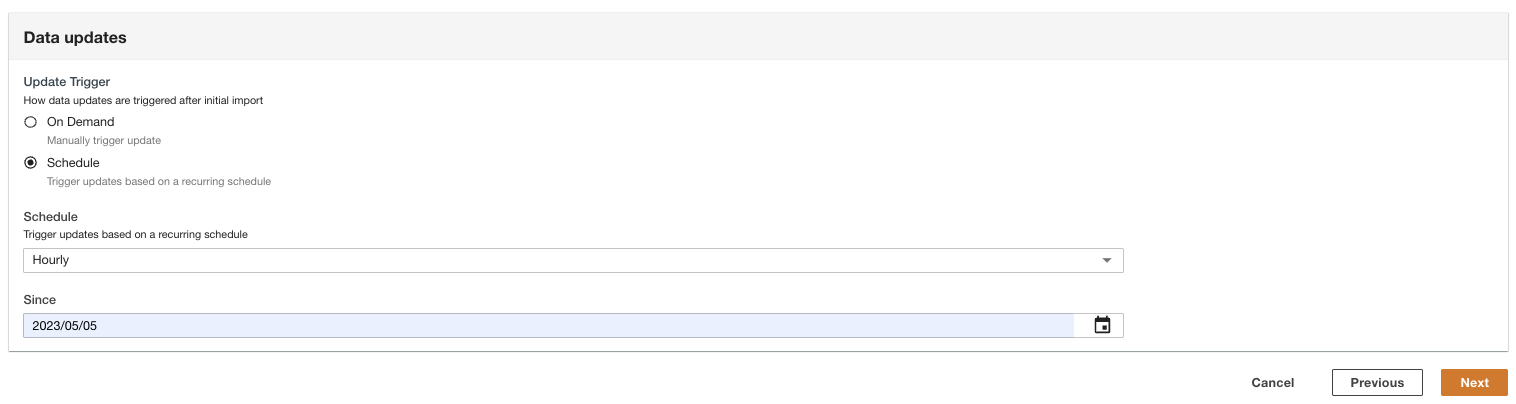
- Wählen Sie aus, wie die Datenaktualisierungen nach dem ersten Import ausgelöst werden.
ADA kann so konfiguriert werden, dass die Daten in flexiblen Intervallen (bis zu 15 Minuten oder später) oder bei Bedarf von der Quelle aufgenommen werden. Für die Demo stellen wir die Datenaktualisierungen so ein, dass sie stündlich ausgeführt werden.
- Auswählen Weiter.
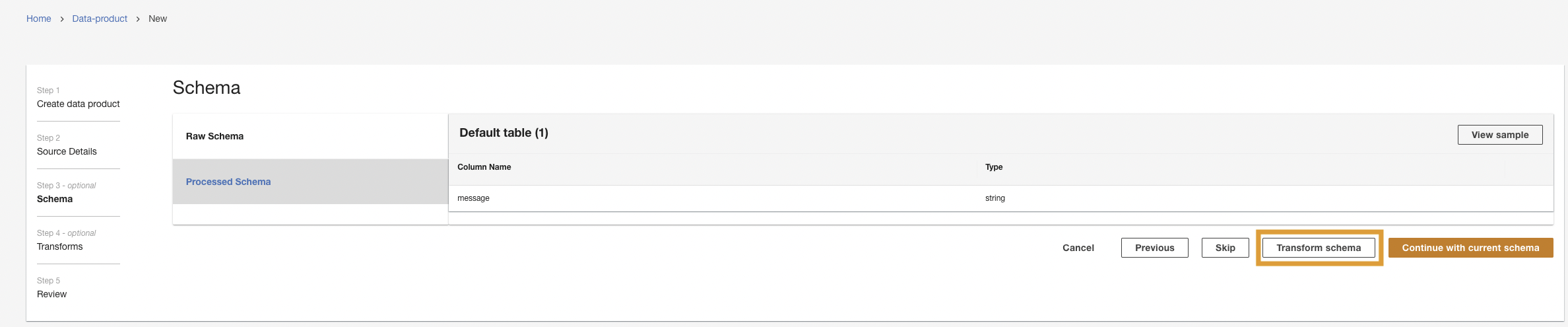
Als nächstes stellt ADA eine Verbindung zur Protokollgruppe her und fragt das Schema ab. Da die Protokolle im Apache-Protokollformat vorliegen, wandeln wir die Protokolle in separate Felder um, damit wir Abfragen für die spezifischen Protokollfelder ausführen können. ADA bietet vier Standard Transformationen und unterstützt benutzerdefinierte Transformationen über ein Python-Skript. In dieser Demo führen wir ein benutzerdefiniertes Python-Skript aus, um das JSON-Nachrichtenfeld in Felder im Apache-Protokollformat umzuwandeln.
- Auswählen
Schema transformieren.
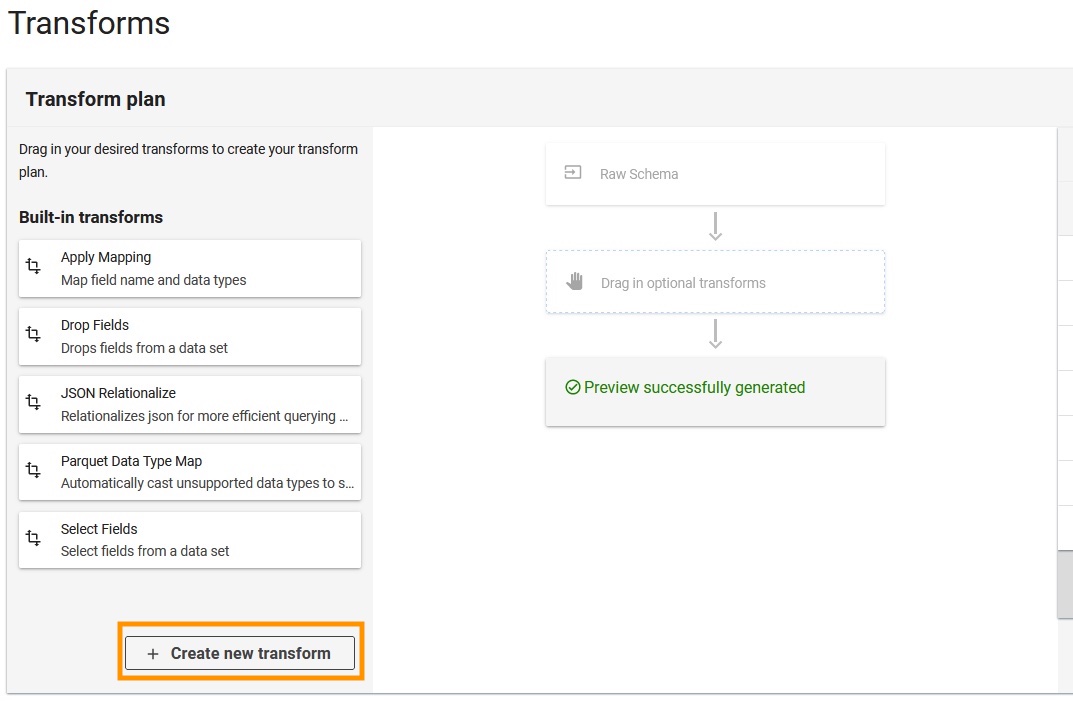
- Auswählen
Erstellen Sie eine neue Transformation.
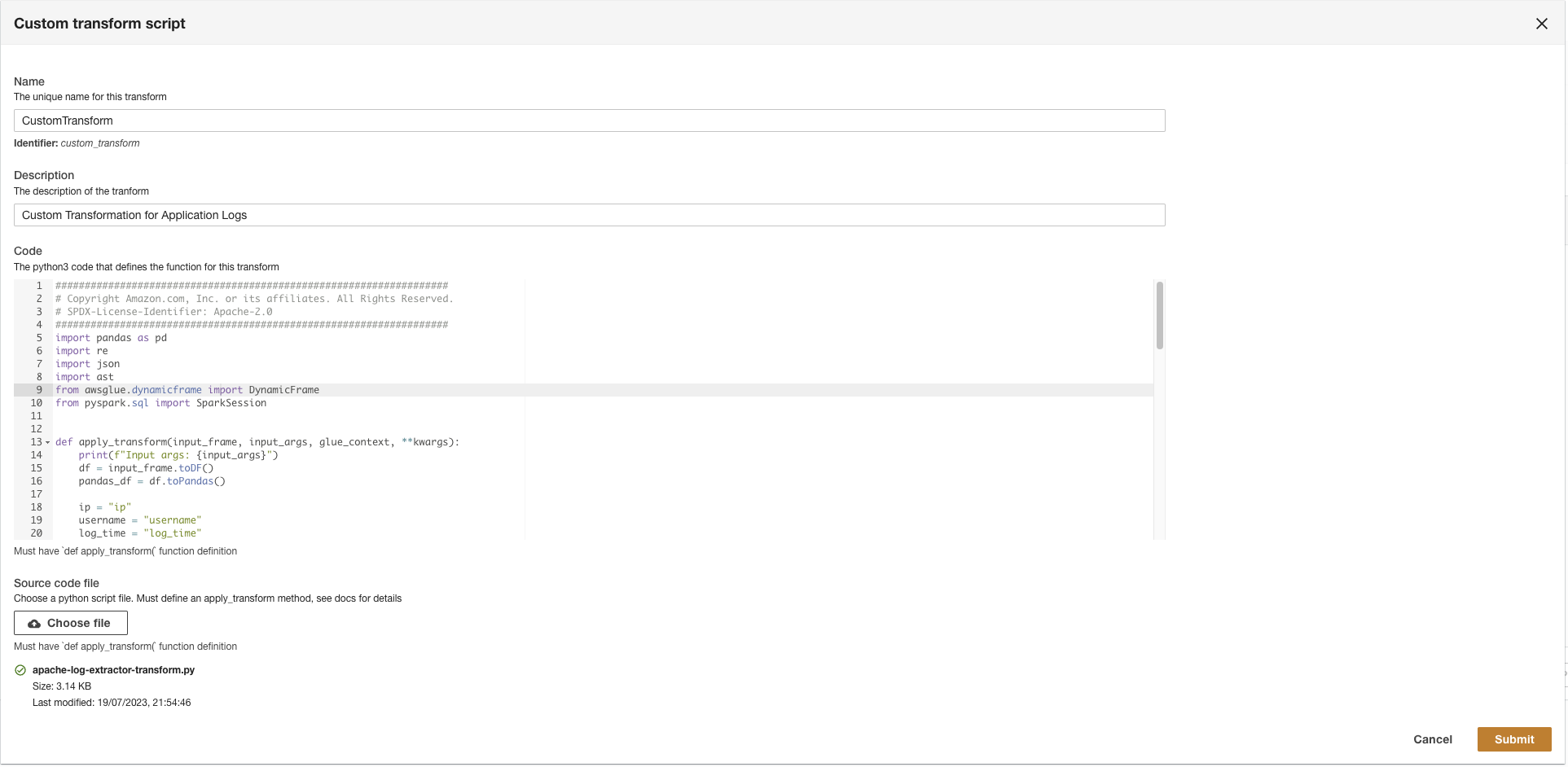
- Laden Sie die
apache-log-extractor-transform.pyDrehbuch aus dem/asset/transform_logs/-Ordner. - Auswählen
Absenden.
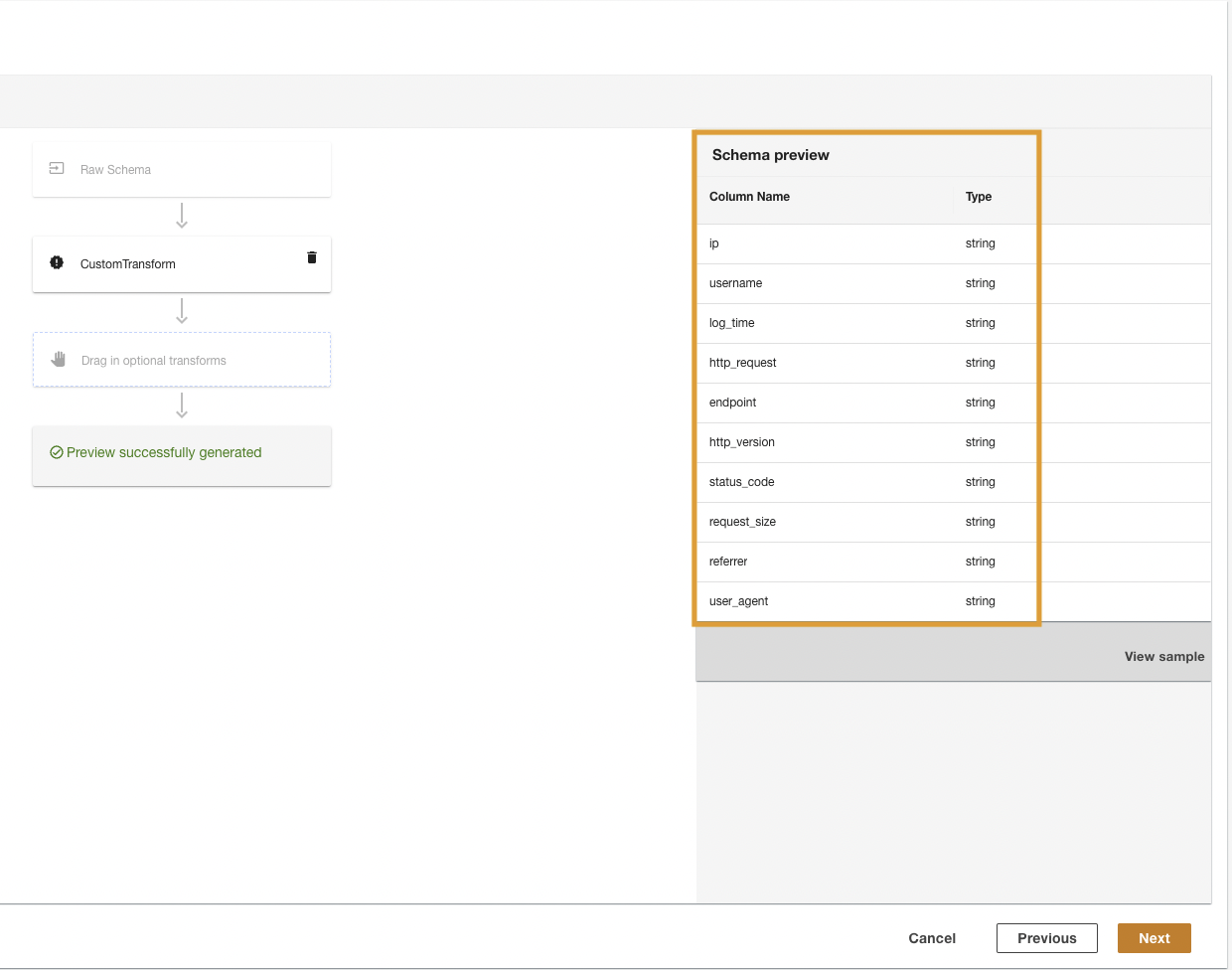
ADA transformiert die CloudWatch-Protokolle mithilfe des Skripts und präsentiert das verarbeitete Schema.
- Auswählen
Weiter.
- Überprüfen Sie im letzten Schritt die Schritte und wählen Sie aus Absenden.
ADA startet die Datenverarbeitung, erstellt die Datenpipelines und bereitet die CloudWatch-Protokollgruppen vor, die von der Query Workbench abgefragt werden sollen. Dieser Vorgang dauert einige Minuten und wird unten auf der ADA-Konsole angezeigt Datenprodukte.
Erstellen Sie ein Amazon S3-Datenprodukt
Wir wiederholen die Schritte, um die historischen Protokolle aus der Amazon S3-Datenquelle hinzuzufügen und Referenzdaten aus der DynamoDB-Tabelle nachzuschlagen. Für diese beiden Datenquellen erstellen wir keine benutzerdefinierten Transformationen, da die Datenformate in CSV (für historische Protokolle) und Schlüsselattributen (für Referenzsuchdaten) vorliegen.
- Erstellen Sie auf der ADA-Konsole ein neues Datenprodukt.
- Geben Sie einen Namen ein (
hist_logs) und wähle Amazon S3.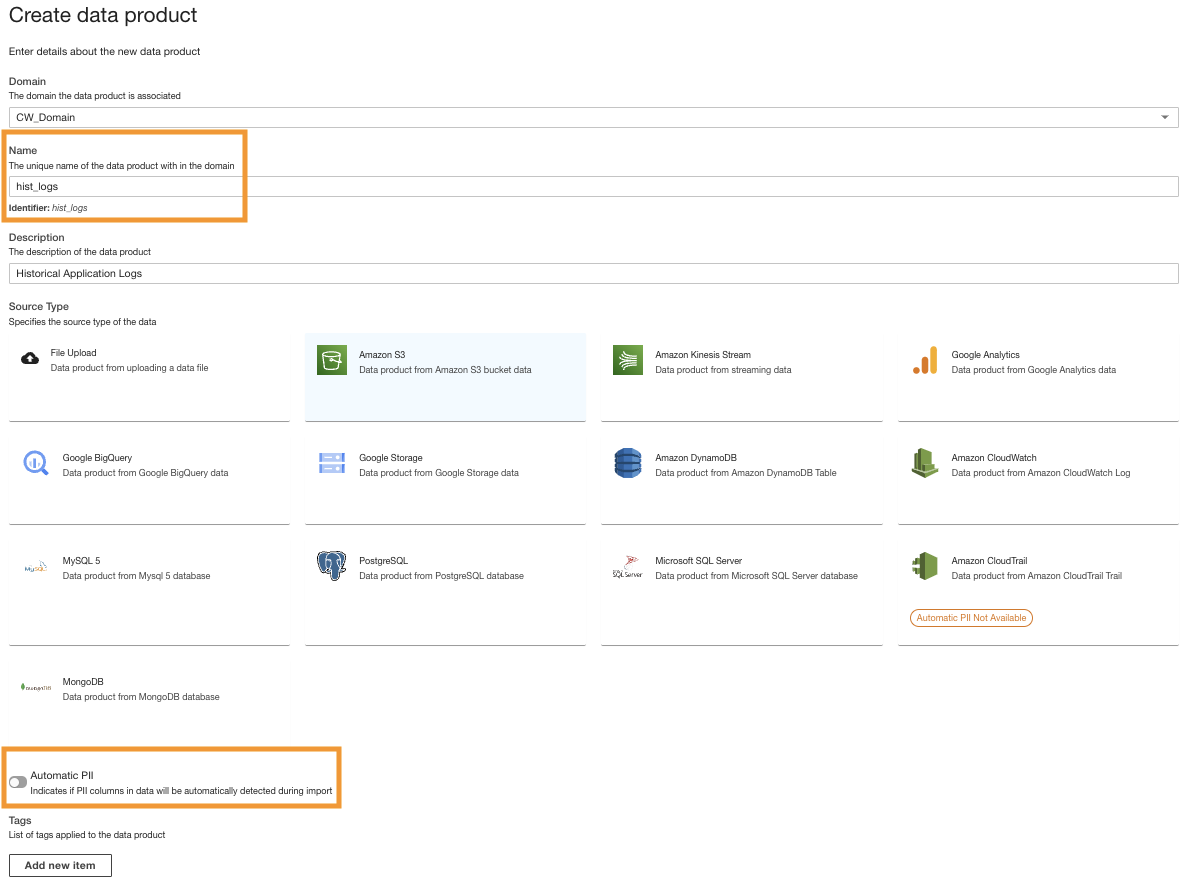
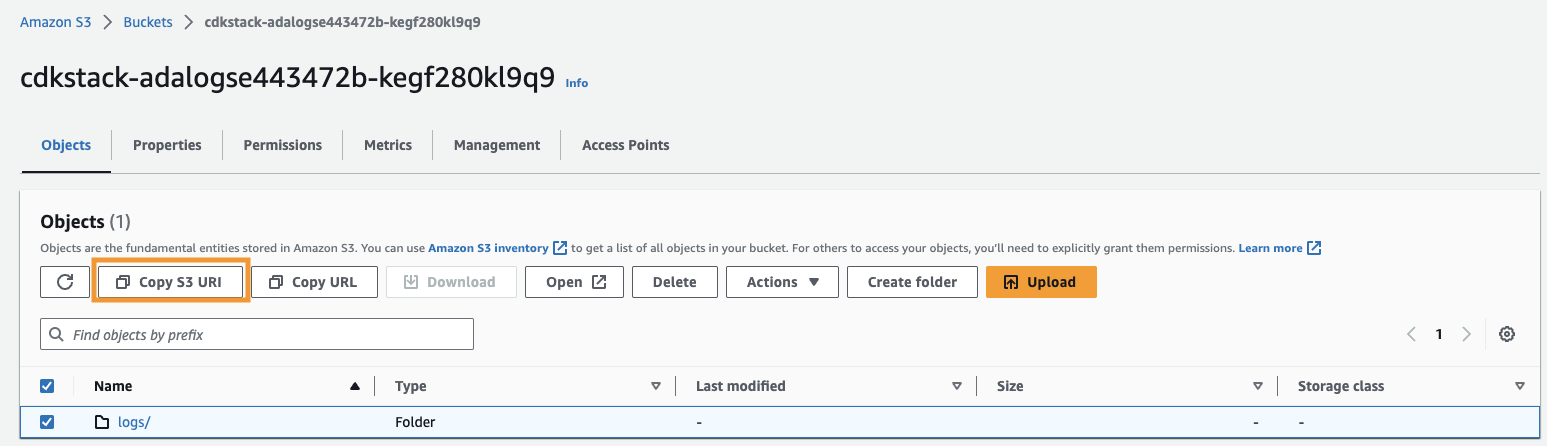
- Kopieren Sie den Amazon S3-URI (den Text danach).
arn:aws:s3:::) Aus demCdkStack.S3Ausgabevariable und navigieren Sie zur Amazon S3-Konsole. - Geben Sie im Suchfeld den kopierten Text ein, öffnen Sie den S3-Bucket und wählen Sie den aus
/logsOrdner und wählen Sie S3-URI kopieren.
Die historischen Protokolle werden in diesem Pfad gespeichert.
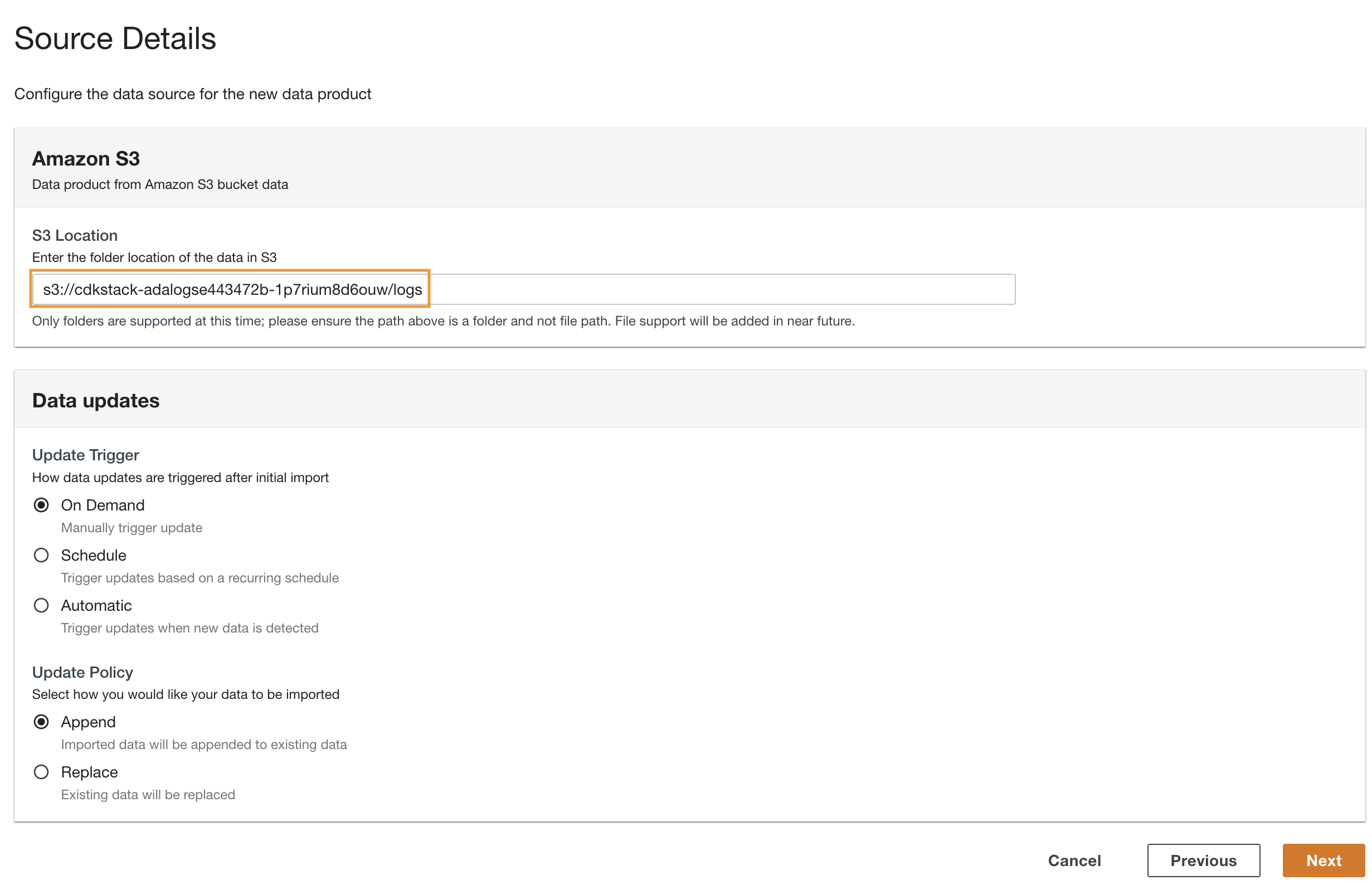
- Navigieren Sie zurück zur ADA-Konsole und geben Sie den kopierten S3-URI für ein S3 Standort.
- Aussichten für Update-TriggerWählen On Demand weil die historischen Protokolle in einer nicht festgelegten Häufigkeit aktualisiert werden.
- Aussichten für Richtlinie aktualisierenWählen Anhängen um neu importierte Daten an die vorhandenen Daten anzuhängen.
- Auswählen Weiter.
ADA verarbeitet das Schema für die Dateien im ausgewählten Ordnerpfad. Da die Protokolle im CSV-Format vorliegen, kann ADA die Spaltennamen lesen, ohne dass zusätzliche Transformationen erforderlich sind. Allerdings sind die Spalten status_code und request_size werden von ADA als langer Typ abgeleitet. Wir möchten die Spaltendatentypen zwischen den Datenprodukten konsistent halten, damit wir die Datentabellen verknüpfen und die Daten abfragen können. Die Kolumne status_code wird verwendet, um Verknüpfungen zwischen den Datentabellen zu erstellen.
- Auswählen Schema transformieren um die Datentypen der beiden Spalten in den Datentyp „String“ zu ändern.
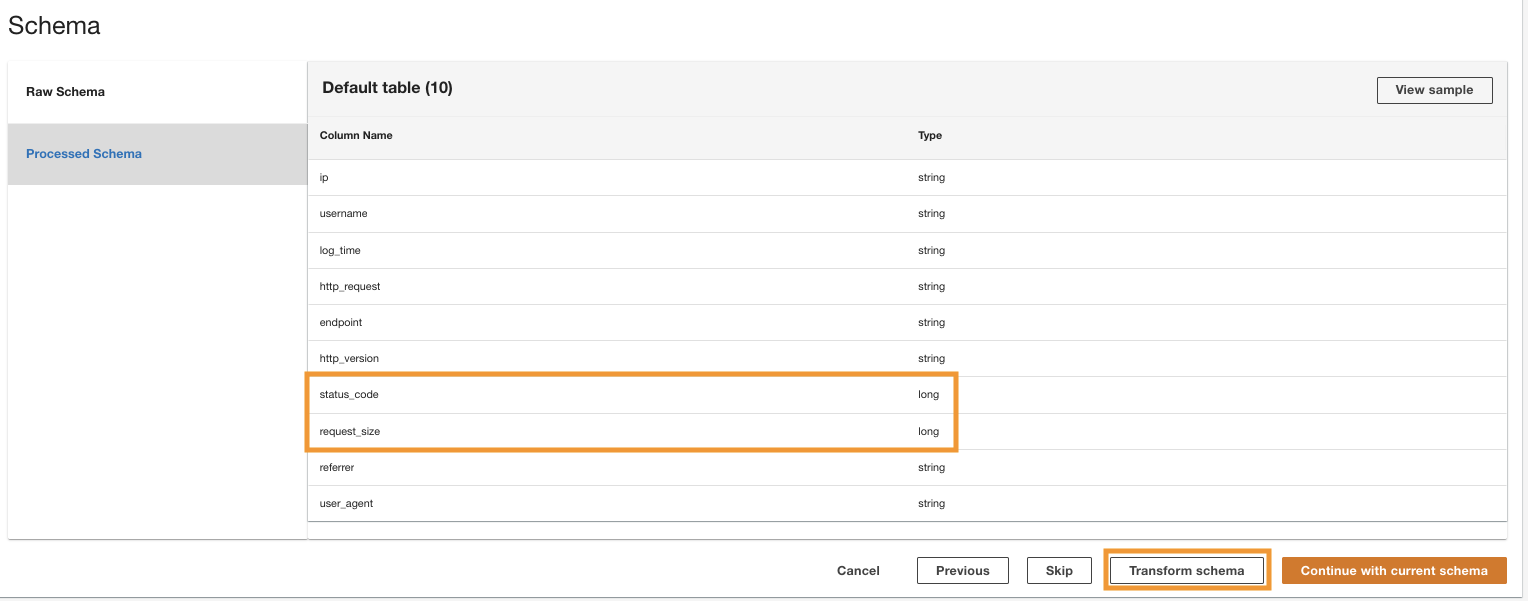
Beachten Sie die hervorgehobenen Spaltennamen im Schemavorschau Bereich, bevor Sie die Datentyptransformationen anwenden.
- Im Transformationsplan Scheibe, unter Integrierte Transformationen, wählen Zuordnung anwenden.
Mit dieser Option können Sie den Datentyp von einem Typ in einen anderen ändern.
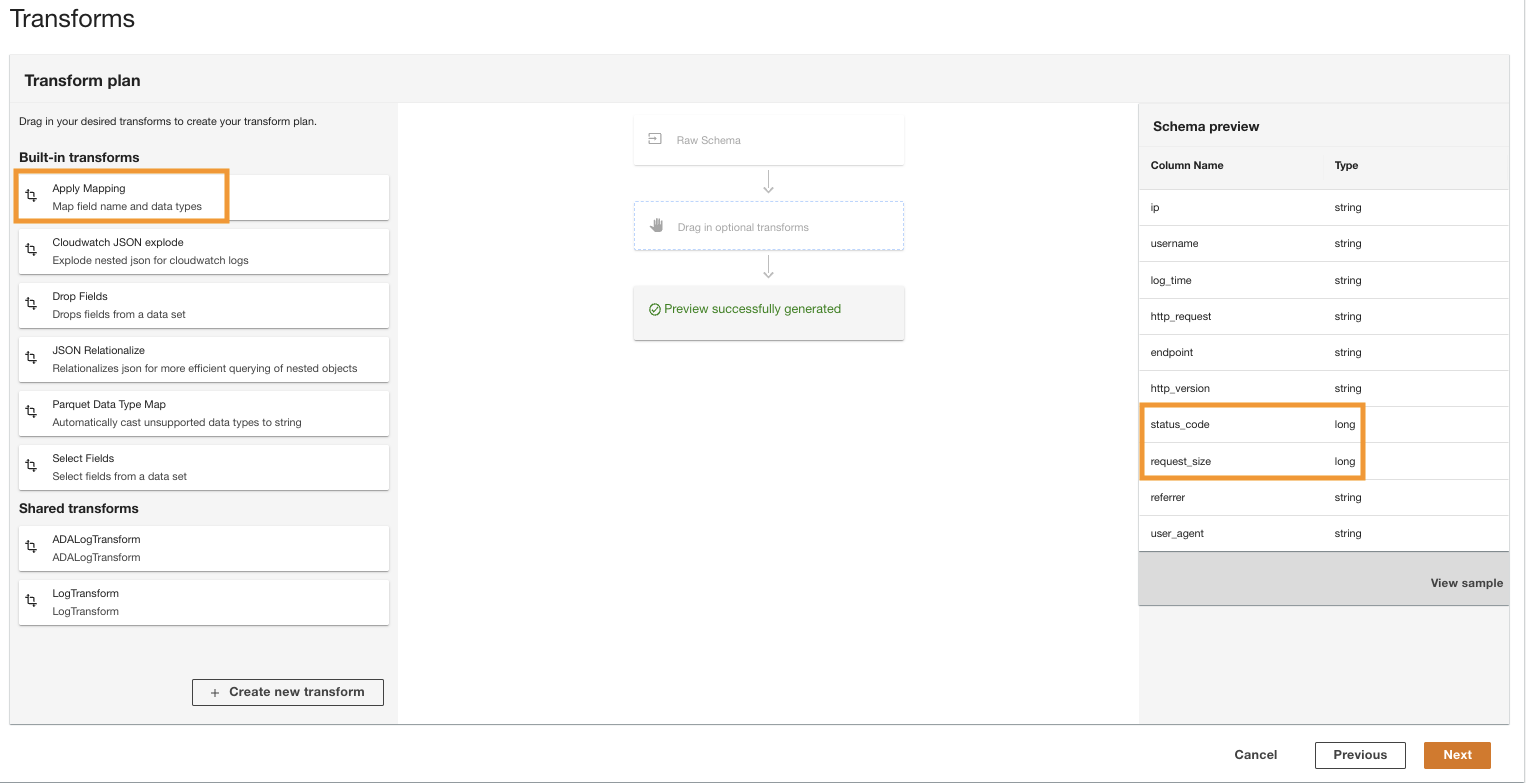
- Im Zuordnung anwenden Abschnitt, abwählen Andere Felder löschen.
Wenn diese Option nicht deaktiviert ist, bleiben nur die transformierten Spalten erhalten und alle anderen Spalten werden gelöscht. Da wir alle Spalten beibehalten möchten, deaktivieren wir diese Option.
- Der Feldzuordnungenzum Alte Bezeichnung und Neuer Name, eingeben
status_codeund für Neuer Typ, eingebenstring.
- Auswählen
Artikel hinzufügen.
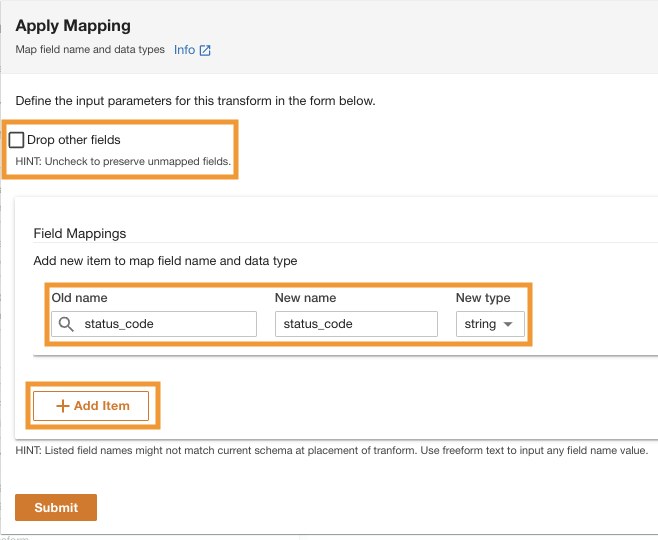
- Aussichten für Alte Bezeichnung und Neuer Name¸ Geben Sie request_size und for ein Neuer Datentyp, Zeichenfolge eingeben.
- Auswählen Absenden.
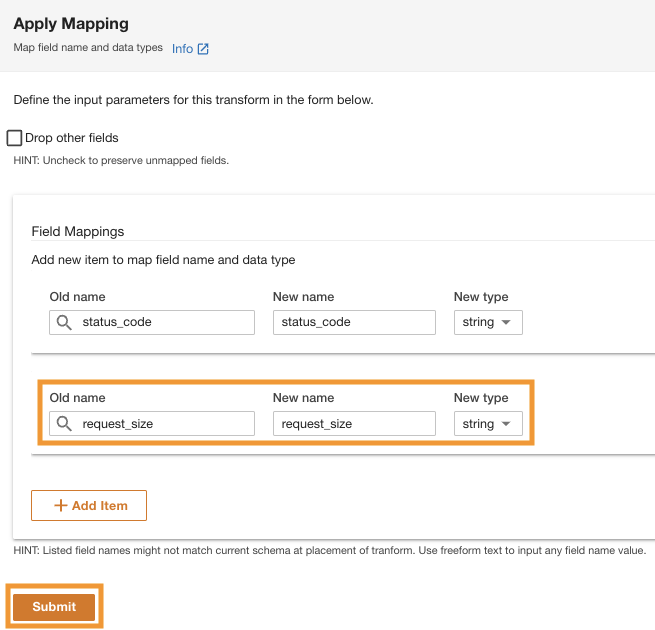
ADA wendet die Zuordnungstransformation auf die Amazon S3-Datenquelle an. Beachten Sie die Spaltentypen in der Schemavorschau Feld.
- Auswählen Beispiel ansehen , um eine Vorschau der Daten mit der angewendeten Transformation anzuzeigen.
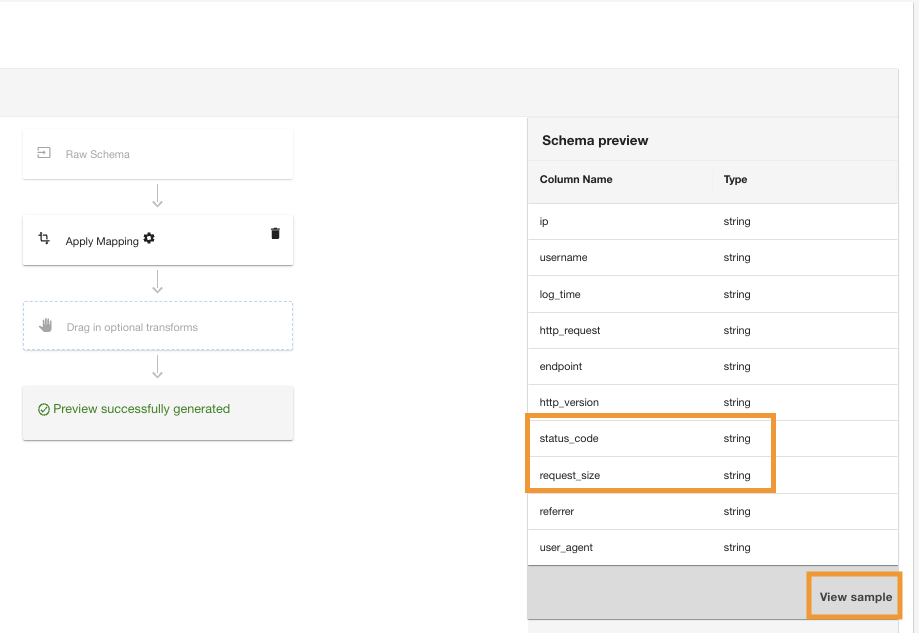
ADA zeigt die PII-Datenbestätigung an, um sicherzustellen, dass entweder nur autorisierte Benutzer die Daten anzeigen können oder dass der Datensatz keine PII-Daten enthält.
- Auswählen zustimmen , um die Beispieldaten weiterhin anzuzeigen.
Beachten Sie, dass das Schema mit dem CloudWatch-Protokollgruppenschema identisch ist, da sowohl die aktuelle Anwendung als auch die historischen Anwendungsprotokolle im Apache-Protokollformat vorliegen.
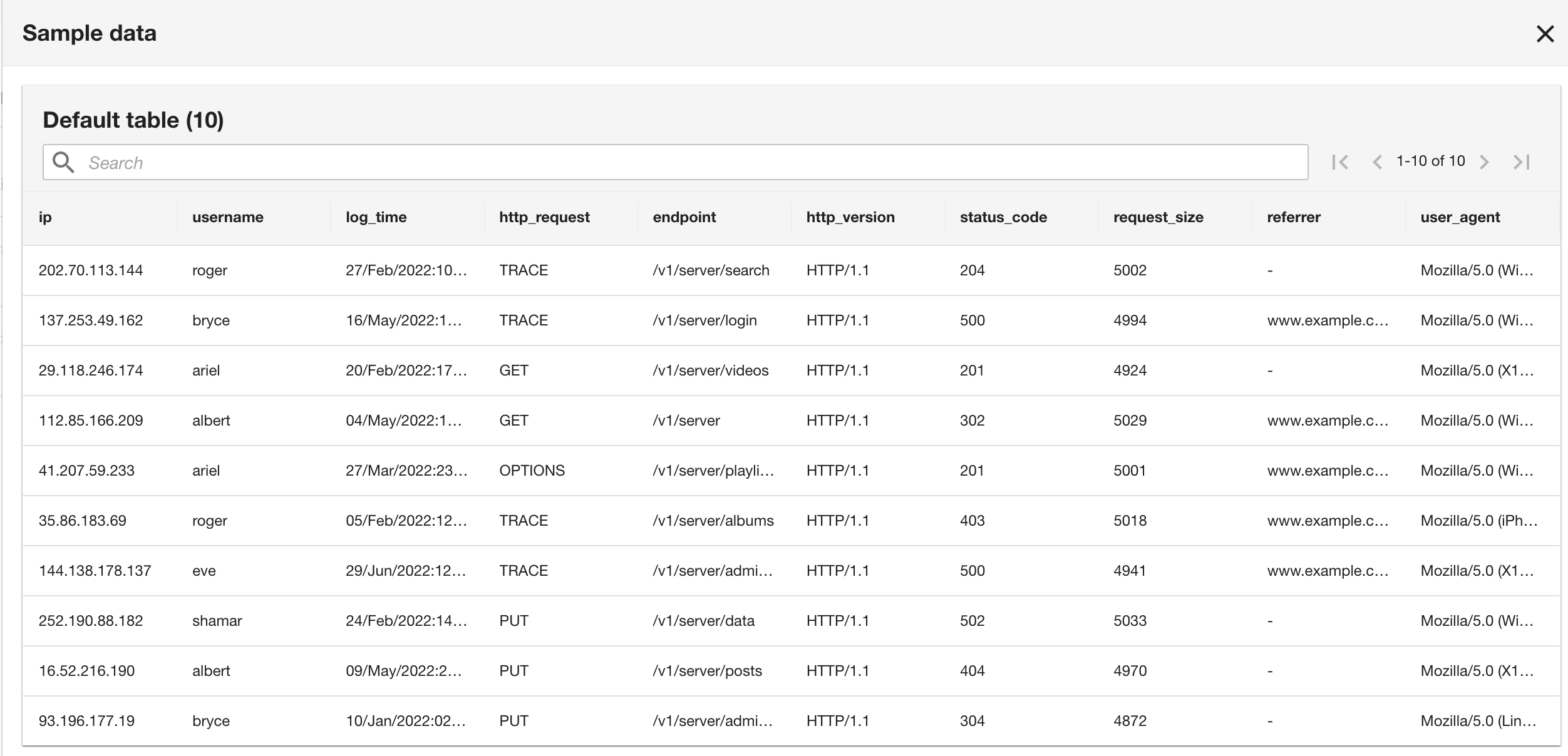
- Überprüfen Sie im letzten Schritt die Konfiguration und wählen Sie aus Absenden.
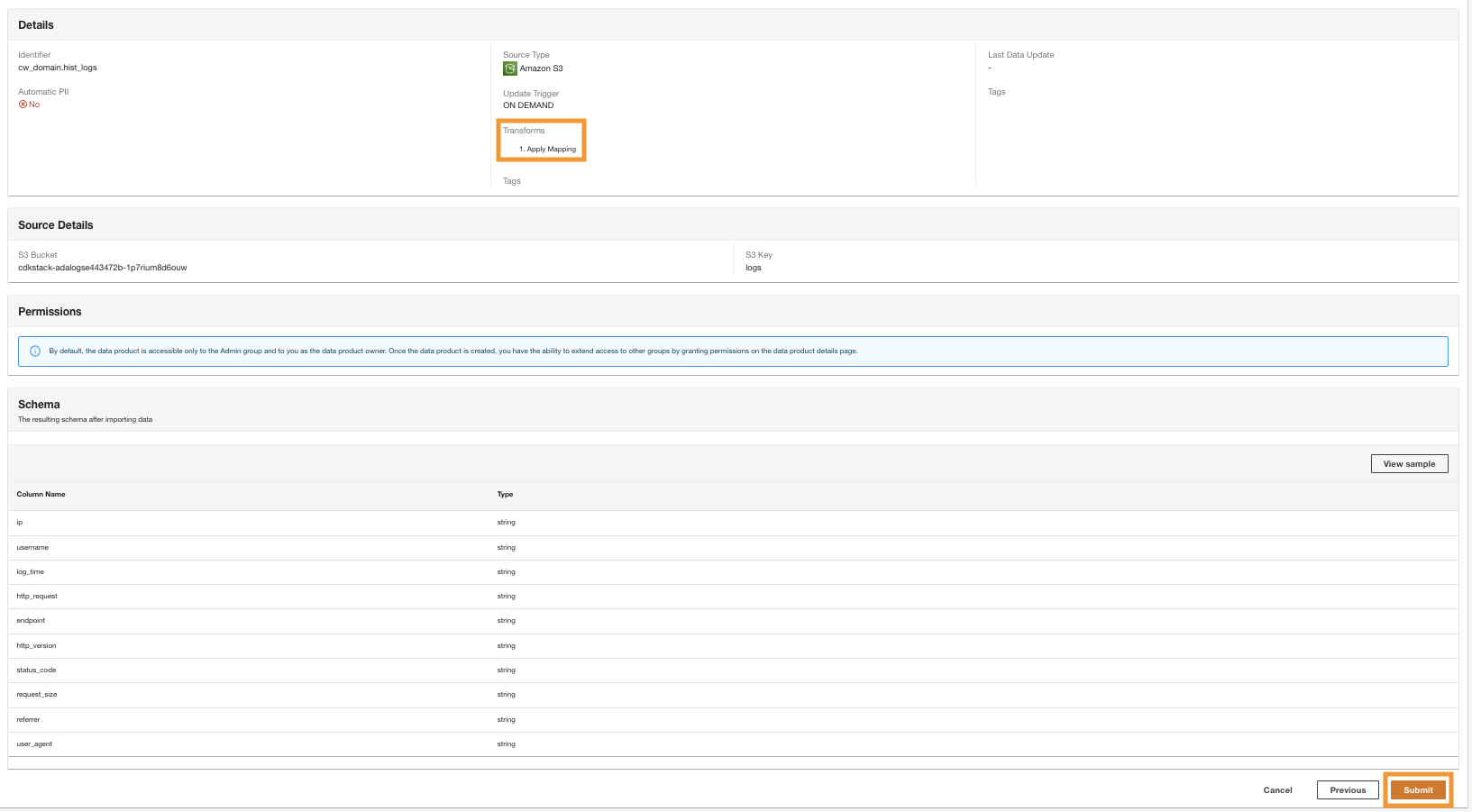
ADA beginnt mit der Verarbeitung der Daten aus der Amazon S3-Quelle, erstellt die Backend-Infrastruktur und bereitet das Datenprodukt vor. Dieser Vorgang dauert je nach Datenumfang einige Minuten.
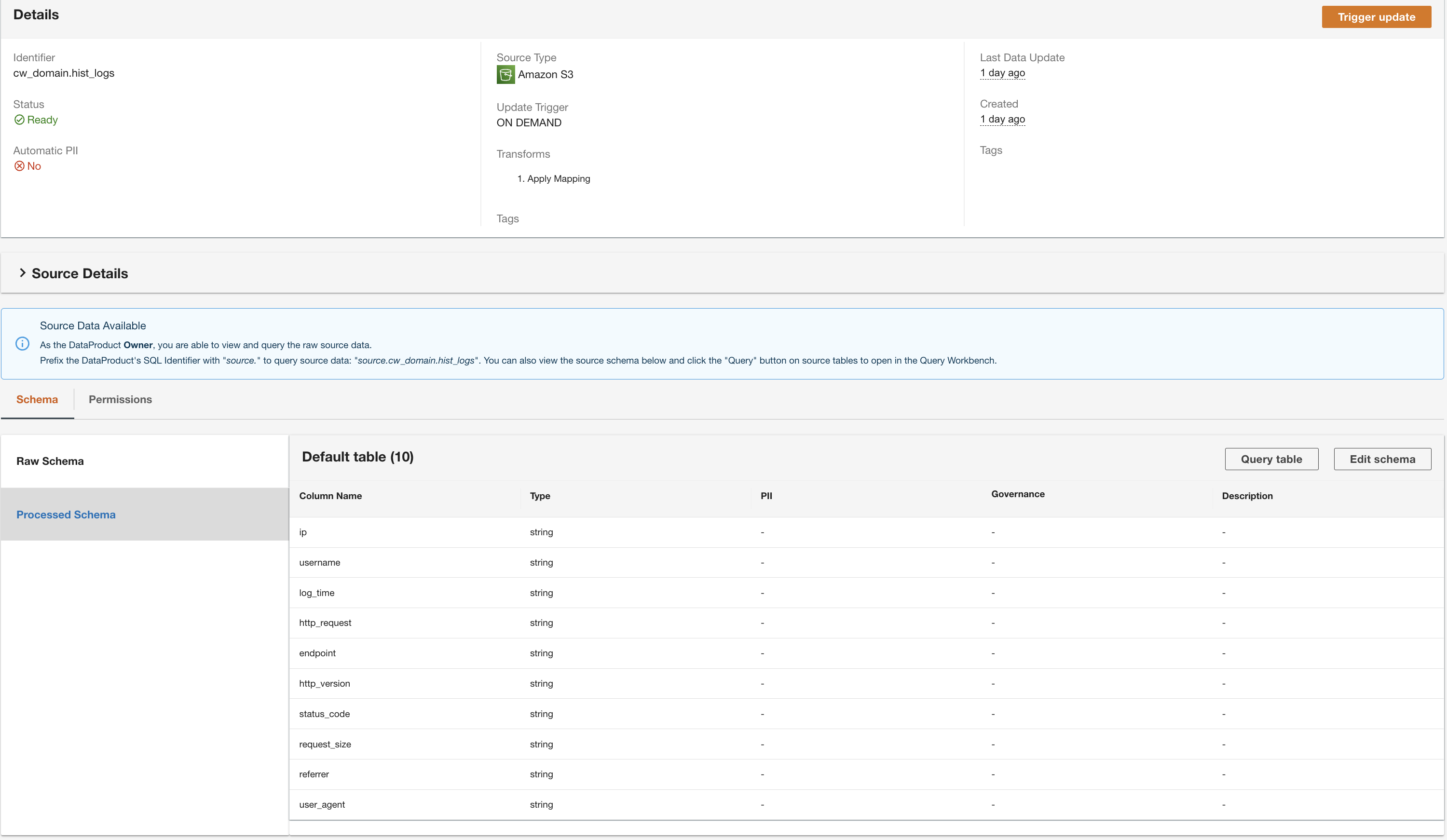
Erstellen Sie ein DynamoDB-Datenprodukt
Zuletzt erstellen wir ein DynamoDB-Datenprodukt. Führen Sie die folgenden Schritte aus:
- Erstellen Sie auf der ADA-Konsole ein neues Datenprodukt.
- Geben Sie einen Namen ein (
lookup) und wähle Amazon DynamoDB.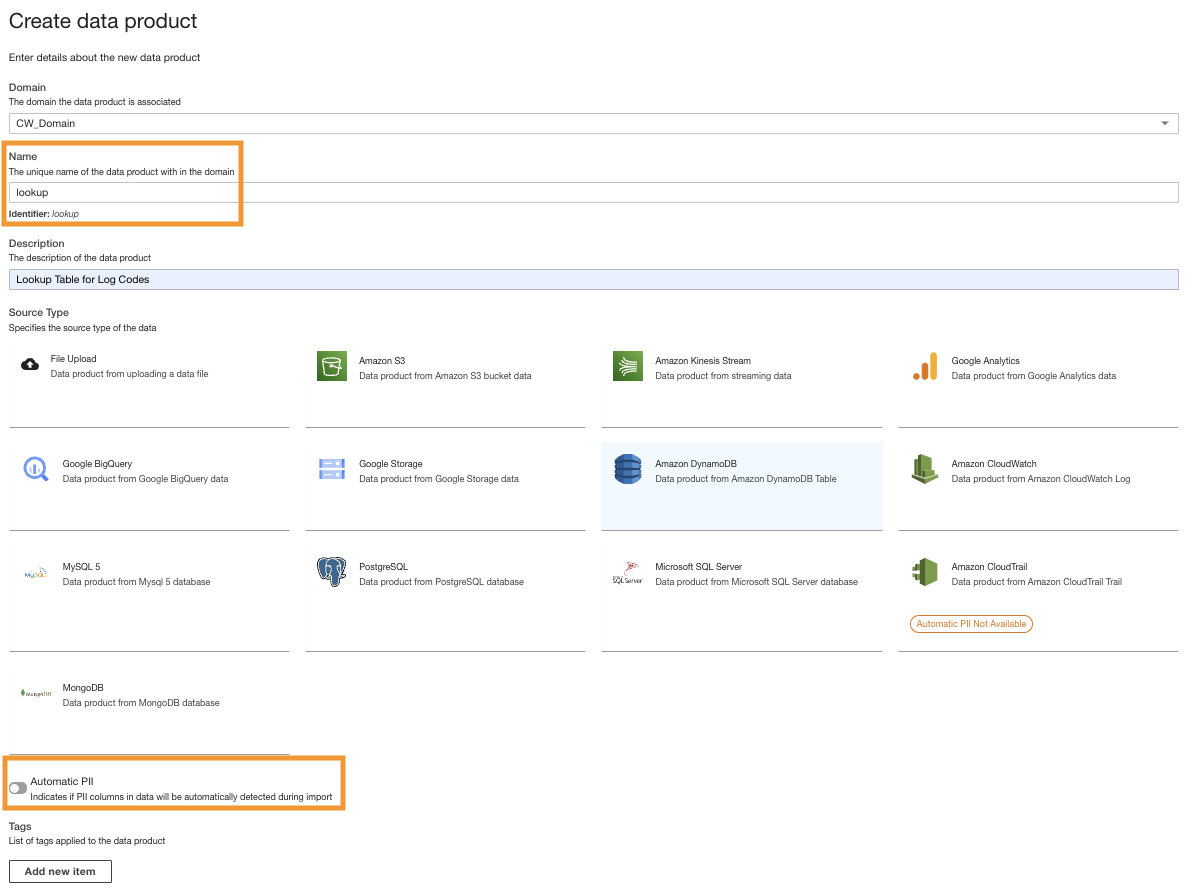
- Geben Sie die
Cdk.DynamoDBTableAusgabevariable für DynamoDB-Tabellen-ARN.
Diese Tabelle enthält Schlüsselattribute, die in dieser Demo als Nachschlagetabelle verwendet werden. Für die Suchdaten verwenden wir die HTTP-Codes sowie lange und kurze Beschreibungen der Codes. Alternativ können Sie auch PostgreSQL, MySQL oder eine CSV-Dateiquelle verwenden.
- Aussichten für Update-TriggerWählen On-Demand.
Die Aktualisierungen erfolgen bei Bedarf, da die Suche hauptsächlich zu Referenzzwecken während der Abfrage dient und alle Aktualisierungen der Suchdaten in ADA mithilfe von On-Demand-Triggern aktualisiert werden können.
- Auswählen Weiter.
ADA liest das Schema aus dem zugrunde liegenden DynamoDB-Schema und stellt den Spaltennamen und -typ für die optionale Transformation bereit. Wir werden mit der Standardschemaauswahl fortfahren, da die Spaltentypen mit den Typen aus der CloudWatch-Protokollgruppe und der Amazon S3 CSV-Datenquelle übereinstimmen. Da Datentypen über alle Datenquellen hinweg konsistent sind, können wir Abfragen schreiben, um Datensätze abzurufen, indem wir die Tabellen mithilfe der Spaltenfelder verbinden. Zum Beispiel die Spalte key im DynamoDB-Schema entspricht dem status_code in den Datenprodukten Amazon S3 und CloudWatch. Wir können Abfragen schreiben, die die drei Tabellen mithilfe des Spaltennamens verbinden können key. Ein Beispiel wird im nächsten Abschnitt gezeigt.
- Auswählen
Fahren Sie mit dem aktuellen Schema fort.
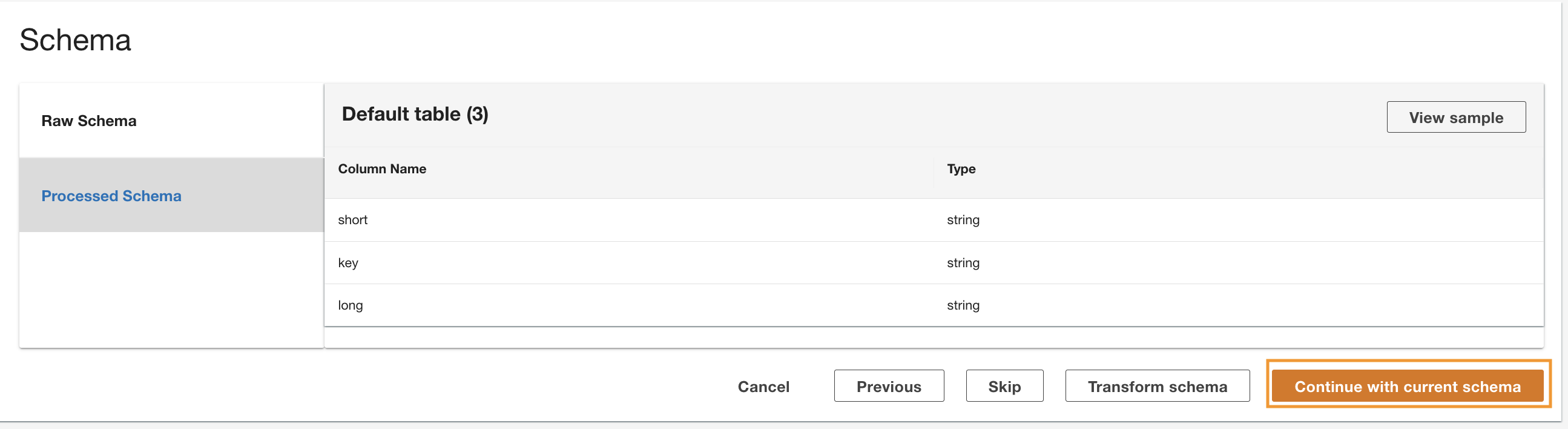
- Überprüfen Sie die Konfiguration und wählen Sie aus Absenden.
ADA verarbeitet die Daten aus der DynamoDB-Tabellendatenquelle und bereitet das Datenprodukt vor. Abhängig von der Größe der Daten dauert dieser Vorgang einige Minuten.
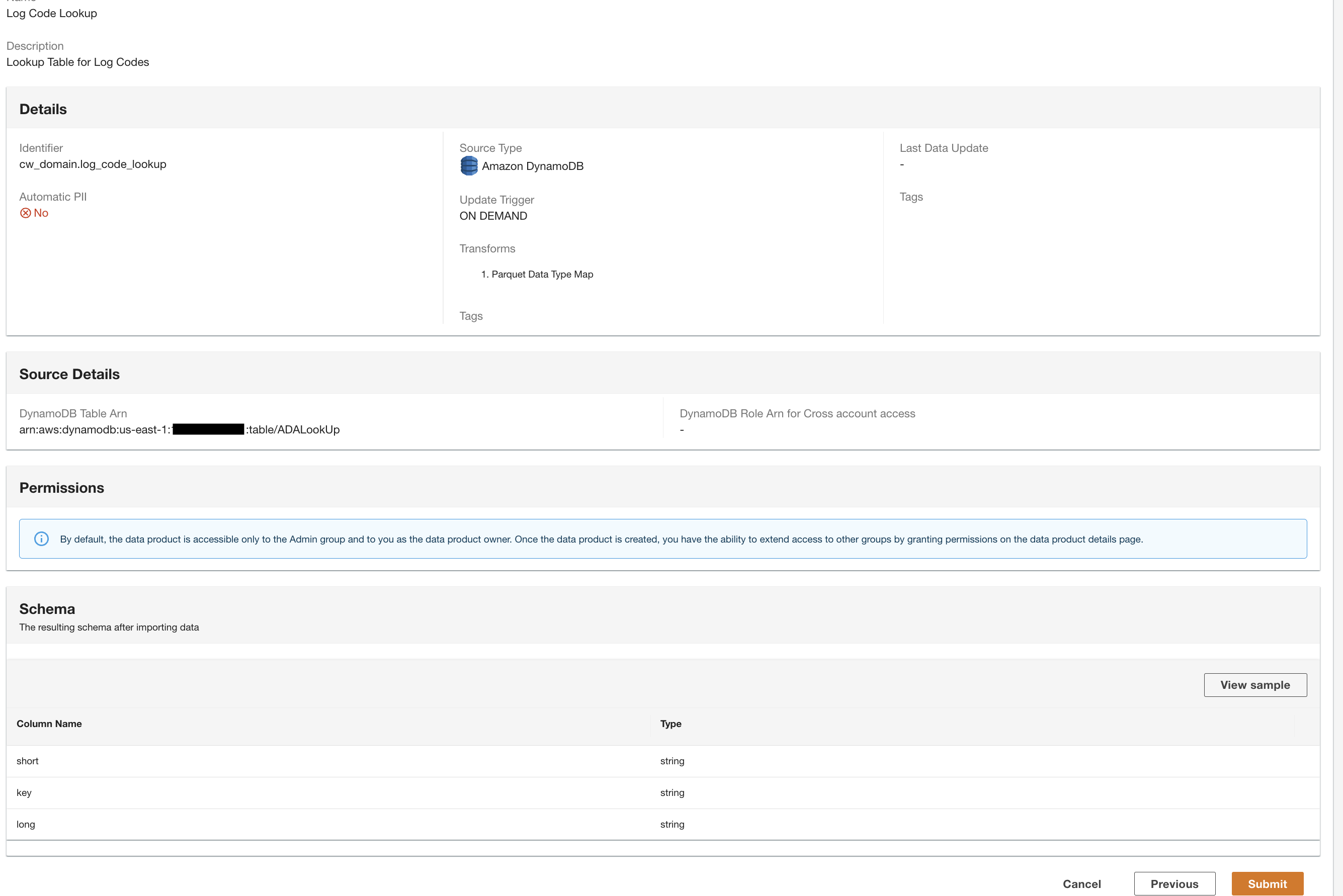
Jetzt haben wir alle drei Datenprodukte von ADA verarbeitet und stehen Ihnen für die Durchführung von Abfragen zur Verfügung.

Verwenden Sie die Query Workbench, um die Daten abzufragen
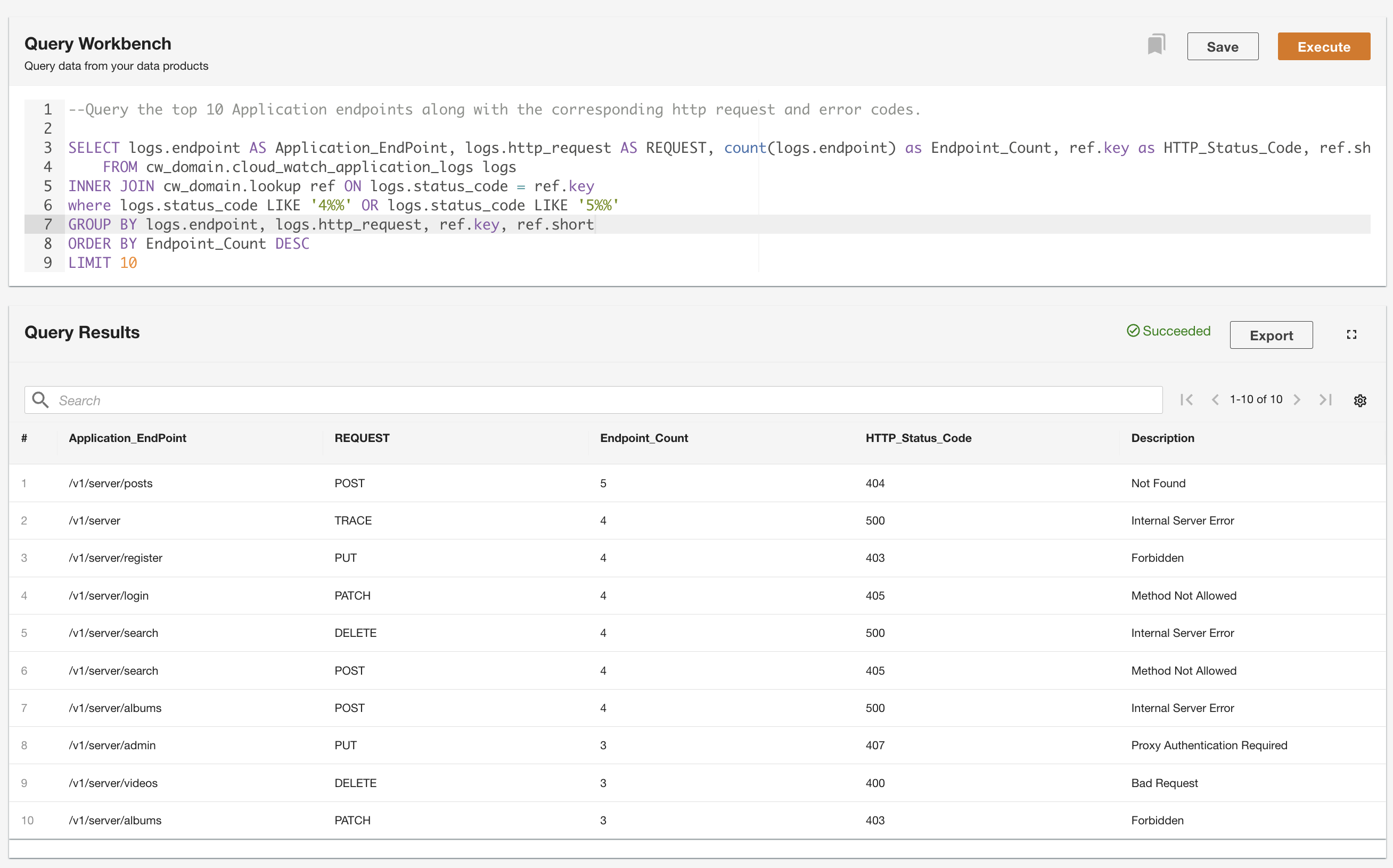
Mit ADA können Sie Abfragen für die Datenprodukte ausführen und gleichzeitig die Datenquelle abstrahieren und sie mithilfe von SQL (Structured Query Language) zugänglich machen. Sie können Abfragen schreiben und die Tabellen verknüpfen, genau wie Sie Tabellen in einer relationalen Datenbank abfragen würden. Wir demonstrieren die Abfragefähigkeit von ADA anhand von zwei Benutzerszenarien. In beiden Szenarien verknüpfen wir einen Anwendungsprotokolldatensatz mit der Fehlercode-Nachschlagetabelle. Im ersten Anwendungsfall fragen wir die aktuellen Anwendungsprotokolle ab, um die zehn am häufigsten aufgerufenen Anwendungsendpunkte zusammen mit den entsprechenden HTTP-Statuscodes zu identifizieren:
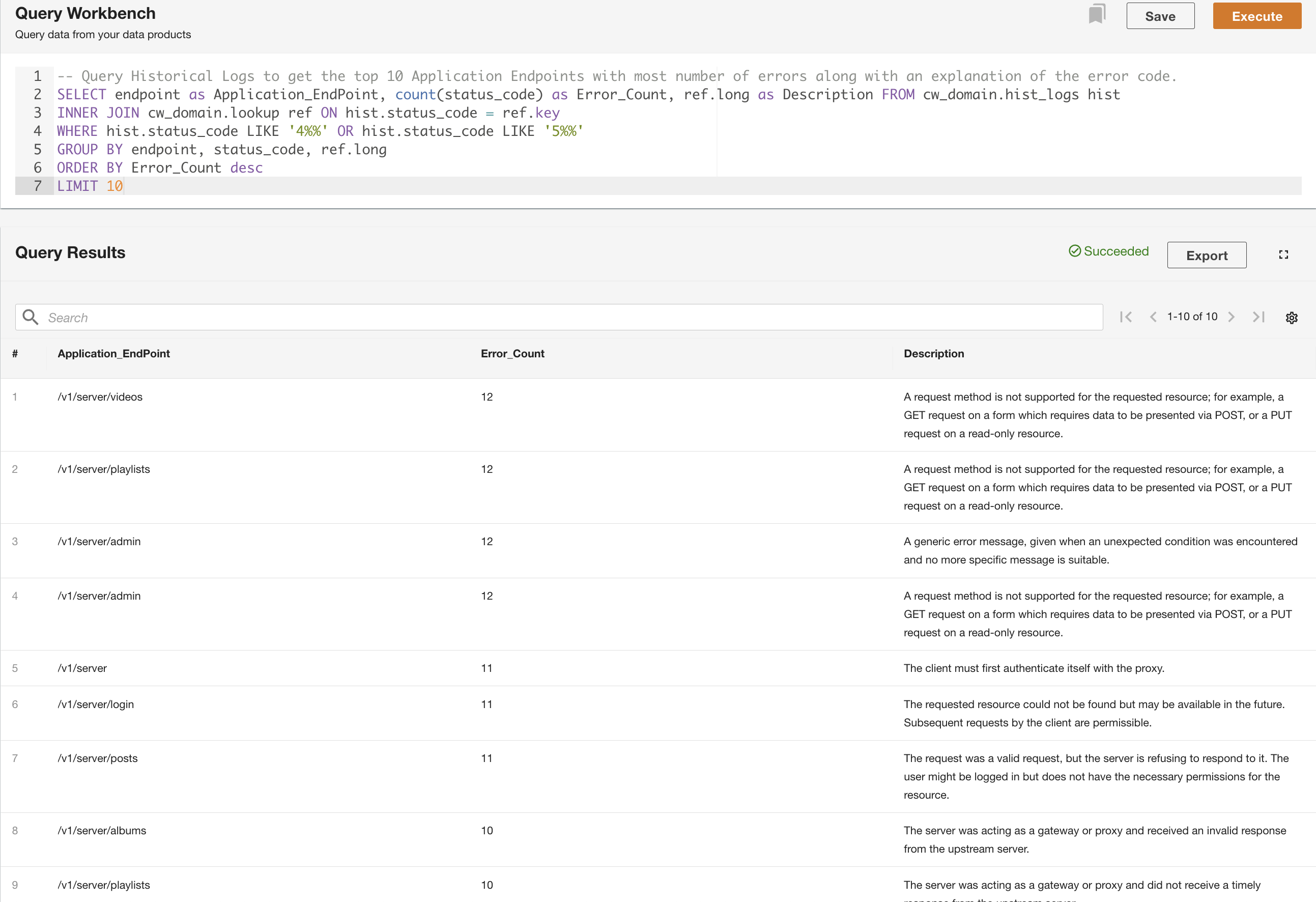
Im zweiten Beispiel fragen wir die Tabelle der historischen Protokolle ab, um die zehn Anwendungsendpunkte mit den meisten Fehlern zu ermitteln und so das Endpunktaufrufmuster zu verstehen:
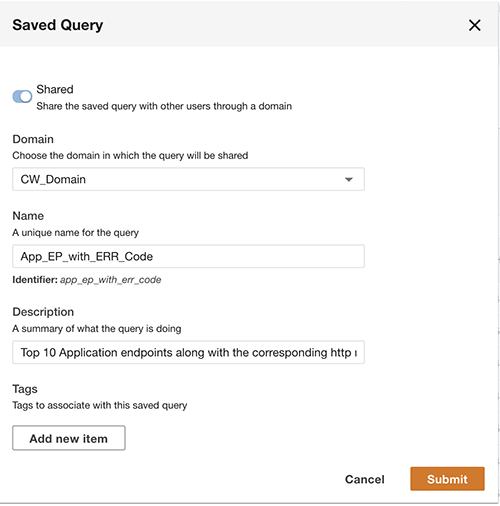
Zusätzlich zur Abfrage können Sie die Abfrage optional speichern und die gespeicherte Abfrage mit anderen Benutzern in derselben Domäne teilen. Auf die freigegebenen Abfragen kann direkt über die Abfrage-Workbench zugegriffen werden. Die Abfrageergebnisse können auch in das CSV-Format exportiert werden.
Visualisieren Sie ADA-Datenprodukte in Tableau
ADA bietet die Möglichkeit dazu Connect an BI-Tools von Drittanbietern, um Daten zu visualisieren und Berichte aus den ADA-Datenprodukten zu erstellen. In dieser Demo verwenden wir die native Integration von ADA mit Tableau, um die Daten der drei zuvor konfigurierten Datenprodukte zu visualisieren. Verwenden Sie den Athena-Connector von Tableau und befolgen Sie die Schritte in Tableau-Konfigurationkönnen Sie ADA als Datenquelle in Tableau konfigurieren. Nachdem eine erfolgreiche Verbindung zwischen Tableau und ADA hergestellt wurde, füllt Tableau die drei Datenprodukte im Tableau-Katalog auf cw_domain.
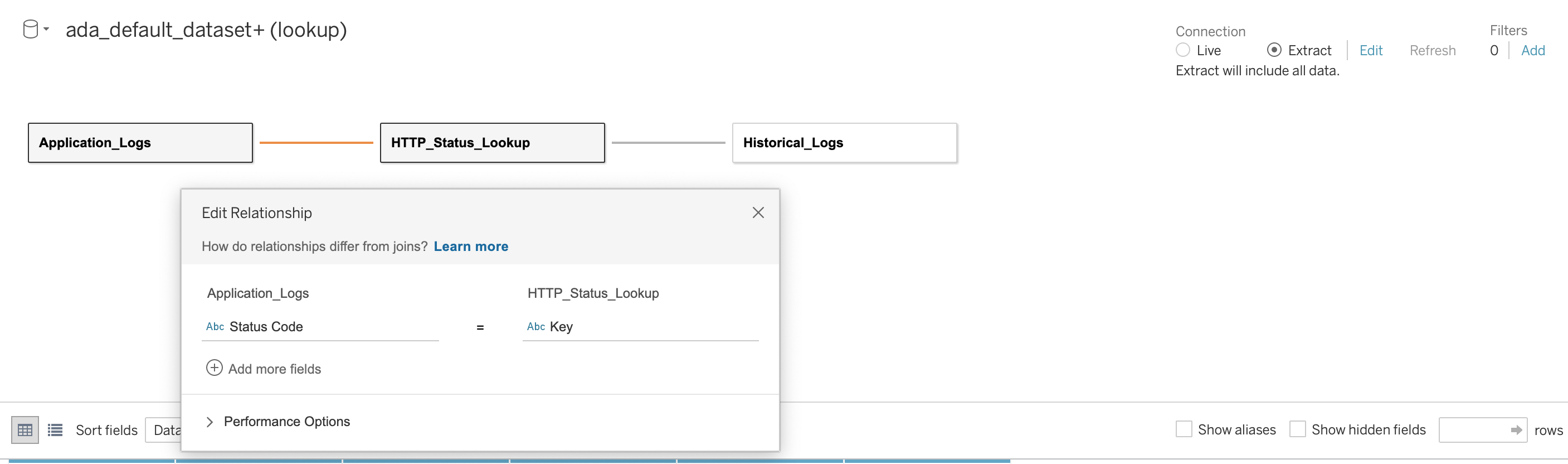
Anschließend stellen wir eine Beziehung zwischen den drei Datenbanken her, indem wir den HTTP-Statuscode als Verbindungsspalte verwenden, wie im folgenden Screenshot gezeigt. Tableau ermöglicht es uns, im Online- und Offline-Modus mit den Datenquellen zu arbeiten. Im Online-Modus stellt Tableau eine Verbindung zu ADA her und fragt die Datenprodukte live ab. Im Offline-Modus können wir das verwenden Extrahieren Option zum Extrahieren der Daten aus ADA und zum Importieren der Daten in Tableau. In dieser Demo importieren wir die Daten in Tableau, um die Abfrage reaktionsschneller zu gestalten. Anschließend speichern wir die Tableau-Arbeitsmappe. Wir können die Daten aus den Datenquellen überprüfen, indem wir die Datenbank auswählen und Jetzt Aktualisieren.
Mit den in Tableau vorhandenen Datenquellenkonfigurationen können wir benutzerdefinierte Berichte, Diagramme und Visualisierungen für die ADA-Datenprodukte erstellen. Betrachten wir zwei Anwendungsfälle für Visualisierungen.
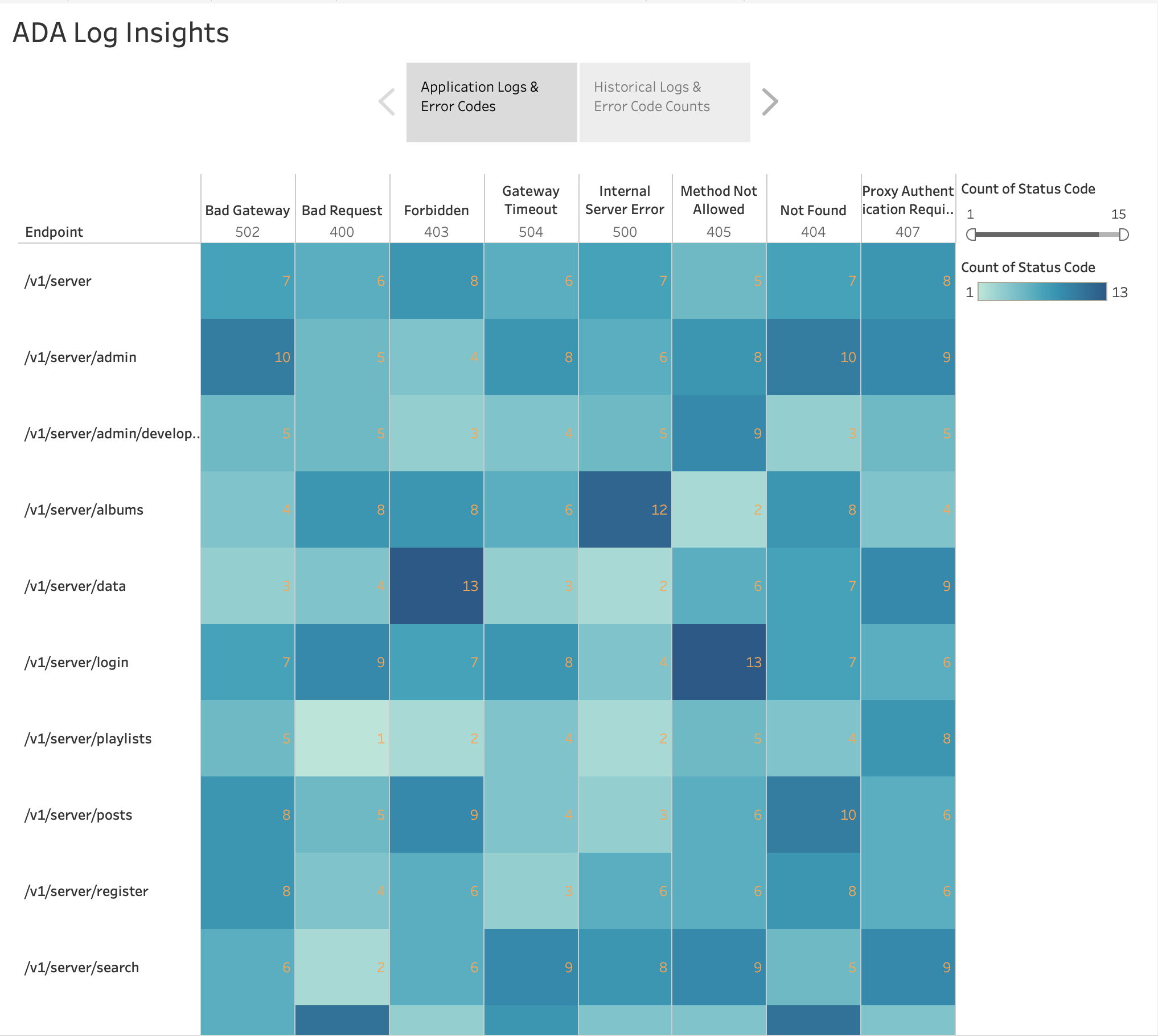
Wie in der folgenden Abbildung dargestellt, haben wir die Häufigkeit der HTTP-Fehler nach Anwendungsendpunkten mithilfe der integrierten Tableau-Funktion visualisiert Wärmekarte Diagramm. Wir haben die HTTP-Statuscodes herausgefiltert, um nur Fehlercodes im Bereich 4xx und 5xx einzuschließen.
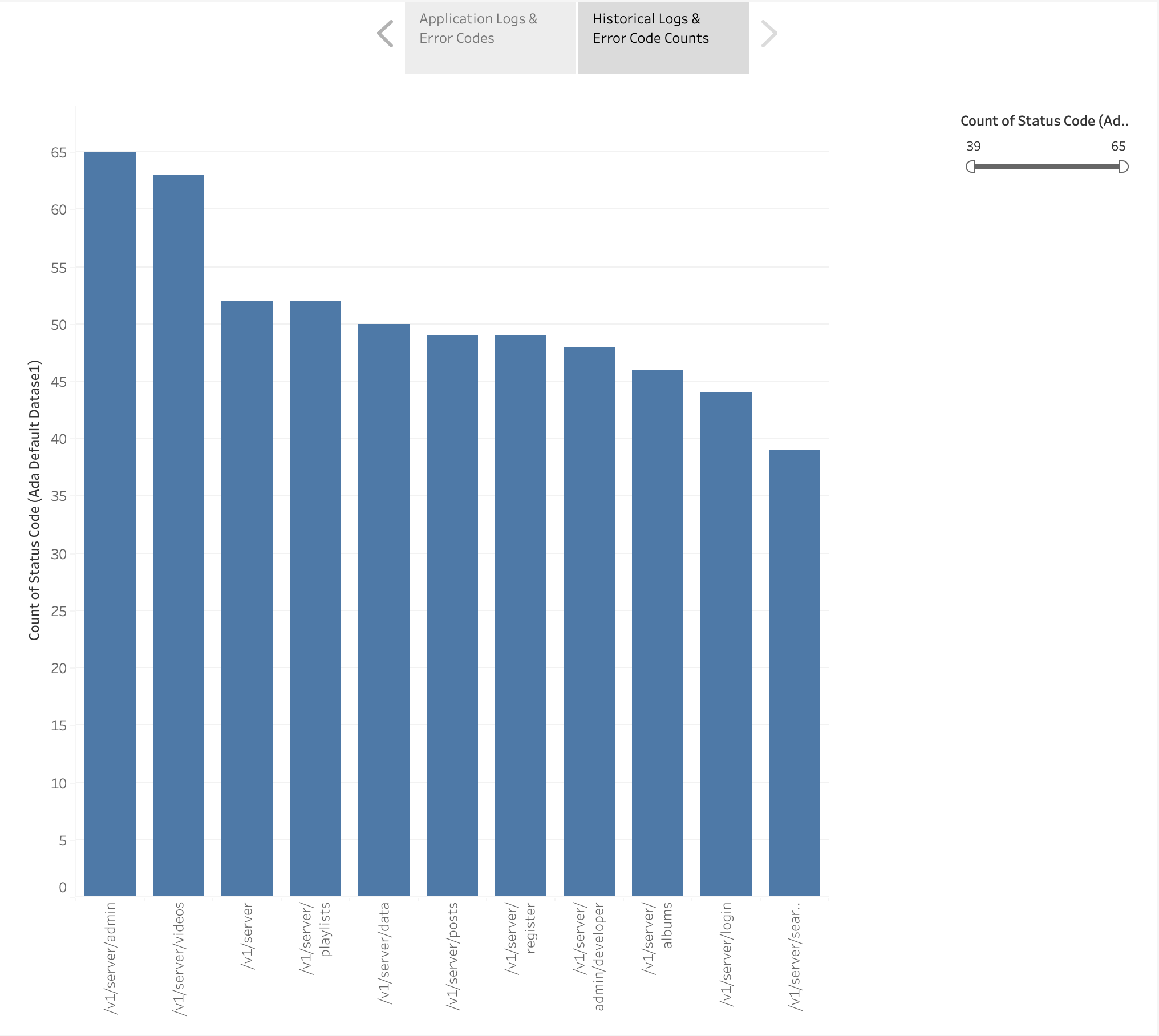
Wir haben außerdem ein Balkendiagramm erstellt, um die Anwendungsendpunkte aus den historischen Protokollen, sortiert nach der Anzahl der HTTP-Fehlercodes, darzustellen. In diesem Diagramm können wir sehen, dass die /v1/server/admin Der Endpunkt hat die meisten HTTP-Fehlerstatuscodes generiert.
Aufräumen
Das Bereinigen der Beispielanwendungsinfrastruktur ist ein zweistufiger Prozess. Um die für diese Demo bereitgestellte Infrastruktur zu entfernen, führen Sie zunächst den folgenden Befehl im Terminal aus:
Geben Sie für die folgende Frage „y“ ein und AWS CDK löscht die für die Demo bereitgestellten Ressourcen:
Alternativ können Sie die Ressourcen über die AWS CloudFormation-Konsole entfernen, indem Sie zum CdkStack-Stack navigieren und auswählen Löschen.
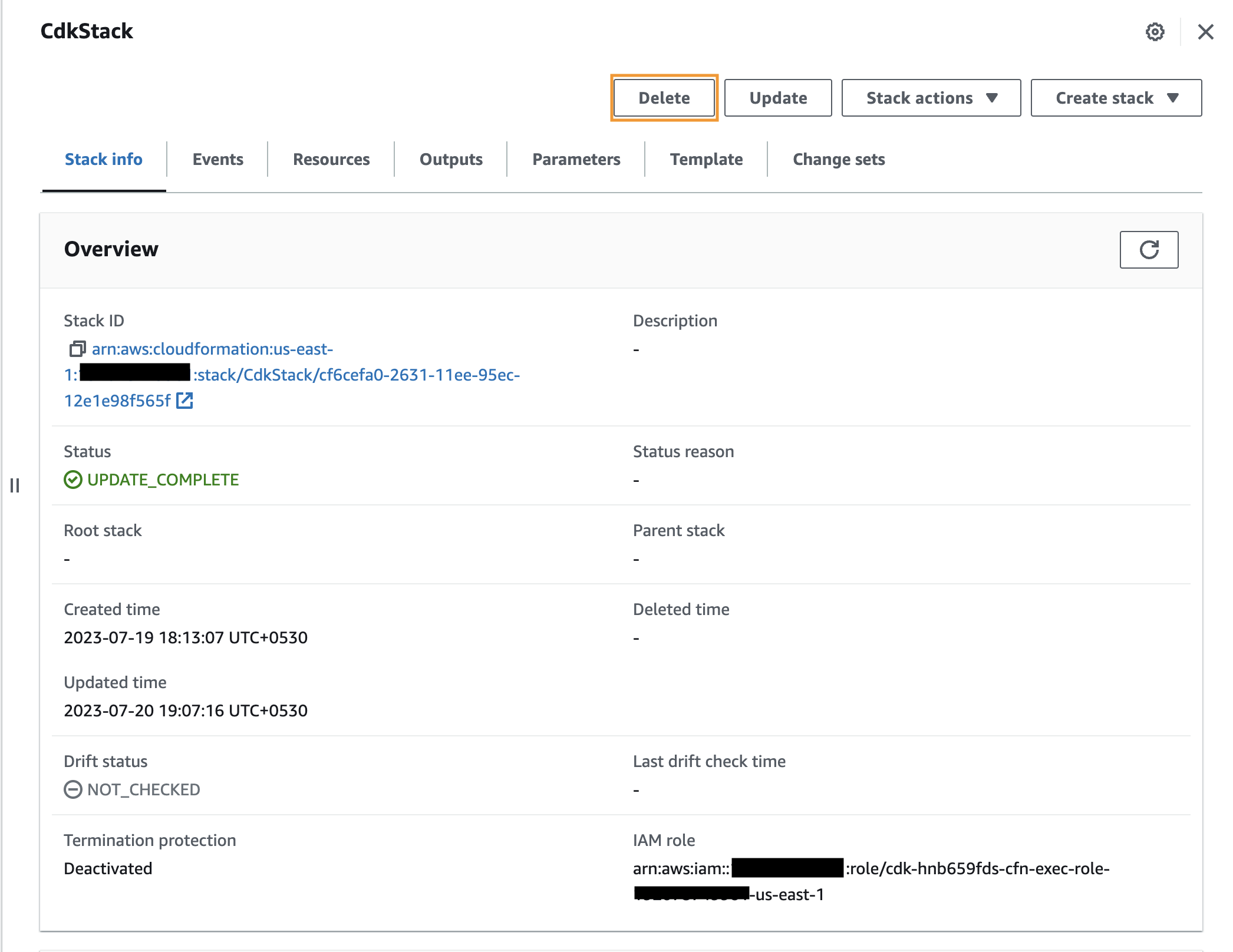
Der zweite Schritt besteht darin, ADA zu deinstallieren. Anweisungen finden Sie unter Deinstallieren Sie die Lösung.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie mit der ADA-Lösung Erkenntnisse aus Anwendungsprotokollen gewinnen, die in zwei verschiedenen Datenquellen gespeichert sind. Wir haben gezeigt, wie man ADA auf einem AWS-Konto installiert und die Demokomponenten mit AWS CDK bereitstellt. Wir haben Datenprodukte in ADA erstellt und die Datenprodukte mithilfe der in ADA integrierten Datenkonnektoren mit den jeweiligen Datenquellen konfiguriert. Wir haben gezeigt, wie man die Datenprodukte mithilfe von Standard-SQL-Abfragen abfragt und Einblicke in die Protokolldaten generiert. Wir haben auch den Tableau Desktop-Client, ein BI-Produkt eines Drittanbieters, mit ADA verbunden und gezeigt, wie man Visualisierungen für die Datenprodukte erstellt.
ADA automatisiert den Prozess der Aufnahme, Transformation, Verwaltung und Abfrage verschiedener Datensätze und vereinfacht die Lebenszyklusverwaltung von Daten. Mit den vorgefertigten Konnektoren von ADA können Sie Daten aus verschiedenen Datenquellen erfassen. Softwareteams mit Grundkenntnissen zu AWS-Produkten und -Services können in wenigen Stunden eine betriebsbereite Datenanalyseplattform einrichten und einen sicheren Zugriff auf die Daten ermöglichen. Über eine intuitive und eigenständige Web-Benutzeroberfläche können die Daten dann einfach und schnell abgefragt werden.
Probieren Sie ADA noch heute aus, um Daten einfach zu verwalten und Erkenntnisse daraus zu gewinnen.
Über die Autoren
 Aparajithan Vaidyanathan ist Principal Enterprise Solutions Architect bei AWS. Er unterstützt Unternehmenskunden bei der Migration und Modernisierung ihrer Workloads in die AWS-Cloud. Er ist ein Cloud-Architekt mit mehr als 23 Jahren Erfahrung in der Gestaltung und Entwicklung von Unternehmens-, Groß- und verteilten Softwaresystemen. Er ist spezialisiert auf maschinelles Lernen und Datenanalyse mit Schwerpunkt auf dem Bereich Daten- und Feature-Engineering. Er ist ein aufstrebender Marathonläufer und zu seinen Hobbys zählen Wandern, Radfahren und Zeit mit seiner Frau und seinen beiden Söhnen verbringen.
Aparajithan Vaidyanathan ist Principal Enterprise Solutions Architect bei AWS. Er unterstützt Unternehmenskunden bei der Migration und Modernisierung ihrer Workloads in die AWS-Cloud. Er ist ein Cloud-Architekt mit mehr als 23 Jahren Erfahrung in der Gestaltung und Entwicklung von Unternehmens-, Groß- und verteilten Softwaresystemen. Er ist spezialisiert auf maschinelles Lernen und Datenanalyse mit Schwerpunkt auf dem Bereich Daten- und Feature-Engineering. Er ist ein aufstrebender Marathonläufer und zu seinen Hobbys zählen Wandern, Radfahren und Zeit mit seiner Frau und seinen beiden Söhnen verbringen.
 Rashim Rahman ist ein Softwareentwickler mit Sitz in Sydney, Australien, mit mehr als 10 Jahren Erfahrung in der Softwareentwicklung und -architektur. Er arbeitet hauptsächlich an der Entwicklung groß angelegter Open-Source-AWS-Lösungen für häufige Anwendungsfälle und Geschäftsprobleme von Kunden. In seiner Freizeit treibt er gerne Sport und verbringt Zeit mit Freunden und Familie.
Rashim Rahman ist ein Softwareentwickler mit Sitz in Sydney, Australien, mit mehr als 10 Jahren Erfahrung in der Softwareentwicklung und -architektur. Er arbeitet hauptsächlich an der Entwicklung groß angelegter Open-Source-AWS-Lösungen für häufige Anwendungsfälle und Geschäftsprobleme von Kunden. In seiner Freizeit treibt er gerne Sport und verbringt Zeit mit Freunden und Familie.
 Hafiz Saadullah ist leitender technischer Produktmanager bei Amazon Web Services. Hafiz konzentriert sich auf AWS-Lösungen, die darauf ausgelegt sind, Kunden bei der Bewältigung häufiger Geschäftsprobleme und Anwendungsfälle zu unterstützen.
Hafiz Saadullah ist leitender technischer Produktmanager bei Amazon Web Services. Hafiz konzentriert sich auf AWS-Lösungen, die darauf ausgelegt sind, Kunden bei der Bewältigung häufiger Geschäftsprobleme und Anwendungsfälle zu unterstützen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- ChartPrime. Verbessern Sie Ihr Handelsspiel mit ChartPrime. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- Fähigkeit
- Fähig
- Über Uns
- Zugang
- Zugriff
- zugänglich
- Konto
- über
- Aktionen
- ADA
- hinzufügen
- Zusatz
- Zusätzliche
- Adressierung
- Administrator
- Nach der
- gegen
- Alle
- erlauben
- erlaubt
- entlang
- ebenfalls
- Alternative
- Amazon
- Amazon Web Services
- unter
- an
- Analyse
- Business Analysten
- Analytik
- analysieren
- und
- Ein anderer
- jedem
- Apache
- Bienen
- APIs
- Anwendung
- Anwendungen
- angewandt
- Bewerben
- Anwendung
- Architektur
- SIND
- AS
- strebend
- At
- Attribute
- Australien
- Authentifizierung
- zugelassen
- Automatisiert
- Automatisches Erfassen:
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- AWS
- AWS CloudFormation
- Zurück
- Backend
- Bar
- basierend
- basic
- BE
- weil
- war
- Bevor
- maßgeschneiderte
- zwischen
- beide
- Box
- bauen
- Building
- eingebaut
- Geschäft
- Business Intelligence
- aber
- by
- rufen Sie uns an!
- CAN
- capability
- Häuser
- Fälle
- Katalog
- CD
- Übernehmen
- Chart
- Charts
- Auswählen
- Auswahl
- Auftraggeber
- Cloud
- Code
- Codes
- Sammlung
- Kolonne
- Spalten
- gemeinsam
- abschließen
- Komponenten
- Konfiguration
- konfiguriert
- Vernetz Dich
- Sie
- Verbindung
- Connects
- Geht davon
- konsistent
- Konsul (Console)
- enthält
- fortsetzen
- korreliert
- Korrelation
- Dazugehörigen
- entspricht
- Kosten
- erstellen
- erstellt
- schafft
- Erstellen
- Referenzen
- Strom
- Original
- Kunde
- Kunden
- Armaturenbrett
- technische Daten
- Datenanalyse
- Datenverarbeitung
- Datenbase
- Datenbanken
- Datensätze
- Standard
- Demand
- Demo
- zeigen
- Synergie
- Abhängig
- einsetzen
- Einsatz
- Einsatz
- setzt ein
- Beschreibung
- entworfen
- Entwerfen
- Desktop
- detailliert
- Details
- Entwickler:in / Unternehmen
- Entwicklung
- Entwicklung
- Diagnose
- anders
- Direkt
- behindert
- Entdeckung
- Display
- verteilt
- verschieden
- Tut nicht
- Domain
- Domains
- Nicht
- fallen gelassen
- im
- jeder
- Früher
- leicht
- Bearbeitung
- entweder
- freigegeben
- ermöglicht
- Endpunkt
- Endpunkte
- Entwicklung
- gewährleisten
- Enter
- Unternehmen
- Unternehmenskunden
- Enterprise-Lösungen
- Fehler
- Fehler
- etablieren
- etablierten
- Äther (ETH)
- Beispiel
- vorhandenen
- ERFAHRUNGEN
- Erklären
- Erklärung
- Extrakt
- Extrahieren Sie die Daten
- vertraut
- Familie
- Merkmal
- wenige
- Feld
- Felder
- Abbildung
- Reichen Sie das
- Mappen
- Finale
- Finanzen
- Vorname
- flexibel
- Setzen Sie mit Achtsamkeit
- konzentriert
- Folgende
- Aussichten für
- Format
- vier
- Frequenz
- Freunde
- für
- Funktion
- Gewinnen
- erzeugen
- erzeugt
- bekommen
- bekommen
- regieren
- Gruppe an
- Gruppen
- Haben
- mit
- he
- Hilfe
- Besondere
- Wandern
- seine
- historisch
- Hobbys
- gehostet
- STUNDEN
- Ultraschall
- Hilfe
- aber
- HTML
- http
- HTTPS
- IAM
- identisch
- identifizieren
- Identitätsschutz
- if
- importieren
- in
- das
- Dazu gehören
- Einschließlich
- Information
- Infrastruktur
- Anfangs-
- Einblicke
- installieren
- Installation
- Anleitung
- integriert
- Integration
- Intelligenz
- interaktive
- interessiert
- Schnittstelle
- in
- intuitiv
- ruft auf
- beteiligt
- Problem
- IT
- join
- Beitritt
- Joins
- jpg
- JSON
- nur
- Behalten
- Wesentliche
- Wissen
- Sprache
- grosse
- großflächig
- Nachname
- später
- Start
- lernen
- Bibliothek
- Zugelassen
- Lebenszyklus
- Gefällt mir
- LIMIT
- Line
- Liste
- leben
- Log
- Protokollierung
- Lang
- aussehen
- Nachschlagen
- Maschine
- Maschinelles Lernen
- um
- Making
- verwalten
- Management
- Manager
- viele
- Karte
- Mapping
- Marathon
- Marketing
- Materie
- sinnvoll
- Nachricht
- MFA
- könnte
- migriert
- Minuten
- Model
- modernisieren
- mehr
- vor allem warme
- meist
- Mozilla
- Multi-Faktor-Authentifizierung
- MySQL
- Name
- Namens
- Namen
- nativen
- Navigieren
- navigieren
- Menü
- Need
- erforderlich
- Bedürfnisse
- Neu
- neu
- weiter
- Anzahl
- of
- Angebote
- Offline-Bereich.
- Alt
- on
- On-Demand
- EINEM
- Online
- einzige
- XNUMXh geöffnet
- Open-Source-
- Betriebs-
- Option
- or
- Auftrag
- Andere
- Anders
- Möglichkeiten für das Ausgangssignal:
- Überblick
- Seite
- Brot
- Passwort
- Weg
- Schnittmuster
- ausführen
- Berechtigungen
- Persönlich
- Telefon
- pii
- Pipeline
- Ort
- Ebene
- Plan
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Politik durchzulesen
- Portal
- Post
- Postgresql
- angetriebene
- Danach
- Bereitet sich vor
- Voraussetzungen
- Gegenwart
- Geschenke
- Vorspann
- früher
- in erster Linie
- Principal
- Vor
- Probleme
- vorgehen
- Prozessdefinierung
- verarbeitet
- anpassen
- Verarbeitung
- Produziert
- Produkt
- Produkt-Manager
- Produkte
- Produkte und Dienstleistungen
- Programme
- Projekt
- die
- vorausgesetzt
- Versorger
- bietet
- Zweck
- Zwecke
- Python
- Abfragen
- Frage
- schnell
- Angebot
- Lesen Sie mehr
- bereit
- erhalten
- Aufzeichnungen
- bezeichnet
- Region
- Beziehung
- relevant
- entfernen
- wiederholen
- Meldungen
- Anforderung
- falls angefordert
- Downloads
- diejenigen
- ansprechbar
- Die Ergebnisse
- behalten
- Überprüfen
- Reiten
- Rollen
- Wurzel
- Regel
- Führen Sie
- Läufer
- Laufen
- Vertrieb
- gleich
- Speichern
- Skalieren
- Szenarien
- vorgesehen
- Umfang
- Suche
- Zweite
- Abschnitt
- Verbindung
- Sicherheitdienst
- sehen
- ausgewählt
- Auswahl
- senden
- geschickt
- getrennte
- brauchen
- Serverlos
- Lösungen
- kompensieren
- Einstellung
- Teilen
- von Locals geführtes
- Short
- gezeigt
- Konzerte
- Einfacher
- vereinfachte
- Vereinfachung
- Größe
- Fähigkeiten
- So
- Software
- Software-Entwicklung
- Lösung
- Lösungen
- Quelle
- Quellen
- Spezialist
- spezialisiert
- spezifisch
- angegeben
- Ausgabe
- Sports
- SQL
- Stapel
- standalone
- Standard
- Anfang
- beginnt
- Status
- Schritt
- Shritte
- Lagerung
- gelagert
- Schnur
- strukturierte
- erfolgreich
- Erfolgreich
- so
- Unterstützt
- sicher
- Sydney
- Systeme und Techniken
- Tabelle
- Tableau
- Nehmen
- nimmt
- Team
- Teams
- Technische
- technische Fähigkeiten
- Terminal
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- ihr
- dann
- Dort.
- Diese
- basierte Online-to-Offline-Werbezuordnungen von anderen gab.
- fehlen uns die Worte.
- nach drei
- Durch
- Zeit
- zu
- heute
- Werkzeuge
- Top
- Top 10
- Gesamt
- Transformieren
- Transformation
- Transformationen
- verwandelt
- Transformieren
- Transformationen
- ausgelöst
- XNUMX
- tippe
- Typen
- für
- zugrunde liegen,
- verstehen
- aktualisiert
- Updates
- auf
- URI
- us
- -
- Anwendungsfall
- benutzt
- Mitglied
- Benutzerschnittstelle
- Nutzer
- Verwendung von
- Werte
- Variable
- Vielfalt
- Version
- Anzeigen
- wollen
- Weg..
- we
- Netz
- Web-Services
- GUT
- wann
- welche
- während
- breit
- Große Auswahl
- Frau
- werden wir
- mit
- .
- ohne
- Arbeiten
- Arbeitsablauf.
- Werk
- würde
- schreiben
- Jahr
- U
- Ihr
- Zephyrnet