Pandas ist eine leistungsstarke und weit verbreitete Open-Source-Bibliothek zur Datenbearbeitung und -analyse mit Python. Eine seiner Hauptfunktionen ist die Möglichkeit, Daten mithilfe der Groupby-Funktion zu gruppieren, indem ein DataFrame basierend auf einer oder mehreren Spalten in Gruppen aufgeteilt und anschließend verschiedene Aggregationsfunktionen auf jede einzelne Spalte angewendet werden.

Bild aus Unsplash
Das groupby Die Funktion ist unglaublich leistungsstark, da sie es Ihnen ermöglicht, große Datensätze schnell zusammenzufassen und zu analysieren. Sie können beispielsweise einen Datensatz nach einer bestimmten Spalte gruppieren und den Mittelwert, die Summe oder die Anzahl der verbleibenden Spalten für jede Gruppe berechnen. Sie können auch nach mehreren Spalten gruppieren, um ein detaillierteres Verständnis Ihrer Daten zu erhalten. Darüber hinaus können Sie benutzerdefinierte Aggregationsfunktionen anwenden, die ein sehr leistungsfähiges Werkzeug für komplexe Datenanalyseaufgaben sein können.
In diesem Tutorial erfahren Sie, wie Sie die Groupby-Funktion in Pandas verwenden, um verschiedene Datentypen zu gruppieren und verschiedene Aggregationsvorgänge durchzuführen. Am Ende dieses Tutorials sollten Sie in der Lage sein, diese Funktion zum Analysieren und Zusammenfassen von Daten auf verschiedene Arten zu verwenden.
Konzepte werden verinnerlicht, wenn sie gut geübt werden, und das ist es, was wir als nächstes tun werden, nämlich die Groupby-Funktion von Pandas praktisch auszuprobieren. Es wird empfohlen, a zu verwenden Jupyter Notizbuch für dieses Tutorial, da Sie die Ausgabe bei jedem Schritt sehen können.
Generieren Sie Beispieldaten
Importieren Sie die folgenden Bibliotheken:
- Pandas: Zum Erstellen eines Datenrahmens und Anwenden der Gruppierung nach
- Zufällig – Um Zufallsdaten zu generieren
- Pprint – Zum Drucken von Wörterbüchern
import pandas as pd
import random
import pprint
Als Nächstes initialisieren wir einen leeren Datenrahmen und geben Werte für jede Spalte ein, wie unten gezeigt:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Bonus-Tipp: Eine sauberere Möglichkeit, dieselbe Aufgabe zu erledigen, besteht darin, ein Wörterbuch aller Variablen und Werte zu erstellen und es später in einen Datenrahmen zu konvertieren.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
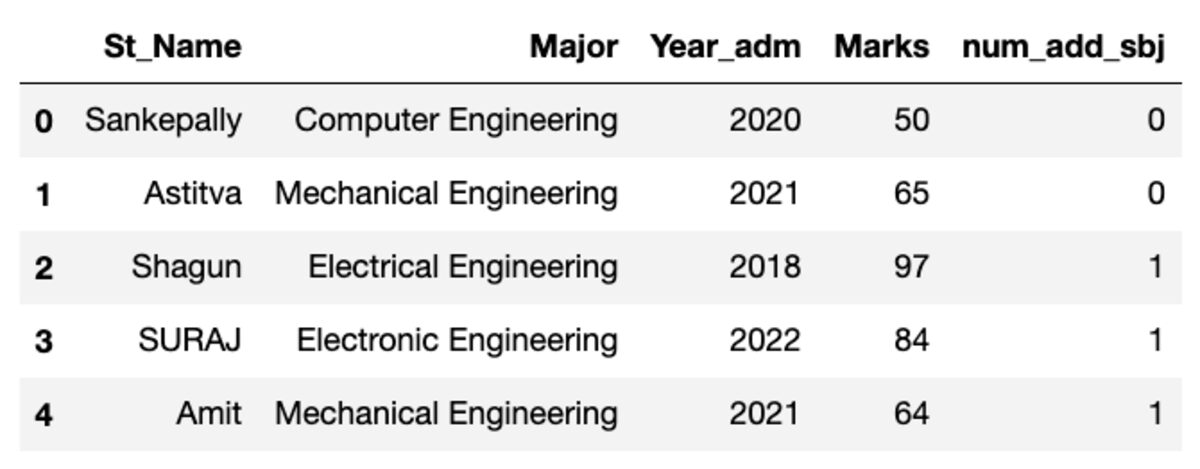
Der Datenrahmen sieht wie unten gezeigt aus. Beim Ausführen dieses Codes stimmen einige Werte nicht überein, da wir eine Zufallsstichprobe verwenden.
Gruppen bilden
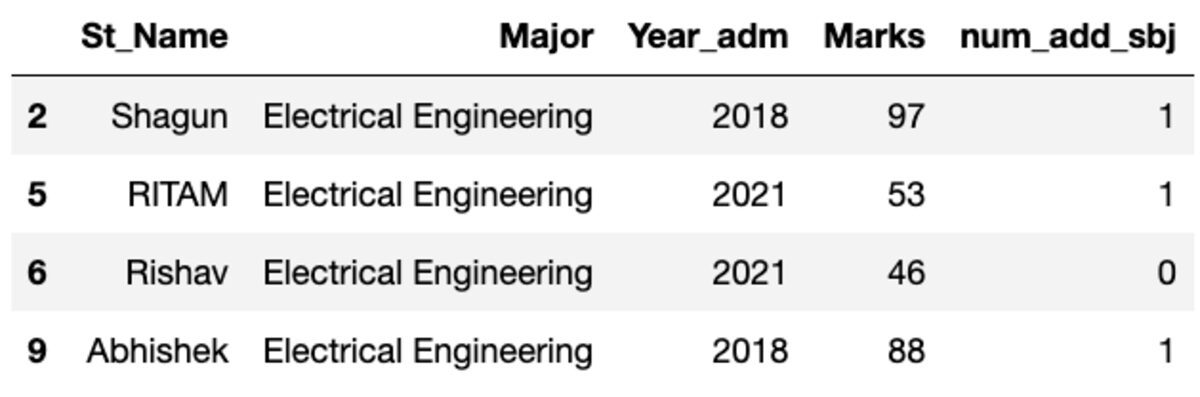
Lassen Sie uns die Daten nach dem „Hauptthema“ gruppieren und den Gruppenfilter anwenden, um zu sehen, wie viele Datensätze in diese Gruppe fallen.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Dem Hauptfach Elektrotechnik gehören somit vier Studierende an.
Sie können auch nach mehr als einer Spalte gruppieren (in diesem Fall Major und num_add_sbj).
groups = df.groupby(['Major', 'num_add_sbj'])
Beachten Sie, dass alle Aggregatfunktionen, die auf Gruppen mit einer Spalte angewendet werden können, auch auf Gruppen mit mehreren Spalten angewendet werden können. Im weiteren Verlauf des Tutorials konzentrieren wir uns auf die verschiedenen Arten von Aggregationen am Beispiel einer einzelnen Spalte.
Lassen Sie uns mithilfe von Groupby in der Spalte „Major“ Gruppen erstellen.
groups = df.groupby('Major')Anwenden direkter Funktionen
Nehmen wir an, Sie möchten die Durchschnittsnoten in jedem Hauptfach ermitteln. Was würden Sie tun?
- Wählen Sie die Spalte „Markierungen“.
- Wenden Sie die Mittelwertfunktion an
- Rundenfunktion anwenden, um Noten auf zwei Dezimalstellen abzurunden (optional)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Aggregat
Eine andere Möglichkeit, das gleiche Ergebnis zu erzielen, ist die Verwendung einer Aggregatfunktion wie unten gezeigt:
groups['Marks'].aggregate('mean').round(2)
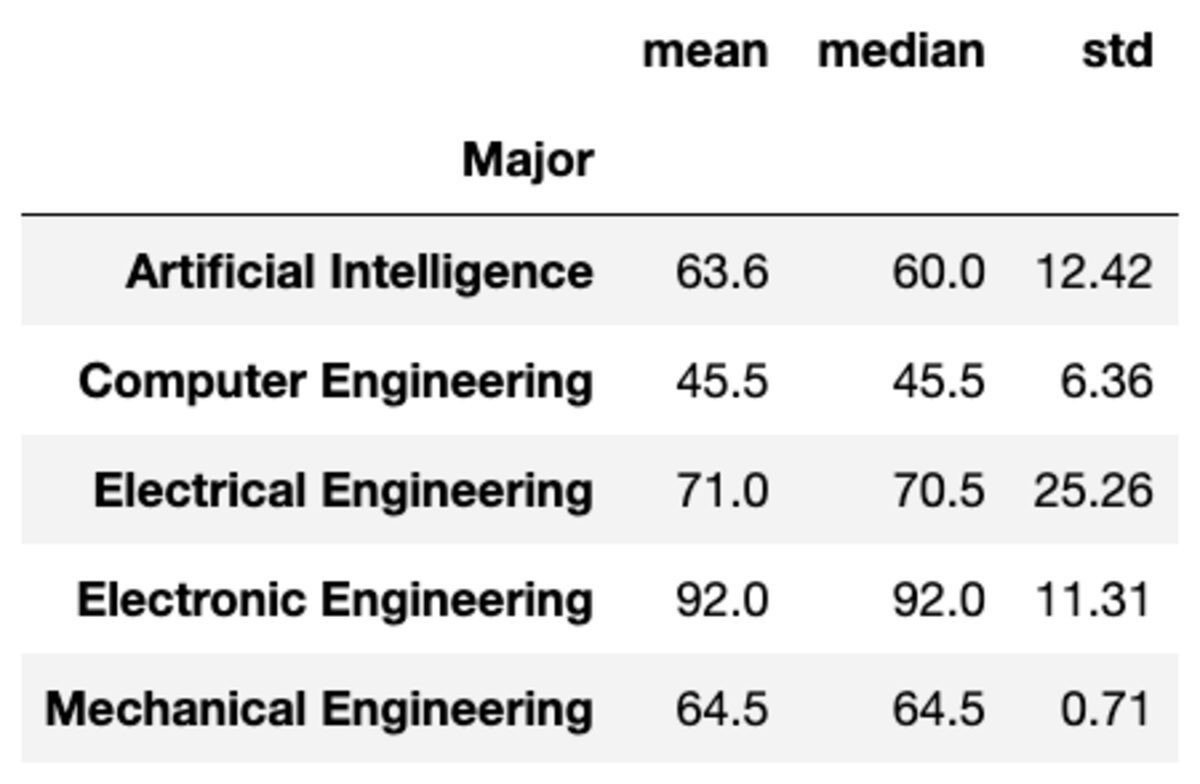
Sie können auch mehrere Aggregationen auf die Gruppen anwenden, indem Sie die Funktionen als Liste von Zeichenfolgen übergeben.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
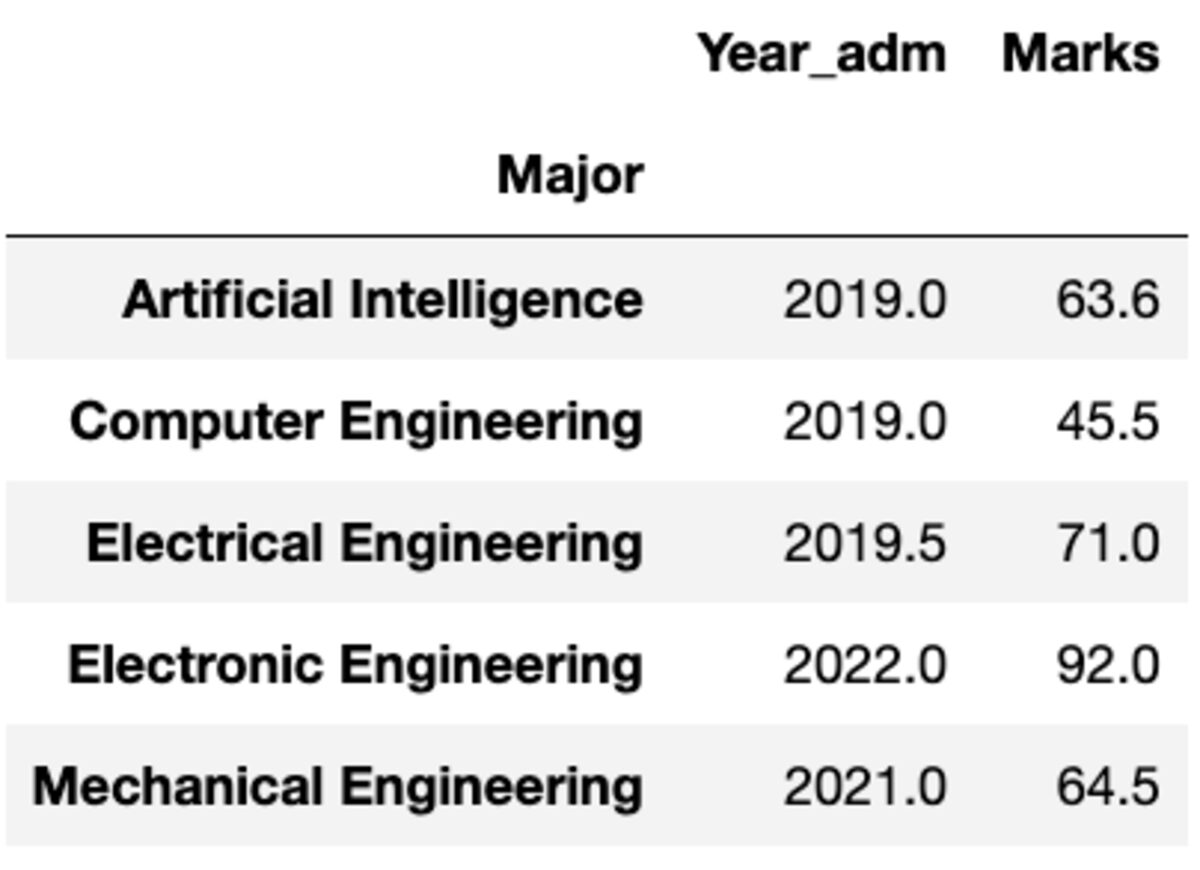
Was aber, wenn Sie eine andere Funktion auf eine andere Spalte anwenden müssen? Mach dir keine Sorge. Sie können dies auch tun, indem Sie das Paar {column: function} übergeben.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Verwandelt sich
Möglicherweise müssen Sie benutzerdefinierte Transformationen für eine bestimmte Spalte durchführen, was mit groupby() einfach möglich ist. Definieren wir einen Standardskalar, der dem im Vorverarbeitungsmodul von sklearn verfügbaren ähnelt. Sie können alle Spalten transformieren, indem Sie die Transformationsmethode aufrufen und die benutzerdefinierte Funktion übergeben.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
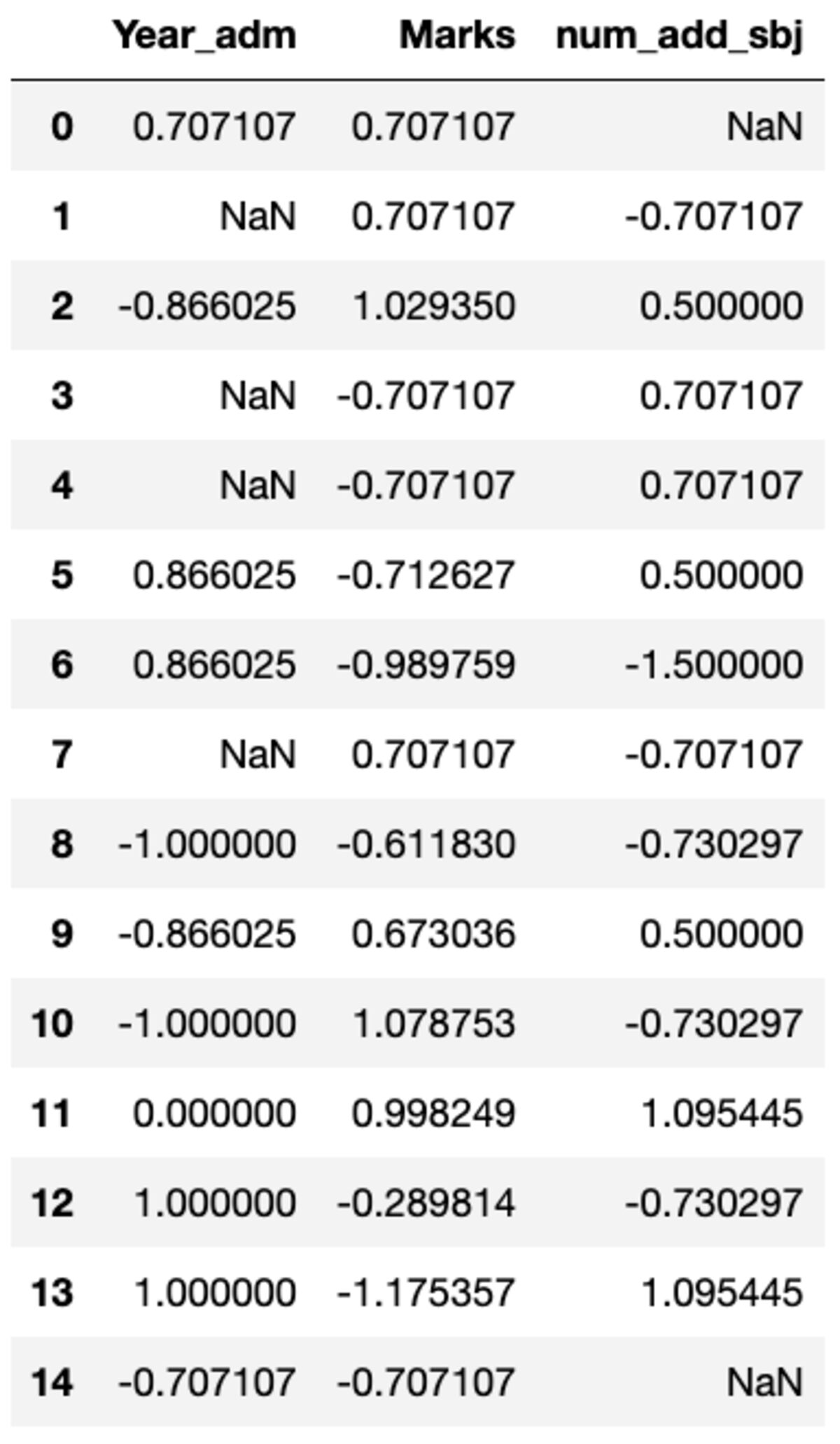
Beachten Sie, dass „NaN“ Gruppen mit einer Standardabweichung von Null darstellt.
Filter
Möglicherweise möchten Sie überprüfen, welches Hauptfach schlechter abschneidet, d. h. das Hauptfach, bei dem die durchschnittliche „Noten“ der Schüler unter 60 liegt. Dazu müssen Sie eine Filtermethode auf Gruppen anwenden, die eine Funktion enthalten. Der folgende Code verwendet a Lambda-Funktion um die gefilterten Ergebnisse zu erzielen.
groups.filter(lambda x: x['Marks'].mean() 60)

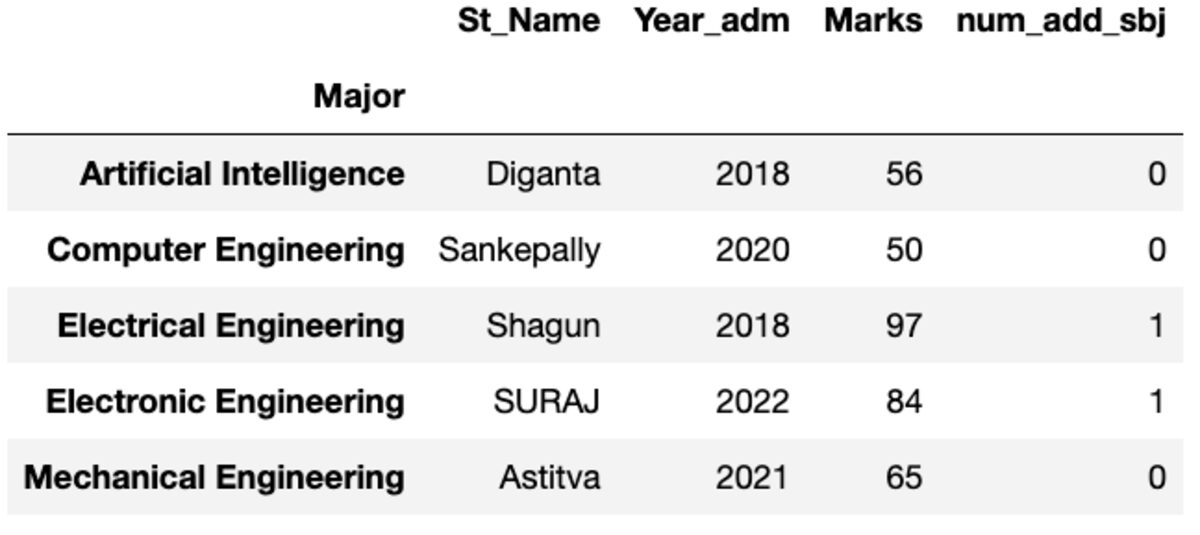
Vorname
Sie erhalten die erste Instanz, sortiert nach Index.
groups.first()
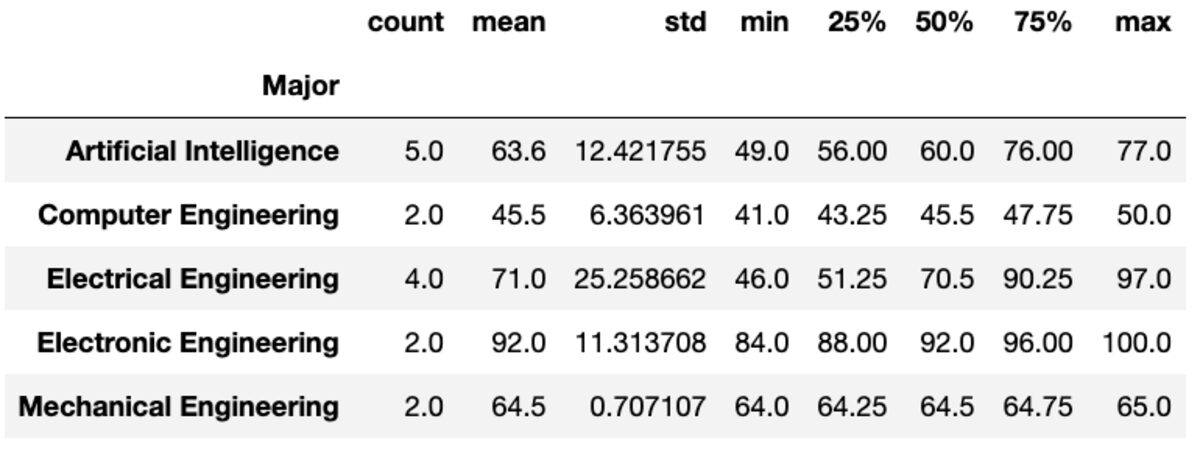
Beschreiben
Die Methode „describe“ gibt grundlegende Statistiken wie Anzahl, Mittelwert, Standard, Min, Max usw. für die angegebenen Spalten zurück.
groups['Marks'].describe()
Größe
Wie der Name schon sagt, gibt „Size“ die Größe jeder Gruppe in Bezug auf die Anzahl der Datensätze zurück.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Graf und Nunique
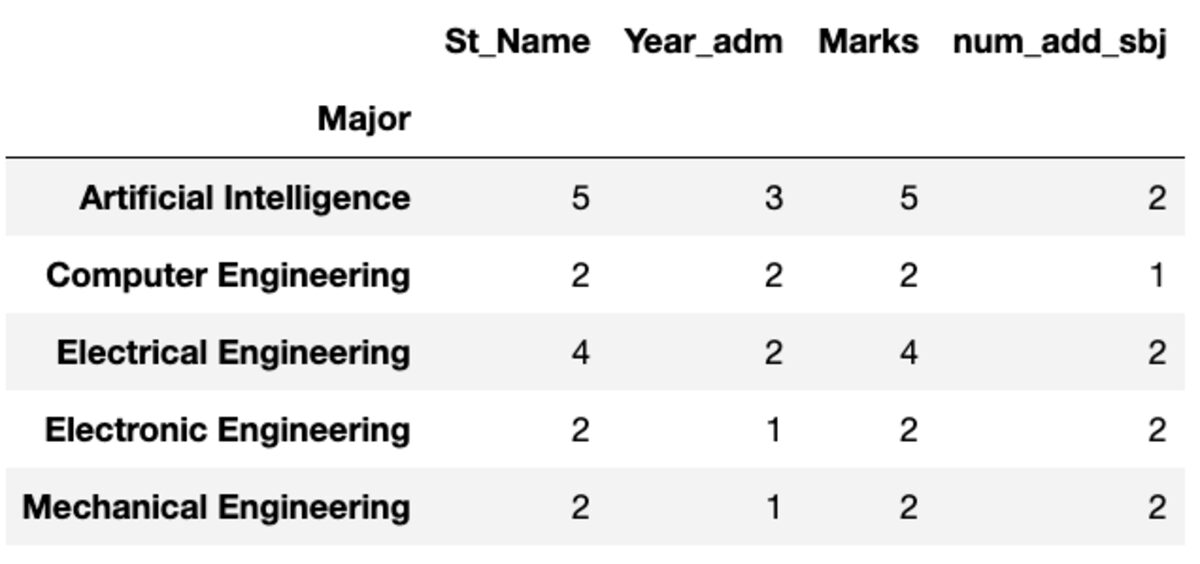
„Count“ gibt alle Werte zurück, während „Nunique“ nur die eindeutigen Werte in dieser Gruppe zurückgibt.
groups.count()
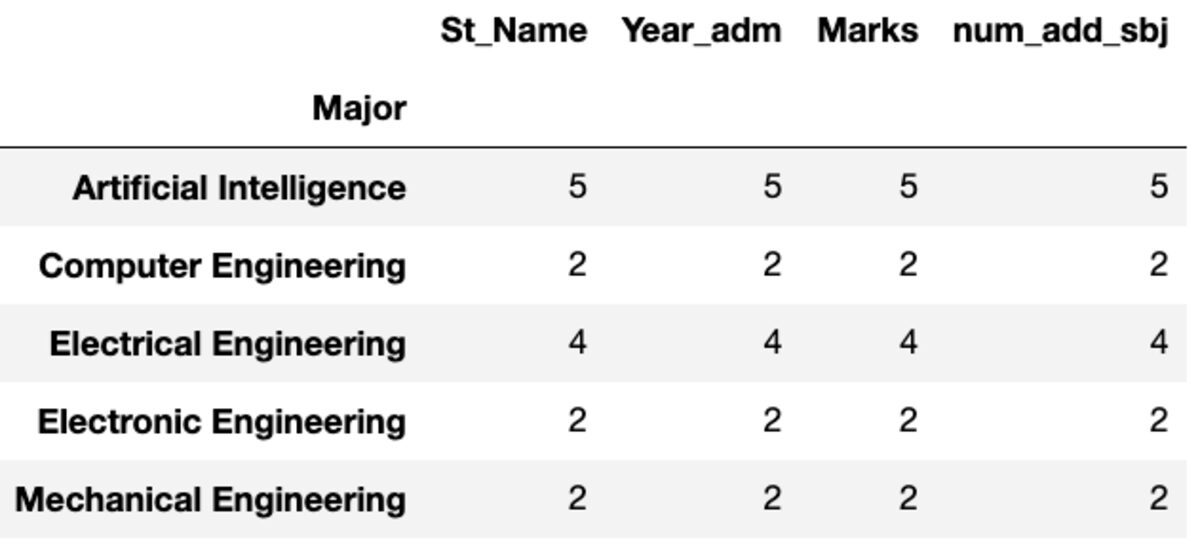
groups.nunique()
Umbenennen
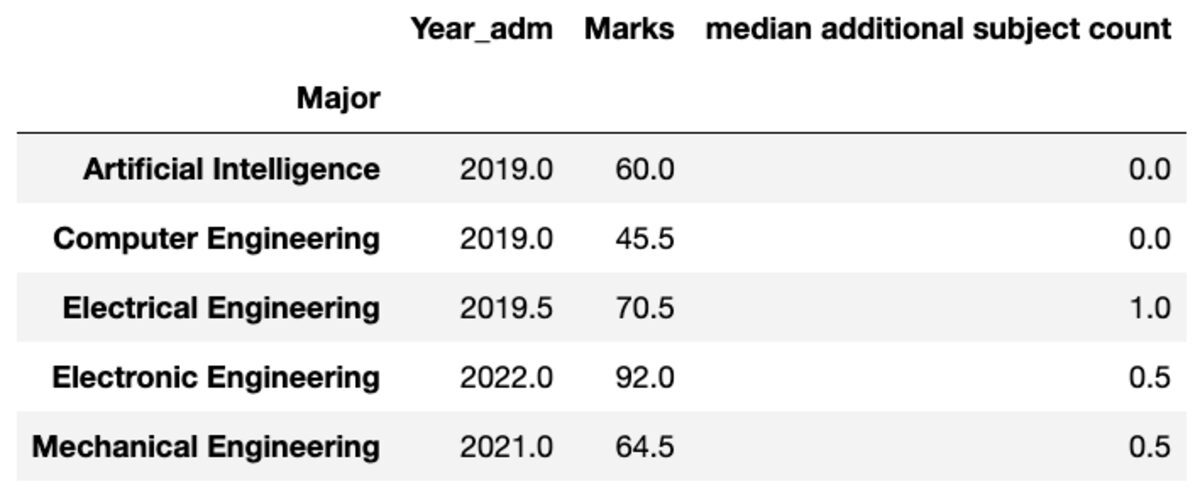
Sie können den Namen der aggregierten Spalten auch nach Ihren Wünschen umbenennen.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Machen Sie sich den Zweck des Groupby klar: Versuchen Sie, die Daten nach einer Spalte zu gruppieren, um den Mittelwert einer anderen Spalte zu ermitteln? Oder versuchen Sie, die Daten nach mehreren Spalten zu gruppieren, um die Anzahl der Zeilen in jeder Gruppe zu ermitteln?
- Verstehen Sie die Indizierung des Datenrahmens: Die Groupby-Funktion verwendet den Index, um die Daten zu gruppieren. Wenn Sie die Daten nach einer Spalte gruppieren möchten, stellen Sie sicher, dass die Spalte als Index festgelegt ist, oder Sie können .set_index() verwenden.
- Verwenden Sie die entsprechende Aggregatfunktion: Es kann mit verschiedenen Aggregationsfunktionen wie mean(), sum(), count(), min(), max() verwendet werden
- Verwenden Sie den Parameter as_index: Wenn dieser Parameter auf „Falsch“ gesetzt ist, weist er Pandas an, die gruppierten Spalten als reguläre Spalten statt als Index zu verwenden.
Sie können groupby() auch in Verbindung mit anderen Pandas-Funktionen wie Pivot_table(), Crosstab() und Cut() verwenden, um mehr Erkenntnisse aus Ihren Daten zu gewinnen.
Eine Groupby-Funktion ist ein leistungsstarkes Werkzeug zur Datenanalyse und -bearbeitung, da sie es Ihnen ermöglicht, Datenzeilen basierend auf einer oder mehreren Spalten zu gruppieren und dann aggregierte Berechnungen für die Gruppen durchzuführen. Das Tutorial demonstrierte anhand von Codebeispielen verschiedene Möglichkeiten, die Groupby-Funktion zu verwenden. Ich hoffe, es vermittelt Ihnen ein Verständnis für die verschiedenen Optionen, die damit verbunden sind, und auch, wie sie bei der Datenanalyse hilfreich sind.
Vidhi Chugh ist ein KI-Stratege und ein Leiter der digitalen Transformation, der an der Schnittstelle von Produkt, Wissenschaft und Technik arbeitet, um skalierbare Systeme für maschinelles Lernen zu entwickeln. Sie ist eine preisgekrönte Innovationsführerin, Autorin und internationale Rednerin. Sie hat es sich zur Aufgabe gemacht, maschinelles Lernen zu demokratisieren und den Jargon zu brechen, damit jeder Teil dieser Transformation sein kann.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- Fähigkeit
- Fähig
- Erreichen
- erreicht
- Zusätzliche
- zusätzlich
- Anhäufung
- AI
- Alle
- erlaubt
- Analyse
- analysieren
- und
- Ein anderer
- angewandt
- Bewerben
- Anwendung
- angemessen
- künstlich
- künstliche Intelligenz
- Autor
- verfügbar
- durchschnittlich
- preisgekrönte
- basierend
- basic
- unten
- Biotechnologie
- Break
- bauen
- Berechnen
- Aufruf
- Häuser
- aus der Ferne überprüfen
- klar
- Code
- Kolonne
- Spalten
- wie die
- Komplex
- Computer
- Informationstechnik
- erstellen
- Erstellen
- Original
- technische Daten
- Datenanalyse
- Datensätze
- demokratisieren
- Synergie
- Abweichung
- anders
- digital
- Digitale Transformation
- Direkt
- Nicht
- jeder
- leicht
- effektiv
- Elektrotechnik
- elektronisch
- Entwicklung
- etc
- jedermann
- Beispiel
- Beispiele
- Extrakt
- Fallen
- Eigenschaften
- füllen
- Filter
- Finden Sie
- Vorname
- Setzen Sie mit Achtsamkeit
- Folgende
- FRAME
- für
- Funktion
- Funktionen
- erzeugen
- bekommen
- gegeben
- gibt
- gehen
- Gruppe an
- Gruppen
- praktische
- Hilfe
- ein Geschenk
- Ultraschall
- Hilfe
- HTML
- HTTPS
- importieren
- in
- unglaublich
- Index
- Innovation
- Einblicke
- Instanz
- beantragen müssen
- Intelligenz
- International
- Überschneidung
- IT
- Jargon
- KDnuggets
- Wesentliche
- grosse
- Führer
- LERNEN
- lernen
- Bibliotheken
- Bibliothek
- Liste
- SIEHT AUS
- Maschine
- Maschinelles Lernen
- Dur
- um
- Manipulation
- viele
- Spiel
- max
- mechanisch
- Maschinenbau
- mittlere
- Methode
- Ziel
- Modulen
- mehr
- mehrere
- Name
- Namen
- Need
- weiter
- Anzahl
- EINEM
- Open-Source-
- Einkauf & Prozesse
- Optionen
- Andere
- Pandas
- Parameter
- Teil
- besondere
- Bestehen
- ausführen
- Länder/Regionen
- Plato
- Datenintelligenz von Plato
- PlatoData
- größte treibende
- Produkt
- bietet
- Zweck
- Python
- schnell
- zufällig
- empfohlen
- Aufzeichnungen
- regulär
- verbleibenden
- representiert
- erfordert
- REST
- Folge
- Die Ergebnisse
- Rückkehr
- Rückgabe
- Daniel
- rund
- Laufen
- gleich
- skalierbaren
- WISSENSCHAFTEN
- kompensieren
- sollte
- gezeigt
- ähnlich
- Single
- Größe
- einige
- Speaker
- spezifisch
- Standard
- Statistiken
- Schritt
- Stratege
- Schüler und Studenten
- Die Kursteilnehmer
- Fach
- Schlägt vor
- zusammenfassen
- Systeme und Techniken
- Aufgabe
- und Aufgaben
- erzählt
- AGB
- Das
- Tip
- zu
- Werkzeug
- Transformieren
- Transformation
- Transformationen
- Lernprogramm
- Typen
- Verständnis
- einzigartiges
- -
- Werte
- verschiedene
- Wege
- Was
- welche
- werden wir
- arbeiten,
- würde
- X
- Jahr
- Ihr
- Zephyrnet
- Null







