Amazon OpenSearch-Dienst ist ein verwalteter Service, der es einfach macht, OpenSearch- und Legacy-Elasticsearch-Cluster in großem Umfang in der AWS Cloud zu sichern, bereitzustellen und zu betreiben. Amazon OpenSearch Service stellt alle Ressourcen für Ihren Cluster bereit, startet ihn und erkennt und ersetzt automatisch ausgefallene Knoten, wodurch der Overhead von selbstverwalteten Infrastrukturen reduziert wird. Der Service macht es Ihnen leicht, interaktive Protokollanalysen, Echtzeit-Anwendungsüberwachung, Website-Suchen und mehr durchzuführen, indem er die neuesten Versionen von OpenSearch, Unterstützung für 19 Versionen von Elasticsearch (Versionen 1.5 bis 7.10) und Visualisierungsfunktionen powered by bietet OpenSearch-Dashboards und Kibana (Versionen 1.5 bis 7.10).
In der neuesten Dienstsoftwareversion haben wir die Shard-Zuweisungslogik so aktualisiert, dass sie lastbewusst ist, sodass der Dienst bei der Neuverteilung von Shards im Falle von Knotenausfällen verhindert, dass überlebende Knoten durch Shards überlastet werden, die zuvor auf dem ausgefallenen Knoten gehostet wurden. Dies ist besonders wichtig für Multi-AZ-Domänen, um eine konsistente und vorhersehbare Clusterleistung bereitzustellen.
Weitere Hintergrundinformationen zur Shard-Zuweisungslogik im Allgemeinen finden Sie unter Entmystifizierung der Elasticsearch-Shard-Zuweisung.
Die Herausforderung
Eine Amazon OpenSearch Service-Domain wird als „ausgeglichen“ bezeichnet, wenn die Anzahl der Knoten gleichmäßig über die konfigurierten Availability Zones verteilt ist und die Gesamtzahl der Shards gleichmäßig über alle verfügbaren Knoten verteilt ist, ohne dass sich die Shards eines Indexes auf einen beliebigen Index konzentrieren Knoten. Außerdem verfügt OpenSearch über eine Eigenschaft namens „Zone Awareness“, die bei Aktivierung sicherstellt, dass der primäre Shard und sein entsprechendes Replikat in verschiedenen Availability Zones zugewiesen werden. Wenn Sie über mehr als eine Datenkopie verfügen, bieten mehrere Availability Zones eine bessere Fehlertoleranz und Verfügbarkeit. Für den Fall, dass die Domäne hoch- oder herunterskaliert wird oder während des Ausfalls von Knoten, verteilt OpenSearch die Shards automatisch zwischen verfügbaren Knoten neu und befolgt dabei die Zuweisungsregeln basierend auf Zonenbewusstsein.
Während der Shard-Balancing-Prozess sicherstellt, dass Shards gleichmäßig über die Availability Zones verteilt werden, werden Shards in einigen Fällen bei einem unerwarteten Ausfall in einer einzelnen Zone den überlebenden Knoten neu zugewiesen. Dies kann dazu führen, dass die verbleibenden Knoten überlastet werden, was sich auf die Stabilität des Clusters auswirkt.
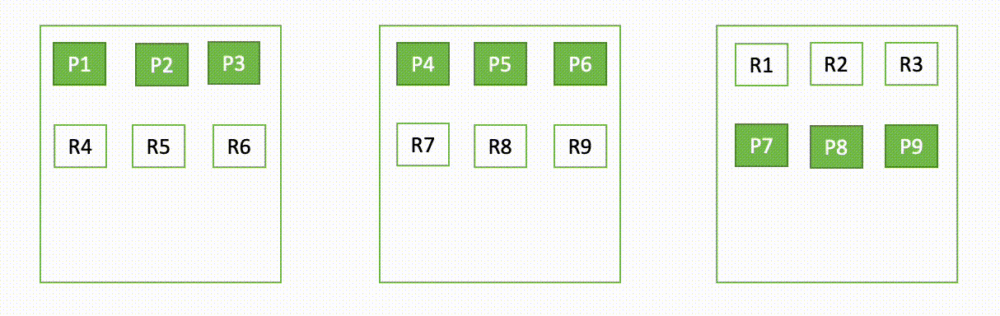
Wenn beispielsweise ein Knoten in einem Cluster mit drei Knoten ausfällt, verteilt OpenSearch die nicht zugewiesenen Shards neu, wie im folgenden Diagramm dargestellt. Hier steht „P“ für eine primäre Shard-Kopie, während „R“ für eine Replikat-Shard-Kopie steht.

Dieses Verhalten der Domäne kann in zwei Teilen erklärt werden – während des Ausfalls und während der Wiederherstellung.
Während des Scheiterns
Eine Domäne, die über mehrere Availability Zones bereitgestellt wird, kann während ihres Lebenszyklus auf mehrere Arten von Fehlern stoßen.
Kompletter Zonenausfall
Ein Cluster kann aus verschiedenen Gründen eine einzelne Availability Zone und auch alle Knoten in dieser Zone verlieren. Heute versucht der Service, die verlorenen Knoten in den verbleibenden fehlerfreien Availability Zones zu platzieren. Der Dienst versucht auch, die verlorenen Shards in den verbleibenden Knoten neu zu erstellen, während er weiterhin die Zuordnungsregeln befolgt. Dies kann zu einigen unbeabsichtigten Folgen führen.
- Wenn die Shards der betroffenen Zone gesunden Zonen neu zugewiesen werden, lösen sie Shard-Wiederherstellungen aus, die die Latenzen erhöhen können, da sie zusätzliche CPU-Zyklen und Netzwerkbandbreite verbrauchen.
- Bei einem Setup mit n-AZ und n Kopien (n>1) werden die verbleibenden n-1 Availability Zones der n-ten Shard-Kopie zugewiesen, was unerwünscht sein kann, da es zu einer Schiefe in der Shard-Verteilung führen kann, was ebenfalls zu einer solchen führen kann unausgeglichener Datenverkehr zwischen Knoten. Diese Knoten können überlastet werden, was zu weiteren Ausfällen führt.
Teilweiser Zonenausfall
Im Falle eines teilweisen Zonenausfalls oder wenn die Domäne nur einige der Knoten in einer Availability Zone verliert, versucht Amazon OpenSearch Service, die ausgefallenen Knoten so schnell wie möglich zu ersetzen. Falls es jedoch zu lange dauert, die Knoten zu ersetzen, versucht OpenSearch, die nicht zugewiesenen Shards dieser Zone den verbleibenden Knoten in der Availability Zone zuzuweisen. Wenn der Service die Knoten in der betroffenen Availability Zone nicht ersetzen kann, weist er sie möglicherweise in der anderen konfigurierten Availability Zone zu, was die Verteilung von Shards sowohl über als auch innerhalb der Zone weiter verzerren kann. Dies wiederum hat unbeabsichtigte Folgen.
- Wenn die Knoten in der Domäne nicht über genügend Speicherplatz verfügen, um die zusätzlichen Shards aufzunehmen, kann die Domäne schreibgeschützt werden, was sich auf den Indexierungsvorgang auswirkt.
- Aufgrund der verzerrten Verteilung von Shards kann es in der Domäne auch zu verzerrtem Datenverkehr über die Knoten kommen, was die Latenzen oder Zeitüberschreitungen für Lese- und Schreibvorgänge weiter erhöhen kann.
Recovery
Heute startet Amazon OpenSearch Service, um die gewünschte Knotenanzahl der Domäne aufrechtzuerhalten, Datenknoten in den verbleibenden fehlerfreien Availability Zones, ähnlich wie in den oben im Fehlerabschnitt beschriebenen Szenarien. Um nach einem solchen Vorfall eine ordnungsgemäße Knotenverteilung über alle Availability Zones sicherzustellen, war ein manuelles Eingreifen von AWS erforderlich.
Was ändert sich?
Um die Fehlerbehandlung insgesamt zu verbessern und die Auswirkungen von Fehlern auf den Zustand und die Leistung der Domain zu minimieren, führt Amazon OpenSearch Service die folgenden Änderungen durch:
- Bewusstsein für erzwungene Zonen: OpenSearch verfügt über eine bereits vorhandene Shard-Balancing-Konfiguration namens Forced Awareness, die verwendet wird, um die Availability Zones festzulegen, denen Shards zugewiesen werden müssen. Wenn Sie beispielsweise ein Awareness-Attribut namens Zone haben und Knoten in konfigurieren
zone1undzone2, können Sie Forced Awareness verwenden, um zu verhindern, dass OpenSearch Replikate zuweist, wenn nur eine Zone verfügbar ist:
Bei dieser Beispielkonfiguration starten Sie zwei Knoten mit node.attr.zone einstellen zone1 und einen Index mit fünf Shards und einem Replikat erstellen, erstellt OpenSearch den Index und weist die fünf primären Shards, aber keine Replikate zu. Replikate werden nur einmal Knoten mit zugeordnet node.attr.zone einstellen zone2 stehen zur Verfügung.
Amazon OpenSearch Service verwendet die erzwungene Awareness-Konfiguration auf Multi-AZ-Domains, um sicherzustellen, dass Shards nur gemäß den Regeln der Zone Awareness zugewiesen werden. Dies würde den plötzlichen Anstieg der Last auf den Knoten der fehlerfreien Availability Zones verhindern.
- Lastbewusste Shard-Zuweisung: Amazon OpenSearch Service berücksichtigt Faktoren wie die bereitgestellte Kapazität, die tatsächliche Kapazität und die Gesamtzahl der Shard-Kopien, um zu berechnen, ob ein Knoten mit mehr Shards überlastet ist, basierend auf den erwarteten durchschnittlichen Shards pro Knoten. Es würde die Shard-Zuweisung verhindern, wenn ein Knoten eine Shard-Anzahl zugewiesen hat, die diese Grenze überschreitet.
Note dass alle nicht zugewiesen primär Das Kopieren wäre auf dem überlasteten Knoten weiterhin zulässig, um den Cluster vor einem bevorstehenden Datenverlust zu schützen.
Um das Problem der manuellen Wiederherstellung (wie im Abschnitt „Wiederherstellung“ oben beschrieben) zu beheben, nimmt Amazon OpenSearch Service ebenfalls Änderungen an seiner internen Skalierungskomponente vor. Mit den neueren Änderungen startet Amazon OpenSearch Service keine Knoten in den verbleibenden Availability Zones, selbst wenn das zuvor beschriebene Fehlerszenario durchlaufen wird.
Visualisierung des aktuellen und neuen Verhaltens
Beispielsweise ist eine Amazon OpenSearch Service-Domäne mit 3-AZ, 6 Datenknoten, 12 primären Shards und 24 Replikat-Shards konfiguriert. Die Domäne wird über AZ-1, AZ-2 und AZ-3 bereitgestellt, mit zwei Knoten in jeder der Zonen.
Aktuelle Shard-Zuweisung:
Gesamtzahl der Shards: 12 primäre + 24 Replica = 36 Shards
Anzahl der Availability Zones: 3
Anzahl der Shards pro Zone (Zone Awareness ist wahr): 36/3 = 12
Anzahl der Knoten pro Availability Zone: 2
Anzahl der Shards pro Knoten: 12/2 = 6
Das folgende Diagramm bietet eine visuelle Darstellung der Domäneneinrichtung. Die Kreise geben die Anzahl der dem Knoten zugewiesenen Shards an. Amazon OpenSearch Service weist sechs Shards pro Knoten zu.

Bei einem teilweisen Zonenausfall, bei dem ein Knoten in AZ-3 ausfällt, wird der ausgefallene Knoten der verbleibenden Zone zugewiesen, und die Shards in der Zone werden basierend auf den verfügbaren Knoten neu verteilt. Nach den oben beschriebenen Änderungen wird der Cluster keinen neuen Knoten erstellen oder Shards nach dem Ausfall des Knotens neu verteilen.

Im obigen Diagramm würde Amazon OpenSearch Service beim Verlust eines Knotens in AZ-3 versuchen, die Ersatzkapazität in derselben Zone zu starten. Aufgrund eines Ausfalls könnte die Zone jedoch beeinträchtigt sein und den Ersatz nicht starten. In einem solchen Fall versucht der Service, Defizitkapazität in einer anderen fehlerfreien Zone zu starten, was zu einem Zonenungleichgewicht zwischen Availability Zones führen kann. Splitter in der betroffenen Zone werden auf den überlebenden Knoten in derselben Zone gestopft. Mit dem neuen Verhalten würde der Dienst jedoch versuchen, Kapazität in derselben Zone zu starten, aber es vermeiden, Defizitkapazität in anderen Zonen zu starten, um ein Ungleichgewicht zu vermeiden. Der Shard-Allokator würde auch sicherstellen, dass die überlebenden Knoten nicht überlastet werden.

Falls alle Knoten in AZ-3 verloren gehen oder AZ-3 beeinträchtigt wird, bringt Amazon OpenSearch Service die verlorenen Knoten in der verbleibenden Availability Zone hoch und verteilt auch die Shards auf den Knoten neu. Nach den neuen Änderungen wird Amazon OpenSearch Service jedoch weder Knoten der verbleibenden Zone zuweisen noch versuchen, verlorene Shards der verbleibenden Zone neu zuzuweisen. Amazon OpenSearch Service wartet auf die Wiederherstellung und darauf, dass die Domäne nach der Wiederherstellung zur ursprünglichen Konfiguration zurückkehrt.
Wenn Ihre Domäne nicht mit genügend Kapazität ausgestattet ist, um den Verlust einer Availability Zone zu überstehen, kann es zu einem Durchsatzabfall für Ihre Domäne kommen. Es wird daher dringend empfohlen, bei der Dimensionierung Ihrer Domäne die Best Practices zu befolgen, was bedeutet, dass genügend Ressourcen bereitgestellt werden, um den Ausfall eines einzelnen Availability Zone-Ausfalls zu überstehen.

Derzeit erfordert der Dienst nach der Wiederherstellung der Domäne einen manuellen Eingriff, um die Kapazität über die Availability Zones hinweg auszugleichen, was auch Shard-Bewegungen mit sich bringt. Mit dem neuen Verhalten ist jedoch während des Wiederherstellungsprozesses kein Eingreifen erforderlich, da die Kapazität in der betroffenen Zone zurückkehrt und die Shards auch automatisch den wiederhergestellten Knoten zugewiesen werden. Dadurch wird sichergestellt, dass es keine konkurrierenden Prioritäten für die verbleibenden Ressourcen gibt.
Was Sie erwartet
Nachdem Sie Ihre Amazon OpenSearch Service-Domain auf die neueste Version der Service-Software aktualisiert haben, werden die Domains, die mit Best Practices konfiguriert auch nach dem Verlust eines oder mehrerer Datenknoten in einer Availability Zone eine besser vorhersagbare Leistung aufweisen. Es wird weniger Fälle von Shard-Überallokation in einem Knoten geben. Es empfiehlt sich, ausreichend Kapazität bereitzustellen, um einen Ausfall einer einzelnen Zone tolerieren zu können
Bei solchen unerwarteten Ausfällen kann es vorkommen, dass eine Domäne gelb wird, da wir überlasteten Knoten keine Replikat-Shards zuweisen. Dies bedeutet jedoch nicht, dass es in einer gut konfigurierten Domäne zu Datenverlusten kommt. Wir werden weiterhin sicherstellen, dass alle Primärfarben während der Ausfälle zugewiesen werden. Es ist eine automatisierte Wiederherstellung vorhanden, die sich um den Ausgleich der Knoten in der Domäne kümmert und sicherstellt, dass die Replikate zugewiesen werden, sobald der Fehler behoben ist.
Aktualisieren Sie die Service-Software Ihrer Amazon OpenSearch Service-Domain, damit diese neuen Änderungen auf Ihre Domain angewendet werden. Weitere Einzelheiten zum Aktualisierungsprozess der Servicesoftware finden Sie in der Amazon OpenSearch Service-Dokumentation.
Zusammenfassung
In diesem Beitrag haben wir gesehen, wie Amazon OpenSearch Service kürzlich die Logik zur Verteilung von Knoten und Shards über Availability Zones während Zonenausfällen verbessert hat.
Diese Änderung hilft dem Dienst, eine konsistentere und vorhersehbarere Leistung bei Knoten- oder Zonenausfällen sicherzustellen. Domains sehen keine erhöhten Latenzen oder Schreibblöcke während der Verarbeitung von Schreib- und Lesevorgängen, die früher aufgrund der Überzuweisung von Shards auf Knoten auftauchten.
Über die Autoren
 Buchtawar Khan ist Senior Software Engineer und arbeitet am Amazon OpenSearch Service. Er interessiert sich für verteilte und autonome Systeme. Er ist ein aktiver Mitarbeiter von OpenSearch.
Buchtawar Khan ist Senior Software Engineer und arbeitet am Amazon OpenSearch Service. Er interessiert sich für verteilte und autonome Systeme. Er ist ein aktiver Mitarbeiter von OpenSearch.
 Anshu Agarwal ist Senior Software Engineer und arbeitet an AWS OpenSearch bei Amazon Web Services. Ihre Leidenschaft gilt der Lösung von Problemen im Zusammenhang mit dem Aufbau skalierbarer und hochzuverlässiger Systeme.
Anshu Agarwal ist Senior Software Engineer und arbeitet an AWS OpenSearch bei Amazon Web Services. Ihre Leidenschaft gilt der Lösung von Problemen im Zusammenhang mit dem Aufbau skalierbarer und hochzuverlässiger Systeme.
 Shourya Dutta Biswas ist ein Software Engineer, der an AWS OpenSearch bei Amazon Web Services arbeitet. Seine Leidenschaft gilt dem Aufbau hoch belastbarer verteilter Systeme.
Shourya Dutta Biswas ist ein Software Engineer, der an AWS OpenSearch bei Amazon Web Services arbeitet. Seine Leidenschaft gilt dem Aufbau hoch belastbarer verteilter Systeme.
 Rishab Nahata ist ein Software Engineer, der bei Amazon Web Services an OpenSearch arbeitet. Er ist fasziniert davon, Probleme in verteilten Systemen zu lösen. Er ist aktiver Mitarbeiter von OpenSearch.
Rishab Nahata ist ein Software Engineer, der bei Amazon Web Services an OpenSearch arbeitet. Er ist fasziniert davon, Probleme in verteilten Systemen zu lösen. Er ist aktiver Mitarbeiter von OpenSearch.
 Ranjith Ramachandra ist Engineering Manager und arbeitet am Amazon OpenSearch Service bei Amazon Web Services.
Ranjith Ramachandra ist Engineering Manager und arbeitet am Amazon OpenSearch Service bei Amazon Web Services.
 Jon Handler ist Senior Principal Solutions Architect, spezialisiert auf AWS-Suchtechnologien – Amazon CloudSearch und Amazon OpenSearch Service. Von Palo Alto aus unterstützt er ein breites Spektrum von Kunden dabei, ihre Such- und Protokollanalyse-Workloads richtig bereitzustellen und gut zu betreiben.
Jon Handler ist Senior Principal Solutions Architect, spezialisiert auf AWS-Suchtechnologien – Amazon CloudSearch und Amazon OpenSearch Service. Von Palo Alto aus unterstützt er ein breites Spektrum von Kunden dabei, ihre Such- und Protokollanalyse-Workloads richtig bereitzustellen und gut zu betreiben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/
- 1
- 10
- 100
- 7
- 9
- a
- Fähig
- Über Uns
- oben
- unterbringen
- Nach
- über
- aktiv
- Zusätzliche
- Adresse
- Nach der
- Alle
- zugeordnet
- Zuweisen
- Zuteilung
- Amazon
- Amazon Web Services
- Analytik
- und
- Ein anderer
- Anwendung
- angewandt
- zugewiesen
- Attribute
- Automatisiert
- Im Prinzip so, wie Sie es von Google Maps kennen.
- Autonom
- Verfügbarkeit
- verfügbar
- durchschnittlich
- Bewusstsein
- AWS
- Hintergrund
- Balance
- Bandbreite
- basierend
- weil
- wird
- BESTE
- Best Practices
- Besser
- zwischen
- Beyond
- Blockiert
- Brings
- breit
- Building
- namens
- Kann bekommen
- kann keine
- Fähigkeiten
- Kapazität
- österreichische Unternehmen
- Häuser
- Fälle
- Verursachen
- Übernehmen
- Änderungen
- Kreise
- Cloud
- Cluster
- konkurrierenden
- Komponente
- Konzentration
- Konfiguration
- Folgen
- Berücksichtigung
- konsistent
- Beiträger
- Dazugehörigen
- erstellen
- schafft
- Strom
- Kunden
- Zyklen
- technische Daten
- Data Loss
- DEFIZIT
- einsetzen
- Einsatz
- beschrieben
- Details
- anders
- verteilen
- verteilt
- verteilte Systeme
- Verteilung
- Domain
- Domains
- Nicht
- nach unten
- Drop
- im
- jeder
- Früher
- Ingenieur
- Entwicklung
- genug
- gewährleisten
- sorgt
- Gewährleistung
- gleichermaßen
- insbesondere
- Äther (ETH)
- Sogar
- Event
- Beispiel
- erwartet
- ERFAHRUNGEN
- erklärt
- Faktoren
- FAIL
- Gescheitert
- scheitert
- Scheitern
- folgen
- Folgende
- Zwingen
- für
- funktioniert
- weiter
- Allgemeines
- bekommen
- bekommen
- gif
- Goes
- gut
- Handling
- passieren
- mit
- Gesundheit
- gesund
- Hilfe
- hilft
- hier
- hoch
- gehostet
- Ultraschall
- aber
- HTML
- HTTPS
- Unausgewogenheit
- Impact der HXNUMXO Observatorien
- wirkt
- wichtig
- zu unterstützen,
- verbessert
- in
- In anderen
- Zwischenfall
- Erhöhung
- hat
- Index
- Infrastruktur
- Infrastruktur
- Instanz
- interaktive
- interessiert
- intern
- Intervention
- Problem
- IT
- neueste
- starten
- startet
- Start
- führen
- führenden
- Legacy
- LIMIT
- Belastung
- Lang
- verlieren
- Verliert
- verlieren
- Verlust
- halten
- um
- MACHT
- Making
- verwaltet
- Manager
- manuell
- viele
- Mittel
- könnte
- minimieren
- Überwachung
- mehr
- Bewegungen
- mehrere
- Need
- Weder
- Netzwerk
- Neu
- Knoten
- Knotenverteilung
- Fiber Node
- Anzahl
- bieten
- EINEM
- betreiben
- Betrieb
- Einkauf & Prozesse
- Auftrag
- Original
- Andere
- Ausfall
- Ausfälle
- Gesamt-
- überwältigt
- Palo Alto
- Teile
- leidenschaftlich
- ausführen
- Leistung
- Durchführung
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- möglich
- Post
- angetriebene
- Praxis
- Praktiken
- Vorhersagbar
- verhindern
- vorher
- primär
- Principal
- Probleme
- Prozessdefinierung
- Verarbeitung
- ordnungsgemäße
- Resorts
- die
- bietet
- Bereitstellung
- schnell
- Angebot
- Lesen Sie mehr
- Echtzeit
- Gründe
- kürzlich
- empfohlen
- Erholt sich
- Erholung
- Reduziert
- Reduzierung
- bezogene
- Release
- zuverlässig
- verbleibenden
- ersetzen
- antworten
- Darstellung
- representiert
- erfordert
- federnde
- Downloads
- Folge
- Rückkehr
- Rückgabe
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- Said
- gleich
- skalierbaren
- Skalieren
- Skalierung
- Szenarien
- Suche
- Abschnitt
- Verbindung
- Lösungen
- kompensieren
- Setup
- gezeigt
- ähnlich
- da
- Single
- SIX
- schief
- So
- Software
- Software IngenieurIn
- Lösungen
- Auflösung
- einige
- Raumfahrt
- spezialisieren
- Stabilität
- Anfang
- Immer noch
- Lagerung
- starker
- so
- plötzlich
- ausreichend
- Support
- Oberfläche
- Systeme und Techniken
- Nehmen
- nimmt
- Technologies
- Das
- ihr
- deswegen
- Durch
- Durchsatz
- mal
- zu
- heute
- Toleranz
- auch
- Gesamt
- der Verkehr
- auslösen
- was immer dies auch sein sollte.
- Drehung
- Typen
- Unerwartet
- Aktualisierung
- aktualisiert
- -
- Werte
- Vielfalt
- Visualisierung
- warten
- Netz
- Web-Services
- Webseite
- welche
- während
- werden wir
- .
- ohne
- arbeiten,
- würde
- schreiben
- Ihr
- Zephyrnet
- Zonen