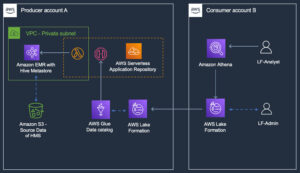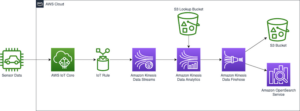
Amazonas Athena ist ein interaktiver Abfragedienst, der die Analyse von Daten in Amazon Simple Storage-Service (Amazon S3) und Datenquellen, die sich in AWS, vor Ort oder anderen Cloud-Systemen befinden und SQL oder Python verwenden. Athena basiert auf den Open-Source-Engines Trino und Presto sowie Apache Spark-Frameworks, ohne dass Bereitstellungs- oder Konfigurationsaufwand erforderlich ist. Athena ist serverlos, daher muss keine Infrastruktur verwaltet werden und Sie zahlen nur für die Abfragen, die Sie ausführen.
Apache Eisberg ist ein offenes Tabellenformat für sehr große analytische Datensätze. Es verwaltet große Dateisammlungen als Tabellen und unterstützt moderne analytische Data-Lake-Vorgänge wie Einfügen, Aktualisieren, Löschen und Zeitreiseabfragen auf Datensatzebene. Athena unterstützt Lese-, Zeitreise-, Schreib- und DDL-Abfragen für Apache Iceberg-Tabellen, die das Apache Parquet-Format für Daten verwenden AWS Glue-Datenkatalog für ihren Metastore.
Feature Engineering ist ein Prozess zur Identifizierung und Transformation von Rohdaten (Bilder, Textdateien, Videos usw.), zum Auffüllen fehlender Daten und zum Hinzufügen eines oder mehrerer aussagekräftiger Datenelemente, um Kontext bereitzustellen, damit ein Modell für maschinelles Lernen (ML) daraus lernen kann. Die Datenkennzeichnung ist für verschiedene Anwendungsfälle erforderlich, darunter Prognosen, Computer Vision, Verarbeitung natürlicher Sprache und Spracherkennung.
In Kombination mit den Funktionen von Athena bietet Apache Iceberg Datenwissenschaftlern einen vereinfachten Arbeitsablauf zum Erstellen neuer Datenfunktionen, ohne dass der gesamte Datensatz kopiert oder neu erstellt werden muss. Sie können Features mit Standard-SQL auf Athena erstellen, ohne einen anderen Dienst für das Feature-Engineering zu verwenden. Datenwissenschaftler können den Zeitaufwand für das Vorbereiten und Kopieren von Datensätzen reduzieren und sich stattdessen auf die Entwicklung von Datenmerkmalen, Experimente und die Analyse von Daten im großen Maßstab konzentrieren.
In diesem Beitrag besprechen wir die Vorteile der Verwendung von Athena mit dem offenen Tabellenformat Apache Iceberg und wie es allgemeine Feature-Engineering-Aufgaben für Datenwissenschaftler vereinfacht. Wir demonstrieren, wie Athena eine vorhandene Tabelle im Apache Iceberg-Format konvertieren, dann Spalten hinzufügen, Spalten löschen und die Daten in der Tabelle ändern kann, ohne den Datensatz neu zu erstellen oder zu kopieren, und diese Funktionen verwenden, um neue Funktionen für Apache Iceberg-Tabellen zu erstellen.
Lösungsüberblick
Datenwissenschaftler sind im Allgemeinen daran gewöhnt, mit großen Datenmengen zu arbeiten. Datensätze werden normalerweise entweder in JSON, CSV, ORC oder gespeichert Apache-Parkett Format oder ähnliche leseoptimierte Formate für eine schnelle Leseleistung. Datenwissenschaftler erstellen häufig neue Datenfunktionen und füllen diese Datenfunktionen mit aggregierten und ergänzenden Daten auf. In der Vergangenheit wurde diese Aufgabe dadurch gelöst, dass eine Ansicht über der Tabelle mit den zugrunde liegenden Daten im Apache-Parquet-Format erstellt wurde, wobei solche Spalten und Daten zur Laufzeit hinzugefügt wurden, oder indem eine neue Tabelle mit zusätzlichen Spalten erstellt wurde. Obwohl dieser Workflow für viele Anwendungsfälle gut geeignet ist, ist er für große Datensätze ineffizient, da Daten zur Laufzeit generiert werden müssten oder Datensätze kopiert und transformiert werden müssten.
Athena hat vorgestellt ACID-Transaktion (Atomizität, Konsistenz, Isolation, Haltbarkeit). Funktionen, die INSERT-, UPDATE-, DELETE-, MERGE- und Zeitreiseoperationen hinzufügen Apache Iceberg-Tabellen. Diese Funktionen ermöglichen es Datenwissenschaftlern, neue Datenfunktionen zu erstellen und vorhandene Datenfunktionen auf vorhandene Datensätze zu übertragen, ohne sich Gedanken über das Kopieren oder Transformieren des Datensatzes oder dessen Abstrahierung mit einer Ansicht machen zu müssen. Datenwissenschaftler können sich auf die Feature-Engineering-Arbeit konzentrieren und das Kopieren und Transformieren der Datensätze vermeiden.
Der Athena Iceberg UPDATE-Vorgang schreibt Apache Iceberg-Positionslöschdateien und neu aktualisierte Zeilen als Datendateien in derselben Transaktion. Sie können Datensatzkorrekturen über eine einzige UPDATE-Anweisung vornehmen.
Mit der Veröffentlichung der Athena-Engine Version 3 werden die Funktionen für Apache Iceberg-Tabellen durch die Unterstützung von Vorgängen wie erweitert TABELLE ALS AUSWÄHLEN ERSTELLEN (CTAS) und MERGE-Befehle, die die Lebenszyklusverwaltung Ihrer Iceberg-Daten optimieren. CTAS ermöglicht die schnelle und effiziente Erstellung von Tabellen aus anderen Formaten wie Apache Paquet und VEREINEN Bedingte Aktualisierungen, Löschungen oder das Einfügen von Zeilen in eine Iceberg-Tabelle. Eine einzelne Anweisung kann Aktualisierungs-, Lösch- und Einfügeaktionen kombinieren.
Voraussetzungen:
Richten Sie eine Athena-Arbeitsgruppe mit der Athena-Engine Version 3 ein, um CTAS- und MERGE-Befehle mit einer Apache Iceberg-Tabelle zu verwenden. Um Ihre vorhandene Athena-Engine in Ihrer Athena-Arbeitsgruppe auf Version 3 zu aktualisieren, befolgen Sie die Anweisungen unter Führen Sie ein Upgrade auf Version 3 der Athena-Engine durch, um die Abfrageleistung zu steigern und auf mehr Analysefunktionen zuzugreifen oder beziehen sich auf Ändern der Engine-Version in der Athena-Konsole.
Datensatz
Zur Demonstration verwenden wir eine Apache-Parquet-Tabelle, die mehrere Millionen Datensätze zufällig verteilter fiktiver Verkaufsdaten der letzten Jahre enthält, die in einem S3-Bucket gespeichert sind. Herunterladen Entpacken Sie den Datensatz auf Ihrem lokalen Computer und laden Sie ihn in Ihren S3-Bucket hoch. In diesem Beitrag haben wir unseren Datensatz hochgeladen s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
Die folgende Tabelle zeigt das Layout der Tabelle customer_orders.
| Spaltenname | Dateityp | Beschreibung |
| Bestellschlüssel | Schnur | Bestellnummer für die Bestellung |
| Kundenschlüssel | Schnur | Kundenidentifikationsnummer |
| Auftragsstatus | Schnur | Status der Bestellung |
| Gesamtpreis | Schnur | Gesamtpreis der Bestellung |
| Auftragsdatum | Schnur | Datum der Bestellung |
| Bestellpriorität | Schnur | Priorität der Bestellung |
| Schreiber | Schnur | Name des Sachbearbeiters, der die Bestellung bearbeitet hat |
| Schiffspriorität | Schnur | Priorität beim Versand |
| Name | Schnur | Kundenname |
| Adresse | Schnur | Kundenadresse |
| Nationkey | Schnur | Länderschlüssel des Kunden |
| Telefon | Schnur | Telefonnummer des Kunden |
| acctbal | Schnur | Kontostand des Kunden |
| mktsegment | Schnur | Kundenmarktsegment |
Feature-Engineering durchführen
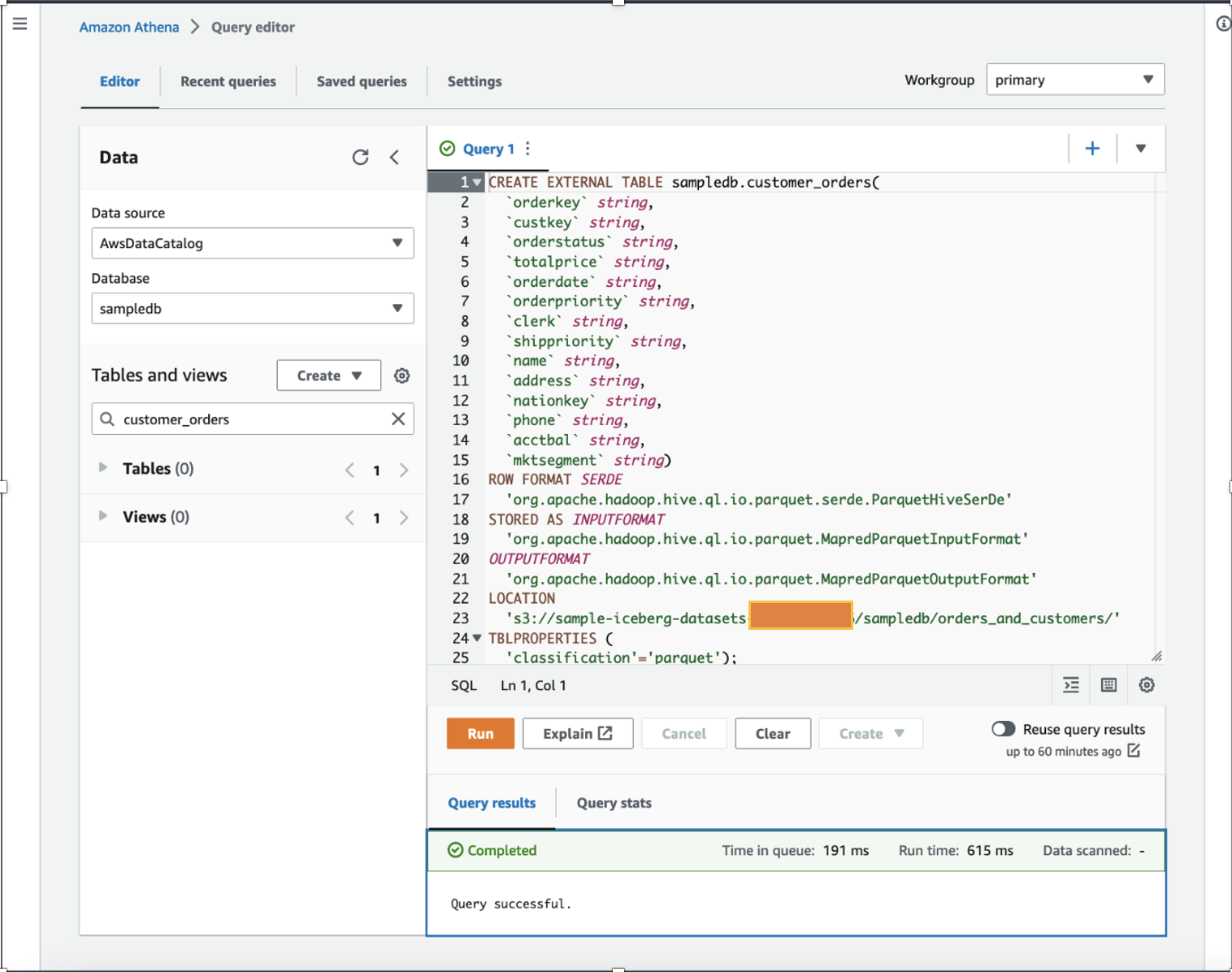
Als Datenwissenschaftler wollen wir Leistung erbringen Feature Engineering auf den Daten zu Kundenbestellungen, indem für jeden Kunden im vorhandenen Datensatz die berechneten Gesamteinkäufe für ein Jahr und die durchschnittlichen Einkäufe für ein Jahr addiert werden. Zu Demonstrationszwecken haben wir das erstellt customer_orders Tisch im sampledb Datenbank mithilfe von Athena, wie im folgenden DDL-Befehl gezeigt. (Sie können jeden Ihrer vorhandenen Datensätze verwenden und die in diesem Beitrag genannten Schritte befolgen.) Die customer_orders Der Datensatz wurde generiert und am S3-Bucket-Speicherort gespeichert s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ im Parkettformat. Diese Tabelle ist keine Apache Iceberg-Tabelle.
![]()
Validieren Sie die Daten in der Tabelle, indem Sie eine Abfrage ausführen:
![]()
Wir möchten dieser Tabelle neue Funktionen hinzufügen, um ein tieferes Verständnis der Kundenverkäufe zu erhalten, was zu einer schnelleren Modellschulung und wertvolleren Erkenntnissen führen kann. Um dem Datensatz neue Features hinzuzufügen, konvertieren Sie die customer_orders Athena-Tisch zum Apache Iceberg-Tisch auf Athena. Ausgabe a CTAS Abfrageanweisung zum Erstellen einer neuen Tabelle im Apache Iceberg-Format aus dem customer_orders Tisch. Dabei wird eine neue Funktion hinzugefügt, um den Gesamtkaufbetrag im vergangenen Jahr (maximales Jahr des Datensatzes) für jeden Kunden zu ermitteln.
In der folgenden CTAS-Abfrage wird eine neue Spalte mit dem Namen one_year_sales_aggregate mit dem Standardwert as 0.0 des Datentyps double hinzugefügt wird und table_type eingestellt ist ICEBERG:
![]()
Geben Sie die folgende Abfrage aus, um die Daten in der Apache Iceberg-Tabelle mit der neuen Spalte zu überprüfen one_year_sales_aggregate Werte wie 0.0:
![]()
Wir möchten die Werte für die neue Funktion füllen one_year_sales_aggregate im Datensatz, um den Gesamtkaufbetrag für jeden Kunden basierend auf seinen Einkäufen im vergangenen Jahr (maximales Jahr des Datensatzes) zu erhalten. Geben Sie eine MERGE-Abfrageanweisung an die Apache Iceberg-Tabelle aus, indem Sie Athena verwenden, um Werte für zu füllen one_year_sales_aggregate Feature:
![]()
Führen Sie die folgende Abfrage aus, um den aktualisierten Wert für die Gesamtausgaben jedes Kunden im vergangenen Jahr zu validieren:
![]()
Wir beschließen, einer vorhandenen Apache Iceberg-Tabelle eine weitere Funktion hinzuzufügen, um den durchschnittlichen Kaufbetrag jedes Kunden im vergangenen Jahr zu berechnen und zu speichern. Geben Sie eine ALTER-Abfrageanweisung aus, um einer vorhandenen Tabelle für ein Feature eine neue Spalte hinzuzufügen one_year_sales_average:
![]()
Bevor Sie die Werte für dieses neue Feature eingeben, können Sie den Standardwert für das Feature festlegen one_year_sales_average zu 0.0. Geben Sie unter Verwendung derselben Apache Iceberg-Tabelle auf Athena eine UPDATE-Abfrageanweisung aus, um den Wert für die neue Funktion als aufzufüllen 0.0:
![]()
Führen Sie die folgende Abfrage aus, um zu überprüfen, ob der aktualisierte Wert für die durchschnittlichen Ausgaben jedes Kunden im vergangenen Jahr festgelegt ist 0.0:
![]()
Jetzt wollen wir die Werte für die neue Funktion füllen one_year_sales_average im Datensatz, um den durchschnittlichen Kaufbetrag für jeden Kunden basierend auf seinen Einkäufen im vergangenen Jahr (maximales Jahr des Datensatzes) zu erhalten. Geben Sie eine MERGE-Abfrageanweisung an die vorhandene Apache Iceberg-Tabelle auf Athena aus, indem Sie die Athena-Engine verwenden, um Werte für die Funktion zu füllen one_year_sales_average:
![]()
Führen Sie die folgende Abfrage aus, um die aktualisierten Werte für die durchschnittlichen Ausgaben jedes Kunden zu überprüfen:
![]()
Sobald dem Datensatz zusätzliche Datenfunktionen hinzugefügt wurden, trainieren Datenwissenschaftler im Allgemeinen ML-Modelle und ziehen Schlussfolgerungen mithilfe von Amazon Sagemaker oder einem gleichwertigen Toolset.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie man Feature Engineering mit Athena und Apache Iceberg durchführt. Wir haben außerdem die Verwendung der CTAS-Abfrage zum Erstellen einer Apache Iceberg-Tabelle auf Athena aus einem vorhandenen Datensatz im Apache Parquet-Format, das Hinzufügen neuer Funktionen in einer vorhandenen Apache Iceberg-Tabelle auf Athena mithilfe der ALTER-Abfrage und die Verwendung von UPDATE- und MERGE-Abfrageanweisungen zum Aktualisieren demonstriert Merkmalswerte vorhandener Spalten.
Wir empfehlen Ihnen, CTAS-Abfragen zu verwenden, um Tabellen schnell und effizient zu erstellen, und die MERGE-Abfrageanweisung zu verwenden, um Tabellen in einem Schritt zu synchronisieren, um Datenvorbereitungen und Aktualisierungsaufgaben bei der Transformation der Funktionen mithilfe von Athena mit Apache Iceberg zu vereinfachen. Wenn Sie Kommentare oder Feedback haben, hinterlassen Sie diese bitte im Kommentarbereich.
Über die Autoren
![]() Vivek Gautam ist ein Datenarchitekt mit Spezialisierung auf Data Lakes bei AWS Professional Services. Er arbeitet mit Unternehmenskunden zusammen, die Datenprodukte, Analyseplattformen und Lösungen auf AWS entwickeln. Wenn er nicht gerade moderne Datenplattformen baut und gestaltet, ist Vivek ein Food-Enthusiast, der auch gerne neue Reiseziele erkundet und Wanderungen unternimmt.
Vivek Gautam ist ein Datenarchitekt mit Spezialisierung auf Data Lakes bei AWS Professional Services. Er arbeitet mit Unternehmenskunden zusammen, die Datenprodukte, Analyseplattformen und Lösungen auf AWS entwickeln. Wenn er nicht gerade moderne Datenplattformen baut und gestaltet, ist Vivek ein Food-Enthusiast, der auch gerne neue Reiseziele erkundet und Wanderungen unternimmt.
![]() Michail Vaynshteyn ist ein Lösungsarchitekt bei Amazon Web Services. Mikhail arbeitet mit Kunden aus dem Gesundheitswesen und den Biowissenschaften zusammen, um Lösungen zu entwickeln, die dazu beitragen, die Ergebnisse der Patienten zu verbessern. Mikhail ist auf Datenanalysedienste spezialisiert.
Michail Vaynshteyn ist ein Lösungsarchitekt bei Amazon Web Services. Mikhail arbeitet mit Kunden aus dem Gesundheitswesen und den Biowissenschaften zusammen, um Lösungen zu entwickeln, die dazu beitragen, die Ergebnisse der Patienten zu verbessern. Mikhail ist auf Datenanalysedienste spezialisiert.
![]() Naresh Gautam ist ein Data Analytics- und KI/ML-Leiter bei AWS mit 20 Jahren Erfahrung, der Kunden gerne dabei unterstützt, hochverfügbare, leistungsstarke und kostengünstige Datenanalyse- und KI/ML-Lösungen zu entwickeln, um Kunden eine datengesteuerte Entscheidungsfindung zu ermöglichen . In seiner Freizeit meditiert und kocht er gerne.
Naresh Gautam ist ein Data Analytics- und KI/ML-Leiter bei AWS mit 20 Jahren Erfahrung, der Kunden gerne dabei unterstützt, hochverfügbare, leistungsstarke und kostengünstige Datenanalyse- und KI/ML-Lösungen zu entwickeln, um Kunden eine datengesteuerte Entscheidungsfindung zu ermöglichen . In seiner Freizeit meditiert und kocht er gerne.
![]() Harsha Tadiparthi ist ein spezialisierter Principal Solutions Architect, Analytics bei AWS. Er löst gerne komplexe Kundenprobleme in Datenbanken und Analysen und liefert erfolgreiche Ergebnisse. Außerhalb der Arbeit verbringt er gerne Zeit mit seiner Familie, schaut sich Filme an und reist wann immer möglich.
Harsha Tadiparthi ist ein spezialisierter Principal Solutions Architect, Analytics bei AWS. Er löst gerne komplexe Kundenprobleme in Datenbanken und Analysen und liefert erfolgreiche Ergebnisse. Außerhalb der Arbeit verbringt er gerne Zeit mit seiner Familie, schaut sich Filme an und reist wann immer möglich.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- EVM-Finanzen. Einheitliche Schnittstelle für dezentrale Finanzen. Hier zugreifen.
- Quantum Media Group. IR/PR verstärkt. Hier zugreifen.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 10
- 100
- 12
- 17
- 20
- 20 Jahre
- 23
- 27
- 7
- a
- Über Uns
- beschleunigen
- Zugang
- erreicht
- Konto
- Aktionen
- hinzufügen
- hinzugefügt
- Hinzufügen
- Zusätzliche
- Adresse
- AI / ML
- ebenfalls
- Obwohl
- Amazon
- Amazonas Athena
- Amazon Sage Maker
- Amazon Web Services
- Betrag
- an
- Analytisch
- Analytische
- Analytik
- analysieren
- Analyse
- und
- Ein anderer
- jedem
- Apache
- Apache Funken
- SIND
- AS
- At
- verfügbar
- durchschnittlich
- vermeiden
- AWS
- Professionelle AWS-Services
- basierend
- BE
- weil
- war
- Vorteile
- bauen
- Building
- erbaut
- by
- berechnet
- CAN
- Fähigkeiten
- Fälle
- Einstufung
- Cloud
- Produktauswahl
- Kolonne
- Spalten
- kombinieren
- Bemerkungen
- gemeinsam
- Komplex
- Berechnen
- Computer
- Computer Vision
- Konfiguration
- enthält
- Kontext
- verkaufen
- Kochen
- Kopieren
- Korrekturen
- kostengünstiger
- erstellen
- erstellt
- Erstellen
- Kunde
- Kunden
- technische Daten
- Datenanalyse
- Datensee
- Datenwissenschaft
- Datenwissenschaftler
- datengesteuerte
- Datenbase
- Datenbanken
- Datensätze
- Datum
- entscheidet
- Decision Making
- tiefer
- Standard
- liefern
- liefert
- zeigen
- Synergie
- Entwerfen
- Reiseziele
- verteilt
- Dabei
- doppelt
- Drop
- Haltbarkeit
- jeder
- Einfache
- effizient
- effizient
- Anstrengung
- entweder
- Elemente
- ermächtigen
- ermöglichen
- ermutigen
- Motor
- Entwicklung
- Motor (en)
- verbesserte
- Unternehmen
- Unternehmenskunden
- Enthusiast
- Ganz
- Äquivalent
- Äther (ETH)
- vorhandenen
- ERFAHRUNGEN
- ERKUNDEN
- extern
- falsch
- Familie
- FAST
- beschleunigt
- Merkmal
- Eigenschaften
- Feedback
- Mappen
- Setzen Sie mit Achtsamkeit
- folgen
- Folgende
- Nahrung,
- Aussichten für
- Format
- Gerüste
- Frei
- für
- allgemein
- erzeugt
- bekommen
- Go
- Gruppe an
- Hadoop
- Haben
- he
- Gesundheitswesen
- Hilfe
- Unternehmen
- Hohe Leistungsfähigkeit
- hoch
- Wanderungen
- seine
- historisch
- Bienenstock
- Ultraschall
- Hilfe
- HTML
- HTTPS
- Login
- Identifizierung
- if
- Bilder
- zu unterstützen,
- in
- Einschließlich
- Erhöhung
- ineffizient
- Infrastruktur
- Einsätze
- Einblicke
- beantragen müssen
- Anleitung
- interaktive
- in
- eingeführt
- Isolierung
- Problem
- IT
- jpg
- JSON
- Beschriftung
- See
- Sprache
- grosse
- Nachname
- Layout
- Führer
- LERNEN
- lernen
- Verlassen
- Lebensdauer
- Biowissenschaften
- Lebenszyklus
- LIMIT
- aus einer regionalen
- Standorte
- liebt
- Maschine
- Maschinelles Lernen
- um
- MACHT
- verwalten
- Management
- Managed
- viele
- Markt
- abgestimmt
- max
- sinnvoll
- Meditation
- erwähnt
- Merge
- Million
- Kommt demnächst...
- ML
- Modell
- für
- modern
- ändern
- mehr
- Filme
- Name
- Namens
- Nation gemacht haben
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Need
- benötigen
- Neu
- neue Funktion
- Neue Funktionen
- neu
- nicht
- Anzahl
- of
- vorgenommen,
- on
- EINEM
- einzige
- XNUMXh geöffnet
- Open-Source-
- Betrieb
- Einkauf & Prozesse
- or
- Bestellungen
- Andere
- UNSERE
- Ergebnisse
- aussen
- passt
- AUFMERKSAMKEIT
- ausführen
- Leistung
- Telefon
- Plattformen
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Position
- möglich
- Post
- Vorbereitung
- Preis
- Principal
- Probleme
- Prozessdefinierung
- verarbeitet
- Verarbeitung
- Produkte
- Professionell
- die
- Kauf
- Einkäufe
- Zwecke
- Python
- Abfragen
- schnell
- Roh
- Rohdaten
- Lesen Sie mehr
- Anerkennung
- Rekord
- Aufzeichnungen
- Veteran
- Release
- falls angefordert
- Folge
- Überprüfen
- REIHE
- Führen Sie
- Laufen
- sagemaker
- Vertrieb
- gleich
- Skalieren
- Wissenschaft
- WISSENSCHAFTEN
- Wissenschaftler
- Wissenschaftler
- Abschnitt
- Serverlos
- Lösungen
- kompensieren
- mehrere
- gezeigt
- Konzerte
- ähnlich
- Einfacher
- vereinfachte
- vereinfachen
- Single
- So
- Lösungen
- Auflösung
- Quellen
- Spark
- Spezialist
- spezialisiert
- Rede
- Spracherkennung
- verbringen
- verbrachte
- SQL
- Standard
- Erklärung
- Aussagen
- Schritt
- Shritte
- Lagerung
- speichern
- gelagert
- rationalisieren
- Schnur
- erfolgreich
- so
- Support
- Unterstützt
- Systeme und Techniken
- Tabelle
- Aufgabe
- und Aufgaben
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Fusion
- ihr
- Sie
- dann
- Dort.
- Diese
- fehlen uns die Worte.
- Zeit
- Zeitreise
- zu
- Top
- Gesamt
- Training
- Ausbildung
- Transaktion
- Transaktion
- verwandelt
- Transformieren
- reisen
- tippe
- zugrunde liegen,
- Verständnis
- Aktualisierung
- aktualisiert
- Updates
- mehr Stunden
- hochgeladen
- -
- Verwendung von
- gewöhnlich
- BESTÄTIGEN
- wertvoll
- Wert
- Werte
- verschiedene
- überprüfen
- Version
- sehr
- Videos
- Anzeigen
- Seh-
- wollen
- wurde
- Ansehen
- we
- Netz
- Web-Services
- waren
- wann
- sobald
- welche
- während
- WHO
- mit
- ohne
- Arbeiten
- Arbeitsablauf.
- Arbeitsgruppen
- arbeiten,
- Werk
- würde
- schreiben
- Jahr
- Jahr
- U
- Ihr
- Zephyrnet
- PLZ