Dette er et gæsteindlæg skrevet sammen med Raghu Boppanna fra Vanguard.
At Vanguard, Enterprise Advice-branchen forbedrer investorresultater gennem digital adgang til overlegen, personlig og økonomisk overkommelig rådgivning. De gjorde det muligt, delvist ved at skabe stordriftsfordele over hele kloden for investorer med en yderst robust og effektiv teknisk platform. Vanguard valgte en multi-regionsarkitektur til denne arbejdsbyrde for at hjælpe med at beskytte mod svækkelser af regionale tjenester. Af hensyn til høj tilgængelighed er der behov for at gøre de data, der bruges af arbejdsbyrden, tilgængelige ikke kun i den primære region, men også i den sekundære region med minimalt replikeringsforsinkelse. I tilfælde af en serviceforringelse i den primære region, bør løsningen kunne svigte over til den sekundære region med så lidt datatab som muligt og mulighed for at genoptage dataindtagelse.
Vanguard Cloud Technology Office og AWS gik sammen om at bygge en infrastrukturløsning på AWS, der opfyldte deres modstandsdygtighedskrav. Multi-Region-løsningen muliggør en robust fail-over-mekanisme med indbygget observerbarhed og gendannelse. Løsningen understøtter også streaming af data fra flere kilder til forskellige Kinesis-datastrømme. Løsningen er i øjeblikket ved at blive udrullet til de forskellige brancher af forretningsteams for at forbedre modstandsdygtigheden i deres arbejdsbelastninger.
Den use case, der diskuteres her, kræver Change Data Capture (CDC) for at streame data fra en fjerndatakilde (mainframe DB2) til Amazon Kinesis datastrømme, fordi forretningskapaciteten afhænger af disse data. Kinesis Data Streams er en fuldt administreret, massivt skalerbar, holdbar og lavpris streamingtjeneste, der kontinuerligt kan fange og streame store mængder data fra flere kilder og gør dataene tilgængelige til forbrug inden for millisekunder. Tjenesten er bygget til at være yderst robust og bruger flere tilgængelighedszoner til at behandle og gemme data.
Løsningen diskuteret i dette indlæg forklarer, hvordan AWS og Vanguard innoverede for at bygge en modstandsdygtig arkitektur for at opfylde deres høje tilgængelighedsmål.
Løsningsoversigt
Løsningen bruger AWS Lambda at replikere data fra Kinesis datastrømme i den primære region til en sekundær region. I tilfælde af en serviceforringelse, der påvirker CDC-pipelinen, fremmer failover-processen den sekundære region til primær for producenter og forbrugere. Vi bruger Amazon DynamoDB globale tabeller for replikeringskontrolpunkter, der gør det muligt at genoptage datastreaming fra kontrolpunktet og også opretholder et primært områdekonfigurationsflag, der forhindrer en uendelig replikeringsløkke af de samme data frem og tilbage.
Løsningen giver også fleksibilitet for Kinesis Data Streams-forbrugere til at bruge den primære eller en hvilken som helst sekundær region inden for den samme AWS-konto.
Følgende diagram illustrerer referencearkitekturen.
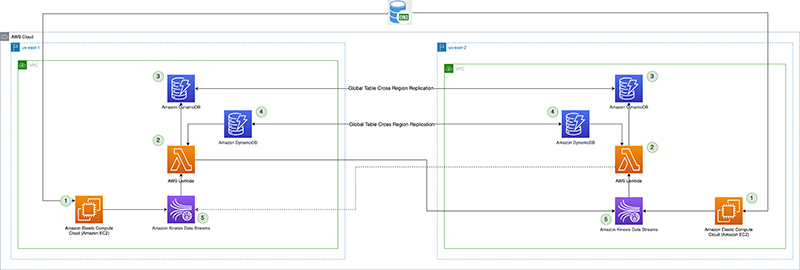
Lad os se på hver komponent i detaljer:
- CDC processor (producent) – I denne referencearkitektur er producenten indsat på Amazon Elastic Compute Cloud (Amazon EC2) i både den primære og sekundære region, og er aktiv i den primære region og på standby-tilstand i den sekundære region. Den fanger CDC-data fra den eksterne datakilde (som en DB2-database som vist i arkitekturen ovenfor) og streamer til Kinesis-datastrømme i den primære region. Vanguard bruger en 3rd festværktøjet Qlik Replicate som deres CDC-processor. Det producerer en velformet nyttelast, inklusive DB2-tidsstemplet for commit til Kinesis-datastrømmen, ud over de faktiske rækkedata fra den eksterne datakilde. (
example-stream-1i dette eksempel). Følgende kode er et eksempel på en nyttelast, der kun indeholder den primære nøgle til den post, der ændrede sig, og tidsstemplet for forpligtelsen (for nemheds skyld er resten af tabelrækkedataene ikke vist nedenfor):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }Den Base64-dekodede værdi på
Dataer som følgende. Den faktiske Kinesis-post ville indeholde hele rækkedataene for den tabelrække, der ændrede sig, ud over den primære nøgle og tidsstemplet for forpligtelsen.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}CommitTimestampiDatafeltet bruges i replikeringskontrolpunktet og er afgørende for nøjagtigt at spore, hvor meget af strømdataene, der er blevet replikeret til den sekundære region. Kontrolpunktet kan derefter bruges til at lette en CDC-processor (producent) failover og nøjagtigt genoptage produktionen af data fra replikeringskontrolpunktets tidsstempling og fremefter.Alternativet til at bruge en ekstern datakilde
CommitTimestamp(hvis den ikke er tilgængelig) er at brugeApproximateArrivalTimestamp(som er tidsstemplet, når posten faktisk skrives til datastrømmen). - Cross-Region replikation Lambda funktion – Funktionen er udsendt til både primære og sekundære regioner. Det er sat op med en hændelseskilde, der er kortlagt til datastrømmen, der indeholder CDC-data. Den samme funktion kan bruges til at replikere data fra flere strømme. Det påkaldes med en batch af poster fra Kinesis Data Streams og replikerer batchen til en målreplikeringsregion (som leveres via Lambda-konfigurationsmiljøet). Af omkostningshensyn, hvis CDC-dataene kun produceres aktivt i den primære region, kan den reserverede samtidighed af funktionen i den sekundære region sættes til nul og ændres under regional failover. Funktionen har AWS identitets- og adgangsstyring (IAM) rolletilladelser til at gøre følgende:
- Læs og skriv til de globale DynamoDB-tabeller, der bruges i denne løsning, inden for samme konto.
- Læs og skriv til Kinesis Data Streams i begge regioner inden for samme konto.
- Udgiv tilpassede metrics til amazoncloudwatch i begge regioner inden for samme konto.
- Replikationskontrolpunkt – Replikeringskontrolpunktet bruger den globale DynamoDB-tabel i både de primære og sekundære regioner. Den bruges af lambda-funktionen for replikering på tværs af regioner til at fortsætte tidsstemplet for den sidste replikeringspost som replikeringskontrolpunktet for hver strøm, der er konfigureret til replikering. Til dette indlæg opretter og bruger vi en global tabel kaldet
kdsReplicationCheckpoint. - Active Region config – Den aktive region bruger den globale DynamoDB-tabel i både primære og sekundære regioner. Den bruger den indbyggede tværregionale replikeringskapacitet i den globale tabel til at replikere konfigurationen. Den er på forhånd udfyldt med data om, hvilken der er den primære region for en strøm, for at forhindre replikering tilbage til den primære region af Lambda-funktionen i standby-regionen. Denne konfiguration er muligvis ikke påkrævet, hvis Lambda-funktionen i standby-regionen har en reserveret samtidighed sat til nul, men kan tjene som et sikkerhedstjek for at undgå uendelig replikeringsløkke af dataene. Til dette indlæg opretter vi en global tabel kaldet
kdsActiveRegionConfigog sæt et element med følgende data:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Kinesis datastrømme – Den strøm, som CDC-processoren producerer dataene til. Til dette indlæg bruger vi en strøm kaldet
example-stream-1i begge regioner med samme shard-konfiguration og adgangspolitikker.
Sekvens af trin i tværgående replikering
Lad os kort se på, hvordan arkitekturen udøves ved hjælp af følgende sekvensdiagram.

Sekvensen består af følgende trin:
- CDC-processoren (i
us-east-1) læser CDC-dataene fra den eksterne datakilde. - CDC-processoren (i
us-east-1) streamer CDC-dataene til Kinesis Data Streams (ius-east-1). - Lambda-funktionen på tværs af regioner (i us-east-1) forbruger dataene fra datastrømmen (i
us-east-1). Det forbedrede fan-out-mønster anbefales til dedikeret og øget gennemløb til replikering på tværs af regioner. - Replikator Lambda-funktionen (i
us-east-1) validerer sin nuværende region med den aktive regionskonfiguration for den strøm, der forbruges, ved hjælp afkdsActiveRegionConfigDynamoDB global tabel Følgende eksempelkode (i Java) kan hjælpe med at illustrere den tilstand, der evalueres:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - Funktionen evaluerer svaret fra DynamoDB med følgende kode:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Afhængigt af svaret udfører funktionen følgende handlinger:
- Hvis svaret er
true, producerer replikatorfunktionen posterne til Kinesis Data Streams ius-east-2på en sekventiel måde.- Hvis der er en fejl, spores postens sekvensnummer, og iterationen brydes. Funktionen returnerer listen over mislykkede sekvensnumre. Ved at returnere det mislykkede sekvensnummer bruger løsningen funktionen af Lambda checkpointing for at kunne genoptage behandlingen af en batch af poster med delvise fejl. Dette er nyttigt ved håndtering af eventuelle serviceforringelser, hvor funktionen forsøger at replikere data på tværs af regioner for at sikre strømparitet og intet datatab.
- Hvis der ikke er nogen fejl, returneres en tom liste, hvilket indikerer, at batchen var vellykket.
- Hvis svaret er
false, returnerer replikatorfunktionen uden at udføre nogen replikering. For at reducere omkostningerne til Lambda-kaldene kan du indstille den reserverede samtidighed af funktionen i DR-regionen (us-east-2) til nul. Dette vil forhindre funktionen i at blive aktiveret. Når du failover, kan du opdatere denne værdi til et passende tal baseret på CDC-gennemløbet og indstille den reserverede samtidighed af funktionen ius-east-1til nul for at forhindre den i at køre unødigt.
- Hvis svaret er
- Efter alle optegnelser er produceret til Kinesis Data Streams i
us-east-2, replikatorfunktionen checkpoints tilkdsReplicationCheckpointDynamoDB global tabel (ius-east-1) med følgende data:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - Funktionen vender tilbage efter vellykket behandling af partiet af poster.
Ydelsesovervejelser
Løsningens præstationsforventninger skal forstås i forhold til følgende faktorer:
- Regionsvalg – Replikationsforsinkelsen er direkte proportional med den afstand, som dataene tilbagelægger, så forstå dit områdevalg
- Velocity – Den indkommende hastighed af dataene eller mængden af data, der replikeres
- Nyttelast størrelse – Størrelsen af den nyttelast, der replikeres
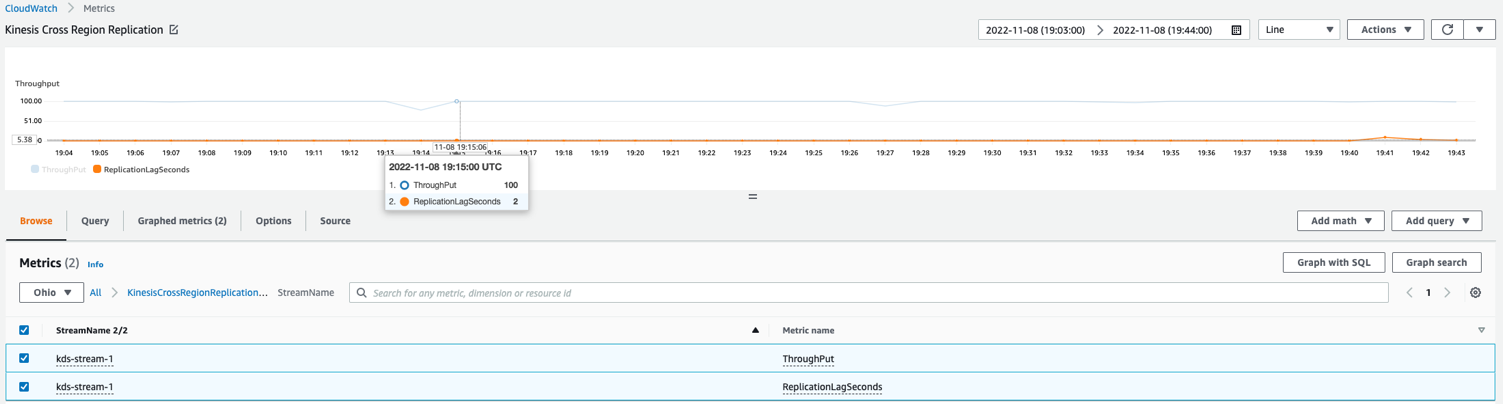
Overvåg replikeringen på tværs af regioner
Det anbefales at spore og observere replikationen, mens den sker. Du kan skræddersy Lambda-funktionen til at udgive tilpassede metrics til CloudWatch med følgende metrics i slutningen af hver påkaldelse. Udgivelse af disse metrics til både den primære og sekundære region hjælper med at beskytte dig selv mod forringelser, der påvirker observerbarheden i den primære region.
- gennemløb – Den aktuelle lambda-opkaldsbatchstørrelse
- ReplicationLagSeconds – Forskellen mellem det aktuelle tidsstempel (efter behandling af alle posterne) og
ApproximateArrivalTimestampaf den sidste rekord, der blev replikeret
Følgende eksempel CloudWatch metrisk graf viser, at den gennemsnitlige replikeringsforsinkelse var 2 sekunder med en gennemstrømning på 100 poster replikeret fra us-east-1 til us-east-2.
Fælles failover-strategi
Under eventuelle værdiforringelser, der påvirker CDC-pipelinen i den primære region, kan behov for forretningskontinuitet eller katastrofeoprettelse diktere en pipeline-failover til den sekundære (standby-)region. Dette betyder, at et par ting skal gøres som en del af denne failover-proces:
- Hvis det er muligt, skal du stoppe alle CDC-opgaver i CDC-processorværktøjet i
us-east-1. - CDC-processoren skal fejlbehandles til den sekundære region, så den kan læse CDC-dataene fra den eksterne datakilde, mens den opererer uden for standby-regionen.
-
kdsActiveRegionConfigDynamoDB global tabel skal opdateres. For eksempel for strømmenexample-stream-1brugt i vores eksempel, ændres den aktive region tilus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Alle strømkontrolpunkter skal læses fra
kdsReplicationCheckpointDynamoDB global tabel (ius-east-2), og tidsstemplerne fra hvert af kontrolpunkterne bruges til at starte CDC-opgaverne i producentværktøjet ius-east-2Område. Dette minimerer chancerne for tab af data og genoptager nøjagtigt streaming af CDC-data fra den eksterne datakilde fra kontrolpunktets tidsstempling og fremefter. - Hvis du bruger reserveret samtidighed til at kontrollere Lambda-kald, skal du indstille værdien til nul i den primære Region(
us-east-1) og til en passende ikke-nul værdi i den sekundære region(us-east-2).
Vanguards flertrins failover-strategi
Nogle af de tredjepartsværktøjer, som Vanguard bruger, har en to-trins CDC-proces til at streame data fra en fjerndatakilde til en destination. Vanguards foretrukne værktøj til deres CDC-processor følger denne to-trins tilgang:
- Det første trin involverer opsætning af en logstream-opgave, der læser dataene fra den eksterne datakilde og forbliver på en mellemstation.
- Det andet trin involverer opsætning af individuelle forbrugeropgaver, der læser data fra iscenesættelsesstedet - som kunne være tændt Amazon Elastic File System (Amazon EFS) eller Amazon FSx, for eksempel – og stream det til destinationen. Fleksibiliteten her er, at hver af disse forbrugeropgaver kan udløses til at streame fra forskellige forpligtelsestidsstempler. Logstream-opgaven begynder normalt at læse data fra minimum af alle de forpligtelsestidsstempler, der bruges af forbrugeropgaverne.
Lad os se på et eksempel for at forklare scenariet:
- Forbrugeropgave A streamer data fra et forpligtelsestidsstempel 2022-07-19T20:00:00 og frem til
example-stream-1. - Forbrugeropgave B streamer data fra et forpligtelsestidsstempel 2022-07-19T21:00:00 og frem til
example-stream-2. - I denne situation bør logstrømmen læse data fra den eksterne datakilde fra minimum af de tidsstempler, der bruges af forbrugeropgaverne, som er 2022-07-19T20:00:00.
Følgende sekvensdiagram viser de nøjagtige trin, der skal køres under en failover til us-east-2 (standby-regionen).

Trinnene er som følger:
- Failover-processen udløses i standby-regionen (
us-east-2i dette eksempel) efter behov. Bemærk, at triggeren kan automatiseres ved hjælp af omfattende sundhedstjek af pipelinen i den primære region. - Failover-processen opdaterer kdsActiveRegionConfig DynamoDB globale tabel med den nye værdi for regionen som
us-east-2for alle strømnavne. - Det næste trin er at hente alle stream checkpoints fra
kdsReplicationCheckpointDynamoDB global tabel (ius-east-2). - Efter checkpoint-informationen er læst, finder failover-processen minimum af alle
lastReplicatedTimestamp. - Logstream-opgaven i CDC-processorværktøjet startes i
us-east-2med tidsstemplet fundet i trin 4. Det begynder at læse CDC-data fra fjerndatakilden fra dette tidsstempel og fremefter og fortsætter dem på iscenesættelsesstedet på AWS. - Det næste trin er at starte alle forbrugeropgaverne for at læse data fra iscenesættelsesstedet og streame til destinationsdatastrømmen. Det er her hver forbrugeropgave forsynes med det passende tidsstempel fra
kdsReplicationCheckpointtabel ifølgestreamNamehvortil opgaven streamer dataene.
Efter at alle forbrugeropgaver er startet, produceres data til Kinesis datastrømme i us-east-2. Derefter er processen med tværregionsreplikation den samme som beskrevet tidligere - replikations Lambda-funktionen i us-east-2 begynder at replikere data til datastrømmen ind us-east-1.
Forbrugerapplikationerne, der læser data fra strømmene, forventes at være idempotente til at kunne håndtere dubletter. Dubletter kan indføres i strømmen af mange årsager, hvoraf nogle er nævnt nedenfor.
- Producenten eller CDC-processoren introducerer dubletter i strømmen, mens CDC-dataene afspilles under en failover
- DynamoDB Global Table bruger asynkron replikering af data på tværs af regioner og hvis
kdsReplicationCheckpointtabeldata har en replikeringsforsinkelse, kan failover-processen muligvis bruge et ældre kontrolpunkttidsstempel til at afspille CDC-dataene.
Forbrugerapplikationer bør også kontrollere CommitTimestamp for den sidste post, der blev forbrugt. Dette er for at lette bedre overvågning og genopretning.
Vejen til modenhed: Automatiseret genopretning
Den ideelle tilstand er fuldt ud at automatisere failover-processen, hvilket reducerer tiden til genopretning og opfylder resilience Service Level Objective (SLO). Men i de fleste organisationer kræver beslutningen om at fejle over, fejle tilbage og udløse failover manuel intervention i vurderingen af situationen og beslutningen om resultatet. Oprettelse af scriptet automatisering til at udføre failover, der kan køres af et menneske, er et godt sted at starte.
Vanguard har automatiseret alle trin i failover, men har stadig mennesker til at træffe beslutningen om, hvornår de skal påberåbe sig det. Du kan tilpasse løsningen, så den opfylder dine behov og afhængigt af det CDC-processorværktøj, du bruger i dit miljø.
Konklusion
I dette indlæg beskrev vi, hvordan Vanguard fornyede og byggede en løsning til at replikere data på tværs af regioner i Kinesis Data Streams for at gøre dataene yderst tilgængelige. Vi demonstrerede også en robust kontrolpunktstrategi for at lette en regional failover af replikeringsprocessen, når det er nødvendigt. Løsningen illustrerede også, hvordan man bruger DynamoDB globale tabeller til sporing af replikeringskontrolpunkter og konfiguration. Med denne arkitektur var Vanguard i stand til at implementere arbejdsbelastninger afhængigt af CDC-dataene til flere regioner for at imødekomme forretningsbehov med høj tilgængelighed i lyset af serviceforringelser, der påvirker CDC-pipelines i den primære region.
Hvis du har feedback, bedes du skrive en kommentar i kommentarfeltet nedenfor.
Om forfatterne
 Raghu Boppanna arbejder som Enterprise Architect hos Vanguards Chief Technology Office. Raghu har specialiseret sig i dataanalyse, datamigrering/replikering, herunder CDC Pipelines, Disaster Recovery og databaser. Han har opnået adskillige AWS-certificeringer, herunder AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
Raghu Boppanna arbejder som Enterprise Architect hos Vanguards Chief Technology Office. Raghu har specialiseret sig i dataanalyse, datamigrering/replikering, herunder CDC Pipelines, Disaster Recovery og databaser. Han har opnået adskillige AWS-certificeringer, herunder AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
 Parameswaran V Vaidyanathan er en Senior Cloud Resilience Architect med Amazon Web Services. Han hjælper store virksomheder med at nå forretningsmålene ved at designe og bygge skalerbare og modstandsdygtige løsninger på AWS Cloud.
Parameswaran V Vaidyanathan er en Senior Cloud Resilience Architect med Amazon Web Services. Han hjælper store virksomheder med at nå forretningsmålene ved at designe og bygge skalerbare og modstandsdygtige løsninger på AWS Cloud.
 Richa Kaul er en seniorleder inden for kundeløsninger, der betjener Financial Services-kunder. Hun er baseret i New York. Hun har stor erfaring med storskala cloud-transformation, medarbejders excellence og næste generations digitale løsninger. Hun og hendes team fokuserer på at optimere værdien af cloud ved at bygge effektive, robuste og agile løsninger. Richa nyder multisport som triatlon, musik og at lære om nye teknologier.
Richa Kaul er en seniorleder inden for kundeløsninger, der betjener Financial Services-kunder. Hun er baseret i New York. Hun har stor erfaring med storskala cloud-transformation, medarbejders excellence og næste generations digitale løsninger. Hun og hendes team fokuserer på at optimere værdien af cloud ved at bygge effektive, robuste og agile løsninger. Richa nyder multisport som triatlon, musik og at lære om nye teknologier.
 Mithil Prasad er Principal Customer Solutions Manager hos Amazon Web Services. I sin rolle arbejder Mithil sammen med kunder for at fremme realisering af cloud-værdi, levere tankelederskab for at hjælpe virksomheder med at opnå hastighed, smidighed og innovation.
Mithil Prasad er Principal Customer Solutions Manager hos Amazon Web Services. I sin rolle arbejder Mithil sammen med kunder for at fremme realisering af cloud-værdi, levere tankelederskab for at hjælpe virksomheder med at opnå hastighed, smidighed og innovation.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- evne
- I stand
- Om
- over
- adgang
- Ifølge
- Konto
- præcist
- opnå
- tværs
- aktioner
- aktiv
- aktivt
- faktisk
- Desuden
- rådgivning
- påvirker
- overkommelige
- Efter
- mod
- adræt
- Alle
- tillader
- alternativ
- Amazon
- Amazon EC2
- Amazon Kinesis
- Amazon Web Services
- beløb
- analytics
- ,
- applikationer
- tilgang
- passende
- arkitektur
- automatisere
- Automatiseret
- Automation
- tilgængelighed
- til rådighed
- gennemsnit
- AWS
- AWS certificeret
- tilbage
- baseret
- fordi
- være
- jf. nedenstående
- Bedre
- mellem
- kortvarigt
- Broken
- bygge
- Bygning
- bygget
- indbygget
- virksomhed
- business kontinuitet
- virksomheder
- kaldet
- fange
- fanger
- tilfælde
- CDC
- certificeringer
- Certificeret
- odds
- lave om
- kontrollere
- Kontrol
- chef
- valg
- Cloud
- SKY-TEKNOLOGI
- kode
- KOMMENTAR
- kommentarer
- begå
- komponent
- omfattende
- Compute
- betingelse
- Konfiguration
- overvejelser
- forbruges
- forbruger
- Forbrugere
- forbrug
- kontinuerligt
- kontrol
- Koste
- kunne
- Par
- skabe
- Oprettelse af
- kritisk
- Nuværende
- For øjeblikket
- skik
- kunde
- Kundeløsninger
- Kunder
- tilpasse
- data
- Dataanalyse
- datatab
- Database
- databaser
- Beslutter
- beslutning
- dedikeret
- demonstreret
- demonstrerer
- Afhængigt
- afhænger
- indsætte
- indsat
- beskrevet
- destination
- detail
- forskel
- forskellige
- digital
- direkte
- katastrofe
- drøftet
- afstand
- køre
- kørsel
- dubletter
- i løbet af
- hver
- tidligere
- optjent
- økonomier
- Stordriftsfordele
- effektiv
- Medarbejder
- muliggør
- forbedret
- sikre
- Enterprise
- virksomheder
- Hele
- Miljø
- Ether (ETH)
- evaluere
- evalueret
- begivenhed
- Hver
- eksempel
- Excellence
- udførelse
- forventninger
- forventet
- erfaring
- Forklar
- Forklarer
- omfattende
- ekstern
- Ansigtet
- lette
- faktorer
- FAIL
- mislykkedes
- Manglende
- Feature
- tilbagemeldinger
- felt
- File (Felt)
- finansielle
- finansielle tjenesteydelser
- fund
- Fornavn
- Fleksibilitet
- Fokus
- efter
- følger
- Til investorer
- fundet
- fra
- fuldt ud
- funktion
- generation
- Global
- kloden
- Mål
- godt
- graf
- Gæst
- gæst Indlæg
- håndtere
- Håndtering
- sker
- Helse
- hjælpe
- hjælper
- link.
- Høj
- stærkt
- Hvordan
- How To
- Men
- HTTPS
- menneskelig
- Mennesker
- IAM
- ideal
- Identity
- leverfunktion
- Forbedre
- forbedrer
- in
- Herunder
- Indgående
- øget
- angiver
- individuel
- oplysninger
- Infrastruktur
- Innovation
- instans
- indgriben
- introduceret
- Introducerer
- investor
- Investorer
- IT
- iteration
- Java
- juli
- Nøgle
- Kinesis datastrømme
- stor
- Efternavn
- Latency
- leder
- Leadership" (virkelig menneskelig ledelse)
- læring
- Forlade
- Niveau
- Line (linje)
- linjer
- Liste
- lidt
- placering
- Se
- off
- lavet
- fastholder
- lave
- maerker
- lykkedes
- leder
- måde
- manuel
- mange
- kortlægning
- massivt
- modenhed
- midler
- mekanisme
- Mød
- møde
- metrisk
- Metrics
- mindste
- minimum
- tilstand
- modificeret
- overvågning
- mest
- multi
- flere
- Musik
- navn
- navne
- indfødte
- Behov
- behov
- behov
- Ny
- Nye teknologier
- New York
- næste
- nummer
- numre
- objektiv
- observere
- Office
- drift
- optimering
- organisationer
- Resultat
- paritet
- del
- partnerskab
- part
- Mønster
- udføre
- ydeevne
- udfører
- Tilladelser
- vedvarer
- Personlig
- pipeline
- Place
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- politikker
- mulig
- Indlæg
- potentielt
- forhindre
- primære
- Main
- behandle
- forarbejdning
- Processor
- produceret
- producent
- Producenter
- fremmer
- beskytte
- give
- forudsat
- giver
- offentliggøre
- Publicering
- formål
- sætte
- Læs
- Læsning
- erkendelse af
- årsager
- anbefales
- optage
- optegnelser
- Recover
- opsving
- reducere
- reducere
- region
- regional
- regioner
- fjern
- replikeres
- replikerer
- replikation
- påkrævet
- Krav
- Kræver
- forbeholdes
- modstandskraft
- elastisk
- svar
- REST
- Genoptag
- afkast
- vender tilbage
- afkast
- robust
- roller
- Rullet
- RÆKKE
- Kør
- Sikkerhed
- samme
- skalerbar
- Scale
- scenarie
- Anden
- sekundær
- sekunder
- Sektion
- sikkerhed
- senior
- Sequence
- tjener
- tjeneste
- Tjenester
- servering
- sæt
- indstilling
- flere
- bør
- vist
- Shows
- enkelhed
- Situationen
- Størrelse
- So
- løsninger
- Løsninger
- nogle
- Kilde
- Kilder
- specialiseret
- Specialty
- hastighed
- Sport
- iscenesættelse
- starte
- påbegyndt
- starter
- Tilstand
- Trin
- Steps
- Stadig
- Stands
- butik
- Strategi
- strøm
- streaming
- streaming service
- vandløb
- vellykket
- Succesfuld
- egnede
- overlegen
- tilført
- Understøtter
- systemet
- bord
- tager
- mål
- Opgaver
- opgaver
- hold
- hold
- Teknisk
- Teknologier
- Teknologier
- deres
- ting
- tredjepart
- tænkte
- tænkt lederskab
- Gennem
- kapacitet
- tid
- tidsstempel
- til
- værktøj
- værktøjer
- spor
- Sporing
- Transformation
- rejst
- udløse
- udløst
- forstå
- forstået
- unødigt
- Opdatering
- opdateret
- opdateringer
- brug
- brug tilfælde
- sædvanligvis
- UTC
- værdi
- Vanguard
- VeloCity
- via
- bind
- web
- webservices
- som
- mens
- vilje
- inden for
- uden
- virker
- ville
- skriver
- skriftlig
- Din
- dig selv
- zephyrnet
- nul
- zoner