Bild vom Autor
Wenn Sie mit maschinellem Lernen beginnen, ist die logistische Regression einer der ersten Algorithmen, die Sie Ihrer Toolbox hinzufügen. Es handelt sich um einen einfachen und robusten Algorithmus, der häufig für binäre Klassifizierungsaufgaben verwendet wird.
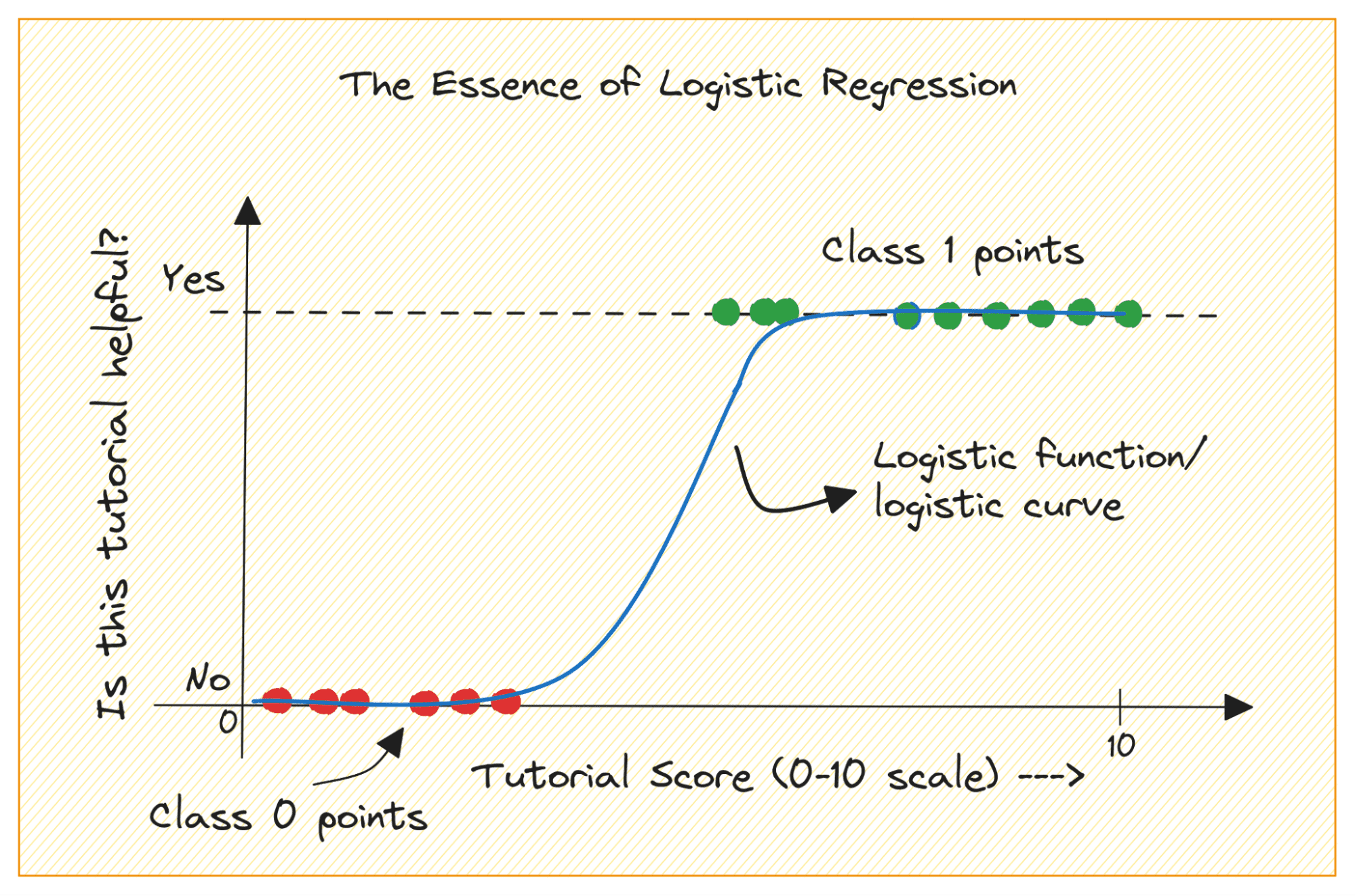
Stellen Sie sich ein binäres Klassifizierungsproblem mit den Klassen 0 und 1 vor. Die logistische Regression passt eine logistische oder Sigmoidfunktion an die Eingabedaten an und sagt die Wahrscheinlichkeit voraus, dass ein Abfragedatenpunkt zur Klasse 1 gehört. Interessant, ja?
In diesem Tutorial lernen wir die logistische Regression von Grund auf kennen und behandeln Folgendes:
- Die logistische (oder Sigmoid-)Funktion
- Wie wir von der linearen zur logistischen Regression übergehen
- Wie die logistische Regression funktioniert
Abschließend erstellen wir ein einfaches logistisches Regressionsmodell Klassifizieren Sie Radarechos aus der Ionosphäre.
Bevor wir mehr über die logistische Regression erfahren, werfen wir einen Blick auf die Funktionsweise der logistischen Funktion. Die Logistikfunktion (oder Sigmoidfunktion) ist gegeben durch:

Wenn Sie die Sigmoidfunktion grafisch darstellen, sieht sie folgendermaßen aus:
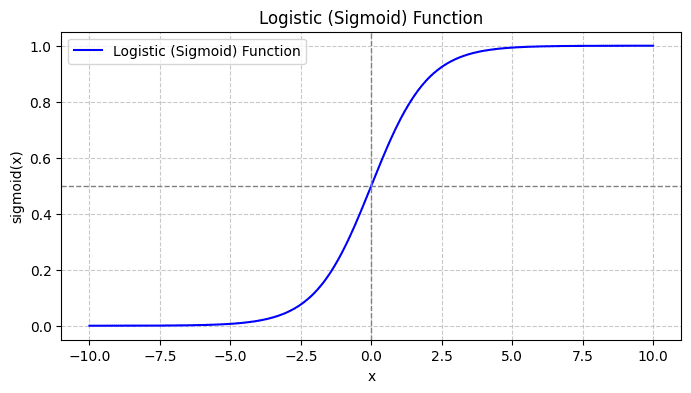
Aus der Handlung sehen wir Folgendes:
- Wenn x = 0, nimmt σ(x) den Wert 0.5 an.
- Wenn x sich +∞ nähert, nähert sich σ(x) 1.
- Wenn x sich -∞ nähert, nähert sich σ(x) 0.
Daher werden alle realen Eingaben durch die Sigmoidfunktion so gequetscht, dass sie Werte im Bereich [0, 1] annehmen.
Lassen Sie uns zunächst diskutieren, warum wir die lineare Regression nicht für ein binäres Klassifizierungsproblem verwenden können.
Bei einem binären Klassifizierungsproblem ist die Ausgabe eine kategoriale Bezeichnung (0 oder 1). Da die lineare Regression kontinuierliche Ausgaben vorhersagt, die kleiner als 0 oder größer als 1 sein können, ist sie für das vorliegende Problem nicht sinnvoll.
Außerdem ist eine gerade Linie möglicherweise nicht die beste Lösung, wenn die Ausgabebezeichnungen zu einer der beiden Kategorien gehören.
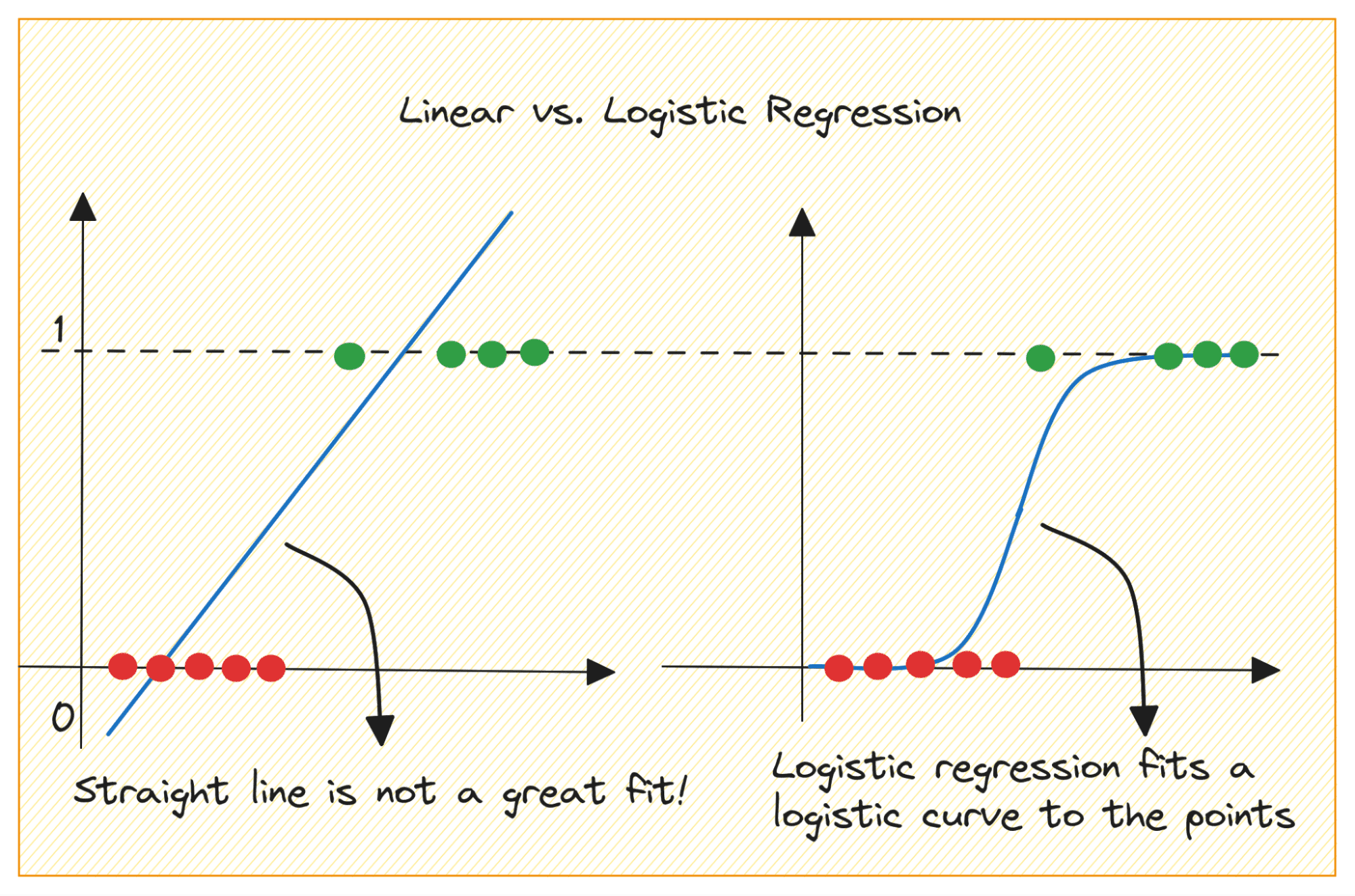
Bild vom Autor
Wie kommen wir also von der linearen zur logistischen Regression? Bei der linearen Regression ist die vorhergesagte Ausgabe wie folgt gegeben:
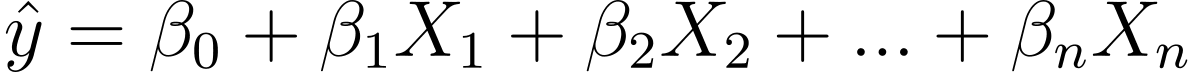
Dabei sind die βs die Koeffizienten und X_is die Prädiktoren (oder Merkmale).
Nehmen wir ohne Beschränkung der Allgemeinheit an, dass X_0 = 1 ist:

So können wir es prägnanter ausdrücken:
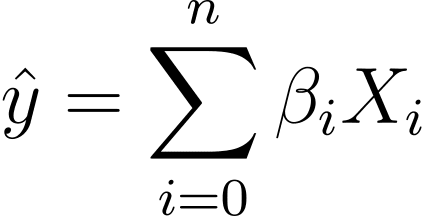
Bei der logistischen Regression benötigen wir die vorhergesagte Wahrscheinlichkeit p_i im Intervall [0,1]. Wir wissen, dass die Logistikfunktion Eingaben so quetscht, dass sie Werte im Intervall [0,1] annehmen.
Wenn wir diesen Ausdruck also in die Logistikfunktion einfügen, erhalten wir die vorhergesagte Wahrscheinlichkeit als:
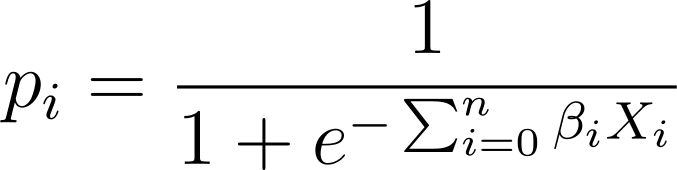
Wie finden wir also die am besten geeignete Logistikkurve für den gegebenen Datensatz? Um dies zu beantworten, wollen wir die Maximum-Likelihood-Schätzung verstehen.
Maximum-Likelihood-Schätzung (MLE) wird verwendet, um die Parameter des logistischen Regressionsmodells durch Maximierung der Likelihood-Funktion zu schätzen. Lassen Sie uns den Prozess von MLE in der logistischen Regression aufschlüsseln und wie die Kostenfunktion für die Optimierung mithilfe des Gradientenabstiegs formuliert wird.
Aufschlüsselung der Maximum-Likelihood-Schätzung
Wie besprochen modellieren wir die Wahrscheinlichkeit, dass ein binäres Ergebnis eintritt, als Funktion einer oder mehrerer Prädiktorvariablen (oder Merkmale):
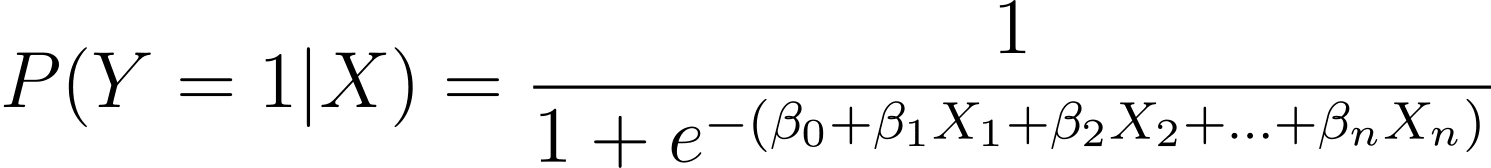
Hier sind die βs die Modellparameter oder Koeffizienten. X_1, X_2,…, X_n sind die Prädiktorvariablen.
MLE zielt darauf ab, die Werte von β zu finden, die die Wahrscheinlichkeit der beobachteten Daten maximieren. Die Wahrscheinlichkeitsfunktion, bezeichnet als L(β), stellt die Wahrscheinlichkeit dar, die gegebenen Ergebnisse für die gegebenen Prädiktorwerte im Rahmen des logistischen Regressionsmodells zu beobachten.
Formulieren der Log-Likelihood-Funktion
Um den Optimierungsprozess zu vereinfachen, wird häufig mit der Log-Likelihood-Funktion gearbeitet. Weil es Produkte von Wahrscheinlichkeiten in Summen von Log-Wahrscheinlichkeiten umwandelt.
Die Log-Likelihood-Funktion für die logistische Regression ist gegeben durch:
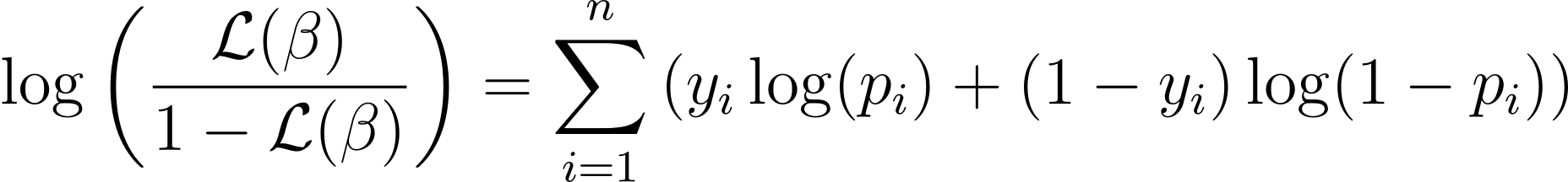
Nachdem wir nun das Wesen der Log-Likelihood kennen, formulieren wir nun die Kostenfunktion für die logistische Regression und anschließend den Gradientenabstieg, um die besten Modellparameter zu finden
Kostenfunktion für die logistische Regression
Um das logistische Regressionsmodell zu optimieren, müssen wir die Log-Likelihood maximieren. Daher können wir die negative Log-Likelihood als Kostenfunktion zur Minimierung während des Trainings verwenden. Die negative Log-Likelihood, oft auch als Logistikverlust bezeichnet, ist definiert als:
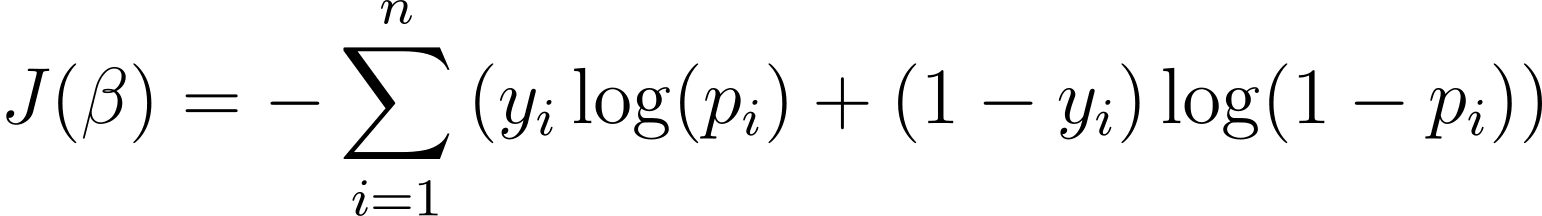
Das Ziel des Lernalgorithmus besteht daher darin, die Werte von ? die diese Kostenfunktion minimieren. Der Gradientenabstieg ist ein häufig verwendeter Optimierungsalgorithmus zum Ermitteln des Minimums dieser Kostenfunktion.
Gradientenabstieg in der logistischen Regression
Gradientenabstieg ist ein iterativer Optimierungsalgorithmus, der die Modellparameter β in der entgegengesetzten Richtung des Gradienten der Kostenfunktion in Bezug auf β aktualisiert. Die Aktualisierungsregel bei Schritt t+1 für die logistische Regression unter Verwendung des Gradientenabstiegs lautet wie folgt:
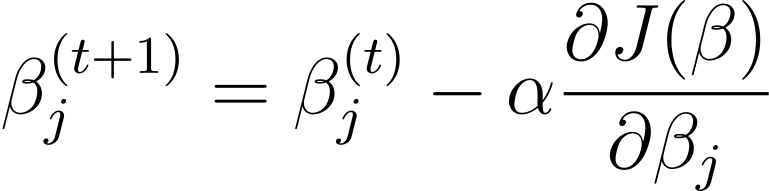
Wobei α die Lernrate ist.
Die partiellen Ableitungen können mit der Kettenregel berechnet werden. Der Gradientenabstieg aktualisiert die Parameter iterativ – bis zur Konvergenz – mit dem Ziel, den logistischen Verlust zu minimieren. Bei der Konvergenz werden die optimalen Werte von β ermittelt, die die Wahrscheinlichkeit der beobachteten Daten maximieren.
Nachdem Sie nun wissen, wie die logistische Regression funktioniert, erstellen wir mithilfe der scikit-learn-Bibliothek ein Vorhersagemodell.
Wir werden das benutzen Ionosphärendatensatz aus dem UCI-Repository für maschinelles Lernen für dieses Tutorial. Der Datensatz umfasst 34 numerische Merkmale. Die Ausgabe ist binär, entweder „gut“ oder „schlecht“ (gekennzeichnet durch „g“ oder „b“). Die Ausgabebezeichnung „gut“ bezieht sich auf RADAR-Echos, die eine gewisse Struktur in der Ionosphäre entdeckt haben.
Schritt 1 – Laden des Datensatzes
Laden Sie zunächst den Datensatz herunter und lesen Sie ihn in einen Pandas-Datenrahmen ein:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Schritt 2 – Erkunden des Datensatzes
Werfen wir einen Blick auf die ersten Zeilen des Datenrahmens:
# Display the first few rows of the DataFrame
df.head()
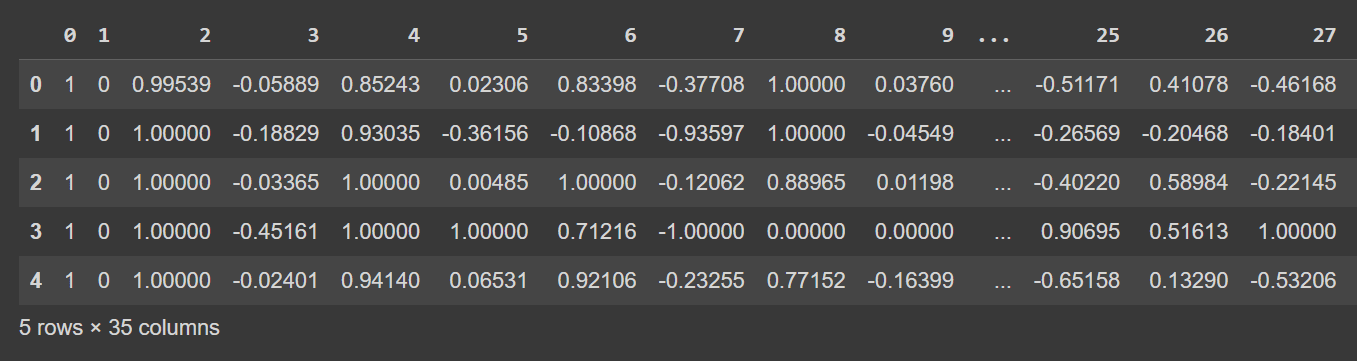
Abgeschnittene Ausgabe von df.head()
Lassen Sie uns einige Informationen über den Datensatz erhalten: die Anzahl der Nicht-Null-Werte und die Datentypen der einzelnen Spalten:
# Get information about the dataset
print(df.info())
 Abgeschnittene Ausgabe von df.info()
Abgeschnittene Ausgabe von df.info()
Da wir über alle numerischen Funktionen verfügen, können wir mithilfe von auch einige deskriptive Statistiken erhalten describe() Methode auf dem Datenrahmen:
# Get descriptive statistics of the dataset
print(df.describe())
Abgeschnittene Ausgabe von df.describe()
Die Spaltennamen sind derzeit 0 bis 34 – einschließlich der Beschriftung. Da der Datensatz keine beschreibenden Namen für die Spalten bereitstellt, werden sie lediglich als Attribut_1 bis Attribut_34 bezeichnet. Wenn Sie möchten, können Sie die Spalten des Datenrahmens wie gezeigt umbenennen:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Hinweis: Dieser Schritt ist rein optional. Wenn Sie möchten, können Sie mit den Standardspaltennamen fortfahren.
# Display the first few rows of the DataFrame
df.head()
Abgeschnittene Ausgabe von df.head() [Nach dem Umbenennen der Spalten]
Schritt 3 – Klassenbezeichnungen umbenennen und Klassenverteilung visualisieren
Da die Ausgabeklassenbezeichnungen „g“ und „b“ lauten, müssen wir sie jeweils 1 und 0 zuordnen. Sie können es mit tun map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Lassen Sie uns auch die Verteilung der Klassenbezeichnungen visualisieren:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
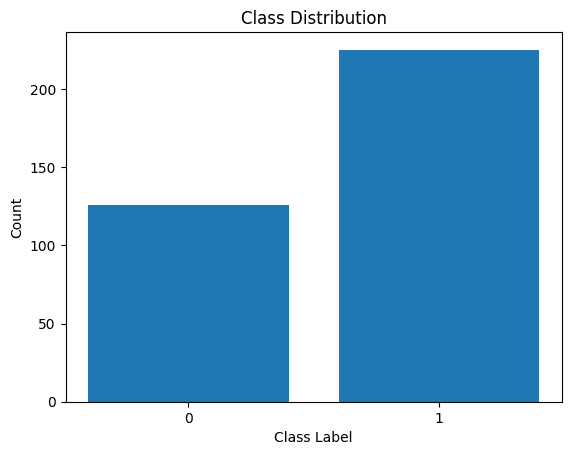
Verteilung von Klassenlabels
Wir sehen, dass es ein Ungleichgewicht in der Verteilung gibt. Es gibt mehr Datensätze, die zur Klasse 1 gehören als zur Klasse 0. Wir werden dieses Klassenungleichgewicht bei der Erstellung des logistischen Regressionsmodells berücksichtigen.
Schritt 5 – Vorverarbeitung des Datensatzes
Sammeln wir die Funktionen und Ausgabebezeichnungen wie folgt:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Nachdem wir den Datensatz in Zug- und Testsätze aufgeteilt haben, müssen wir den Datensatz vorverarbeiten.
Wenn es viele numerische Merkmale gibt – jedes in einem potenziell unterschiedlichen Maßstab – müssen wir die numerischen Merkmale vorverarbeiten. Eine übliche Methode besteht darin, sie so zu transformieren, dass sie einer Verteilung mit einem Mittelwert von Null und einer Einheitsvarianz folgen.
Das StandardScaler Das Vorverarbeitungsmodul von scikit-learn hilft uns dabei.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Schritt 6 – Erstellen eines logistischen Regressionsmodells
Jetzt können wir einen logistischen Regressionsklassifikator instanziieren. Der LogisticRegression Die Klasse ist Teil des linear_model-Moduls von scikit-learn.
Beachten Sie, dass wir das festgelegt haben class_weight Parameter auf „ausgeglichen“ stellen. Dies wird uns helfen, das Klassenungleichgewicht auszugleichen. Durch Zuweisen von Gewichtungen zu jeder Klasse – umgekehrt proportional zur Anzahl der Datensätze in den Klassen.
Nach der Instanziierung der Klasse können wir das Modell an den Trainingsdatensatz anpassen:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Schritt 7 – Bewertung des logistischen Regressionsmodells
Sie können die anrufen predict() Methode, um die Vorhersagen des Modells zu erhalten.
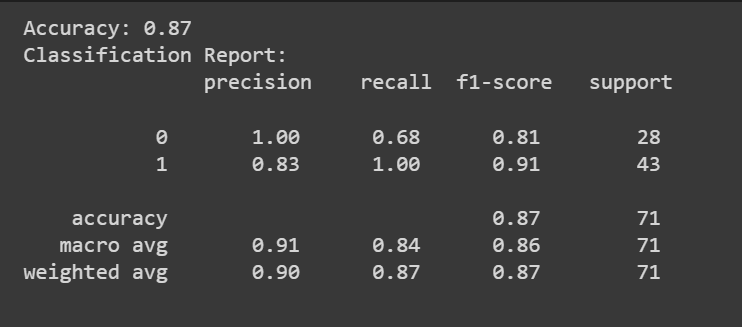
Zusätzlich zur Genauigkeitsbewertung können wir auch einen Klassifizierungsbericht mit Metriken wie Präzision, Rückruf und F1-Bewertung erhalten.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
Herzlichen Glückwunsch, Sie haben Ihr erstes logistisches Regressionsmodell codiert!
In diesem Tutorial haben wir die logistische Regression im Detail kennengelernt: von Theorie und Mathematik bis hin zur Codierung eines logistischen Regressionsklassifikators.
Versuchen Sie als nächsten Schritt, ein logistisches Regressionsmodell für einen geeigneten Datensatz Ihrer Wahl zu erstellen.
Der Ionosphere-Datensatz ist lizenziert unter a Creative Commons Namensnennung 4.0 International (CC BY 4.0) Lizenz:
Sigillito, V., Wing, S., Hutton, L. und Baker, K. (1989). Ionosphäre. UCI-Repository für maschinelles Lernen. https://doi.org/10.24432/C5W01B.
Bala Priya C ist ein Entwickler und technischer Redakteur aus Indien. Sie arbeitet gerne an der Schnittstelle von Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Zu ihren Interessen- und Fachgebieten gehören DevOps, Datenwissenschaft und Verarbeitung natürlicher Sprache. Sie liebt es zu lesen, zu schreiben, zu programmieren und Kaffee zu trinken! Derzeit arbeitet sie daran, zu lernen und ihr Wissen mit der Entwickler-Community zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :Ist
- :nicht
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Über Uns
- Konto
- Genauigkeit
- Erreichen
- hinzufügen
- Zusatz
- Nach der
- Ziel
- Algorithmus
- Algorithmen
- Alle
- ebenfalls
- an
- und
- beantworten
- Ansätze
- SIND
- Bereiche
- AS
- annehmen
- At
- Authoring
- b
- Bäcker
- Ausgewogen
- Bar
- BE
- weil
- gehörend
- BESTE
- Break
- bauen
- Building
- by
- rufen Sie uns an!
- CAN
- kann keine
- Kategorien
- Kette
- Wahl
- Klasse
- Unterricht
- Einstufung
- codiert
- Programmierung
- sammeln
- Kolonne
- Spalten
- gemeinsam
- häufig
- Unterhaus
- community
- inbegriffen
- prägnant
- Inhalt
- Inhaltserstellung
- verkaufen
- Kosten
- Abdeckung
- erstellen
- Schaffung
- Zur Zeit
- Kurve
- technische Daten
- Datenpunkte
- Datenwissenschaft
- Datensatz
- Standard
- definiert
- Derivate
- Detail
- erkannt
- Entwickler:in / Unternehmen
- DevOps
- anders
- Richtung
- diskutieren
- diskutiert
- Display
- Verteilung
- do
- die
- nach unten
- herunterladen
- im
- jeder
- Essenz
- schätzen
- Auswerten
- Expertise
- Möglichkeiten sondieren
- Ausdruck
- Eigenschaften
- wenige
- Finden Sie
- Suche nach
- findet
- Vorname
- passen
- folgen
- folgt
- Aussichten für
- FRAME
- für
- Funktion
- bekommen
- bekommen
- gegeben
- Go
- Kundenziele
- mehr
- Boden
- Anleitungen
- Pflege
- Griff
- Haben
- Hilfe
- hilft
- hier (auf dänisch)
- Ultraschall
- HTTPS
- ICS
- if
- Unausgewogenheit
- importieren
- in
- das
- Index
- Indien
- Indizes
- Information
- Varianten des Eingangssignals:
- Eingänge
- Interesse
- interessant
- Überschneidung
- in
- IT
- nur
- KDnuggets
- Wissen
- Wissen
- Label
- Etiketten
- Sprache
- LERNEN
- gelernt
- lernen
- weniger
- lassen
- Bibliothek
- Lizenz
- Zugelassen
- Gefällt mir
- Wahrscheinlichkeit
- Gleichen
- Line
- Laden
- Log
- aussehen
- aussehen wie
- Verlust
- Maschine
- Maschinelles Lernen
- um
- viele
- Karte
- Mathe
- Matplotlib
- Maximieren
- Maximierung
- maximal
- Kann..
- bedeuten
- Methode
- Metrik
- minimieren
- Minimum
- Modell
- für
- Modulen
- mehr
- schlauer bewegen
- Namen
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Need
- Negativ
- weiter
- Anzahl
- beobachtet
- of
- vorgenommen,
- on
- EINEM
- Meinung
- gegenüber
- optimal
- Optimierung
- Optimieren
- or
- Ergebnis
- Ergebnisse
- Möglichkeiten für das Ausgangssignal:
- Ausgänge
- Pandas
- Parameter
- Parameter
- Teil
- Stücke
- Plato
- Datenintelligenz von Plato
- PlatoData
- Points
- Punkte
- möglicherweise
- Präzision
- vorhergesagt
- Prognosen
- prädiktive
- Predictor
- sagt voraus,
- bevorzugen
- Wahrscheinlichkeit
- Aufgabenstellung:
- vorgehen
- Prozessdefinierung
- Verarbeitung
- Produkte
- Programmierung
- die
- rein
- Python
- Radar
- Angebot
- Bewerten
- Lesen Sie mehr
- Lesebrillen
- echt
- Aufzeichnungen
- bezeichnet
- bezieht sich
- Regression
- berichten
- Quelle
- representiert
- Anforderung
- Umwelt und Kunden
- beziehungsweise
- Rückgabe
- Überprüfen
- robust
- Regel
- s
- Wissenschaft
- scikit-lernen
- Ergebnis
- sehen
- Sinn
- kompensieren
- Sets
- ,,teilen"
- sie
- gezeigt
- Einfacher
- vereinfachen
- So
- einige
- gespalten
- begonnen
- Statistiken
- Schritt
- mit Stiel
- Struktur
- Anschließend
- so
- geeignet
- Summen
- Nehmen
- nimmt
- Target
- und Aufgaben
- Technische
- Test
- Testen
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Sie
- Theorie
- Dort.
- deswegen
- vom Nutzer definierten
- fehlen uns die Worte.
- Durch
- zu
- Tools
- Training
- trainiert
- Ausbildung
- Transformieren
- Transformationen
- versuchen
- Lernprogramm
- Tutorials
- XNUMX
- Typen
- für
- verstehen
- Einheit
- Aktualisierung
- Updates
- URL
- us
- US-Konto
- -
- benutzt
- Verwendung von
- Wert
- Werte
- visualisieren
- we
- wann
- welche
- warum
- Wikipedia
- werden wir
- Flügel
- mit
- Arbeiten
- arbeiten,
- Werk
- würde
- Schriftsteller
- Schreiben
- X
- ja
- U
- Ihr
- Zephyrnet
- Null