Bild vom Herausgeber
Key Take Away
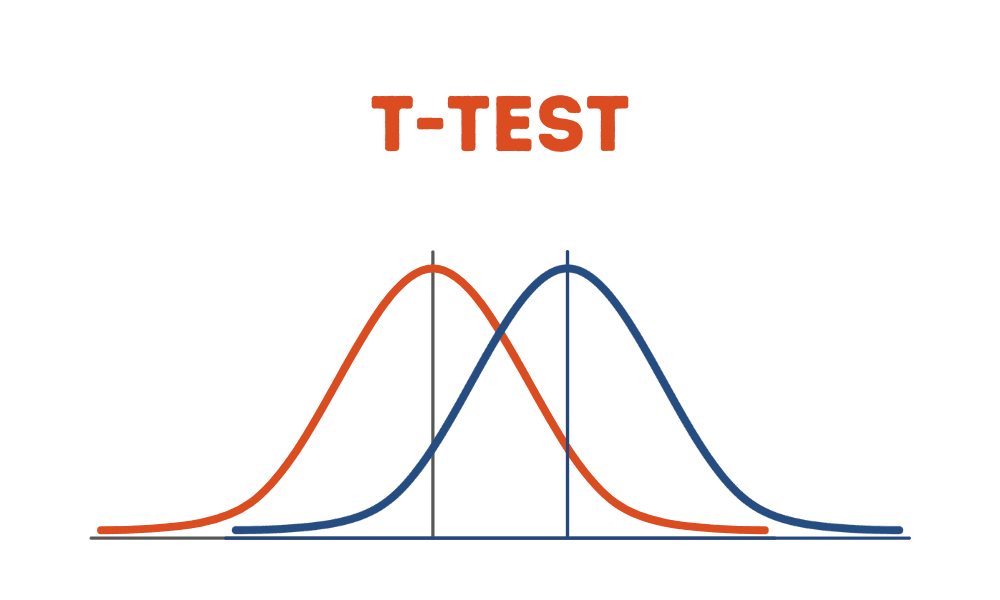
- Der t-Test ist ein statistischer Test, mit dem bestimmt werden kann, ob es einen signifikanten Unterschied zwischen den Mittelwerten zweier unabhängiger Datenstichproben gibt.
- Wir veranschaulichen, wie ein t-Test mit dem Iris-Datensatz und der Scipy-Bibliothek von Python angewendet werden kann.
Der t-Test ist ein statistischer Test, mit dem bestimmt werden kann, ob es einen signifikanten Unterschied zwischen den Mittelwerten zweier unabhängiger Datenstichproben gibt. In diesem Tutorial veranschaulichen wir die grundlegendste Version des t-Tests, bei der wir davon ausgehen, dass die beiden Stichproben gleiche Varianzen aufweisen. Andere fortgeschrittene Versionen des t-Tests umfassen den t-Test nach Welch, der eine Anpassung des t-Tests ist und zuverlässiger ist, wenn die beiden Stichproben ungleiche Varianzen und möglicherweise ungleiche Stichprobenumfänge aufweisen.
Die t-Statistik oder der t-Wert wird wie folgt berechnet:
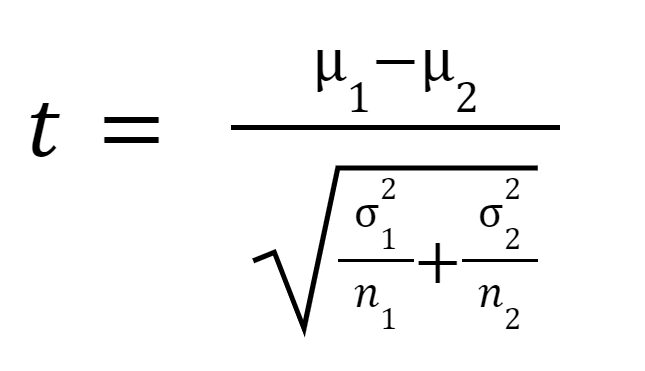
woher
ist der Mittelwert von Stichprobe 1,
ist der Mittelwert von Stichprobe 2,
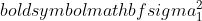 ist die Varianz von Stichprobe 1,
ist die Varianz von Stichprobe 1, 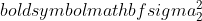 ist die Varianz von Stichprobe 2,
ist die Varianz von Stichprobe 2, 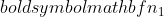 ist die Stichprobengröße von Stichprobe 1, und
ist die Stichprobengröße von Stichprobe 1, und 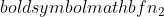 ist die Stichprobengröße von Stichprobe 2.
ist die Stichprobengröße von Stichprobe 2.
Um die Verwendung des t-Tests zu veranschaulichen, zeigen wir ein einfaches Beispiel anhand des Iris-Datensatzes. Angenommen, wir beobachten zwei unabhängige Proben, z. B. Blütenkelchlängen, und wir überlegen, ob die beiden Proben aus derselben Population (z. B. derselben Blütenart oder zwei Arten mit ähnlichen Kelchblattmerkmalen) oder zwei verschiedenen Populationen stammen.
Der t-Test quantifiziert die Differenz zwischen den arithmetischen Mittelwerten der beiden Stichproben. Der p-Wert quantifiziert die Wahrscheinlichkeit, die beobachteten Ergebnisse zu erhalten, unter der Annahme, dass die Nullhypothese (dass die Stichproben aus Grundgesamtheiten mit denselben Mittelwerten der Grundgesamtheit gezogen wurden) wahr ist. Ein p-Wert größer als ein gewählter Schwellenwert (z. B. 5 % oder 0.05) zeigt an, dass es nicht so unwahrscheinlich ist, dass unsere Beobachtung zufällig aufgetreten ist. Daher akzeptieren wir die Nullhypothese gleicher Populationsmittelwerte. Wenn der p-Wert kleiner als unser Schwellenwert ist, haben wir Beweise gegen die Nullhypothese gleicher Populationsmittelwerte.
T-Test-Eingang
Die zur Durchführung eines t-Tests erforderlichen Eingaben oder Parameter sind:
- Zwei Arrays a und b enthält die Daten für Probe 1 und Probe 2
T-Test-Ausgänge
Der t-Test gibt Folgendes zurück:
- Die berechnete t-Statistik
- Der p-Wert
Importieren Sie notwendige Bibliotheken
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Iris-Datensatz laden
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Berechnen Sie die Stichprobenmittelwerte und Stichprobenvarianzen
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementieren Sie den t-Test
stats.ttest_ind(a_1, b_1, equal_var = False)
Output
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Output
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Output
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Beobachtungen
Wir beobachten, dass die Verwendung von „true“ oder „false“ für den „equal-var“-Parameter die t-Test-Ergebnisse nicht sehr verändert. Wir beobachten auch, dass das Vertauschen der Reihenfolge der Probenarrays a_1 und b_1 einen negativen t-Testwert ergibt, aber die Größe des t-Testwerts nicht wie erwartet ändert. Da der berechnete p-Wert viel größer als der Schwellenwert von 0.05 ist, können wir die Nullhypothese verwerfen, dass die Differenz zwischen den Mittelwerten von Stichprobe 1 und Stichprobe 2 signifikant ist. Dies zeigt, dass die Kelchblattlängen für Probe 1 und Probe 2 aus denselben Populationsdaten gezogen wurden.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Berechnen Sie die Stichprobenmittelwerte und Stichprobenvarianzen
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Implementieren Sie den t-Test
stats.ttest_ind(a_1, b_1, equal_var = False)
Output
stats.ttest_ind(a_1, b_1, equal_var = False)Beobachtungen
Wir beobachten, dass die Verwendung von Stichproben mit ungleicher Größe die t-Statistik und den p-Wert nicht signifikant verändert.
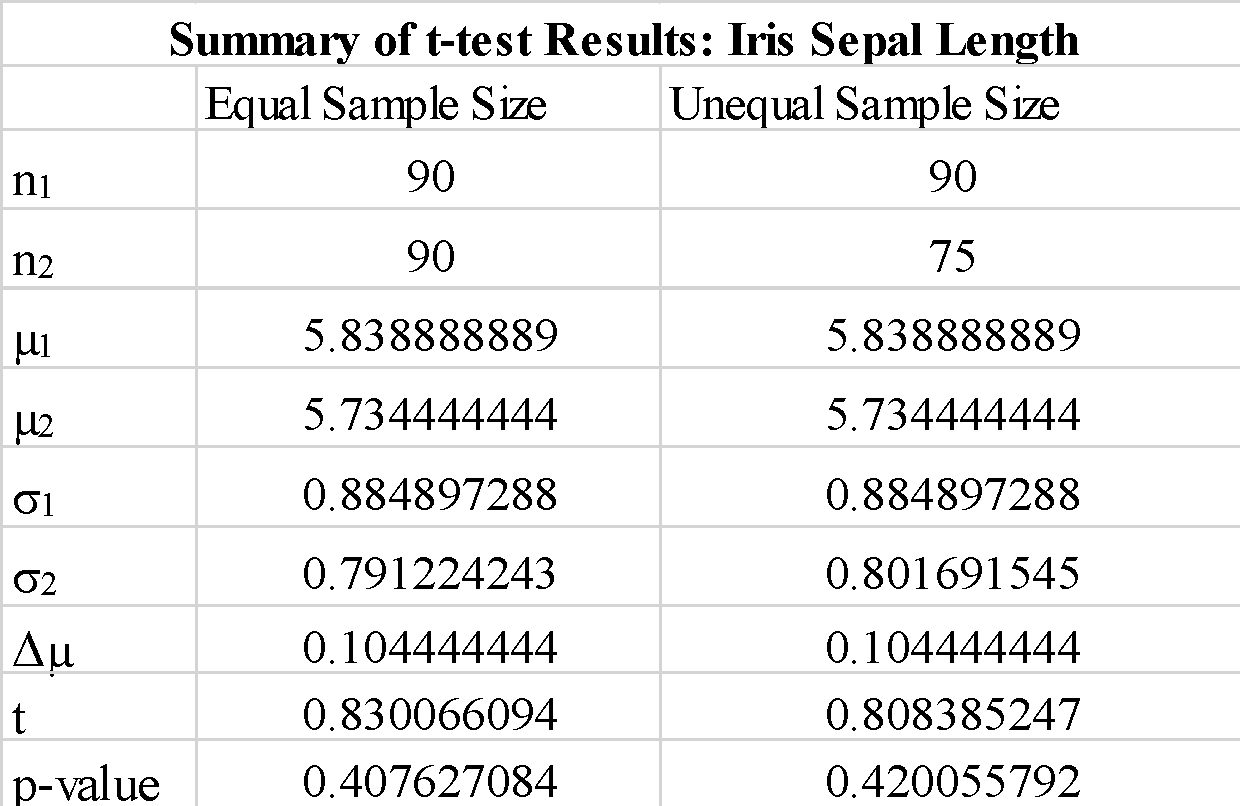
Zusammenfassend haben wir gezeigt, wie ein einfacher t-Test mit der scipy-Bibliothek in Python implementiert werden könnte.
Benjamin O. Tayo ist Physiker, Data Science Educator und Autor sowie Eigentümer von DataScienceHub. Zuvor unterrichtete Benjamin Ingenieurwissenschaften und Physik an der University of Central Oklahoma, der Grand Canyon University und der Pittsburgh State University.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Akzeptieren
- advanced
- gegen
- und
- angewandt
- basic
- Christoph
- zwischen
- berechnet
- Hauptgeschäftsstelle
- Chance
- Übernehmen
- Charakteristik
- gewählt
- Berücksichtigung
- könnte
- technische Daten
- Datenwissenschaft
- Datensätze
- Bestimmen
- Unterschied
- anders
- gezogen
- Entwicklung
- Beweis
- Beispiel
- erwartet
- Blume
- Folgende
- folgt
- für
- Ultraschall
- HTTPS
- umgesetzt
- importieren
- in
- das
- unabhängig
- zeigt
- KDnuggets
- größer
- Bibliothek
- Matplotlib
- Mittel
- mehr
- vor allem warme
- notwendig,
- Negativ
- numpig
- beobachten
- beschaffen
- aufgetreten
- Oklahoma
- Auftrag
- Andere
- Eigentümer
- Parameter
- Parameter
- Durchführung
- Physik
- Pittsburgh
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bevölkerung
- Populationen
- vorher
- Wahrscheinlichkeit
- Python
- zuverlässig
- Die Ergebnisse
- Rückgabe
- gleich
- Wissenschaft
- erklären
- gezeigt
- Konzerte
- signifikant
- bedeutend
- ähnlich
- Einfacher
- da
- Größe
- Größen
- kleinere
- So
- Bundesstaat
- statistisch
- Statistik
- ZUSAMMENFASSUNG
- Einführungen
- Test
- Das
- deswegen
- Schwelle
- zu
- was immer dies auch sein sollte.
- Lernprogramm
- -
- Wert
- Version
- ob
- welche
- werden wir
- Schriftsteller
- Erträge
- Zephyrnet