Wir haben kürzlich festgestellt, dass wir Ihnen seit einiger Zeit keine Data Science-Cheatsheets mehr gebracht haben. Und es ist nicht für ihre mangelnde Verfügbarkeit; Es gibt überall Data-Science-Cheatsheets, die von der Einführung bis zur Fortgeschrittenen reichen und Themen von Algorithmen über Statistiken bis hin zu Interviewtipps und mehr abdecken.
Aber was macht ein gutes Cheatsheet aus? Was macht ein Cheatsheet würdig, als besonders gut ausgezeichnet zu werden? Es ist schwierig, den Finger darauf zu legen genau Was ein gutes Cheatsheet ausmacht, aber offensichtlich eines, das wesentliche Informationen präzise vermittelt - ob diese Informationen allgemeiner Natur sind -, ist definitiv ein guter Anfang. Und das macht unsere Kandidaten heute bemerkenswert. Lesen Sie also vier kuratierte, ergänzende Cheatsheets, um Sie beim Lernen oder Überprüfen von Data Science zu unterstützen.
An erster Stelle steht Aaron Wangs Data Science Cheatsheet 2.0, eine vierseitige Zusammenstellung statistischer Abstraktionen, grundlegender Algorithmen für maschinelles Lernen sowie Themen und Konzepte für tiefes Lernen. Es soll nicht erschöpfend sein, sondern eine Kurzreferenz für Situationen wie die Vorbereitung von Interviews und Prüfungsprüfungen sowie für alles andere, was eine ähnliche Überprüfungstiefe erfordert. Der Autor merkt an, dass diejenigen mit einem grundlegenden Verständnis von Statistik und linearer Algebra diese Ressource am nützlichsten finden würden, Anfänger jedoch in der Lage sein sollten, nützliche Informationen aus ihrem Inhalt zu gewinnen.

Screenshot von Aaron Wang Data Science-Spickzettel 2.0
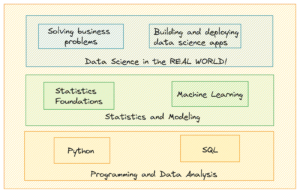
Unser nächstes heutiges Cheatsheet-Angebot ist das, auf dem Aaron Wangs Ressource basiert. Maverick Lins Data Science Cheatsheet (Wangs Hinweis auf sein eigenes als 2.0 ist eine direkte Anspielung auf Lins „Original“). Wir können uns Lins Spickzettel als ausführlicher als Wangs vorstellen (obwohl Wangs Entscheidung, ihn weniger ausführlich zu machen, beabsichtigt und eine nützliche Alternative zu sein scheint), der grundlegendere datenwissenschaftliche Konzepte wie Datenbereinigung, die Idee des Modellierens und das Tun von Big Data “mit Hadoop, SQL und sogar den Grundlagen von Python.
Dies wird eindeutig diejenigen ansprechen, die fester im „Anfänger“ -Lager sind, und es macht einen guten Job, Appetit zu machen und die Leser auf das breite Feld der Datenwissenschaft und viele der unterschiedlichen Konzepte aufmerksam zu machen, die es umfasst. Dies ist definitiv eine weitere solide Ressource, insbesondere wenn der Leser ein Neuling in der Datenwissenschaft ist.

Screenshot von Maverick Lin Data Science-Spickzettel
Wenn wir uns weiter in der Zeit zurückbewegen und nach der Inspiration für Lins Spickzettel suchen, stoßen wir auf etwas William Chens Wahrscheinlichkeits-Spickzettel 2.0. Chens Spickzettel hat im Laufe der Jahre viel Aufmerksamkeit und Lob erhalten, und so sind Sie vielleicht irgendwann darauf gestoßen. Chens Cheatsheet ist eindeutig ein Crashkurs oder eine eingehende Überprüfung von Wahrscheinlichkeitskonzepten, einschließlich einer Vielzahl von Verteilungen, Kovarianzen und Transformationen, bedingten Erwartungen, Markov-Ketten, verschiedenen wichtigen Formeln und viel mehr.
Auf 10 Seiten sollten Sie sich vorstellen können, wie breit die hier behandelten Wahrscheinlichkeitsthemen sind. Aber lassen Sie sich davon nicht abhalten. Bemerkenswert ist Chens Fähigkeit, Konzepte auf das Wesentliche zu reduzieren und im Klartext zu erklären, ohne auf das Wesentliche zu verzichten. Es ist auch reich an erklärenden Visualisierungen, was sehr nützlich ist, wenn der Platz begrenzt ist und der Wunsch, präzise zu sein, stark ist.
Chens Zusammenstellung ist nicht nur eine Qualität, die Ihrer Zeit würdig ist, als Anfänger oder als jemand, der an einer vollständigen Überprüfung interessiert ist, ich würde auch in umgekehrter Reihenfolge arbeiten, wie diese Ressourcen präsentiert wurden - von Chens Spickzettel über Lins bis hin zu Wangs. Bauen Sie auf Konzepte auf, während Sie gehen.
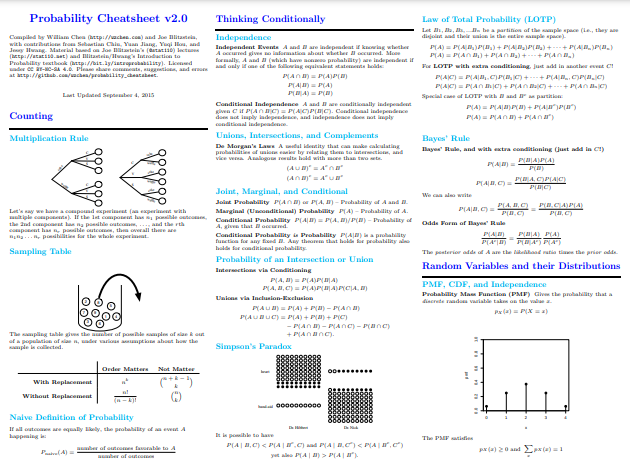
Screenshot von William Chen Wahrscheinlichkeits-Spickzettel 2.0
Eine letzte Ressource, die ich hier einbinde, obwohl technisch gesehen kein Spickzettel, ist Rishabh Anands maschinelles Lernen beißt. Anand hat sich selbst als „[a] n Interview-Leitfaden zu gängigen Konzepten, Best Practices, Definitionen und Theorien des maschinellen Lernens“ bezeichnet und eine umfassende Sammlung von Wissensbissen zusammengestellt, deren Nützlichkeit definitiv über die ursprünglich beabsichtigte Interviewvorbereitung hinausgeht. Zu den behandelten Themen gehören:
- Modellbewertungsmetriken
- Parameterfreigabe
- k-fache Kreuzvalidierung
- Python-Datentypen
- Verbesserung der Modellleistung
- Computer Vision Modelle
- Aufmerksamkeit und ihre Varianten
- Umgang mit Klassenungleichgewicht
- Computer Vision Glossar
- Vanille Backpropagation
- Regulierung
- Bibliographie

Screenshot von Maschinelles Lernen beißt
Während maschinelles Lernen „Konzepte, Best Practices, Definitionen und Theorie“ angesprochen wird, wie in der Beschreibung der Ressource selbst versprochen, sind diese „Bisse“ definitiv auf das Praktische ausgerichtet, wodurch die Website einen Großteil des behandelten Materials ergänzt die drei zuvor erwähnten Cheatsheets. Wenn ich versuchen würde, das gesamte Material in allen vier Ressourcen dieses Beitrags zu behandeln, würde ich mir dies sicherlich nach den anderen drei ansehen.
Dort haben Sie also vier Cheatsheets (oder drei Cheatsheets und eine an Cheatsheets angrenzende Ressource), die Sie für Ihr Lernen oder Ihre Überprüfung verwenden können. Hoffentlich ist hier etwas für Sie nützlich, und ich lade jeden ein, die Cheatsheets zu teilen, die er in den Kommentaren unten als nützlich empfunden hat.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Heinz
- Fähigkeit
- Fähig
- über
- advanced
- Nach der
- Algorithmen
- Alle
- Alternative
- und
- Ein anderer
- jemand
- appellieren
- Aufmerksamkeit
- Autor
- Verfügbarkeit
- Zurück
- basierend
- basic
- Grundlagen
- Anfänger
- Sein
- unten
- Nutzen
- BESTE
- Best Practices
- Beyond
- Big
- Big Data
- Rechnungs-
- Breite
- breit
- gebracht
- Building
- Das Mrčajevci-Freizeitzentrum
- Kandidaten
- sicherlich
- Ketten
- chen
- Klasse
- Reinigung
- Sammlung
- wie die
- Bemerkungen
- gemeinsam
- komplementär
- Konzepte
- Inhalt
- Kurs
- Abdeckung
- bedeckt
- Abdeckung
- Crash
- Cross
- kuratiert
- technische Daten
- Datenwissenschaft
- Entscheidung
- tief
- Tieftauchgang
- tiefe Lernen
- definitiv
- Tiefe
- Beschreibung
- anders
- schwer
- Direkt
- Ausschüttungen
- Dabei
- nach unten
- umfasst
- Englisch
- insbesondere
- essential
- Wesentliche
- Äther (ETH)
- Sogar
- Prüfung
- Erwartung
- Erklären
- Feld
- Abbildung
- Finale
- Endlich
- Finden Sie
- fest
- Setzen Sie mit Achtsamkeit
- gefunden
- für
- voller
- fundamental
- weiter
- ausgerichtet
- Allgemeines
- gegeben
- Go
- gut
- gute Arbeit
- Guide
- hier
- Hoffentlich
- Ultraschall
- HTTPS
- Idee
- Unausgewogenheit
- Bedeutung
- in
- eingehende
- das
- Einschließlich
- Information
- Inspiration
- beantragen müssen
- Vorsätzlich
- interessiert
- Interview
- einleitend
- einladen
- IT
- selbst
- Job
- Wissen
- Mangel
- lernen
- Niveau
- Limitiert
- aussehen
- suchen
- Maschine
- Maschinelles Lernen
- um
- MACHT
- Making
- viele
- Ihres Materials
- Einzelgänger
- erwähnt
- Metrik
- Modell
- für
- mehr
- vor allem warme
- schlauer bewegen
- Name
- Natur
- weiter
- Notizen
- bemerkenswert
- Notion
- bieten
- EINEM
- Auftrag
- Original
- ursprünglich
- Andere
- besitzen
- besonders
- Leistung
- Ebene
- Plato
- Datenintelligenz von Plato
- PlatoData
- Points
- Punkte
- Post
- Praktisch
- Praktiken
- vorgeführt
- vorher
- versprochen
- setzen
- Python
- Qualität
- Direkt
- Bereich
- Lesen Sie mehr
- Leser
- Leser
- realisiert
- kürzlich
- Ressourcen
- Downloads
- rückgängig machen
- Überprüfen
- Bewertungen
- Reiches
- opfern
- Wissenschaft
- Wertung
- auf der Suche nach
- scheint
- Teilen
- ,,teilen"
- sollte
- ähnlich
- am Standort
- Umstände
- So
- solide
- einige
- Jemand,
- etwas
- Raumfahrt
- spezifisch
- Anfang
- statistisch
- Statistiken
- stark
- so
- Das
- Die Grundlagen
- ihr
- nach drei
- Zeit
- Tipps
- zu
- heute
- Top
- Themen
- gegenüber
- Transformationen
- Typen
- Verständnis
- -
- Bestätigung
- Vielfalt
- verschiedene
- Seh-
- Was
- ob
- welche
- während
- WHO
- breit
- werden wir
- .
- Arbeiten
- würde
- Jahr
- Ihr
- Zephyrnet