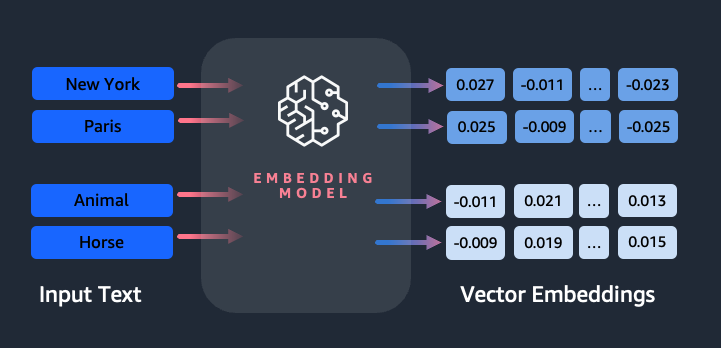
Einbettungen spielen eine Schlüsselrolle bei der Verarbeitung natürlicher Sprache (NLP) und beim maschinellen Lernen (ML). Texteinbettung bezieht sich auf den Prozess der Umwandlung von Text in numerische Darstellungen, die sich in einem hochdimensionalen Vektorraum befinden. Diese Technik wird durch den Einsatz von ML-Algorithmen erreicht, die das Verständnis der Bedeutung und des Kontexts von Daten (semantische Beziehungen) und das Erlernen komplexer Beziehungen und Muster innerhalb der Daten (syntaktische Beziehungen) ermöglichen. Sie können die resultierenden Vektordarstellungen für eine Vielzahl von Anwendungen verwenden, z. B. zum Abrufen von Informationen, zur Textklassifizierung, zur Verarbeitung natürlicher Sprache und für viele andere.
Amazon Titan-Texteinbettungen ist ein Texteinbettungsmodell, das Text in natürlicher Sprache – bestehend aus einzelnen Wörtern, Phrasen oder sogar großen Dokumenten – in numerische Darstellungen umwandelt, die für Anwendungsfälle wie Suche, Personalisierung und Clustering basierend auf semantischer Ähnlichkeit verwendet werden können.
In diesem Beitrag diskutieren wir das Amazon Titan Text Embeddings-Modell, seine Funktionen und Beispielanwendungsfälle.
Zu den Schlüsselkonzepten gehören:
- Die numerische Darstellung von Text (Vektoren) erfasst Semantik und Beziehungen zwischen Wörtern
- Um Textähnlichkeiten zu vergleichen, können umfangreiche Einbettungen verwendet werden
- Mehrsprachige Texteinbettungen können die Bedeutung in verschiedenen Sprachen identifizieren
Wie wird ein Text in einen Vektor umgewandelt?
Es gibt mehrere Techniken, um einen Satz in einen Vektor umzuwandeln. Eine beliebte Methode besteht darin, Worteinbettungsalgorithmen wie Word2Vec, GloVe oder FastText zu verwenden und die Worteinbettungen dann zu aggregieren, um eine Vektordarstellung auf Satzebene zu bilden.
Ein weiterer gängiger Ansatz ist die Verwendung großer Sprachmodelle (LLMs) wie BERT oder GPT, die kontextualisierte Einbettungen für ganze Sätze bereitstellen können. Diese Modelle basieren auf Deep-Learning-Architekturen wie Transformers, die die Kontextinformationen und Beziehungen zwischen Wörtern in einem Satz effektiver erfassen können.
Warum brauchen wir ein Einbettungsmodell?
Vektoreinbettungen sind für LLMs von grundlegender Bedeutung, um die semantischen Grade der Sprache zu verstehen, und ermöglichen es LLMs auch, bei nachgelagerten NLP-Aufgaben wie Sentimentanalyse, Erkennung benannter Entitäten und Textklassifizierung gute Leistungen zu erbringen.
Zusätzlich zur semantischen Suche können Sie Einbettungen verwenden, um Ihre Eingabeaufforderungen durch Retrieval Augmented Generation (RAG) zu erweitern und genauere Ergebnisse zu erzielen. Um sie verwenden zu können, müssen Sie sie jedoch in einer Datenbank mit Vektorfunktionen speichern.
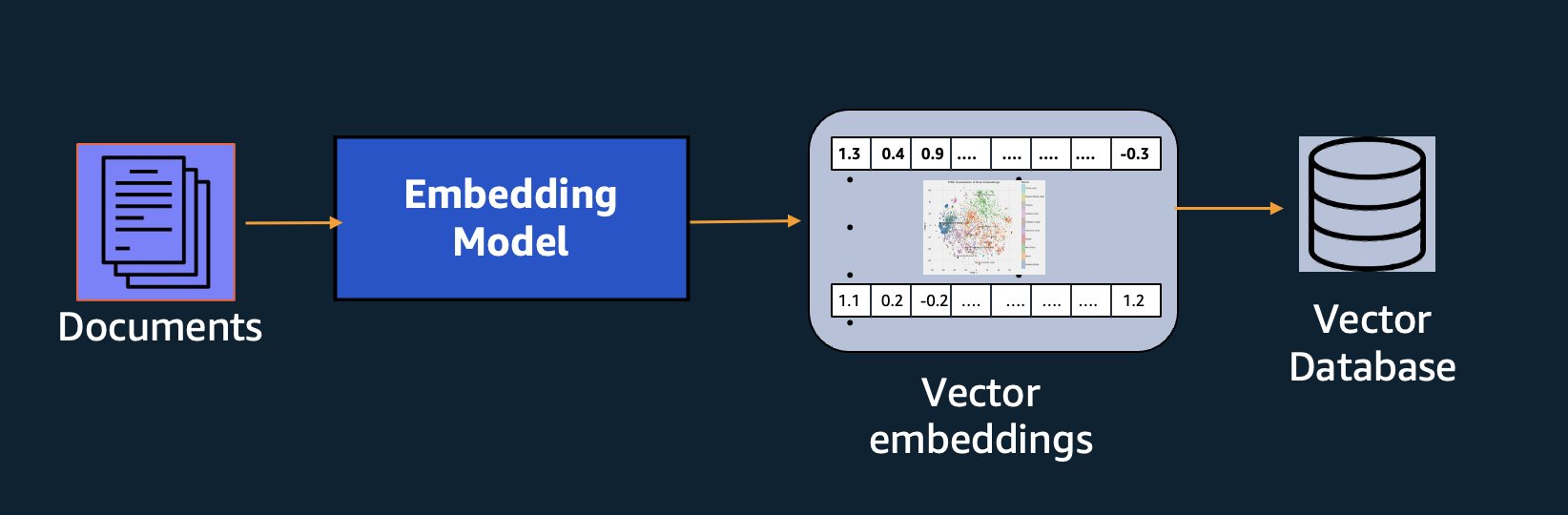
Das Amazon Titan Text Embeddings-Modell ist für den Textabruf optimiert, um RAG-Anwendungsfälle zu ermöglichen. Es ermöglicht Ihnen, Ihre Textdaten zunächst in numerische Darstellungen oder Vektoren umzuwandeln und diese Vektoren dann zu verwenden, um präzise nach relevanten Passagen aus einer Vektordatenbank zu suchen, sodass Sie Ihre proprietären Daten in Kombination mit anderen Basismodellen optimal nutzen können.
Denn Amazon Titan Text Embeddings ist ein verwaltetes Modell Amazonas Grundgestein, es wird als völlig serverloses Erlebnis angeboten. Sie können es entweder über Amazon Bedrock REST verwenden API oder das AWS SDK. Die erforderlichen Parameter sind der Text, dessen Einbettungen Sie generieren möchten, und der modelID Parameter, der den Namen des Amazon Titan Text Embeddings-Modells darstellt. Der folgende Code ist ein Beispiel für die Verwendung des AWS SDK for Python (Boto3):
Die Ausgabe sieht in etwa wie folgt aus:
Beziehen auf Amazon Bedrock boto3-Setup Weitere Informationen zum Installieren der erforderlichen Pakete, zum Herstellen einer Verbindung zu Amazon Bedrock und zum Aufrufen von Modellen finden Sie hier.
Funktionen von Amazon Titan Text Embeddings
Mit Amazon Titan Text Embeddings können Sie bis zu 8,000 Token eingeben, sodass es je nach Anwendungsfall gut für die Arbeit mit einzelnen Wörtern, Phrasen oder ganzen Dokumenten geeignet ist. Amazon Titan gibt Ausgabevektoren der Dimension 1536 zurück, was ihm ein hohes Maß an Genauigkeit verleiht und gleichzeitig für kostengünstige Ergebnisse mit geringer Latenz optimiert.
Amazon Titan Text Embeddings unterstützt das Erstellen und Abfragen von Einbettungen für Text in über 25 verschiedenen Sprachen. Dies bedeutet, dass Sie das Modell auf Ihre Anwendungsfälle anwenden können, ohne für jede Sprache, die Sie unterstützen möchten, separate Modelle erstellen und verwalten zu müssen.
Ein einziges Einbettungsmodell, das für viele Sprachen trainiert wurde, bietet die folgenden Hauptvorteile:
- Größere Reichweite – Durch die standardmäßige Unterstützung von über 25 Sprachen können Sie die Reichweite Ihrer Anwendungen auf Benutzer und Inhalte in vielen internationalen Märkten erweitern.
- Gleichbleibende Leistung – Mit einem einheitlichen Modell, das mehrere Sprachen abdeckt, erhalten Sie konsistente Ergebnisse in allen Sprachen, anstatt die Optimierung einzeln pro Sprache durchzuführen. Das Modell wird ganzheitlich trainiert, sodass Sie sprachübergreifende Vorteile erzielen.
- Unterstützung mehrsprachiger Abfragen – Amazon Titan Text Embeddings ermöglicht die Abfrage von Texteinbettungen in jeder der unterstützten Sprachen. Dies bietet die Flexibilität, semantisch ähnliche Inhalte sprachübergreifend abzurufen, ohne auf eine einzige Sprache beschränkt zu sein. Sie können mithilfe desselben einheitlichen Einbettungsraums Anwendungen erstellen, die mehrsprachige Daten abfragen und analysieren.
Zum jetzigen Zeitpunkt werden die folgenden Sprachen unterstützt:
- Arabisch
- Chinesisch (vereinfacht)
- Chinesisch (traditionell)
- Tschechische
- Niederländisch
- Englisch
- Französisch
- Deutsch
- Hebräisch
- Hindi
- Italienisch
- Japanisch
- kannada
- Koreanisch
- Malayalam
- Marathi
- Polnisch
- Portugiesisch
- Russisch
- Spanisch
- Schwedisch
- Philippinischer Tagalog
- Tamilisch
- Telugu
- Türkische
Verwendung von Amazon Titan-Texteinbettungen mit LangChain
LangChain ist ein beliebtes Open-Source-Framework für die Arbeit mit generativen KI-Modellen und unterstützenden Technologien. Es umfasst a BedrockEmbeddings-Kunde das das Boto3 SDK bequem mit einer Abstraktionsschicht umhüllt. Der BedrockEmbeddings Mit dem Client können Sie direkt mit Text und Einbettungen arbeiten, ohne die Details der JSON-Anfrage- oder Antwortstrukturen zu kennen. Das Folgende ist ein einfaches Beispiel:
Sie können auch LangChain verwenden BedrockEmbeddings Client neben dem Amazon Bedrock LLM-Client, um die Implementierung von RAG, semantischer Suche und anderen einbettungsbezogenen Mustern zu vereinfachen.
Anwendungsfälle für Einbettungen
Obwohl RAG derzeit der beliebteste Anwendungsfall für die Arbeit mit Einbettungen ist, gibt es viele andere Anwendungsfälle, in denen Einbettungen angewendet werden können. Im Folgenden sind einige zusätzliche Szenarien aufgeführt, in denen Sie Einbettungen zur Lösung spezifischer Probleme verwenden können, entweder allein oder in Zusammenarbeit mit einem LLM:
- Frage und Antwort – Einbettungen können dabei helfen, Frage- und Antwortschnittstellen über das RAG-Muster zu unterstützen. Die Generierung von Einbettungen gepaart mit einer Vektordatenbank ermöglicht es Ihnen, enge Übereinstimmungen zwischen Fragen und Inhalten in einem Wissensrepository zu finden.
- Personalisierte Empfehlungen – Ähnlich wie bei Fragen und Antworten können Sie Einbettungen verwenden, um Urlaubsziele, Hochschulen, Fahrzeuge oder andere Produkte basierend auf den vom Benutzer angegebenen Kriterien zu finden. Dies könnte in Form einer einfachen Liste von Übereinstimmungen erfolgen, oder Sie könnten dann ein LLM verwenden, um jede Empfehlung zu verarbeiten und zu erklären, wie sie die Kriterien des Benutzers erfüllt. Sie können diesen Ansatz auch verwenden, um benutzerdefinierte „10 beste“ Artikel für einen Benutzer basierend auf seinen spezifischen Bedürfnissen zu generieren.
- Datenmanagement – Wenn Sie über Datenquellen verfügen, die nicht eindeutig aufeinander abgestimmt sind, Sie aber über Textinhalte verfügen, die den Datensatz beschreiben, können Sie Einbettungen verwenden, um potenzielle Duplikate von Datensätzen zu identifizieren. Beispielsweise könnten Sie Einbettungen verwenden, um doppelte Kandidaten zu identifizieren, die möglicherweise unterschiedliche Formatierungen oder Abkürzungen verwenden oder sogar übersetzte Namen haben.
- Rationalisierung des Anwendungsportfolios – Wenn man die Anwendungsportfolios einer Muttergesellschaft und einer Akquisition aufeinander abstimmen möchte, ist es nicht immer offensichtlich, wo man potenzielle Überschneidungen finden kann. Die Qualität der Konfigurationsmanagementdaten kann ein limitierender Faktor sein und es kann schwierig sein, sich zwischen den Teams zu koordinieren, um die Anwendungslandschaft zu verstehen. Durch die Verwendung von semantischem Matching mit Einbettungen können wir eine schnelle Analyse aller Anwendungsportfolios durchführen, um Anwendungen mit hohem Potenzial für eine Rationalisierung zu identifizieren.
- Inhaltsgruppierung – Sie können Einbettungen verwenden, um die Gruppierung ähnlicher Inhalte in Kategorien zu erleichtern, die Sie möglicherweise vorher nicht kennen. Nehmen wir zum Beispiel an, Sie hätten eine Sammlung von Kunden-E-Mails oder Online-Produktbewertungen. Sie können für jedes Element Einbettungen erstellen und diese Einbettungen dann durchlaufen lassen k-bedeutet Clustering um logische Gruppierungen von Kundenanliegen, Produktlob oder -beschwerden oder anderen Themen zu identifizieren. Mithilfe eines LLM können Sie dann gezielte Zusammenfassungen aus den Inhalten dieser Gruppierungen erstellen.
Beispiel für eine semantische Suche
In unserer Beispiel auf GitHub, demonstrieren wir eine einfache Suchanwendung für Einbettungen mit Amazon Titan Text Embeddings, LangChain und Streamlit.
Das Beispiel ordnet die Abfrage eines Benutzers den nächstgelegenen Einträgen in einer speicherinternen Vektordatenbank zu. Diese Übereinstimmungen zeigen wir dann direkt in der Benutzeroberfläche an. Dies kann nützlich sein, wenn Sie eine Fehlerbehebung für eine RAG-Anwendung durchführen oder ein Einbettungsmodell direkt bewerten möchten.
Der Einfachheit halber verwenden wir das In-Memory FAISS Datenbank zum Speichern und Suchen nach Einbettungsvektoren. In einem realen Szenario im großen Maßstab möchten Sie wahrscheinlich einen dauerhaften Datenspeicher wie den verwenden Vektor-Engine für Amazon OpenSearch Serverless oder im pgvector Erweiterung für PostgreSQL.
Probieren Sie einige Eingabeaufforderungen der Webanwendung in verschiedenen Sprachen aus, beispielsweise die folgenden:
- Wie kann ich meine Nutzung überwachen?
- Wie kann ich Modelle anpassen?
- Welche Programmiersprachen kann ich nutzen?
- Kommentar me données sont-elles sécurisées ?
- のデータはどのように保護されていますか?
- Wo sind die benötigten Modelle für mich von Bedrock verfügbar?
- In welchen Regionen ist Amazon Bedrock verfügbar?
- 有哪些级别的支持?
Beachten Sie, dass, obwohl das Quellmaterial auf Englisch war, die Suchanfragen in anderen Sprachen mit relevanten Einträgen abgeglichen wurden.
Zusammenfassung
Die Textgenerierungsfähigkeiten von Basismodellen sind sehr spannend, aber es ist wichtig zu bedenken, dass das Verstehen von Text, das Finden relevanter Inhalte aus einem Wissensbestand und das Herstellen von Verbindungen zwischen Passagen entscheidend sind, um den vollen Wert der generativen KI auszuschöpfen. Wir werden in den nächsten Jahren weiterhin neue und interessante Anwendungsfälle für Einbettungen sehen, da sich diese Modelle weiter verbessern.
Nächste Schritte
Weitere Beispiele für Einbettungen als Notebooks oder Demoanwendungen finden Sie in folgenden Workshops:
Über die Autoren
 Jason Stehle ist Senior Solutions Architect bei AWS mit Sitz in der Region New England. Er arbeitet mit Kunden zusammen, um die AWS-Funktionen an ihre größten geschäftlichen Herausforderungen anzupassen. Außerhalb der Arbeit verbringt er seine Zeit damit, Dinge zu bauen und mit seiner Familie Comic-Filme anzusehen.
Jason Stehle ist Senior Solutions Architect bei AWS mit Sitz in der Region New England. Er arbeitet mit Kunden zusammen, um die AWS-Funktionen an ihre größten geschäftlichen Herausforderungen anzupassen. Außerhalb der Arbeit verbringt er seine Zeit damit, Dinge zu bauen und mit seiner Familie Comic-Filme anzusehen.
 Nitin Eusebius ist Sr. Enterprise Solutions Architect bei AWS, erfahren in Software Engineering, Unternehmensarchitektur und KI/ML. Ihm liegt die Erforschung der Möglichkeiten generativer KI sehr am Herzen. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau gut strukturierter Anwendungen auf der AWS-Plattform zu helfen, und widmet sich der Lösung technologischer Herausforderungen und der Unterstützung bei ihrer Cloud-Reise.
Nitin Eusebius ist Sr. Enterprise Solutions Architect bei AWS, erfahren in Software Engineering, Unternehmensarchitektur und KI/ML. Ihm liegt die Erforschung der Möglichkeiten generativer KI sehr am Herzen. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau gut strukturierter Anwendungen auf der AWS-Plattform zu helfen, und widmet sich der Lösung technologischer Herausforderungen und der Unterstützung bei ihrer Cloud-Reise.
 Raj Pathak ist leitender Lösungsarchitekt und technischer Berater für große Fortune-50-Unternehmen und mittelgroße Finanzdienstleistungsinstitute (FSI) in Kanada und den Vereinigten Staaten. Er ist spezialisiert auf Anwendungen des maschinellen Lernens wie generative KI, Verarbeitung natürlicher Sprache, intelligente Dokumentenverarbeitung und MLOps.
Raj Pathak ist leitender Lösungsarchitekt und technischer Berater für große Fortune-50-Unternehmen und mittelgroße Finanzdienstleistungsinstitute (FSI) in Kanada und den Vereinigten Staaten. Er ist spezialisiert auf Anwendungen des maschinellen Lernens wie generative KI, Verarbeitung natürlicher Sprache, intelligente Dokumentenverarbeitung und MLOps.
 Mani Chanuja ist Tech Lead – Generative AI Specialists, Autorin des Buches „Applied Machine Learning and High Performance Computing on AWS“ und Mitglied des Vorstands der Women in Manufacturing Education Foundation. Sie leitet Projekte zum maschinellen Lernen (ML) in verschiedenen Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und generative KI. Sie hilft Kunden dabei, große Modelle für maschinelles Lernen in großem Maßstab zu erstellen, zu trainieren und bereitzustellen. Sie spricht auf internen und externen Konferenzen wie re:Invent, Women in Manufacturing West, YouTube-Webinaren und GHC 23. In ihrer Freizeit geht sie gerne lange Läufe am Strand entlang.
Mani Chanuja ist Tech Lead – Generative AI Specialists, Autorin des Buches „Applied Machine Learning and High Performance Computing on AWS“ und Mitglied des Vorstands der Women in Manufacturing Education Foundation. Sie leitet Projekte zum maschinellen Lernen (ML) in verschiedenen Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und generative KI. Sie hilft Kunden dabei, große Modelle für maschinelles Lernen in großem Maßstab zu erstellen, zu trainieren und bereitzustellen. Sie spricht auf internen und externen Konferenzen wie re:Invent, Women in Manufacturing West, YouTube-Webinaren und GHC 23. In ihrer Freizeit geht sie gerne lange Läufe am Strand entlang.
 Markus Roy ist Principal Machine Learning Architect für AWS und unterstützt Kunden beim Entwerfen und Erstellen von KI/ML-Lösungen. Marks Arbeit deckt ein breites Spektrum von ML-Anwendungsfällen ab, wobei sein Hauptinteresse an Computer Vision, Deep Learning und der Skalierung von ML im gesamten Unternehmen liegt. Er hat Unternehmen in vielen Branchen unterstützt, darunter Versicherungen, Finanzdienstleistungen, Medien und Unterhaltung, Gesundheitswesen, Versorgungsunternehmen und Fertigung. Mark verfügt über sechs AWS-Zertifizierungen, darunter die ML Specialty Certification. Bevor er zu AWS kam, war Mark über 25 Jahre lang als Architekt, Entwickler und Technologieführer tätig, davon 19 Jahre im Finanzdienstleistungsbereich.
Markus Roy ist Principal Machine Learning Architect für AWS und unterstützt Kunden beim Entwerfen und Erstellen von KI/ML-Lösungen. Marks Arbeit deckt ein breites Spektrum von ML-Anwendungsfällen ab, wobei sein Hauptinteresse an Computer Vision, Deep Learning und der Skalierung von ML im gesamten Unternehmen liegt. Er hat Unternehmen in vielen Branchen unterstützt, darunter Versicherungen, Finanzdienstleistungen, Medien und Unterhaltung, Gesundheitswesen, Versorgungsunternehmen und Fertigung. Mark verfügt über sechs AWS-Zertifizierungen, darunter die ML Specialty Certification. Bevor er zu AWS kam, war Mark über 25 Jahre lang als Architekt, Entwickler und Technologieführer tätig, davon 19 Jahre im Finanzdienstleistungsbereich.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Über uns
- Abstraktion
- Akzeptieren
- Genauigkeit
- genau
- genau
- erreicht
- Erreichen
- Erwerb
- über
- Zusatz
- Zusätzliche
- Vorteil
- Berater
- voraus
- AI
- KI-Modelle
- AI / ML
- Algorithmen
- ausrichten
- Alle
- erlauben
- Zulassen
- erlaubt
- entlang
- neben
- ebenfalls
- immer
- Amazon
- Amazon Web Services
- an
- Analyse
- analysieren
- und
- beantworten
- jedem
- Anwendung
- Anwendungen
- angewandt
- Jetzt bewerben
- Ansatz
- Architektur
- Architekturen
- SIND
- Bereich
- Artikel
- AS
- Unterstützung
- At
- vermehren
- Augmented
- Autor
- verfügbar
- AWS
- basierend
- BE
- Beach
- Sein
- Vorteile
- zwischen
- Tafel
- Vorstand
- Körper
- buchen
- Box
- bauen
- Building
- Geschäft
- aber
- by
- CAN
- Kanada
- Kandidat
- Kandidaten
- Fähigkeiten
- Erfassung
- Captures
- Häuser
- Fälle
- Kategorien
- Zertifizierung
- Zertifizierungen
- Herausforderungen
- Einstufung
- Auftraggeber
- Menu
- Cloud
- Clustering
- Code
- Sammlung
- Hochschulen
- Kombination
- gemeinsam
- Unternehmen
- Unternehmen
- vergleichen
- Beschwerden
- Komplex
- Computer
- Computer Vision
- Computing
- Konzepte
- Bedenken
- Kongressbegleitung
- Konfiguration
- Vernetz Dich
- Verbindung
- Verbindungen
- konsistent
- Inhalt
- Kontext
- kontextuelle
- fortsetzen
- bequem
- verkaufen
- umgewandelt
- Zusammenarbeit
- koordinieren
- kostengünstiger
- könnte
- Abdeckung
- deckt
- erstellen
- Erstellen
- Kriterien
- wichtig
- Zur Zeit
- Original
- Kunde
- Kunden
- anpassen
- technische Daten
- Datenbase
- de
- gewidmet
- tief
- tiefe Lernen
- tief
- definieren
- Grad
- Demo
- zeigen
- einsetzen
- beschreibt
- Design
- Reiseziele
- Details
- Entwickler:in / Unternehmen
- anders
- schwer
- Abmessungen
- Direkt
- Geschäftsführung
- diskutieren
- Display
- do
- Dokument
- Unterlagen
- Domains
- Nicht
- jeder
- Bildungswesen
- effektiv
- entweder
- E-Mails
- Einbettung
- entstehen
- ermöglichen
- ermöglicht
- Motor
- Entwicklung
- England
- Englisch
- Unternehmen
- Enterprise-Lösungen
- Unterhaltung
- Ganz
- vollständig
- Einheit
- Äther (ETH)
- bewerten
- Sogar
- Beispiel
- Beispiele
- unterhaltsame Programmpunkte
- Erweitern Sie die Funktionalität der
- ERFAHRUNGEN
- erfahrensten
- Erklären
- Möglichkeiten sondieren
- Erweiterung
- extern
- erleichtern
- Faktor
- Familie
- Eigenschaften
- wenige
- Revolution
- Finanzdienstleistungen
- Finden Sie
- Suche nach
- Vorname
- Flexibilität
- konzentriert
- Folgende
- Aussichten für
- unten stehende Formular
- Vermögen
- Foundation
- Unser Ansatz
- Frei
- für
- voller
- fundamental
- erzeugen
- Generation
- generativ
- Generative KI
- bekommen
- bekommen
- Unterstützung
- Handschuh
- Go
- größte
- hätten
- Haben
- he
- Gesundheitswesen
- Hilfe
- dazu beigetragen,
- Unternehmen
- hilft
- hier (auf dänisch)
- GUTE
- Hochleistungsrechnen
- seine
- hält
- Ultraschall
- Hilfe
- HTML
- HTTPS
- i
- identifizieren
- if
- Umsetzung
- importieren
- wichtig
- zu unterstützen,
- in
- In anderen
- das
- Dazu gehören
- Einschließlich
- Branchen
- Information
- Varianten des Eingangssignals:
- installieren
- beantragen müssen
- Institutionen
- Versicherung
- Intelligent
- Intelligente Dokumentenverarbeitung
- Interesse
- interessant
- Schnittstelle
- Schnittstellen
- intern
- International
- in
- IT
- SEINE
- Beitritt
- Reise
- jpg
- JSON
- Wesentliche
- Wissen
- Wissend
- Wissen
- Landschaft
- Sprache
- Sprachen
- grosse
- Schicht
- führen
- Führer
- umwandeln
- lernen
- lassen
- Gefällt mir
- wahrscheinlich
- Gleichen
- Begrenzung
- Liste
- llm
- logisch
- Lang
- aussehen
- suchen
- Maschine
- Maschinelles Lernen
- halten
- um
- Making
- verwaltet
- Management
- Herstellung
- viele
- Karte
- Kennzeichen
- Marks
- Märkte
- abgestimmt
- Streichhölzer
- Abstimmung
- Ihres Materials
- me
- Bedeutung
- Mittel
- Medien
- Mitglied
- Methode
- könnte
- ML
- ML-Algorithmen
- MLOps
- Modell
- für
- Überwachen
- mehr
- vor allem warme
- Am beliebtesten
- Filme
- mehrere
- my
- Name
- Namens
- Namen
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Need
- benötigen
- Bedürfnisse
- Neu
- weiter
- Nlp
- Laptops
- offensichtlich
- of
- angeboten
- on
- EINEM
- Online
- XNUMXh geöffnet
- Open-Source-
- optimiert
- Optimierung
- or
- Auftrag
- Andere
- Anders
- UNSERE
- Möglichkeiten für das Ausgangssignal:
- aussen
- übrig
- besitzen
- Pakete
- gepaart
- Parameter
- Parameter
- Muttergesellschaft
- Passagen
- leidenschaftlich
- Schnittmuster
- Muster
- für
- ausführen
- Leistung
- Personalisierung
- Sätze
- Stück
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Play
- Bitte
- Beliebt
- BY
- Mappe
- Portfolios
- Möglichkeiten
- Post
- Postgresql
- Potenzial
- Werkzeuge
- primär
- Principal
- Vor
- Probleme
- Prozessdefinierung
- Verarbeitung
- Produkt
- Produktrezensionen
- Produkte
- Programmierung
- Programmiersprachen
- Projekte
- Eingabeaufforderungen
- Eigentums-
- die
- vorausgesetzt
- bietet
- Python
- Qualität
- Abfragen
- query
- Frage
- Fragen
- Direkt
- Lappen
- Angebot
- RE
- erreichen
- realen Welt
- Anerkennung
- Software Empfehlungen
- Empfehlungen
- Rekord
- Aufzeichnungen
- bezieht sich
- Beziehungen
- relevant
- merken
- Quelle
- Darstellung
- representiert
- Anforderung
- falls angefordert
- Antwort
- REST
- eingeschränkt
- was zu
- Die Ergebnisse
- Abruf
- Rückgabe
- Bewertungen
- Rollen
- Führen Sie
- läuft
- s
- gleich
- Skalieren
- Skalierung
- Szenario
- Szenarien
- Sdk
- Suche
- sehen
- semantisch
- Semantik
- Senior
- Satz
- Gefühl
- getrennte
- Serverlos
- Dienstleistungen
- sie
- ähnlich
- Einfacher
- Einfachheit
- vereinfachte
- vereinfachen
- Single
- SIX
- So
- Software
- Softwareentwicklung
- Lösungen
- LÖSEN
- Auflösung
- einige
- etwas
- Quelle
- Quellen
- Raumfahrt
- spricht
- Spezialisten
- spezialisiert
- Spezialprodukte
- spezifisch
- Anfang
- begonnen
- Staaten
- speichern
- Strukturen
- so
- Support
- Unterstützte
- Unterstützung
- Unterstützt
- Nehmen
- und Aufgaben
- Teams
- Tech
- Technische
- Technik
- Techniken
- Technologies
- Technologie
- erzählen
- Text
- Textklassifizierung
- Texterzeugung
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Die Quelle
- ihr
- Sie
- Themen
- dann
- Dort.
- Diese
- fehlen uns die Worte.
- diejenigen
- obwohl?
- Durch
- Zeit
- Titan
- zu
- Tokens
- traditionell
- Training
- trainiert
- Transformer
- Transformieren
- verstehen
- Verständnis
- einheitlich
- Vereinigt
- USA
- Anwendungsbereich
- -
- Anwendungsfall
- benutzt
- nützlich
- Mitglied
- Benutzerschnittstelle
- Nutzer
- Verwendung von
- Dienstprogramme
- Urlaub
- Wert
- verschiedene
- Fahrzeuge
- sehr
- Seh-
- wollen
- wurde
- beobachten
- we
- Netz
- Internetanwendung
- Web-Services
- Webinare
- GUT
- waren
- West
- wann
- welche
- während
- breit
- Große Auswahl
- werden wir
- mit
- .
- ohne
- Damen
- Word
- Worte
- Arbeiten
- arbeiten,
- Werk
- Workshops
- würde
- schreiben
- Schreiben
- Jahr
- U
- Ihr
- Youtube
- Zephyrnet