Amazon RedShift ist ein schnelles, vollständig verwaltetes Cloud-Data-Warehouse im Petabyte-Bereich, das die einfache und kostengünstige Analyse aller Ihrer Daten mit Standard-SQL und Ihren vorhandenen Business-Intelligence-Tools (BI) ermöglicht. Zehntausende Kunden nutzen heute Amazon Redshift, um Exabytes an Daten zu analysieren und analytische Abfragen auszuführen, was es zum am weitesten verbreiteten Cloud-Data-Warehouse macht. Amazon Redshift ist sowohl in serverlosen als auch in bereitgestellten Konfigurationen verfügbar.
Mit Amazon Redshift können Sie direkt auf die in gespeicherten Daten zugreifen Amazon Simple Storage-Service (Amazon S3) mithilfe von SQL-Abfragen und verknüpfen Sie Daten in Ihrem Data Warehouse und Data Lake. Mit Amazon Redshift können Sie die Daten in Ihrem S3 Data Lake zentral abfragen AWS-Kleber Metastore aus Ihrem Redshift-Data-Warehouse.
Amazon Redshift unterstützt die Abfrage einer Vielzahl von Datenformaten wie CSV, JSON, Parquet und ORC sowie Tabellenformaten wie Apache Hudi und Delta. Amazon Redshift unterstützt auch die Abfrage verschachtelter Daten mit komplexen Datentypen wie Struktur, Array und Karte.
Mit dieser Funktion erweitert Amazon Redshift Ihr Data Warehouse im Petabyte-Bereich auf kostengünstige Weise zu einem Data Lake im Exabyte-Bereich auf Amazon S3.
Apache Iceberg ist das neueste Tabellenformat, das jetzt in der Vorschau von Amazon Redshift unterstützt wird. In diesem Beitrag zeigen wir Ihnen, wie Sie Iceberg-Tabellen mit Amazon Redshift abfragen, und erkunden die Unterstützung und Optionen von Iceberg.
Lösungsüberblick
Apache Eisberg ist ein offenes Tabellenformat für sehr große Analysedatensätze im Petabyte-Bereich. Iceberg verwaltet große Dateisammlungen als Tabellen und unterstützt moderne analytische Data-Lake-Vorgänge wie Einfügen, Aktualisieren, Löschen und Zeitreiseabfragen auf Datensatzebene. Die Iceberg-Spezifikation ermöglicht eine nahtlose Tabellenentwicklung wie Schema- und Partitionsentwicklung und ihr Design ist für die Verwendung auf Amazon S3 optimiert.
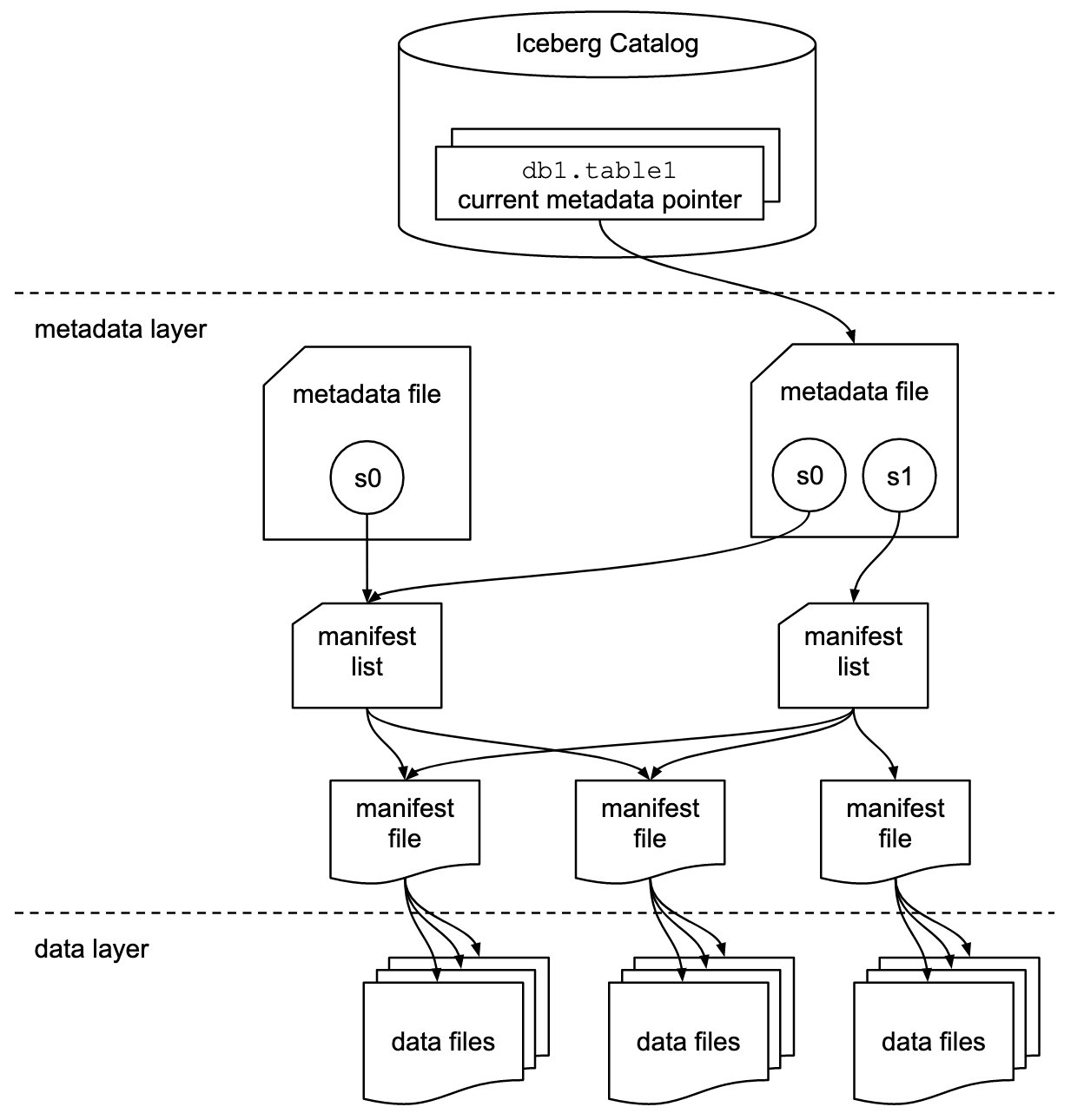
Iceberg speichert den Metadatenzeiger für alle Metadatendateien. Wenn eine SELECT-Abfrage eine Iceberg-Tabelle liest, geht die Abfrage-Engine zuerst zum Iceberg-Katalog und ruft dann den Eintrag mit dem Speicherort der neuesten Metadatendatei ab, wie im folgenden Diagramm dargestellt.
Amazon Redshift bietet jetzt Unterstützung für Apache Iceberg-Tabellen, wodurch Data-Lake-Kunden schreibgeschützte Analyseabfragen transaktionskonsistent ausführen können. Dadurch können Sie Ihre Tabellen in transaktionalen Data Lakes einfach verwalten und pflegen.
Amazon Redshift unterstützt die nativen Schema- und Partitionsentwicklungsfunktionen von Apache Iceberg mithilfe von AWS Glue-DatenkatalogDadurch entfällt die Notwendigkeit, Tabellendefinitionen zu ändern, um neue Partitionen hinzuzufügen oder große Datenmengen zu verschieben und zu verarbeiten, um das Schema einer vorhandenen Data Lake-Tabelle zu ändern. Amazon Redshift nutzt die in den Metadaten der Apache Iceberg-Tabelle gespeicherten Spaltenstatistiken, um seine Abfragepläne zu optimieren und die zum Ausführen von Abfragen erforderlichen Dateiscans zu reduzieren.
In diesem Beitrag verwenden wir die Öffentlicher Datensatz für gelbe Taxis der NYC Taxi & Limousine Commission als unsere Quelldaten. Der Datensatz enthält Datendateien in Apache-Parkett Format auf Amazon S3. Wir gebrauchen Amazonas Athena um diesen Parquet-Datensatz zu konvertieren und dann zu verwenden Amazon Redshift-Spektrum zum Abfragen und Verknüpfen mit einer lokalen Redshift-Tabelle, zum Durchführen von Löschungen und Aktualisierungen auf Zeilenebene sowie zur Partitionsentwicklung, alles koordiniert über den AWS Glue Data Catalog in einem S3-Datensee.
Voraussetzungen:
Folgende Voraussetzungen sollten Sie mitbringen:
Konvertieren Sie Parquet-Daten in eine Iceberg-Tabelle
Für diesen Beitrag benötigen Sie die Öffentlicher Datensatz für gelbe Taxis der NYC Taxi & Limousine Commission erhältlich im Iceberg-Format. Sie können die Dateien herunterladen und dann mit Athena den Parquet-Datensatz in eine Iceberg-Tabelle konvertieren oder darauf zugreifen Erstellen Sie einen Apache Iceberg Data Lake mit Amazon Athena, Amazon EMR und AWS Glue Blogbeitrag zum Erstellen der Iceberg-Tabelle.
In diesem Beitrag verwenden wir Athena, um die Daten zu konvertieren. Führen Sie die folgenden Schritte aus:
- Laden Sie die Dateien über den vorherigen Link herunter oder verwenden Sie die AWS-Befehlszeilenschnittstelle (AWS CLI), um die Dateien aus dem öffentlichen S3-Bucket für die Jahre 2020 und 2021 in Ihren S3-Bucket zu kopieren, indem Sie den folgenden Befehl verwenden:
Weitere Informationen finden Sie unter Einrichten der Amazon Redshift CLI.
- Erstellen Sie eine Datenbank
Icebergdbund erstellen Sie mit Athena eine Tabelle, die auf die Dateien im Parquet-Format verweist, indem Sie die folgende Anweisung verwenden: - Validieren Sie die Daten in der Parquet-Tabelle mit dem folgenden SQL:

- Erstellen Sie mit dem folgenden Code eine Iceberg-Tabelle in Athena. Im Folgenden können Sie die Eigenschaften des Tabellentyps als Iceberg-Tabelle mit Parquet-Format und schneller Komprimierung sehen
create tableStellungnahme. Sie müssen den S3-Speicherort aktualisieren, bevor Sie SQL ausführen. Beachten Sie auch, dass die Iceberg-Tabelle mit partitioniert istYearKey. - Nachdem Sie die Tabelle erstellt haben, laden Sie die Daten mithilfe der zuvor geladenen Parquet-Tabelle in die Iceberg-Tabelle
nyc_taxi_yellow_parquetmit folgendem SQL: - Wenn die SQL-Anweisung abgeschlossen ist, validieren Sie die Daten in der Iceberg-Tabelle
nyc_taxi_yellow_iceberg. Dieser Schritt ist erforderlich, bevor mit dem nächsten Schritt fortgefahren werden kann. - Mit dem folgenden Befehl können Sie überprüfen, ob die Tabelle „nyc_taxi_yellow_iceberg“ im Iceberg-Format vorliegt und in der Spalte „Jahr“ partitioniert ist:



Erstellen Sie ein externes Schema in Amazon Redshift
In diesem Abschnitt zeigen wir, wie Sie in Amazon Redshift ein externes Schema erstellen, das auf die AWS Glue-Datenbank verweist icebergdb um die Iceberg-Tabelle abzufragen nyc_taxi_yellow_iceberg das haben wir im vorherigen Abschnitt mit Athena gesehen.
Melden Sie sich bei Redshift an über Abfrage-Editor v2 oder einen SQL-Client und führen Sie den folgenden Befehl aus (beachten Sie, dass die AWS Glue-Datenbank icebergdb und Regionsinformationen werden verwendet):

Weitere Informationen zum Erstellen externer Schemata in Amazon Redshift finden Sie unter Erstellen Sie ein externes Schema
Nachdem Sie das externe Schema erstellt haben spectrum_iceberg_schemakönnen Sie die Iceberg-Tabelle in Amazon Redshift abfragen.
Fragen Sie die Iceberg-Tabelle in Amazon Redshift ab
Führen Sie die folgende Abfrage im Abfrageeditor v2 aus. Beachten Sie, dass spectrum_iceberg_schema ist der Name des in Amazon Redshift erstellten externen Schemas und nyc_taxi_yellow_iceberg ist die Tabelle in der AWS Glue-Datenbank, die in der Abfrage verwendet wird:
Die Abfragedatenausgabe im folgenden Screenshot zeigt, dass die AWS Glue-Tabelle im Iceberg-Format mit Redshift Spectrum abfragbar ist.

Überprüfen Sie den Erklärungsplan zum Abfragen der Iceberg-Tabelle
Sie können die folgende Abfrage verwenden, um die EXPLAIN-Plan-Ausgabe abzurufen, die das Format zeigt ICEBERG:

Validieren Sie Aktualisierungen auf Datenkonsistenz
Nachdem die Aktualisierung der Iceberg-Tabelle abgeschlossen ist, können Sie Amazon Redshift abfragen, um die transaktionskonsistente Ansicht der Daten anzuzeigen. Lassen Sie uns eine Abfrage ausführen, indem wir a auswählen vendorid und für eine bestimmte Abholung und Rückgabe:

Aktualisieren Sie als Nächstes den Wert von passenger_count zu 4 und trip_distance bis 9.4 für a vendorid und bestimmte Abhol- und Rückgabetermine in Athena:

Führen Sie abschließend die folgende Abfrage im Abfrageeditor v2 aus, um den aktualisierten Wert von anzuzeigen passenger_count und trip_distance:
Wie im folgenden Screenshot gezeigt, sind die Aktualisierungsvorgänge für die Iceberg-Tabelle in Amazon Redshift verfügbar.

Erstellen Sie eine einheitliche Ansicht der lokalen Tabelle und der historischen Daten in Amazon Redshift
Als moderne Datenarchitekturstrategie können Sie historische Daten oder weniger häufig aufgerufene Daten im Data Lake organisieren und häufig aufgerufene Daten im Redshift Data Warehouse aufbewahren. Dies bietet die Flexibilität, Analysen im großen Maßstab zu verwalten und die kostengünstigste Architekturlösung zu finden.
In diesem Beispiel laden wir Daten aus zwei Jahren in eine Redshift-Tabelle. Der Rest der Daten verbleibt im S2 Data Lake, da dieser Datensatz seltener abgefragt wird.
- Verwenden Sie den folgenden Code, um Daten aus zwei Jahren in die zu laden
nyc_taxi_yellow_recentTabelle in Amazon Redshift, Bezug aus der Iceberg-Tabelle:
- Als Nächstes können Sie die Daten der letzten 2 Jahre mit dem folgenden Befehl in Athena aus der Iceberg-Tabelle entfernen, da Sie die Daten im vorherigen Schritt in eine Redshift-Tabelle geladen haben:

Nachdem Sie diese Schritte ausgeführt haben, verfügt die Redshift-Tabelle über Daten aus zwei Jahren und der Rest der Daten befindet sich in der Iceberg-Tabelle in Amazon S2.
- Erstellen Sie eine Ansicht mit
nyc_taxi_yellow_icebergEisbergtisch undnyc_taxi_yellow_recentTabelle in Amazon Redshift: - Fragen Sie nun die Ansicht ab. Abhängig von den Filterbedingungen scannt Redshift Spectrum entweder die Iceberg-Daten, die Redshift-Tabelle oder beides. Die folgende Beispielabfrage gibt eine Reihe von Datensätzen aus jeder der Quelltabellen zurück, indem beide Tabellen gescannt werden:

Partitionsentwicklung
Iceberg verwendet versteckte Partitionierung, was bedeutet, dass Sie Partitionen für Ihre Apache Iceberg-Tabellen nicht manuell hinzufügen müssen. Neue Partitionswerte oder neue Partitionsspezifikationen (Partitionsspalten hinzufügen oder entfernen) in Apache Iceberg-Tabellen werden von Amazon Redshift automatisch erkannt und es ist kein manueller Vorgang erforderlich, um Partitionen in der Tabellendefinition zu aktualisieren. Das folgende Beispiel zeigt dies.
In unserem Beispiel die Iceberg-Tabelle nyc_taxi_yellow_iceberg war ursprünglich nach Jahr und später nach Spalte unterteilt vendorid als zusätzliche Partitionsspalte hinzugefügt wurde, kann Amazon Redshift die Iceberg-Tabelle nahtlos abfragen nyc_taxi_yellow_iceberg mit zwei verschiedenen Partitionsschemata über einen bestimmten Zeitraum.

Überlegungen beim Abfragen von Iceberg-Tabellen mit Amazon Redshift
Berücksichtigen Sie während des Vorschauzeitraums Folgendes, wenn Sie Amazon Redshift mit Iceberg-Tabellen verwenden:
- Es werden nur im AWS Glue Data Catalog definierte Iceberg-Tabellen unterstützt.
- Externe Tabellenbefehle CREATE oder ALTER werden nicht unterstützt, was bedeutet, dass die Iceberg-Tabelle bereits in einer AWS Glue-Datenbank vorhanden sein sollte.
- Zeitreiseabfragen werden nicht unterstützt.
- Iceberg-Versionen 1 und 2 werden unterstützt. Weitere Einzelheiten zu den Versionen im Iceberg-Format finden Sie unter Versionierung formatieren.
- Eine Liste der unterstützten Datentypen mit Iceberg-Tabellen finden Sie unter Unterstützte Datentypen mit Apache Iceberg-Tabellen (Vorschau).
- Die Preise für die Abfrage einer Iceberg-Tabelle sind die gleichen wie für den Zugriff auf andere Datenformate mit Amazon Redshift.
Weitere Einzelheiten zu Überlegungen zur Tabellenvorschau im Iceberg-Format finden Sie unter Verwendung von Apache Iceberg-Tabellen mit Amazon Redshift (Vorschau).
Kunden-Feedback
„Tinuiti, das größte unabhängige Performance-Marketing-Unternehmen, verarbeitet täglich große Datenmengen und muss über eine robuste Data-Lake- und Data-Warehouse-Strategie verfügen, damit unsere Market-Intelligence-Teams alle unsere Kundendaten einfach, erschwinglich und sicher speichern und analysieren können.“ , und robust“, sagt Justin Manus, Chief Technology Officer bei Tinuiti. „Die Unterstützung von Amazon Redshift für Apache Iceberg-Tabellen in unserem Data Lake, der die einzige Quelle der Wahrheit darstellt, bewältigt eine entscheidende Herausforderung bei der Optimierung von Leistung und Zugänglichkeit und vereinfacht unsere Datenintegrationspipelines weiter, um auf alle aus verschiedenen Quellen erfassten Daten zuzugreifen und unsere Daten mit Strom zu versorgen das Markenpotenzial der Kunden.“
Zusammenfassung
In diesem Beitrag haben wir Ihnen ein Beispiel für die Abfrage einer Iceberg-Tabelle in Redshift unter Verwendung von in Amazon S3 gespeicherten und als Tabelle im AWS Glue Data Catalog katalogisierten Dateien gezeigt und einige der wichtigsten Funktionen wie effizientes Aktualisieren und Löschen auf Zeilenebene demonstriert. und die Schema-Evolution-Erfahrung für Benutzer, um mit Athena das Potenzial von Big Data auszuschöpfen.
Sie können Amazon Redshift verwenden, um Abfragen für Data Lake-Tabellen in verschiedenen Datei- und Tabellenformaten auszuführen, z Apache Hudi und Delta Lakeund jetzt mit Apache Iceberg (Vorschau), das zusätzliche Optionen für Ihre modernen Datenarchitekturanforderungen bietet.
Wir hoffen, dass dies Ihnen einen guten Ausgangspunkt für die Abfrage von Iceberg-Tabellen in Amazon Redshift bietet.
Über die Autoren
 Rohit Bansal ist Analytics Specialist Solutions Architect bei AWS. Er ist auf Amazon Redshift spezialisiert und arbeitet mit Kunden zusammen, um Analyselösungen der nächsten Generation unter Verwendung anderer AWS Analytics-Services zu entwickeln.
Rohit Bansal ist Analytics Specialist Solutions Architect bei AWS. Er ist auf Amazon Redshift spezialisiert und arbeitet mit Kunden zusammen, um Analyselösungen der nächsten Generation unter Verwendung anderer AWS Analytics-Services zu entwickeln.
 Satish Sathiya ist Senior Product Engineer bei Amazon Redshift. Er ist ein begeisterter Big-Data-Enthusiast, der mit Kunden auf der ganzen Welt zusammenarbeitet, um erfolgreich zu sein und deren Anforderungen an Data Warehousing und Data Lake-Architektur zu erfüllen.
Satish Sathiya ist Senior Product Engineer bei Amazon Redshift. Er ist ein begeisterter Big-Data-Enthusiast, der mit Kunden auf der ganzen Welt zusammenarbeitet, um erfolgreich zu sein und deren Anforderungen an Data Warehousing und Data Lake-Architektur zu erfüllen.
 Ranjan Burmann ist Analytics Specialist Solutions Architect bei AWS. Er ist auf Amazon Redshift spezialisiert und hilft Kunden beim Aufbau skalierbarer Analyselösungen. Er verfügt über mehr als 16 Jahre Erfahrung in verschiedenen Datenbank- und Data-Warehousing-Technologien. Seine Leidenschaft gilt der Automatisierung und Lösung von Kundenproblemen mit Cloud-Lösungen.
Ranjan Burmann ist Analytics Specialist Solutions Architect bei AWS. Er ist auf Amazon Redshift spezialisiert und hilft Kunden beim Aufbau skalierbarer Analyselösungen. Er verfügt über mehr als 16 Jahre Erfahrung in verschiedenen Datenbank- und Data-Warehousing-Technologien. Seine Leidenschaft gilt der Automatisierung und Lösung von Kundenproblemen mit Cloud-Lösungen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- ChartPrime. Verbessern Sie Ihr Handelsspiel mit ChartPrime. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Über Uns
- Zugang
- Zugriff
- Zugänglichkeit
- Zugriff
- Erreichen
- über
- hinzufügen
- hinzugefügt
- Zusätzliche
- Adressen
- Ranking
- Alle
- erlaubt
- bereits
- ebenfalls
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- Beträge
- an
- Analytisch
- Analytische
- Analytik
- analysieren
- und
- jedem
- Apache
- Architektur
- SIND
- um
- Feld
- AS
- At
- Im Prinzip so, wie Sie es von Google Maps kennen.
- automatisieren
- verfügbar
- AWS
- AWS-Kleber
- Grundlage
- weil
- Bevor
- Sein
- Big
- Big Data
- Bindung
- Blog
- beide
- Marke
- bauen
- Geschäft
- Business Intelligence
- by
- CAN
- Fähigkeiten
- capability
- Katalog
- Hauptgeschäftsstelle
- sicher
- challenges
- Übernehmen
- Chef
- Chief Technology Officer
- Auftraggeber
- Cloud
- Code
- Produktauswahl
- Kolonne
- Spalten
- abschließen
- Komplex
- Bedingungen
- Geht davon
- Überlegungen
- konsistent
- enthält
- verkaufen
- koordiniert
- kostengünstiger
- erstellen
- erstellt
- Erstellen
- kritischem
- Kunde
- Kundendaten
- Kunden
- Unterricht
- technische Daten
- Datenintegration
- Datensee
- Data Warehouse
- Datenbase
- Datensätze
- Datum
- Standard
- definiert
- Definition
- Definitionen
- Delta
- zeigen
- Synergie
- zeigt
- Abhängig
- Design
- Details
- erkannt
- Entwickler
- anders
- Direkt
- Nicht
- doppelt
- herunterladen
- jeder
- leicht
- Einfache
- Herausgeber
- effizient
- entweder
- eliminieren
- ermöglicht
- Motor
- Ingenieur
- Enthusiast
- Eintrag
- Äther (ETH)
- Evolution
- Beispiel
- existieren
- vorhandenen
- ERFAHRUNGEN
- Erklären
- ERKUNDEN
- erweitert
- extern
- extra
- FAST
- Eigenschaften
- Reichen Sie das
- Mappen
- Filter
- Finden Sie
- Fest
- Vorname
- Flexibilität
- Folgende
- Aussichten für
- Format
- häufig
- für
- voll
- weiter
- bekommen
- gibt
- Globus
- Goes
- groß
- Gruppe an
- Griffe
- Haben
- he
- hilft
- historisch
- ein Geschenk
- Ultraschall
- Hilfe
- HTML
- http
- HTTPS
- if
- in
- unabhängig
- Information
- Integration
- Intelligenz
- in
- IT
- SEINE
- join
- jpg
- JSON
- Niklas
- Behalten
- Wesentliche
- See
- grosse
- höchste
- Nachname
- später
- neueste
- LERNEN
- weniger
- Gefällt mir
- LIMIT
- Line
- LINK
- Liste
- Belastung
- aus einer regionalen
- Standorte
- halten
- MACHT
- Making
- verwalten
- verwaltet
- Managed
- Weise
- manuell
- manuell
- Karte
- Markt
- Marketing
- Mittel
- Triff
- Metadaten
- modern
- mehr
- vor allem warme
- schlauer bewegen
- ziehen um
- sollen
- Name
- nativen
- Need
- erforderlich
- Bedürfnisse
- Neu
- weiter
- nächste Generation
- nicht
- beachten
- jetzt an
- Anzahl
- NYC
- of
- Offizier
- on
- XNUMXh geöffnet
- Betrieb
- Einkauf & Prozesse
- Optimieren
- optimiert
- Optimierung
- Optionen
- or
- ursprünglich
- Andere
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- übrig
- Seite
- leidenschaftlich
- ausführen
- Leistung
- Zeit
- Plan
- Pläne
- Plato
- Datenintelligenz von Plato
- PlatoData
- Points
- Post
- Potenzial
- Werkzeuge
- Voraussetzungen
- Vorspann
- früher
- vorher
- Probleme
- Prozessdefinierung
- Produkt
- immobilien
- bietet
- Öffentlichkeit
- Abfragen
- Lesebrillen
- Aufzeichnungen
- Veteran
- Region
- entfernen
- ersetzen
- falls angefordert
- REST
- Rückgabe
- robust
- Führen Sie
- Laufen
- gleich
- sah
- sagt
- skalierbaren
- Skalieren
- Scan
- Scannen
- scannt
- Regelungen
- nahtlos
- nahtlos
- Abschnitt
- Verbindung
- sehen
- Senior
- Serverlos
- Lösungen
- kompensieren
- sollte
- erklären
- zeigte
- gezeigt
- Konzerte
- Einfacher
- Single
- Lösung
- Lösungen
- Auflösung
- einige
- Quelle
- Quellen
- Sourcing
- Spezialist
- spezialisiert
- Spezifikation
- Spezifikation
- Spektrum
- SQL
- Standard
- Beginnen Sie
- Erklärung
- Statistiken
- Schritt
- Shritte
- Lagerung
- speichern
- gelagert
- Läden
- Strategie
- Schnur
- Erfolg
- so
- Support
- Unterstützte
- Unterstützt
- Tabelle
- Teams
- Technologies
- Technologie
- Zehn
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- ihr
- dann
- Diese
- fehlen uns die Worte.
- Tausende
- Durch
- Zeit
- Zeitreise
- Zeitstempel
- zu
- heute
- Werkzeuge
- Transaktion
- reisen
- Wahrheit
- XNUMX
- tippe
- Typen
- einheitlich
- Gewerkschaft
- öffnen
- Aktualisierung
- aktualisiert
- Updates
- Anwendungsbereich
- -
- benutzt
- Nutzer
- verwendet
- Verwendung von
- BESTÄTIGEN
- Wert
- Werte
- Vielfalt
- verschiedene
- sehr
- Anzeigen
- Volumen
- Warehouse
- Lagerung
- wurde
- Weg..
- we
- Netz
- Web-Services
- wann
- welche
- WHO
- breit
- weit
- werden wir
- mit
- Werk
- Jahr
- Jahr
- U
- Ihr
- Zephyrnet