Opsummeringsagenter forestillet af AI-billedgenereringsværktøjet Dall-E.
Er du en del af befolkningen, der efterlader anmeldelser på Google maps, hver gang du besøger en ny restaurant?
Eller måske er du typen, der deler din mening om Amazon-køb, især når du bliver udløst af et produkt af lav kvalitet?
Bare rolig, jeg vil ikke bebrejde dig - vi har alle vores øjeblikke!
I nutidens dataverden bidrager vi alle til datafloden på flere måder. En datatype, som jeg finder særligt interessant på grund af dens mangfoldighed og sværhedsgrad ved fortolkning, er tekstdata, såsom de utallige anmeldelser, der hver dag bliver lagt ud over internettet. Har du nogensinde stoppet op for at overveje vigtigheden af at standardisere og kondensere tekstdata? Velkommen til en verden af opsummeringsagenter!
Opsummeringsagenter er problemfrit integreret i vores daglige liv og kondenserer information og giver hurtig adgang til relevant indhold på tværs af en lang række applikationer og platforme.
I denne artikel vil vi udforske brugen af ChatGPT som en kraftfuld opsummeringsagent til vores tilpassede applikationer. Takket være Large Language Models (LLM) evne til at behandle og forstå tekster, de kan hjælpe med at læse tekster og generere nøjagtige resuméer eller standardisere information. Det er dog vigtigt at vide, hvordan man kan udvinde deres potentiale i at udføre en sådan opgave, samt at erkende deres begrænsninger.
Den største begrænsning for opsummering? LLM'er kommer ofte til kort, når det kommer til at overholde specifikke tegn- eller ordbegrænsninger i deres resuméer.
Lad os udforske de bedste fremgangsmåder til at generere oversigter med ChatGPT for vores brugerdefinerede applikation, såvel som årsagerne bag dens begrænsninger og hvordan man overvinder dem!
Opsummeringsagenter bruges overalt på internettet. For eksempel bruger hjemmesider opsummeringsagenter til at tilbyde kortfattede resuméer af artikler, hvilket gør det muligt for brugerne at få et hurtigt overblik over nyhederne uden at dykke ned i hele indholdet. Det gør sociale medieplatforme og søgemaskiner også.
Fra nyhedsaggregatorer og sociale medieplatforme til e-handelswebsteder er opsummeringsagenter blevet en integreret del af vores digitale landskab. Og med stigningen i LLM'er bruger nogle af disse agenter nu AI til mere effektive opsummeringsresultater.
ChatGPT kan være en god allieret, når du bygger en applikation ved hjælp af opsummeringsagenter til at fremskynde læseopgaver og klassificering af tekster. Forestil dig for eksempel, at vi har en e-handelsvirksomhed, og vi er interesserede i at behandle alle vores kundeanmeldelser. ChatGPT kunne hjælpe os med at opsummere enhver given anmeldelse i nogle få sætninger, standardisere den til et generisk format, bestemme stemningen i anmeldelsen og klassificering det i overensstemmelse hermed.
Selvom det er rigtigt, at vi simpelthen kunne sende anmeldelsen til ChatGPT, er der en liste over bedste praksis - og ting at undgå - at udnytte kraften i ChatGPT i denne konkrete opgave.
Lad os undersøge mulighederne ved at bringe dette eksempel til live!
Eksempel: E-handelsanmeldelser
Selvlavet gif.
Overvej eksemplet ovenfor, hvor vi er interesserede i at behandle alle anmeldelser for et givet produkt på vores e-handelswebsted. Vi ville være interesserede i at behandle anmeldelser såsom følgende om vores stjerneprodukt: den første computer til børn!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
I dette tilfælde vil vi gerne have, at ChatGPT:
Klassificer anmeldelsen i positiv eller negativ.
Giv et resumé af anmeldelsen på 20 ord.
Udskriv svaret med en konkret struktur for at standardisere alle anmeldelser i ét enkelt format.
Implementeringsnoter
Her er den grundlæggende kodestruktur, vi kunne bruge til at bede ChatGPT fra vores brugerdefinerede applikation. Jeg giver også et link til en Jupyter Notebook med alle de eksempler, der er brugt i denne artikel.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
funktionen get_completion() kalder ChatGPT API med en given prompt. Hvis prompten indeholder yderligere brugertekst, såsom selve anmeldelsen i vores tilfælde, er den adskilt fra resten af koden med tredobbelte anførselstegn.
Lad os bruge get_completion() funktion til at bede ChatGPT!
Her er en prompt, der opfylder kravene beskrevet ovenfor:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Som vi kan observere fra outputtet, er anmeldelsen dog nøjagtig og velstruktureret den savner nogle oplysninger, vi kunne være interesserede i som ejere af e-handlen, såsom oplysninger om levering af produktet.
Opsummer med fokus på
Vi kan iterativt forbedre vores prompt ved at bede ChatGPT om at fokusere på visse ting i oversigten. I dette tilfælde er vi interesserede i alle detaljer givet om forsendelse og levering:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Denne gang er ChatGPTs svar følgende:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Nu er anmeldelsen meget mere komplet. At give detaljer om det vigtige fokus i den originale anmeldelse er afgørende for at undgå, at ChatGPT springer nogle oplysninger over, der kan være værdifulde for vores brugssag.
Har du bemærket, at selvom dette andet forsøg indeholder oplysninger om leveringen, sprang den det eneste negative aspekt af den oprindelige anmeldelse over?
Lad os ordne det!
"Udtræk" i stedet for "Opsummer"
Ved at undersøge opsummeringsopgaver fandt jeg ud af det opsummering kan være en vanskelig opgave for LLM'er, hvis brugerprompten ikke er præcis nok.
Når du beder ChatGPT om at give et resumé af en given tekst, kan det springe over oplysninger, der kan være relevante for os – som vi for nylig har oplevet – eller det vil give samme betydning for alle emnerne i teksten, kun give et overblik over hovedpunkterne.
Eksperter i LLM'er bruger udtrykket ekstrakt og yderligere oplysninger om deres fokus i stedet for opsummere når de udfører sådanne opgaver assisteret af disse typer modeller.
Mens opsummering har til formål at give et kortfattet overblik over tekstens hovedpunkter, herunder emner, der ikke er relateret til fokusemnet, fokuserer informationsudtrækning på at hente specifikke detaljer og kan give os det, vi netop leder efter. Lad os så prøve med ekstraktion!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
I dette tilfælde får vi ved at bruge ekstraktion kun information om vores fokusemne: Shipping: Arrived a day earlier than expected.
Automatisering
Dette system fungerer for én enkelt anmeldelse. Ikke desto mindre, når man designer en prompt til en konkret ansøgning, det er vigtigt at teste det i en batch af eksempler, så vi kan fange eventuelle outliers eller forkert opførsel i modellen.
I tilfælde af behandling af flere anmeldelser, her er et eksempel på Python-kodestruktur, der kan hjælpe.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Her er oversigterne over vores batch af anmeldelser:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Bemærk, at selvom ordbegrænsningen i vores resuméer var tydelig nok i vores prompter, kan vi nemt se, at denne ordbegrænsning ikke opnås i nogen af gentagelserne.
Denne uoverensstemmelse i ordtælling sker, fordi LLM'er ikke har en præcis forståelse af ord- eller tegnantal. Årsagen bag dette er afhængig af en af de vigtigste vigtige komponenter i deres arkitektur: tokenizeren.
Tokenizer
LLM'er som ChatGPT er designet til at generere tekst baseret på statistiske mønstre lært fra enorme mængder sprogdata. Selvom de er yderst effektive til at generere flydende og sammenhængende tekst, mangler de præcis kontrol over ordantallet.
I eksemplerne ovenfor, når vi har givet instruktioner om et meget præcist ordtal, ChatGPT kæmpede for at opfylde disse krav. I stedet har den genereret tekst, der faktisk er kortere end det angivne ordantal.
I andre tilfælde kan det generere længere tekster eller blot tekst, der er alt for udførlig eller mangler detaljer. Derudover ChatGPT kan prioritere andre faktorer såsom sammenhæng og relevans frem for streng overholdelse af ordantallet. Dette kan resultere i tekst, der er af høj kvalitet i forhold til indhold og sammenhæng, men som ikke præcist matcher kravet til ordtal.
Tokenizeren er nøgleelementet i ChatGPTs arkitektur, der tydeligt påvirker antallet af ord i det genererede output.
Selvlavet gif.
Tokenizer arkitektur
Tokenizeren er det første trin i processen med tekstgenerering. Det er ansvarligt for at nedbryde det stykke tekst, som vi indtaster til ChatGPT, i individuelle elementer — tokens —, som derefter bearbejdes af sprogmodellen til at generere ny tekst.
Når tokenizeren opdeler et stykke tekst i tokens, gør den det baseret på et sæt regler, der er designet til at identificere målsprogets meningsfulde enheder. Disse regler er dog ikke altid perfekte, og der kan være tilfælde, hvor tokenizeren opdeler eller fusionerer tokens på en måde, der påvirker det samlede ordantal i teksten.
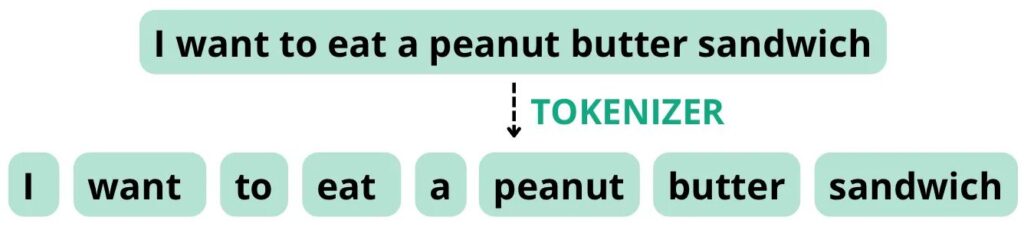
Overvej for eksempel følgende sætning: "Jeg vil spise en peanutbutter sandwich". Hvis tokenizeren er konfigureret til at opdele tokens baseret på mellemrum og tegnsætning, kan den opdele denne sætning i følgende tokens med et samlet ordantal på 8, svarende til token-antallet.
Selvfremstillet billede.
Men hvis tokenizeren er konfigureret til at behandle "jordnøddesmør" som et sammensat ord kan det opdele sætningen i følgende tokens, med et samlet ordantal på 8, men et symbolsk antal på 7.
Således kan den måde, tokenizeren er konfigureret på, påvirke det overordnede ordantal i teksten, og dette kan påvirke LLM'ens evne til at følge instruktioner om præcise ordtællinger. Mens nogle tokenizere tilbyder muligheder for at tilpasse, hvordan tekst tokeniseres, er dette ikke altid tilstrækkeligt til at sikre præcis overholdelse af krav til ordtal. For ChatGPT i dette tilfælde kan vi ikke kontrollere denne del af dets arkitektur.
Dette gør ChatGPT ikke så god til at opnå karakter- eller ordbegrænsninger, men man kan prøve med sætninger i stedet, da tokenizeren ikke påvirker antallet af sætninger, men deres længde.
At være opmærksom på denne begrænsning kan hjælpe dig med at opbygge den bedst egnede prompt til din ansøgning i tankerne. Med denne viden om, hvordan ordtælling fungerer på ChatGPT, lad os lave en sidste iteration med vores prompt til e-handelsapplikationen!
Afslutning: E-handelsanmeldelser
Lad os kombinere vores erfaringer fra denne artikel til en sidste prompt! I dette tilfælde vil vi bede om resultaterne i HTML format for et pænere output:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
Og her er det endelige output fra ChatGPT:
Selvlavet skærmbillede fra Jupyter Notebook med eksemplerne brugt i denne artikel.
Resumé
I denne artikel, vi har diskuteret den bedste praksis for at bruge ChatGPT som en opsummeringsagent til vores tilpassede applikation.
Vi har set, at når du bygger en applikation, er det ekstremt svært at komme med den perfekte prompt, der matcher dine ansøgningskrav i den første prøveperiode. Jeg synes, det er en god besked med hjem tænk på tilskyndelse som en iterativ proces hvor du forfiner og modellerer din prompt, indtil du får præcis det ønskede output.
Ved iterativt at forfine din prompt og anvende den på en batch af eksempler, før du implementerer den i produktionen, kan du sikre dig outputtet er konsistent på tværs af flere eksempler og dækker afvigende svar. I vores eksempel kan det ske, at nogen giver en tilfældig tekst i stedet for en anmeldelse. Vi kan instruere ChatGPT til også at have et standardiseret output for at udelukke disse afvigende svar.
Derudover, når du bruger ChatGPT til en specifik opgave, er det også en god praksis at lære om fordele og ulemper ved at bruge LLM'er til vores målopgave. Det var sådan, vi stødte på, at udtræksopgaver er mere effektive end opsummering, når vi ønsker et fælles menneskelignende resumé af en inputtekst. Vi har også erfaret, at det at give resuméets fokus kan være en game-changer vedrørende det genererede indhold.
Endelig, mens LLM'er kan være yderst effektive til at generere tekst, de er ikke ideelle til at følge præcise instruktioner om ordantal eller andre specifikke formateringskrav. For at nå disse mål kan det være nødvendigt at holde sig til sætningsoptælling eller bruge andre værktøjer eller metoder, såsom manuel redigering eller mere specialiseret software.
Denne artikel blev oprindeligt offentliggjort den Mod datalogi og genudgivet til TOPBOTS med tilladelse fra forfatteren.
Nyder du denne artikel? Tilmeld dig flere AI-forskningsopdateringer.
Vi giver dig besked, når vi udgiver flere oversigtsartikler som denne.