Bild vom Autor
Csvkit ist ein König der tabellarischen Daten. Es verfügt über eine Sammlung von Tools, mit denen CSV-Dateien konvertiert, die Daten bearbeitet und Datenanalysen durchgeführt werden können.
Sie können installieren csvkit mit Pip.
$ pip install csvkitBeispiel 1
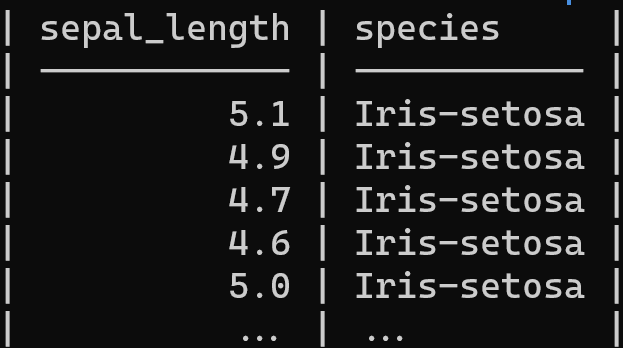
In diesem Beispiel verwenden wir csvcut, um nur zwei Spalten auszuwählen, und verwenden csvlook, um die Ergebnisse im Tabellenformat anzuzeigen.
csvcut -c sepal_length,species iris.csv | csvlook --max-rows 5
Hinweis: Sie können die Anzahl der Zeilen mit dem Argument begrenzen --max-rows
Beispiel 2
Wir konvertieren eine CSV-Datei mit csvjson in eine JSON-Datei.
csvjson iris.csv > iris.json
Hinweis: csvkit bietet uns auch Excel-zu-CSV- und JSON-zu-CSV-Tools.
Beispiel 3
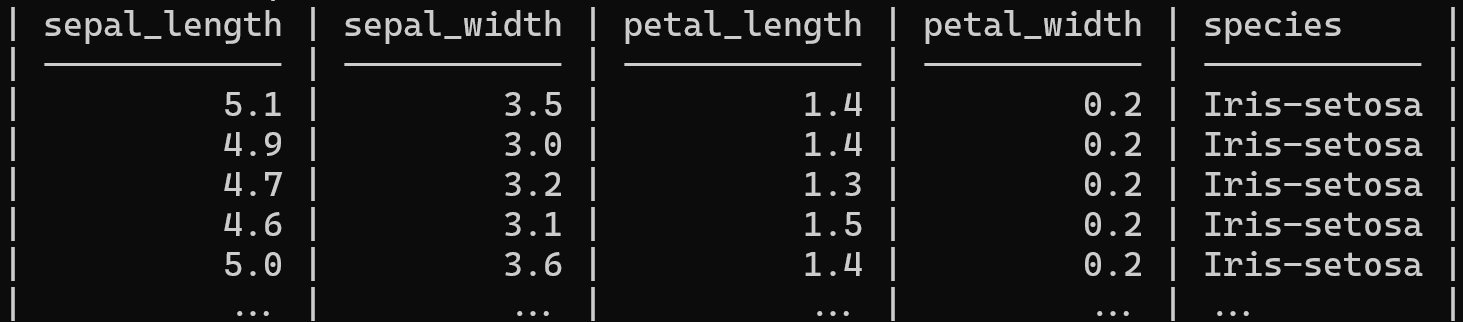
Wir können auch eine Datenanalyse an einer CSV-Datei durchführen, indem wir eine SQL-Abfrage verwenden. Csvsql erfordert SQL-Abfrage und CSV-Dateipfad Sie können die Ergebnisse anzeigen oder in CSV speichern.
csvsql --query "select * from iris where species like 'Iris-setosa'" iris.csv | csvlook --max-rows 5
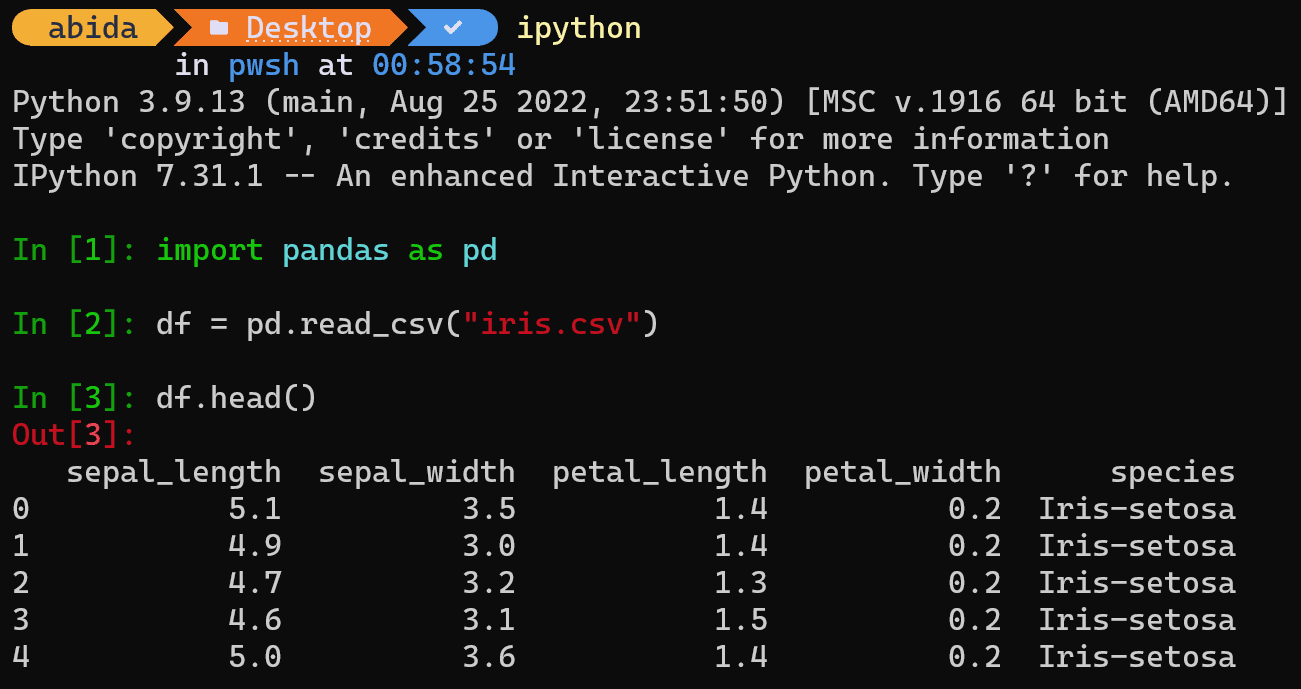
IPython ist eine interaktive Python-Shell, die einige Funktionen eines Jupyter-Notebooks in Ihr Terminal bringt. Sie können Ideen schneller testen, ohne eine Python-Datei zu erstellen.
Installieren ipython mit Pip-Install.
$ pip install ipython
Hinweis: Ipython wird auch mit Anaconda und Jupyter Notebook geliefert. In den meisten Fällen müssen Sie es also nicht installieren.
Geben Sie nach der Installation einfach ein ipython im Terminal und beginnen Sie mit der Datenanalyse, genau wie Sie es in Jupyter-Notebooks tun. Es ist einfach und schnell.
cURL steht für Client-URL und ist ein CLI-Tool zum Übertragen von Daten zum und vom Server mithilfe von URLs. Sie können damit die Rate begrenzen, Fehler protokollieren, den Fortschritt anzeigen und Endpunkte testen.
Im Beispiel laden wir die Machine-Learning-Daten von der University of California herunter und speichern sie als CSV-Datei.
curl -o blood.csv https://archive.ics.uci.edu/ml/machine-learning-databases/blood-transfusion/transfusion.data
Ausgang:
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed
100 12843 100 12843 0 0 7772 0 0:00:01 0:00:01 --:--:-- 7769
Sie können cURL verwenden, um mit Token auf APIs zuzugreifen, Dateien zu pushen und die Datenpipelines zu automatisieren.
Awk ist eine Terminal-Skriptsprache, mit der wir die Daten manipulieren und Datenanalysen durchführen können. Es bedarf keiner Klage. Wir können Variablen, numerische Funktionen, Zeichenfolgenfunktionen und logische Operatoren verwenden, um jede Art von Skript zu schreiben.
Im Beispiel zeigen wir die erste und letzte Spalte der CSV-Datei und die letzten 10 Zeilen. Das $1 im Skript bedeutet die ersten Spalten. Sie können es auch in $3 ändern, um die dritte Spalte anzuzeigen. Das $NF repräsentiert die letzten Spalten.
awk -F "," '{print $1 " | " $NF}' iris.csv | tail

Kaggle-API ermöglicht es Ihnen, alle Arten von Datensätzen von der Kaggle-Website herunterzuladen. Darüber hinaus können Sie Ihren öffentlichen Datensatz aktualisieren, die Datei beim Wettbewerb einreichen und Jupyter Notebook ausführen und verwalten. Es ist ein super Kommandozeilen-Tool.
Installieren Sie die Kaggle-API mit pip.
$ pip install kaggle
Danach gehen Sie zum Kaggle Website und erhalten Sie Ihre Anmeldeinformationen. Du kannst Folgen fehlen uns die Worte. Anleitung zum Einrichten Ihres Benutzernamens und privaten Schlüssels.
export KAGGLE_USERNAME=kingabzpro
export KAGGLE_KEY=xxxxxxxxxxxxxxBeispiel 1
Nachdem Sie die Authentifizierung eingerichtet haben, können Sie nach zufälligen Datensätzen suchen. In unserem Fall verwenden wir die Umfrage zu Beschäftigungstrends Datensatz.
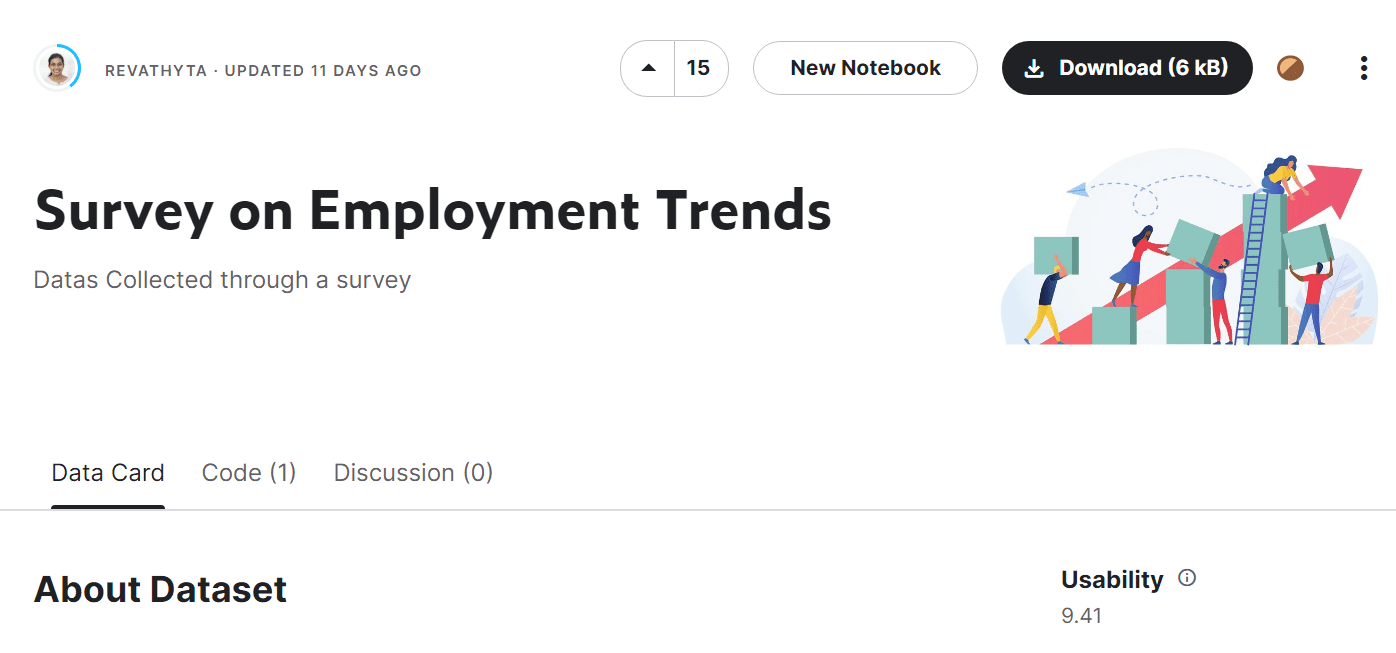
Bild aus Umfrage zu Beschäftigungstrends
Sie können das Download-Skript entweder mit ausführen -d Argument BENUTZERNAME/DATENSATZ.
$ kaggle datasets download -d revathyta/survey-on-employment-trends
Oder,
Sie können einfach den API-Befehl abrufen, indem Sie auf die drei Punkte klicken und die Option „API-Befehl kopieren“ auswählen.
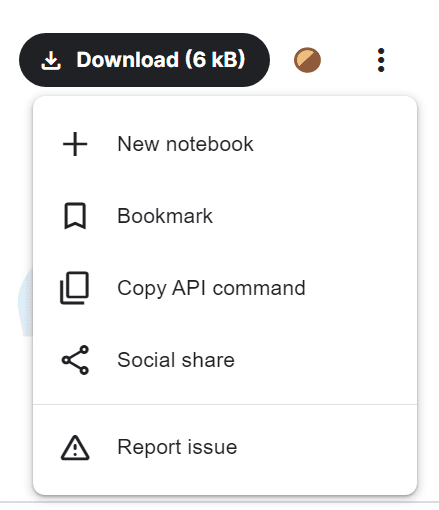
Bild aus Umfrage zu Beschäftigungstrends
Der Datensatz wird in Form einer ZIP-Datei heruntergeladen. Sie können das Skript auch mit dem pipen unzip Befehl zum Extrahieren der Daten.
Downloading survey-on-employment-trends.zip to C:Usersabida 0%| | 0.00/6.22k [00:00<?, ?B/s] 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 6.22k/6.22k [00:00<?, ?B/s]Beispiel 2
Um Ihren Datensatz auf Kaggle zu erstellen und zu teilen, müssen Sie zunächst eine Metadatendatei erstellen, indem Sie den Pfad des Datensatzes angeben.
$ kaggle datasets init -p /work/Kaggle/World-Vaccine-Progress
Erstellen Sie danach das Dataset und übertragen Sie die Datei auf den Kaggle-Server.
$ kaggle datasets create -p /work/Kaggle/World-Vaccine-Progress
Sie können Ihren Datensatz auch aktualisieren, indem Sie die verwenden version Befehl. Es erfordert einen Dateipfad und eine Nachricht. Genau wie Git.
$ kaggle datasets version -p /work/Kaggle/World-Vaccine-Progress -m "second version"
Sie können sich auch mein Projekt ansehen Impfstoffaktualisierungs-Dashboard das die Kaggle-API erfolgreich implementiert hat, um den Datensatz regelmäßig zu aktualisieren.
Es gibt so viele erstaunliche CLI-Tools, die ich verwende, und sie haben meine Produktivität verbessert und mir geholfen, den größten Teil meiner Arbeit zu automatisieren. Sie können sogar Ihr eigenes CLI-Tool in Python mit click oder argparse erstellen.
In diesem Artikel haben wir CLI-Tools kennengelernt, um das Dataset herunterzuladen, zu manipulieren, Analysen durchzuführen, Skripte auszuführen und Berichte zu erstellen.
Ich bin ein Fan der Kaalgle-API und des csvkit. Ich verwende es regelmäßig, um meine Notizbücher und Analysen zu automatisieren. Wenn Sie lernen möchten, wie Sie Befehlszeilentools in Ihrem Data-Science-Workflow verwenden, lesen Sie Data Science an der Kommandozeile kostenlos online buchen.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, Modelle für maschinelles Lernen zu erstellen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und schreibt technische Blogs zu maschinellem Lernen und Data-Science-Technologien. Abid hat einen Master-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Vision ist es, ein KI-Produkt mit einem grafisch-neuronalen Netzwerk für Schüler zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/03/5-command-line-tools-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=5-more-command-line-tools-for-data-science
- :Ist
- $3
- $UP
- 10
- 100
- 7
- 8
- a
- Über uns
- Zugriff
- AI
- Alle
- erlaubt
- erstaunlich
- Analyse
- machen
- Bienen
- APIs
- SIND
- Argument
- Artikel
- AS
- At
- Authentifizierung
- automatisieren
- durchschnittlich
- BE
- Blogs
- Blut
- buchen
- Brings
- bauen
- Building
- by
- Kalifornien
- CAN
- Häuser
- Fälle
- Zertifzierte
- Übernehmen
- aus der Ferne überprüfen
- klicken Sie auf
- Auftraggeber
- Sammlung
- Kolonne
- Spalten
- Wettbewerb
- Inhalt
- verkaufen
- erstellen
- Erstellen
- Schaffung
- Referenzen
- Strom
- Zur Zeit
- technische Daten
- Datenanalyse
- Datenwissenschaft
- Datenwissenschaftler
- Datensätze
- Grad
- Display
- Anzeige
- Nicht
- herunterladen
- entweder
- Beschäftigung
- Entwicklung
- Fehler
- Äther (ETH)
- Sogar
- Beispiel
- Excel
- exportieren
- Extrakt
- Extrahieren Sie die Daten
- Fan
- FAST
- beschleunigt
- Reichen Sie das
- Mappen
- Vorname
- Fokussierung
- folgen
- Aussichten für
- unten stehende Formular
- Format
- Frei
- für
- Funktionsumfang
- Funktionen
- Außerdem
- erzeugen
- bekommen
- Git
- Go
- Graph
- Graph Neuronales Netzwerk
- Guide
- Haben
- dazu beigetragen,
- hält
- Ultraschall
- Hilfe
- HTML
- HTTPS
- i
- ICS
- Ideen
- Krankheit
- umgesetzt
- verbessert
- in
- initiieren
- installieren
- Installieren
- interaktive
- IT
- JSON
- Jupyter Notizbuch
- KDnuggets
- Wesentliche
- King
- Sprache
- Nachname
- LERNEN
- gelernt
- lernen
- Gefällt mir
- LIMIT
- Line
- logisch
- Maschine
- Maschinelles Lernen
- verwalten
- Management
- viele
- Master
- Mittel
- geistig
- Geisteskrankheit
- Nachricht
- Metadaten
- für
- mehr
- vor allem warme
- Need
- Netzwerk
- Neural
- neuronale Netzwerk
- Notizbuch
- Laptops
- Anzahl
- of
- on
- Online
- Betreiber
- Option
- besitzen
- Weg
- ausführen
- Durchführung
- Rohr
- Plato
- Datenintelligenz von Plato
- PlatoData
- privat
- Private Key
- Produkt
- PRODUKTIVITÄT
- Professionell
- Fortschritt
- Projekt
- bietet
- Bereitstellung
- Öffentlichkeit
- Push
- Python
- zufällig
- Bewerten
- Lesen Sie mehr
- Received
- regelmäßig
- Meldungen
- representiert
- erfordert
- Die Ergebnisse
- Führen Sie
- s
- Speichern
- Einsparung
- Wissenschaft
- Wissenschaftler
- Skripte
- Suche
- Zweite
- Auswahl
- kompensieren
- Einstellung
- Teilen
- Schale
- einfach
- So
- einige
- Geschwindigkeit
- verbrachte
- SQL
- steht
- Anfang
- Struggling
- Die Kursteilnehmer
- abschicken
- Erfolgreich
- Super
- Technische
- Technologies
- Technologie
- Telekommunikations
- Terminal
- Test
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- nach drei
- Zeit
- zu
- Tokens
- Werkzeug
- Werkzeuge
- Gesamt
- Übertragen
- Universität
- University of California
- Aktualisierung
- URL
- us
- -
- Version
- Seh-
- Webseite
- welche
- WHO
- werden wir
- mit
- ohne
- Arbeiten
- Arbeitsablauf.
- schreiben
- Schreiben
- Ihr
- Zephyrnet
- PLZ








