
Bild vom Autor
Bei der Analyse der Daten geht es uns darum, verborgene Muster zu finden und aussagekräftige Erkenntnisse zu gewinnen. Betreten wir die neue Kategorie des ML-basierten Lernens, d. h. das unbeaufsichtigte Lernen, bei dem einer der leistungsstarken Algorithmen zur Lösung der Clustering-Aufgaben der K-Means-Clustering-Algorithmus ist, der das Datenverständnis revolutioniert.
K-Means hat sich zu einem nützlichen Algorithmus für maschinelles Lernen und Data-Mining-Anwendungen entwickelt. In diesem Artikel werden wir uns eingehend mit der Funktionsweise von K-Means, seiner Implementierung mit Python und der Erkundung seiner Prinzipien, Anwendungen usw. befassen. Beginnen wir also mit der Reise, um die geheimen Muster zu entschlüsseln und das Potenzial der K-Means auszuschöpfen Clustering-Algorithmus.
Der K-Means-Algorithmus wird verwendet, um die Clustering-Probleme zu lösen, die zur Klasse des unbeaufsichtigten Lernens gehören. Mit Hilfe dieses Algorithmus können wir die Anzahl der Beobachtungen in K Cluster gruppieren.
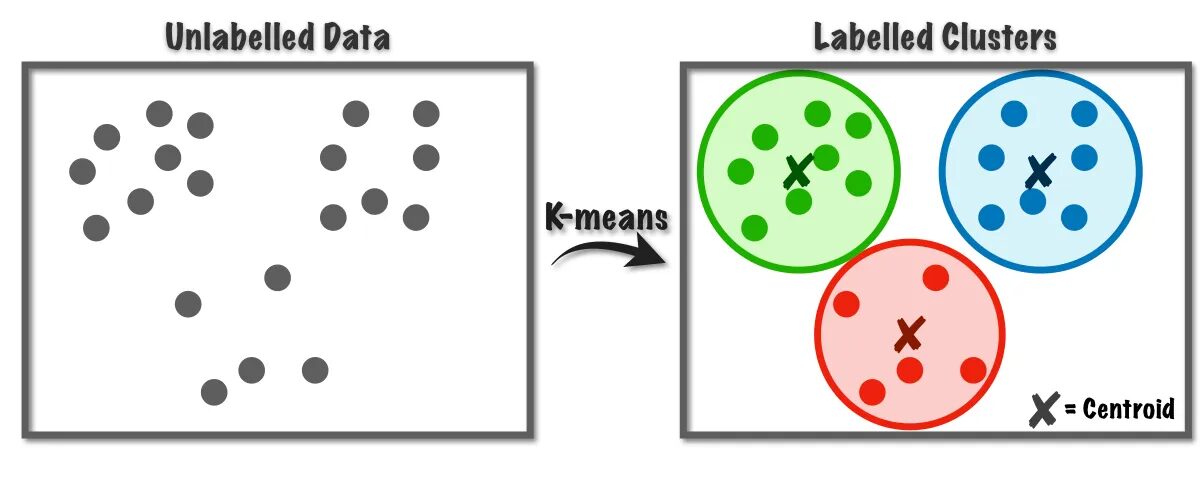
Abb.1 Funktionsweise des K-Means-Algorithmus | Bild von Auf dem Weg zu Data Science
Dieser Algorithmus verwendet intern die Vektorquantisierung, durch die wir jede Beobachtung im Datensatz dem Cluster mit dem minimalen Abstand zuordnen können, der den Prototyp des Clustering-Algorithmus darstellt. Dieser Clustering-Algorithmus wird häufig beim Data Mining und beim maschinellen Lernen zur Datenpartitionierung in K-Cluster basierend auf Ähnlichkeitsmetriken verwendet. Daher müssen wir in diesem Algorithmus den Summenquadratabstand zwischen den Beobachtungen und ihren entsprechenden Schwerpunkten minimieren, was letztendlich zu unterschiedlichen und homogenen Clustern führt.
Anwendungen von K-Means-Clustering
Hier sind einige der Standardanwendungen dieses Algorithmus. Der K-Means-Algorithmus ist eine in industriellen Anwendungsfällen häufig verwendete Technik zur Lösung von Clustering-bezogenen Problemen.
- Kundensegmentierung: K-Means-Clustering kann verschiedene Kunden basierend auf ihren Interessen segmentieren. Es kann auf Bankwesen, Telekommunikation, E-Commerce, Sport, Werbung, Vertrieb usw. angewendet werden.
- Dokumenten-Clustering: Bei dieser Technik werden wir ähnliche Dokumente aus einer Reihe von Dokumenten zusammenfassen, was zu ähnlichen Dokumenten in denselben Clustern führt.
- Empfehlungsmaschinen: Manchmal kann K-Means-Clustering zum Erstellen von Empfehlungssystemen verwendet werden. Sie möchten beispielsweise Ihren Freunden Lieder empfehlen. Sie können sich die Songs ansehen, die dieser Person gefallen, und dann mithilfe von Clustering ähnliche Songs finden und die ähnlichsten empfehlen.
Es gibt noch viele weitere Anwendungen, an die Sie sicher bereits gedacht haben und die Sie wahrscheinlich im Kommentarbereich unter diesem Artikel teilen.
In diesem Abschnitt beginnen wir mit der Implementierung des K-Means-Algorithmus für einen der Datensätze mithilfe von Python, der hauptsächlich in Data Science-Projekten verwendet wird.
1. Importieren Sie die erforderlichen Bibliotheken und Abhängigkeiten
Importieren wir zunächst die Python-Bibliotheken, die wir zur Implementierung des K-Means-Algorithmus verwenden, einschließlich NumPy, Pandas, Seaborn, Marplotlib usw.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. Laden und analysieren Sie den Datensatz
In diesem Schritt laden wir den Schülerdatensatz, indem wir ihn im Pandas-Datenrahmen speichern. Um den Datensatz herunterzuladen, können Sie auf den Link verweisen hier.
Die vollständige Pipeline des Problems ist unten dargestellt:

Abb. 2 Projektpipeline | Bild vom Autor
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. Streudiagramm des Datensatzes
Der Schritt der Modellierung besteht nun darin, die Daten zu visualisieren. Daher verwenden wir matplotlib, um das Streudiagramm zu zeichnen, um zu überprüfen, wie der Clustering-Algorithmus funktioniert, und um verschiedene Cluster zu erstellen.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
Ausgang:
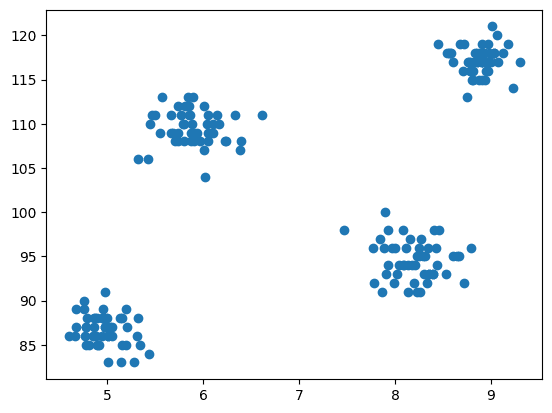
Abb.3 Streudiagramm | Bild vom Autor
4. Importieren Sie die K-Means aus der Cluster-Klasse von Scikit-learn
Da wir nun das K-Means-Clustering implementieren müssen, importieren wir zunächst die Cluster-Klasse und haben dann KMeans als Modul dieser Klasse.
from sklearn.cluster import KMeans5. Ermitteln des optimalen Werts von K mithilfe der Ellbogenmethode
In diesem Schritt ermitteln wir den optimalen Wert von K, einem der Hyperparameter, während wir den Algorithmus implementieren. Der K-Wert gibt an, wie viele Cluster wir für unseren Datensatz erstellen müssen. Es ist nicht möglich, diesen Wert intuitiv zu finden. Um den optimalen Wert zu finden, erstellen wir ein Diagramm zwischen WCSS (Quadratsumme innerhalb des Clusters) und verschiedenen K-Werten und müssen das K auswählen, das gibt uns den Mindestwert von WCSS.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
Lassen Sie uns nun das Ellbogendiagramm zeichnen, um den optimalen Wert von K zu ermitteln.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
Ausgang:
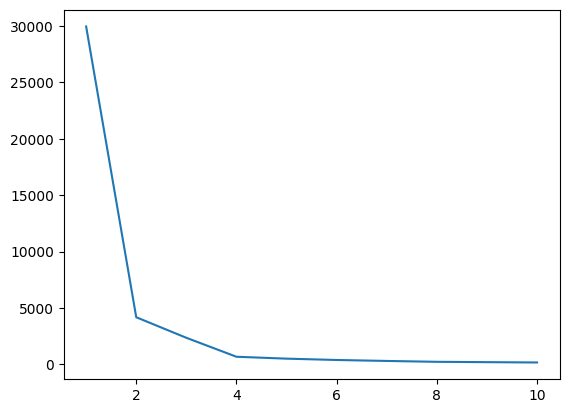
Abb.4 Ellenbogendiagramm | Bild vom Autor
Aus dem obigen Ellbogendiagramm können wir bei K=4 erkennen; Es gibt einen Abfall im Wert von WCSS. Wenn wir also den optimalen Wert 4 verwenden, erhalten Sie durch das Clustering eine gute Leistung.
6. Passen Sie den K-Means-Algorithmus mit dem optimalen Wert von K an
Wir sind damit fertig, den optimalen Wert von K zu finden. Jetzt führen wir die Modellierung durch, bei der wir ein X-Array erstellen, das den vollständigen Datensatz mit allen Funktionen speichert. Es besteht hier keine Notwendigkeit, Ziel- und Merkmalsvektor zu trennen, da es sich um ein unbeaufsichtigtes Problem handelt. Danach erstellen wir ein Objekt der KMeans-Klasse mit einem ausgewählten K-Wert und passen diesen dann an den bereitgestellten Datensatz an. Schließlich drucken wir y_means aus, das die Mittelwerte der verschiedenen gebildeten Cluster angibt.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. Überprüfen Sie die Clusterzuordnung jeder Kategorie
Lassen Sie uns überprüfen, welche Punkte im Datensatz zu welchem Cluster gehören.
X[y_means == 3,1]
Bisher haben wir für die Schwerpunktinitialisierung die K-Means++-Strategie verwendet. Jetzt initialisieren wir die zufälligen Schwerpunkte anstelle von K-Means++ und vergleichen die Ergebnisse, indem wir dem gleichen Prozess folgen.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Überprüfen Sie, wie viele Werte übereinstimmen.
sum(y_means == y_means_new)8. Visualisierung der Cluster
Um jeden Cluster zu visualisieren, zeichnen wir ihn auf den Achsen auf und weisen ihm verschiedene Farben zu, anhand derer wir die gebildeten 4 Cluster leicht erkennen können.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
Ausgang:
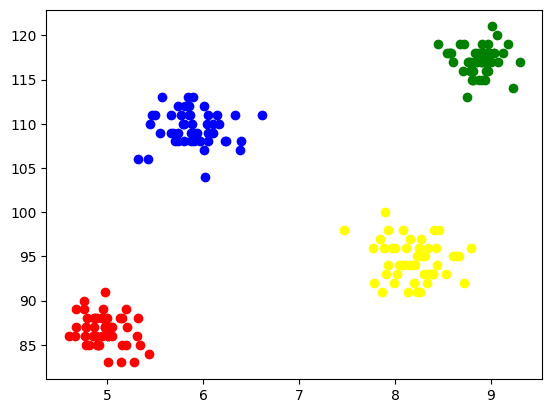
Abb. 5 Visualisierung der gebildeten Cluster | Bild vom Autor
9. K-Means auf 3D-Daten
Da der vorherige Datensatz zwei Spalten hat, haben wir ein 2D-Problem. Jetzt werden wir die gleichen Schritte für ein 2D-Problem verwenden und versuchen, die Code-Reproduzierbarkeit für n-dimensionale Daten zu analysieren.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
Ausgang:
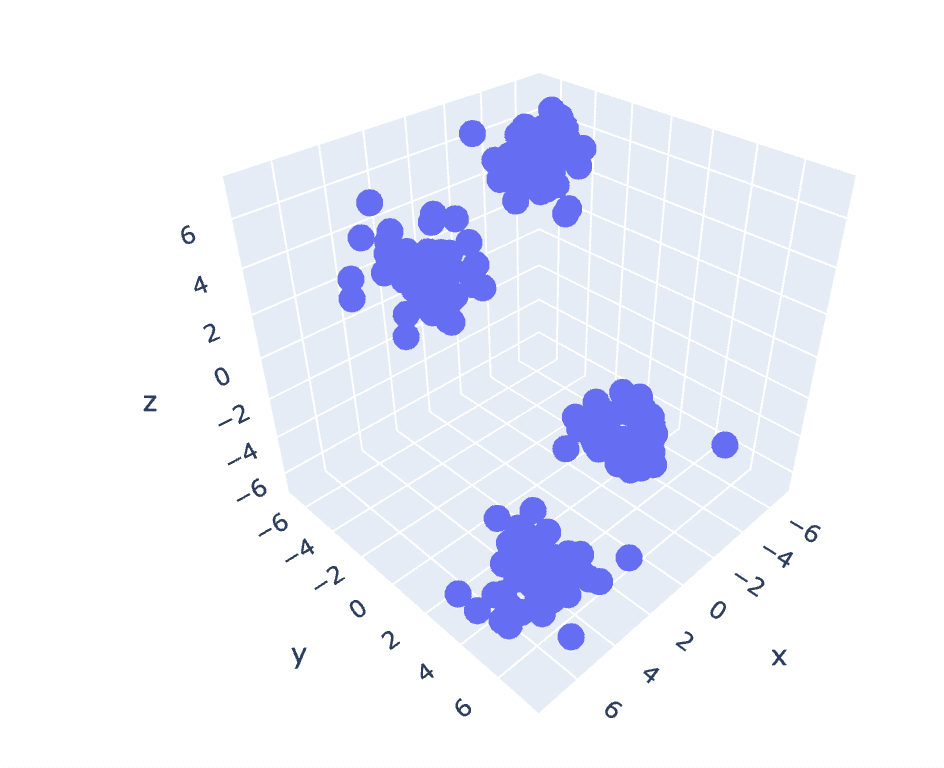
Abb. 6 Streudiagramm eines 3D-Datensatzes | Bild vom Autor
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
Ausgang:

Abb.7 Ellenbogendiagramm | Bild vom Autor
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
Ausgang:
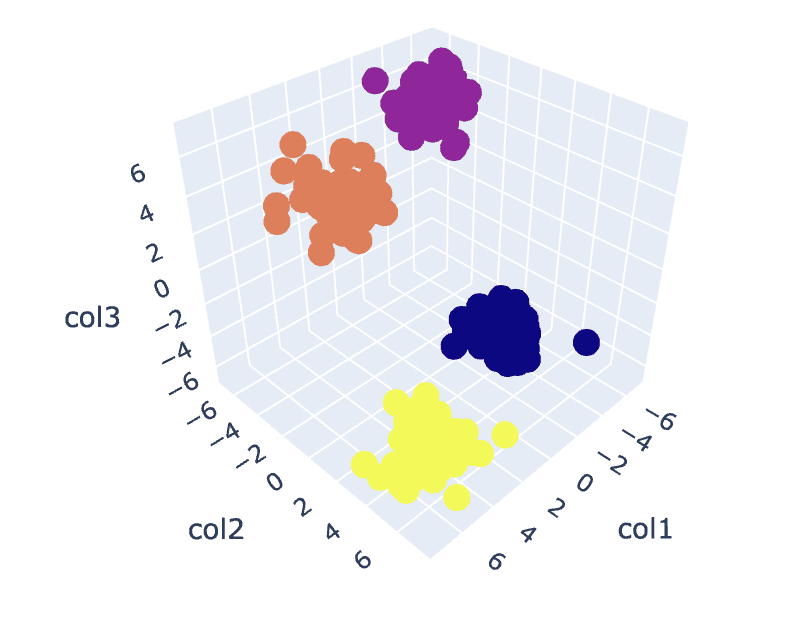
Abb.8. Cluster-Visualisierung | Bild vom Autor
Den vollständigen Code finden Sie hier – Colab-Notizbuch
Damit ist unsere Diskussion abgeschlossen. Wir haben die Funktionsweise, Implementierung und Anwendungen von K-Means besprochen. Zusammenfassend lässt sich sagen, dass es sich bei der Implementierung der Clustering-Aufgaben um einen weit verbreiteten Algorithmus aus der Klasse des unbeaufsichtigten Lernens handelt, der einen einfachen und intuitiven Ansatz zum Gruppieren der Beobachtungen eines Datensatzes bietet. Die Hauptstärke dieses Algorithmus besteht darin, die Beobachtungen mithilfe des Benutzers, der den Algorithmus implementiert, auf der Grundlage der ausgewählten Ähnlichkeitsmetriken in mehrere Sätze aufzuteilen.
Basierend auf der Auswahl der Schwerpunkte im ersten Schritt verhält sich unser Algorithmus jedoch anders und konvergiert zu lokalen oder globalen Optima. Daher ist die Auswahl der Anzahl der Cluster zur Implementierung des Algorithmus, die Vorverarbeitung der Daten, der Umgang mit Ausreißern usw. von entscheidender Bedeutung, um gute Ergebnisse zu erzielen. Wenn wir jedoch die andere Seite dieses Algorithmus hinter den Einschränkungen betrachten, ist K-Means eine hilfreiche Technik für die explorative Datenanalyse und Mustererkennung in verschiedenen Bereichen.
Arischer Garg ist ein B.Tech. Student der Elektrotechnik, derzeit im letzten Jahr seines Studiums. Sein Interesse liegt im Bereich Webentwicklung und maschinelles Lernen. Er hat dieses Interesse verfolgt und ist bestrebt, mehr in diese Richtungen zu arbeiten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :hast
- :Ist
- :nicht
- :Wo
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- oben
- Marketings
- Nach der
- Algorithmus
- Algorithmen
- Alle
- bereits
- am
- an
- analysieren
- Analyse
- analysieren
- Analyse
- und
- Anwendungen
- angewandt
- Ansatz
- SIND
- Feld
- Artikel
- AS
- At
- ACHSEN
- b
- Bankinggg
- basierend
- BE
- werden
- hinter
- unten
- zwischen
- Blau
- Building
- aber
- by
- CAN
- Häuser
- Fälle
- Kategorie
- aus der Ferne überprüfen
- Auswählen
- Klasse
- Club
- Cluster
- Clustering
- Code
- Spalten
- kommt
- Bemerkungen
- häufig
- vergleichen
- abschließen
- Wird abgeschlossen
- Abschluss
- Dazugehörigen
- erstellen
- wichtig
- Zur Zeit
- Kunde
- Kunden
- technische Daten
- Datenanalyse
- Data Mining
- Datenwissenschaft
- Datensätze
- tief
- Tieftauchgang
- Entwicklung
- anders
- Tauchen
- Richtungen
- diskutiert
- Diskussion
- Abstand
- deutlich
- do
- Dokument
- Unterlagen
- erledigt
- herunterladen
- zeichnen
- e
- e-commerce
- jeder
- begierig
- leicht
- Elektrotechnik
- Entwicklung
- Motor (en)
- Enter
- etc
- schließlich
- Beispiel
- Explorative Datenanalyse
- Möglichkeiten sondieren
- express
- Extrakt
- Merkmal
- Eigenschaften
- Feld
- Felder
- Feige
- Finale
- Endlich
- Finden Sie
- Suche nach
- Vorname
- passen
- Folgende
- Aussichten für
- gebildet
- Freunde
- für
- ABSICHT
- gibt
- Global
- gehen
- gut
- Grün
- Gruppe an
- Handling
- Geschirr
- Haben
- mit
- he
- Hilfe
- hilfreich
- hier
- versteckt
- seine
- Ultraschall
- HTTPS
- i
- if
- Image
- implementieren
- Implementierung
- Umsetzung
- importieren
- in
- Einschließlich
- zeigt
- industriell
- Trägheit
- Einblicke
- beantragen müssen
- Interesse
- Interessen
- innen
- in
- intuitiv
- IT
- SEINE
- Reise
- jpg
- KDnuggets
- Label
- lernen
- Bibliotheken
- liegt
- Einschränkungen
- LINK
- Liste
- Belastung
- aus einer regionalen
- aussehen
- Maschine
- Maschinelles Lernen
- Main
- hauptsächlich
- um
- viele
- Spiel
- Matplotlib
- sinnvoll
- Mittel
- Metrik
- Geist / Bewusstsein
- Minimum
- Bergbau
- Modell
- Modellieren
- Modulen
- mehr
- vor allem warme
- mehrere
- sollen
- notwendig,
- Need
- Neu
- nicht
- jetzt an
- Anzahl
- numpig
- Objekt
- beobachten
- erhalten
- of
- on
- EINEM
- Einsen
- optimal
- or
- Andere
- UNSERE
- Pandas
- passieren
- Schnittmuster
- Muster
- Leistung
- person
- Pipeline
- Plato
- Datenintelligenz von Plato
- PlatoData
- Punkte
- möglich
- Potenzial
- größte treibende
- früher
- Grundsätze
- wahrscheinlich
- Aufgabenstellung:
- Probleme
- Prozessdefinierung
- Projekt
- Projekte
- Prototyp
- vorausgesetzt
- bietet
- Python
- zufällig
- Anerkennung
- empfehlen
- Software Empfehlungen
- Rot
- Forschungsprojekte
- was zu
- Die Ergebnisse
- revolutioniert
- s
- Vertrieb
- gleich
- Wissenschaft
- Seeschneur
- Die Geheime
- Abschnitt
- sehen
- Segment
- Segmentierung
- ausgewählt
- Auswahl
- Auswahl
- getrennte
- kompensieren
- Sets
- Form
- Teilen
- gezeigt
- Seite
- bedeutet
- ähnlich
- Einfacher
- So
- LÖSEN
- Auflösung
- einige
- Sports
- Quadrate
- Standard
- Anfang
- Schritt
- Shritte
- speichern
- Läden
- Strategie
- Stärke
- Schüler und Studenten
- sicher
- synthetisch
- Systeme und Techniken
- Target
- und Aufgaben
- Tech
- Telekom
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Dort.
- deswegen
- Diese
- Ding
- fehlen uns die Worte.
- dachte
- Durch
- zu
- versuchen
- Verständnis
- entfesselt
- öffnen
- unbeaufsichtigtes Lernen
- us
- -
- benutzt
- Mitglied
- verwendet
- Verwendung von
- Nutzen
- Wert
- Werte
- verschiedene
- Visualisierung
- vs
- wollen
- we
- Netz
- Web-Entwicklung
- welche
- während
- WHO
- weit
- werden wir
- mit
- Arbeiten
- arbeiten,
- Arbeiten
- Werk
- X
- Jahr
- gelben
- U
- Ihr
- Zephyrnet








