Bild vom Herausgeber
Am 14. März 2023 brachte OpenAI GPT-4 auf den Markt, die neueste und leistungsstärkste Version ihres Sprachmodells.
Innerhalb weniger Stunden nach seinem Start verblüffte GPT-4 die Menschen, indem es ein drehte handgezeichnete Skizze in eine funktionale Website, Bestehen der Anwaltsprüfung und Erstellung genauer Zusammenfassungen von Wikipedia-Artikeln.
Es übertrifft auch seinen Vorgänger GPT-3.5 bei der Lösung mathematischer Probleme und der Beantwortung von Fragen, die auf Logik und Argumentation basieren.
ChatGPT, der Chatbot, der auf GPT-3.5 aufgebaut und für die Öffentlichkeit freigegeben wurde, war berüchtigt für „Halluzinationen“. Es generierte Antworten, die scheinbar richtig waren, und verteidigte seine Antworten mit „Fakten“, obwohl sie voller Fehler waren.
Ein Benutzer ging zu Twitter, nachdem das Modell darauf bestanden hatte, dass Elefanteneier die größten aller Landtiere seien:
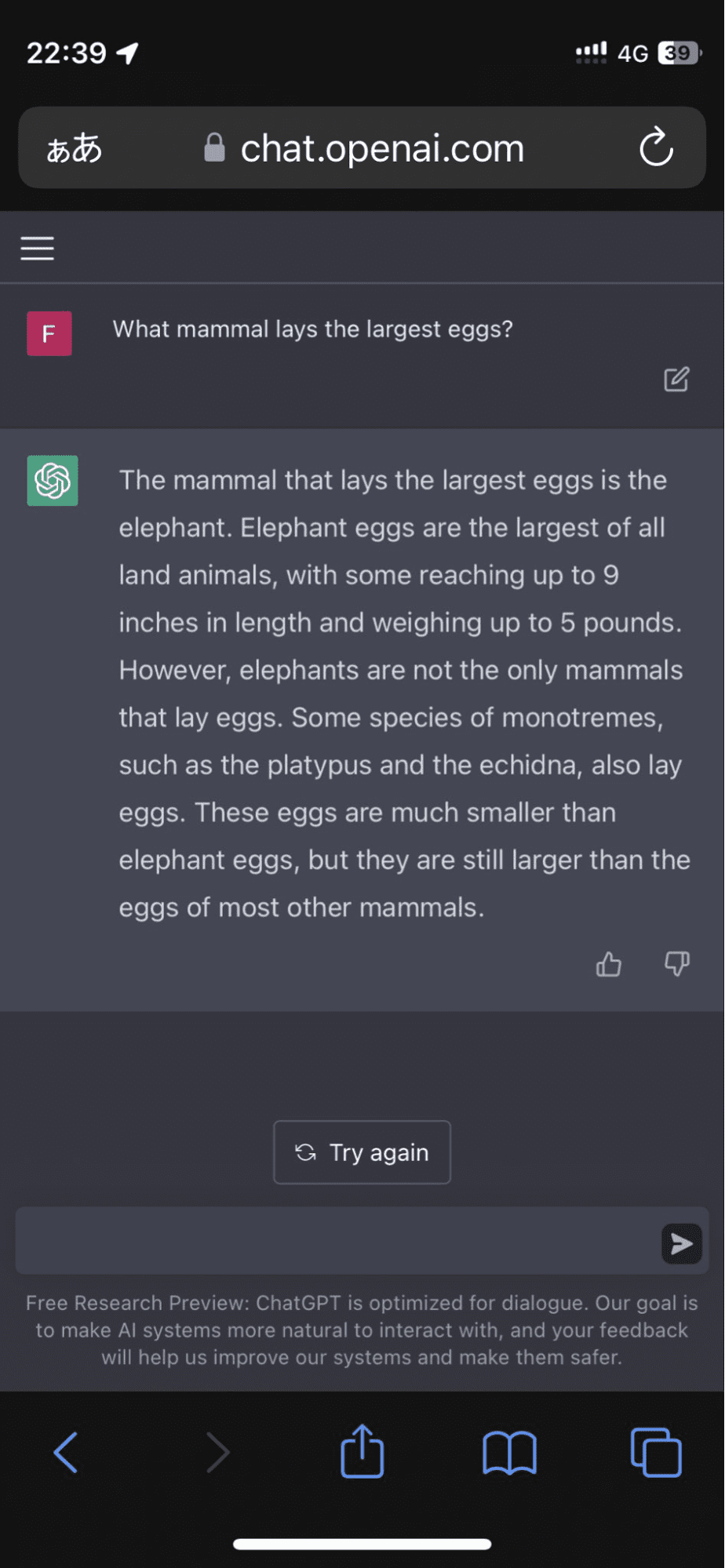
Bild aus FioraAeterna
Und dabei blieb es nicht. Der Algorithmus untermauerte seine Antwort mit erfundenen Fakten, die mich für einen Moment fast überzeugten.
GPT-4 hingegen wurde darauf trainiert, seltener zu „halluzinieren“. Das neueste Modell von OpenAI ist schwerer auszutricksen und erzeugt nicht so oft selbstbewusst Unwahrheiten.
Als Data Scientist muss ich relevante Datenquellen finden, große Datensätze vorverarbeiten und hochpräzise Modelle für maschinelles Lernen erstellen, die den Geschäftswert steigern.
Ich verbringe einen großen Teil meines Tages damit, Daten aus verschiedenen Dateiformaten zu extrahieren und an einem Ort zu konsolidieren.
Nachdem ChatGPT im November 2022 zum ersten Mal eingeführt wurde, suchte ich nach Hilfe des Chatbots für meine täglichen Arbeitsabläufe. Ich habe das Tool verwendet, um den Zeitaufwand für Nebenarbeiten zu sparen und mich stattdessen auf die Entwicklung neuer Ideen und die Erstellung besserer Modelle konzentrieren zu können.
Als GPT-4 veröffentlicht wurde, war ich neugierig, ob es einen Unterschied in meiner Arbeit machen würde. Gab es wesentliche Vorteile bei der Verwendung von GPT-4 gegenüber seinen Vorgängern? Würde es mir helfen, mehr Zeit zu sparen, als ich mit GPT-3.5 bereits war?
In diesem Artikel zeige ich Ihnen, wie ich ChatGPT verwende, um Data-Science-Workflows zu automatisieren.
Ich werde die gleichen Eingabeaufforderungen erstellen und sie sowohl in GPT-4 als auch in GPT-3.5 einspeisen, um zu sehen, ob erstere tatsächlich besser funktioniert und zu mehr Zeitersparnis führt.
Wenn Sie alles mitverfolgen möchten, was ich in diesem Artikel mache, müssen Sie Zugriff auf GPT-4 und GPT-3.5 haben.
GPT-3.5
GPT-3.5 ist auf der Website von OpenAI öffentlich verfügbar. Navigieren Sie einfach zu https://chat.openai.com/auth/login, füllen Sie die erforderlichen Details aus und Sie erhalten Zugriff auf das Sprachmodell:
Bild aus ChatGPT
GPT-4
GPT-4 hingegen verbirgt sich derzeit hinter einer Paywall. Um auf das Modell zugreifen zu können, müssen Sie auf ChatGPTPlus upgraden, indem Sie auf „Upgrade to Plus“ klicken.
Es gibt eine monatliche Abonnementgebühr von 20 $/Monat, die jederzeit gekündigt werden kann:
Bild aus ChatGPT
Wenn Sie die monatliche Abonnementgebühr nicht bezahlen möchten, können Sie auch dem beitreten API-Warteliste für GPT-4. Sobald Sie Zugriff auf die API erhalten haben, können Sie folgen fehlen uns die Worte. Anleitung zur Verwendung in Python.
Es ist in Ordnung, wenn Sie derzeit keinen Zugriff auf GPT-4 haben.
Sie können diesem Tutorial weiterhin mit der kostenlosen Version von ChatGPT folgen, die GPT-3.5 im Backend verwendet.
1. Datenvisualisierung
Wenn ich eine explorative Datenanalyse durchführe, hilft mir das Generieren einer schnellen Visualisierung in Python oft dabei, den Datensatz besser zu verstehen.
Leider kann diese Aufgabe unglaublich zeitaufwändig werden – insbesondere, wenn Sie nicht die richtige Syntax kennen, mit der Sie das gewünschte Ergebnis erzielen.
Ich finde mich oft dabei, die umfangreiche Dokumentation von Seaborn zu durchsuchen und StackOverflow zu verwenden, um einen einzelnen Python-Plot zu generieren.
Mal sehen, ob ChatGPT helfen kann, dieses Problem zu lösen.
Wir werden das benutzen Pima-Indianer Diabetes Datensatz in diesem Abschnitt. Sie können den Datensatz herunterladen, wenn Sie die von ChatGPT generierten Ergebnisse verfolgen möchten.
Nachdem wir den Datensatz heruntergeladen haben, laden wir ihn mithilfe der Pandas-Bibliothek in Python und drucken den Kopf des Datenrahmens:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
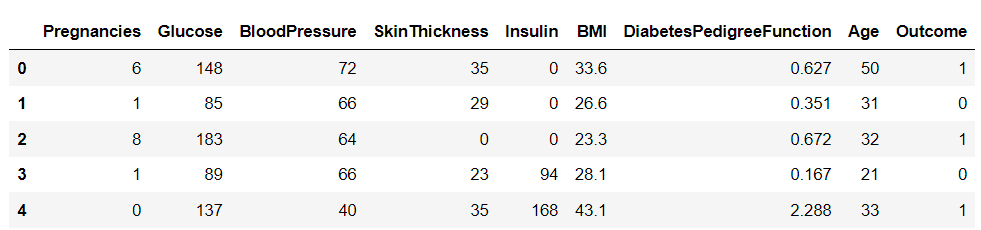
Es gibt neun Variablen in diesem Datensatz. Eine davon, „Outcome“, ist die Zielvariable, die uns sagt, ob eine Person Diabetes entwickeln wird. Die verbleibenden sind unabhängige Variablen, die zur Vorhersage des Ergebnisses verwendet werden.
Okay! Ich möchte also sehen, welche dieser Variablen einen Einfluss darauf haben, ob eine Person Diabetes entwickelt.
Um dies zu erreichen, können wir ein gruppiertes Balkendiagramm erstellen, um die Variable „Diabetes“ über alle abhängigen Variablen im Datensatz hinweg zu visualisieren.
Das ist eigentlich ziemlich einfach zu programmieren, aber fangen wir einfach an. Wir werden im Laufe des Artikels zu komplizierteren Eingabeaufforderungen übergehen.
Datenvisualisierung mit GPT-3.5
Da ich ein kostenpflichtiges ChatGPT-Abonnement habe, kann ich mit dem Tool bei jedem Zugriff das zugrunde liegende Modell auswählen, das ich verwenden möchte.
Ich werde GPT-3.5 auswählen:
Bild von ChatGPT Plus
Wenn Sie kein Abonnement haben, können Sie die kostenlose Version von ChatGPT verwenden, da der Chatbot standardmäßig GPT-3.5 verwendet.
Lassen Sie uns nun die folgende Eingabeaufforderung eingeben, um eine Visualisierung mit dem Diabetes-Datensatz zu generieren:
Ich habe einen Datensatz mit 8 unabhängigen Variablen und 1 abhängigen Variablen. Die abhängige Variable „Outcome“ sagt uns, ob eine Person Diabetes entwickeln wird.
Zur Vorhersage dieses Ergebnisses werden die unabhängigen Variablen „Schwangerschaften“, „Glukose“, „Blutdruck“, „Hautdicke“, „Insulin“, „BMI“, „DiabetesPedigreeFunction“ und „Alter“ verwendet.
Können Sie Python-Code generieren, um alle diese unabhängigen Variablen nach Ergebnis zu visualisieren? Die Ausgabe sollte ein gruppiertes Balkendiagramm sein, das durch die Variable „Ergebnis“ gefärbt wird. Insgesamt sollten 16 Balken vorhanden sein, 2 für jede unabhängige Variable.
Hier ist die Antwort des Modells auf die obige Eingabeaufforderung:
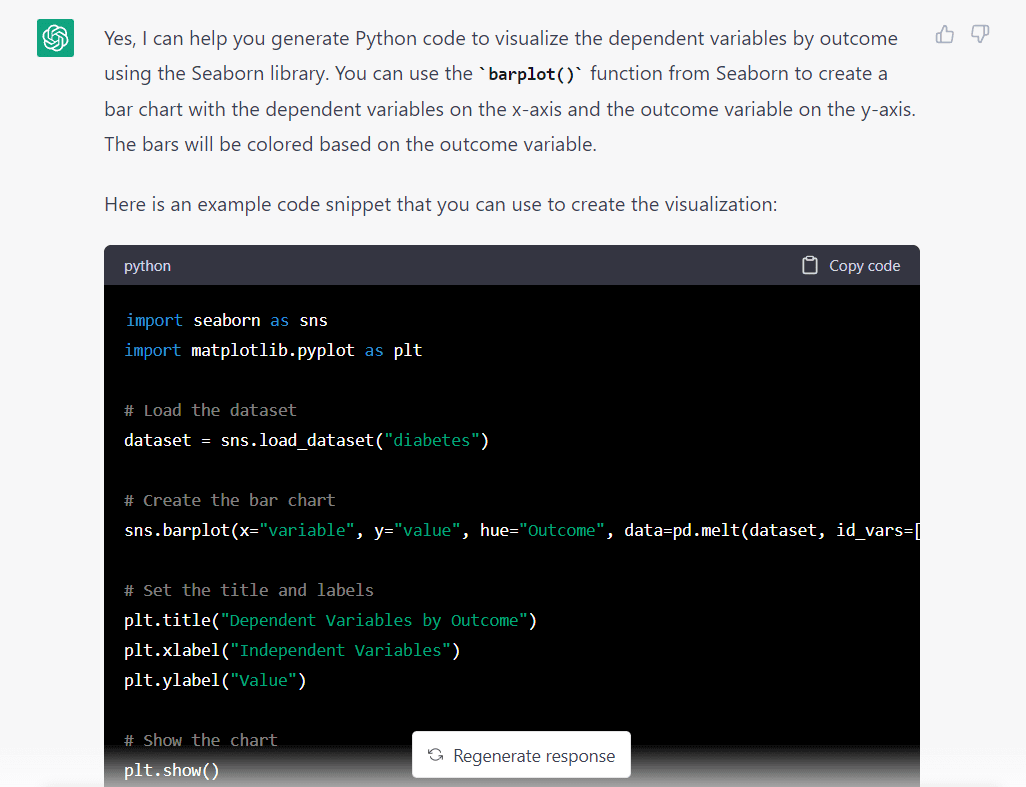
Eine Sache, die sofort auffällt, ist, dass das Modell davon ausging, dass wir einen Datensatz von Seaborn importieren wollten. Wahrscheinlich hat es diese Annahme getroffen, da wir es gebeten haben, die Seaborn-Bibliothek zu verwenden.
Dies ist kein großes Problem, wir müssen nur eine Zeile ändern, bevor wir die Codes ausführen.
Hier ist das vollständige Code-Snippet, das von GPT-3.5 generiert wurde:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
Sie können dies kopieren und in Ihre Python-IDE einfügen.
Hier ist das Ergebnis, das nach dem Ausführen des obigen Codes generiert wird:
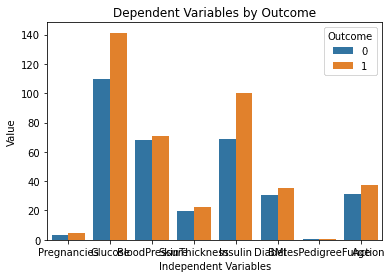
Dieses Diagramm sieht perfekt aus! Genau so habe ich es mir vorgestellt, als ich den Prompt in ChatGPT eingetippt habe.
Ein auffälliges Problem ist jedoch, dass sich der Text in diesem Diagramm überschneidet. Ich werde das Modell fragen, ob es uns helfen kann, dies zu beheben, indem ich die folgende Eingabeaufforderung eintippe:
Der Algorithmus erklärte, dass wir diese Überlappung verhindern könnten, indem wir entweder die Diagrammbeschriftungen drehen oder die Abbildungsgröße anpassen. Es hat auch neuen Code generiert, der uns dabei hilft, dies zu erreichen.
Lassen Sie uns diesen Code ausführen, um zu sehen, ob er uns die gewünschten Ergebnisse liefert:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
Die obigen Codezeilen sollten die folgende Ausgabe erzeugen:
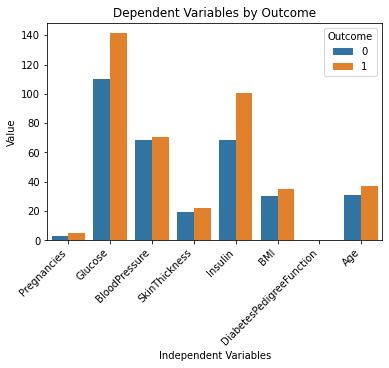
Das sieht gut aus!
Ich verstehe den Datensatz jetzt viel besser, indem ich einfach auf dieses Diagramm schaue. Es scheint, als ob Menschen mit höheren Glukose- und Insulinspiegeln eher an Diabetes erkranken.
Beachten Sie auch, dass die Variable „DiabetesPedigreeFunction“ uns in diesem Diagramm keine Informationen liefert. Dies liegt daran, dass das Merkmal auf einer kleineren Skala liegt (zwischen 0 und 2.4). Wenn Sie weiter mit ChatGPT experimentieren möchten, können Sie es auffordern, mehrere Subplots in einem einzigen Diagramm zu generieren, um dieses Problem zu lösen.
Datenvisualisierung mit GPT-4
Lassen Sie uns nun dieselben Eingabeaufforderungen in GPT-4 einspeisen, um zu sehen, ob wir eine andere Antwort erhalten. Ich werde das GPT-4-Modell in ChatGPT auswählen und die gleiche Eingabeaufforderung wie zuvor eingeben:
Beachten Sie, dass GPT-4 nicht davon ausgeht, dass wir einen in Seaborn integrierten Datenrahmen verwenden werden.
Es sagt uns, dass es einen Datenrahmen namens „df“ verwenden wird, um die Visualisierung zu erstellen, was eine Verbesserung gegenüber der von GPT-3.5 generierten Antwort darstellt.
Hier ist der vollständige Code, der von diesem Algorithmus generiert wird:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
Der obige Code sollte das folgende Diagramm erzeugen:
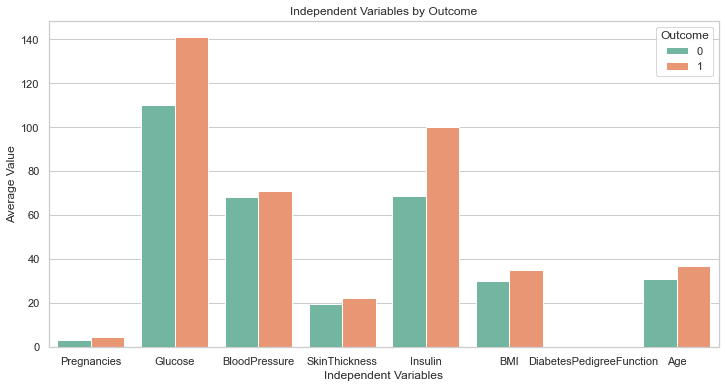
Dies ist perfekt!
Obwohl wir nicht darum gebeten haben, hat GPT-4 eine Codezeile eingefügt, um die Plotgröße zu erhöhen. Die Beschriftungen in diesem Diagramm sind alle deutlich sichtbar, sodass wir nicht zurückgehen und den Code ändern müssen, wie wir es zuvor getan haben.
Dies ist ein Schritt über der von GPT-3.5 generierten Antwort.
Insgesamt scheint es jedoch so, als ob GPT-3.5 und GPT-4 beide effektiv beim Generieren von Code für Aufgaben wie Datenvisualisierung und -analyse sind.
Es ist wichtig zu beachten, dass Sie das Modell mit einer genauen Beschreibung Ihres Datensatzes für optimale Ergebnisse bereitstellen sollten, da Sie keine Daten in die Schnittstelle von ChatGPT hochladen können.
2. Arbeiten mit PDF-Dokumenten
Dies ist zwar kein üblicher Anwendungsfall für Data Science, aber ich musste Textdaten aus Hunderten von PDF-Dateien extrahieren, um einmal ein Stimmungsanalysemodell zu erstellen. Die Daten waren unstrukturiert, und ich verbrachte viel Zeit damit, sie zu extrahieren und vorzuverarbeiten.
Ich arbeite auch oft mit Forschern zusammen, die Inhalte über aktuelle Ereignisse in bestimmten Branchen lesen und erstellen. Sie müssen auf dem Laufenden bleiben, Unternehmensberichte analysieren und sich über potenzielle Trends in der Branche informieren.
Anstatt 100 Seiten eines Unternehmensberichts zu lesen, ist es nicht einfacher, einfach Wörter zu extrahieren, die Sie interessieren, und nur Sätze durchzulesen, die diese Schlüsselwörter enthalten?
Wenn Sie an Trends interessiert sind, können Sie einen automatisierten Workflow erstellen, der das Keyword-Wachstum im Laufe der Zeit anzeigt, anstatt jeden Bericht manuell durchzugehen.
In diesem Abschnitt verwenden wir ChatGPT, um PDF-Dateien in Python zu analysieren. Wir bitten den Chatbot, den Inhalt einer PDF-Datei zu extrahieren und in eine Textdatei zu schreiben.
Auch hier wird sowohl GPT-3.5 als auch GPT-4 verwendet, um zu sehen, ob es einen signifikanten Unterschied im generierten Code gibt.
Lesen von PDF-Dateien mit GPT-3.5
In diesem Abschnitt analysieren wir ein öffentlich zugängliches PDF-Dokument mit dem Titel Eine kurze Einführung in maschinelles Lernen für Ingenieure. Stellen Sie sicher, dass Sie diese Datei herunterladen, wenn Sie in diesem Abschnitt mitcodieren möchten.
Lassen Sie uns zunächst den Algorithmus bitten, Python-Code zu generieren, um Daten aus diesem PDF-Dokument zu extrahieren und in einer Textdatei zu speichern:
Hier ist der vollständige Code, der vom Algorithmus bereitgestellt wird:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Hinweis: Stellen Sie sicher, dass Sie den Namen der PDF-Datei in den Namen ändern, den Sie gespeichert haben, bevor Sie diesen Code ausführen.)
Leider bin ich nach dem Ausführen des von GPT-3.5 generierten Codes auf den folgenden Unicode-Fehler gestoßen:

Gehen wir zurück zu GPT-3.5 und sehen, ob das Modell dies beheben kann:
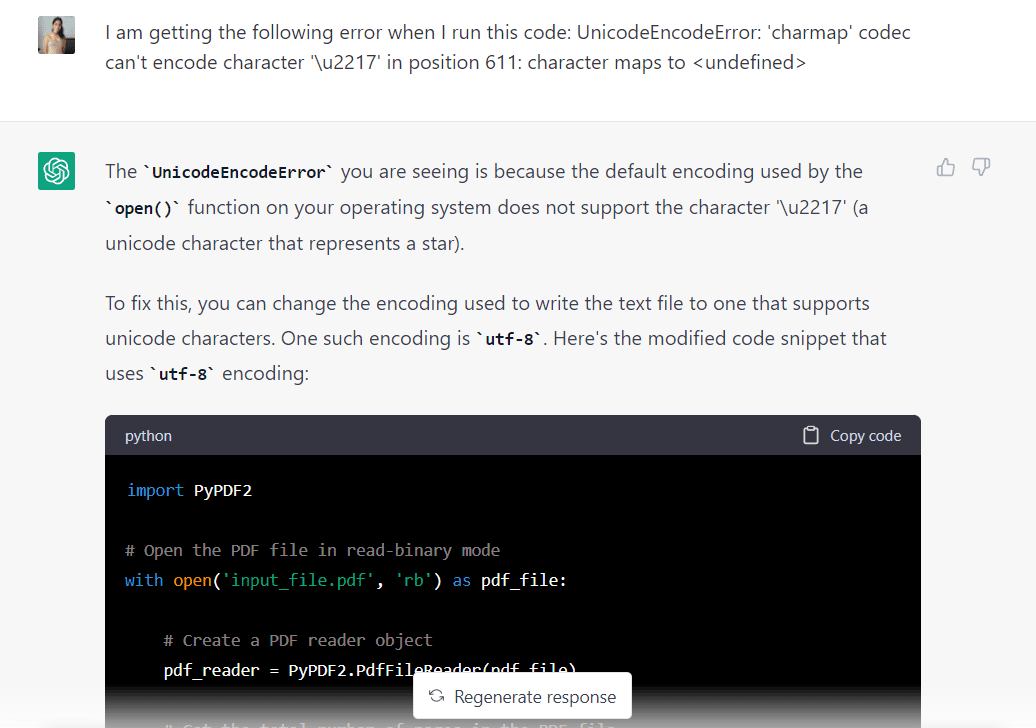
Ich habe den Fehler in ChatGPT eingefügt, und das Modell hat geantwortet, dass er behoben werden könnte, indem die verwendete Codierung in „utf-8“ geändert wird. Es gab mir auch einen modifizierten Code, der diese Änderung widerspiegelte:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Dieser Code wurde erfolgreich ausgeführt und eine Textdatei mit dem Namen „output_file.txt“ erstellt. Der gesamte Inhalt des PDF-Dokuments wurde in die Datei geschrieben:
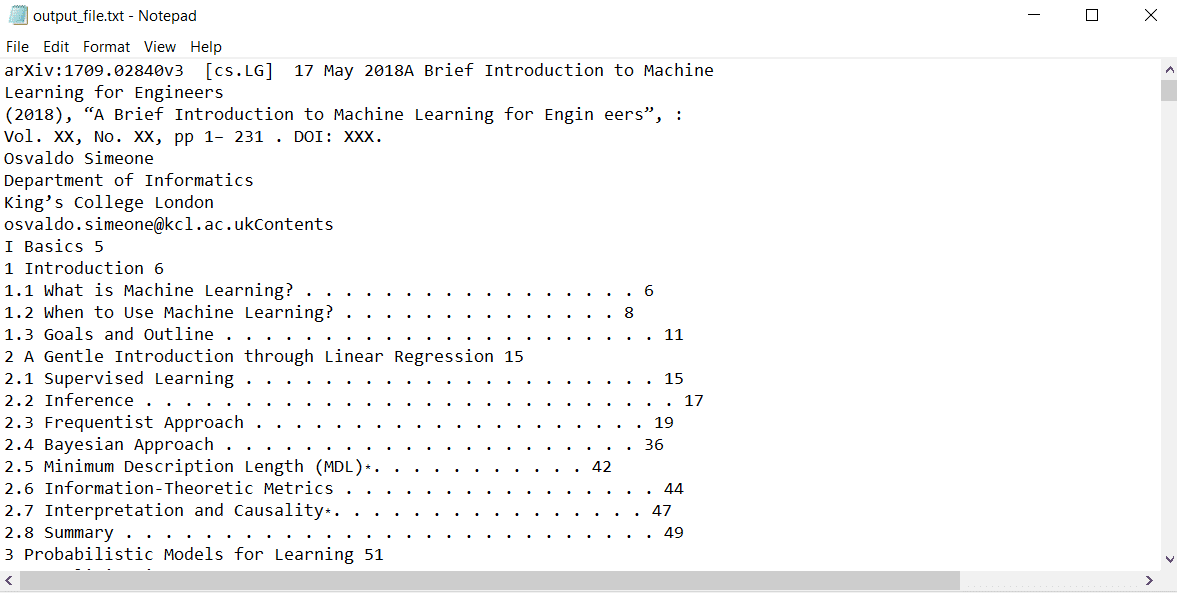
Lesen von PDF-Dateien mit GPT-4
Jetzt füge ich dieselbe Eingabeaufforderung in GPT-4 ein, um zu sehen, was das Modell ergibt:
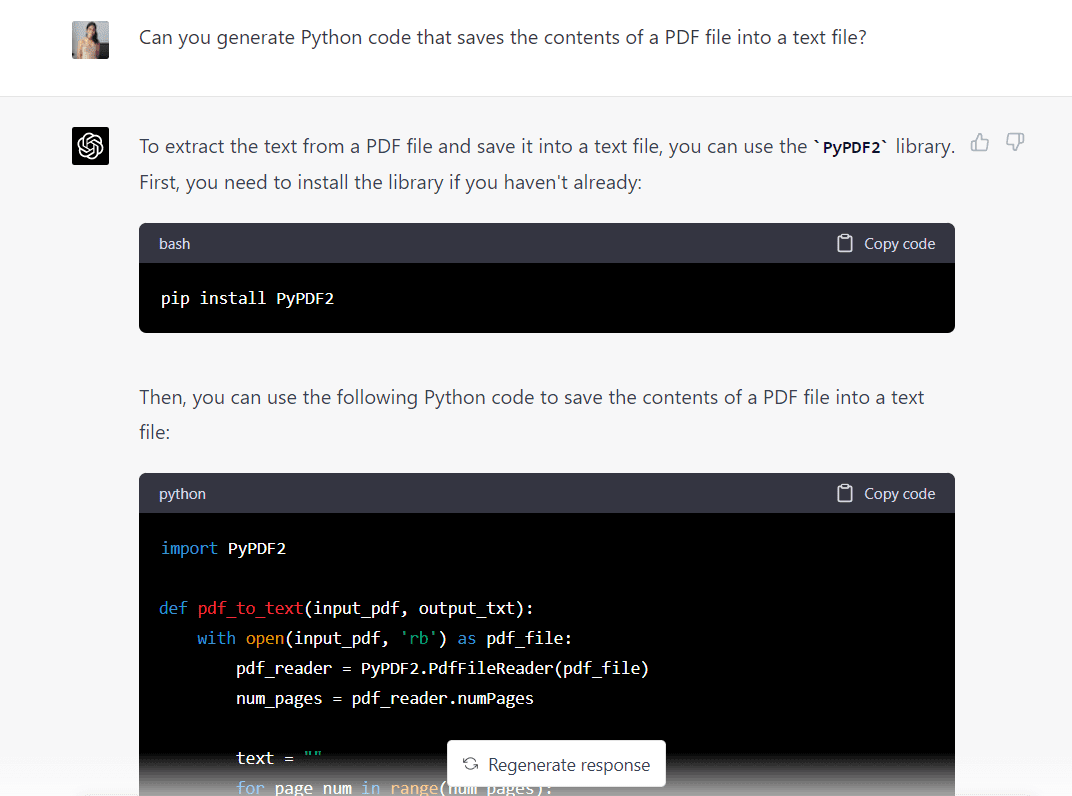
Hier ist der vollständige Code, der von GPT-4 generiert wurde:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Sieh dir das an!
Im Gegensatz zu GPT-3.5 hat GPT-4 bereits festgelegt, dass zum Öffnen der Textdatei die Kodierung „utf-8“ verwendet werden soll. Wir müssen nicht zurückgehen und den Code ändern, wie wir es zuvor getan haben.
Der von GPT-4 bereitgestellte Code sollte erfolgreich ausgeführt werden, und Sie sollten den Inhalt des PDF-Dokuments in der erstellten Textdatei sehen.
Es gibt viele andere Techniken, die Sie verwenden können, um PDF-Dokumente mit Python zu automatisieren. Wenn Sie dies weiter untersuchen möchten, finden Sie hier einige andere Eingabeaufforderungen, die Sie in ChatGPT eingeben können:
- Können Sie Python-Code schreiben, um zwei PDF-Dateien zusammenzuführen?
- Wie kann ich mit Python das Vorkommen eines bestimmten Wortes oder Satzes in einem PDF-Dokument zählen?
- Können Sie Python-Code schreiben, um Tabellen aus PDFs zu extrahieren und sie in Excel zu schreiben?
Ich schlage vor, einige davon in Ihrer Freizeit auszuprobieren – Sie werden überrascht sein, wie schnell Ihnen GPT-4 dabei helfen kann, einfache Aufgaben zu erledigen, deren Ausführung normalerweise Stunden dauert.
3. Versenden von automatisierten E-Mails
Ich verbringe Stunden meiner Arbeitswoche damit, E-Mails zu lesen und zu beantworten. Dies ist nicht nur zeitaufwändig, sondern kann auch unglaublich stressig sein, um den Überblick über E-Mails zu behalten, wenn Sie knappe Fristen verfolgen.
Und obwohl Sie ChatGPT nicht dazu bringen können, alle Ihre E-Mails für Sie zu schreiben (ich wünschte), können Sie es dennoch verwenden, um Programme zu schreiben, die geplante E-Mails zu einer bestimmten Zeit senden, oder eine einzelne E-Mail-Vorlage ändern, die an mehrere Personen gesendet werden kann .
In diesem Abschnitt erhalten wir GPT-3.5 und GPT-4, um uns beim Schreiben eines Python-Skripts zum automatischen Senden von E-Mails zu helfen.
Versenden von automatisierten E-Mails mit GPT-3.5
Lassen Sie uns zunächst die folgende Eingabeaufforderung eingeben, um Codes zum Senden einer automatisierten E-Mail zu generieren:
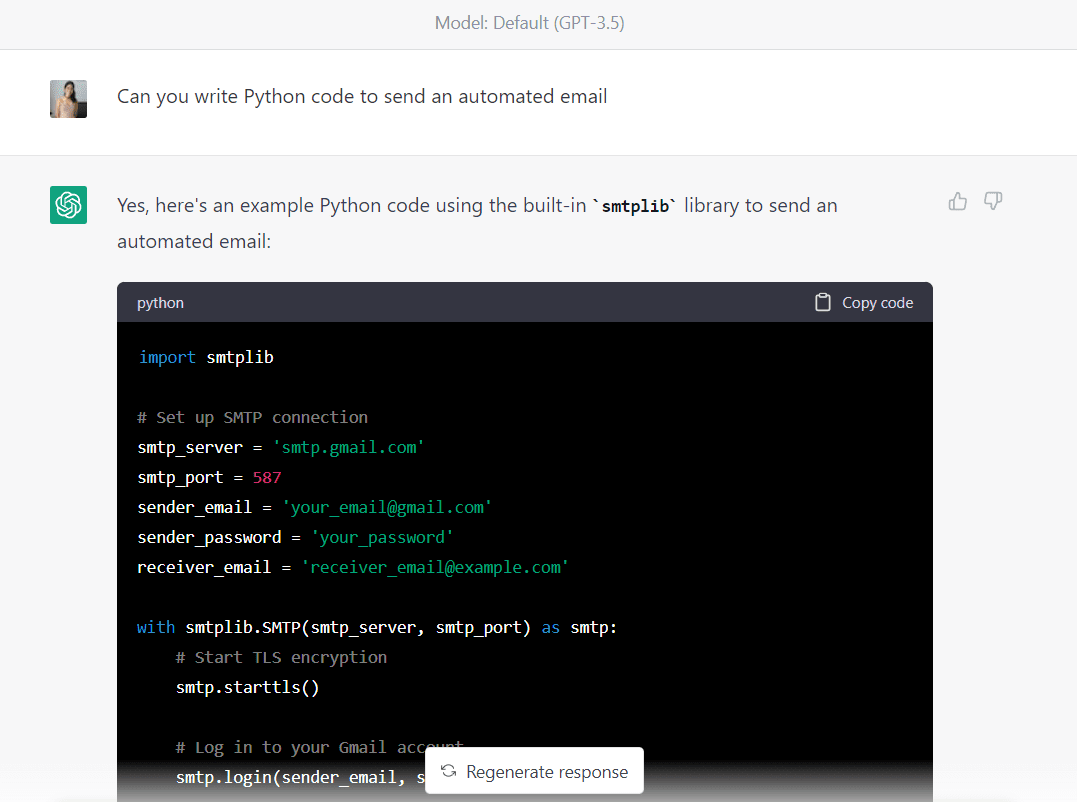
Hier ist der vollständige Code, der von GPT-3.5 generiert wurde (Stellen Sie sicher, dass Sie die E-Mail-Adressen und das Passwort ändern, bevor Sie diesen Code ausführen):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Leider wurde dieser Code bei mir nicht erfolgreich ausgeführt. Es erzeugte den folgenden Fehler:
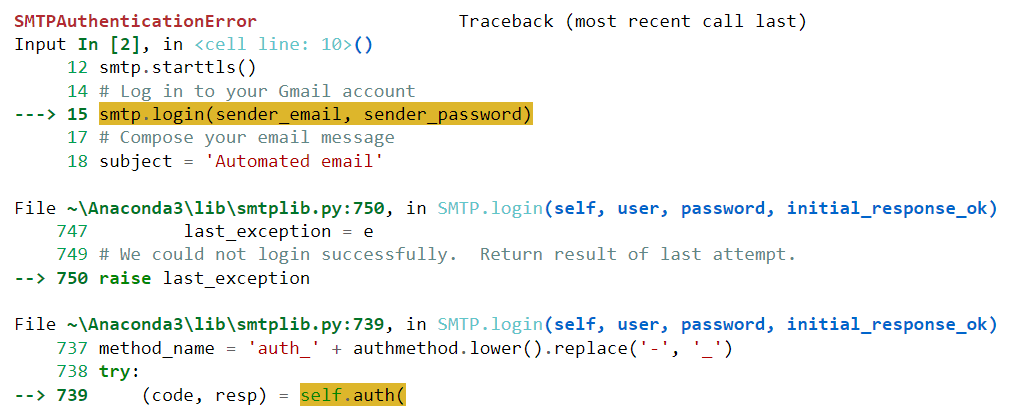
Lassen Sie uns diesen Fehler in ChatGPT einfügen und sehen, ob das Modell uns helfen kann, ihn zu lösen:

Okay, der Algorithmus hat also einige Gründe aufgezeigt, warum wir möglicherweise auf diesen Fehler stoßen.
Ich weiß mit Sicherheit, dass meine Anmeldeinformationen und E-Mail-Adressen gültig waren und dass der Code keine Tippfehler enthielt. Diese Gründe können also ausgeschlossen werden.
GPT-3.5 schlägt auch vor, dass das Zulassen weniger sicherer Apps dieses Problem lösen könnte.
Wenn Sie dies versuchen, finden Sie in Ihrem Google-Konto jedoch keine Option, um den Zugriff auf weniger sichere Apps zuzulassen.
Das liegt daran, dass Google nicht mehr ermöglicht es Benutzern, weniger sichere Apps aufgrund von Sicherheitsbedenken zuzulassen.
Schließlich erwähnt GPT-3.5 auch, dass ein App-Passwort generiert werden sollte, wenn die Zwei-Faktor-Authentifizierung aktiviert war.
Ich habe keine Zwei-Faktor-Authentifizierung aktiviert, also werde ich dieses Modell (vorübergehend) aufgeben und sehen, ob GPT-4 eine Lösung hat.
Versenden von automatisierten E-Mails mit GPT-4
Okay, wenn Sie dieselbe Eingabeaufforderung in GPT-4 eingeben, werden Sie feststellen, dass der Algorithmus Code generiert, der dem von GPT-3.5 sehr ähnlich ist. Dies wird den gleichen Fehler verursachen, auf den wir zuvor gestoßen sind.
Mal sehen, ob GPT-4 uns helfen kann, diesen Fehler zu beheben:

Die Vorschläge von GPT-4 sind denen sehr ähnlich, die wir zuvor gesehen haben.
Dieses Mal gibt es uns jedoch eine Schritt-für-Schritt-Aufschlüsselung, wie die einzelnen Schritte ausgeführt werden können.
GPT-4 schlägt auch vor, ein App-Passwort zu erstellen, also probieren wir es aus.
Besuchen Sie zunächst Ihr Google-Konto, navigieren Sie zu „Sicherheit“ und aktivieren Sie die Zwei-Faktor-Authentifizierung. Dann sollten Sie im selben Abschnitt eine Option mit der Aufschrift „App-Passwörter“ sehen.
Klicken Sie darauf und der folgende Bildschirm wird angezeigt:
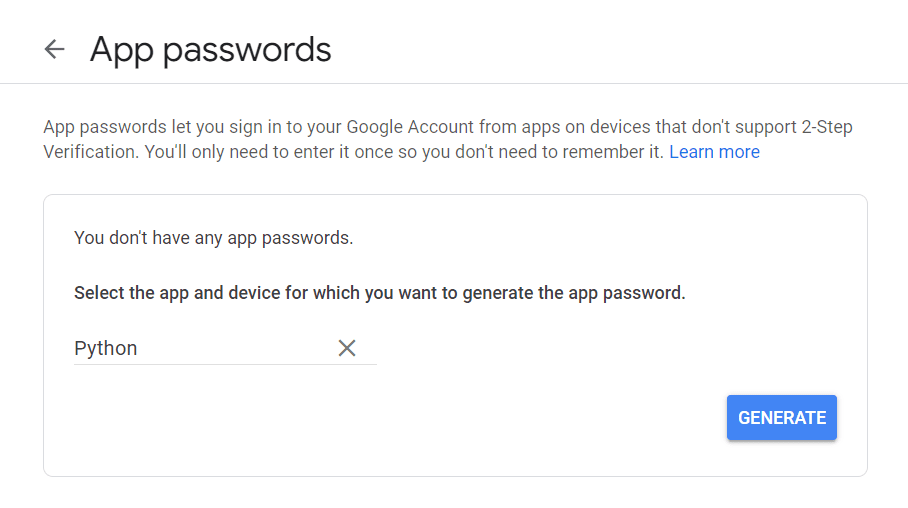
Sie können einen beliebigen Namen eingeben und auf „Generieren“ klicken.
Ein neues App-Passwort wird angezeigt.
Ersetzen Sie Ihr vorhandenes Passwort im Python-Code durch dieses App-Passwort und führen Sie den Code erneut aus:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Diesmal sollte es erfolgreich ausgeführt werden, und Ihr Empfänger erhält eine E-Mail, die so aussieht:
Perfect!
Dank ChatGPT haben wir erfolgreich eine automatisierte E-Mail mit Python versendet.
Wenn Sie noch einen Schritt weiter gehen möchten, schlage ich vor, Eingabeaufforderungen zu generieren, die Ihnen Folgendes ermöglichen:
- Senden Sie Massen-E-Mails gleichzeitig an mehrere Empfänger
- Senden Sie geplante E-Mails an eine vordefinierte Liste von E-Mail-Adressen
- Senden Sie den Empfängern eine personalisierte E-Mail, die auf ihr Alter, Geschlecht und ihren Standort zugeschnitten ist.
Natascha Selvaraj ist ein autodidaktischer Datenwissenschaftler mit einer Leidenschaft für das Schreiben. Du kannst dich mit ihr verbinden LinkedIn.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :Ist
- $UP
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- Über uns
- oben
- Zugang
- erreichen
- Konto
- genau
- Erreichen
- über
- berührt das Schneidwerkzeug
- Adressen
- Nach der
- Algorithmus
- Alle
- Zulassen
- erlaubt
- bereits
- Obwohl
- Betrag
- Analyse
- analysieren
- Analyse
- und
- Tiere
- Antworten
- Bienen
- App
- erscheinen
- Apps
- SIND
- Artikel
- AS
- angenommen
- Annahme
- At
- Authentifizierung
- automatisieren
- Automatisiert
- verfügbar
- durchschnittlich
- Zurück
- Backend
- Bar
- Riegel
- basierend
- BE
- weil
- werden
- Bevor
- hinter
- Vorteile
- Besser
- zwischen
- bmi
- Körper
- Bohren
- Breakdown
- bauen
- erbaut
- Geschäft
- by
- namens
- CAN
- abgebrochen
- kann keine
- Verursachen
- Übernehmen
- Ändern
- Chart
- Chatbot
- ChatGPT
- klicken Sie auf
- Code
- COM
- Kommen
- gemeinsam
- Unternehmen
- Unternehmen
- abschließen
- kompliziert
- Bedenken
- zuversichtlich
- Vernetz Dich
- Verbindung
- konsolidieren
- Inhalt
- Inhalt
- bestätigen
- könnte
- erstellen
- erstellt
- Erstellen
- Referenzen
- neugierig
- Strom
- Zur Zeit
- anpassen
- maßgeschneiderte
- Unterricht
- technische Daten
- Datenanalyse
- Datenwissenschaft
- Datenwissenschaftler
- Datenvisualisierung
- Datensätze
- Tag
- Standard
- abhängig
- Beschreibung
- Details
- entwickeln
- Diabetes
- DID
- Unterschied
- anders
- Dokument
- Dokumentation
- Unterlagen
- Tut nicht
- Dabei
- Nicht
- herunterladen
- Antrieb
- im
- jeder
- Früher
- einfacher
- Effektiv
- Eier
- entweder
- Elefant
- E-Mails
- ermöglichen
- freigegeben
- Verschlüsselung
- Enter
- Fehler
- Fehler
- insbesondere
- Äther (ETH)
- Veranstaltungen
- Jedes
- alles
- genau
- Excel
- ausführen
- vorhandenen
- Experiment
- erklärt
- Explorative Datenanalyse
- ERKUNDEN
- umfangreiche
- Extrakt
- Merkmal
- Gebühr
- wenige
- Abbildung
- Reichen Sie das
- Mappen
- füllen
- Finden Sie
- Vorname
- Fixieren
- fixiert
- Setzen Sie mit Achtsamkeit
- folgen
- Folgende
- Aussichten für
- Früher
- Frei
- häufig
- für
- funktional
- weiter
- Geschlecht
- erzeugen
- erzeugt
- erzeugt
- Erzeugung
- bekommen
- ABSICHT
- gibt
- gmail
- Go
- gehen
- Wachstum
- die Vermittlung von Kompetenzen,
- Guide
- Pflege
- Haben
- ganzer
- Hilfe
- hilft
- hier
- versteckt
- höher
- hoch
- Horizontale
- STUNDEN
- Ultraschall
- Hilfe
- aber
- HTTPS
- riesig
- hunderte
- i
- Ideen
- sofort
- Impact der HXNUMXO Observatorien
- importieren
- wichtig
- Verbesserung
- in
- inklusive
- Erhöhung
- unglaublich
- unabhängig
- Branchen
- Energiegewinnung
- Information
- beantragen müssen
- interessiert
- Schnittstelle
- Einleitung
- Problem
- IT
- SEINE
- Job
- join
- KDnuggets
- Wissen
- Etiketten
- Land
- Sprache
- grosse
- höchste
- neueste
- starten
- ins Leben gerufen
- lernen
- Lasst uns
- Cholesterinspiegel
- Bibliothek
- Gefällt mir
- wahrscheinlich
- Line
- Linien
- Liste
- Belastung
- Standorte
- sah
- suchen
- SIEHT AUS
- Los
- Maschine
- Maschinelles Lernen
- gemacht
- um
- manuell
- viele
- März
- Mathe
- Matplotlib
- Erwähnungen
- Merge
- Nachricht
- könnte
- Model
- Modell
- für
- geändert
- ändern
- Moment
- monatlich
- monatliches Abo
- mehr
- vor allem warme
- schlauer bewegen
- mehrere
- Name
- Navigieren
- Need
- Neu
- neue App
- Neueste
- News
- berüchtigt
- November
- Anzahl
- Objekt
- of
- OK
- on
- EINEM
- XNUMXh geöffnet
- OpenAI
- Optimum
- Option
- Andere
- Ergebnis
- Übertrifft
- Signalausgangsmöglichkeiten:
- Seite
- bezahlt
- Pandas
- Leidenschaft & KREATIVITÄT
- Passwort
- Passwörter
- AUFMERKSAMKEIT
- Personen
- ausführen
- Durchführung
- person
- Ort
- Plato
- Datenintelligenz von Plato
- PlatoData
- erfahren
- Potenzial
- größte treibende
- Vorgänger
- vorhersagen
- ziemlich
- verhindern
- vorher
- wahrscheinlich
- Aufgabenstellung:
- Probleme
- Programme
- Fortschritt
- die
- vorausgesetzt
- Öffentlichkeit
- öffentlich
- Python
- Fragen
- Direkt
- schnell
- Lesen Sie mehr
- Leser
- Lesebrillen
- Gründe
- erhalten
- Empfänger
- reflektiert
- freigegeben
- relevant
- verbleibenden
- berichten
- Meldungen
- falls angefordert
- erfordert
- Forscher
- reagiert
- Antwort
- Folge
- Die Ergebnisse
- Führen Sie
- Laufen
- gleich
- Speichern
- Ersparnisse
- sagt
- Skalieren
- vorgesehen
- Wissenschaft
- Wissenschaftler
- Bildschirm
- Seeschneur
- Suche
- Abschnitt
- Verbindung
- Sicherheitdienst
- Sendung
- Gefühl
- kompensieren
- sollte
- erklären
- signifikant
- ähnlich
- Einfacher
- einfach
- da
- Single
- Größe
- kleinere
- So
- Lösung
- LÖSEN
- Auflösung
- einige
- Quellen
- spezifisch
- angegeben
- verbringen
- verbrachte
- steht
- Anfang
- bleiben
- Schritt
- Immer noch
- Stoppen
- Fach
- Abonnement
- Erfolgreich
- Schlägt vor
- geeignet
- überrascht
- Syntax
- zugeschnitten
- Nehmen
- Einnahme
- Target
- Aufgabe
- und Aufgaben
- Techniken
- erzählt
- Vorlage
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- Dort.
- Diese
- Ding
- Durch
- Zeit
- Zeitaufwendig
- Titel
- betitelt
- TLS
- zu
- Werkzeug
- Top
- Gesamt
- trainiert
- Trends
- Drehung
- Lernprogramm
- zugrunde liegen,
- verstehen
- Unicode
- mehr Stunden
- us
- -
- Mitglied
- Nutzer
- gewöhnlich
- Wert
- Version
- sichtbar
- Besuchen Sie
- Visualisierung
- W
- wollte
- Webseite
- Was
- ob
- welche
- WHO
- Wikipedia
- werden wir
- mit
- .
- Word
- Worte
- Arbeiten
- Arbeitsablauf.
- Workflows
- arbeiten,
- würde
- schreiben
- Schreiben
- geschrieben
- Ihr
- Zephyrnet