Bild von Frimufilme on Freepik
Dies ist eine Ära, in der der KI-Durchbruch täglich kommt. Vor ein paar Jahren hatten wir nicht viele KI-generierte Produkte in der Öffentlichkeit, aber jetzt ist die Technologie für jedermann zugänglich. Es eignet sich hervorragend für viele einzelne Entwickler oder Unternehmen, die die Technologie erheblich nutzen möchten, um etwas Komplexes zu entwickeln, was lange dauern kann.
Einer der unglaublichsten Durchbrüche, die unsere Arbeitsweise verändern, ist die Veröffentlichung des GPT-3.5-Modell von OpenAI. Was ist das GPT-3.5-Modell? Wenn ich das Model für sich sprechen lasse. In diesem Fall lautet die Antwort „Ein hochentwickeltes KI-Modell im Bereich der Verarbeitung natürlicher Sprache mit enormen Verbesserungen bei der Generierung von kontextgenauem und relevantem Textt ”.
OpenAI stellt eine API für das GPT-3.5-Modell bereit, mit der wir eine einfache App entwickeln können, z. B. eine Textzusammenfassung. Dazu können wir Python verwenden, um die Modell-API nahtlos in unsere beabsichtigte Anwendung zu integrieren. Wie sieht der Ablauf aus? Lassen Sie uns darauf eingehen.
Es gibt einige Voraussetzungen, bevor Sie diesem Tutorial folgen, einschließlich:
– Kenntnisse in Python, einschließlich Kenntnisse in der Verwendung externer Bibliotheken und IDE
– Verständnis von APIs und Umgang mit dem Endpunkt mit Python
– Zugriff auf die OpenAI-APIs haben
Um Zugriff auf die OpenAI-APIs zu erhalten, müssen wir uns bei der registrieren OpenAI-Entwicklerplattform und besuchen Sie die API-Schlüssel anzeigen in Ihrem Profil. Klicken Sie im Internet auf die Schaltfläche „Neuen geheimen Schlüssel erstellen“, um API-Zugriff zu erhalten (siehe Abbildung unten). Denken Sie daran, die Schlüssel zu speichern, da ihnen die Schlüssel danach nicht mehr angezeigt werden.

Bild vom Autor
Nachdem alle Vorbereitungen abgeschlossen sind, versuchen wir, die Grundlagen des OpenAI-APIs-Modells zu verstehen.
Das Modell der GPT-3.5-Familie wurde für viele Sprachaufgaben spezifiziert, und jedes Modell in der Familie zeichnet sich durch einige Aufgaben aus. Für dieses Tutorial-Beispiel würden wir die verwenden gpt-3.5-turbo da es aufgrund seiner Leistungsfähigkeit und Kosteneffizienz das empfohlene aktuelle Modell war, als dieser Artikel geschrieben wurde.
Wir verwenden oft die text-davinci-003 im OpenAI-Tutorial, aber wir würden das aktuelle Modell für dieses Tutorial verwenden. Wir würden uns auf die verlassen Chat-Abschluss endpoint anstelle von Completion, da das aktuell empfohlene Modell ein Chat-Modell ist. Auch wenn der Name ein Chat-Modell war, funktioniert er für jede Sprachaufgabe.
Versuchen wir zu verstehen, wie die API funktioniert. Zuerst müssen wir die aktuellen OpenAI-Pakete installieren.
pip install openai
Nachdem wir die Installation des Pakets abgeschlossen haben, versuchen wir, die API zu verwenden, indem wir eine Verbindung über den ChatCompletion-Endpunkt herstellen. Wir müssen jedoch die Umgebung festlegen, bevor wir fortfahren.
Erstellen Sie in Ihrer bevorzugten IDE (für mich ist es VS Code) zwei Dateien mit dem Namen .env und summarizer_app.py, ähnlich dem Bild unten.
Bild vom Autor
Das summarizer_app.py Hier würden wir unsere einfache Zusammenfassungsanwendung erstellen, und die .env Datei ist, wo wir unseren API-Schlüssel speichern würden. Aus Sicherheitsgründen wird immer empfohlen, unseren API-Schlüssel in einer anderen Datei zu trennen, anstatt sie in der Python-Datei fest zu codieren.
Im .env file geben Sie die folgende Syntax ein und speichern Sie die Datei. Ersetzen Sie your_api_key_here durch Ihren tatsächlichen API-Schlüssel. Ändern Sie den API-Schlüssel nicht in ein Zeichenfolgenobjekt; lass sie so wie sie ist.
OPENAI_API_KEY=your_api_key_here
Um die GPT-3.5-API besser zu verstehen; Wir würden den folgenden Code verwenden, um den Wortzusammenfasser zu generieren.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
Der obige Code zeigt, wie wir mit dem GPT-3.5-Modell der OpenAI-APIs interagieren. Mit der ChatCompletion-API erstellen wir eine Konversation und erhalten das beabsichtigte Ergebnis, nachdem wir die Eingabeaufforderung bestanden haben.
Lassen Sie uns jeden Teil aufschlüsseln, um sie besser zu verstehen. In der ersten Zeile verwenden wir die openai.ChatCompletion.create Code zum Erstellen der Antwort aus der Eingabeaufforderung, die wir an die API übergeben würden.
In der nächsten Zeile haben wir unsere Hyperparameter, die wir verwenden, um unsere Textaufgaben zu verbessern. Hier ist die Zusammenfassung jeder Hyperparameterfunktion:
model: Die Modellfamilie, die wir verwenden möchten. In diesem Tutorial verwenden wir das aktuell empfohlene Modell (gpt-3.5-turbo).max_tokens: Die Obergrenze der vom Modell generierten Wörter. Es hilft, die Länge des generierten Textes zu begrenzen.temperature: Die Zufälligkeit der Modellausgabe mit einer höheren Temperatur bedeutet ein vielfältigeres und kreativeres Ergebnis. Der Wertebereich liegt zwischen 0 und unendlich, obwohl Werte über 2 nicht üblich sind.top_p: Top-P- oder Top-k-Sampling oder Nucleus-Sampling ist ein Parameter zur Steuerung des Sampling-Pools aus der Ausgabeverteilung. Der Wert 0.1 bedeutet beispielsweise, dass das Modell nur die Ausgabe der obersten 10 % der Verteilung abtastet. Der Wertebereich lag zwischen 0 und 1; höhere Werte bedeuten ein vielfältigeres Ergebnis.frequency_penalty: Die Strafe für das Wiederholungstoken aus der Ausgabe. Der Wertebereich liegt zwischen -2 und 2, wobei positive Werte das Modell daran hindern würden, Token zu wiederholen, während negative Werte das Modell dazu anregen, sich wiederholende Wörter zu verwenden. 0 bedeutet keine Strafe.messages: Der Parameter, an den wir unsere Texteingabeaufforderung übergeben, die mit dem Modell verarbeitet werden soll. Wir übergeben eine Liste von Wörterbüchern, in denen der Schlüssel das Rollenobjekt ist (entweder „System“, „Benutzer“ oder „Assistent“), das dem Modell hilft, den Kontext und die Struktur zu verstehen, während die Werte der Kontext sind.- Die Rolle „System“ ist die festgelegten Richtlinien für das Verhalten des Modells „Assistent“,
- Die Rolle „Benutzer“ stellt die Aufforderung der Person dar, die mit dem Modell interagiert,
- Die Rolle „Assistent“ ist die Antwort auf die Eingabeaufforderung „Benutzer“.
Nachdem wir den obigen Parameter erklärt haben, können wir sehen, dass die messages Der obige Parameter hat zwei Dictionary-Objekte. Das erste Wörterbuch ist, wie wir das Modell als Textzusammenfassung festlegen. Im zweiten würden wir unseren Text übergeben und die Zusammenfassungsausgabe erhalten.
Im zweiten Wörterbuch sehen Sie auch die Variable person_type und promptdem „Vermischten Geschmack“. Seine person_type ist eine Variable, die ich verwendet habe, um den zusammengefassten Stil zu steuern, den ich im Tutorial zeigen werde. Während prompt Hier würden wir unseren zusammenzufassenden Text übergeben.
Fahren Sie mit dem Tutorial fort und platzieren Sie den folgenden Code in der summarizer_app.py Datei und wir werden versuchen, durchzuspielen, wie die Funktion unten funktioniert.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
Im obigen Code erstellen wir eine Python-Funktion, die verschiedene zuvor besprochene Parameter akzeptiert und die Textzusammenfassungsausgabe zurückgibt.
Probieren Sie die obige Funktion mit Ihrem Parameter aus und sehen Sie sich die Ausgabe an. Lassen Sie uns dann mit dem Tutorial fortfahren, um eine einfache Anwendung mit dem Streamlit-Paket zu erstellen.
Stromlit ist ein Open-Source-Python-Paket, das zum Erstellen von Web-Apps für maschinelles Lernen und Data Science entwickelt wurde. Es ist einfach zu bedienen und intuitiv, daher wird es vielen Anfängern empfohlen.
Lassen Sie uns das Streamlit-Paket installieren, bevor wir mit dem Tutorial fortfahren.
pip install streamlit
Nachdem die Installation abgeschlossen ist, fügen Sie den folgenden Code in die summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
Versuchen Sie, den folgenden Code in Ihrer Eingabeaufforderung auszuführen, um die Anwendung zu starten.
streamlit run summarizer_app.py
Wenn alles gut funktioniert, sehen Sie die folgende Anwendung in Ihrem Standardbrowser.
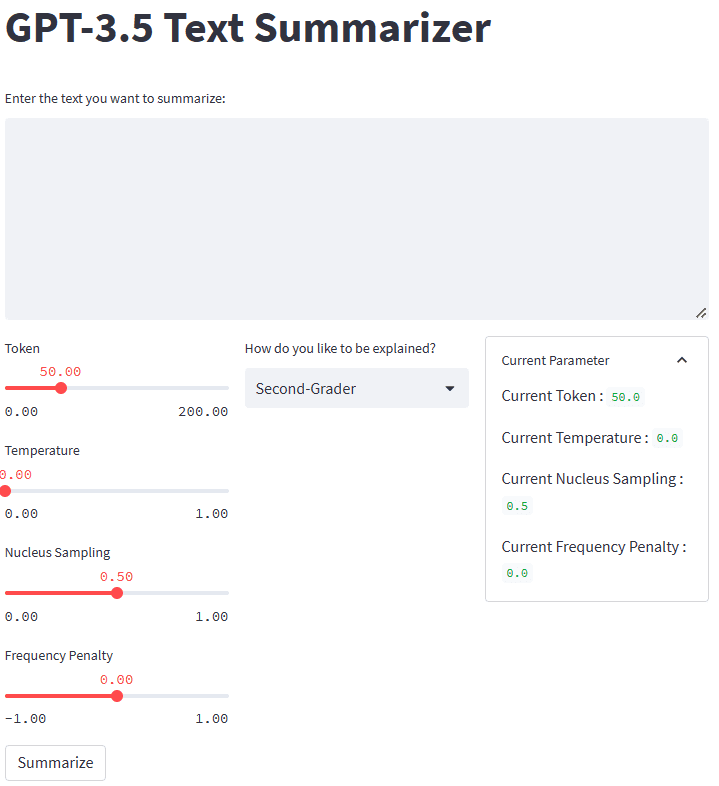
Bild vom Autor
Also, was ist im obigen Code passiert? Lassen Sie mich kurz jede Funktion erklären, die wir verwendet haben:
.st.title: Geben Sie den Titeltext der Webanwendung an..st.write: Schreibt das Argument in die Anwendung; es könnte alles sein, aber hauptsächlich ein Zeichenfolgentext..st.text_area: Stellen Sie einen Bereich für die Texteingabe bereit, der in der Variablen gespeichert und für die Eingabeaufforderung für unseren Textzusammenfasser verwendet werden kann.st.columns: Objektcontainer, um eine Interaktion nebeneinander bereitzustellen..st.slider: Stellen Sie ein Schieberegler-Widget mit festgelegten Werten bereit, mit denen der Benutzer interagieren kann. Der Wert wird in einer Variablen gespeichert, die als Modellparameter verwendet wird..st.selectbox: Stellen Sie ein Auswahl-Widget bereit, mit dem Benutzer den gewünschten Zusammenfassungsstil auswählen können. Im obigen Beispiel verwenden wir fünf verschiedene Stile..st.expander: Stellen Sie einen Container bereit, den Benutzer erweitern und mehrere Objekte aufnehmen können..st.button: Stellen Sie eine Schaltfläche bereit, die die beabsichtigte Funktion ausführt, wenn der Benutzer sie drückt.
Da streamlit die Benutzeroberfläche automatisch nach dem vorgegebenen Code von oben nach unten gestalten würde, könnten wir uns mehr auf die Interaktion konzentrieren.
Wenn alle Teile vorhanden sind, probieren wir unsere Zusammenfassungsanwendung mit einem Textbeispiel aus. Für unser Beispiel würde ich die verwenden Wikipedia-Seite zur Relativitätstheorie zusammenzufassender Text. Mit einem Standardparameter und einem Zweitklässlerstil erhalten wir das folgende Ergebnis.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
Sie erhalten möglicherweise ein anderes Ergebnis als das obige. Probieren wir den Housewives-Stil aus und passen den Parameter ein wenig an (Token 100, Temperature 0.5, Nucleus Sampling 0.5, Frequency Penalty 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
Wie wir sehen können, gibt es für denselben Text, den wir bereitstellen, einen Unterschied im Stil. Mit einer Änderungsaufforderung und einem Parameter kann unsere Anwendung funktionaler sein.
Das Gesamtbild unserer Textzusammenfassungsanwendung ist im Bild unten zu sehen.
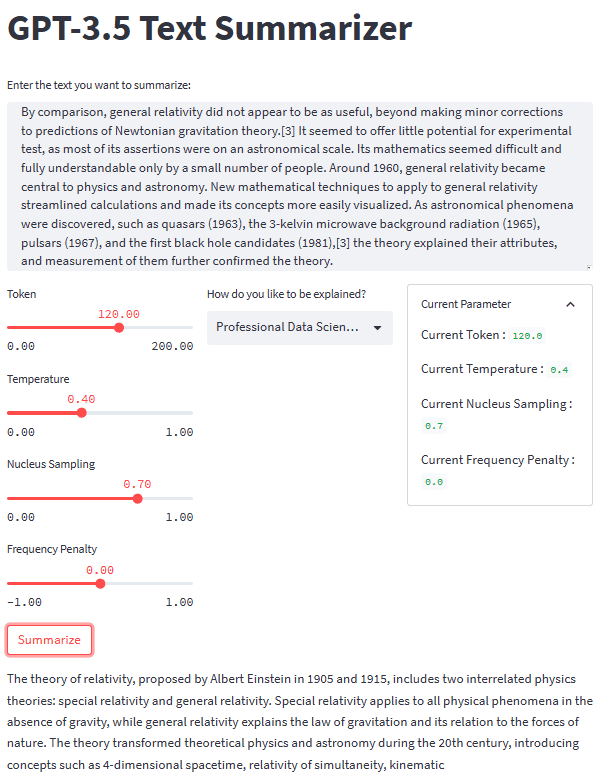
Bild vom Autor
Das ist das Tutorial zum Erstellen einer Textzusammenfassungsanwendungsentwicklung mit GPT-3.5. Sie könnten die Anwendung noch weiter optimieren und die Anwendung bereitstellen.
Generative KI ist auf dem Vormarsch, und wir sollten die Gelegenheit nutzen, indem wir eine fantastische Anwendung erstellen. In diesem Tutorial lernen wir, wie die GPT-3.5 OpenAI-APIs funktionieren und wie man sie verwendet, um mit Hilfe von Python und dem Streamlit-Paket eine Textzusammenfassungsanwendung zu erstellen.
Cornellius Yudha Wijaya ist Data Science Assistant Manager und Data Writer. Während er Vollzeit bei Allianz Indonesien arbeitet, liebt er es, Python- und Datentipps über soziale Medien zu teilen und Medien zu schreiben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :Ist
- ][P
- $UP
- 1
- 100
- 28
- 7
- a
- Über uns
- oben
- Akzeptieren
- Zugang
- zugänglich
- genau
- erwerben
- advanced
- Vorteil
- Nach der
- AI
- Alle
- Allianz
- Obwohl
- immer
- und
- Ein anderer
- beantworten
- Bienen
- API-Zugriff
- APIs
- App
- Anwendung
- Anwendungsentwicklung
- Apps
- SIND
- Bereich
- Argument
- Artikel
- AS
- Assistentin
- Astronomie
- At
- Im Prinzip so, wie Sie es von Google Maps kennen.
- basic
- BE
- weil
- Bevor
- Anfänger
- unten
- Besser
- zwischen
- Bit
- Schwarz
- Schwarze Löcher
- Boden
- Box
- Break
- Durchbruch
- Durchbrüche
- kurz
- Browser
- bauen
- Taste im nun erscheinenden Bestätigungsfenster nun wieder los.
- by
- namens
- CAN
- Häuser
- Jahrhundert
- Übernehmen
- Entscheidungen
- klicken Sie auf
- Code
- Spalten
- Kommen
- gemeinsam
- Unternehmen
- Abschluss
- Komplex
- Konzepte
- Sich zusammenschliessen
- Container
- Behälter
- Inhalt
- Kontext
- fortsetzen
- Smartgeräte App
- Gespräch
- könnte
- erstellen
- Erstellen
- Kreativ (Creative)
- Schöpfer
- Strom
- Unterricht
- technische Daten
- Datenwissenschaft
- Datenwissenschaftler
- Standard
- einsetzen
- Design
- entworfen
- entwickeln
- Entwickler:in / Unternehmen
- Entwicklung
- Unterschied
- anders
- entdeckt,
- diskutiert
- Verteilung
- verschieden
- Nicht
- nach unten
- jeder
- entweder
- ermutigen
- Endpunkt
- Enter
- Arbeitsumfeld
- Era
- Äther (ETH)
- Sogar
- jedermann
- alles
- Beispiel
- Ausgezeichnet
- ausführen
- Erweitern Sie die Funktionalität der
- Erklären
- erklärt
- Erklärt
- extern
- Familie
- fantastisch
- Favorit
- wenige
- Feld
- Reichen Sie das
- Mappen
- Vorname
- Setzen Sie mit Achtsamkeit
- Folgende
- Aussichten für
- Streitkräfte
- Frequenz
- für
- Funktion
- funktional
- weiter
- Allgemeines
- erzeugen
- erzeugt
- Erzeugung
- bekommen
- gegeben
- Schwerkraft
- Gravitationswellen
- Schwerkraft
- Richtlinien
- Handling
- passiert
- Haben
- mit
- Hilfe
- dazu beigetragen,
- hilfreich
- hilft
- hier
- höher
- hoch
- Bohrungen
- Ultraschall
- Hilfe
- Wie wir arbeiten
- aber
- HTTPS
- i
- Ideen
- Image
- importieren
- wichtig
- zu unterstützen,
- Verbesserungen
- in
- Dazu gehören
- Einschließlich
- unglaublich
- Krankengymnastik
- Indonesien
- Unendlichkeit
- initiieren
- Varianten des Eingangssignals:
- installieren
- Installieren
- beantragen müssen
- integrieren
- interagieren
- Interaktion
- Interaktion
- Einführung
- intuitiv
- IT
- SEINE
- jpg
- KDnuggets
- Wesentliche
- Tasten
- Wissen
- Sprache
- Recht
- LERNEN
- lernen
- Länge
- Bibliotheken
- Gefällt mir
- LIMIT
- Line
- Liste
- Lang
- lange Zeit
- aussehen
- aussehen wie
- Maschine
- Maschinelles Lernen
- Manager
- viele
- Mittel
- Medien
- Nachricht
- könnte
- Modell
- mehr
- vor allem warme
- schlauer bewegen
- mehrere
- Name
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Natur
- Need
- Negativ
- Neu
- weiter
- Objekt
- Objekte
- erhalten
- of
- on
- EINEM
- Open-Source-
- OpenAI
- Gelegenheit
- Option
- OS
- Andere
- Möglichkeiten für das Ausgangssignal:
- Gesamt-
- Paket
- Pakete
- Parameter
- Parameter
- Teil
- Bestehen
- person
- physikalisch
- Physik
- Stücke
- Ort
- Planets
- Plato
- Datenintelligenz von Plato
- PlatoData
- Pool
- positiv
- Vorhersage
- Voraussetzungen
- vorher
- Prozessdefinierung
- Verarbeitung
- Professionell
- Profil
- vorgeschlage
- die
- bietet
- Öffentlichkeit
- setzen
- Python
- Zufälligkeit
- Angebot
- lieber
- bereit
- Gründe
- empfohlen
- Registrieren
- Beziehung
- Release
- relevant
- merken
- repetitiv
- ersetzen
- representiert
- Antwort
- Folge
- Rückkehr
- Anstieg
- Rollen
- Führen Sie
- gleich
- Speichern
- Wissenschaft
- Wissenschaftler
- nahtlos
- Zweite
- Die Geheime
- Abschnitt
- Sicherheitdienst
- Auswahl
- getrennte
- kompensieren
- Teilen
- sollte
- erklären
- gezeigt
- bedeutend
- ähnlich
- Einfacher
- Schieber
- smart
- So
- Social Media
- Social Media
- einige
- etwas
- Raumfahrt
- besondere
- angegeben
- Sterne
- speichern
- gelagert
- Schnur
- Struktur
- Schüler und Studenten
- Stil
- Stile
- so
- zusammenfassen
- ZUSAMMENFASSUNG
- Syntax
- System
- Nehmen
- Reden
- Gespräche
- Aufgabe
- und Aufgaben
- Technologie
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- das Gesetz
- die Welt
- Sie
- sich
- theoretisch
- Diese
- nach drei
- Durch
- Zeit
- Tipps
- Titel
- zu
- Zeichen
- Top
- verwandelt
- Lernprogramm
- ui
- verstehen
- Verständnis
- Universität
- us
- -
- Mitglied
- Nutzer
- Nutzen
- Wert
- Werte
- verschiedene
- riesig
- Anzeigen
- Besuchen Sie
- vs
- gegen Code
- Wellen
- Netz
- Internetanwendung
- GUT
- Was
- Was ist
- welche
- während
- WHO
- Wikipedia
- werden wir
- mit
- .
- ohne
- Word
- Worte
- Arbeiten
- arbeiten,
- Werk
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- Schriftsteller
- Schreiben
- geschrieben
- Jahr
- Ihr
- Zephyrnet