Genereret med Midjourney
NeurIPS 2023-konferencen, der blev afholdt i den pulserende by New Orleans fra den 10. til den 16. december, havde en særlig vægt på generativ kunstig intelligens og store sprogmodeller (LLM'er). I lyset af de seneste banebrydende fremskridt på dette område var det ingen overraskelse, at disse emner dominerede diskussionerne.
Et af kernetemaerne for dette års konference var søgen efter mere effektive AI-systemer. Forskere og udviklere søger aktivt måder at konstruere AI, der ikke kun lærer hurtigere end nuværende LLM'er, men som også besidder forbedrede ræsonnementer, mens de bruger færre computerressourcer. Denne forfølgelse er afgørende i kapløbet mod at nå Artificial General Intelligence (AGI), et mål, der synes mere og mere opnåeligt i en overskuelig fremtid.
De inviterede samtaler på NeurIPS 2023 var en afspejling af disse dynamiske og hurtigt udviklende interesser. Oplægsholdere fra forskellige sfærer af AI-forskning delte deres seneste resultater og gav et vindue til banebrydende AI-udviklinger. I denne artikel dykker vi ned i disse foredrag, uddrager og diskuterer de vigtigste takeaways og erfaringer, som er afgørende for at forstå de nuværende og fremtidige landskaber for AI-innovation.
NextGenAI: Vrangforestillingen om skalering og fremtiden for generativ AI
In hans snak, Björn Ommer, leder af Computer Vision & Learning Group ved Ludwig Maximilian Universitetet i München, delte, hvordan hans laboratorium kom til at udvikle stabil diffusion, nogle få erfaringer, de lærte af denne proces, og den seneste udvikling, herunder hvordan vi kan blande diffusionsmodeller med flowmatching, retrieval augmentation og LoRA approksimationer, blandt andre.
Nøgleaftagelser:
- I en alder af Generativ AI flyttede vi fra fokus på perception i synsmodeller (dvs. objektgenkendelse) til at forudsige de manglende dele (f.eks. billed- og videogenerering med diffusionsmodeller).
- I 20 år var computersyn fokuseret på benchmarkforskning, som var med til at sætte fokus på de mest fremtrædende problemer. I Generative AI har vi ingen benchmarks at optimere efter, hvilket åbnede feltet for alle til at gå i deres egen retning.
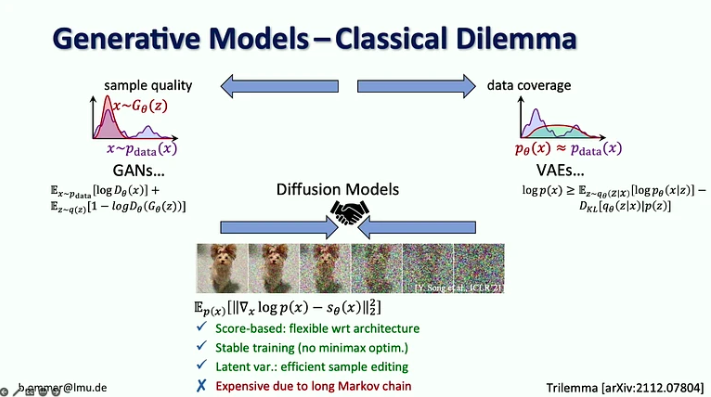
- Diffusionsmodeller kombinerer fordelene ved tidligere generative modeller ved at være scorebaserede med en stabil træningsprocedure og effektiv prøveredigering, men de er dyre på grund af deres lange Markov-kæde.
- Udfordringen med stærke sandsynlighedsmodeller er, at de fleste af bits går ind i detaljer, der næppe kan opfattes af det menneskelige øje, mens kodning af semantik, som betyder mest, kun tager nogle få bits. Skalering alene ville ikke løse dette problem, fordi efterspørgslen efter computerressourcer vokser 9x hurtigere end GPU-udbuddet.
- Den foreslåede løsning er at kombinere styrkerne ved diffusionsmodeller og ConvNets, især effektiviteten af foldninger til at repræsentere lokale detaljer og diffusionsmodellernes udtryksevne til lang rækkevidde kontekst.
- Björn Ommer foreslår også at bruge en flow-matching-tilgang til at muliggøre billedsyntese i høj opløsning fra små latente diffusionsmodeller.
- En anden tilgang til at øge effektiviteten af billedsyntese er at fokusere på scenekomposition, mens du bruger genfindingsforøgelse til at udfylde detaljerne.
- Til sidst introducerede han iPoke-tilgangen til kontrolleret stokastisk videosyntese.
Hvis dette dybdegående indhold er nyttigt for dig, abonner på vores AI-mailingliste for at blive advaret, når vi udgiver nyt materiale.
De mange ansigter af ansvarlig AI
In hendes oplæg, Lora Aroyo, en forsker ved Google Research, fremhævede en vigtig begrænsning i traditionelle maskinlæringstilgange: deres afhængighed af binære kategoriseringer af data som positive eller negative eksempler. Denne oversimplificering, hævdede hun, overser den komplekse subjektivitet, der er iboende i virkelige scenarier og indhold. Gennem forskellige use cases demonstrerede Aroyo, hvordan indholdets tvetydighed og den naturlige varians i menneskelige synspunkter ofte fører til uundgåelige uenigheder. Hun understregede vigtigheden af at behandle disse uenigheder som meningsfulde signaler frem for blot støj.

Her er de vigtigste ting fra foredraget:
- Uenighed mellem menneskelige laboratorier kan være produktive. I stedet for at behandle alle svar som enten korrekte eller forkerte, introducerede Lora Aroyo "sandhed ved uenighed", en tilgang til fordelingssandhed til at vurdere pålideligheden af data ved at udnytte vurderingernes uenighed.
- Datakvalitet er vanskelig, selv med eksperter, fordi eksperter er lige så uenige som crowd Labers. Disse uenigheder kan være meget mere informative end svar fra en enkelt ekspert.
- I sikkerhedsevalueringsopgaver er eksperter uenige i 40 % af eksemplerne. I stedet for at prøve at løse disse uenigheder, er vi nødt til at indsamle flere sådanne eksempler og bruge dem til at forbedre modellerne og evalueringsmetrikkene.
- Lora Aroyo præsenterede også deres Sikkerhed med mangfoldighed metode til at granske dataene i forhold til, hvad der er i dem, og hvem der har kommenteret dem.
- Denne metode producerede et benchmark-datasæt med variabilitet i LLM-sikkerhedsvurderinger på tværs af forskellige demografiske grupper af bedømmere (2.5 millioner vurderinger i alt).
- For 20 % af samtalerne var det svært at afgøre, om chatbot-svaret var sikkert eller usikkert, da der var nogenlunde lige mange respondenter, der betegnede dem som enten sikre eller usikre.
- Mangfoldigheden af bedømmere og data spiller en afgørende rolle i evalueringen af modeller. Hvis man undlader at anerkende den brede vifte af menneskelige perspektiver og tvetydigheden i indholdet, kan det hindre afstemningen af maskinlæringspræstationer med virkelighedens forventninger.
- 80 % af AI-sikkerhedsindsatsen er allerede ret god, men de resterende 20 % kræver en fordobling af indsatsen for at adressere kanttilfælde og alle varianterne i mangfoldighedens uendelige rum.
Kohærensstatistikker, selvgenereret erfaring og hvorfor unge mennesker er meget klogere end nuværende AI
In hendes snak, Linda Smith, en fremtrædende professor ved Indiana University Bloomington, udforskede emnet datasparhed i spædbørns og småbørns læreprocesser. Hun fokuserede specifikt på genkendelse af objekter og navneindlæring, og dykkede ned i, hvordan statistikken over selvgenererede oplevelser af spædbørn tilbyder potentielle løsninger på udfordringen med datasparhed.
Nøgleaftagelser:
- I en alder af tre har børn udviklet evnen til at være one-shot-elever på forskellige områder. På mindre end 16,000 vågne timer op til deres fjerde fødselsdag formår de at lære over 1,000 objektkategorier, mestre syntaksen i deres modersmål og absorbere de kulturelle og sociale nuancer i deres miljø.
- Dr. Linda Smith og hendes team opdagede tre principper for menneskelig læring, der gør det muligt for børn at fange så meget fra så sparsomme data:
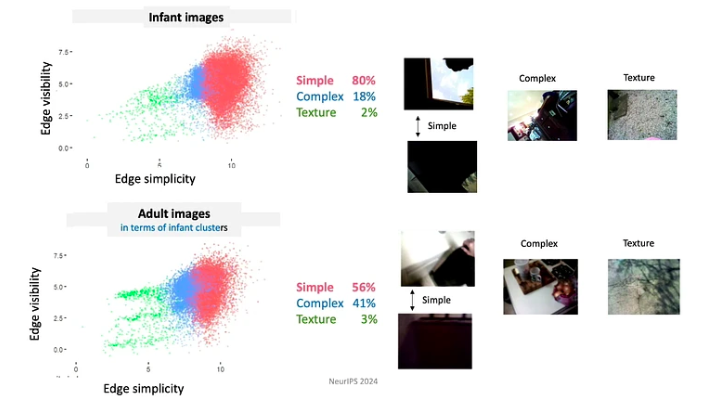
- Eleverne kontrollerer input, fra øjeblik til øjeblik former og strukturerer de input. For eksempel har babyer i de første par måneder af deres liv en tendens til at se mere på genstande med enkle kanter.
- Da babyer konstant udvikler sig i deres viden og evner, følger de en meget begrænset læseplan. De data, de udsættes for, er organiseret på dybt betydningsfulde måder. For eksempel bruger babyer under 4 måneder mest tid på at se på ansigter, cirka 15 minutter i timen, mens de ældre end 12 måneder primært fokuserer på hænder og observerer dem i omkring 20 minutter i timen.
- Læringsepisoder består af en række indbyrdes forbundne oplevelser. Rumlige og tidsmæssige sammenhænge skaber sammenhæng, som igen letter dannelsen af varige minder fra engangsbegivenheder. For eksempel, når børn præsenteres for et tilfældigt udvalg af legetøj, fokuserer børn ofte på nogle få "favorit" legetøj. De engagerer sig i dette legetøj ved hjælp af gentagne mønstre, som hjælper med hurtigere indlæring af objekterne.
- Forbigående (arbejds)hukommelser varer længere end det sensoriske input. Egenskaber, der forbedrer læringsprocessen, omfatter multimodalitet, associationer, forudsigende relationer og aktivering af tidligere minder.
- For hurtig læring har du brug for en alliance mellem de mekanismer, der genererer dataene, og de mekanismer, der lærer.
Skitsering: kerneværktøjer, læringsforøgelse og adaptiv robusthed
Jelani Nelson, professor i elektroteknik og datalogi ved UC Berkeley, introducerede begrebet data 'skitser' – en hukommelseskomprimeret repræsentation af et datasæt, der stadig muliggør besvarelse af nyttige forespørgsler. Selvom foredraget var ret teknisk, gav det et fremragende overblik over nogle grundlæggende skitseværktøjer, inklusive de seneste fremskridt.
Vigtige takeaways:
- CountSketch, kerneskitseværktøjet, blev første gang introduceret i 2002 for at løse problemet med "heavy hitters" og rapporterede en lille liste over de mest hyppige elementer fra den givne strøm af varer. CountSketch var den første kendte sublineære algoritme, der blev brugt til dette formål.
- To ikke-streaming applikationer af heavy hitters inkluderer:
- Interiør punktbaseret metode (IPM), der giver en asymptotisk hurtigste kendte algoritme til lineær programmering.
- HyperAttention-metode, der adresserer den beregningsmæssige udfordring, som den voksende kompleksitet af lange kontekster, der bruges i LLM'er.
- Meget nyligt arbejde har været fokuseret på at designe skitser, der er robuste over for adaptiv interaktion. Hovedideen er at bruge indsigt fra adaptiv dataanalyse.
Beyond Scaling Panel
Denne fantastisk panel om store sprogmodeller blev modereret af Alexander Rush, lektor ved Cornell Tech og forsker ved Hugging Face. Blandt de øvrige deltagere var:
- Aakanksha Chowdhery – Forsker hos Google DeepMind med forskningsinteresser i systemer, LLM-fortræning og multimodalitet. Hun var en del af teamet, der udviklede PaLM, Gemini og Pathways.
- Angela Fan – Forsker hos Meta Generative AI med forskningsinteresser i tilpasning, datacentre og flersprogethed. Hun deltog i udviklingen af Llama-2 og Meta AI Assistant.
- Percy Liang – Professor ved Stanford, der forsker i skabere, open source og generative agenter. Han er direktør for Center for Research on Foundation Models (CRFM) i Stanford og grundlæggeren af Together AI.
Diskussionen fokuserede på fire nøgleemner: (1) arkitektur og teknik, (2) data og tilpasning, (3) evaluering og gennemsigtighed og (4) skabere og bidragydere.
Her er nogle af takeaways fra dette panel:
- At træne nuværende sprogmodeller er ikke i sig selv svært. Den største udfordring ved at træne en model som Llama-2-7b ligger i infrastrukturkravene og behovet for at koordinere mellem flere GPU'er, datacentre osv. Men hvis antallet af parametre er lille nok til at tillade træning på en enkelt GPU, selv en bachelor kan klare det.
- Mens autoregressive modeller normalt bruges til tekstgenerering og diffusionsmodeller til generering af billeder og videoer, har der været eksperimenter med at vende disse tilgange. Specifikt i Gemini-projektet bruges en autoregressiv model til billedgenerering. Der har også været undersøgelser i brug af diffusionsmodeller til tekstgenerering, men disse har endnu ikke vist sig at være tilstrækkeligt effektive.
- I betragtning af den begrænsede tilgængelighed af engelsksprogede data til træningsmodeller, undersøger forskere alternative tilgange. En mulighed er at træne multimodale modeller på en kombination af tekst, video, billeder og lyd med forventning om, at færdigheder lært fra disse alternative modaliteter kan overføres til tekst. En anden mulighed er brugen af syntetiske data. Det er vigtigt at bemærke, at syntetiske data ofte blander sig i rigtige data, men denne integration er ikke tilfældig. Tekst offentliggjort online gennemgår typisk menneskelig kuration og redigering, hvilket kan tilføje yderligere værdi til modeltræning.
- Åbne fundamentmodeller ses ofte som gavnlige for innovation, men potentielt skadelige for AI-sikkerhed, da de kan udnyttes af ondsindede aktører. Dr. Percy Liang argumenterer dog for, at åbne modeller også bidrager positivt til sikkerheden. Han argumenterer for, at de ved at være tilgængelige giver flere forskere muligheder for at udføre AI-sikkerhedsforskning og gennemgå modellerne for potentielle sårbarheder.
- I dag kræver annoteringsdata markant mere ekspertise inden for annotationsdomænet sammenlignet med for fem år siden. Men hvis AI-assistenter udfører som forventet i fremtiden, vil vi modtage mere værdifulde feedbackdata fra brugere, hvilket reducerer afhængigheden af omfattende data fra annotatorer.
Systemer til fundamentmodeller og fundamentmodeller til systemer
In denne snak, Christopher Ré, lektor ved Institut for Datalogi ved Stanford University, viser, hvordan fundamentmodeller ændrede de systemer, vi bygger. Han udforsker også, hvordan man effektivt bygger fundamentmodeller, låner indsigt fra databasesystemforskning og diskuterer potentielt mere effektive arkitekturer for fundamentmodeller end Transformeren.
Her er de vigtigste ting fra denne snak:
- Fundamentmodeller er effektive til at løse problemer med 'død ved 1000 nedskæringer', hvor hver enkelt opgave kan være relativt enkel, men den store bredde og mangfoldighed af opgaver udgør en betydelig udfordring. Et godt eksempel på dette er datarensningsproblemet, som LLM'er nu kan hjælpe med at løse meget mere effektivt.
- Efterhånden som acceleratorerne bliver hurtigere, opstår hukommelsen ofte som en flaskehals. Dette er et problem, som databaseforskere har behandlet i årtier, og vi kan vedtage nogle af deres strategier. For eksempel minimerer Flash Attention-tilgangen input-output-flow gennem blokering og aggressiv fusion: hver gang vi får adgang til et stykke information, udfører vi så mange operationer på det som muligt.
- Der er en ny klasse af arkitekturer, forankret i signalbehandling, der kunne være mere effektiv end Transformer-modellen, især til at håndtere lange sekvenser. Signalbehandling giver stabilitet og effektivitet, hvilket lægger grundlaget for innovative modeller som S4.
Online forstærkende læring i digitale sundhedsinterventioner
In hendes snak, Susan Murphy, professor i statistik og datalogi ved Harvard University, delte de første løsninger på nogle af de udfordringer, de står over for i udviklingen af online RL-algoritmer til brug i digitale sundhedsinterventioner.
Her er et par ting fra præsentationen:
- Dr. Susan Murphy diskuterede to projekter, som hun har arbejdet på:
- HeartStep, hvor aktiviteter er blevet foreslået baseret på data fra smartphones og bærbare trackere, og
- Oralytics for oral sundhed coaching, hvor interventioner var baseret på engagement data modtaget fra en elektronisk tandbørste.
- Når forskerne udvikler en adfærdspolitik for en AI-agent, skal forskerne sikre, at den er selvstændig og praktisk implementeret i det bredere sundhedssystem. Dette indebærer at sikre, at den tid, der kræves for en persons engagement, er rimelig, og at de anbefalede handlinger er både etisk forsvarlige og videnskabeligt plausible.
- De primære udfordringer ved at udvikle en RL-agent til digitale sundhedsinterventioner omfatter håndtering af høje støjniveauer, da mennesker lever deres liv og måske ikke altid er i stand til at reagere på beskeder, selvom de ønsker det, samt at håndtere stærke, forsinkede negative effekter .
Som du kan se, har NeurIPS 2023 givet et lysende indblik i fremtiden for kunstig intelligens. De inviterede samtaler fremhævede en tendens til mere effektive, ressourcebevidste modeller og udforskningen af nye arkitekturer ud over traditionelle paradigmer.
Nyder du denne artikel? Tilmeld dig flere AI-forskningsopdateringer.
Vi giver dig besked, når vi udgiver flere oversigtsartikler som denne.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.topbots.com/neurips-2023-invited-talks/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 1
- 10
- 10.
- 11
- 110
- 12
- 12 måneder
- 125
- 13
- 14
- 15 %
- 154
- 16
- 16.
- 17
- 20
- 20 år
- 2023
- 32
- 35 %
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- evne
- I stand
- Om
- acceleratorer
- adgang
- tilgængelig
- resultater
- opnå
- anerkende
- tværs
- aktioner
- Aktivering
- aktivt
- aktiviteter
- aktører
- adaptive
- tilføje
- Yderligere
- adresse
- adresser
- adressering
- vedtage
- fremskridt
- fordele
- alder
- Agent
- midler
- aggressive
- AGI
- siden
- AI
- AI assistent
- ai forskning
- AI-systemer
- hjælpemidler
- Alexander
- algoritme
- algoritmer
- tilpasning
- Alle
- Alliance
- tillade
- alene
- allerede
- også
- alternativ
- Skønt
- altid
- tvetydigheden
- blandt
- an
- analyse
- ,
- En anden
- enhver
- applikationer
- tilgang
- tilgange
- cirka
- ER
- argumenteret
- hævder
- artikel
- artikler
- kunstig
- kunstig generel intelligens
- AS
- Vurdering
- Assistant
- assistenter
- Associate
- foreninger
- sortiment
- At
- opnåelige
- opmærksomhed
- lyd
- autonom
- tilgængelighed
- baseret
- BE
- fordi
- bliver
- været
- adfærd
- være
- benchmark
- Benchmarks
- gavnlig
- Berkeley
- mellem
- Beyond
- Blanding
- blandinger
- blokering
- låntagning
- både
- bredde
- bredere
- bygge
- men
- by
- kom
- CAN
- kapaciteter
- fange
- tilfælde
- kategorier
- center
- Centers
- kæde
- udfordre
- udfordringer
- ændret
- chatbot
- Børn
- Christopher
- By
- klasse
- Rengøring
- coaching
- indsamler
- kombination
- kombinerer
- sammenlignet
- komplekse
- kompleksitet
- sammensætning
- beregningsmæssige
- computer
- Datalogi
- Computer Vision
- computing
- Konceptet
- Adfærd
- Konference
- konstruere
- indhold
- sammenhæng
- sammenhænge
- løbende
- bidrage
- bidragydere
- kontrol
- kontrolleret
- samtaler
- koordinere
- Core
- Cornell
- korrigere
- korrelationer
- kunne
- skabe
- skabere
- crowd
- afgørende
- kulturelle
- datasikring
- Nuværende
- Curriculum
- banebrydende
- data
- dataanalyse
- datacentre
- Database
- beskæftiger
- årtier
- december
- beslutte
- DeepMind
- Forsinket
- dykke
- Efterspørgsel
- krav
- demografiske
- demonstreret
- Afdeling
- designe
- detail
- detaljer
- udvikle
- udviklet
- udviklere
- udvikling
- Udvikling
- udvikling
- svært
- Broadcasting
- digital
- Digital sundhed
- retning
- Direktør
- opdaget
- drøftet
- diskuterer
- diskussion
- diskussioner
- Distinguished
- Mangfoldighed
- domæne
- Domæner
- domineret
- Dont
- fordobling
- dr
- grund
- i løbet af
- dynamisk
- e
- hver
- Edge
- redigering
- Effektiv
- effekter
- effektivitet
- effektiv
- effektivt
- indsats
- indsats
- enten
- Elektroteknik
- elektronisk
- fremgår
- vægt
- understreget
- muliggøre
- muliggør
- kodning
- engagere
- engagement
- Engineering
- forbedre
- forbedret
- nok
- sikre
- sikring
- Miljø
- Episoder
- lige
- især
- væsentlig
- etc.
- Ether (ETH)
- evaluere
- evaluering
- Endog
- begivenheder
- alle
- udvikle sig
- udviklende
- eksempel
- eksempler
- fremragende
- forventning
- forventninger
- forventet
- dyrt
- erfaring
- Oplevelser
- eksperimenter
- ekspert
- ekspertise
- eksperter
- Exploited
- udforskning
- udforsket
- udforsker
- Udforskning
- udsat
- omfattende
- øje
- Ansigtet
- ansigter
- letter
- svigtende
- ventilator
- hurtigere
- hurtigste
- tilbagemeldinger
- få
- færre
- felt
- udfylde
- Fornavn
- fem
- Blink
- flow
- strømme
- Fokus
- fokuserede
- følger
- Til
- overskuelig
- formation
- Foundation
- grundlægger
- fire
- Fjerde
- hyppig
- hyppigt
- fra
- fundamental
- fusion
- fremtiden
- Fremtiden for AI
- Gemini
- Generelt
- generel intelligens
- generere
- generere
- generation
- generative
- Generativ AI
- given
- giver
- glimt
- Go
- mål
- godt
- GPU
- GPU'er
- banebrydende
- gruppe
- Gruppens
- Dyrkning
- havde
- Håndtering
- hænder
- skadelig
- udnyttelse
- Harvard
- Harvard Universitet
- Have
- he
- hoved
- Helse
- sundhedspleje
- tunge
- Held
- hjælpe
- hjulpet
- hende
- Høj
- høj opløsning
- Fremhævet
- stærkt
- hindre
- hans
- time
- HOURS
- Hvordan
- How To
- Men
- http
- HTTPS
- menneskelig
- Mennesker
- i
- idé
- if
- lysende
- billede
- billedgenerering
- billeder
- implementeret
- betydning
- vigtigt
- Forbedre
- in
- dybdegående
- omfatter
- medtaget
- Herunder
- stigende
- stigende
- Indiana
- individuel
- uundgåelige
- oplysninger
- informative
- Infrastruktur
- iboende
- sagens natur
- Innovation
- innovativ
- indgang
- indsigt
- instans
- i stedet
- integration
- Intelligens
- interaktion
- sammenkoblet
- interesser
- interventioner
- ind
- introduceret
- inviteret
- IT
- Varer
- jpg
- domme
- Nøgle
- Kend
- viden
- kendt
- lab
- mærkning
- Sprog
- stor
- varig
- seneste
- æglæggende
- føre
- førende
- LÆR
- lærte
- elever
- læring
- Legacy
- mindre
- Lessons
- lad
- niveauer
- ligger
- lys
- ligesom
- sandsynlighed
- begrænsning
- Limited
- linda
- Liste
- Lives
- lokale
- Lang
- længere
- Se
- leder
- maskine
- machine learning
- mailing
- Main
- administrere
- styring
- mange
- Master
- matchende
- materiale
- Matters
- max-bredde
- Kan..
- meningsfuld
- mekanismer
- Memories
- Hukommelse
- blotte
- beskeder
- Meta
- metode
- Metrics
- måske
- million
- minimerer
- minutter
- mangler
- modaliteter
- model
- modeller
- øjeblik
- måned
- mere
- mere effektiv
- mest
- flyttet
- meget
- flere
- München
- skal
- navn
- indfødte
- Natural
- Behov
- negativ
- NeurIPS
- Ny
- New Orleans
- ingen
- Støj
- Ingen
- Bemærk
- roman
- nu
- nuancer
- nummer
- objekt
- objekter
- of
- tilbyde
- tilbyde
- Tilbud
- tit
- ældre
- on
- ONE
- online
- kun
- åbent
- open source
- åbnet
- Produktion
- Muligheder
- Optimer
- Option
- or
- oral
- Mental sundhed
- Organiseret
- orleans
- Andet
- Andre deltagere
- Andre
- vores
- i løbet af
- oversigt
- egen
- håndflade
- panel
- paradigmer
- parametre
- del
- deltagere
- deltog
- særlig
- især
- dele
- forbi
- pathways
- mønstre
- Mennesker
- per
- opfattelsen
- udføre
- ydeevne
- perspektiver
- stykke
- plato
- Platon Data Intelligence
- PlatoData
- plausibel
- spiller
- politik
- stillet
- positiv
- positivt
- besidder
- Muligheden
- mulig
- potentiale
- potentielt
- forudsige
- forudsigende
- præsentere
- præsentation
- forelagt
- tidligere
- primært
- primære
- principper
- Problem
- problemer
- procedure
- behandle
- Processer
- forarbejdning
- produceret
- produktiv
- Professor
- dybt
- Programmering
- projekt
- projekter
- fremtrædende
- egenskaber
- gennemprøvet
- give
- forudsat
- offentliggjort
- formål
- udøvelse
- kvalitet
- forespørgsler
- Quest
- helt
- Løb
- tilfældig
- rækkevidde
- hurtige
- hurtigt
- hellere
- ratings
- ægte
- virkelige verden
- rimelige
- modtage
- modtaget
- nylige
- anerkendelse
- anbefales
- reducere
- refleksion
- forstærkning læring
- relationer
- relativt
- frigive
- pålidelighed
- afhængighed
- resterende
- repetitiv
- Rapportering
- repræsentation
- repræsenterer
- kræver
- påkrævet
- Krav
- forskning
- forsker
- forskere
- løse
- Ressourcer
- Svar
- respondenter
- svar
- reaktioner
- ansvarlige
- gennemgå
- robust
- roller
- rødder
- groft
- haste
- sikker
- Sikkerhed
- skalering
- scenarier
- scene
- Videnskab
- VIDENSKABER
- Videnskabsmand
- se
- søger
- synes
- set
- semantik
- Series
- forme
- delt
- hun
- Shows
- underskrive
- Signal
- signaler
- signifikant
- betydeligt
- Simpelt
- enkelt
- færdigheder
- lille
- smartere
- smartphones
- smith
- So
- Social
- løsninger
- Løsninger
- SOLVE
- nogle
- Lyd
- Kilde
- Space
- rumlige
- specifikt
- tilbringe
- Stabilitet
- stabil
- Stanford
- Stanford University
- statistik
- Stadig
- strategier
- strøm
- styrker
- stærk
- strukturering
- sådan
- foreslår
- RESUMÉ
- forsyne
- overraskelse
- Susan
- syntaks
- syntese
- syntetisk
- syntetiske data
- systemet
- Systemer
- Takeaways
- tager
- Tal
- Talks
- Opgaver
- opgaver
- hold
- tech
- Teknisk
- tendens
- vilkår
- tekst
- tekstgenerering
- end
- at
- Fremtiden
- deres
- Them
- temaer
- Der.
- Disse
- de
- denne
- dem
- tre
- Gennem
- tid
- til
- sammen
- værktøj
- værktøjer
- TOPBOTS
- emne
- Emner
- I alt
- mod
- trackers
- traditionelle
- Kurser
- overførsel
- transformer
- Gennemsigtighed
- behandling
- Trend
- Sandheden
- forsøger
- TUR
- to
- typisk
- under
- gennemgår
- forståelse
- universitet
- opdateringer
- brug
- anvendte
- brugere
- ved brug af
- sædvanligvis
- udnyttet
- Værdifuld
- værdi
- række
- forskellige
- levende
- video
- Videoer
- synspunkter
- vision
- Sårbarheder
- W3
- var
- måder
- we
- wearable
- GODT
- var
- Hvad
- hvornår
- når
- ud fra følgende betragtninger
- hvorvidt
- som
- mens
- WHO
- hvorfor
- bred
- Bred rækkevidde
- vilje
- vindue
- med
- Arbejde
- arbejder
- Forkert
- år
- endnu
- dig
- unge
- zephyrnet