Einleitung
Large Language Models (LLMs) und Generative KI stellen einen transformativen Durchbruch in der künstlichen Intelligenz und der Verarbeitung natürlicher Sprache dar. Sie können menschliche Sprache verstehen und erzeugen und Inhalte wie Text, Bilder, Audio und synthetische Daten produzieren, was sie in verschiedenen Anwendungen äußerst vielseitig macht. Generative KI ist in realen Anwendungen von enormer Bedeutung, da sie die Erstellung von Inhalten automatisiert und verbessert, Benutzererlebnisse personalisiert, Arbeitsabläufe rationalisiert und Kreativität fördert. In dieser Lektüre konzentrieren wir uns darauf, wie Unternehmen Open LLMs integrieren können, indem sie die Eingabeaufforderungen mithilfe von Enterprise Knowledge Graphs effektiv verankern.
Lernziele
- Erwerben Sie Kenntnisse über Grounding und Prompt Building bei der Interaktion mit LLMs/Gen-AI-Systemen.
- Verstehen Sie die Unternehmensrelevanz von Grounding und den Geschäftswert der Integration mit offenen Gen-AI-Systemen anhand eines Beispiels.
- Analysieren Sie zwei große, konkurrierende Lösungen, Knowledge Graphs und Vector Stores an verschiedenen Fronten und ermitteln Sie, welche Lösungen wann geeignet sind.
- Studieren Sie ein beispielhaftes Unternehmensdesign für die Grundlagen- und Prompt-Erstellung, die Nutzung von Wissensgraphen, die Modellierung von Lerndaten und die Graphenmodellierung in JAVA für ein personalisiertes Kundenempfehlungsszenario.
Dieser Artikel wurde als Teil des veröffentlicht Data-Science-Blogathon.
Inhaltsverzeichnis
Was sind große Sprachmodelle?
Ein Large Language Model ist ein fortschrittliches KI-Modell, das mithilfe von Deep-Learning-Techniken auf riesigen Textmengen und unstrukturierten Daten trainiert wird. Diese Modelle sind in der Lage, mit der menschlichen Sprache zu interagieren, menschenähnliche Texte, Bilder und Audio zu erzeugen und verschiedene Aufgaben auszuführen Verarbeitung natürlicher Sprache Aufgaben.
Im Gegensatz dazu bezieht sich die Definition eines Sprachmodells auf die Zuweisung von Wahrscheinlichkeiten zu Wortfolgen auf der Grundlage der Analyse von Textkorpora. Ein Sprachmodell kann von einfachen N-Gramm-Modellen bis hin zu komplexeren neuronalen Netzwerkmodellen variieren. Der Begriff „großes Sprachmodell“ bezieht sich jedoch normalerweise auf Modelle, die Deep-Learning-Techniken verwenden und über eine große Anzahl von Parametern verfügen, die von Millionen bis Milliarden reichen können. Diese Modelle können komplexe Muster in der Sprache erfassen und Texte erzeugen, die oft nicht von den von Menschen geschriebenen Texten zu unterscheiden sind.
Was ist eine Eingabeaufforderung?
Eine Aufforderung an ein beliebiges LLM oder ein ähnliches Chatbot-KI-System ist eine textbasierte Eingabe oder Nachricht, die Sie bereitstellen, um ein Gespräch oder eine Interaktion mit der KI zu initiieren. LLMs sind vielseitig, mit einer Vielzahl von Big Data trainiert und können für verschiedene Aufgaben eingesetzt werden; Daher haben Kontext, Umfang, Qualität und Klarheit Ihrer Eingabeaufforderung erheblichen Einfluss auf die Antworten, die Sie von den LLM-Systemen erhalten.
Was ist Erdung/RAG?
Grounding, AKA Retrieval-Augmented Generation (RAG), bezieht sich im Kontext der LLM-Verarbeitung in natürlicher Sprache auf die Anreicherung der Eingabeaufforderung mit Kontext, zusätzlichen Metadaten und Spielraum, den wir LLMs zur Verfügung stellen, um maßgeschneiderte und genauere Antworten zu verbessern und abzurufen. Diese Verbindung hilft KI-Systemen, die Daten so zu verstehen und zu interpretieren, dass sie dem erforderlichen Umfang und Kontext entsprechen. Untersuchungen zu LLMs zeigen, dass die Qualität ihrer Reaktion von der Qualität der Aufforderung abhängt.
Es handelt sich um ein grundlegendes Konzept der KI, da es die Lücke zwischen Rohdaten und der Fähigkeit der KI schließt, diese Daten auf eine Weise zu verarbeiten und zu interpretieren, die mit dem menschlichen Verständnis und dem räumlichen Kontext im Einklang steht. Es verbessert die Qualität und Zuverlässigkeit von KI-Systemen und ihre Fähigkeit, genaue und nützliche Informationen oder Antworten zu liefern.
Was sind die Nachteile von LLMs?
Large Language Models (LLMs) wie GPT-3 haben große Aufmerksamkeit erlangt und werden in verschiedenen Anwendungen eingesetzt, sie bringen jedoch auch einige Vor- und Nachteile mit sich. Zu den Hauptnachteilen von LLMs gehören:
1. Voreingenommenheit und Fairness: LLMs erben häufig Verzerrungen aus den Trainingsdaten. Dies kann dazu führen, dass voreingenommene oder diskriminierende Inhalte entstehen, die schädliche Stereotypen verstärken und bestehende Vorurteile aufrechterhalten können.
2. Halluzinationen: LLMs verstehen die von ihnen generierten Inhalte nicht wirklich; Sie generieren Text basierend auf Mustern in den Trainingsdaten. Dies bedeutet, dass sie sachlich falsche oder unsinnige Informationen liefern können, wodurch sie für kritische Anwendungen wie medizinische Diagnosen oder Rechtsberatung ungeeignet sind.
3. Computerressourcen: Das Training und der Betrieb von LLMs erfordern enorme Rechenressourcen, einschließlich spezieller Hardware wie GPUs und TPUs. Dies macht ihre Entwicklung und Wartung teuer.
4. Datenschutz und Sicherheit: LLMs können überzeugende gefälschte Inhalte generieren, einschließlich Text, Bildern und Audio. Dies gefährdet den Datenschutz und die Datensicherheit, da sie zur Erstellung betrügerischer Inhalte oder zur Nachahmung von Einzelpersonen ausgenutzt werden können.
5. Ethische Bedenken: Der Einsatz von LLMs in verschiedenen Anwendungen, wie Deepfakes oder automatisierter Inhaltsgenerierung, wirft ethische Fragen hinsichtlich ihres Missbrauchspotenzials und ihrer Auswirkungen auf die Gesellschaft auf.
6. Regulatorische Herausforderungen: Die rasante Entwicklung der LLM-Technologie hat die regulatorischen Rahmenbedingungen überholt, was es schwierig macht, geeignete Richtlinien und Vorschriften festzulegen, um den potenziellen Risiken und Herausforderungen im Zusammenhang mit LLMs zu begegnen.
Es ist wichtig zu beachten, dass viele dieser Nachteile LLMs nicht inhärent sind, sondern eher darauf zurückzuführen sind, wie sie entwickelt, eingesetzt und genutzt werden. Es werden weiterhin Anstrengungen unternommen, um diese Nachteile zu mildern und LLMs verantwortungsvoller und vorteilhafter für die Gesellschaft zu machen. Hier können Erdung und Maskierung eingesetzt werden und für die Unternehmen von großem Vorteil sein.
Unternehmensrelevanz der Erdung
Unternehmen sind bestrebt, Large Language Models (LLMs) in ihre geschäftskritischen Anwendungen zu integrieren. Sie verstehen den potenziellen Wert, den LLMs in verschiedenen Bereichen bieten könnten. Der Aufbau, die Vorschulung und die Feinabstimmung von LLMs ist für sie ziemlich teuer und umständlich. Vielmehr könnten sie die in der Branche verfügbaren offenen KI-Systeme nutzen, um die Eingabeaufforderungen rund um Unternehmensanwendungsfälle zu verankern und zu maskieren.
Daher ist Grounding eine wichtige Überlegung für Unternehmen und für sie relevanter und hilfreicher, sowohl bei der Verbesserung der Qualität der Antworten als auch bei der Überwindung von Bedenken hinsichtlich Halluzinationen, Datensicherheit und Compliance, da es einen erstaunlichen Geschäftswert aus der Offenlegung heraus schaffen kann Auf dem Markt sind LLMs für zahlreiche Anwendungsfälle verfügbar, deren Automatisierung heute eine Herausforderung darstellt.
Vorteile für Unternehmen
Die Implementierung von Grounding mit LLMs bietet Unternehmen mehrere Vorteile:
1. Erhöhte Glaubwürdigkeit: Indem Unternehmen sicherstellen, dass die von LLMs generierten Informationen und Inhalte auf verifizierten Datenquellen basieren, können sie die Glaubwürdigkeit ihrer Kommunikation, Berichte und Inhalte erhöhen. Dies kann dazu beitragen, Vertrauen bei Kunden, Klienten und Stakeholdern aufzubauen.
2. Verbesserte Entscheidungsfindung: In Unternehmensanwendungen, insbesondere solchen im Zusammenhang mit Datenanalyse und Entscheidungsunterstützung, kann der Einsatz von LLMs mit Datengrundlage zuverlässigere Erkenntnisse liefern. Dies kann zu einer fundierteren Entscheidungsfindung führen, die für die strategische Planung und das Geschäftswachstum von entscheidender Bedeutung ist.
3. Einhaltung Gesetzlicher Vorschriften: Viele Branchen unterliegen regulatorischen Anforderungen an die Datengenauigkeit und -konformität. Die Datenerhebung mit LLMs kann bei der Einhaltung dieser Compliance-Standards helfen und das Risiko rechtlicher oder regulatorischer Probleme verringern.
4. Generierung hochwertiger Inhalte: LLMs werden häufig bei der Erstellung von Inhalten verwendet, beispielsweise für Marketing, Kundensupport und Produktbeschreibungen. Durch die Datenerhebung wird sichergestellt, dass die generierten Inhalte sachlich korrekt sind, wodurch das Risiko der Verbreitung falscher oder irreführender Informationen oder Halluzinationen verringert wird.
5. Reduzierung von Fehlinformationen: In Zeiten gefälschter Nachrichten und Fehlinformationen kann Data Grounding Unternehmen dabei helfen, die Verbreitung falscher Informationen zu bekämpfen, indem sichergestellt wird, dass die von ihnen generierten oder geteilten Inhalte auf validierten Datenquellen basieren.
6. Kundenzufriedenheit: Die Bereitstellung genauer und zuverlässiger Informationen für Kunden kann ihre Zufriedenheit und ihr Vertrauen in die Produkte oder Dienstleistungen eines Unternehmens steigern.
7. Risikominderung: Die Datenerhebung kann dazu beitragen, das Risiko zu verringern, Entscheidungen auf der Grundlage ungenauer oder unvollständiger Informationen zu treffen, was zu finanziellen Schäden oder Reputationsschäden führen könnte.
Beispiel: Ein Produktempfehlungsszenario eines Kunden
Sehen wir uns an, wie die Datenerdung mithilfe von openAI chatGPT für einen Unternehmensanwendungsfall hilfreich sein könnte
Grundlegende Eingabeaufforderungen
Generate a short email adding coupons on recommended products to customer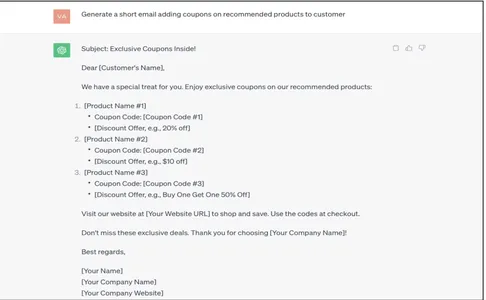
Die von ChatGPT generierte Antwort ist sehr allgemein, nicht kontextualisiert und unformatiert. Dies muss manuell mit den richtigen Unternehmenskundendaten aktualisiert/zugeordnet werden, was teuer ist. Sehen wir uns an, wie dies mit Datenerdungstechniken automatisiert werden könnte.
Angenommen, das Unternehmen verfügt bereits über die Unternehmenskundendaten und ein intelligentes Empfehlungssystem, das Gutscheine und Empfehlungen für die Kunden generieren kann. Wir könnten die obige Eingabeaufforderung sehr gut untermauern, indem wir sie mit den richtigen Metadaten anreichern, sodass der von chatGPT generierte E-Mail-Text genau so ist, wie wir ihn haben möchten, und sehr gut automatisiert werden kann, um E-Mails an den Kunden ohne manuelles Eingreifen zu senden.
Nehmen wir an, dass unsere Grounding-Engine die richtigen Anreicherungsmetadaten aus Kundendaten erhält und die Eingabeaufforderung unten aktualisiert. Sehen wir uns an, wie die ChatGPT-Antwort für die geerdete Eingabeaufforderung aussehen würde.
Geerdete Eingabeaufforderung
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off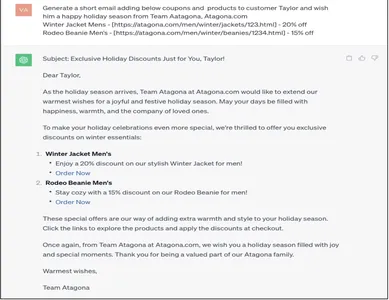
Die mit der Bodenaufforderung generierte Antwort entspricht genau der Art und Weise, wie das Unternehmen den Kunden benachrichtigen möchte. Die Einbettung angereicherter Kundendaten in eine E-Mail-Antwort von Gen AI ist eine Automatisierung, die für die Skalierung und den Erhalt von Unternehmen bemerkenswert wäre.
LLM-Erdungslösungen für Unternehmen für Softwaresysteme
Es gibt mehrere Möglichkeiten, die Daten in Unternehmenssystemen zu verankern, und eine Kombination dieser Techniken könnte für eine effektive Datenverankerung und eine zeitnahe Generierung speziell für den Anwendungsfall verwendet werden. Die beiden Hauptkandidaten als mögliche Lösungen für die Implementierung von Retrieval Augmented Generation (Grounding) sind
- Anwendungsdaten|Wissensdiagramme
- Vektoreinbettungen und semantische Suche
Die Verwendung dieser Lösungen hängt vom Anwendungsfall und der Erdung ab, die Sie anwenden möchten. Beispielsweise können von Vektorspeichern bereitgestellte Antworten ungenau und vage sein, wohingegen Wissensgraphen präzise, genaue und in einem für Menschen lesbaren Format gespeicherte Antworten zurückgeben würden.
Ein paar andere Strategien, die zusätzlich zu den oben genannten Strategien kombiniert werden könnten, könnten sein
- Verknüpfung mit externen APIs und Suchmaschinen
- Datenmaskierungs- und Compliance-Einhaltungssysteme
- Integration mit internen Datenspeichern und Systemen
- Echtzeit-Vereinheitlichung von Daten aus mehreren Quellen
Schauen wir uns in diesem Blog einen Beispiel-Softwareentwurf an, der zeigt, wie Sie mit Datendiagrammen für Unternehmensanwendungen etwas erreichen können.
Unternehmenswissensgraphen
Ein Wissensgraph kann semantische Informationen verschiedener Entitäten und Beziehungen zwischen ihnen darstellen. In der Unternehmenswelt speichern sie Wissen über Kunden, Produkte und darüber hinaus. Unternehmenskundendiagramme wären ein leistungsstarkes Werkzeug, um Daten effektiv zu begründen und angereicherte Eingabeaufforderungen zu generieren. Wissensgraphen ermöglichen eine graphbasierte Suche, sodass Benutzer Informationen anhand verknüpfter Konzepte und Entitäten erkunden können, was zu präziseren und vielfältigeren Suchergebnissen führen kann.
Vergleich mit Vektordatenbanken
Die Wahl der Erdungslösung wäre anwendungsfallspezifisch. Allerdings bieten Diagramme gegenüber Vektoren mehrere Vorteile
| Eigenschaften | Diagrammerdung | Vektorerdung |
| Analytische Abfragen | Datendiagramme eignen sich für strukturierte Daten und analytische Abfragen und liefern aufgrund ihres abstrakten Diagrammlayouts genaue Ergebnisse. | Vektordatenspeicher funktionieren bei analytischen Abfragen möglicherweise nicht so gut, da sie meist mit unstrukturierten Daten arbeiten, eine semantische Suche mit Vektoreinbettungen durchführen und auf der Ähnlichkeitsbewertung basieren. |
| Genauigkeit und Glaubwürdigkeit | Wissensgraphen verwenden Knoten und Beziehungen zum Speichern von Daten und geben nur die vorhandenen Informationen zurück. Sie vermeiden unvollständige oder irrelevante Ergebnisse. | Vektordatenbanken liefern möglicherweise unvollständige oder irrelevante Ergebnisse, hauptsächlich aufgrund ihrer Abhängigkeit von der Ähnlichkeitsbewertung und vordefinierten Ergebnisgrenzen. |
| Halluzinationen korrigieren | Wissensgraphen sind transparent und bieten eine für Menschen lesbare Darstellung der Daten. Sie helfen dabei, Fehlinformationen zu erkennen und zu korrigieren, den Pfad der Abfrage zurückzuverfolgen und Korrekturen daran vorzunehmen, wodurch die Genauigkeit des LLM (Large Language Model) verbessert wird. | Vektordatenbanken werden oft als Black Boxes angesehen, die nicht in einem lesbaren Format gespeichert sind und möglicherweise keine einfache Identifizierung und Korrektur von Fehlinformationen ermöglichen. |
| Sicherheit und Governance | Knowledge Graphen bieten eine bessere Kontrolle über die Datengenerierung, Governance und Compliance-Einhaltung, einschließlich Vorschriften wie der DSGVO. | Vektordatenbanken können aufgrund ihrer intransparenten Natur vor Herausforderungen bei der Einführung von Beschränkungen und der Verwaltung stehen. |
Hochwertiges Design
Lassen Sie uns auf einer sehr hohen Ebene sehen, wie das System nach einem Unternehmen suchen kann, das Wissensgraphen und offene LLMs als Grundlage verwendet.
In der Basisschicht werden Unternehmenskundendaten und Metadaten in verschiedenen Datenbanken, Data Warehouses und Data Lakes gespeichert. Es kann einen Dienst geben, der aus diesen Daten die Datenwissensdiagramme erstellt und sie in einer Diagrammdatenbank speichert. In einer verteilten Cloud-nativen Welt kann es zahlreiche Unternehmensdienste/Mikrodienste geben, die mit diesen Datenspeichern interagieren würden. Über diesen Diensten könnten verschiedene Anwendungen stehen, die die zugrunde liegende Infrastruktur nutzen würden.
Anwendungen können zahlreiche Anwendungsfälle haben, um KI in ihre Szenarien oder intelligente automatisierte Kundenströme einzubetten, was die Interaktion mit internen und externen KI-Systemen erfordert. Nehmen wir im Fall generativer KI-Szenarien ein einfaches Beispiel für einen Arbeitsablauf, bei dem ein Unternehmen Kunden per E-Mail ansprechen und ihnen während der Feiertage einige Rabatte auf personalisierte empfohlene Produkte anbieten möchte. Dies können sie durch erstklassige Automatisierung erreichen und KI effektiver nutzen.
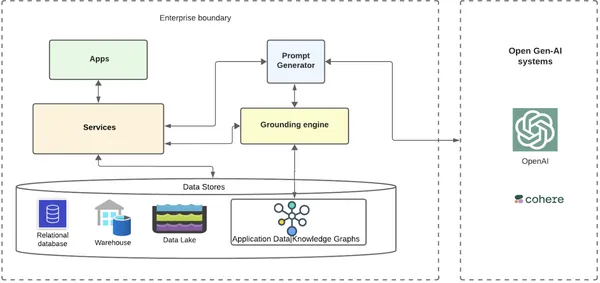
Der Workflow
- Ein Workflow, der eine E-Mail senden möchte, kann die Hilfe offener Gen-KI-Systeme nutzen, indem er eine fundierte Eingabeaufforderung mit kontextualisierten Kundendaten sendet.
- Die Workflow-Anwendung würde eine Anfrage an ihren Backend-Dienst senden, um den E-Mail-Text mithilfe von GenAI-Systemen abzurufen.
- Der Backend-Dienst würde den Dienst an einen Prompt-Generator-Dienst weiterleiten, der wiederum an eine Grounding-Engine weiterleitet.
- Die Grounding-Engine erfasst alle Kundenmetadaten von einem ihrer Dienste und ruft den Kundendaten-Wissensgraphen ab.
- Die Grounding-Engine durchläuft den Graphen über die Knoten und relevanten Beziehungen hinweg, extrahiert die letztendlich benötigten Informationen und sendet sie zurück an den Prompt-Generator.
- Der Eingabeaufforderungsgenerator fügt die fundierten Daten einer bereits vorhandenen Vorlage für den Anwendungsfall hinzu und sendet die fundierte Eingabeaufforderung an die offenen KI-Systeme, in die das Unternehmen eine Integration wählt (z. B. OpenAI/Cohere).
- Offene GenAI-Systeme geben eine viel relevantere und kontextualisiertere Antwort an das Unternehmen zurück, die per E-Mail an den Kunden gesendet wird.
Lassen Sie uns dies in zwei Teile aufteilen und im Detail verstehen:
1. Generieren von Kundenwissensdiagrammen
Das folgende Design passt zum obigen Beispiel. Die Modellierung kann je nach Anforderung auf verschiedene Arten erfolgen.
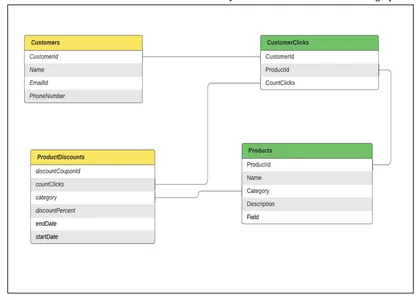
Datenmodellierung: Angenommen, wir haben verschiedene Tabellen, die als Knoten in einem Diagramm modelliert sind, und Verknüpfungen zwischen Tabellen als Beziehungen zwischen Knoten. Für das obige Beispiel benötigen wir
- eine Tabelle, die die Daten des Kunden enthält,
- eine Tabelle, die die Produktdaten enthält,
- eine Tabelle, die die CustomerInterests-Daten (Klicks) für personalisierte Empfehlungen enthält
- eine Tabelle, die die ProductDiscounts-Daten enthält
Es liegt in der Verantwortung des Unternehmens, alle diese Daten aus mehreren Datenquellen zu erfassen und regelmäßig zu aktualisieren, um die Kunden effektiv zu erreichen.
Sehen wir uns an, wie diese Tabellen modelliert und in ein Kundendiagramm umgewandelt werden können.
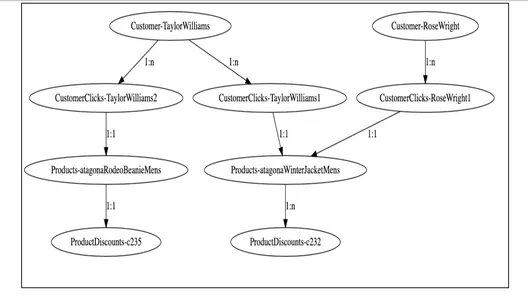
2. Graphenmodellierung
Anhand der obigen Diagrammvisualisierung können wir sehen, wie Kundenknoten basierend auf ihren Klick-Engagement-Daten mit verschiedenen Produkten und weiter mit den Rabattknoten verknüpft sind. Für den Erdungsdienst ist es einfach, diese Kundendiagramme abzufragen, diese Knoten anhand von Beziehungen zu durchlaufen und die erforderlichen Informationen zu den für die jeweiligen Kunden berechtigten Rabatten zu erhalten.
Ein Beispiel für einen Diagrammknoten und Beziehungs-JAVA-POJOs für das Obige könnte ähnlich wie das Folgende aussehen
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Ein Beispiel für ein Rohdiagramm in diesem Szenario könnte wie folgt aussehen
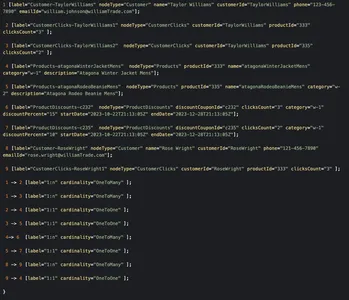
Das Durchlaufen des Diagramms vom Kundenknoten „Taylor Williams“ würde das Problem für uns lösen und die richtigen Produktempfehlungen und berechtigten Rabatte abrufen.
3. Beliebte Graph-Läden in der Industrie
Auf dem Markt sind zahlreiche Graph-Stores verfügbar, die für Unternehmensarchitekturen geeignet sind. Neo4j, TigerGraph, Amazon Neptune und OrientDB werden häufig als Diagrammdatenbanken eingesetzt.
Wir stellen das neue Paradigma von Graph Data Lakes vor, das Diagrammabfragen für Tabellendaten (strukturierte Daten in Seen, Lagerhäusern und Seehäusern) ermöglicht. Dies wird mit den unten aufgeführten neuen Lösungen erreicht, ohne dass Daten in Diagrammdatenspeichern gespeichert oder gespeichert werden müssen, indem Zero-ETL genutzt wird.
- PuppyGraph (Graph Data Lake)
- Timbr.ai
Compliance und ethische Überlegungen
Datenschutz: Unternehmen müssen für die Speicherung und Nutzung von Kundendaten im Einklang mit der DSGVO und anderen PII-Konformitäten verantwortlich sein. Gespeicherte Daten müssen verwaltet und bereinigt werden, bevor sie für Erkenntnisse oder die Anwendung von KI verarbeitet und wiederverwendet werden können.
Halluzinationen und Versöhnung: Unternehmen können auch Abgleichsdienste hinzufügen, die Fehlinformationen in Daten identifizieren, den Pfad der Abfrage zurückverfolgen und Korrekturen daran vornehmen, was zur Verbesserung der LLM-Genauigkeit beitragen kann. Da die gespeicherten Daten transparent und für Menschen lesbar sind, sollte dies mit Wissensgraphen relativ einfach zu erreichen sein.
Restriktive Aufbewahrungsrichtlinien: Um den Datenschutz einzuhalten und den Missbrauch von Kundendaten bei der Interaktion mit offenen LLM-Systemen zu verhindern, ist es sehr wichtig, keine Aufbewahrungsrichtlinien einzuhalten, damit die externen Systeme, mit denen Unternehmen interagieren, die angeforderten Sofortdaten nicht für weitere Analyse- oder Geschäftszwecke speichern.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass Large Language Models (LLMs) einen bemerkenswerten Fortschritt in der künstlichen Intelligenz und der Verarbeitung natürlicher Sprache darstellen. Sie können verschiedene Branchen und Anwendungen verändern, vom Verständnis und der Generierung natürlicher Sprache bis hin zur Unterstützung bei komplexen Aufgaben. Der Erfolg und die verantwortungsvolle Nutzung von LLMs erfordern jedoch ein starkes Fundament und eine solide Grundlage in verschiedenen Schlüsselbereichen.
Key Take Away
- Unternehmen können enorm von einer effektiven Einführung und Anleitung profitieren, wenn sie LLMs für verschiedene Szenarien einsetzen.
- Knowledge Graphs und Vector Stores sind beliebte Grounding-Lösungen, und die Auswahl hängt vom Zweck der Lösung ab.
- Wissensgraphen können im Vergleich zu Vektorspeichern genauere und zuverlässigere Informationen liefern, was einen Vorteil für Unternehmensanwendungsfälle verschafft, ohne dass zusätzliche Sicherheits- und Compliance-Ebenen hinzugefügt werden müssen.
- Verwandeln Sie die traditionelle Datenmodellierung mit Entitäten und Beziehungen in Wissensgraphen mit Knoten und Kanten.
- Integrieren Sie die Enterprise Knowledge Graphs mit verschiedenen Datenquellen in bestehende Big-Data-Speicherunternehmen.
- Wissensgraphen eignen sich ideal für analytische Abfragen. Graph Data Lakes ermöglichen die Abfrage tabellarischer Daten als Diagramme im Unternehmensdatenspeicher.
Häufig gestellte Fragen
A. LLM ist ein KI-Algorithmus, der DL-Techniken und enorm große Datensätze verwendet, um neue Inhalte zu verstehen, zusammenzufassen, zu generieren und vorherzusagen.
A. Ein Anwendungsdatengraph ist eine Datenstruktur, die Daten in Form von Knoten und Kanten speichert. Modellieren Sie sie als Beziehungen zwischen verschiedenen Datenknoten.
A. Eine Vektordatenbank speichert und verwaltet unstrukturierte Daten wie Text, Audio und Video. Es zeichnet sich durch eine schnelle Indizierung und einen schnellen Abruf für Anwendungen wie Empfehlungsmaschinen, maschinelles Lernen und Gen-KI aus.
A. In einem Vektorspeicher sind Einbettungen numerische Darstellungen von Objekten, Wörtern oder Datenpunkten in einem hochdimensionalen Vektorraum. Diese Einbettungen erfassen semantische Beziehungen und Ähnlichkeiten zwischen Elementen und ermöglichen so eine effiziente Datenanalyse, Ähnlichkeitssuche und maschinelle Lernaufgaben.
A. Strukturierte Daten sind gut organisiert mit definierten Tabellen und Schemata. Unstrukturierte Daten wie Text, Bilder, Audio oder Video sind aufgrund ihres fehlenden Formats schwieriger zu analysieren.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/
- :hast
- :Ist
- :nicht
- :Wo
- $UP
- 11
- 12
- 13
- 15%
- 19
- 22
- 49
- 500
- 52
- 53
- 750
- 8
- 9
- a
- Fähigkeit
- Über uns
- oben
- ABSTRACT
- Nach
- Genauigkeit
- genau
- Erreichen
- erreicht
- über
- hinzufügen
- Hinzufügen
- Zusätzliche
- Adresse
- Fügt
- haften
- Einhaltung
- haften
- angenommen
- advanced
- Förderung
- Vorteil
- Vorteilen
- Beratung
- AI
- KI-Systeme
- Auch bekannt als:
- Algorithmus
- Richtet sich aus
- Alle
- Zulassen
- bereits
- ebenfalls
- erstaunlich
- Amazon
- Amazon Neptun
- unter
- Beträge
- an
- Analyse
- Analytische
- Analytik
- Analytics-Vidhya
- analysieren
- und
- jedem
- APIs
- Anwendung
- Anwendungen
- Jetzt bewerben
- Anwendung
- angemessen
- SIND
- Bereiche
- um
- Artikel
- künstlich
- künstliche Intelligenz
- AS
- helfen
- Unterstützung
- damit verbundenen
- annehmen
- At
- Aufmerksamkeit
- Audio-
- Augmented
- Automatisiert
- automatisieren
- Automation
- verfügbar
- vermeiden
- Zurück
- Backend
- Base
- basierend
- BE
- Bevor
- unten
- vorteilhaft
- Nutzen
- Vorteile
- Besser
- zwischen
- Beyond
- voreingenommen
- Vorurteile
- Big
- Big Data
- große Datenspeicherung
- Milliarden
- Schwarz
- Blog
- beide
- Boxen
- Break
- Durchbruch
- Brücken
- bauen
- Vertrauen aufbauen
- Building
- Geschäft
- aber
- by
- CAN
- fähig
- Erfassung
- Häuser
- Fälle
- Kategorie
- challenges
- Herausforderungen
- herausfordernd
- Chatbot
- ChatGPT
- Auswahl
- Clarity
- Klasse
- Kunden
- Cloud
- Wolke native
- COM
- Bekämpfung
- Kombination
- wie die
- Kommunikation
- Komplex
- Compliance
- rechnerisch
- konzept
- Konzepte
- Hautpflegeprobleme
- Abschluss
- Verbindung
- Nachteile
- Berücksichtigung
- konsistent
- Inhalt
- Inhaltserstellung
- Kontext
- Kontrast
- Smartgeräte App
- Gespräch
- und beseitigen Muskelschwäche
- Korrekturen
- könnte
- erstellen
- Schaffung
- Kreativität
- Kommunikation
- kritischem
- wichtig
- schwerfällig
- Kunde
- Kundendaten
- Kundensupport
- Kunden
- technische Daten
- Datenanalyse
- Datensee
- Datenpunkte
- Datenschutz
- Datenschutz und Sicherheit
- Datenschutz
- Datensicherheit
- Datensätze
- Datenspeichervorrichtung
- Data Warehouse
- Datenbase
- Datenbanken
- datetime
- Entscheidung
- Decision Making
- Entscheidungen
- tief
- tiefe Lernen
- Deepfakes
- definiert
- Definition
- Übergeben
- hängt
- Einsatz
- Beschreibung
- Design
- Detail
- entwickeln
- entwickelt
- Entwicklung
- Diagnose
- Unterschied
- anders
- exklusive Rabatte
- Diskretion
- verteilt
- verschieden
- do
- Domains
- erledigt
- Nachteile
- Antrieb
- zwei
- im
- e
- Einfache
- Edge
- Effektiv
- effektiv
- effizient
- Bemühungen
- förderfähigen
- einbetten
- Einbettung
- ermöglichen
- ermöglicht
- ermöglichen
- Engagement
- Motor
- Motor (en)
- zu steigern,
- verbesserte
- Verbessert
- Eine Verbesserung der
- enorm
- angereichert
- bereichernd
- sorgt
- Gewährleistung
- Unternehmen
- Unternehmen
- Entitäten
- Era
- insbesondere
- etablieren
- Äther (ETH)
- ethisch
- genau
- Beispiel
- vorhandenen
- teuer
- Erfahrungen
- Exploited
- ERKUNDEN
- extern
- KONZENTRAT
- Gesicht
- erleichtern
- Fälschung
- gefälschte Nachrichten
- falsch
- wenige
- Finale
- Revolution
- Fließt
- Setzen Sie mit Achtsamkeit
- Aussichten für
- unten stehende Formular
- Format
- Förderung
- Foundation
- Gerüste
- betrügerisch
- für
- fundamental
- weiter
- gewonnen
- Lücke
- DSGVO
- Jan
- erzeugen
- erzeugt
- Erzeugung
- Generation
- generativ
- Generative KI
- Generator
- gibt
- Governance
- geregelt
- GPUs
- Grabs
- Graph
- Graphen
- Boden
- Wachstum
- Richtlinien
- glücklich
- Schwerer
- Hardware
- schaden
- schädlich
- Haben
- mit
- Hilfe
- hilfreich
- hilft
- daher
- hier
- GUTE
- High-Level
- hoch
- ihm
- hält
- Urlaub
- Ultraschall
- aber
- HTML
- HTTPS
- riesig
- Riesig
- human
- für Menschen lesbar
- Humans
- ideal
- Login
- identifizieren
- Bilder
- immens
- Impact der HXNUMXO Observatorien
- Umsetzung
- implementiert
- Bedeutung
- wichtig
- imposant
- zu unterstützen,
- Verbesserung
- in
- ungenau
- das
- Einschließlich
- Einzelpersonen
- Branchen
- Energiegewinnung
- beeinflussen
- Information
- inhärent
- initiieren
- Varianten des Eingangssignals:
- Einblicke
- integrieren
- Integration
- Intelligenz
- Intelligent
- interagieren
- Interaktion
- Interaktion
- Schnittstelle
- intern
- Intervention
- in
- einführen
- Probleme
- IT
- Artikel
- SEINE
- Javac
- join
- jpg
- Wesentliche
- Hauptbereiche
- Wissen
- Mangel
- See
- Seen
- Sprache
- grosse
- Schicht
- Lagen
- Layout
- führen
- führenden
- lernen
- Rechtlich
- Niveau
- Hebelwirkung
- gehebelt
- Nutzung
- Gefällt mir
- Grenzen
- verknüpft
- Gelistet
- aussehen
- aussehen wie
- Maschine
- Maschinelles Lernen
- Main
- hauptsächlich
- halten
- Dur
- um
- MACHT
- Making
- Managed
- manuell
- manuell
- viele
- Markt
- Marketing
- massiv
- massiv
- max-width
- Kann..
- Mittel
- Medien
- sowie medizinische
- Treffen
- Nachricht
- Metadaten
- Millionen
- Fehlinformationen
- irreführend
- Missbrauch
- Mildern
- Milderung
- Modell
- Modellieren
- für
- mehr
- meist
- viel
- mehrere
- sollen
- Name
- nativen
- Natürliche
- Natürliche Sprache
- Verarbeitung natürlicher Sprache
- Natürliches Verständnis der Sprache
- Natur
- Need
- Bedürfnisse
- Neptun
- Netzwerk
- Neural
- neuronale Netzwerk
- Neu
- neue Lösungen
- News
- Knoten
- Fiber Node
- beachten
- Anzahl
- und viele
- Objekte
- erhalten
- of
- WOW!
- bieten
- bieten
- vorgenommen,
- on
- EINEM
- laufend
- einzige
- XNUMXh geöffnet
- OpenAI
- betreiben
- or
- Andere
- UNSERE
- übrig
- Überwindung
- Besitz
- Paradigma
- Parameter
- Teil
- Teile
- Weg
- Muster
- ausführen
- Durchführung
- Personalisiert
- Telefon
- pii
- Planung
- Plato
- Datenintelligenz von Plato
- PlatoData
- Punkte
- Politik durchzulesen
- Beliebt
- Potenzial
- größte treibende
- präzise
- vorhersagen
- Gegenwart
- verhindern
- Preis
- primär
- Datenschutz
- Datenschutz und Sicherheit
- privat
- Aufgabenstellung:
- Prozessdefinierung
- Verarbeitung
- produziert
- Produkt
- Produkte
- Sicherheit
- die
- vorausgesetzt
- Bereitstellung
- Öffentlichkeit
- veröffentlicht
- Zweck
- Zwecke
- Qualität
- Abfragen
- Fragen
- Direkt
- ganz
- wirft
- Angebot
- schnell
- lieber
- Roh
- Rohdaten
- erreichen
- Lesen Sie mehr
- realen Welt
- erhalten
- Software Empfehlungen
- Empfehlungen
- empfohlen
- Versöhnung
- Veteran
- Reduzierung
- bezieht sich
- reflektieren
- regelmäßig
- Vorschriften
- Regulierungsbehörden
- verstärken
- bezogene
- Beziehung
- Beziehungen
- verhältnismäßig
- Relevanz
- relevant
- Zuverlässigkeit
- zuverlässig
- Vertrauen
- verlassen
- bemerkenswert
- Meldungen
- vertreten
- Darstellung
- Anforderung
- angefordert
- erfordern
- falls angefordert
- Anforderung
- Voraussetzungen:
- erfordert
- Forschungsprojekte
- Downloads
- diejenigen
- Antwort
- Antworten
- Verantwortung
- für ihren Verlust verantwortlich.
- Einschränkungen
- Folge
- Die Ergebnisse
- Beibehaltung
- Rückkehr
- Rückkehr
- Recht
- Risiko
- Risiken
- Rollen
- Straße
- Routen
- Laufen
- gleich
- Zufriedenheit
- Skalieren
- Szenario
- Szenarien
- Wissenschaft
- Umfang
- Wertung
- Suche
- Suchbegriffe
- Jahreszeit
- Sicherheitdienst
- sehen
- gesehen
- senden
- Sendung
- sendet
- geschickt
- Dienstleistungen
- Sets
- mehrere
- Teilen
- Short
- sollte
- gezeigt
- Konzerte
- signifikant
- bedeutend
- ähnlich
- Ähnlichkeiten
- Einfacher
- da
- So
- Gesellschaft
- Software
- Lösung
- Lösungen
- LÖSEN
- einige
- anspruchsvoll
- Quellen
- Raumfahrt
- spezialisiert
- spezifisch
- Verbreitung
- Stakeholder
- Normen
- Lagerung
- speichern
- gelagert
- Läden
- Strategisch
- Strategien
- Rationalisierung
- Schnur
- stark
- Struktur
- strukturierte
- strukturierte und unstrukturierte Daten
- Fach
- Erfolg
- so
- Anzug
- geeignet
- zusammenfassen
- Support
- synthetisch
- synthetische Daten
- System
- Systeme und Techniken
- Tabelle
- zugeschnitten
- Nehmen
- Target
- und Aufgaben
- Taylor
- Team
- Techniken
- Technologie
- Vorlage
- Begriff
- Text
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- Der Graph
- die Informationen
- ihr
- Sie
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- diejenigen
- Entwickeln Sie
- Durch
- zu
- heute
- Werkzeug
- Top
- Spur
- traditionell
- trainiert
- Ausbildung
- Transformieren
- Transformativ
- verwandelt
- transparent
- Traverse
- wirklich
- Vertrauen
- XNUMX
- letzte
- zugrunde liegen,
- verstehen
- Verständnis
- Aktualisierung
- aktualisiert
- us
- -
- Anwendungsfall
- benutzt
- nützliche Informationen
- Mitglied
- Nutzer
- verwendet
- Verwendung von
- gewöhnlich
- validiert
- Wert
- Vielfalt
- verschiedene
- verified
- vielseitig
- sehr
- Video
- wollen
- will
- wurde
- Weg..
- Wege
- we
- webp
- GUT
- Was
- Was ist
- wann
- während
- welche
- während
- breit
- weit
- werden wir
- Winter
- mit
- ohne
- Worte
- Arbeitsablauf.
- Workflows
- weltweit wie ausgehandelt und gekauft ausgeführt wird.
- würde
- geschrieben
- U
- Ihr
- Zephyrnet
- Null