Bild von Freepik
Konversations-KI bezieht sich auf virtuelle Agenten und Chatbots, die menschliche Interaktionen nachahmen und Menschen in Gespräche einbeziehen können. Der Einsatz von Konversations-KI wird schnell zu einer Lebensart – von der Bitte um Alexa bis hin zu „Finden Sie das nächstgelegene Restaurant“ Siri zu bitten, „Erstellen Sie eine Erinnerung“, Virtuelle Assistenten und Chatbots werden häufig verwendet, um Verbraucherfragen zu beantworten, Beschwerden zu lösen, Reservierungen vorzunehmen und vieles mehr.
Die Entwicklung dieser virtuellen Assistenten erfordert einen erheblichen Aufwand. Allerdings kann das Verständnis und die Bewältigung der wichtigsten Herausforderungen den Entwicklungsprozess rationalisieren. Ich habe meine Erfahrungen aus erster Hand bei der Erstellung eines ausgereiften Chatbots für eine Rekrutierungsplattform als Bezugspunkt genutzt, um die wichtigsten Herausforderungen und die entsprechenden Lösungen zu erläutern.
Um einen Konversations-KI-Chatbot zu erstellen, können Entwickler Frameworks wie RASA, Amazons Lex oder Googles Dialogflow verwenden, um Chatbots zu erstellen. Die meisten bevorzugen RASA, wenn sie benutzerdefinierte Änderungen planen oder der Bot sich im ausgereiften Stadium befindet, da es sich um ein Open-Source-Framework handelt. Auch andere Frameworks eignen sich als Ausgangspunkt.
Die Herausforderungen lassen sich in drei Hauptkomponenten eines Chatbots einteilen.
Natürliches Sprachverständnis (NLU) ist die Fähigkeit eines Bots, menschliche Dialoge zu verstehen. Es führt eine Absichtsklassifizierung, Entitätsextraktion und das Abrufen von Antworten durch.
Dialogmanager ist dafür verantwortlich, dass eine Reihe von Aktionen basierend auf den aktuellen und vorherigen Benutzereingaben ausgeführt werden. Es nimmt Absichten und Entitäten als Eingabe (als Teil der vorherigen Konversation) und identifiziert die nächste Antwort.
Erzeugung natürlicher Sprache (NLG) ist der Prozess der Generierung geschriebener oder gesprochener Sätze aus gegebenen Daten. Es rahmt die Antwort ein, die dann dem Benutzer präsentiert wird.
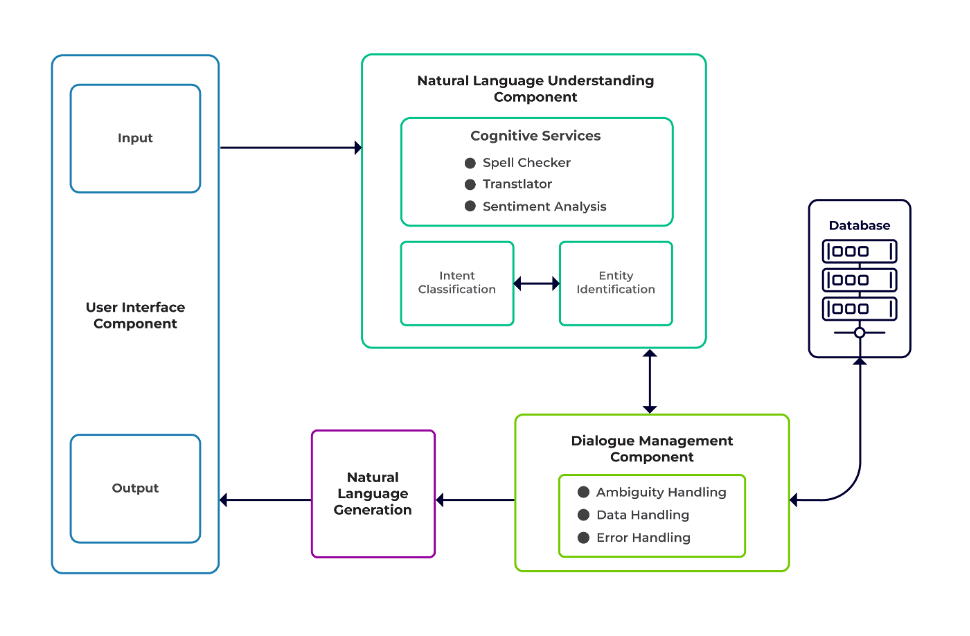
Bild von Talentica Software
Unzureichende Daten
Wenn Entwickler FAQs oder andere Supportsysteme durch einen Chatbot ersetzen, erhalten sie eine ansehnliche Menge an Trainingsdaten. Das Gleiche passiert jedoch nicht, wenn sie den Bot von Grund auf neu erstellen. In solchen Fällen generieren Entwickler Trainingsdaten synthetisch.
Was ist zu tun?
Ein vorlagenbasierter Datengenerator kann eine beträchtliche Anzahl von Benutzeranfragen für das Training generieren. Sobald der Chatbot fertig ist, können Projektinhaber ihn einer begrenzten Anzahl von Benutzern zugänglich machen, um Trainingsdaten zu verbessern und sie über einen bestimmten Zeitraum hinweg zu aktualisieren.
Unpassende Modellauswahl
Die richtige Modellauswahl und Trainingsdaten sind entscheidend, um die besten Ergebnisse bei der Absichts- und Entitätsextraktion zu erzielen. Entwickler trainieren Chatbots normalerweise in einer bestimmten Sprache und Domäne, und die meisten der verfügbaren vorab trainierten Modelle sind oft domänenspezifisch und in einer einzigen Sprache trainiert.
Es kann auch Fälle von gemischten Sprachen geben, bei denen Menschen mehrsprachig sind. Möglicherweise geben sie Abfragen in einer gemischten Sprache ein. In einer französisch dominierten Region verwenden die Menschen beispielsweise möglicherweise eine Art Englisch, das eine Mischung aus Französisch und Englisch ist.
Was ist zu tun?
Die Verwendung von Modellen, die in mehreren Sprachen trainiert wurden, könnte das Problem verringern. In solchen Fällen kann ein vorab trainiertes Modell wie LaBSE (Sprachagnostische Bert-Satzeinbettung) hilfreich sein. LaBSE wird in mehr als 109 Sprachen auf eine Satzähnlichkeitsaufgabe trainiert. Das Modell kennt bereits ähnliche Wörter in einer anderen Sprache. In unserem Projekt hat es wirklich gut funktioniert.
Unsachgemäße Entitätsextraktion
Chatbots erfordern, dass Entitäten identifizieren, welche Art von Daten der Benutzer sucht. Zu diesen Entitäten gehören Zeit, Ort, Person, Gegenstand, Datum usw. Es kann jedoch sein, dass Bots eine Entität anhand der natürlichen Sprache nicht identifizieren können:
Gleicher Kontext, aber unterschiedliche Entitäten. Bots können beispielsweise einen Ort als Ganzes verwechseln, wenn ein Benutzer „Name der Studenten vom IIT Delhi“ und dann „Name der Studenten aus Bengaluru“ eingibt.
Szenarien, in denen die Entitäten mit geringer Konfidenz falsch vorhergesagt werden. Beispielsweise kann ein Bot IIT Delhi als eine Stadt mit geringem Vertrauen identifizieren.
Teilweise Entitätsextraktion durch maschinelles Lernmodell. Wenn ein Benutzer „Studenten vom IIT Delhi“ eingibt, kann das Modell „IIT“ nur als Entität anstelle von „IIT Delhi“ identifizieren.
Einzelworteingaben ohne Kontext können die Modelle des maschinellen Lernens verwirren. Beispielsweise kann ein Wort wie „Rishikesh“ sowohl den Namen einer Person als auch einer Stadt bedeuten.
Was ist zu tun?
Das Hinzufügen weiterer Trainingsbeispiele könnte eine Lösung sein. Aber es gibt eine Grenze, ab der es nicht mehr hilft, weitere hinzuzufügen. Darüber hinaus ist es ein endloser Prozess. Eine andere Lösung könnte darin bestehen, Regex-Muster mithilfe vordefinierter Wörter zu definieren, um Entitäten mit einem bekannten Satz möglicher Werte wie Stadt, Land usw. zu extrahieren.
Modelle weisen ein geringeres Vertrauen auf, wenn sie sich über die Entitätsvorhersage nicht sicher sind. Entwickler können dies als Auslöser verwenden, um eine benutzerdefinierte Komponente aufzurufen, die die geringe Vertrauenswürdigkeit der Entität beheben kann. Betrachten wir das obige Beispiel. Wenn IIT Delhi als eine Stadt mit geringer Konfidenz vorhergesagt wird, kann der Benutzer jederzeit in der Datenbank danach suchen. Nachdem die vorhergesagte Entität nicht gefunden wurde Stadt In der Tabelle würde das Modell zu anderen Tabellen weitergehen und sie schließlich in der finden Institut Tabelle, was zu einer Entitätskorrektur führt.
Falsche Absichtsklassifizierung
Mit jeder Benutzernachricht ist eine bestimmte Absicht verbunden. Da Absichten die nächste Vorgehensweise eines Bots ableiten, ist die korrekte Klassifizierung von Benutzeranfragen mit Absicht von entscheidender Bedeutung. Allerdings müssen Entwickler Absichten mit minimaler Verwirrung zwischen den Absichten identifizieren. Andernfalls kann es zu Fällen kommen, in denen Verwirrung herrscht. Zum Beispiel, "Zeigen Sie mir offene Stellen“ gegen „Zeigen Sie mir offene Stellenkandidaten.“
Was ist zu tun?
Es gibt zwei Möglichkeiten, verwirrende Abfragen zu unterscheiden. Erstens kann ein Entwickler eine Unterabsicht einführen. Zweitens können Modelle Abfragen basierend auf identifizierten Entitäten verarbeiten.
Ein domänenspezifischer Chatbot sollte ein geschlossenes System sein, in dem klar erkennbar ist, wozu er fähig ist und was nicht. Entwickler müssen die Entwicklung in Phasen durchführen und gleichzeitig domänenspezifische Chatbots planen. In jeder Phase können sie die nicht unterstützten Funktionen des Chatbots identifizieren (über eine nicht unterstützte Absicht).
Sie können auch erkennen, was der Chatbot in der Absicht „außerhalb des Geltungsbereichs“ nicht verarbeiten kann. Es könnte jedoch Fälle geben, in denen der Bot hinsichtlich der nicht unterstützten und außerhalb des Geltungsbereichs liegenden Absicht verwirrt ist. Für solche Szenarien sollte ein Fallback-Mechanismus vorhanden sein, mit dem das Modell problemlos mit einem Fallback-Intent arbeiten kann, um Verwirrungsfälle zu behandeln, wenn die Absichtskonfidenz unter einem Schwellenwert liegt.
Sobald der Bot die Absicht der Nachricht eines Benutzers identifiziert, muss er eine Antwort zurücksenden. Der Bot entscheidet über die Reaktion auf der Grundlage eines bestimmten Satzes definierter Regeln und Geschichten. Beispielsweise kann eine Regel so einfach wie völlig sein "guten Morgen" wenn der Benutzer grüßt "Hallo". In den meisten Fällen handelt es sich bei Gesprächen mit Chatbots jedoch um Folgeinteraktionen, deren Antworten vom Gesamtkontext des Gesprächs abhängen.
Was ist zu tun?
Um dies zu bewältigen, werden Chatbots mit echten Gesprächsbeispielen, sogenannten Stories, gefüttert. Allerdings interagieren Benutzer nicht immer wie beabsichtigt. Ein ausgereifter Chatbot sollte mit allen derartigen Abweichungen elegant umgehen. Designer und Entwickler können dies gewährleisten, wenn sie sich beim Schreiben von Geschichten nicht nur auf einen glücklichen Weg konzentrieren, sondern auch an unglücklichen Pfaden arbeiten.
Die Interaktion der Benutzer mit Chatbots hängt stark von den Chatbot-Antworten ab. Benutzer könnten das Interesse verlieren, wenn die Antworten zu roboterhaft oder zu vertraut sind. Beispielsweise könnte einem Benutzer eine Antwort wie „Sie haben eine falsche Abfrage eingegeben“ auf eine falsche Eingabe nicht gefallen, obwohl die Antwort korrekt ist. Die Antwort hier passt nicht zur Persona eines Assistenten.
Was ist zu tun?
Der Chatbot fungiert als Assistent und sollte über eine bestimmte Persönlichkeit und einen bestimmten Tonfall verfügen. Sie sollten einladend und bescheiden sein, und Entwickler sollten Gespräche und Äußerungen entsprechend gestalten. Die Antworten sollten nicht roboterhaft oder mechanisch klingen. Der Bot könnte zum Beispiel sagen: „Tut mir leid, es scheint, als hätte ich keine Details. Könnten Sie bitte Ihre Anfrage noch einmal eingeben?“ um eine falsche Eingabe anzusprechen.
Auf LLM (Large Language Model) basierende Chatbots wie ChatGPT und Bard sind bahnbrechende Innovationen und haben die Fähigkeiten von Konversations-KIs verbessert. Sie sind nicht nur gut darin, offene, menschenähnliche Gespräche zu führen, sondern können auch verschiedene Aufgaben wie Textzusammenfassung, Absätze schreiben usw. ausführen, die früher nur von bestimmten Modellen erfüllt werden konnten.
Eine der Herausforderungen bei herkömmlichen Chatbot-Systemen besteht darin, jeden Satz in Absichten zu kategorisieren und die Reaktion entsprechend zu entscheiden. Dieser Ansatz ist nicht praktikabel. Antworten wie „Tut mir leid, ich konnte Sie nicht erreichen“ sind oft irritierend. Intentless Chatbot-Systeme sind der Weg in die Zukunft, und LLMs können dies Wirklichkeit werden lassen.
LLMs können problemlos hochmoderne Ergebnisse bei der allgemeinen Erkennung benannter Entitäten erzielen, mit Ausnahme bestimmter domänenspezifischer Entitätserkennungen. Ein gemischter Ansatz zur Verwendung von LLMs mit jedem Chatbot-Framework kann zu einem ausgereifteren und robusteren Chatbot-System führen.
Dank der neuesten Fortschritte und kontinuierlicher Forschung im Bereich der Konversations-KI werden Chatbots von Tag zu Tag besser. Bereiche wie die Bearbeitung komplexer Aufgaben mit mehreren Absichten, wie zum Beispiel „Buchen Sie einen Flug nach Mumbai und organisieren Sie ein Taxi nach Dadar“, erhalten große Aufmerksamkeit.
Bald werden personalisierte Gespräche basierend auf den Merkmalen des Benutzers stattfinden, um den Benutzer zu motivieren. Wenn ein Bot beispielsweise feststellt, dass der Benutzer unzufrieden ist, leitet er die Konversation an einen echten Agenten weiter. Darüber hinaus können Deep-Learning-Techniken wie ChatGPT bei ständig wachsenden Chatbot-Daten mithilfe einer Wissensdatenbank automatisch Antworten auf Anfragen generieren.
Suman Saurav ist Data Scientist bei Talentica Software, einem Unternehmen für die Entwicklung von Softwareprodukten. Er ist Absolvent des NIT Agartala und verfügt über mehr als 8 Jahre Erfahrung in der Entwicklung und Implementierung revolutionärer KI-Lösungen unter Verwendung von NLP, Konversations-KI und generativer KI.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :hast
- :Ist
- :nicht
- :Wo
- 8
- a
- Fähigkeit
- Über Uns
- oben
- entsprechend
- Erreichen
- erreicht
- über
- Aktionen
- Hinzufügen
- zusätzlich
- Adresse
- Adressierung
- Fortschritte
- Nach der
- Makler
- Agenten
- AI
- AI Chatbot
- Alexa
- Alle
- bereits
- ebenfalls
- Alumnus
- immer
- Betrag
- an
- und
- Ein anderer
- beantworten
- jedem
- Ansatz
- SIND
- Bereiche
- AS
- fragen
- Assistentin
- Assistenten
- damit verbundenen
- At
- Aufmerksamkeit
- Im Prinzip so, wie Sie es von Google Maps kennen.
- verfügbar
- vermeiden
- Zurück
- Base
- basierend
- BE
- Werden
- Wesen
- unten
- BESTE
- Besser
- Wander- und Outdoorschuhen
- beide
- Bots
- bauen
- aber
- by
- rufen Sie uns an!
- namens
- CAN
- kann keine
- Fähigkeiten
- fähig
- Fälle
- Kategorisieren
- sicher
- Herausforderungen
- Änderungen
- Charakteristik
- Chatbot
- Chatbots
- ChatGPT
- Stadt
- Einstufung
- eingestuft
- geschlossen
- Unternehmen
- Beschwerden
- Komplex
- Komponente
- Komponenten
- begreifen
- Vertrauen
- verwirrt
- verwirrend
- Verwirrung
- Geht davon
- Kontext
- kontinuierlich
- Gespräch
- Konversations
- Konversations-KI
- Gespräche
- und beseitigen Muskelschwäche
- korrekt
- Dazugehörigen
- könnte
- Land
- Kurs
- erstellen
- Erstellen
- wichtig
- Strom
- Original
- technische Daten
- Datenwissenschaftler
- Datenbase
- Datum
- Tag
- anständig
- Entscheiden
- tief
- tiefe Lernen
- definieren
- definiert
- Delhi
- abhängen
- ableiten
- Design
- Designer
- Entwerfen
- Details
- Entwickler:in / Unternehmen
- Entwickler
- Entwicklung
- Dialogfluss
- Dialog
- anders
- unterscheiden
- do
- Tut nicht
- Domain
- Nicht
- jeder
- Früher
- leicht
- Anstrengung
- Einbettung
- Endlos
- engagieren
- beschäftigt
- Engagement
- Englisch
- zu steigern,
- Enter
- Entitäten
- Einheit
- etc
- Sogar
- schließlich
- immer größer
- Jedes
- jeden Tag
- Beispiel
- Beispiele
- ERFAHRUNGEN
- Erklären
- Extrakt
- Extraktion
- FAIL
- andernfalls
- vertraut
- FAST
- Eigenschaften
- Fed
- Finden Sie
- findet
- Flugkosten
- Setzen Sie mit Achtsamkeit
- Aussichten für
- vorwärts
- Unser Ansatz
- Gerüste
- Französisch
- für
- Allgemeines
- erzeugen
- Erzeugung
- Generation
- generativ
- Generative KI
- Generator
- bekommen
- bekommen
- gegeben
- gut
- Garantie
- Griff
- Handling
- passieren
- glücklich
- Haben
- mit
- he
- schwer
- Hilfe
- hilfreich
- hier
- Ultraschall
- Hilfe
- aber
- HTTPS
- human
- demütig
- i
- identifiziert
- identifiziert
- identifizieren
- if
- Umsetzung
- verbessert
- in
- das
- Innovationen
- Varianten des Eingangssignals:
- Eingänge
- inspirieren
- Instanz
- beantragen müssen
- beabsichtigt
- Absicht
- interagieren
- Interaktion
- Interaktionen
- Interesse
- in
- einführen
- IT
- jpg
- nur
- KDnuggets
- Behalten
- Wesentliche
- Art
- Wissen
- bekannt
- kennt
- Sprache
- Sprachen
- grosse
- neueste
- lernen
- Lebensdauer
- Gefällt mir
- LIMIT
- Limitiert
- verlieren
- Sneaker
- senken
- Maschine
- Maschinelles Lernen
- Dur
- um
- Making
- Spiel
- reifen
- Kann..
- me
- bedeuten
- mechanisch
- Mechanismus
- Nachricht
- könnte
- minimal
- mischen
- gemischt
- Modell
- für
- mehr
- Zudem zeigt
- vor allem warme
- viel
- mehrere
- Mumbai
- sollen
- my
- Name
- Namens
- Natürliche
- Natürliche Sprache
- weiter
- NLG
- Nlp
- nlu
- nicht
- Anzahl
- of
- vorgenommen,
- on
- einmal
- einzige
- XNUMXh geöffnet
- Open-Source-
- or
- Andere
- Andernfalls
- UNSERE
- übrig
- Gesamt-
- Besitzer
- Teil
- Weg
- Pfade
- Muster
- Personen
- ausführen
- durchgeführt
- führt
- Zeit
- person
- Personalisiert
- Phase
- Phasen
- Ort
- Plan
- Planung
- Plattform
- Plato
- Datenintelligenz von Plato
- PlatoData
- Bitte
- Points
- Position
- besitzen
- möglich
- Praktisch
- vorhergesagt
- Prognose
- bevorzugen
- vorgeführt
- früher
- Aufgabenstellung:
- vorgehen
- Prozessdefinierung
- Produkt
- Produktentwicklung
- Projekt
- Abfragen
- Fragen
- R
- rasa
- bereit
- echt
- Realität
- wirklich
- Anerkennung
- Rekrutierung
- Veteran
- Referenz
- bezieht sich
- Region
- verlassen
- Erinnerung
- ersetzen
- erfordern
- erfordert
- Forschungsprojekte
- lösen
- Antwort
- Antworten
- für ihren Verlust verantwortlich.
- was zu
- Die Ergebnisse
- Revolutionär
- robust
- Regel
- Ohne eine erfahrene Medienplanung zur Festlegung von Regeln und Strategien beschleunigt der programmatische Medieneinkauf einfach die Rate der verschwenderischen Ausgaben.
- gleich
- Szenarien
- Wissenschaftler
- kratzen
- Suche
- Suche
- scheint
- Auswahl
- senden
- Satz
- dient
- kompensieren
- Teilen
- sollte
- ähnlich
- Einfacher
- da
- Single
- Krabbe
- Software
- Lösung
- Lösungen
- einige
- Klingen
- spezifisch
- gesprochen
- Stufe
- Beginnen Sie
- State-of-the-art
- Geschichten
- rationalisieren
- Die Kursteilnehmer
- wesentlich
- so
- geeignet
- Support
- Unterstützungssysteme
- sicher
- synthetisch
- System
- Systeme und Techniken
- T
- Tabelle
- Nehmen
- nimmt
- Aufgabe
- und Aufgaben
- Techniken
- Text
- als
- zur Verbesserung der Gesundheitsgerechtigkeit
- Das
- ihr
- Sie
- dann
- Dort.
- Diese
- vom Nutzer definierten
- fehlen uns die Worte.
- obwohl?
- nach drei
- Schwelle
- Zeit
- zu
- TONE
- Tonfall
- auch
- traditionell
- Training
- trainiert
- Ausbildung
- auslösen
- XNUMX
- tippe
- Typen
- Verständnis
- mehr Stunden
- -
- benutzt
- Mitglied
- Nutzer
- Verwendung von
- gewöhnlich
- Werte
- Assistent
- Stimme
- vs
- W
- Weg..
- Wege
- Begrüßung
- GUT
- Was
- wann
- sobald
- welche
- während
- werden wir
- mit
- Word
- Worte
- Arbeiten
- gearbeitet
- würde
- Schreiben
- geschrieben
- Falsch
- Jahr
- U
- Ihr
- Zephyrnet